YOLOv9改进策略:注意力机制 | 用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测,暴力涨点
💡💡💡本文改进内容:用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测
yolov9-c-ContextAggregation summary: 971 layers, 51002153 parameters, 51002121 gradients, 238.9 GFLOPs改进结构图如下:
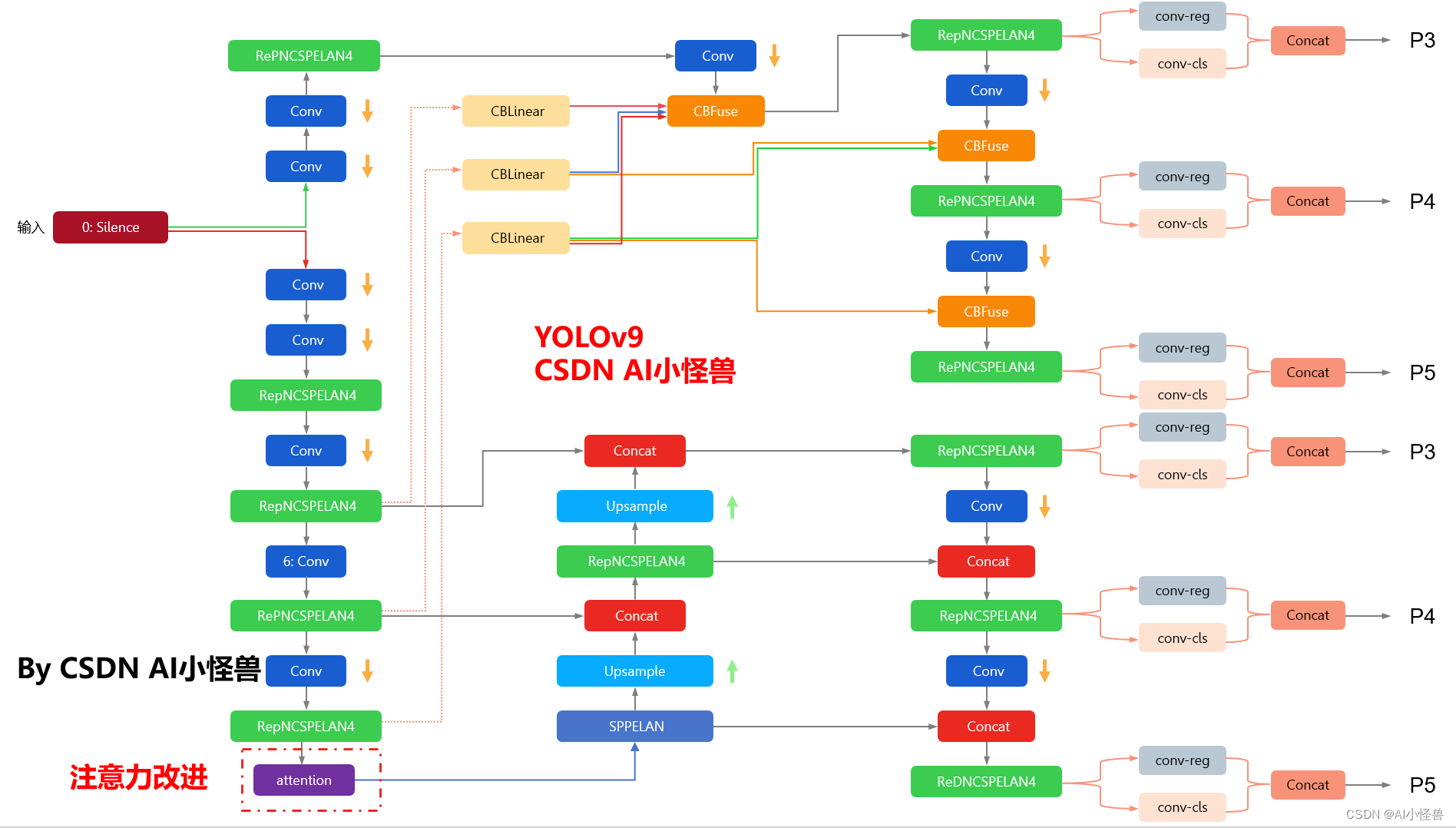
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥50+ ,冲刺100+🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9框架图
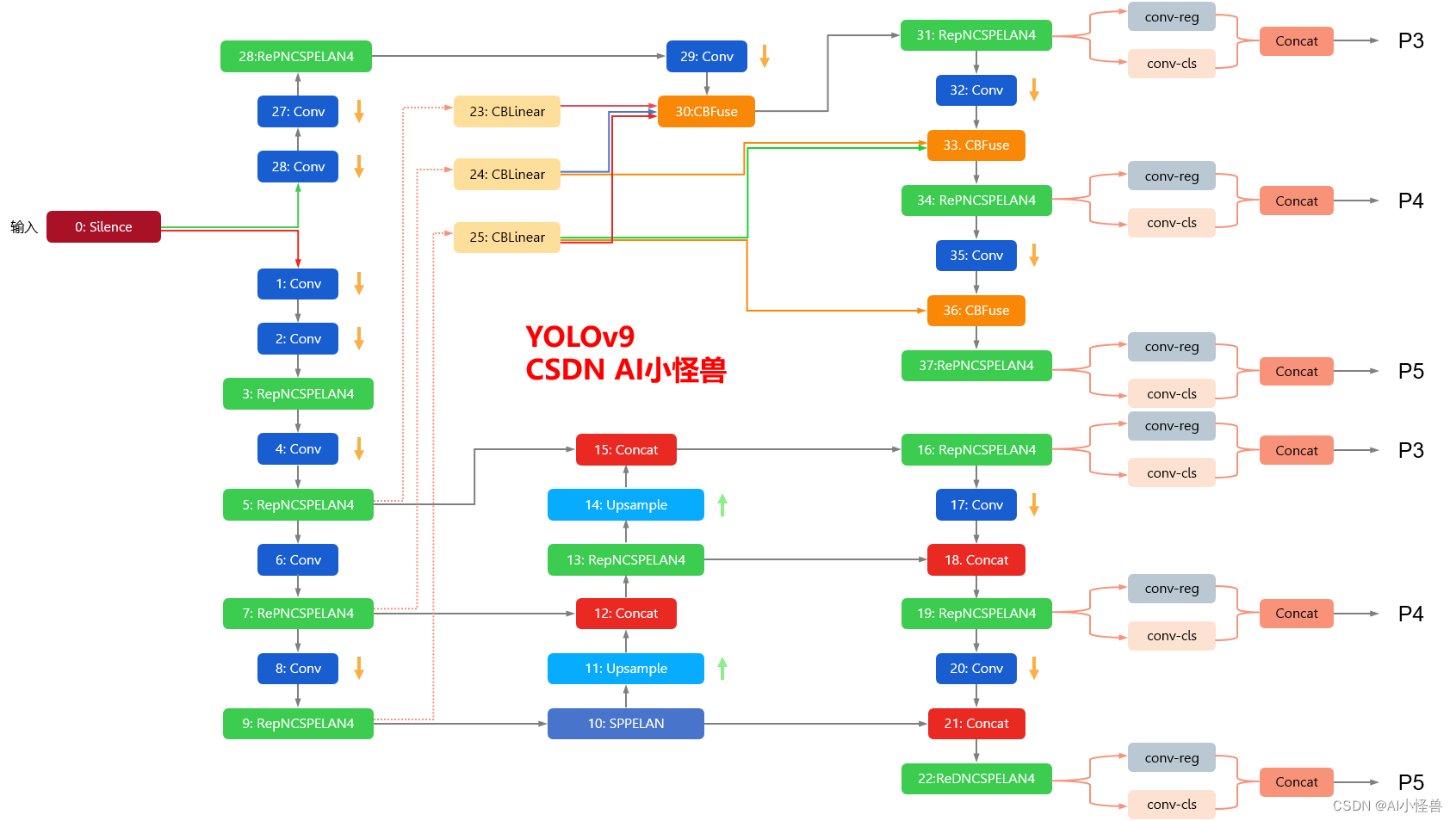
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

2.Context Aggregation介绍

论文:https://arxiv.org/abs/2106.01401
摘要
卷积神经网络(CNNs)在计算机视觉中无处不在,具有无数有效和高效的变化。最近,Container——最初是在自然语言处理中引入的——已经越来越多地应用于计算机视觉。早期的用户继续使用CNN的骨干,最新的网络是端到端无CNN的Transformer解决方案。最近一个令人惊讶的发现表明,一个简单的基于MLP的解决方案,没有任何传统的卷积或Transformer组件,可以产生有效的视觉表示。虽然CNN、Transformer和MLP-Mixers可以被视为完全不同的架构,但我们提供了一个统一的视图,表明它们实际上是在神经网络堆栈中聚合空间上下文的更通用方法的特殊情况。我们提出了Container(上下文聚合网络),一个用于多头上下文聚合的通用构建块,它可以利用Container的长期交互作用,同时仍然利用局部卷积操作的诱导偏差,导致更快的收敛速度,这经常在CNN中看到。我们的Container架构在ImageNet上使用22M参数实现了82.7%的Top-1精度,比DeiT-Small提高了2.8,并且可以在短短200个时代收敛到79.9%的Top-1精度。比起相比的基于Transformer的方法不能很好地扩展到下游任务依赖较大的输入图像的分辨率,我们高效的网络,名叫CONTAINER-LIGHT,可以使用在目标检测和分割网络如DETR实例,RetinaNet和Mask-RCNN获得令人印象深刻的检测图38.9,43.8,45.1和掩码mAP为41.3,与具有可比较的计算和参数大小的ResNet-50骨干相比,分别提供了6.6、7.3、6.9和6.6 pts的较大改进。与DINO框架下的DeiT相比,我们的方法在自监督学习方面也取得了很好的效果。
仅需22M参数量,所提CONTAINER在ImageNet数据集取得了82.7%的的top1精度,以2.8%优于DeiT-Small;此外仅需200epoch即可达到79.9%的top1精度。不用于难以扩展到下游任务的Transformer方案(因为需要更高分辨率),该方案CONTAINER-LIGHT可以嵌入到DETR、RetinaNet以及Mask-RCNN等架构中用于目标检测、实例分割任务并分别取得了6.6,7.6,6.9指标提升。
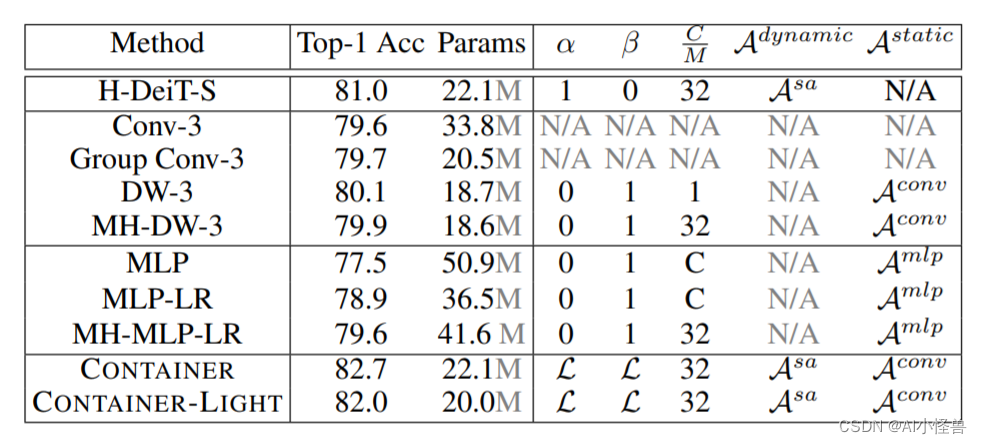
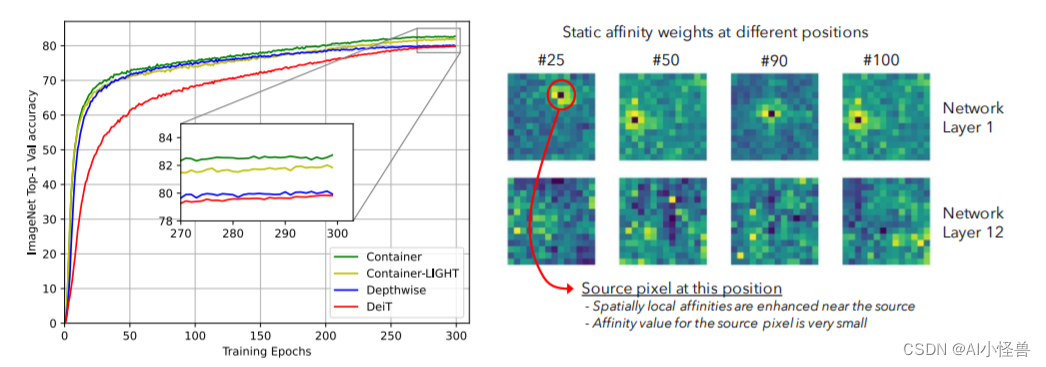
提供了一个统一视角表明:它们均是更广义方案下通过神经网络集成空间上下文信息的特例。我们提出了CONTAINER(CONText AggregatIon NEtwoRK),一种用于多头上下文集成(Context Aggregation)的广义构建模块 。
本文有以下几点贡献:
- 提出了关于主流视觉架构的一个统一视角;
- 提出了一种新颖的模块CONTAINER,它通过可学习参数和响应的架构混合使用了静态与动态关联矩阵(Affinity Matrix),在图像分类任务中表现出了很强的结果;
- 提出了一种高效&有效的扩展CONTAINER-LIGHT在检测与分割方面取得了显著的性能提升。
3.Context Aggregation加入到YOLOv9
3.1新建py文件,路径为models/attention/attention.py
###################### ContextAggregation #### START by AI&CV ###############################from mmcv.cnn import ConvModule
from mmengine.model import caffe2_xavier_init, constant_initclass ContextAggregation(nn.Module):"""Context Aggregation Block.Args:in_channels (int): Number of input channels.reduction (int, optional): Channel reduction ratio. Default: 1.conv_cfg (dict or None, optional): Config dict for the convolutionlayer. Default: None."""def __init__(self, in_channels, reduction=1):super(ContextAggregation, self).__init__()self.in_channels = in_channelsself.reduction = reductionself.inter_channels = max(in_channels // reduction, 1)conv_params = dict(kernel_size=1, act_cfg=None)self.a = ConvModule(in_channels, 1, **conv_params)self.k = ConvModule(in_channels, 1, **conv_params)self.v = ConvModule(in_channels, self.inter_channels, **conv_params)self.m = ConvModule(self.inter_channels, in_channels, **conv_params)self.init_weights()def init_weights(self):for m in (self.a, self.k, self.v):caffe2_xavier_init(m.conv)constant_init(self.m.conv, 0)def forward(self, x):# n, c = x.size(0)n = x.size(0)c = self.inter_channels# n, nH, nW, c = x.shape# a: [N, 1, H, W]a = self.a(x).sigmoid()# k: [N, 1, HW, 1]k = self.k(x).view(n, 1, -1, 1).softmax(2)# v: [N, 1, C, HW]v = self.v(x).view(n, 1, c, -1)# y: [N, C, 1, 1]y = torch.matmul(v, k).view(n, c, 1, 1)y = self.m(y) * areturn x + y###################### ContextAggregation #### END by AI&CV ###############################
3.2修改yolo.py
1)首先进行引用
from models.attention.attention import *2)修改def parse_model(d, ch): # model_dict, input_channels(3)
在源码基础上加入ContextAggregation
elif m is nn.BatchNorm2d:args = [ch[f]]###attention #####elif m in {EMA_attention, CoordAtt,CBAM,GAM_Attention,PolarizedSelfAttention,SimAM,NAMAttention,DoubleAttention,SKAttention,ContextAggregation}:c2 = ch[f]args = [c2, *args]###attention #####3.3 yolov9-c-ContextAggregation.yaml
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# avg-conv down[-1, 1, ADown, [256]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# avg-conv down[-1, 1, ADown, [512]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# avg-conv down[-1, 1, ADown, [512]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9[-1, 1, ContextAggregation, [512]], # 10]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 11# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)# avg-conv-down merge[-1, 1, ADown, [256]],[[-1, 14], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)# avg-conv-down merge[-1, 1, ADown, [512]],[[-1, 11], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)# multi-level reversible auxiliary branch# routing[5, 1, CBLinear, [[256]]], # 24[7, 1, CBLinear, [[256, 512]]], # 25[9, 1, CBLinear, [[256, 512, 512]]], # 26# conv down[0, 1, Conv, [64, 3, 2]], # 27-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 28-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29# avg-conv down fuse[-1, 1, ADown, [256]], # 30-P3/8[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32# avg-conv down fuse[-1, 1, ADown, [512]], # 33-P4/16[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35# avg-conv down fuse[-1, 1, ADown, [512]], # 36-P5/32[[26, -1], 1, CBFuse, [[2]]], # 37# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38# detection head# detect[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]相关文章:
YOLOv9改进策略:注意力机制 | 用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测,暴力涨点
💡💡💡本文改进内容:用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测 yolov9-c-ContextAggregation summary: 971 layers, 51002153 parameters, 51002121 gradients, 238.9 GFLOPs 改…...

基于单片机的老人防丢系统设计
目 录 摘 要 I Abstract II 引 言 3 1 系统总体架构 6 1.1方案设计与选择 6 1.2 系统架构设计 6 1.3 系统器件选择 7 2 系统硬件设计 9 2.1 单片机外围电路设计 9 2.2 LCD1602液晶显示电路设计 12 2.3 短信模块电路设计 14 2.4 GPS模块电路设计 14 2.5 电源与按键控制电路设计…...

从海外开发者大会的亲身体悟聊起,谈谈 AI 与开发者关系的重构 | 编码人声
本期「编码人声」节目中,我们聚焦于「AI 与开发者关系的重构」这一主题,从嘉宾参加海外开发者大会的亲身体验开始分享,聊一聊 AI 技术如何影响开发者社区和生态,以及开发者如何在这一变革中找到新的位置。 我们邀请了开发者社区与…...
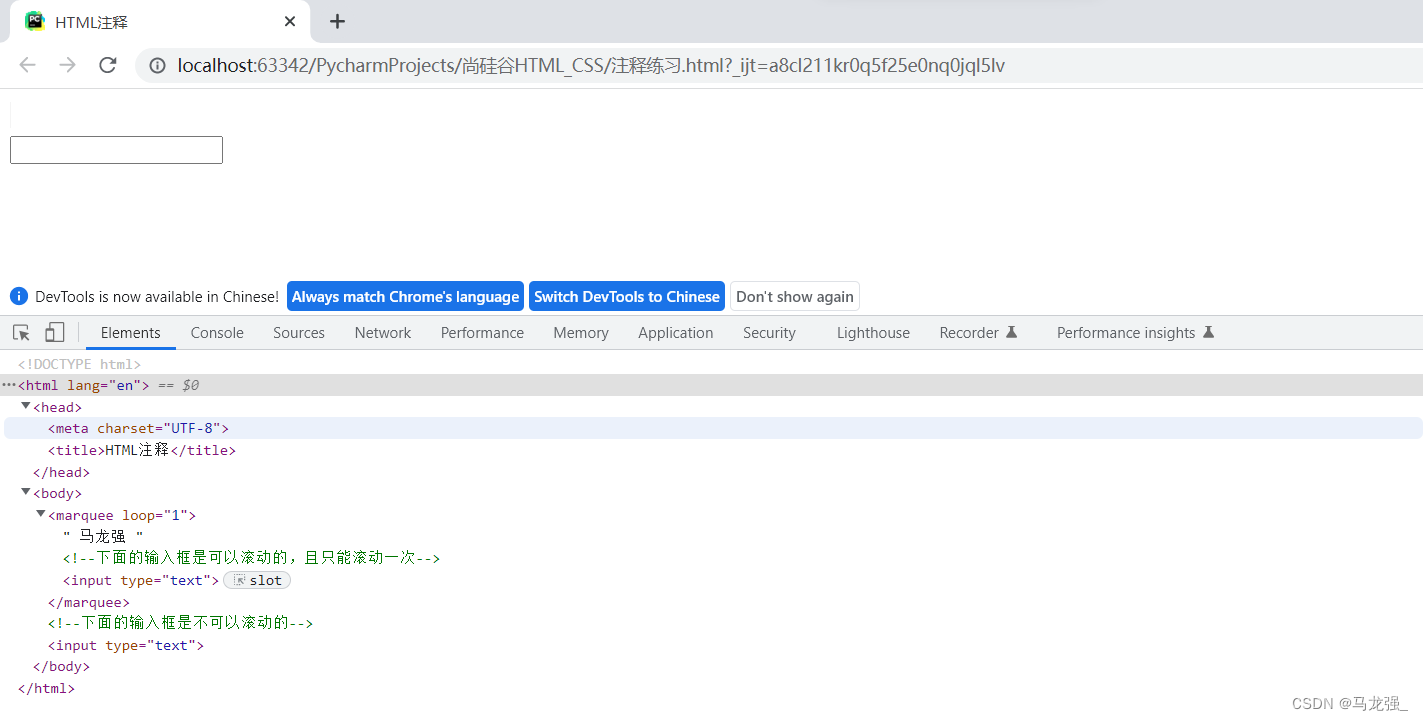
HTML_CSS练习:HTML注释
一、代码示例 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>HTML注释</title> </head> <body><marquee loop"1">马龙强<!--下面的输入框是可以滚动的&#x…...

面试官问我Java异步编程用过吗?我直接说了6种方式!
文章目录 线程池 Runnable/Callable线程池 FutureCompletableFuture线程池 Async注解Spring 事件创建事件事件发布者事件监听器调用事件 消息队列生产者消费者 在实际开发中有些耗时操作,或者对主流程不是那么重要的逻辑,可以通过异步的方式去执行&am…...
一维坐标的移动(bfs)
在一个长度为n的坐标轴上,小S想从A点移动B点。 他的移动规则如下: 向前一步,坐标增加1。 向后一步,坐标减少1。 跳跃一步,使得坐标乘2。 小S不能移动到坐标小于0或大于n的位置。 小S想知道从A点移动到B点的最少步数是多…...

面试题 整理
第1题:常见数据类型大小 这边以64位计算机系统,环境而言。 类型 存储大小 值范围 char 1 字节 -128 到 127 或 0 到 255 unsigned char 1 字节 0 到 255 signed char 1 字节 -128 到 127 int 4 字节 -32,768 到 32,767 或 -2,147,483,648…...
苍穹外卖-day08:导入地址簿功能代码(单表crud)、用户下单(业务逻辑)、订单支付(业务逻辑,cpolar软件)
苍穹外卖-day08 课程内容 导入地址簿功能代码用户下单订单支付 功能实现:用户下单、订单支付 用户下单效果图: 订单支付效果图: 1. 导入地址簿功能代码(单表crud) 1.1 需求分析和设计 1.1.1 产品原型(…...

Java面试相关问题
一.MySql篇 1优化相关问题 1.1.MySql中如何定位慢查询? 慢查询的概念:在MySQL中,慢查询是指执行时间超过一定阈值的SQL语句。这个阈值是由long_query_time参数设定的,它的默认值是10秒1。也就是说,如果一条SQL语句的执…...

Linux Shell中的循环控制语句
Linux Shell中的循环控制语句 在编写Shell脚本时,循环是一种常用的控制结构,用于重复执行一系列命令。在Shell中,主要有三种循环控制语句:for循环,while循环,和until循环。 1. For循环 for循环是最常见的…...

proto3语言指南
Language Guide (proto3) 本指南介绍了如何使用 protocol buffer 语言来构建protocol buffer数据,包括.proto文件语法以及如何从.proto 文件生成数据访问类。它涵盖了proto3 版本的协议缓冲语言:有关proto2语法的信息,请参阅proto2语言指南。 文章目录 Language Guide (pro…...

解决后端传给前端的日期问题
解决方式: 1). 方式一 在属性上加上注解,对日期进行格式化 但这种方式,需要在每个时间属性上都要加上该注解,使用较麻烦,不能全局处理。 2). 方式二(推荐 ) 在WebMvcConfiguration中扩展SpringMVC的消息转…...

MySQL中的索引失效情况介绍
MySQL中的索引是提高查询性能的重要工具。然而,在某些情况下,索引可能无法发挥作用,甚至导致查询性能下降。在本教程中,我们将探讨MySQL中常见的索引失效情况,以及它们的特点和简单的例子。 1. **索引失效的情况** …...
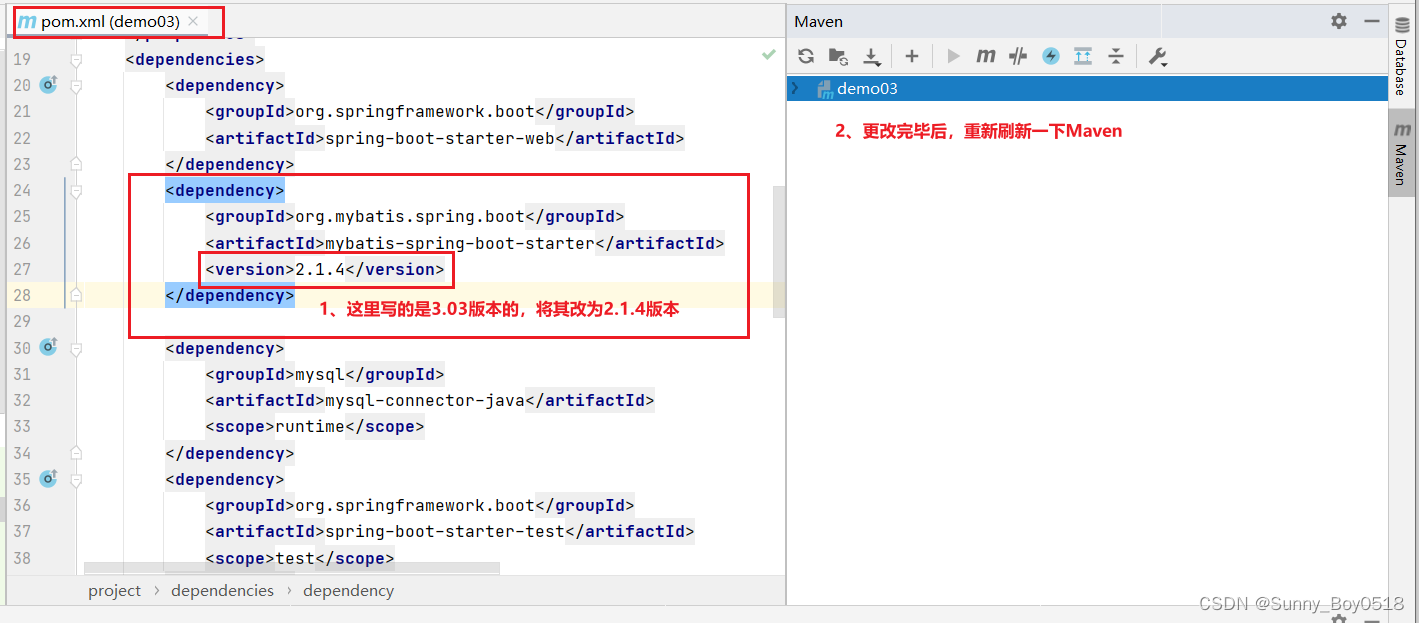
SpringBoot异常:类文件具有错误的版本 61.0, 应为 52.0的解决办法
问题: java: 无法访问org.mybatis.spring.annotation.MapperScan 错误的类文件: /D:/Program Files/apache-maven-3.6.0/repository/org/mybatis/mybatis-spring/3.0.3/mybatis-spring-3.0.3.jar!/org/mybatis/spring/annotation/MapperScan.class 类文件具有错误的…...
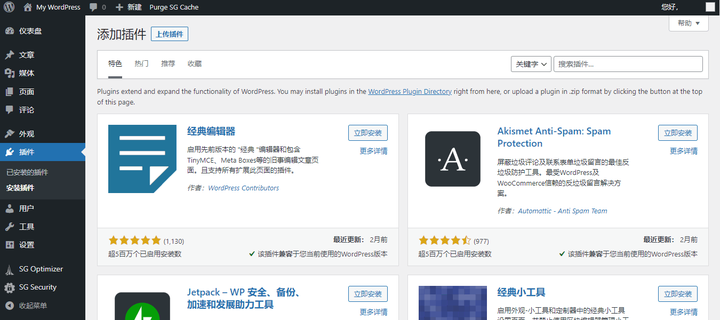
Cloudways搭建WordPress外贸独立站完整教程
现在做个网站不比从前了,搭建网站非常的简单,主要是由于开源的CMS建站系统的崛起,就算不懂编程写代码的人也能搭建一个自己的网站,这些CMS系统提供了丰富的主题模板和插件,使用户可以通过简单的拖放和配置操作来建立自…...

关于 闰年 的小知识,为什么这样判断闰年
闰年的规定: 知道了由来,我们就可以写程序来判断: #include <stdio.h> int main() {int year, leap;scanf("%d",&year);if((year%4 0 && year%100 ! 0) || year%400 0)leap 1;else leap 0;if(leap) printf(…...
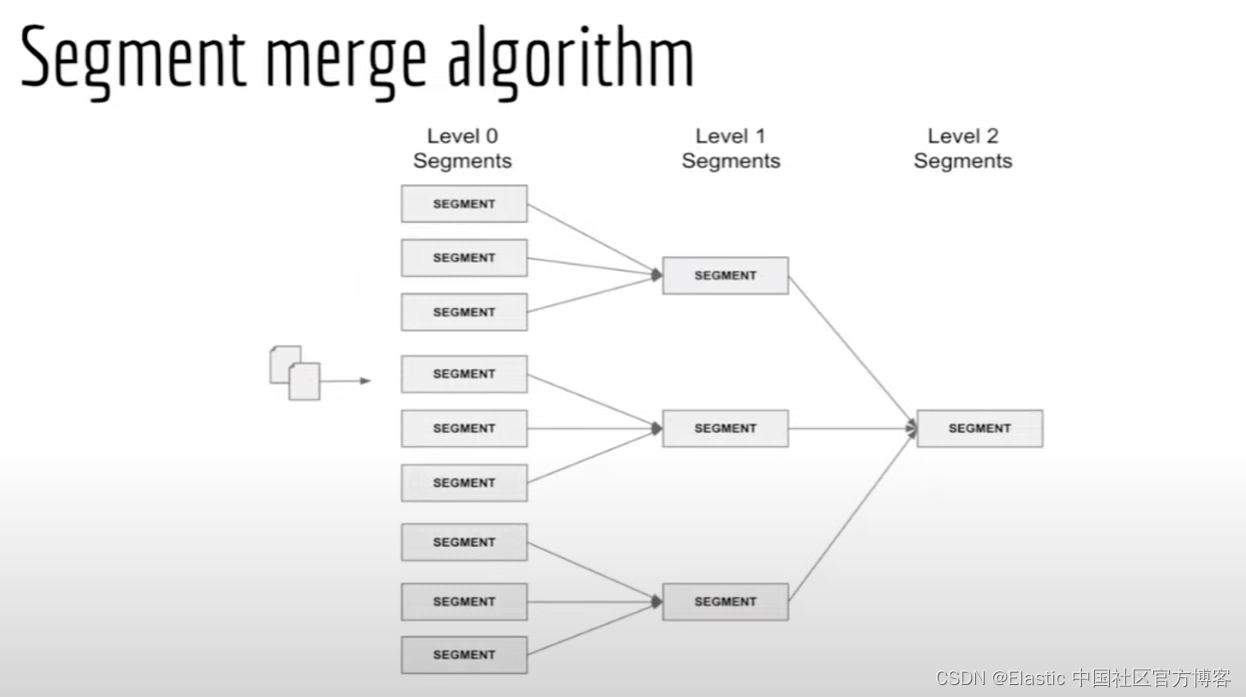
Elasticsearch:调整近似 kNN 搜索
在我之前的文章 “Elasticsearch:调整搜索速度”,我详细地描述了如何调整正常的 BM25 的搜索速度。在今天的文章里,我们来进一步探讨如何提高近似 kNN 的搜索速度。希望对广大的向量搜索开发者有一些启示。 Elasticsearch 支持近似 k 最近邻…...

UE5数字孪生系列笔记(二)
智慧城市数字孪生系统 制作流云动画效果 首先添加一个图像在需要添加流云效果的位置 添加动画效果让其旋转 这个动画效果是程序开始就要进行的,所以要在EventConstruct中就可以启动这个动画效果 添加一个一样的图像在这里,效果是从此处进行放大消散 添…...
基于vue实现bilibili网页
学校要求的实验设计,基于vue实现bilibili网页版,可实现以下功能 (1)基本的悬浮动画和页面渲染 (2)可实现登录和未登录的页面变化 (3)在登录页面的,实现密码判断,或者短信验证方式的倒数功能 (4)实现轮播图 (5)实现预览视频(GIF) (6)页面下拉到一定高度出现top栏以及右下角的返回…...
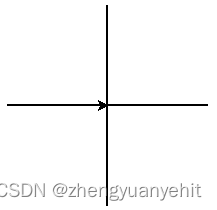
计算机二级(Python)真题讲解每日一题:《十字叉》
描述 …...

相场模拟结合贝叶斯优化:高效探索电池枝晶抑制与快充的权衡设计
1. 项目概述:当相场模拟遇见贝叶斯优化在金属电池,尤其是锂金属电池的研发前线,我们这些工程师和科学家每天都在与一个“幽灵”作斗争——枝晶。这些在充电过程中从金属负极表面肆意生长的针状或苔藓状晶体,不仅是导致电池容量衰减…...

鸿蒙electron跨端框架PC墨案写作实战:把 Markdown 正文区做成桌面写作的中心
前言 欢迎加入鸿蒙PC开发者社区,共同打造开发者工具生态:鸿蒙PC开发者社区 :https://harmonypc.csdn.net/ 项目开源地址:https://AtomGit.com/lqjmac/ele-moanxiezuo 墨案写作这个小工具看起来轻,但真正落地时要先把…...

CoQMoE:面向FPGA的MoE-ViT量化与硬件协同设计实践
1. 项目概述:当视觉Transformer遇上FPGA,为何需要“协同设计”?最近几年,视觉Transformer(ViT)在图像识别、目标检测等任务上展现出了不输甚至超越传统卷积神经网络(CNN)的性能。但随…...

RuoYi接口调试:Postman作为Spring Boot权限系统可信信使
1. 为什么RuoYi项目里Postman不是“配角”,而是调试生命线在RuoYi开发实战中,很多人把Postman当成一个“临时工具”——写完接口顺手点一下,成功了就扔一边,失败了就切回IDE疯狂加日志、重启服务、反复试错。我带过三届实习生&…...

Python数据库设计模式:从ORM到数据层架构
Python数据库设计模式:从ORM到数据层架构 引言 数据库设计是后端开发的核心环节。作为从Python转向Rust的后端开发者,我发现Python的数据库生态非常成熟,尤其是SQLAlchemy提供了强大的ORM能力。本文将深入探讨Python数据库设计模式࿰…...
专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢)
项目介绍 基于Python的大学生竞赛组队系统设计与实现(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢
基于Python的大学生竞赛组队系统设计与实现的详细项目实例 请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 大学生竞赛已成为高校人才培养…...

鸿蒙今日穿搭页面构建:单品清单、一周搭配日历与穿搭提示模块详解
鸿蒙今日穿搭页面构建:单品清单、一周搭配日历与穿搭提示模块详解 前言 在 HarmonyOS 6.0 应用开发中,穿搭类页面的单品管理、周计划安排和温馨提醒是完善用户体验的重要补充模块。本文将以“今日穿搭”应用中的“单品清单”网格模块、“一周搭配日历”周…...

JMeter HTTP接口压测实战:定位性能瓶颈的工程方法论
1. 这不是点几下就能出报告的“压测”,而是对系统真实承压能力的外科手术式探查很多人第一次打开JMeter,以为只要填个URL、设个线程数、点“启动”,跑完看个聚合报告就叫“压测完了”。我见过太多团队在上线前用JMeter跑出“99.9%成功率、平均…...

GPT-4稀疏激活机制解析:1.8万亿参数为何仅用2%
1. 项目概述:参数规模与稀疏激活的真相拆解“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区被反复引用、误读、放大,甚至成为AI算力焦虑的具象化符号。但作为从2017年就开始部署LSTM语音模型、2019年…...

RK3399嵌入式3D人脸识别系统:双目视觉与轻量化算法实战
1. 项目概述与核心价值最近在做一个挺有意思的项目,客户那边有个需求,要在他们现有的RK3399工控板上,集成一套完整的3D人脸识别系统。这活儿听起来挺酷,但真干起来,里头门道不少。RK3399这块板子大家应该不陌生&#x…...