深入浅出Hive性能优化策略
我们将从基础的HiveQL优化讲起,涵盖数据存储格式选择、数据模型设计、查询执行计划优化等多个方面。会的直接滑到最后看代码和语法。
目录
引言
Hive架构概览
示例1:创建表并加载数据
示例2:优化查询
Hive查询优化
1. 选择适当的文件格式
2. 利用分区和分桶
3. 使用合适的JOIN策略
4. 优化HiveQL语句
Hive参数调优
1. hive.exec.parallel
2.hive.exec.parallel.thread.number
3.hive.exec.dynamic.partition
4.hive.vectorized.execution.enabled
5.mapreduce.job.reduces
6.hive.optimize.sort.dynamic.partition
实践建议
技巧总结
引言
在当今这个数据驱动的时代,数据已成为企业制胜的关键。众多企业和组织正通过海量数据的分析和处理来挖掘有价值的信息,以支持决策制定,优化业务流程,提升客户体验,甚至开发新的商业模式。在这一背景下,Apache Hive作为一个建立在Hadoop生态系统之上的数据仓库工具,因其能够提供类SQL查询功能而变得极为重要。Hive使得即使是不熟悉Java或MapReduce的数据分析师也能轻松处理大规模数据集。
Hive的设计初衷是用于数据汇总、查询和分析,但随着数据量的日益增长,性能优化成为了使用Hive时不可或缺的一部分。无论是在数据查询、数据存储格式,还是在执行策略上,Hive都提供了多种优化手段,以满足不同场景下对性能的需求。
性能优化不仅可以减少资源的浪费,提高查询的响应速度,还能在一定程度上降低计算成本,提升用户体验。优化的过程就像是在寻找最佳路径一样,需要对Hive的内部机制有深入的了解,同时也需要根据实际情况灵活应变,才能找到最适合自己业务场景的优化方案。
在探索Hive优化策略中,我们将从基础的HiveQL优化讲起,涵盖数据存储格式选择、数据模型设计、查询执行计划优化等多个方面。我们也会讨论如何通过调整Hive配置和使用资源管理器来优化资源利用率,以及如何根据实际的业务需求和数据特性来选择合适的优化手段。

Hive架构概览
Apache Hive 是一个构建在 Hadoop 生态系统之上的数据仓库软件,用于数据提取、转换和加载(ETL)任务。它提供了一种类似 SQL 的查询语言,称为 HiveQL,让那些熟悉 SQL 的用户可以轻松地进行数据查询和分析。为了更好地理解 Hive 如何进行性能优化,我们首先需要对其架构有一个基本的了解。
Hive 的架构主要包括以下几个组件:
- 用户接口:Hive 支持多种用户接口,包括命令行工具(Hive CLI)、Web界面和 JDBC/ODBC 驱动程序。
- Hive Server:它允许客户端使用 Thrift 协议远程提交请求到 Hive。
- 元数据存储:Hive 使用关系型数据库(如 MySQL、PostgreSQL)存储元数据,包括表的定义、列数据类型、分区信息等。
- 执行引擎:Hive 查询最初是通过 MapReduce 执行的,但现在它也支持 Tez 和 Spark 等其他执行引擎,以提高性能。
- HDFS:Hive 存储其数据在 Hadoop 分布式文件系统(HDFS)中,利用 HDFS 的高可靠性和高吞吐量。
示例1:创建表并加载数据
为了展示 Hive 的基本用法,我们首先通过一个简单的示例来创建一个 Hive 表,并向其中加载一些数据。
CREATE TABLE IF NOT EXISTS employees (id INT,name STRING,age INT,department STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
这段代码创建了一个名为 employees 的表,其中包含 id、name、age 和 department 四个字段。字段之间通过逗号分隔。
接下来,我们将数据加载到这个表中。
LOAD DATA LOCAL INPATH '/path/to/employees.txt' INTO TABLE employees;
此命令将本地文件系统中的 employees.txt 文件中的数据加载到 employees 表中。假设该文本文件的每一行都是一个记录,字段之间由逗号分隔。
示例2:优化查询
理解了 Hive 的基础架构后,我们可以通过一些优化技巧来提高查询的性能。假设我们想要查询 department 为 'Sales' 的所有员工,一个未优化的查询可能如下所示:
SELECT * FROM employees WHERE department = 'Sales';
为了优化这个查询,我们可以考虑使用分区。首先,重新创建 employees 表,并按 department 进行分区:
CREATE TABLE employees_partitioned (id INT,name STRING,age INT
)
PARTITIONED BY (department STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
然后,我们可以针对特定的 department 分区执行查询,这样 Hive 只需扫描相关的分区数据,而不是整个表:
SELECT * FROM employees_partitioned WHERE department = 'Sales';
通过这种方式,我们可以显著减少查询所需扫描的数据量,从而提高查询效率。
Hive查询优化
在大数据处理中,编写高效的查询是提高数据处理速度的关键之一。Hive提供了多种方式来优化查询,从而减少执行时间和资源消耗。以下是一些常用的查询优化技巧:
1. 选择适当的文件格式
Hive支持多种文件格式,包括文本文件、SequenceFile、ORC、Parquet等。选择合适的文件格式对于查询性能有显著影响。例如,ORC(Optimized Row Columnar)格式提供了高效的压缩和编码方案,能够显著减少存储空间并加速查询。
示例:
假设我们有一个大型数据集需要频繁查询,我们可以选择ORC格式来存储数据:
CREATE TABLE employees_orc (id INT,name STRING,age INT,department STRING
)
STORED AS ORC;使用ORC格式后,查询同样的数据将更快,因为ORC格式提供了更好的读取性能。
2. 利用分区和分桶
通过将数据分区和分桶,Hive能够更快地定位到查询所需的数据子集,从而减少查询所需扫描的数据量。
示例:
假设我们想要根据部门对员工数据进行分区,并在每个部门内部根据年龄进行分桶:
CREATE TABLE employees_partitioned_bucketed (id INT,name STRING,age INT
)
PARTITIONED BY (department STRING)
CLUSTERED BY (age) INTO 10 BUCKETS
STORED AS ORC;
在这个表中,数据首先按部门进行分区,然后每个部门内的数据根据员工年龄分成10个桶。这样,当执行涉及特定部门和年龄范围的查询时,Hive只需扫描相关的分区和桶,大大提升查询效率。
3. 使用合适的JOIN策略
Hive支持多种JOIN策略,包括MapJoin、SortMergeJoin等。在某些情况下,明确指定JOIN策略可以优化查询性能。
示例:
当我们知道参与JOIN的一个表非常小的时候,可以使用MapJoin来加速处理:
SET hive.auto.convert.join=true;
SET hive.auto.convert.join.noconditionaltask.size=100000;SELECT /*+ MAPJOIN(small_table) */ *
FROM big_table
JOIN small_table ON big_table.id = small_table.id;
在这个示例中,我们假设small_table的大小足够小,可以完全装载进内存,通过提示Hive使用MapJoin,可以在内存中直接进行JOIN操作,从而加快查询速度。
4. 优化HiveQL语句
编写高效的HiveQL语句也是优化查询的一个重要方面。例如,避免使用SELECT *,而是只选择需要的列,可以减少数据传输和处理的开销。
示例:
-- 不推荐的写法
SELECT * FROM employees WHERE department = 'Sales';-- 推荐的写法
SELECT id, name FROM employees WHERE department = 'Sales';
在推荐的写法中,我们只选择了id和name列,而不是选择所有列,这样可以减少数据的读取和传输量,提高查询效率。
Hive参数调优
Hive的性能不仅取决于查询的写法或数据的存储方式,还受到Hive配置参数的极大影响。正确调整这些参数可以显著提高查询速度和处理效率。下面,我们将探讨一些关键的Hive性能调优参数。
1. hive.exec.parallel
这个参数默认为false,意味着Hive在执行任务时不会并行处理。如果将其设置为true,Hive会尝试并行执行多个任务,这可以显著减少执行时间。
SET hive.exec.parallel = true;
2.hive.exec.parallel.thread.number
当启用并行执行时,此参数控制并行执行的线程数。调整此参数以适应你的集群资源和任务负载。
SET hive.exec.parallel.thread.number = 8;3.hive.exec.dynamic.partition
此参数用于控制Hive是否启用动态分区。启用动态分区(设置为true)可以在执行插入操作时自动创建分区,这对于处理大量分区非常有用。
SET hive.exec.dynamic.partition = true;
SET hive.exec.dynamic.partition.mode = nonstrict;4.hive.vectorized.execution.enabled
启用向量化查询执行可以显著提高查询性能,因为它使得Hive在处理数据批次时能够利用CPU的向量化指令。默认情况下,这个选项可能是关闭的。
SET hive.vectorized.execution.enabled = true;
SET hive.vectorized.execution.reduce.enabled = true;5.mapreduce.job.reduces
虽然这是一个MapReduce级别的参数,但它也影响Hive的性能。此参数控制Reduce任务的数量。合理设置此值可以平衡负载并减少执行时间。
SET mapreduce.job.reduces = 10;6.hive.optimize.sort.dynamic.partition
当设置为true时,此参数会对动态分区操作进行排序,以减少作为Reduce阶段一部分的I/O操作。这对于提高包含大量动态分区的查询的性能非常有用。
SET hive.optimize.sort.dynamic.partition = true;实践建议
在调整这些参数时,重要的是要记住,并没有一套适合所有情况的最佳设置。最佳的参数设置取决于具体的查询类型、数据量、集群大小和其他因素。因此,进行参数调优时应该采取迭代的方法,逐一调整参数,观察性能变化,从而找到最适合你当前工作负载的配置。
技巧总结
各种优化技巧和相应代码示例。这些优化措施包括但不限于并行处理、动态分区、向量化查询执行以及MapReduce作业的调整。
-- 启用并行执行以提高任务处理速度
SET hive.exec.parallel = true;
SET hive.exec.parallel.thread.number = 8; -- 根据你的集群资源调整线程数-- 启用动态分区以便在执行插入操作时自动创建分区
SET hive.exec.dynamic.partition = true;
SET hive.exec.dynamic.partition.mode = nonstrict;-- 启用向量化查询执行,以利用CPU的向量化指令来加速处理
SET hive.vectorized.execution.enabled = true;
SET hive.vectorized.execution.reduce.enabled = true;-- 调整Reduce任务的数量以平衡负载并减少执行时间
SET mapreduce.job.reduces = 10; -- 根据数据量和查询复杂度来调整-- 对动态分区操作进行排序,以减少Reduce阶段的I/O操作
SET hive.optimize.sort.dynamic.partition = true;-- 示例:创建分区表并使用优化的查询
CREATE TABLE employees_partitioned (id INT,name STRING,age INT
)
PARTITIONED BY (department STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;-- 加载数据进入分区表
LOAD DATA LOCAL INPATH '/path/to/employees.txt' INTO TABLE employees_partitioned PARTITION(department);-- 针对特定分区执行查询,减少扫描数据量
SELECT * FROM employees_partitioned WHERE department = 'Sales';
一些查询优化的实用示例,比如使用合适的JOIN类型、合理利用WHERE子句来过滤数据,以及使用合适的数据存储格式和分区策略来提高查询效率
-- 启用向量化查询执行
SET hive.vectorized.execution.enabled = true;
SET hive.vectorized.execution.reduce.enabled = true;-- 限制查询结果,仅用于测试和开发阶段
SELECT name, age FROM employees WHERE age > 30 LIMIT 100;-- 使用INNER JOIN代替CROSS JOIN,并在JOIN之前过滤数据
SELECT e.name, d.department_name
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE e.age > 25 AND d.location = 'New York';-- 使用MAPJOIN优化小表JOIN大表
SELECT /*+ MAPJOIN(small_table) */ big_table.*
FROM big_table
JOIN small_table ON big_table.key = small_table.key;-- 使用窗口函数进行优化的聚合查询
SELECT department, AVG(salary) OVER (PARTITION BY department) as avg_salary
FROM employees;-- 使用SORT BY进行局部排序,避免全局排序的开销
SELECT * FROM employees ORDER BY name SORT BY age;-- 使用分区键进行查询,减少扫描的数据量
SELECT * FROM employees_partitioned WHERE department = 'Sales';-- 使用DISTRIBUTE BY和SORT BY组合优化GROUP BY操作
SELECT department, COUNT(*) FROM employees
DISTRIBUTE BY department
SORT BY department
GROUP BY department;-- 使用EXPLAIN命令检查执行计划
EXPLAIN
SELECT name, age FROM employees WHERE age > 30;-- 使用COLLECT_SET来去重聚合
SELECT department, COLLECT_SET(name)
FROM employees
GROUP BY department;-- 避免使用NOT IN和NOT EXISTS,使用LEFT SEMI JOIN代替
SELECT e.name
FROM employees e
LEFT SEMI JOIN departments d ON e.department_id = d.id
WHERE d.department_name = 'Sales';-- 注意:每一种优化策略都需要根据具体的查询和数据环境进行调整和测试以验证其有效性。
具体的HiveQL代码示例
-- 1. 使用内连接代替全连接,减少数据量
SELECT a.*, b.*
FROM table_a a
JOIN table_b b ON a.key = b.key;-- 2. 在JOIN前使用WHERE子句过滤,减少JOIN操作的数据量
SELECT a.*, b.*
FROM table_a a
JOIN table_b b ON a.key = b.key
WHERE a.date = '2024-03-17';-- 3. 利用MAPJOIN优化小表与大表的JOIN操作
SELECT /*+ MAPJOIN(small_table) */ big_table.*, small_table.*
FROM big_table
JOIN small_table ON big_table.key = small_table.key;-- 4. 仅选择需要的列,避免使用SELECT *
SELECT id, name, department
FROM employees;-- 5. 使用分区查询,减少扫描的数据量
SELECT *
FROM sales_data
WHERE partition_date = '2024-03-17';-- 6. 使用SORT BY代替ORDER BY进行局部排序
SELECT name, age
FROM employees
SORT BY age;-- 7. 使用CLUSTER BY在分布式处理时同时进行数据分配和排序
SELECT name, department
FROM employees
CLUSTER BY department;-- 8. 使用LIMIT进行测试,限制结果集大小
SELECT *
FROM large_table
LIMIT 100;-- 9. 使用EXPLAIN命令分析查询执行计划
EXPLAIN
SELECT name, sum(salary)
FROM employees
GROUP BY name;-- 10. 开启向量化查询执行
SET hive.vectorized.execution.enabled = true;
SET hive.vectorized.execution.reduce.enabled = true;-- 11. 压缩MapReduce作业的中间结果
SET hive.exec.compress.intermediate = true;-- 12. 使用窗口函数优化聚合操作
SELECT name,department,AVG(salary) OVER (PARTITION BY department) as avg_dept_salary
FROM employees;-- 13. 使用COLLECT_SET聚合函数去重
SELECT department, COLLECT_SET(name)
FROM employees
GROUP BY department;-- 14. 使用DISTRIBUTE BY和SORT BY优化GROUP BY操作,减少数据倾斜
SELECT department, count(*)
FROM employees
DISTRIBUTE BY department
SORT BY department;-- 15. 使用SEMI JOIN减少数据传输
SELECT a.*
FROM table_a a
WHERE EXISTS (SELECT 1 FROM table_b b WHERE a.key = b.key);-- 16. 避免复杂正则表达式,简化查询条件
SELECT *
FROM logs
WHERE url LIKE '%openai%';-- 17. 优化CASE语句,将最可能的情况放在前面
SELECT name,CASE WHEN age < 20 THEN 'Generation Z'WHEN age BETWEEN 20 AND 39 THEN 'Millennials'ELSE 'Other'END as generation
FROM employees;-- 18. 使用动态分区插入,优化数据写入操作
SET hive.exec.dynamic.partition = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
INSERT INTO TABLE employees_partitioned PARTITION(department)
SELECT id, name, age, department
FROM employees_staging;-- 19. 使用TEZ引擎优化执行
SET hive.execution.engine=tez;-- 20. 优化GROUP BY操作,使用GROUP BY ... SKEWED BY
SET hive.groupby.skewindata=true;
SELECT department, count(*)
FROM employees
GROUP BY department;
相关文章:
深入浅出Hive性能优化策略
我们将从基础的HiveQL优化讲起,涵盖数据存储格式选择、数据模型设计、查询执行计划优化等多个方面。会的直接滑到最后看代码和语法。 目录 引言 Hive架构概览 示例1:创建表并加载数据 示例2:优化查询 Hive查询优化 1. 选择适当的文件格…...

利用卷积神经网络进行人脸识别
利用卷积神经网络(Convolutional Neural Networks, CNNs)进行人脸识别是计算机视觉领域的一个热门话题。下面是一个简化的指南,涵盖了从理论基础到实际应用的各个方面,可以作为你博文的基础内容。 理论基础 卷积神经网络简介&am…...

固态硬盘有坏道怎么恢复数据 固态硬盘坏道怎么修复
固态硬盘是一种高速、低噪音、低功耗的存储设备,但是它也有一个致命的问题——坏道。坏道是指存储芯片中的某些存储单元出现了故障,导致数据无法正常读取或写入。如果你的固态硬盘出现了坏道,那么你的数据就有可能会丢失,带来了很大的困扰。那么,固态硬盘有坏道怎么恢复数…...
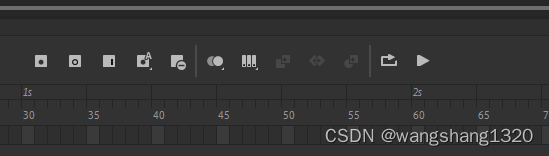
adobe animate 时间轴找不到编辑多个帧按钮
如题,找了半天,在时间轴上找不到编辑多个帧按钮,导致无法批量处理帧 然后搜索发现原来是有些版本被隐藏了,需要再设置一下 勾选上就好了...

5 亿欧元巨额奖励!法国国防部启动量子初创公司项目
内容来源:量子前哨(ID:Qforepost) 编辑丨王珩 编译/排版丨沛贤 深度好文:800字丨6分钟阅读 据C4ISNET报道,法国国防部采购机构宣布向五家法国量子计算研究初创公司授予合同,用于开发量子计算技…...
Linux:系统初始化,内核优化,性能优化(2)
优化ssh协议 Linux:ssh配置_ssh配置文件-CSDN博客https://blog.csdn.net/w14768855/article/details/131520745?ops_request_misc%257B%2522request%255Fid%2522%253A%2522171068202516800197044705%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fb…...

JS08-DOM节点
DOM节点 查找节点 父节点 通过.parentNode属性可以获得某个元素的父节点,并对其进行操作。例如,隐藏.son元素的父节点。 <div class"father"><div class"son">儿子</div></div><script>let son d…...
2024/3/14打卡棋子(14届蓝桥杯)——差分
标准差分模板 差分——前缀和的逆运算(一维二维)-CSDN博客 题目 小蓝拥有 nn 大小的棋盘,一开始棋盘上全都是白子。 小蓝进行了 m 次操作,每次操作会将棋盘上某个范围内的所有棋子的颜色取反(也就是白色棋子变为黑色࿰…...
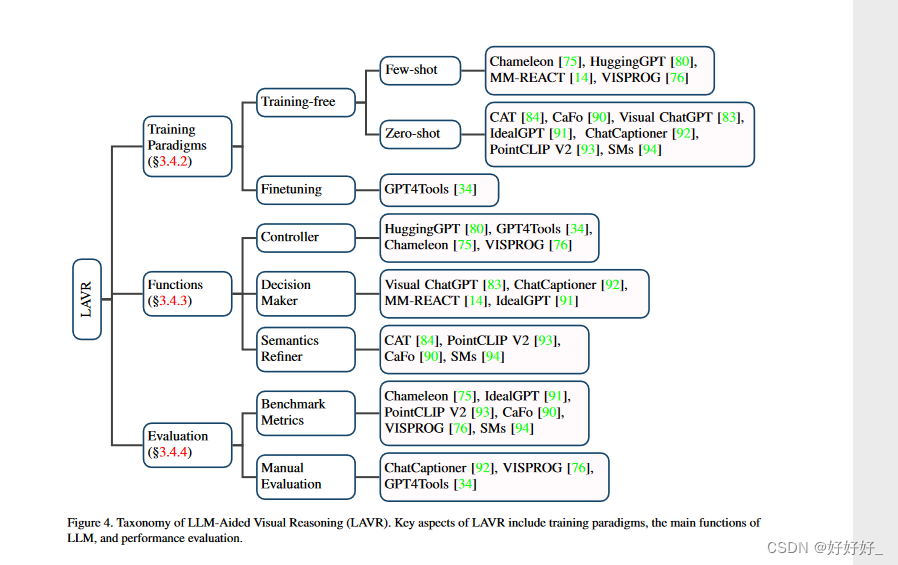
A Survey on Multimodal Large Language Models
目录 1. Introduction2. 概述方法多模态指令调优 3.1.1 简介3.1.2 预备知识3.1.3 模态对齐3.1.4 数据3.1.5 模态桥接3.1.6 评估 3.2.多模态情境学习3.3.多模态思维链3.3.1 模态桥接3.3.2 学习范式3.3.3 链配置3.3.4 生成模式3.4.LLMs辅助视觉推理3.4.1 简介3.4.2 训练范式3.4.3…...
一)
Java面向对象编程(高级)一
在Java中,面向对象编程更是核心设计理念之一,为开发者提供了丰富的工具和特性来创建灵活、可扩展的应用程序。 本博客将深入探讨Java面向对象编程的高级特性,包括但不限于多态、继承、封装、抽象类、接口等方面的内容。我们将从实际案例出发…...

1056:点和正方形的关系
【题目描述】 有一个正方形,四个角的坐标(x,y)分别是(1,-1),(1,1),(-1,-1),(-1,1),x是横轴,y是纵轴。写一个程序,判断一个给定的点是…...
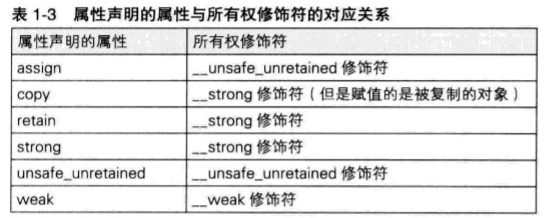
【iOS】ARC学习
文章目录 前言一、autorelease实现二、苹果的实现三、内存管理的思考方式__strong修饰符取得非自己生成并持有的对象__strong 修饰符的变量之间可以相互赋值类的成员变量也可以使用strong修饰 __weak修饰符循环引用 __unsafe_unretained修饰符什么时候使用__unsafe_unretained …...
数据分析 | Matplotlib
Matplotlib 是 Python 中常用的 2D 绘图库,它能轻松地将数据进行可视化,作出精美的图表。 绘制折线图: import matplotlib.pyplot as plt #时间 x[周一,周二,周三,周四,周五,周六,周日] #能量值 y[61,72,66,79,80,88,85] # 用来设置字体样式…...

mac npm install 很慢或报错
npm ERR! code CERT_HAS_EXPIRED npm ERR! errno CERT_HAS_EXPIRED npm ERR! request to https://registry.npm.taobao.org/pnpm failed, reason: certificate has expired 1、取消ssl验证: npm config set strict-ssl false 修改后一般就可以了,…...

100天精通Python(实用脚本篇)——第118天:基于selenium和ddddocr库实现反反爬策略之验证码识别
文章目录 专栏导读一、前言二、ddddocr库使用说明1. 介绍2. 算法步骤3. 安装4. 参数说明5. 纯数字验证码识别6. 纯英文验证码识别7. 英文数字验证码识别8. 带干扰的验证码识别 三、验证码识别登录代码实战1. 输入账号密码2. 下载验证码3. 识别验证码并登录 书籍推荐 专栏导读 …...

51单片机与ARM单片机的区别
51的MCU与ARM的MCU的区别 51单片机与ARM单片机区别主要体现在以下几个方面: 指令集架构(ISA): 51单片机:基于Intel 8051架构,采用的是CISC(复杂指令集计算机)设计,其指令…...

Android 10.0 mtk平台系统添加公共so库的配置方法
1.前言 在10.0的系统定制化开发中,由于 Android对应用应用的系统库限制越来越严格,上层应用包括(apk、jar包)不能直接引用系统的一些so库了。如果需要使用,只能使用,系统申明的公共库。 如果使用非系统申明的公共库,apk运行后调用该so库时,app会直接挂掉,或者系统开发…...
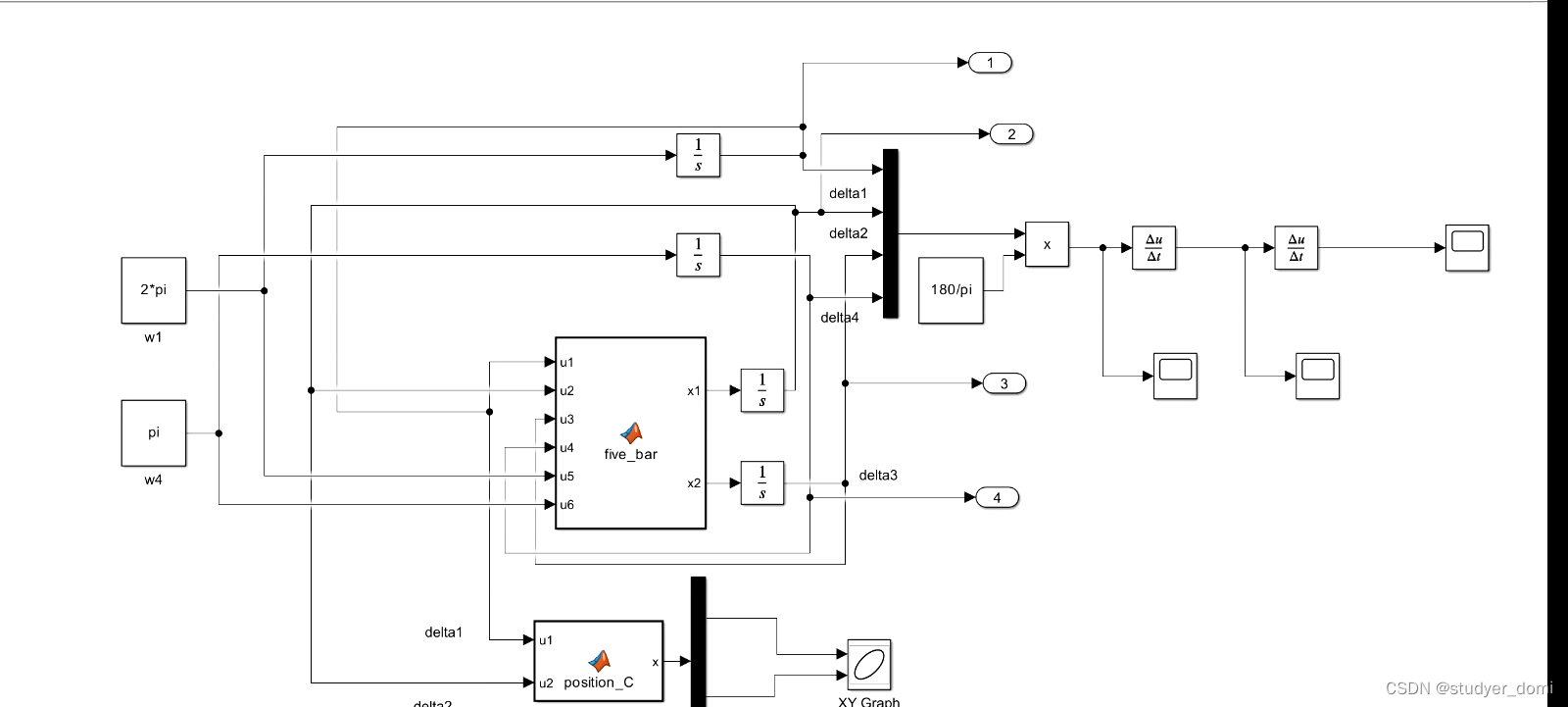
simulink平面五杆机构运动学仿真
1、内容简介 略 68-可以交流、咨询、答疑 2、内容说明 simulink平面五杆机构运动学仿真 [ 摘 要 ] 以 MATLAB 程序设计语言为平台 , 以平面可调五杆机构为主要研究对象 , 给定机构的尺寸参数 , 列出所 要分析机构的闭环矢量方程 , 使用 MATLAB 软件中 SIMULINK 仿真工…...

【Docker】APISIX Ingress Controller部署
APISIX Ingress Controller环境标准软件基于Bitnami apisix-ingress-controller:构建。当前版本为1.8.0 你可以通过轻云UC部署工具直接安装部署,也可以手动按如下文档操作,该项目已经全面开源,可以从如下环境获取 配置文件地址: https://git…...

常见的十大网络安全攻击类型
常见的十大网络安全攻击类型 网络攻击是一种针对我们日常使用的计算机或信息系统的行为,其目的是篡改、破坏我们的数据,甚至直接窃取,或者利用我们的网络进行不法行为。你可能已经注意到,随着我们生活中越来越多的业务进行数字化&…...

UnrealPakViewer:虚幻引擎Pak文件分析终极可视化工具
UnrealPakViewer:虚幻引擎Pak文件分析终极可视化工具 【免费下载链接】UnrealPakViewer 查看 UE4 Pak 文件的图形化工具,支持 UE4 pak/ucas 文件 项目地址: https://gitcode.com/gh_mirrors/un/UnrealPakViewer UnrealPakViewer是一款专业的开源工…...

【ChatGPT项目计划书生成实战指南】:20年PMO总监亲授5大高转化模板+3类避坑红线
更多请点击: https://kaifayun.com 第一章:ChatGPT项目计划书生成的核心价值与适用场景 在敏捷开发与跨职能协作日益普及的今天,项目计划书不再仅是交付物,更是对目标对齐、资源预判与风险共识的关键载体。ChatGPT驱动的项目计划…...
)
93、【Agent】【OpenCode】edit 工具提示词(二)
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除 背景 上篇 blog 【Agent】【OpenCode】edit 工…...

本地大语言模型推理新选择:为什么llama-cpp-python成为开发者首选?
本地大语言模型推理新选择:为什么llama-cpp-python成为开发者首选? 【免费下载链接】llama-cpp-python Python bindings for llama.cpp 项目地址: https://gitcode.com/gh_mirrors/ll/llama-cpp-python 在人工智能快速发展的今天,能够…...
昇腾CANN ops-transformer FlashAttention 反向传播:不存 Attention 矩阵怎么求梯度
FlashAttention 前向传播的精髓:不存 NN 的 attention 矩阵,只存 O(N) 的输出和 softmax 归一化因子。反向传播时,需要 attention 矩阵来计算梯度——但矩阵没存。解法:重新算一遍。用额外的计算换显存——这是典型的 compute-for…...

ncmdumpGUI:三步解密网易云音乐NCM文件,实现音乐自由播放
ncmdumpGUI:三步解密网易云音乐NCM文件,实现音乐自由播放 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了心爱…...

融合模糊决策与ECSA优化的软件项目智能风险评估框架
1. 项目概述与核心价值在软件工程这个行当里摸爬滚打十几年,我见过太多项目因为对风险的“视而不见”或“束手无策”而走向失败。项目延期、预算超支、质量滑坡,这些问题的根源往往不是技术本身,而是对潜在威胁的评估和应对失当。传统的风险管…...

3大止损策略拯救你的交易:backtrader实战指南
3大止损策略拯救你的交易:backtrader实战指南 【免费下载链接】backtrader Python Backtesting library for trading strategies 项目地址: https://gitcode.com/gh_mirrors/ba/backtrader 作为一名量化交易者,你是否经常面临这样的困境ÿ…...

GetQzonehistory:如何通过开源工具实现QQ空间数据主权迁移?
GetQzonehistory:如何通过开源工具实现QQ空间数据主权迁移? 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字资产管理领域,数据主权已成为个人用…...

三指拖拽终极指南:在Windows上实现macOS级触控板体验
三指拖拽终极指南:在Windows上实现macOS级触控板体验 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFingersDragOnW…...