Hive优化
工作中涉及到优化部分不多,下面的一些方案可能会缺少实际项目支撑,这里主要是为了完备一下知识体系。
参考的hive参数管理文档地址:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
对于Hive优化,可以从下面几个角度出发:
- 一、建表优化
- 二、存储压缩优化
- 1.存储
- 2.压缩
- 三、Job层面优化
- 1.合理控制map&reduce个数
- 2.JVM重用
- 3.Fetch抓取
- 4.本地模式
- 5.并行执行
- 6.推测执行
- 7.严格模式
- 四、HQL层面优化
- 1.列裁剪&分区裁剪
- 2.谓词下推
- 3.CBO优化
- 4.group by优化
- 5.join优化
- 6.order by+limit
- 7.避免产生笛卡尔积
一、建表优化
根据业务选择合适的分区表或分桶表,分区在HDFS上的表现就是分文件夹,分桶就是分文件,这样在进行数据查询分析时可以避免全表扫描,直接读取目标分区或分桶。
二、存储压缩优化
1.存储
存储主要分为列式存储与行式存储,hive支持的主要存储方式有:
TextFile:行式,也是hive默认的存储格式,数据以纯文本格式存储,可直接文本编辑器打开查看。
Sequence File:行式,序列化为二进制存储,可以被MR高效读写,但因为行式所以不适合SQL分析,因此当某些需要MR处理但不需要进行SQL分析的可以选择。
ORC File:列式,RCFile的升级版,对hadoop生态的原生支持比较好,Hive 0.11版本及之后引入。支持ACID事务和行级别的更新。
Parquet File:列式,兼容性比较好,包括hadoop生态和很多非hadoop生态系统。
hive中,往往是基于大数据量对某些指标进行分析计算,只需要处理某几个特定的字段就行了,因此一般选择列式存储,可以提升读的效率。
2.压缩
压缩可以从3个角度来说,分别是map输出结果的压缩,reduce最终输出结果的压缩,和同一个job中不同MR之间中间结果数据的压缩。压缩会一定程度的增加CPU开销,但是降低了磁盘IO和网络传输IO。
开发中常用的方案:ORC/Parquet + Snappy
三、Job层面优化
1.合理控制map&reduce个数
MR中,一个map或者一个reduce就是一个进程,进程的创建启动开销大,如对于小文件问题,会造成为每个小文件都启动一个map任务,浪费资源。可以通过参数设置在map任务执行前对小文件进行合并。或者是,input的文件很大,处理逻辑又复杂,就会导致单个map的负载过重,造成整体任务缓慢,这种情况可以通过减小每个map可以读取的数据量最大值来增加map数量,提高并行计算的能力。
对于reduce的个数,可以通过调整每个reduce处理的数据量进而调整reduce的个数,或者是通过参数直接强行指定个数。但要注意reduce个数太少可能会导致单个任务处理缓慢,过多可能会导致reduce任务启动开销的浪费和输出小文件过多的问题。一般来说,让hive自己选择就好。
2.JVM重用
原因同上,默认情况下,每个map或reduce任务都会启动一个JVM进程,通过参数设置JVM重用JVM重用就是为了减少进程的频繁创建启动,当通过参数指定每个JVM进程处理的任务数后,JVM实例只有在处理完指定的任务数量之后才会销毁。需要注意的是,设置JVM重用并不会影响启动的JVM个数,区别只是在于执行完任务后是直接执行下一个任务,还是销毁进程,重新启动一个JVM
去执行下个任务。可以通过在hadoop的mapred-site.xml配置文件中设置 mapreduce.job.jvm.numtasks参数(在一些低版本的hadoop中参数可能为mapred.job.reuse.jvm.num.tasks)为JVM设置可重复运行的task任务个数。

参考:https://hadoop.apache.org/docs/r2.5.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
3.Fetch抓取
hive读取HDFS数据有两种方式:
1)通过MR读取。
2)直接读取。
开启fetch机制后,特定条件下的查询不会转换成MR任务,而是直接从HDFS中读取数据,从而提升效率。
通过参数hive.fetch.task.conversion设置,值允许为none, minimal , more。
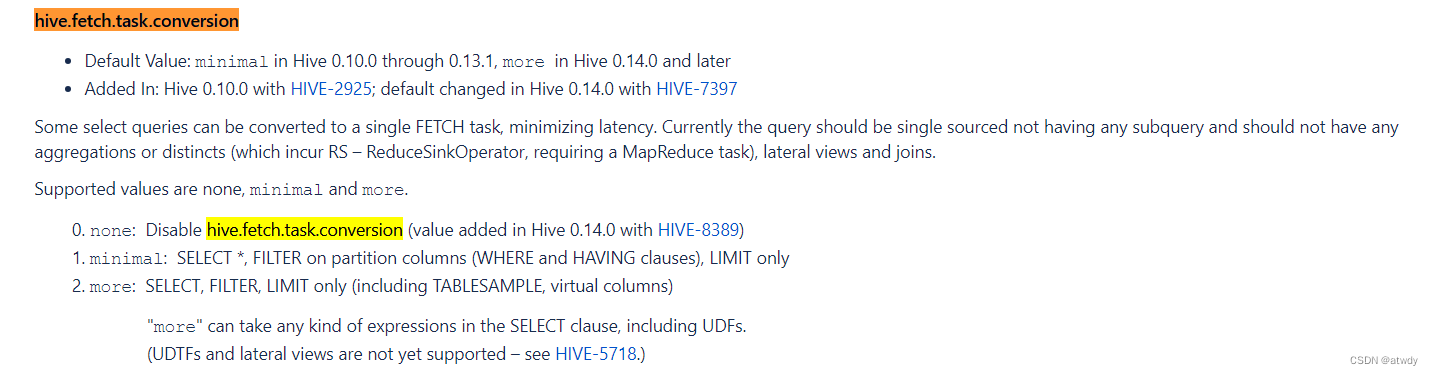
在Hive 0.14.0及之后默认值为more,当涉及到简单的select全局查找或字段查找,where过滤或者limit查找时不走MR。这就要求当前的查询不能出现分组、聚合、关联等类似操作,很好理解,因为涉及到后面的操作时必须启动MR计算,而不是简单的将数据原样读取返回即可。
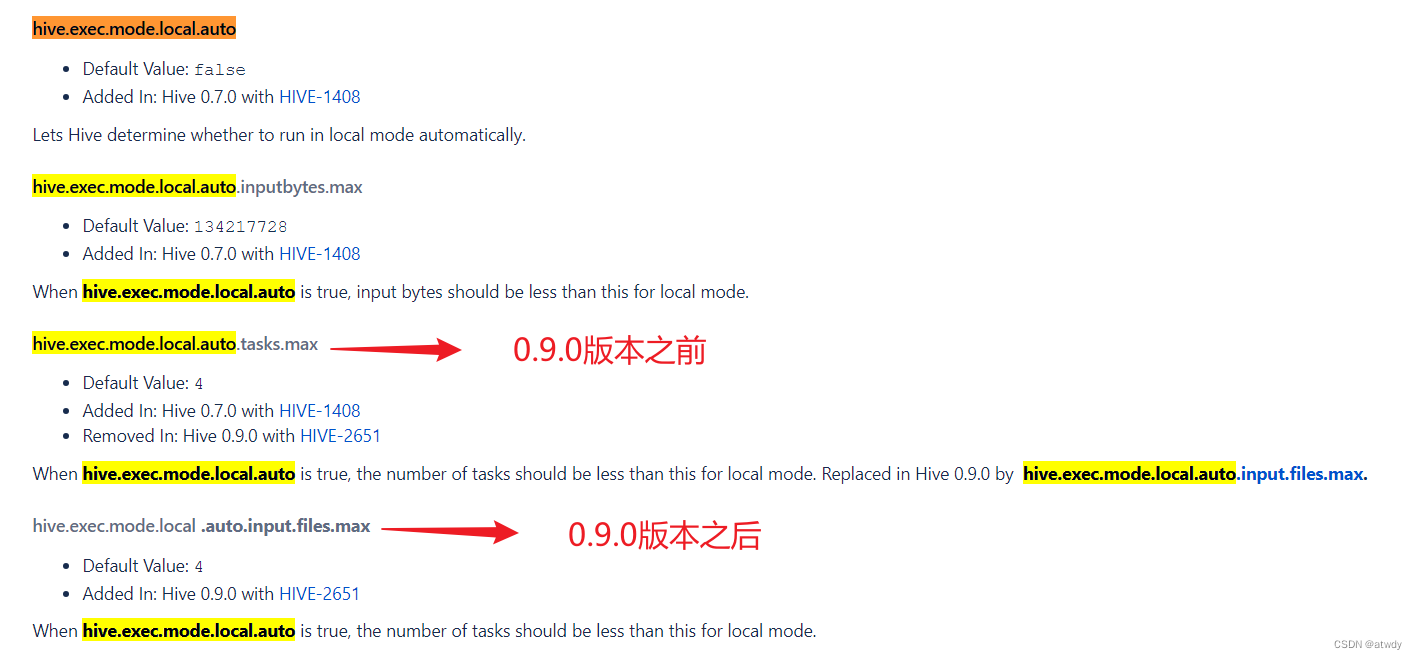
4.本地模式
这点主要是针对小数据量的任务而言的。也就是对于小数据量的任务,不提交到集群执行,而是在集群的某个单一节点上执行。好处是避免了集群间不必要的资源协调调度和跨节点数据传输。可通过下面参数开启配置:
5.并行执行
一个HiveSQL可能会转化为多个stage阶段,如果这些阶段之间没有依赖关系是可以并行执行的,最大化利用集群资源。类似于(A) union all (B),此时AB是可以并行执行的。可以通过下面参数设置:

并行执行受限于集群资源,只有当集群资源充足才会并行执行。同时对于小数据量的sql可能反而导致效率变慢,原因是增加了资源和任务的调度开销,超过了小查询本身执行的时间。
6.推测执行
这主要是针对个别执行过慢的任务的一种优化策略。如果某个任务执行时间明显超过其他同类型任务时,可能是因为执行该任务的节点硬件故障,网络拥堵,或者其他原因。此时hive会重启一个备份任务执行,和原任务谁先执行完就以谁的结果为准。设置参数:

参考:https://hadoop.apache.org/docs/r2.5.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
7.严格模式
严格模式就是不让执行hive认为有“风险”的查询,比如分区表必须使用分区过滤,order by时必须跟着limit子句,限制产生笛卡尔积的查询等。参数设置:

四、HQL层面优化
1.列裁剪&分区裁剪
就是查询时只select需要的字段,对于分区表指定分区查找。
2.谓词下推
就是将where数据过滤尽早的提前到map端过滤,而不是在reduce端对处理后的结果进行过滤。类似于下面这两段SQL:
-- 没有使用谓词下推的sql执行逻辑
select *
from A join B on A.id = B.id
where A.id<10;-- 使用谓词下推后的sql执行逻辑
select*
from (select * from A where id<10) A join B on A.id=B.id;
hive中默认开启此配置:

3.CBO优化
CBO:Cost based Optimizer,基于代价/成本的优化。比如多个表join的时候,如果不考虑CBO优化,往往前面的表作为驱动表被加载进内存,后面的表作为被驱动表进行磁盘扫描。开启CBO优化后,hive会根据统计信息决定最优的表连接顺序,连接算法等。可以通过下面4个参数开启设置:
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
在hive1.1.0之后默认开启:

关于hive中CBO优化细节可以查看https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive
4.group by优化
group by是对相同key的数据拉取到同一个reduce中处理,如果这个key的数据量很大,就可能导致数据倾斜。可以通过开启map端预聚合,和当出现数据倾斜时开启负载均衡来优化。
负载均衡指的是将原先的一个MR job转换成两个MR job,第一阶段随机打散预聚合,第二阶段对预聚合的结果进行最终聚合。
可通过下面参数开启:
-- 开启map端预聚合
set hive.map.aggr = true;
-- map端预聚合的数据条数
set hive.groupby.mapaggr.checkinterval = 100000;
-- 开启负载均衡
set hive.groupby.skewindata = true;

5.join优化
join优化可分为map join(小表join大表)和SMB join(大表join大表)。
map join
map join是将小表直接分发到各个map任务的进程中,在map进程中完成join,省略了shuffle的过程,也就避免了数据倾斜的可能。
参数设置:
-- 开启map join
set hive.auto.convert.join=true;
-- 小表阈值,单位字节,大约25MB
set hive.mapjoin.smalltable.filesize=25000000;
SMB join
SMB(Sort Merge Bucket Join),这种方式要求两个表都根据关联字段分桶并排序。原理是将两个大表分桶,且两表桶数成倍数关系,那么关联的时候,驱动表的每个桶都只会被驱动表中与自己相关的桶进行连接,避免了全局shuffle,在map阶段就可以完成,所以也不会导致数据倾斜单个任务执行缓慢。同时因为桶内有序,所以连接时可以采用类似归并排序的方式进行连接,提高连接效率。
6.order by+limit
如果排序时不加limit限制,那么就会将所有数据拉取到同一个reduce中进行排序,非常容易导致任务执行缓慢。而+limit限制之后,比如说limit 5,那么会首先在每个reduce中对局部数据进行排序,并从每个reduce中找出局部前5的数据,再将所有reduce的结果进行最终排序,选出全局前5的数据。
7.避免产生笛卡尔积
这里主要就是说,join连接时要指定连接字段,一般开发中也不会犯这种错误。
相关文章:
Hive优化
工作中涉及到优化部分不多,下面的一些方案可能会缺少实际项目支撑,这里主要是为了完备一下知识体系。 参考的hive参数管理文档地址:https://cwiki.apache.org/confluence/display/Hive/ConfigurationProperties 对于Hive优化,可以…...

React 的 diff 算法
React 的 diff 算法的演进。 在 React 16 之前,React 使用的是称为 Reconciliation 的 diff 算法。Reconciliation 算法通过递归地比较新旧虚拟 DOM 树的每个节点,找出节点的差异,并将这些差异应用到实际的 DOM 上。整个过程是递归的&#x…...
综合知识篇07-软件架构设计考点(2024年软考高级系统架构设计师冲刺知识点总结系列文章)
专栏系列文章: 2024高级系统架构设计师备考资料(高频考点&真题&经验)https://blog.csdn.net/seeker1994/category_12593400.html案例分析篇00-【历年案例分析真题考点汇总】与【专栏文章案例分析高频考点目录】(2024年软考高级系统架构设计师冲刺知识点总结-案例…...
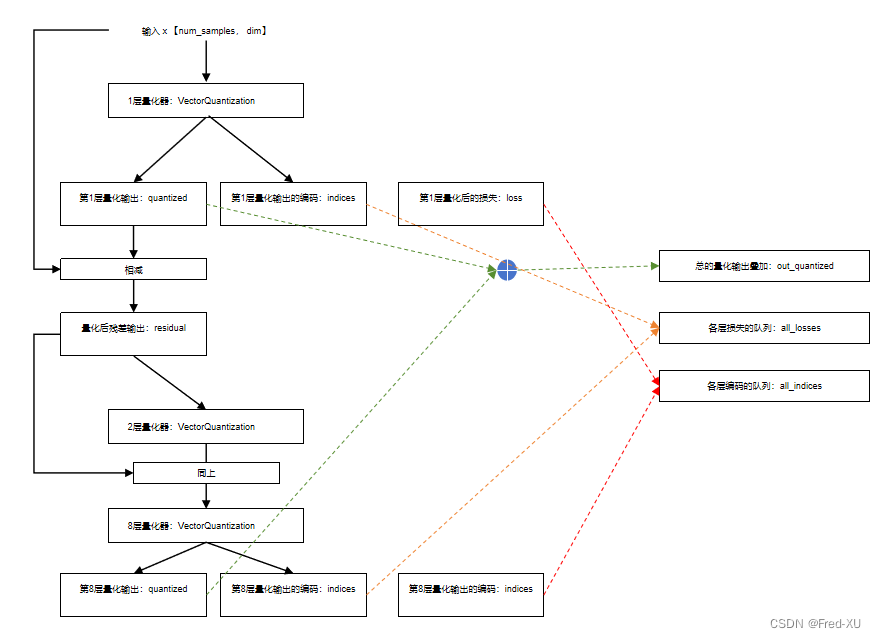
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。 知乎专栏地址: 语音生成专栏 系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【G…...

Flutter第四弹:Flutter图形渲染性能
目标: 1)Flutter图形渲染性能能够媲美原生? 2)Flutter性能优于React Native? 一、Flutter图形渲染原理 1.1 Flutter图形渲染原理 Flutter直接调用Skia。 Flutter不使用WebView,也不使用操作系统的原生控件,而是…...
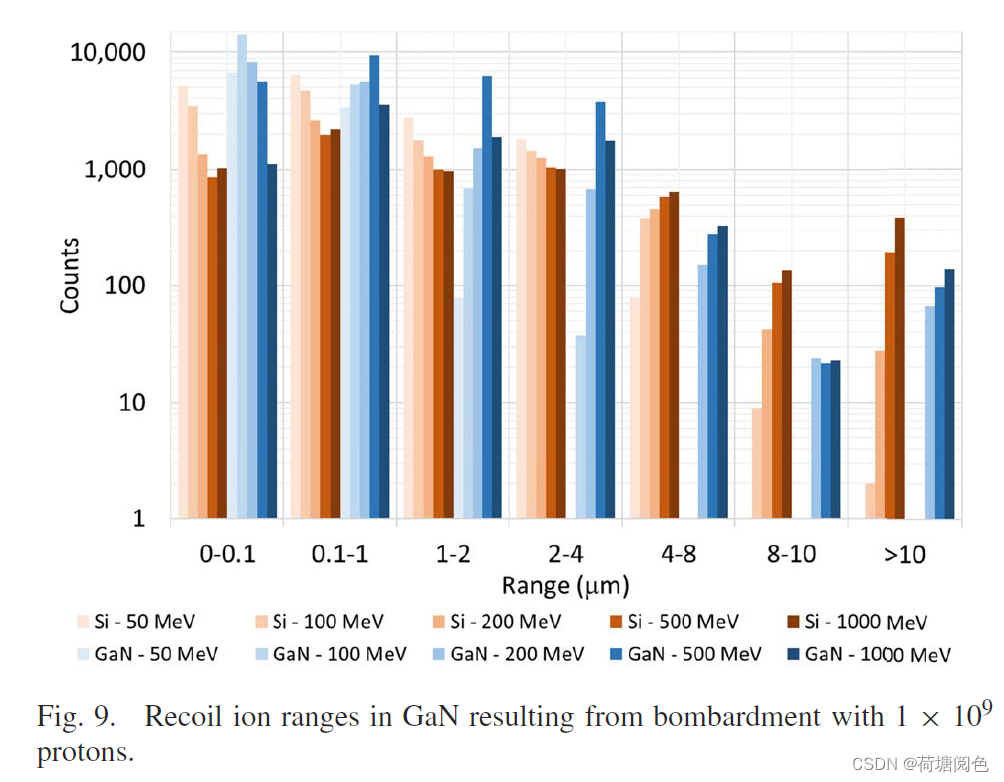
[氮化镓]GaN中质子反冲离子的LET和射程特性
这篇文件是一篇关于氮化镓(GaN)中质子反冲离子的线性能量转移(LET)和射程特性的研究论文,发表在《IEEE Transactions on Nuclear Science》2021年5月的期刊上。论文的主要内容包括: 研究背景:氮…...
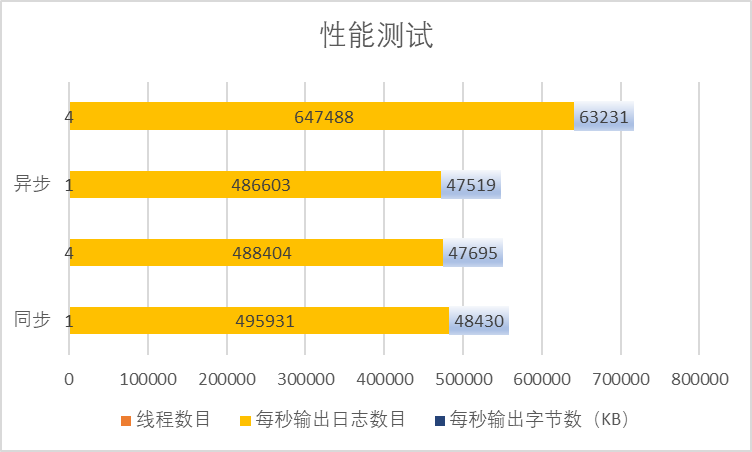
【项目】C++ 基于多设计模式下的同步异步日志系统
前言 一般而言,业务的服务都是周而复始的运行,当程序出现某些问题时,程序员要能够进行快速的修复,而修复的前提是要能够先定位问题。 因此为了能够更快的定位问题,我们可以在程序运行过程中记录一些日志,通…...

安卓国产百度网盘与国外云盘软件onedrive对比
我更愿意使用国外软件公司的产品,而不是使用国内百度等制作的流氓软件。使用这些国产软件让我不放心,他们占用我的设备大量空间,在我的设备上推送运行各种无用的垃圾功能。瞒着我,做一些我不知道的事情。 百度网盘安装包大小&…...

健身·健康行业Web3新尝试:MATCHI
随着区块链技术进入主流,web3 运动已经开始彻底改变互联网,改写从游戏到金融再到艺术的行业规则。现在,MATCHI的使命是颠覆健身行业。 MATCHI是全球首个基于Web3的在线舞蹈健身游戏和全球首个Web3舞蹈游戏的发起者,注册于新加坡&a…...

VB.NET高级面试题:什么是 VB.NET?与 Visual Basic 6.0 相比有哪些主要区别?
什么是 VB.NET?与 Visual Basic 6.0 相比有哪些主要区别? VB.NET是一种面向对象的编程语言,是微软公司推出的.NET平台上的一种编程语言,用于构建Windows应用程序、Web应用程序和Web服务等。它是Visual Basic的后续版本࿰…...
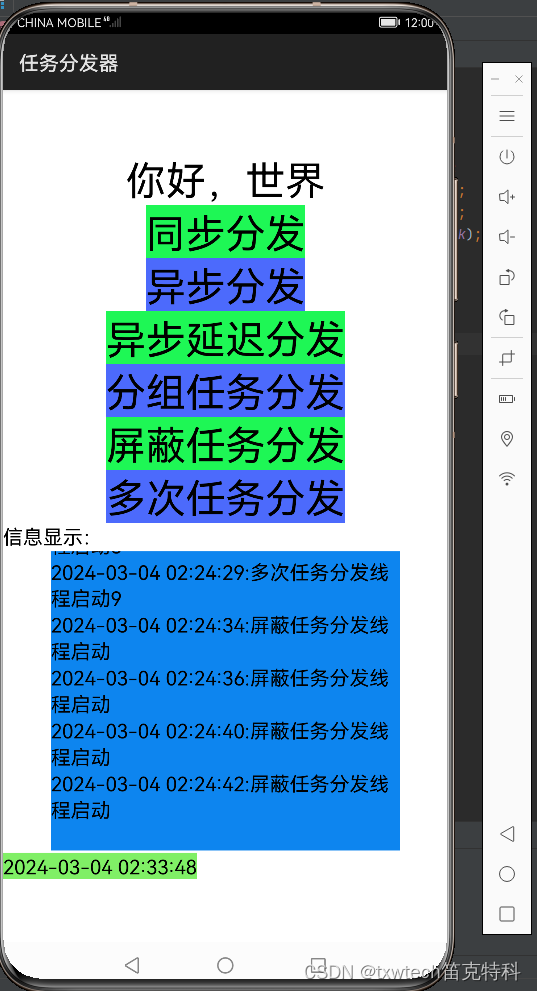
30.HarmonyOS App(JAVA)鸿蒙系统app多线程任务分发器
HarmonyOS App(JAVA)多线程任务分发器 打印时间,记录到编辑框textfield信息显示 同步分发,异步分发,异步延迟分发,分组任务分发,屏蔽任务分发,多次任务分发 参考代码注释 场景介绍 如果应用的业务逻辑比…...

伺服电机编码器的分辨率指得是什么?
伺服电机编码器的分辨率是伺服电机编码器的重要参数。 一般来说,具体的伺服电机编码器型号可以找到对应的分辨率值。 伺服电机编码器的分辨率和精度不同,但也有一定的关系。 伺服电机编码器的分辨率是多少? 1、伺服编码器(同步伺…...

WPF中使用LiveCharts绘制散点图
一、背景 这里的代码使用MVVM模式进行编写 二、Model public class DataPoint{public double X { get; set; }public double Y { get; set; }} 三、ViewModel public class ScatterChartViewModel{public SeriesCollection Series { get; set; }public ScatterChartViewMod…...
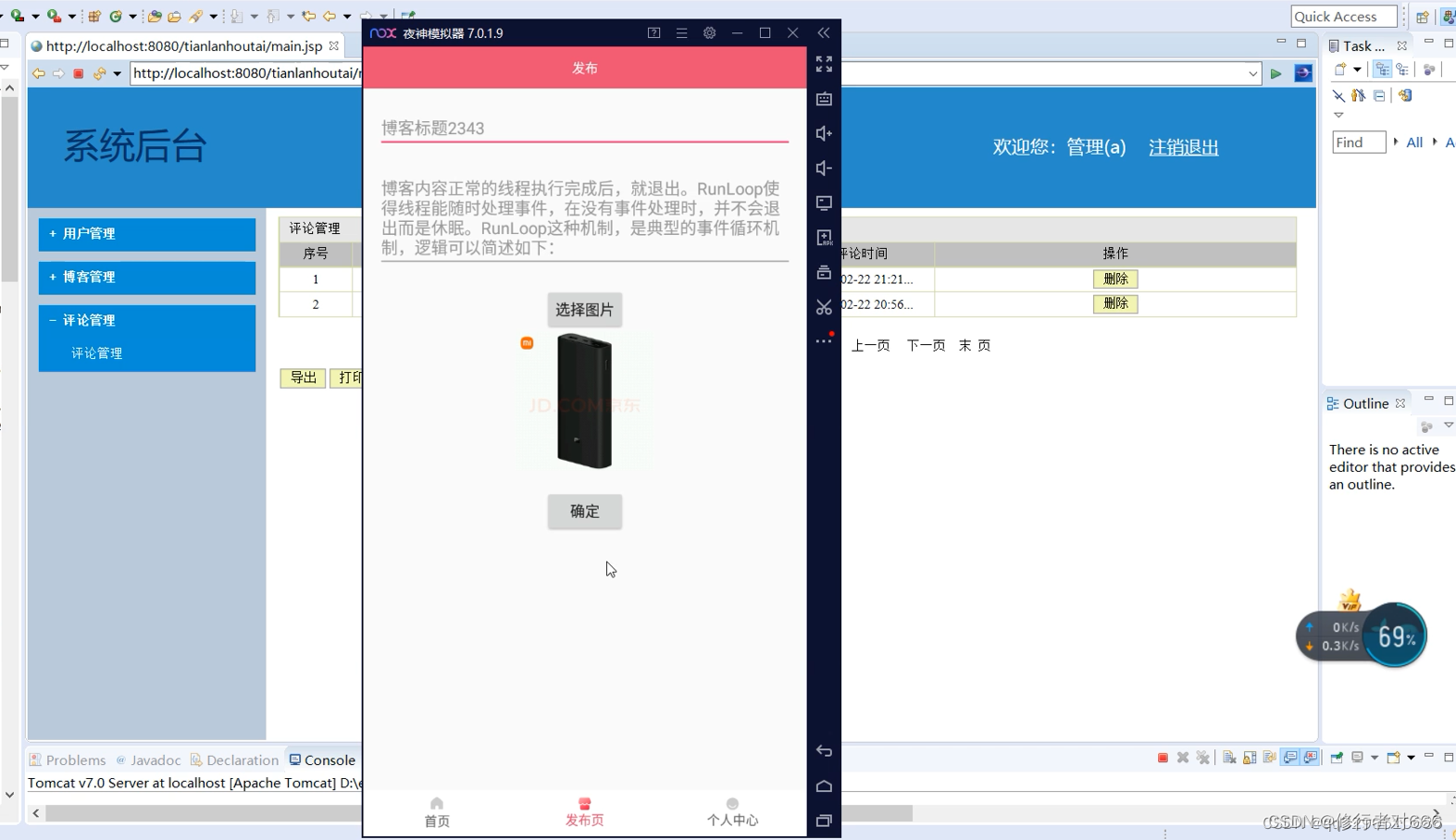
Android Studio实现内容丰富的安卓博客发布平台
获取源码请点击文章末尾QQ名片联系,源码不免费,尊重创作,尊重劳动 项目编号078 1.开发环境android stuido jdk1.8 eclipse mysql tomcat 2.功能介绍 安卓端: 1.注册登录 2.查看博客列表 3.查看博客详情 4.评论博客, 5.…...
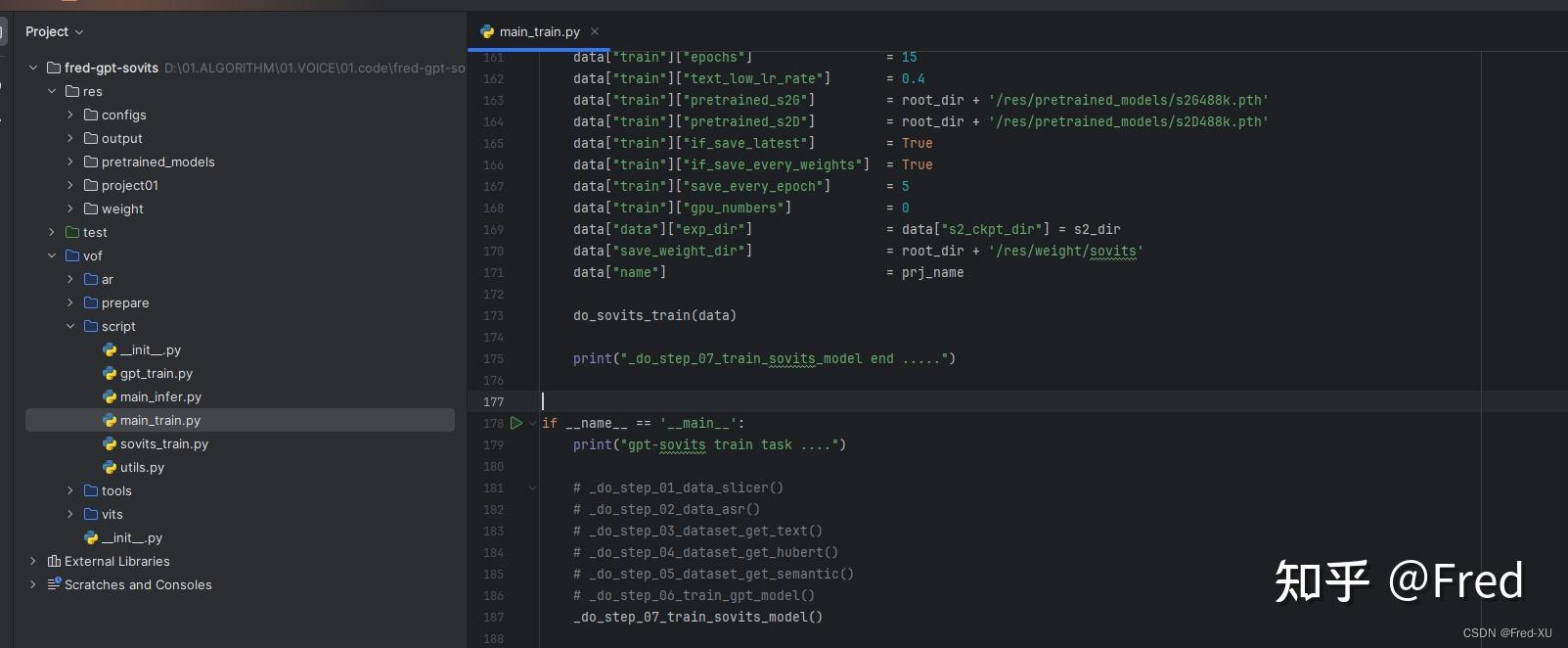
【GPT-SOVITS-01】源码梳理
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。 知乎专栏地址: 语音生成专栏 系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【G…...

数据结构大合集02——线性表的相关函数运算算法
函数运算算法合集02 顺序表的结构体顺序表的基本运算的实现1. 建立顺序表2. 顺序表的基本运算2.1 初始化线性表2. 2 销毁顺序表2.3 判断顺序表是否为空表2.4 求顺序表的长度2.5 输出顺序表2.6 按序号求顺序表中的元素2.7 按元素值查找2.8 插入数据元素2.9 删除数据元素 单链表的…...

threejs案例,与静态三角形网格的基本碰撞, 鼠标环顾四周并投球游戏
创建一个时钟对象: const clock new THREE.Clock();这行代码创建了一个新的THREE.Clock对象,它用于跟踪经过的时间。这在动画和物理模拟中很有用。 2. 创建场景: const scene new THREE.Scene();这行代码创建了一个新的3D场景。所有的物体(如模型、灯…...
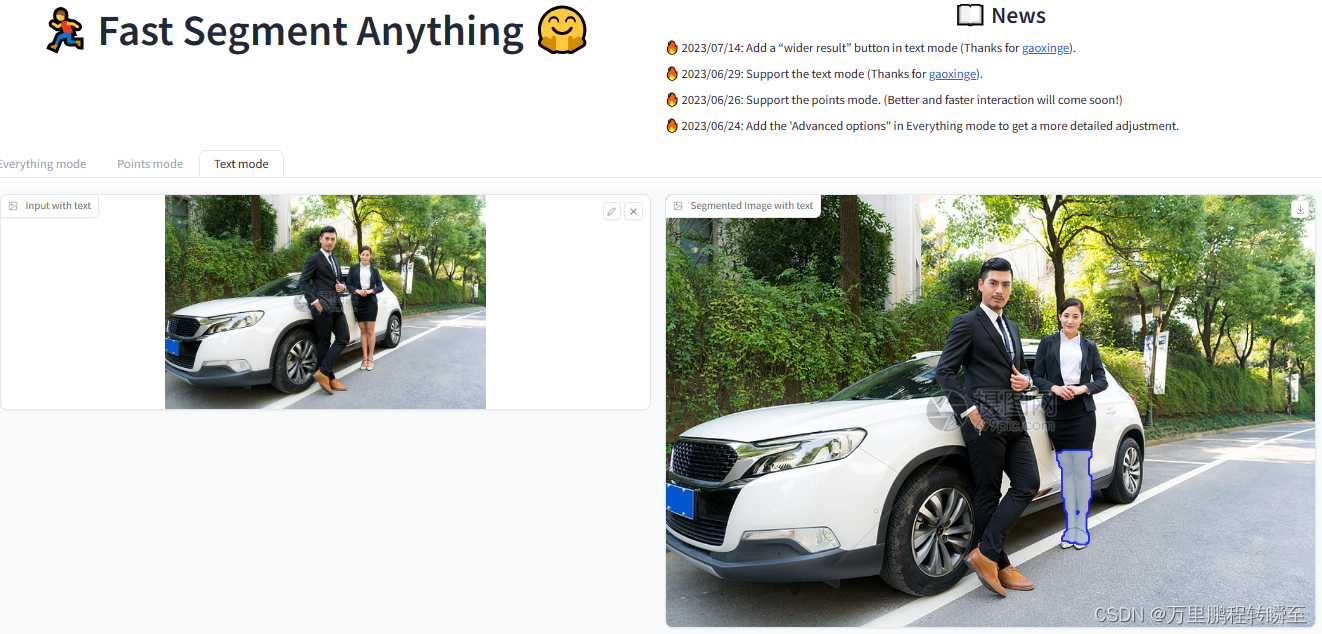
将FastSAM中的TextPrompt迁移到MobileSAM中
本博文简单介绍了SAM、FastSAM与MobileSAM,主要关注于TextPrompt功能的使用。从性能上看MobileSAM是最实用的,但其没有提供TextPrompt功能,故而参考FastSAM中的实现,在MobileSAM中嵌入TextPrompt类。并将TextPrompt能力嵌入到MobileSAM官方项目提供的gradio.py部署代码中,…...
)
KY191 矩阵幂(用Java实现)
描述 给定一个n*n的矩阵,求该矩阵的k次幂,即P^k。 输入描述: 第一行:两个整数n(2<n<10)、k(1<k<5),两个数字之间用一个空格隔开,含义如上所示…...

基于Python的股票市场分析:趋势预测与策略制定
一、引言 股票市场作为投资领域的重要组成部分,其价格波动和趋势变化一直是投资者关注的焦点。准确预测股票市场的趋势对于制定有效的投资策略至关重要。本文将使用Python编程语言,结合时间序列分析和机器学习算法,对股票市场的历史数据进行…...

OpenCore Legacy Patcher终极教程:如何让老旧Mac重获新生,运行最新macOS
OpenCore Legacy Patcher终极教程:如何让老旧Mac重获新生,运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为老旧Ma…...

GASShooter伤害计算与GameplayEffectContext:自定义伤害类型与爆头机制终极指南 [特殊字符]
GASShooter伤害计算与GameplayEffectContext:自定义伤害类型与爆头机制终极指南 🎯 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/G…...

RHEL8 SSH蜜罐实战:生产级威胁感知与行为仿真
1. 为什么在RHEL8上部署SSH蜜罐不是“搞个假登录框”那么简单 很多人第一次听说“SSH蜜罐”,脑子里浮现的是一台开着22端口、用户名密码全设成admin/admin的虚拟机,等着黑客连上来截图发朋友圈。我在金融行业做红蓝对抗支撑的那几年,亲眼见过…...

Docbox与Slate对比分析:哪个API文档生成器更适合你?
Docbox与Slate对比分析:哪个API文档生成器更适合你? 【免费下载链接】docbox REST API documentation generator 项目地址: https://gitcode.com/gh_mirrors/do/docbox 在选择REST API文档生成工具时,开发者常常面临选择困难。今天我们…...

特征函数损失:频域视角解决机器学习分布偏移问题
1. 项目概述在机器学习项目的实际落地过程中,我们常常会遇到一个令人头疼的“幽灵”:模型在精心准备的训练集上表现优异,但一到真实的生产环境,性能就出现断崖式下跌。这个幽灵就是“分布偏移”。无论是计算机视觉、自然语言处理还…...

LLM推理解耦技术:提升大型语言模型推理效率的关键方法
1. LLM推理解耦技术概述在大型语言模型(LLM)推理服务领域,推理解耦(Inference Disaggregation)正成为突破传统性能瓶颈的关键技术路径。这项技术的核心思想是将原本耦合的推理流程拆分为具有不同计算特征的独立阶段&am…...

2026年照片去水印免费软件保姆级教程!学会这几招,告别水印烦恼
你是不是也遇到过这样的抓狂时刻?在平台上刷到一张特别适合做壁纸或配图的高清照片,兴冲冲地保存下来,结果角落里的水印瞬间让整张图的格调打了对折;又或者,自己辛辛苦苦做好的图片,在分享转发几道后&#…...
,附可直接复用的Prompt模板)
【AI翻译避坑指南】:92%用户忽略的5个ChatGPT翻译陷阱(含术语一致性崩塌、文化错译、被动语态误判),附可直接复用的Prompt模板
更多请点击: https://intelliparadigm.com 第一章:ChatGPT翻译质量怎么样 ChatGPT 在多语种翻译任务中展现出较强的上下文理解与语义连贯能力,尤其在非技术类通用文本(如日常对话、新闻摘要、文学性段落)中常能生成自…...

论文初稿被批太水?青年教师力荐这几个AI论文写作软件
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

3个场景告诉你:为什么你需要PowerToys Text Extractor
3个场景告诉你:为什么你需要PowerToys Text Extractor 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/PowerToys…...