【数据结构】哈希表与哈希桶

👀樊梓慕:个人主页
🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C++》《Linux》《算法》
🌝每一个不曾起舞的日子,都是对生命的辜负
目录
前言
1.概念
2.哈希冲突
3.解决哈希冲突
3.1闭散列
3.2开散列(哈希桶)
4.模拟实现
4.1闭散列的模拟实现
4.1.1哈希表结构设计
4.1.2插入
4.1.3删除
4.2哈希桶的模拟实现
4.2.1哈希桶结构设计
4.2.2插入
4.2.3查找
4.2.4删除
前言
本篇文章我们共同学习哈希结构,哈希结构追求更极致的搜索效率。
之前学习的结构中搜索的效率取决于搜索过程中元素的比较次数,因此顺序结构中查找的时间复杂度为O(N),平衡树中查找的时间复杂度为树的高度O(logN)。
那我们能不能构建一种数据结构,让搜索效率达到O(1)呢。
如果构造一种存储结构,该结构能够通过某种函数使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时就能通过该函数很快找到该元素进而达到O(1)的查找效率。
接下来就让我们共同学习哈希结构。
欢迎大家📂收藏📂以便未来做题时可以快速找到思路,巧妙的方法可以事半功倍。
=========================================================================
GITEE相关代码:🌟樊飞 (fanfei_c) - Gitee.com🌟
=========================================================================
1.概念
哈希结构的本质就是利用了『 映射关系』。
向该结构当中插入和搜索元素的过程如下:
- 插入元素: 根据待插入元素的关键码,用此函数计算出该元素的存储位置,并将元素存放到此位置。
- 搜索元素: 对元素的关键码进行同样的计算,把求得的函数值当作元素的存储位置,在结构中按此位置取元素进行比较,若关键码相等,则搜索成功。
该方式即为哈希(散列)方法, 哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(散列表)。
例如,集合{1, 7, 6, 4, 5, 9}
哈希函数设置为:hash( key ) = key % capacity ,其中capacity为存储元素底层空间的总大小。

用该方法进行存储,在搜索时就只需通过哈希函数判断对应位置是否存放的是待查找元素,而不必进行多次关键码的比较,因此搜索的速度比较快。
2.哈希冲突
不同关键字通过相同哈希函数计算出相同的哈希地址,这种现象称为哈希冲突或哈希碰撞。我们把关键码不同而具有相同哈希地址的数据元素称为“同义词”。
例如,在上述例子中,再将元素11插入当前的哈希表就会产生哈希冲突。 因为元素11通过该哈希函数得到的哈希地址与元素1相同,都是下标为1的位置。
hash( 11 ) = 11 % 10 = 1。
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
一、直接定址法(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
面试题:字符串中第一个只出现一次字符
二、除留余数法(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
三、平方取中法(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;
再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
四、折叠法(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况
五、随机数法(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。通常应用于关键字长度不等时采用此法
六、数学分析法(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。例如:

假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是相同的,那么我们可以选择后面的四位作为哈希地址。
如果这样的抽取方式还容易出现冲突,还可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环位移(如1234改成2341)、前两数与后两数叠加(如1234改成12+34=46)等操作。
数字分析法通常适合处理关键字位数比较大的情况,或事先知道关键字的分布且关键字的若干位分布较均匀的情况。
注意:无法避免哈希冲突,哈希函数设计的越精妙,产生哈希冲突的可能性越低。
3.解决哈希冲突
3.1闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
1. 线性探测

如图,现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
插入
- 通过哈希函数获取待插入元素在哈希表中的位置
- 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
删除
- 采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。
- 因此线性探测采用标记的伪删除法来删除一个元素。
// 哈希表每个空间给个标记 // EMPTY此位置空, EXIST此位置已经有元素, DELETE元素已经删除 enum State{EMPTY, EXIST, DELETE};
我们将数据插入到有限的空间,那么空间中的元素越多,插入元素时产生冲突的概率也就越大,冲突多次后插入哈希表的元素,在查找时的效率必然也会降低。介于此,哈希表当中引入了负载因子(载荷因子)。
负载因子 = 表中有效数据个数 / 空间的大小
虽然负载因子越小,冲突概率就会变低,查找效率会变高,但是负载因子越小,也就意味着空间的利用率越低,此时大量的空间实际上都被浪费了。对于闭散列(开放定址法)来说,负载因子是特别重要的因素,一般控制在0.7~0.8以下,超过0.8会导致在查表时CPU缓存不命中(cache missing)按照指数曲线上升。
因此,一些采用开放定址法的hash库,如JAVA的系统库限制了负载因子为0.75,当超过该值时,会对哈希表进行增容。
- 优点:实现非常简单。
- 缺点:一旦发生冲突,所有的冲突连在一起,容易产生数据『 堆积』,即不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要多次比较(踩踏效应),导致搜索效率降低。
2.二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:
Hi=(H0 + i^2) % m (i=1,2,3,...)
- H0:通过哈希函数对元素的关键码进行计算得到的位置。
- Hi:冲突元素通过二次探测后得到的存放位置。
- m:表的大小。
如图:如果要插入44,产生冲突,使用解决后的情况为:

研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
采用二次探测为产生哈希冲突的数据寻找下一个位置,相比线性探测而言,采用二次探测的哈希表中元素的分布会相对稀疏一些,不容易导致数据堆积,但也因此,闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
3.2开散列(哈希桶)
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。

这样看来,对于开散列来说,不同哈希值的元素之间不会互相干扰。
并且哈希桶的负载因子可以更大,空间利用率高。
极端情况:所有元素的哈希值均相同,最终都放到了同一个哈希桶中,此时该哈希表增删查改的效率就退化成了O(N),对于这种情况,有这样一种解决方案:『 桶中种树』。

为了避免出现这种极端情况,当桶当中的元素个数超过一定长度,有些地方就会选择将该桶中的单链表结构换成红黑树结构。
但有些地方也会选择不做此处理,因为随着哈希表中数据的增多,该哈希表的负载因子也会逐渐增大,最终会触发哈希表的增容条件,此时该哈希表当中的数据会全部重新插入到另一个空间更大的哈希表,此时同一个桶当中冲突的数据个数也会减少,因此不做处理问题也不大。
4.模拟实现
4.1闭散列的模拟实现
4.1.1哈希表结构设计
前面在讲解线性探测的部分时,提到过我们不能直接删除哈希表中的元素,而是采用伪标记的删除法,这里我们展开讲解一下:
闭散列又称开放定址法,当两个元素的哈希值冲突时我们采用线性探测的方式来解决冲突。
那么查找某个元素时,如何判断可以找到还是找不到?
根据线性探测的思想,明显是当遇到空时,就证明找不到了。
可当我们要删除某个元素时,如果直接删除,他所在的位置变成空值,那将来在查找『 因为它而产生的哈希冲突后移的元素』时,可能会受到该位置为空的影响,提前结束查找操作。
所以这里不能简单的直接删除,并且也不能用某个具体的值代表空值,这样会导致哈希表存储不了这个值,所以最有效的方式就是给每个元素设置一个状态。
- EMPTY(无数据的空位置)。
- EXIST(已存储数据)。
- DELETE(原本有数据,但现在被删除了)。
//枚举:标识每个位置的状态
enum State
{EMPTY,EXIST,DELETE
};//哈希表每个位置存储的结构
template<class K, class V>
struct HashData
{pair<K, V> _kv;State _state = EMPTY; //状态
};并且为了在插入元素时好计算当前哈希表的负载因子,我们还应该时刻存储整个哈希表中的有效元素个数,当负载因子过大时就应该进行哈希表的增容。
//哈希表
template<class K, class V>
class HashTable
{
public://...
private:vector<HashData<K, V>> _table; //哈希表size_t _n = 0; //哈希表中的有效元素个数
};4.1.2插入
向哈希表中插入数据的步骤如下:
- 查看哈希表中是否存在该键值的键值对,若已存在则插入失败。
- 判断是否需要调整哈希表的大小,若哈希表的大小为0,或负载因子过大都需要对哈希表的大小进行调整。
- 将键值对插入哈希表。
- 哈希表中的有效元素个数加一。
其中,哈希表的调整方式如下:
- 若哈希表的大小为0,则将哈希表的初始大小设置为10(在构造时完成)。
- 若哈希表的负载因子大于0.7,则先创建一个新的哈希表,该哈希表的大小为原哈希表的两倍,之后遍历原哈希表,将原哈希表中的数据插入到新哈希表,最后将原哈希表与新哈希表交换即可。
注意: 在将原哈希表的数据插入到新哈希表的过程中,需要重新计算哈希值,不能只是简单的将原哈希表中的数据对应的挪到新哈希表中,而是需要根据新哈希表的大小重新计算每个数据在新哈希表中的位置,然后再进行插入。
将键值对插入哈希表的具体步骤如下:
- 通过哈希函数计算出对应的哈希地址。
- 若产生哈希冲突,则从哈希地址处开始,采用线性探测向后寻找一个状态为EMPTY或DELETE的位置。
- 将键值对插入到该位置,并将该位置的状态设置为EXIST。
注意: 产生哈希冲突向后进行探测时,一定会找到一个合适位置进行插入,因为哈希表的负载因子是控制在0.7以下的,也就是说哈希表永远都不会被装满。
//插入函数
bool Insert(const pair<K, V>& kv)
{//1、查看哈希表中是否存在该键值的键值对HashData<K, V>* ret = Find(kv.first);if (ret) //哈希表中已经存在该键值的键值对(不允许数据冗余){return false; //插入失败}if _n * 10 / _table.size() >= 7) //负载因子大于0.7需要增容{//增容//a、创建一个新的哈希表,新哈希表的大小设置为原哈希表的2倍HashTable<K, V> newHT;newHT._table.resize(2 * _table.size());//b、将原哈希表当中的数据插入到新哈希表for (auto& e : _table){if (e._state == EXIST){newHT.Insert(e._kv);}}//c、vector的交换函数swap交换这两个哈希表_table.swap(newHT._table);}//3、将键值对插入哈希表//a、通过哈希函数计算哈希地址size_t hashi= kv.first%_table.size(); //除数不能是capacity//b、找到一个状态为EMPTY或DELETE的位置while (_table[hashi]._state == EXIST){++hashi;hashi %= _table.size(); //防止下标超出哈希表范围}//c、将数据插入该位置,并将该位置的状态设置为EXIST_table[hashi]._kv = kv;_table[hashi]._state = EXIST;//4、哈希表中的有效元素个数加一_n++;return true;
}4.1.3删除
删除哈希表中的元素非常简单,我们只需要进行伪标记的删除法即可,也就是将待删除元素所在位置的状态设置为DELETE。
在哈希表中删除数据的步骤如下:
- 查看哈希表中是否存在该键值的键值对,若不存在则删除失败。
- 若存在,则将该键值对所在位置的状态改为DELETE即可。
- 哈希表中的有效元素个数减一。
注意: 虽然删除元素时没有将该位置的数据清0,只是将该元素所在状态设为了DELETE,但是并不会造成空间的浪费,因为我们在插入数据时是可以将数据覆盖到状态为DELETE的位置的。
//删除函数
bool Erase(const K& key)
{//1、查看哈希表中是否存在该键值的键值对HashData<K, V>* ret = Find(key);if (ret){//2、若存在,则将该键值对所在位置的状态改为DELETE即可ret->_state = DELETE;//3、哈希表中的有效元素个数减一_n--;return true;}return false;
}4.2哈希桶的模拟实现
4.2.1哈希桶结构设计
在开散列的哈希表中,哈希表的每个位置存储的实际上是某个单链表的头结点,即每个哈希桶中存储的数据实际上是一个结点类型,该结点类型除了存储所给数据之外,还需要存储一个结点指针用于指向下一个结点。
//每个哈希桶中存储数据的结构
template<class K, class V>
struct HashNode
{pair<K, V> _kv;HashNode<K, V>* _next;//构造函数HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}
};注意:哈希桶的结构设计中不需要状态字,因为不同哈希值的元素不会互相影响。
哈希表的开散列实现方式,在插入数据时也需要根据负载因子判断是否需要增容,所以我们也应该时刻存储整个哈希表中的有效元素个数,当负载因子过大时就应该进行哈希表的增容。
//哈希表
template<class K, class V>
class HashTable
{
public://...
private:vector<Node*> _table; //哈希表size_t _n = 0; //哈希表中的有效元素个数
};4.2.2插入
向哈希表中插入数据的步骤如下:
- 查看哈希表中是否存在该键值的键值对,若已存在则插入失败。
- 判断是否需要调整哈希表的大小,若哈希表的大小为0,或负载因子过大都需要对哈希表的大小进行调整。
- 将键值对插入哈希表。
- 哈希表中的有效元素个数加一。
其中,哈希表的调整方式如下:
- 若哈希表的大小为0,则将哈希表的初始大小设置为10(构造时完成)。
- 若哈希表的负载因子已经等于1了,则先创建一个新的哈希表,该哈希表的大小为原哈希表的两倍,之后遍历原哈希表,将原哈希表中的数据插入到新哈希表,最后将原哈希表与新哈希表交换即可。
注意:我们只需要遍历原哈希表的每个哈希桶,通过哈希函数将每个旧哈希桶中的结点重新挂到新哈希表即可,不用进行结点的创建与释放。
//插入函数
bool Insert(const pair<K, V>& kv)
{//1、查看哈希表中是否存在该键值的键值对if (Find(kv.first)) //哈希表中已经存在该键值的键值对(不允许数据冗余){return false; //插入失败}//2、判断是否需要调整哈希表的大小if (_n == _table.size()) //负载因子超过1{//增容//a、创建一个新的哈希表,新哈希表的大小设置为原哈希表的2倍vector<Node*> newTables(_tables.size()*2, nullptr);//b、将原哈希表当中的结点插入到新哈希表for (size_t i = 0; i < _table.size(); i++){//取出旧表中的节点,重新计算挂到新表桶中Node* cur = _table[i];while (cur){Node* next = cur->_next;size_t hashi = cur->_kv.first % newTables.size(); //将该结点头插到新哈希表中编号为index的哈希桶中cur->_next = newTables[hashi ];newTables[hashi] = cur;cur = next;}_table[i] = nullptr; //该桶取完后将该桶置空}//c、交换这两个哈希表_table.swap(newTables);}//3、将键值对插入哈希表size_t hashi= kv.first % _table.size(); //通过哈希函数计算出对应的哈希桶编号index(除数不能是capacity)Node* newnode = new Node(kv); //根据所给数据创建一个待插入结点//将该结点头插到新哈希表中编号为index的哈希桶中newnode->_next = _table[hashi];_table[hashi] = newnode;//4、哈希表中的有效元素个数加一_n++;return true;
}4.2.3查找
在哈希表中查找数据的步骤如下:
- 先判断哈希表的大小是否为0,若为0则查找失败。
- 通过哈希函数计算出对应的哈希地址。
- 通过哈希地址找到对应的哈希桶中的单链表,遍历单链表进行查找即可。
//查找函数
HashNode<K, V>* Find(const K& key)
{if (_table.size() == 0) //哈希表大小为0,查找失败{return nullptr;}size_t hashi = key % _table.size();//遍历编号为index的哈希桶HashNode<K, V>* cur = _table[hashi];while (cur) //直到将该桶遍历完为止{if (cur->_kv.first == key) //key值匹配,则查找成功{return cur;}cur = cur->_next;}return nullptr; //直到该桶全部遍历完毕还没有找到目标元素,查找失败
}4.2.4删除
在哈希表中删除数据的步骤如下:
- 通过哈希函数计算出对应的哈希桶编号。
- 遍历对应的哈希桶,寻找待删除结点。
- 若找到了待删除结点,则将该结点从单链表中移除并释放。
- 删除结点后,将哈希表中的有效元素个数减一。
//删除函数
bool Erase(const K& key)
{//1、通过哈希函数计算出对应的哈希桶编号hashi(除数不能是capacity)size_t hashi = key % _table.size();//2、在编号为index的哈希桶中寻找待删除结点Node* prev = nullptr;Node* cur = _table[hashi];while (cur) //直到将该桶遍历完为止{if (cur->_kv.first == key) //key值匹配,则查找成功{//3、若找到了待删除结点,则删除该结点if (prev == nullptr) //待删除结点是哈希桶中的第一个结点{_table[hashi] = cur->_next; //将第一个结点从该哈希桶中移除}else //待删除结点不是哈希桶的第一个结点{prev->_next = cur->_next; //将该结点从哈希桶中移除}delete cur; //释放该结点//4、删除结点后,将哈希表中的有效元素个数减一_n--;return true; //删除成功}prev = cur;cur = cur->_next;}return false; //直到该桶全部遍历完毕还没有找到待删除元素,删除失败
}🐸思考🐸
除留余数法是映射哈希值的有效方法,但是这里我们考虑的都是整型情况下,那如果是字符串呢?如果key值是字符串,字符串可没办法取余数,而我们最终是一定要实现泛型编程的,我们怎样才能构建出一个通用的映射关系呢?
=========================================================================
如果你对该系列文章有兴趣的话,欢迎持续关注博主动态,博主会持续输出优质内容
🍎博主很需要大家的支持,你的支持是我创作的不竭动力🍎
🌟~ 点赞收藏+关注 ~🌟
=========================================================================
相关文章:
【数据结构】哈希表与哈希桶
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C》《Linux》《算法》 🌝每一个不曾起舞的日子,都是对生命的辜负 目录 前言 1.概念 2.哈希冲突…...

幼儿教育管理系统|基于jsp 技术+ Mysql+Java的幼儿教育管理系统设计与实现(可运行源码+数据库+设计文档)
推荐阅读100套最新项目 最新ssmjava项目文档视频演示可运行源码分享 最新jspjava项目文档视频演示可运行源码分享 最新Spring Boot项目文档视频演示可运行源码分享 2024年56套包含java,ssm,springboot的平台设计与实现项目系统开发资源(可…...

【赠书第21期】游戏力:竞技游戏设计实战教程
文章目录 前言 1 竞技游戏设计的核心要素 1.1 游戏机制 1.2 角色与技能 1.3 地图与环境 2 竞技游戏设计的策略与方法 2.1 以玩家为中心 2.2 不断迭代与优化 2.3 营造竞技氛围与社区文化 3 实战案例分析 4 结语 5 推荐图书 6 粉丝福利 前言 在数字化时代的浪潮中&…...

基于VMware虚拟机安装MacOS BigSur系统
这周用VMWare搞了个MacOS虚拟机,也算是完成初中高中时候的梦想了吧~~(那时候我的电脑配置还很拉跨,带不动虚拟机)~~ 写一篇博客记录一下,当然这也是yonagi04.github.io建站的第一篇新博客 准备工作(VMWare…...
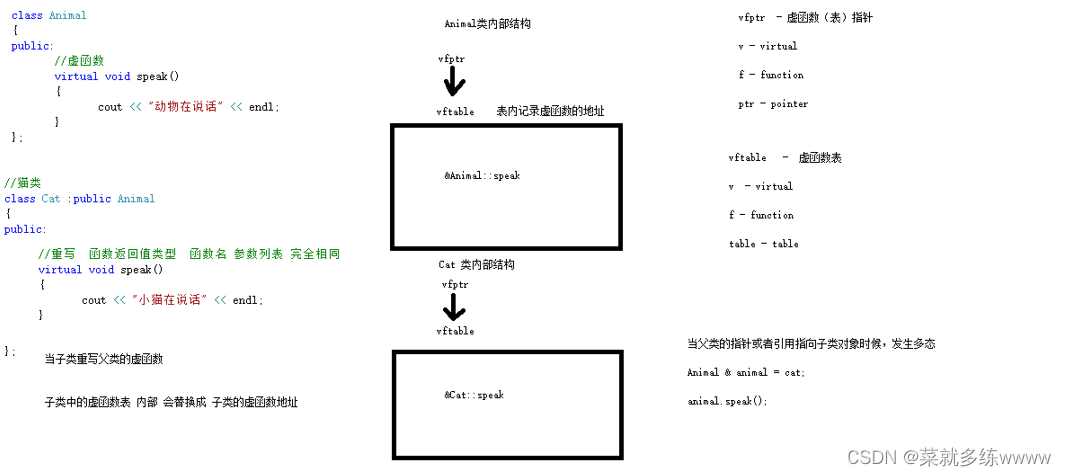
C++特性三:多态的基本语法及原理剖析
一、多态的基本语法 多态分为两类 静态多态: 函数重载 和 运算符重载属于静态多态,复用函数名 动态多态: 派生类和虚函数实现运行时多态 静态多态和动态多态区别: 静态多态的函数地址早绑定 - 编译阶段确定函数地址 动态多态的函数地址晚绑定 - 运…...

Windows下的TCP/IP实例
1.注意事项 windows下winsock.h/winsock2.h linux下sys/socket.h 不同平台头文件不一样 #include <winsock.h> 或者 #include <winsock2.h> 2. 安装minGW 目标是在 Windows 环境下提供类似于 Unix/Linux 环境下的开发工具,使开发者能够轻松地在 Wind…...
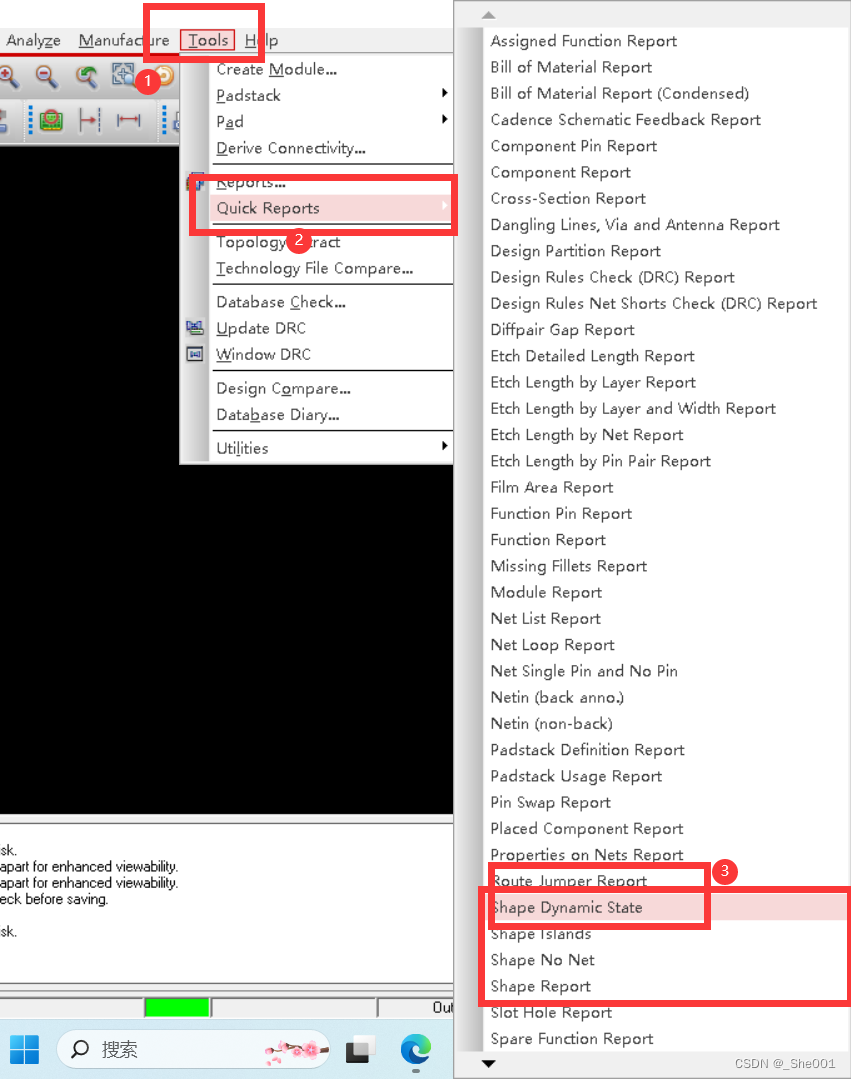
硬件学习件Cadence day15 allegro 查看state 后发现有网络未连接怎么办, shape 有问题怎么办,
1. 当我们查看 state 有问题怎么解决 1. 有问题的图片 2.解决办法: A.网络和节点有问题 如下图所示,点开下面这个窗口进行下面操作,能简单的网络未连接问题。 如下图所示,能进一步解决更难得网络节点未连接问题 如下图所示&#x…...

nginx 中 user 配置的作用
在 Nginx 配置文件中,user 指令用于指定 Nginx 运行时所使用的用户和用户组。默认情况下,Nginx 会以 nobody 用户的身份运行(即使使用 root 用户运行nginx进程, nginx运行过程中线程的用户还是用的nobody),这是一个低权限用户,专门…...
)
愚人节礼物(C++)
这不愚人节 快到了吗?身为顶级程序员,不用c编写愚人节礼物那心里是很不舒服的,所以,趁着愚人节到来之际,下面分享一种坑朋友的c代码: 内容包含一些敏感词,如果对你产生了影响或伤害,…...

Lua 学习
参照 注释 -- 这是单行注释--[[这是多行注释--]]if语句 if true thenprint(true) endif else语句 nil是false if nil thenprint("nil被当作true处理") elseprint("nil被当作false处理") end运算符 % 取余 ^ 乘幂 A10,A^2100 // 整除运算符࿰…...

YOLOv7 | 添加GSConv,VoVGSCSP等多种卷积,有效提升目标检测效果,代码改进(超详细)
⭐欢迎大家订阅我的专栏一起学习⭐ 🚀🚀🚀订阅专栏,更新及时查看不迷路🚀🚀🚀 YOLOv5涨点专栏:http://t.csdnimg.cn/QdCj6 YOLOv7专栏: http://t.csdnimg.cn/dy…...
『运维心得』BPC-EPM-AddIn专家看过来
目录 系统版本问题 安装顺序问题 framework问题 vstor_redis问题 dll问题 一个小彩蛋 总结 最近在搞BPC,安装Office所需的EPM-AddIn的过程中,碰到了一些奇怪的问题。 查了BPC专家提供的安装说明文档,文档里要么没有提到我们碰到的问题…...

论文浅尝 | GPT-RE:基于大语言模型针对关系抽取的上下文学习
笔记整理:张廉臣,东南大学硕士,研究方向为自然语言处理、信息抽取 链接:https://arxiv.org/pdf/2305.02105.pdf 1、动机 在很多自然语言处理任务中,上下文学习的性能已经媲美甚至超过了全资源微调的方法。但是…...
)
Rust语言:告诉编译器允许存在未使用的代码(Rust保留未使用的实现)
Rust告诉编译器允许存在未使用的代码(Rust保留未使用的实现) Rust的Lint工具clippy clippy是一个Rust的Lint工具,旨在帮助开发者发现并改进代码中的潜在问题。它提供了许多静态代码分析的规则和建议,以提高代码质量和可读性。其中就包括检查未使用的代…...

Winform数据绑定
简介# 在C#中提起控件绑定数据,大部分人首先想到的是WPF,其实Winform也支持控件和数据的绑定。 Winform中的数据绑定按控件类型可以分为以下几种: 简单控件绑定列表控件绑定表格控件绑定 绑定基类# 绑定数据类必须实现INotifyPropertyChanged…...
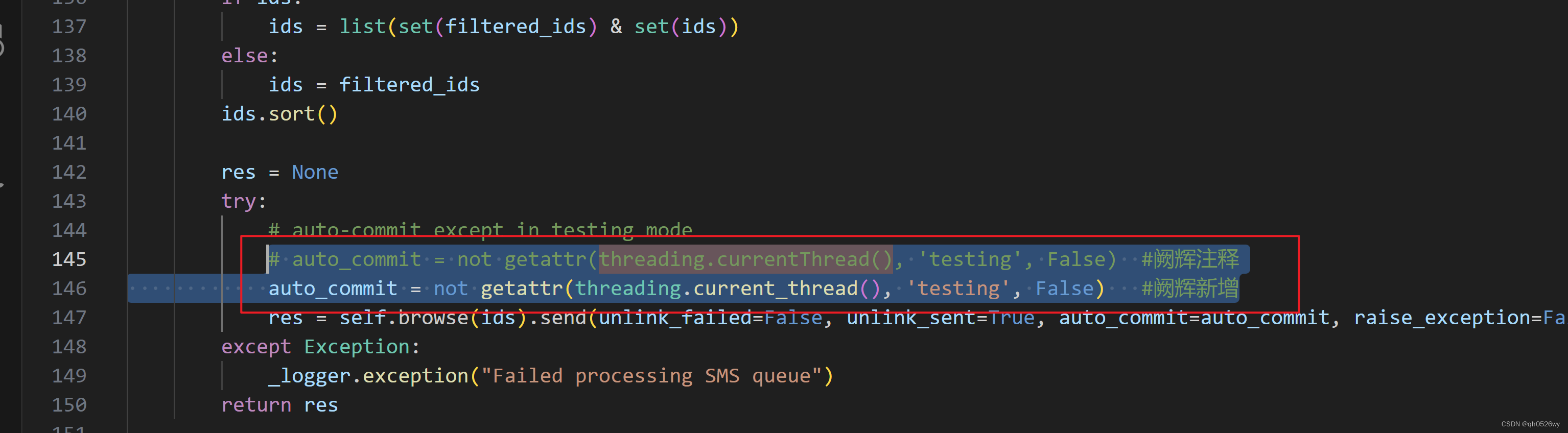
DeprecationWarning: currentThread() is deprecated, use current_thread() instead
解决方案: # auto_commit not getattr(threading.currentThread(), testing, False) #阙辉注释 auto_commit not getattr(threading.current_thread(), testing, False) #阙辉新增...

2024届 C++ 刷题 笔试强训 Day 03
选择题 01 以下程序的输出结果是() #include <stdio.h> void main() {char a[10] {1, 2, 3, 4, 5, 6, 7, 8, 9, 0}, *p;int i;i 8;p a i;printf("%s\n", p - 3); }A 6 B 6789 C ‘6’ D 789 题目解析: 题目中定义了一个…...
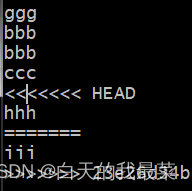
linux用git拉取我云端以及git处理冲突
拉取后切换一个跟云端分支(dev)一样的 git branch --set-upstream-toorigin/dev dev 之后就同步了 A在dev分支写了iii,提交 B在dev分支写了hhh,提交,冲突 怎么修改,B把云端的拉下来,随便改改就行...
Learn OpenGL 17 立方体贴图
立方体贴图 我们已经使用2D纹理很长时间了,但除此之外仍有更多的纹理类型等着我们探索。在本节中,我们将讨论的是将多个纹理组合起来映射到一张纹理上的一种纹理类型:立方体贴图(Cube Map)。 简单来说,立方体贴图就是一个包含了…...
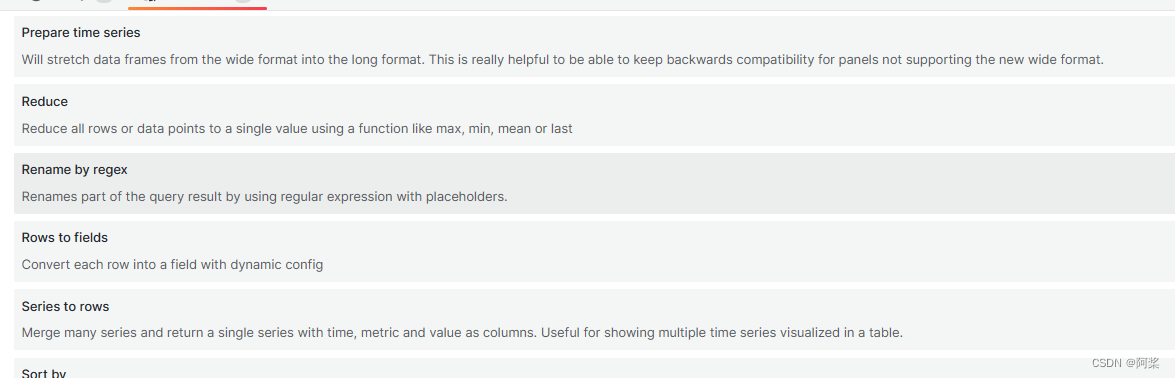
【四 (6)数据可视化之 Grafana安装、页面介绍、图表配置】
目录 文章导航一、Grafana介绍[✨ 特性]二、安装和配置1、安装2、权限配置(账户/团队/用户)①用户管理②团队管理③账户管理④看板权限 3、首选项配置4、插件管理①数据源插件②图表插件③应用插件④插件安装方式一⑤安装方式二 三、数据源管理1、添加数…...

OMNeT++ 6.0.1 踩坑记:手把手教你搞定INET 4.5.0与TSN仿真环境搭建
OMNeT 6.0.1 踩坑记:手把手教你搞定INET 4.5.0与TSN仿真环境搭建 第一次打开OMNeT 6.0.1的IDE时,那种既兴奋又忐忑的心情至今记忆犹新。作为一款开源的离散事件网络仿真工具,OMNeT在学术界和工业界都有着广泛的应用,特别是在时间…...

语音转文字神器AsrTools:零门槛批量处理音频视频文件
语音转文字神器AsrTools:零门槛批量处理音频视频文件 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn your audio into accurate t…...

宗格替尼Zongertinib说明书深度解析:HER2突变非小细胞肺癌的靶向新星与腹泻、皮疹分级管理
在非小细胞肺癌(NSCLC)的治疗领域,HER2突变型肺癌一直是一块难啃的“硬骨头”。这类患者约占所有NSCLC的2%-4%,其肿瘤往往进展迅速、侵袭性强,且对传统化疗和免疫治疗反应不佳。然而,随着靶向治疗的发展&am…...

手机里的“保险柜”RPMB:UFS存储安全区的原理与实战访问指南
手机里的“保险柜”RPMB:UFS存储安全区的原理与实战访问指南 现代智能手机中存储着大量敏感信息,从指纹模板到支付凭证,这些数据需要比普通文件更高级别的保护。这就是RPMB(Replay Protected Memory Block)存在的意义—…...

Magpie深度解析:3大技术突破重构Windows窗口放大体验
Magpie深度解析:3大技术突破重构Windows窗口放大体验 【免费下载链接】Magpie A general-purpose window upscaler for Windows 10/11. 项目地址: https://gitcode.com/gh_mirrors/mag/Magpie 在Windows系统中,窗口放大工具长期面临"清晰度与…...

用旧手机和ESP8266-01做个智能开关:手把手教你用Arduino和巴法云实现远程控制
旧手机改造智能家居中枢:零成本玩转ESP8266与Arduino联动 家里抽屉角落那台积灰的旧安卓手机,除了换脸盆还能做什么?去年搬家时,我偶然发现五年前的小米6居然还能开机,充电器插上半小时后——电量从3%顽强爬升到78%。这…...
)
避坑指南:TM1638按键读取那些事儿(附STM32 HAL库代码与常见问题排查)
TM1638按键功能深度解析:从硬件原理到高级功能实现 引言 在嵌入式开发中,TM1638芯片因其集成了数码管显示、LED控制和按键扫描功能而广受欢迎。但很多开发者在使用按键功能时,经常会遇到各种"玄学"问题——按键时灵时不灵、误触发、…...
)
达梦数据库误删表怎么办?手把手教你用dexp/dimp快速恢复(含避坑指南)
达梦数据库误删表紧急恢复指南:从原理到实战的完整解决方案 当达梦数据库中的关键业务表被误删时,那种瞬间袭来的窒息感,相信每位DBA都深有体会。去年双十一大促前夜,我们电商平台的用户订单表就曾因一个自动化脚本的bug被清空&am…...

HunterPie完整指南:怪物猎人世界终极叠加层工具配置与优化
HunterPie完整指南:怪物猎人世界终极叠加层工具配置与优化 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/HunterPi…...

搞定微信小程序云开发`cloud.callFunction`报错:从`-501000`到成功获取`openid`的保姆级避坑指南
微信小程序云开发实战:从-501000报错到稳定获取openid的完整解决方案 第一次接触微信小程序云开发时,很多人都会被cloud.callFunction报错-501000搞得焦头烂额。这个看似简单的错误代码背后,往往隐藏着从环境配置到代码调用的系统性认知偏差。…...