搭建Hadoop3.x完全分布式集群
零、资源准备
- 虚拟机相关:
- VMware workstation 16:虚拟机 > vmware_177981.zip
- CentOS Stream 9:虚拟机 > CentOS-Stream-9-latest-x86_64-dvd1.iso
- Hadoop相关
- jdk1.8:JDK > jdk-8u261-linux-x64.tar.gz
- Hadoop 3.3.6:Hadoop > Hadoop 3.3.6.tar.gz
- 辅助工具
- putty:tools > putty.exe
- mtputty:tools > mtputty.exe
- winscp:tools > WinSCP-6.3.1-Portable.zip
本文相关资源可以在文末提供的百度网盘资源中下载,除了vmware(你懂的…),以上资源均来源于官网,putty和winscp都是便捷式软件,无需安装
一、安装准备
1. 创建虚拟机

1) 选择典型安装

2)安装来源暂时不指定

3)操作系统选择Linux

4)设置虚拟机名称和位置
注意:位置可以根据自己电脑的使用情况,选择空闲更多的磁盘

5)磁盘容量指定

6)完成新建

7)虚拟机设置
注意:配置内存为2G,处理器2个,可根据电脑配置适当增加


2. 安装CentOS
1)设置CentOS映像文件
ISO映像选择下载的CentOS-Stream-9-xxxxxxx.iso

2)启动虚拟机

3)开始安装
选择Install CentOS Stream 9进行安装

4)语言选择English

5)安装前的配置

① 安装目的地
默认配置即可

② 软件选择
选择最小安装

③ 时区
区域选择Asia, 城市选择shanghai

④ 网络设置
确保网卡已经打开
设置主机名,也可以后续设置

⑤ 配置root用户密码
注意勾选Allow root SSH login with password,作为练习,密码可以设置简单点,比如123456

6)等待安装完成后重启系统。

7)配置虚拟机SSH远程登录
① 启动hadoop1
进入登录界面输入用户名root和密码,注意:密码输入时光标不会跳动

②配置虚拟机SSH远程登录
第一步,检查SSH服务是否安装和启动
在虚拟机中,分别执行rpm -qa | grep ssh和ps -ef | grep sshd命令,查看当前虚拟机是否安装了SSH服务,以及SSH服务是否启动。

rpm(英文全拼:redhat package manager) 原本是 Red Hat Linux 发行版专门用来管理 Linux 各项套件的程序,由于它遵循 GPL 规则且功能强大方便,因而广受欢迎。逐渐受到其他发行版的采用。RPM 套件管理方式的出现,让 Linux 易于安装,升级,间接提升了 Linux 的适用度。
ps(英文全拼:process status)命令用于显示当前进程的状态,类似于 windows 的任务管理器。grep (global regular expression) 命令用于查找文件里符合条件的字符串或正则表达式。该命令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
如果没有安装,可以使用以下命令进行安装
yum install openssh-server openssh-clients
第二步,修改SSH服务配置文件
默认情况下,CentOS Stream 9不允许用户root进行远程登录,在虚拟机Hadoop2中执行vi /etc/ssh/sshd_config命令编辑配置文件sshd_config。
PermitRootLogin yes

对于小白,这里介绍下
vi命令的简单使用方式:使用vi命令打开文件后,输入字母i进入插入模式 => 修改相应的文件内容 => 按Esc键进入命令行模式 => 输入:进入底行模式 => 输入x或者wq保存退出。如果文件修改后不想保存,进行底行模式后输入
q!进行不保存退出。
第三步, 重启SSH服务
systemctl restart sshd
3. 克隆主机
1)关闭hadoop1
使用命令shutdown -h now关闭hadoop1
或者

2)克隆虚拟机
克隆虚拟机hadoop2、hadoop3,以克隆hadoop2为例


->

-
完整克隆的虚拟机是通过复制原虚拟机创建完全独立的新虚拟机,不和原虚拟机共享任何资源,可以脱离原虚拟机独立使用。
-
链接克隆的虚拟机需要和原虚拟机共享同一个虚拟磁盘文件,不能脱离原虚拟机独立运行。

4. 网络设置
网络整体规划如下:
| 虚拟机名 | 主机名 | IP |
|---|---|---|
| hadoop1 | hadoop1 | 192.168.121.160 |
| hadoop2 | hadoop2 | 192.168.121.161 |
| hadoop3 | hadoop3 | 192.168.121.162 |
1)配置VMware Workstation网络
在VMware Workstation主界面,依次单击“编辑”→“虚拟网络编辑器…”选项,配置VMware Workstation网络。

2)配置静态IP
以hadoop1主机为例,类似配置hadoop2、 hadoop3
编辑配置文件
vi /etc/NetworkManager/system-connections/ens33.nmconnection

method=manual
address1=192.168.121.160/24,192.168.121.2
dns=114.114.114.114
修改uuid(只需要修改hadoop2、 hadoop3主机)
uuid的作用是使分布式系统中的所有元素都有唯一的标识码。
sed -i '/uuid=/c\uuid='`uuidgen`'' /etc/NetworkManager/system-connections/ens33.nmconnection
重启ens33网卡和重新加载网络配置文件
nmcli c reload
nmcli c up ens33
查看网络信息
ip a

检测网络
ping www.baidu.com

输入ctrl+c退出检测
3)主机名
配置hadoop2主机名
hostnamectl set-hostname hadoop2
配置hadoop3主机名
hostnamectl set-hostname hadoop3
4)配置虚拟机SSH远程登录

① 配置putty

② 配置winscp

5)修改映射文件
在虚拟机hadoop1主机执行vi /etc/hosts命令编辑映射文件hosts,在配置文件中添加如下内容。
192.168.121.160 hadoop1
192.168.121.161 hadoop2
192.168.121.162 hadoop3
在虚拟机hadoop1主机执行如下命令,拷贝配置到hadoop2, hadoop3
scp /etc/hosts root@hadoop2:/etc/hosts
scp /etc/hosts root@hadoop3:/etc/hosts

6) 关闭防火墙
关闭虚拟机Hadoop1、Hadoop2和Hadoop3的防火墙,分别在3台虚拟机中运行如下命令关闭防火墙并禁止防火墙开启启动。
-
关闭防火墙
systemctl stop firewalld -
禁止防火墙开机启动
systemctl disable firewalld
5. 免密登录
在集群环境中,主节点需要频繁的访问从节点,以获取从节点的运行状态,主节点每次访问从节点时都需要通过输入密码的方式进行验证,确定密码输入正确后才建立连接,这会对集群运行的连续性造成不良影响,为主节点配置SSH免密登录功能,可以有效避免访问从节点时频繁输入密码。接下来,虚拟机hadoop1作为集群环境的主节点实现SSH免密登录。
SSH免密登录原理(原理:非对称加密算法:公钥加密(给别人)、私钥解密给自己)

1)生成密钥
在虚拟机hadoop1中执行ssh-keygen -t rsa命令,生成密钥。

查看秘钥文件
在虚拟机hadoop1中执行ll /root/.ssh命令查看密钥文件。

2)复制公钥文件
将虚拟机hadoop1生成的公钥文件复制到集群中相关联的所有虚拟机,实现通过虚拟机hadoop1可以免密登录虚拟机hadoop1、hdp3-2和hdp3-3。
ssh-copy-id hadoop1

ssh-copy-id hadoop2
ssh-copy-id hadoop3
3)测试免密登录
ssh hadoop1
ssh hadoop2
ssh hadoop3

6. 安装JDK
约定:软件安装包存放于
/software,软件安装至/opt
1)创建目录
在虚拟机hadoop1中执行mkdir /software
2)上传jdk
利用winscp将jdk-8u261-linux-x64.tar.gz上传至hadoop1的/software目录
3)解压jdk
cd /software
ll
tar -xvf jdk-8u261-linux-x64.tar.gz -C /opt
4)配置JDK系统环境变量
在虚拟机hadoop1执行vi /etc/profile命令编辑环境变量文件profile,在该文件的底部添加配置JDK系统环境变量的内容。
export JAVA_HOME=/opt/jdk1.8.0_261
export PATH=$PATH:$JAVA_HOME/bin
记得执行source /etc/profile重新加载系统环境变量
5)验证jdk
java -version

6)同步文件
分发JDK安装目录和系统环境变量文件至hadoop2、hadoop3
scp -r /opt/jdk* root@hadoop2:/opt
scp /etc/profile root@hadoop2:/etcscp -r /opt/jdk* root@hadoop3:/opt
scp /etc/profile root@hadoop3:/etc
二、完全分布式部署
基于完全分布式模式部署Hadoop,需要将Hadoop中HDFS和YARN的相关服务运行在不同的计算机中,我们使用已经部署好的3台虚拟机Hadoop1、Hadoop2和Hadoop3。为了避免在使用过程中造成混淆,先规划HDFS和YARN的相关服务所运行的虚拟机。
| 虚拟机名 | 主机名 | IP | 角色 | 服务 |
|---|---|---|---|---|
| hadoop1 | hadoop1 | 192.168.121.160 | master | NameNode、ResourceManager |
| hadoop2 | hadoop2 | 192.168.121.161 | workers | SecondaryNameNode、DataNode、NodeManager |
| hadoop3 | hadoop3 | 192.168.121.162 | workers | DataNode、NodeManager |
1. 安装Hadoop
1)解压
以解压方式安装Hadoop,将Hadoop安装到虚拟机Hadoop1的/opt目录。
tar -xvf /software/hadoop-3.3.6.tar.gz -C /opt
2)配置环境变量
在Hadoop1执行vi /etc/profile命令配置系统环境变量,在该文件的底部添加如下内容。
export HADOOP_HOME=/opt/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3)验证
在虚拟机Hadoop1的任意目录执行hadoop version命令查看当前虚拟机中Hadoop的版本号。

2. 修改配置文件
| 配置文件 | 功能描述 |
|---|---|
| hadoop-env.sh | 配置Hadoop运行时的环境,确保HDFS能够正常运行NameNode、SecondaryNameNode和DataNode服务 |
| yarn-env.sh | 配置YARN运行时的环境,确保YARN能够正常运行ResourceManager和NodeManager服务 |
| core-site.sh | Hadoop核心配置文件 |
| hdfs-site.xml | HDFS核心配置文件 |
| mapred-site.xml | MapReduce核心配置文件 |
| yarn-site.xml | YARN核心配置文件 |
| workers | 控制从节点所运行的服务器 |
1)配置Hadoop运行时环境
在Hadoop安装目录/etc/hadoop/目录,执行vi hadoop-env.sh命令,在hadoop-env.sh文件的底部添加如下内容。
export JAVA_HOME=/opt/jdk1.8.0_261
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
指定Hadoop使用的JDK
指定管理NameNode、DataNode等服务的用户为root
2)配置hadoop
在Hadoop安装目录/etc/hadoop/目录,执行vi core-site.xml命令,在core-site.xml文件中添加如下内容。
<property><name>fs.defaultFS</name><value>hdfs://hadoop1:9000</value>
</property>
<property><name>hadoop.tmp.dir</name><value>/opt/data/hadoop-3.3.6</value>
</property>
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property>
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
<property><name>fs.trash.interval</name><value>1440</value>
</property>
注意:
- 上面的配置项要配置到
<configuration>标签中,后面的配置项类似配置项:
- fs.defaultFS:指定HDFS的通信地址
- hadoop.tmp.dir:指定Hadoop临时数据的存储目录
- hadoop.http.staticuser.user:指定通过Web UI访问HDFS的用户root
- hadoop.proxyuser.root.hosts:允许任何服务器的root用户可以向Hadoop提交任务
- hadoop.proxyuser.root.groups:允许任何用户组的root用户可以向Hadoop提交任务
- fs.trash.interval:指定HDFS中被删除文件的存活时长为1440秒
更多参数请参考官网:https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-common/core-default.xml
3)配置HDFS
在Hadoop安装目录/etc/hadoop/目录,执行vi hdfs-site.xml命令,在hdfs-site.xml文件中添加如下内容。
<property><name>dfs.replication</name><value>2</value>
</property>
<property><name>dfs.namenode.secondary.http-address</name><value>hadoop2:9868</value>
</property>
配置项:
dfs.replication:指定数据副本个数
dfs.namenode.secondary.http-address:指定SecondaryNameNode服务的通信地址
更多参数请参考官网:https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
4)配置MapReduce
在Hadoop安装目录/etc/hadoop/目录,执行vi mapred-site.xml命令,在mapred-site.xml文件中添加如下内容。
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
<property><name>mapreduce.job.ubertask.enable</name><value>true</value>
</property>
<property><name>mapreduce.jobhistory.address</name><value>hadoop1:10020</value>
</property>
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop1:19888</value>
</property>
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
配置项:
- mapreduce.framework.name:MapReduce的执行模式,默认是本地模式,另外可以设置成classic(采用MapReduce1.0模式运行) 或 yarn(基于YARN框架运行).
- mapreduce.job.ubertask.enable:是否允许开启uber模式,当开启后,小作业会在一个JVM上顺序运行,而不需要额外申请资源
- mapreduce.jobhistory.address:指定MapReduce历史服务的通信地址
- mapreduce.jobhistory.webapp.address:指定通过Web UI访问MapReduce历史服务的地址
- yarn.app.mapreduce.am.env:指定MapReduce任务的运行环境
- mapreduce.map.env:指定MapReduce任务中Map阶段的运行环境
- mapreduce.reduce.env:指定MapReduce任务中Reduce阶段的运行环境
更多参数请参考官网:https://hadoop.apache.org/docs/r3.3.6/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
5)配置YARN
在Hadoop安装目录/etc/hadoop/目录,执行vi yarn-site.xml命令,在yarn-site.xml文件中添加如下内容。
<property><name>yarn.resourcemanager.hostname</name><value>hadoop1</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property>
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<property><name>yarn.log.server.url</name><value>http://hadoop1:19888/jobhistory/logs</value>
</property>
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
配置项:
- yarn.resourcemanager.hostname:指定ResourceManager服务运行的主机
- yarn.nodemanager.aux-services:指定NodeManager运行的附属服务
- yarn.nodemanager.pmem-check-enabled:指定是否启动检测每个任务使用的物理内存
- yarn.nodemanager.vmem-check-enabled:指定是否启动检测每个任务使用的虚拟内存
- yarn.log-aggregation-enable:指定是否开启日志聚合功能
- yarn.log.server.url:指定日志聚合的服务器
- yarn.log-aggregation.retain-seconds:指定日志聚合后日志保存的时间
更多参数请参考官网:https://hadoop.apache.org/docs/r3.3.6/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
6)配置workers
在虚拟机Hadoop1的/opt/hadoop-3.3.6/etc/hadoop/目录,执行vi workers命令,将workers文件默认的内容修改为如下内容。
hadoop2
hadoop3
3. 同步文件
使用scp命令将虚拟机Hadoop1的Hadoop安装目录分发至虚拟机Hadoop2和Hadoop3中存放安装程序的目录。
scp -r /opt/hadoop-3.3.6 root@hadoop2:/opt
scp -r /opt/hadoop-3.3.6 root@hadoop3:/optscp /etc/profile root@hadoop2:/etc
scp /etc/profile root@hadoop3:/etc
4. 格式化
-
在基于伪分布式模式部署的Hadoop安装目录
/opt/pdch/hadoop-3.3.6中,关闭基于伪分布式模式部署的Hadoop -
在虚拟机Hadoop1执行
hdfs namenode -format命令,对基于完全分布式模式部署的Hadoop进行格式化HDFS文件系统的操作。
注意:格式化HDFS文件系统的操作只在初次启动Hadoop集群之前进行。
5. 启动
在虚拟机Hadoop1中执行命令启动Hadoop
start-dfs.sh
start-yarn.sh
6. 检测
1)jps查看进程
HDFS和YARN的相关服务运行在JVM进程中,可以执行jps命令查看当前虚拟机中运行的JVM进程。



2)Web UI
① 在本地计算机的浏览器输入http://192.168.121.160:9870查看HDFS的运行状态。

② 在本地计算机的浏览器输入http://192.168.121.160:8088查看YARN的运行状态。

如果希望在本地计算机上使用 http://hadoop1:9870和http://hadoop1:8088查看Hadoop运行状态, 需要配置本机的hosts文件
C:\Windows\System32\drivers\etc\hosts, 添加如下内容即可192.168.121.160 hadoop1 192.168.121.161 hadoop2 192.168.121.162 hadoop3
7. Hadoop启动服务总结
下面就Hadoop的服务启动进行简单的总结:
1)整体启动和关闭
start-all.sh
stop-all.sh
2)各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh stop namenode
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop secondarynamenode
(2)分别启动/停止YARN组件
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
3) 各个模块分开启动/停止
(1)整体启动/停止HDFS
start-dfs.sh
stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh stop-yarn.sh
8. 常见错误及解决办法
1)出现command not found错误
-
检查
/etc/profile文件中是否配置了正确的PATH -
如果
/etc/profile设置正确,是否没有执行source /etc/profile使环境变量生效
2)所有命令都不能运行
如果你发现不止安装的程序命令,就连原系统的内置命令都使用不了(比如ls、vi、cat等),很明显,你在修改/etc/profile时,将PATH路径设置错了。最常见的是错误就是在设置PATH时,PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin,把$PATH:漏掉了,这就相当于现在的PATH路径只有两个值$HADOOP_HOME/bin和$HADOOP_HOME/sbin。
解决办法:
1)恢复默认的PATH路径:
export PATH=/root/.local/bin:/root/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
2)使用vi命令修改/etc/profile文件,检查设置PATH的地方是否漏掉了$PATH:
3)不小心多次格式化
多次格式化导致DataNode 与 NameNode namespaceID不一致,导致启动HDFS失败,这里告诉最直接暴力的解决办法:
首先清空$hadoop.tmp.dir这个目录,以本文为例:
stop-all.sh
#本教程配置的hadoop.tmp.dir目录为/home/xiaobai/opt/hadoop/tmp
rm -fr /opt/data/hadoop-3.3.6
然后重新格式化HDFS即可
4)NameNode启动不成功
-
NameNode没有格式化
-
环境变量配置错误
-
Ip和hostname绑定失败,需要通过
ip a查看ip地址,重新配置/etc/hosts文件,设置正确的ip和hostname -
hostname含有特殊符号如
.(符号点),会被误解析
5)万能大法
一切的错误,最好的解决办法是查看日志
Hadoop的默认日志文件目录在$HADOOP_HOME/logs
三、案例——词频统计
WordCount示例是大数据计算里的”Hello World”, 它的功能是对输入文件的单词进行统计,输出每个单词的出现次数。
1. 准备数据
1)创建文本数据
在hadoop1上使用 vi /opt/data/word.txt命令编辑如下内容:
hello world
hello hadoop
hello hdfs
hello yarn
2)创建目录
在HDFS创建/wordcount/input目录,用于存放文件word.txt。
hdfs dfs -mkdir -p /wordcount/input
3)在虚拟机Hadoop1执行如下命令将文件word.txt上传到HDFS的/wordcount/input目录。
hdfs dfs -put /opt/data/word.txt /wordcount/input
4)查看文件是否上传成功
通过HDFS的Web UI查看文件word.txt是否上传成功。

2. 运行MapReduce程序
1)查看示例程序
进入虚拟机Hadoop1的/opt/hadoop-3.3.6/share/hadoop/mapreduce 目录,在该目录下执行“ll”命令,查看Hadoop提供的MapReduce程序。

2)执行程序
在MapReduce程序所在的目录执行下列命令,统计word.txt中每个单词出现的次数。
hadoop jar hadoop-mapreduce-examples-3.3.6.jar wordcount /wordcount/input /wordcount/output
- hadoop jar:用于指定运行的MapReduce程序;也可以使用yarn jar运行
- wordcount:表示程序名称;
- wordcount/input:表示文件word.txt所在目录;
- wordcount/output:表示统计结果输出的目录
3)MapReduce程序部分运行效果。

3. 查看程序运行状态
MapReduce程序运行过程中,使用浏览器访问YARN的Web UI查看MapReduce程序的运行状态。

在HDFS的Web UI查看统计结果。


附、网盘资源
链接:https://pan.baidu.com/s/1MSUdwbPArIAglQTDRhOjrg?pwd=jiau
提取码:jiau
相关文章:
搭建Hadoop3.x完全分布式集群
零、资源准备 虚拟机相关: VMware workstation 16:虚拟机 > vmware_177981.zipCentOS Stream 9:虚拟机 > CentOS-Stream-9-latest-x86_64-dvd1.iso Hadoop相关 jdk1.8:JDK > jdk-8u261-linux-x64.tar.gzHadoop 3.3.6&am…...
)
linux常用命令(二)
目录 前言 常用命令 1.ls命令 2. cd命令 3.pwd命令 4.mkdir 命令 5. rmdir 命令 6.rm 命令 7.cp命令 8.mv命令 9.touch命令 10.cat命令 11.more命令 12.less命令 13.head命令 14.tail命令 15.tail命令 16.find命令 17.tar命令 18.gzip命令 19.gunzip命令 …...

【Vue】Request模块 - axios 封装Vuex的持久化存储
📝个人主页:五敷有你 🔥系列专栏:Vue ⛺️稳中求进,晒太阳 Request模块 - axios 封装 使用axios来请求后端接口,一般会对axios进行一些配置(比如配置基础地址,请求响应拦截器…...

【2024第一期CANN训练营】4、AscendCL推理应用开发
文章目录 【2024第一期CANN训练营】4、AscendCL推理应用开发1. 创建代码目录2. 构建模型2.1 下载原始模型文件2.2 使用ATC工具转换模型2.3 注意事项 3. 模型加载3.1 示例代码 4. 模型执行4.1 获取模型描述信息4.2 准备输入/输出数据结构4.3 执行模型推理4.4 释放内存和数据类型…...
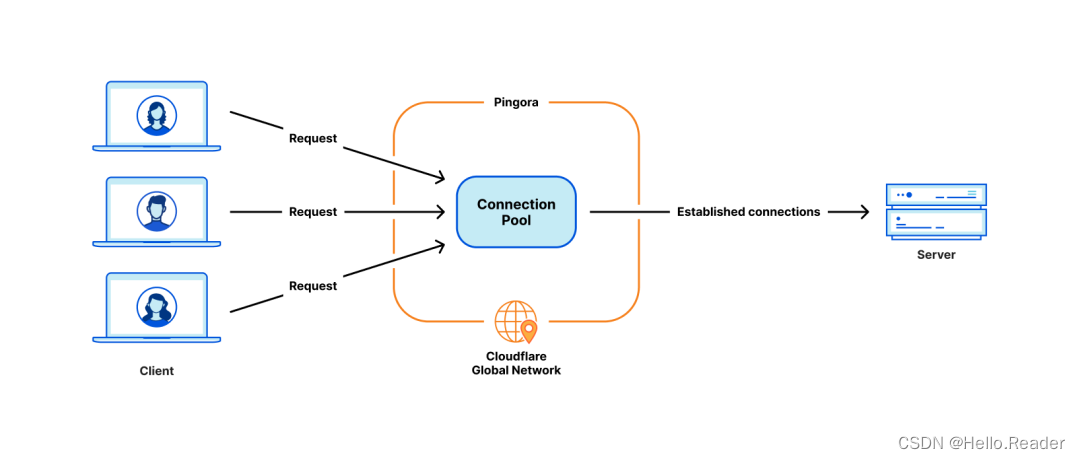
Rust 构建开源 Pingora 框架可以与nginx媲美
一、概述 Cloudflare 为何弃用 Nginx,选择使用 Rust 重新构建新的代理 Pingora 框架。Cloudflare 成立于2010年,是一家领先的云服务提供商,专注于内容分发网络(CDN)和分布式域名解析。它提供一系列安全和性能优化服务…...

MediaCodec源码分析 ACodec状态详解
前言 本文分析ACodec状态机,ACodec是MediaCodec的底层实现,在MediaCodec命令下切换不同状态进行编解码,基于7.0代码。 ACodec状态介绍 UninitializedState:未初始化状态。 在业务层调用MediaCodec. createByCodecName 完成后切换到LoadedState。 LoadedState:表示解码器…...
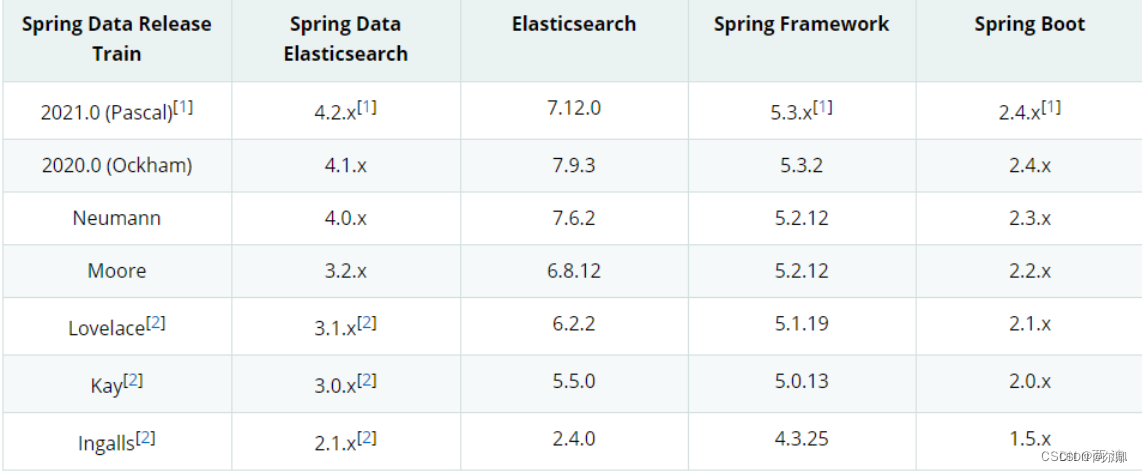
【Elasticsearch】windows安装elasticsearch教程及遇到的坑
一、安装参考 1、安装参考:ES的安装使用(windows版) elasticsearch的下载地址:https://www.elastic.co/cn/downloads/elasticsearch ik分词器的下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases kibana可视化工具下载…...

如何快速搭建物联网工业云平台
随着物联网技术的快速发展,物联网工业云平台已经成为推动工业领域数字化转型的重要引擎。合沃作为专业的物联网云服务提供商,致力于为企业提供高效、可靠的物联网工业云平台解决方案。本文将深入探讨物联网工业云平台的功能、解决行业痛点的能力以及如何…...

Spring Data访问Elasticsearch----Elasticsearch对象映射
Spring Data访问Elasticsearch----Elasticsearch对象映射 一、元模型(Meta Model)对象映射1.1 映射注解概述1.1.1 控制向Elasticsearch写入和从其读取哪些属性1.1.2 日期格式映射1.1.3 Range类型1.1.4 映射的字段名1.1.5 Non-field-backed属性1.1.6 其他属性注解 1.2 映射规则1…...

Linux之shell循环
华子目录 for循环带列表的for循环格式分析示例shell允许用户指定for语句的步长,格式如下示例 不带列表的for循环示例 基于C语言风格的for循环格式示例注意 while循环格式示例 until循环作用格式示例 循环控制breakcontinue详细语法示例 循环嵌套示例 for循环 for循…...
|基本语法概述)
Python入门教程(一)|基本语法概述
目录 1. 注释 2. 变量和数据类型 3. 控制流 4. 函数 5. 类与对象 6. 异常处理 7. 模块和包 8. 文件操作 1. 注释 在Python中,单行注释以#开始,多行注释使用三个引号 """ 或 。 # 这是单行注释""" 这是 多行 注释…...
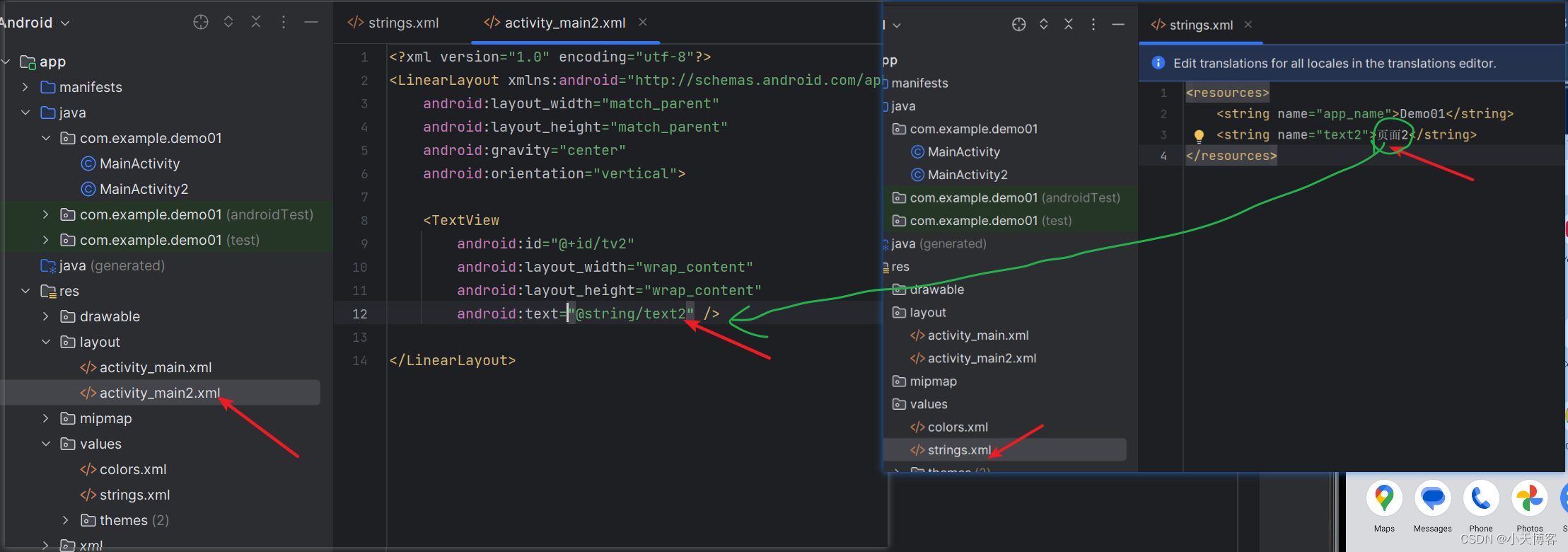
Android Studio入门——页面跳转
1.工程目录 2.MainActivity package com.example.demo01;import android.content.Intent; import android.os.Bundle; import android.view.View; import android.widget.TextView;import androidx.appcompat.app.AppCompatActivity;public class MainActivity extends AppCo…...
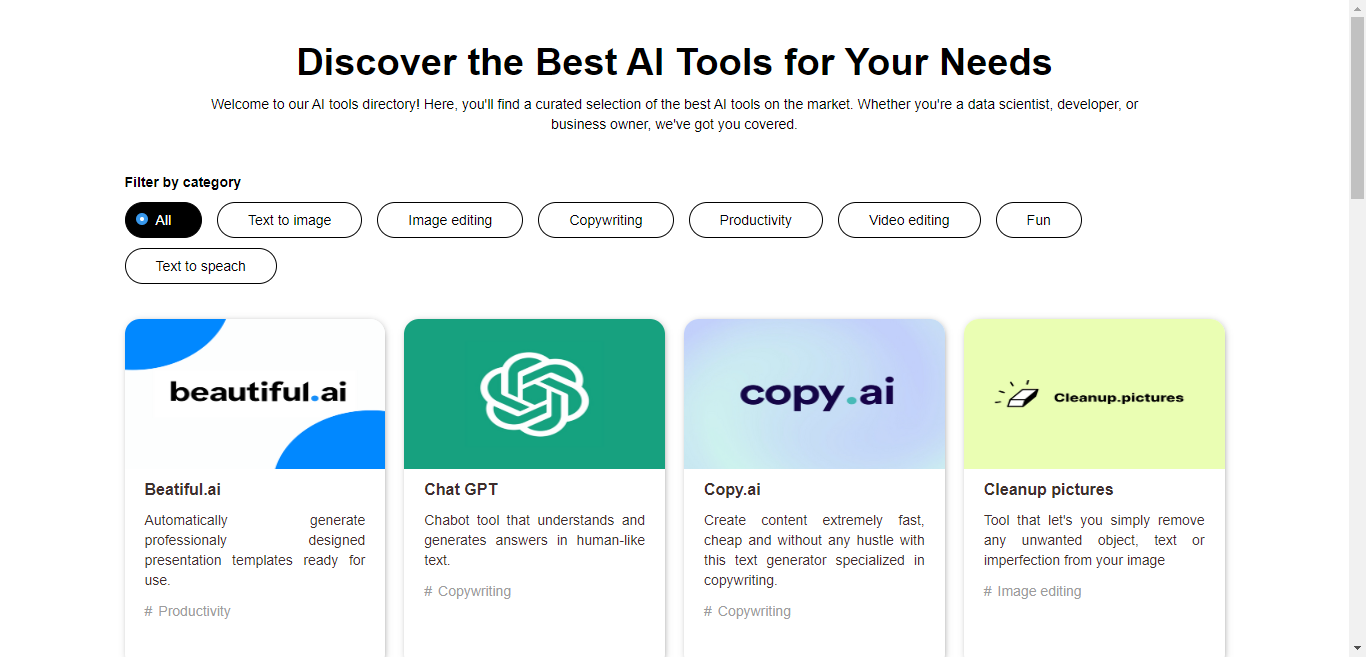
肝了三天,完成了AIGC工具网站大全,建议收藏再看
说是肝了三天,其实远远不止,前前后后,从资料搜集到最后整理成文,有近一个月了,大家看在整理不易的份上,给点个赞吧,不要光顾着收藏呀! 国内网站 AIGC 导航 https://www.aigc.cn 网…...
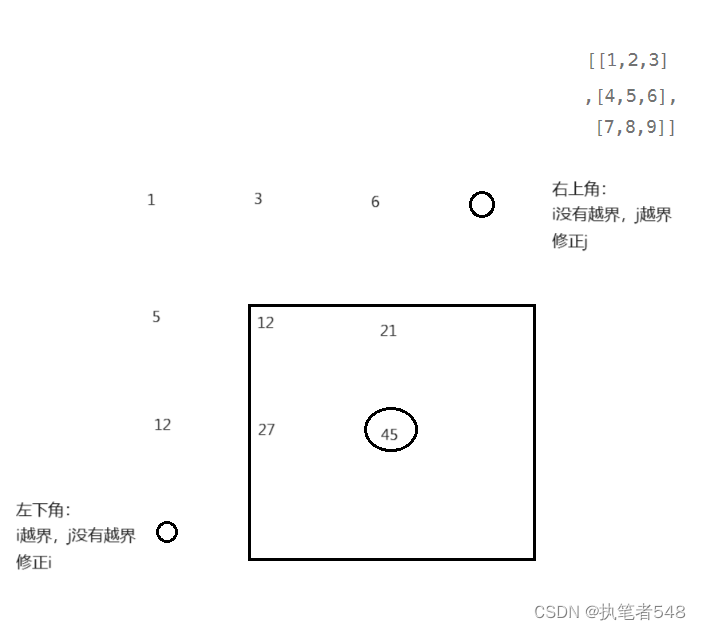
算法练习:前缀和
目录 1. 一维前缀和2. 二维前缀和3. 寻找数组中心下标4. 除自身以外数组的乘积5. !和为k的子数字6. !和可被k整除的子数组7. !连续数组8. 矩阵区域和 1. 一维前缀和 题目信息: 题目链接: 一维前缀和思路:求前缀和数组,sum dp[r] …...

Kafka MQ 生产者
Kafka MQ 生产者 生产者概览 尽管生产者 API 使用起来很简单,但消息的发送过程还是有点复杂的。图 3-1 展示了向 Kafka 发送消息的主要步骤。 我们从创建一个 ProducerRecord 对象开始,ProducerRecord 对象需要包含目标主题和要发送的内容。我们还可以…...

SQLiteC/C++接口详细介绍之sqlite3类(十)
返回目录:SQLite—免费开源数据库系列文章目录 上一篇:SQLiteC/C接口详细介绍之sqlite3类(九) 下一篇:SQLiteC/C接口详细介绍之sqlite3类(十一) 30.sqlite3_enable_load_extension&#x…...

Vue中nextTick一文详解
什么是 nextTick? 在 Vue 中,当我们修改数据时,Vue 会自动更新视图。但是,由于 JavaScript 的事件循环机制,我们无法立即得知视图更新完成的时机。这时候,我们就需要使用 nextTick 来获取视图更新完成后的…...

爱奇艺 CTR 场景下的 GPU 推理性能优化
01 背景介绍 GPU 目前大量应用在了爱奇艺深度学习平台上。GPU 拥有成百上千个处理核心,能够并行的执行大量指令,非常适合用来做深度学习相关的计算。在 CV(计算机视觉),NLP(自然语言处理)的模型…...
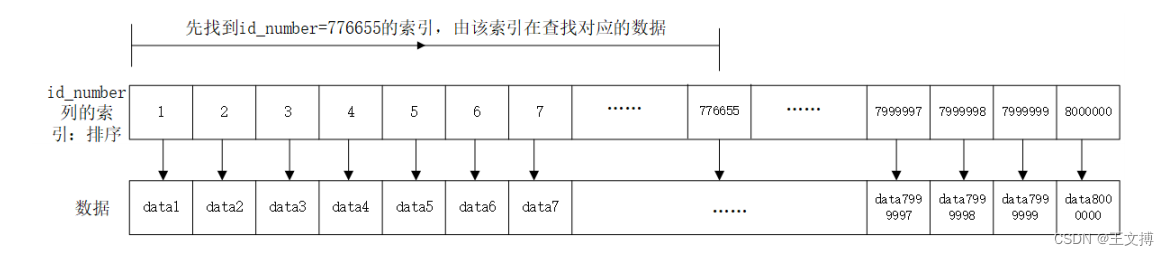
详解MySql索引
目录 一 、概念 二、使用场景 三、索引使用 四、索引存在问题 五、命中索引问题 六、索引执行原理 一 、概念 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。暂时可以理解成C语言的指针,文章后面详解 二、使用场景 数据量较大,且…...

struct 和 union 的区别?
struct和union的分对应点总结 存储方式: struct:struct中的每个成员都拥有独立的内存空间。一个struct变量的总长度是其所有成员的长度之和,且通常会根据编译器的内存对齐规则进行适当调整。union:union中的所有成员共享同一段内…...

服务器日志分析实战:用Python追踪HTTP 404错误并可视化异常频率
作为一名爬虫开发者或网站运维人员,服务器日志就像飞机的“黑匣子”——它记录了每个请求的来龙去脉。而404错误(页面未找到)尤其值得关注:它可能是用户输错了网址,可能是你爬虫的URL构造逻辑有漏洞,也可能是网站改版后旧的链接失效了。更严重的是,大量突然涌出的404请求…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...