Kubernetes Pod 水平自动伸缩(HPA)
Pod 自动扩缩容
之前提到过通过手工执行kubectl scale命令和在Dashboard上操作可以实现Pod的扩缩容,但是这样毕竟需要每次去手工操作一次,而且指不定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个很麻烦的事情。如果Kubernetes系统能够根据Pod当前的负载的变化情况来自动的进行扩缩容就好了,因为这个过程本来就是不固定的,频繁发生的,所以纯手工的方式不是很现实。
幸运的是Kubernetes为我们提供了这样一个资源对象:Horizontal Pod Autoscaling(Pod水平自动伸缩),简称HPA。HAP通过监控分析RC或者Deployment控制的所有Pod的负载变化情况来确定是否需要调整Pod的副本数量,这是HPA最基本的原理。
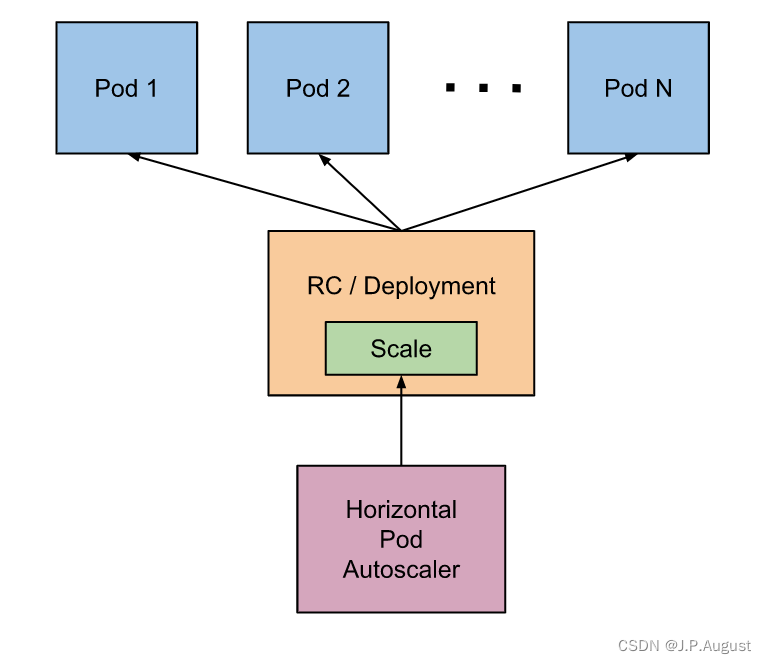
HPA在kubernetes集群中被设计成一个controller,我们可以简单的通过kubectl autoscale命令来创建一个HPA资源对象,HPA Controller默认30s轮询一次(可通过kube-controller-manager的标志--horizontal-pod-autoscaler-sync-period进行设置),查询指定的资源(RC或者Deployment)中Pod的资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
当你创建了HPA后,HPA会从Heapster或者用户自定义的RESTClient端获取每一个一个Pod利用率或原始值的平均值,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值并进行相应的操作。目前,HPA可以从两个地方获取数据:
- Heapster:仅支持
CPU使用率 - 自定义监控:我们到后面的监控的文章中再给大家讲解这部分的使用方法
现在来介绍从Heapster获取监控数据来进行自动扩缩容的方法,所以首先我们得安装Heapster,前面我们在kubeadm搭建集群的文章中,实际上我们已经默认把Heapster相关的镜像都已经拉取到节点上了,所以接下来我们只需要部署即可,我们这里使用的是Heapster 1.4.2 版本的,前往Heapster的github页面:
https://github.com/kubernetes/heapster
我们将该目录下面的yaml文件保存到我们的集群上,然后使用kubectl命令行工具创建即可,另外创建完成后,如果需要在Dashboard当中看到监控图表,我们还需要在Dashboard中配置上我们的heapster-host。
同样的,我们来创建一个Deployment管理的Nginx Pod,然后利用HPA来进行自动扩缩容。定义Deployment的YAML文件如下:(hap-deploy-demo.yaml)
---
apiVersion: apps/v1
kind: Deployment
metadata:name: hpa-nginx-deploylabels:app: nginx-demo
spec:revisionHistoryLimit: 15selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80
然后创建Deployment:
$ kubectl create -f hpa-deploy-demo.yaml
现在我们来创建一个HPA,可以使用kubectl autoscale命令来创建:
$ kubectl autoscale deployment hpa-nginx-deploy --cpu-percent=10 --min=1 --max=10
deployment "hpa-nginx-deploy" autoscaled
···
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 13s
此命令创建了一个关联资源 hpa-nginx-deploy 的HPA,最小的 pod 副本数为1,最大为10。HPA会根据设定的 cpu使用率(10%)动态的增加或者减少pod数量。
当然出来使用kubectl autoscale命令来创建外,我们依然可以通过创建YAML文件的形式来创建HPA资源对象。如果我们不知道怎么编写的话,可以查看上面命令行创建的HPA的YAML文件:
$ kubectl get hpa hpa-nginx-deploy -o yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:creationTimestamp: 2017-06-29T08:04:08Zname: nginxtestnamespace: defaultresourceVersion: "951016361"selfLink: /apis/autoscaling/v1/namespaces/default/horizontalpodautoscalers/nginxtestuid: 86febb63-5ca1-11e7-aaef-5254004e79a3
spec:maxReplicas: 5 //资源最大副本数minReplicas: 1 //资源最小副本数scaleTargetRef:apiVersion: apps/v1kind: Deployment //需要伸缩的资源类型name: nginxtest //需要伸缩的资源名称targetCPUUtilizationPercentage: 50 //触发伸缩的cpu使用率
status:currentCPUUtilizationPercentage: 48 //当前资源下pod的cpu使用率currentReplicas: 1 //当前的副本数desiredReplicas: 2 //期望的副本数lastScaleTime: 2017-07-03T06:32:19Z
好,现在我们根据上面的YAML文件就可以自己来创建一个基于YAML的HPA描述文件了。
现在我们来增大负载进行测试,我们来创建一个busybox,并且循环访问上面创建的服务。
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://172.16.255.60:4000; done
下图可以看到,HPA已经开始工作。
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 29% 1 10 27m
同时我们查看相关资源hpa-nginx-deploy的副本数量,副本数量已经从原来的1变成了3。
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 3 3 3 3 4d
同时再次查看HPA,由于副本数量的增加,使用率也保持在了10%左右。
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 9% 1 10 35m
同样的这个时候我们来关掉busybox来减少负载,然后等待一段时间观察下HPA和Deployment对象
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 48m
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 1 1 1 1 4d
可以看到副本数量已经由3变为1。
不过当前的HPA只有CPU使用率这一个指标,还不是很灵活的,在后面的文章中我们来根据我们自定义的监控来自动对Pod进行扩缩容。
相关文章:
Kubernetes Pod 水平自动伸缩(HPA)
Pod 自动扩缩容 之前提到过通过手工执行kubectl scale命令和在Dashboard上操作可以实现Pod的扩缩容,但是这样毕竟需要每次去手工操作一次,而且指不定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个…...
钉钉、企业微信和飞书向“钱”看
在急剧变革的时候,不管黑猫白猫,要抓到老鼠才算好猫。如今,各互联网企业早已进入降本增效的新阶段。勒紧裤腰带过日子之下,能不能盈利、商业化空间有多大,就成为各个业务极为重要的考核指标。在各业务板块中࿰…...
网上购物网站的设计
技术:Java、JSP等摘要:本文介绍了JSP和JAVA等相关技术,针对网上购物系统的实际需求,设计开发了一个基于JSP的小型电子商务网站也就是网上购物系统,。在设计开发中,采用的是SSH框架(strutsspring…...

【Java学习笔记】8.Java 运算符
Java 运算符 计算机的最基本用途之一就是执行数学运算,作为一门计算机语言,Java也提供了一套丰富的运算符来操纵变量。我们可以把运算符分成以下几组: 算术运算符关系运算符位运算符逻辑运算符赋值运算符其他运算符 算术运算符 算术运算符…...
)
RHCSA-使用命令管理文件(3.6)
硬链接与软链接基本操作: 创建软硬连接的命令:ln 硬链接:ln 源文件(已经存在的文件) 链接文件名(新建) 软连接:ln -s 源文件(已存在的文件) 快捷方式文件名…...
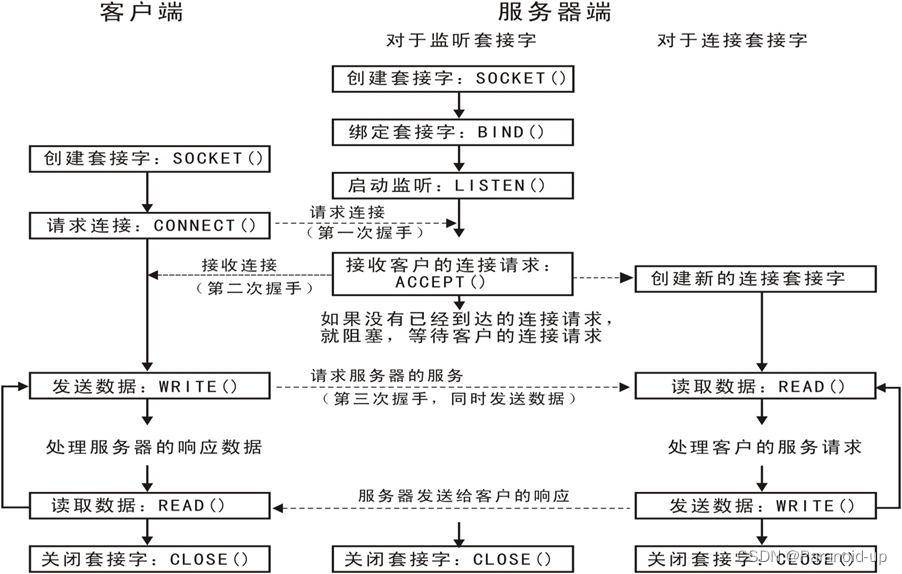
socket聊天室--socket的建立
socket聊天室–socket实现 文章目录 socket聊天室--socket实现socket()bind()listen()accept()connect()发送接收read()函数recv()函数write()函数send()函数close()关闭套接字IP 地址格式转换函数socket() #include <sys/types...
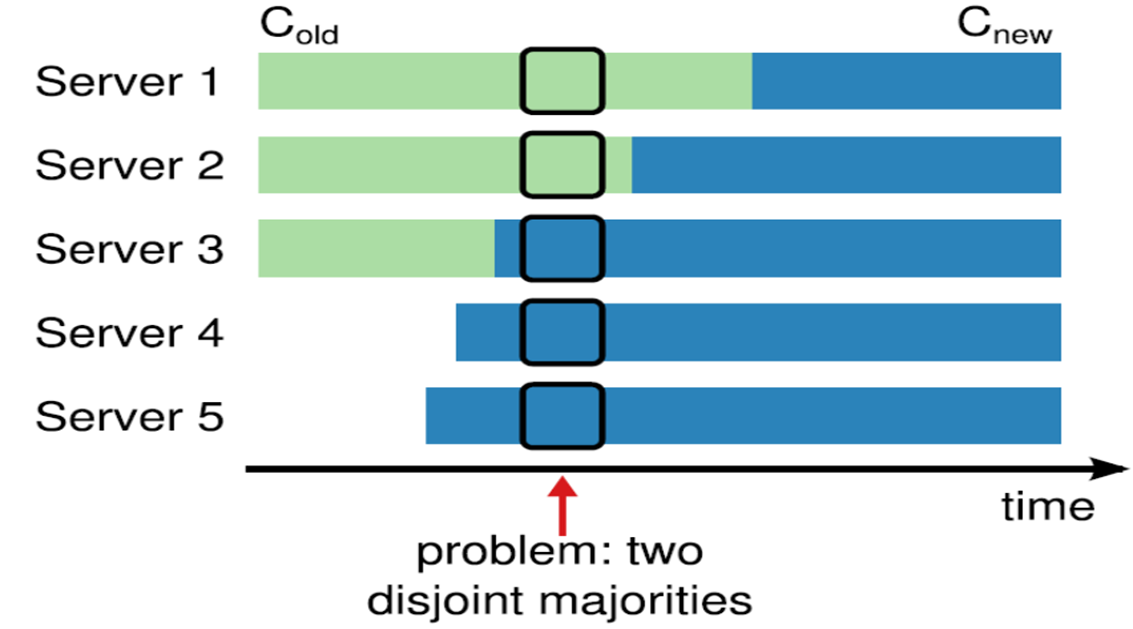
Raft图文详解
Raft图文详解 refer to: Raft lecture (Raft user study) - YouTube Raft PDF Raft算法详解 - 知乎 (zhihu.com) 今天来详细介绍一下Raft协议 Raft是来解决公式问题的协议,那么什么是共识呢? 在分布式系统里面,consensus指的是多个节点对…...

春季出游,学会这些功能,让你旅途更舒心
春意盎然,万物复苏,春天正是旅游观光的好时节,相信不少小伙伴已经做好了出游的准备。想拥有好的心情,除了美食美景,好的出游神器也必不可少,好的出游神器能让我们的旅途更舒心,一起来看看是哪些…...
)
【华为OD机试真题java、python、c++、jsNode】简单的自动曝光【2022 Q4 100分】(100%通过)
代码请进行一定修改后使用,本代码保证100%通过率。本文章提供java、python、c++、jsNode四种代码 题目描述 一个图像有n个像素点,存储在一个长度为n的数组img里,每个像素点的取值范围[0,255]的正整数。 请你给图像每个像素点值加上一个整数k(可以是负数),得到新图newImg…...

react学习笔记-1:创建项目
安装nodejs https://nodejs.org/dist/v18.14.2/node-v18.14.2-x64.msi 修改国内源:npm config set registry https://registry.npm.taobao.org 使用create-react-app脚手架创建项目 安装脚手架 npm install -g create-react-app 全局安装,可以在任意的…...
vulnhub five86-2
总结:sudo -l,抓流量包,搜索引擎。。 目录 下载地址 漏洞分析 信息收集 网站渗透 编辑 反弹shell提权 下载地址 Five86-2.zip (Size: 1.7 GB)Download (Mirror): https://download.vulnhub.com/five86/Five86-2.zip使用:下…...
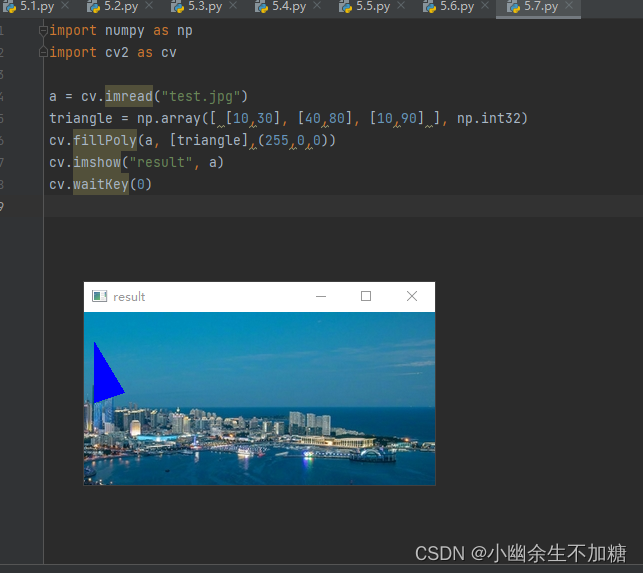
OpenCV入门(四)快速学会OpenCV3画基本图形
OpenCV入门(四)快速学会OpenCV3画基本图形 1.画点 在OpenCV中,点分为2D平面中的点和3D平面中的点,区别就是3D中点多了一个z坐标。我们首先介绍2D中的点,坐标为整数的点可以直接用(x, y)代替,其中x是横坐标…...
【MAC OS 命令行】Redis的安装、启动和停止。就是如此简单
目录Mac 安装 Redis使用 Homebrew 安装 Redis总结Mac 安装 Redis 使用 Homebrew 安装 Redis 如果没有安装 Homebrew,先安装 Homebrew 执行命令: 方法一、brew 官网的安装脚本 /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homeb…...

Leetecode 661. 图片平滑器
图像平滑器 是大小为 3 x 3 的过滤器,用于对图像的每个单元格平滑处理,平滑处理后单元格的值为该单元格的平均灰度。 每个单元格的 平均灰度 定义为:该单元格自身及其周围的 8 个单元格的平均值,结果需向下取整。(即&…...

剑指 Offer II 020. 回文子字符串的个数
题目链接 剑指 Offer II 020. 回文子字符串的个数 mid 题目描述 给定一个字符串 s,请计算这个字符串中有多少个回文子字符串。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。 示例 1: 输入…...
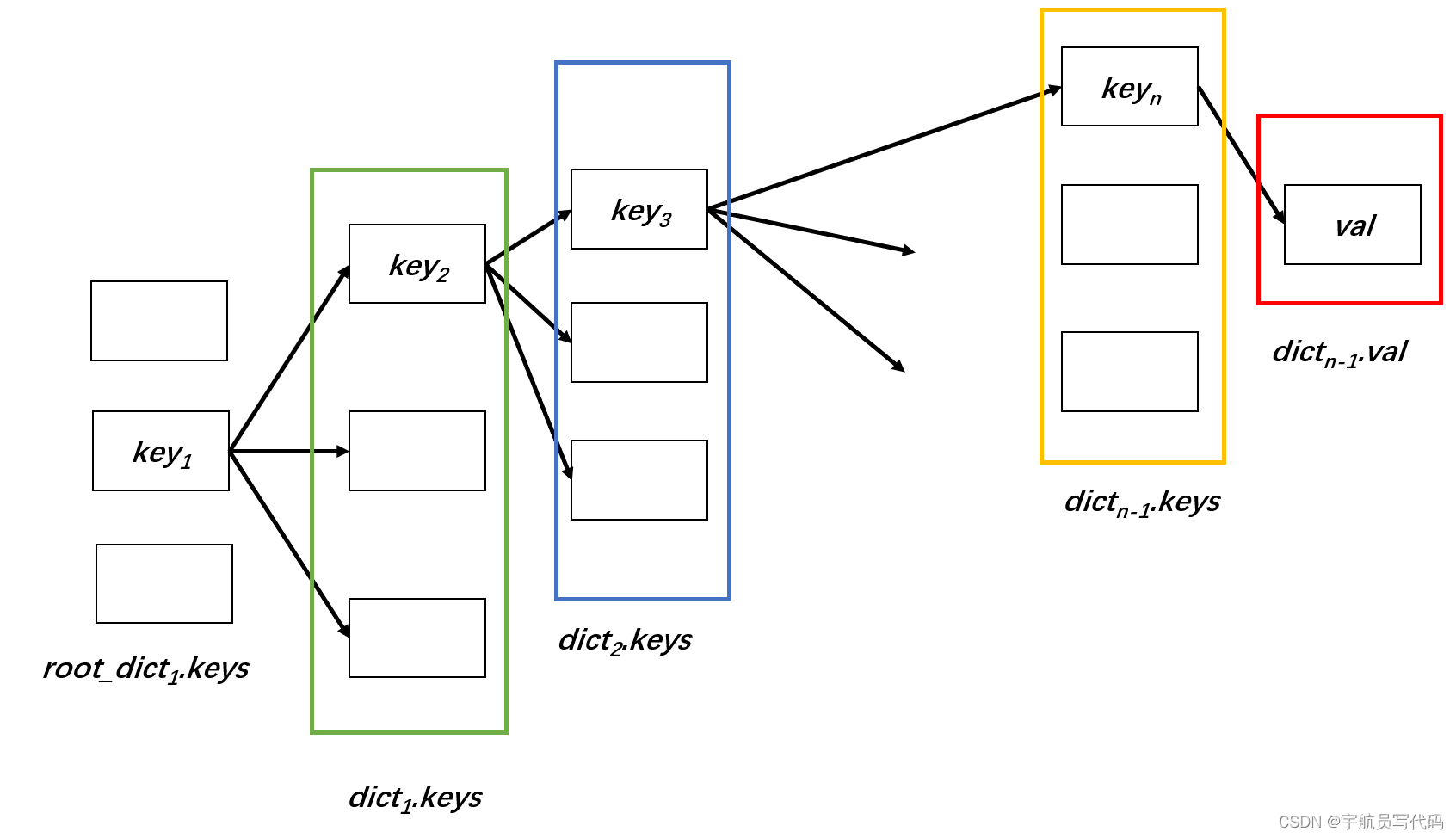
Python实现多键字典
实现背景 在许多场景中,有时需要通过多种信息来获取某个特定的值,而各种编程语言(包括Python)使用的字典(Dict)数据结构通常只支持单个键值寻值key-val对,即“一对一”(一个键对应一…...

【python socket】实现websocket服务端
一、获取握手信息首先通过如下代码,我们使用socket来获取客户端的握手信息import socketsock socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sock.bind(("127.0.0.1", 8002)) sock.li…...

PANGO的CFG那些事
先来看位于VCCIOCFG这个bank上引脚, MODE JTAG时,MODExxx. except 3’b000. 禁止设置为3’b000. Slave Parallel时,MODE 3’b110,不常用。 Slave Serial时,MODE 3’b111,不常用。 Master SPI 时&…...
路由协议(OSPF、ISIS、BGP)实验配置
目录 OSPF基础实验 建立OSPF邻居 配置虚连接 配置接口的网络类型 配置特殊区域 配置路由选路 配置路由过滤 ISIS基础实验配置 配置ISIS邻居建立 配置认证 配置路由扩散 配置路由过滤 配置定时器 BGP基础实验配置 建立BGP对等体 建立IBGP对等体 建立EBGP对等体…...

Python可变对象与不可变对象的浅拷贝与深拷贝
前言 本文主要介绍了python中容易面临的考试点和犯错点,即浅拷贝与深拷贝 首先,针对Python中的可变对象来说,例如列表,我们可以通过以下方式进行浅拷贝和深拷贝操作: import copya [1, 2, 3, 4, [a, b]]b a …...

互斥锁如何避免数据竞争
互斥锁(Mutex, Mutual Exclusion Lock)是一种用于保护共享资源,确保在任意时刻只有一个线程可以访问该资源的同步原语。其核心目的是解决多线程环境下的**数据竞争(Data Race)**问题,防止因并发…...

2026届必备的六大降重复率工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要落实信息输出的精简规范,就得设定维度清晰的降效调整规则,核心规则…...

Mermaid CLI深度解析:文本驱动图表生成在DevOps与文档自动化中的实践指南
Mermaid CLI深度解析:文本驱动图表生成在DevOps与文档自动化中的实践指南 【免费下载链接】mermaid-cli Command line tool for the Mermaid library 项目地址: https://gitcode.com/gh_mirrors/me/mermaid-cli Mermaid CLI作为Mermaid图表库的命令行接口&am…...

从动画原理到嵌入式实现:赋予机器人生命感的设计与工程实践
1. 项目概述:当技术遇见灵魂在数字世界和物理世界的交汇处,我们总在尝试创造一些能与我们对话、甚至能触动我们内心的存在。无论是屏幕里那个让你牵挂的动画角色,还是面前这个试图与你眼神交流的服务机器人,一个核心的挑战始终横亘…...

如何掌握Node.js模块系统:Node.js-Design-Patterns-Third-Edition深度解析
如何掌握Node.js模块系统:Node.js-Design-Patterns-Third-Edition深度解析 【免费下载链接】Node.js-Design-Patterns-Third-Edition Node.js Design Patterns Third Edition, published by Packt 项目地址: https://gitcode.com/gh_mirrors/no/Node.js-Design-Pa…...

基于Apify与AI模型的产品安全风险智能识别系统构建指南
1. 项目概述:一个面向产品安全与消费者风险管理的智能工具最近在梳理一些供应链和电商合规的项目时,我反复被一个核心痛点困扰:如何系统性地、自动化地识别和评估海量商品信息中潜藏的消费者风险?无论是作为平台方的风控团队&…...

域自适应学习研究新进展
篇名问题背景方法其他域自适应学习研究进展目前关于域自适应学 习产生了大量的理论研究成果, 提出了新的学习算 法, 但是这些理论研究所涉及的领域庞杂, 如统计分 类、自然语言处理、情感分析、机器翻译、气象分析 等领域, 研究内容往往涉及域自适应学习的某一方 面, 存在着概念…...

如何免费解锁英雄联盟历史回放?ROFL-Player终极解决方案
如何免费解锁英雄联盟历史回放?ROFL-Player终极解决方案 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾因为英雄联…...

开源AI对话界面chat-ui:快速部署与定制化LLM前端实践
1. 项目概述:一个开源的AI对话界面如果你最近在折腾大语言模型(LLM),不管是想部署一个私有的ChatGPT替代品,还是想给自己训练或微调的模型配一个像样的“脸面”,那你大概率绕不开一个核心问题:前…...

LZ4压缩算法演进:从r131到v1.9.5的终极速度革命 [特殊字符]
LZ4压缩算法演进:从r131到v1.9.5的终极速度革命 🚀 【免费下载链接】lz4 Extremely Fast Compression algorithm 项目地址: https://gitcode.com/GitHub_Trending/lz/lz4 LZ4作为当今最快的无损压缩算法之一,自诞生以来经历了令人瞩目…...