[C++]20:unorderedset和unorderedmap结构和封装。
unorderedset和unorderedmap结构和封装
- 一.哈希表:
- 1.直接定址法:
- 2.闭散列的开放定址法:
- 1.基本结构:
- 2.insert
- 3.find
- 4.erase
- 5.补充:
- 6.pair<k,v> k的数据类型:
- 3.开散列的拉链法/哈希桶:
- 1.基本结构:
- 2.insert
- 1.正常插入:
- 2.考虑扩容
- 3.find
- 4.erase
- 5.数据计算观察:
- 二.unordered_set和unordered_map的封装:
- 1.unordered_set
- 1.基本结构:
- 2.插入:
- 3.迭代器:
- 4.find
- 5.整体代码:
- 2.unorder_map
- 1.基本结构:
- 2.插入:
- 3.迭代器:
- 4.find
- 5.operator[]重载:
- 6.整体代码:
- 7.补充代码:
- 3.HashTable
- 1.find查找:
- 2.迭代器:
- 1.基本结构:
- 2.operator++
- 3.整体代码:
- 3.插入:
- 1.bool返回的插入:
- 2.重载operator[]实现的重载unordered_map独有:
一.哈希表:
1.直接定址法:
1.数据比较集中并且数据都比较小。
2.使用key值作为下标进行数据的存贮。
3.适用于数据比较小并且连续的情况。
字符串中第一个唯一字符
2.闭散列的开放定址法:
1.基本结构:
namespace oper_addres {enum state {Empty,Delete,Exist,};template<class k, class v>struct Hash_Node {Hash_Node(pair<k, v> x = pair<k,v>()):_date(x),_state(Empty){}pair<k, v> _date;state _state;};template<class k, class v>class Hash {public:Hash(size_t n = 10){_hash.resize(n);}private:vector<Hash_Node<k, v>> _hash;size_t _num = 0;};
}2.insert
1.不存在重复数据:除留余数法,1%10==1 下标1位置放置数值1,4%10=4 下标4位置放置数值4,以此类推。
2.存在重复数据->线性探测->7%10=7 ,下标7位置放置数值7,17%10=7 下标7位置有值就向后放置下标8就放置17,27%10=7下标7位置有值 下标8位置有值下标9放置,++然后取模找到可以放置值的位置结束。
3.如何确定这个位置的值情况?
提供枚举常量 :Empty Delete Exist
4.扩容+数值拷贝:每插入一个值都需要计算负载因子 = 当前插入的数据量/可以插入的size 当这个差值>=0.7就需要进行扩容,新建一个newhashtable大小为当前表的两倍,新的表使用insert插入原来哈希表数据最后交换两个哈希表的vector。
bool insert(pair<k, v> x){//扩容:size_t tmp = ((_num * 10) / _hash.size());if (tmp >= 7){Hash<k, v>* newhash = new Hash<k, v>(_hash.size() * 2);for (auto e : _hash){newhash->insert(e._date);}_hash.swap(newhash->_hash);}//1.正常插入:插入位置size_t indx = x.first % _hash.size();//2.进行插入:if ((_hash[indx]._state) != Empty || (_hash[indx]._state) == Delete){//向后查找->线性探测:while (_hash[indx]._state == Exist){indx++;indx %= _hash.size();}_hash[indx]._date = x;_hash[indx]._state = Exist;_num++;return true;}_hash[indx]._date = x;_hash[indx]._state = Exist;_num++;return true;}
3.find
1.find数据传参查找的数据并且返回数据的下标。
2.数据%hashtable.size(),对应下标位置就是这个值返回下标,如果不是线性探测直到空为止。数据不存在返回-1.
int find(const k& fd){size_t Hashi = fd % _hash.size();if (_hash[Hashi]._state == Exist && _hash[Hashi]._date.first == fd){return Hashi;}else{while (_hash[Hashi]._date.first != fd && _hash[Hashi]._state != Empty){Hashi++;Hashi %= _hash.size();}if (_hash[Hashi]._date.first == fd && _hash[Hashi]._state == Exist)return Hashi;elsereturn -1;}}
4.erase
1.这个地方首先使用find找到对应的下标位置进行返回。
2.找到就修改这个位置的状态为Delete,并且返回true。
bool erase(const k& fd){int hashi = find(fd);if (hashi != -1){_hash[hashi]._state = Delete;return true;}return false;}
5.补充:
size_t size(){return _num;}bool empty(){if (_num == 0)return true;return false;}
1.哈希冲突?
2.数据%hashtable.size()同一个位置的数据然后进行线性探测,线性探测的次数越多哈希冲突越多。哈希冲突越多,效率就越低。
3.当因子大于0.7就考虑进行扩容。
6.pair<k,v> k的数据类型:
1.数据类型的一个转换考虑如何变成下标可以识别的size_t类型。
2.实现仿函数,并且重载operator()
3.特殊类型可以使用类模板的特化。
template<class T>struct transition{size_t operator()(const T& x){return x;}};//1.string -> stringtemplate<>struct transition<string>{size_t operator()(const string& x){//1.可以计算string字符串的asia码的和并且每次*131降低哈希冲突:size_t sum = 0;for (auto& e : x){sum += (e*131);}return sum;}};

3.开散列的拉链法/哈希桶:
1.开散列,首先对于key值计算出下标位置,具有相同下标位置的值放在同一个子集里面,每一个子集就是一个桶,每一个桶中的元素通过一个单链表连接在一起,每一个链表的头节点由vector保存
1.基本结构:
namespace Hash_bucket{template<class T>struct transition{size_t operator()(const T& x){return x;}};//1.string -> stringtemplate<>struct transition<string>{size_t operator()(const string& x){//1.可以计算string字符串的asia码的和并且每次*131降低哈希冲突:size_t sum = 0;for (auto& e : x){sum += (e * 131);}return sum;}};template<class k, class v>struct Hash_Node {typedef Hash_Node Node;Hash_Node(pair<k, v> x = pair<k, v>()):_date(x),_next(nullptr){}pair<k, v> _date;Node* _next;};//, class trans = transition<k>template<class k, class v, class trans = transition<k>>class Hash {public:typedef Hash_Node<k, v> Node;Hash(size_t n = 10){_hash.resize(n,nullptr);_num = 0;}private:vector<Node*> _hash;size_t _num;};
}
2.insert
1.正常插入:
bool insert(const pair<k, v>& x){//1.正常插入:trans kot;size_t hashi = kot(x.first) % _hash.size();Node* newnode = new Node(x);//1-1:_hash[hashi]==nullptr 直接插入节点:if (_hash[hashi] == nullptr){_hash[hashi] = newnode;_num++;return true;}//1-2:_hash[hashi]!=nullptr 进行单链表的头插:else{newnode->_next = _hash[hashi];_hash[hashi] = newnode;_num++;return true;}return false;}

2.考虑扩容
1,什么时候需要取进行扩容?
2.当我们的vector<Node*> _hash;每一个下标处都有非空节点就进行扩容。
3.扩容需要考虑原来链表中保存的节点并且考虑进行重新的插入数据。
4.节点数据不需要先delete后new,直接进行简单连接的转移。
5.开头使用find可以帮助我们判断要插入的这个节点之前存不存在。
bool insert(const pair<k, v>& x){if (find(x.first))return false;trans kot;//1.计算平衡因子:if (_num == _hash.size()){vector<Node*> newhash(_hash.size() * 2, nullptr);for(int i=0;i<_hash.size();i++){Node* cur = _hash[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = kot(cur->_date.first) % (_hash.size()*2);cur->_next = newhash[hashi];newhash[hashi] = cur;cur = next;}_hash[i] = nullptr;}_hash.swap(newhash);}else{//1.正常插入size_t hashi = kot(x.first) % _hash.size();Node* newnode = new Node(x);//1-1:_hash[hashi]==nullptr 直接插入节点:newnode->_next = _hash[hashi];_hash[hashi] = newnode;_num++;return true;}return false;}
3.find
1.%_hash.size()快速确定下标位置。
2.通过cur遍历单链表找到值相同的节点就返回。
3.找不到就返回空节点。
Node* find(const k& fd)
{trans kot;size_t i = kot(fd) % _hash.size();Node* cur = _hash[i];while (cur){if (cur->_date.first == fd)return cur;cur = cur->_next;}return nullptr;
}
4.erase
1.%_hash.size()快速确定下标位置。
2.两个情况:
2-1:_hash[hashi]保存的就是需要删除的节点
2-1:需要删除的节点在单链表中。
bool erase(const k& fd){trans kot;size_t i = kot(fd) % _hash.size();Node* cur = _hash[i];Node* prev = nullptr;while (cur){if (cur->_date.first == fd){//头节点就是需要删除的if (prev == nullptr){_hash[i] = cur->_next;}//在单链表中的节点需要被删除:else{prev->_next = cur->_next;}return true;}prev = cur;cur = cur->_next;}return false;}
5.数据计算观察:
void Some(){size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _hash.size(); i++){Node* cur = _hash[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;//平衡因子printf("load factor:%lf\n", (double)_num / _hash.size());//表长度:printf("all bucketSize:%d\n",_hash.size());//桶的个数:printf("bucketSize:%d\n", bucketSize);//最长的桶的长度printf("maxBucketLen:%d\n", maxBucketLen);//平均桶长度printf("averageBucketLen:%lf\n\n", averageBucketLen);}二.unordered_set和unordered_map的封装:
1.unordered_set
1.基本结构:
namespace sfpy {template<class k,class transition = transition<k>>class myunset {public:struct copy_set {const k& operator()(const k& x){return x;}};private:Hash_bucket::Hash<k,k,copy_set,transition> _t;};
}
2.插入:
//1.插入:bool Insert(const k& x){pair<iterator, bool> ret = _t.Insert(x);return ret.second;}bool insert(const k& x){return _t.insert(x);}
3.迭代器:
typedef typename Hash_bucket::Hash<k, k, copy_set, transition>::_iterator iterator;iterator begin(){return _t.find_begin();}iterator end(){return nullptr;}4.find
//3.find()iterator _find(const k& x){return _t.Find(x);}
5.整体代码:
namespace sfpy {template<class k,class transition = transition<k>>class myunset {public:struct copy_set {const k& operator()(const k& x){return x;}};typedef typename Hash_bucket::Hash<k, k, copy_set, transition>::_iterator iterator;//1.插入:bool Insert(const k& x){pair<iterator, bool> ret = _t.Insert(x);return ret.second;}bool insert(const k& x){return _t.insert(x);}//2.迭代器:iterator begin(){return _t.find_begin();}iterator end(){return nullptr;}//3.find()iterator _find(const k& x){return _t.Find(x);}private:Hash_bucket::Hash<k,k,copy_set,transition> _t;};
}
2.unorder_map
1.基本结构:
namespace sfpy {template<class k , class v , class transition = transition<k>>class myunmap {public:struct copy_map{const k& operator()(const pair<k,v>& x){return x.first;}};private:Hash_bucket::Hash<k,pair<k,v>, copy_map , transition> _t;};
}
2.插入:
//1.插入:bool Insert(const pair<k, v> x){pair<iterator, bool> ret = _t.Insert(x);return ret.second;}bool insert(const pair<k, v> x){return _t.insert(x);}
3.迭代器:
typedef typename Hash_bucket::Hash<k, pair<k, v>, copy_map, transition>::_iterator iterator;//2.迭代器iterator begin(){return _t.find_begin();}iterator end(){return _t.find_end();}
4.find
iterator _find(const k& x){return _t.Find(x);}5.operator[]重载:
v& operator[](const k& key){pair<iterator, bool> ret = _t.Insert(make_pair(key,v()));return ret.first->second;}
6.整体代码:
namespace sfpy {template<class k , class v , class transition = transition<k>>class myunmap {public:struct copy_map{const k& operator()(const pair<k,v>& x){return x.first;}};typedef typename Hash_bucket::Hash<k, pair<k, v>, copy_map, transition>::_iterator iterator;//1.插入:bool Insert(const pair<k, v> x){pair<iterator, bool> ret = _t.Insert(x);return ret.second;}bool insert(const pair<k, v> x){return _t.insert(x);}//2.迭代器iterator begin(){return _t.find_begin();}iterator end(){return _t.find_end();}//3.find()iterator _find(const k& x){return _t.Find(x);}v& operator[](const k& key){pair<iterator, bool> ret = _t.Insert(make_pair(key,v()));return ret.first->second;}private:Hash_bucket::Hash<k,pair<k,v>, copy_map , transition> _t;};
}
7.补充代码:
1.我们知道在unordered_set和unordered_map中key值是不可以被修改的。
2.我们上面的代码是可以修改key值就是一个比较离谱的事情。
3.封装unordered_map和unordered_set对key的类型进行加const。
namespace sfpy {template<class k , class v , class transition = transition<k>>class myunmap {public:struct copy_map{const k& operator()(const pair<const k,v>& x){return x.first;}};typedef typename Hash_bucket::Hash<k, pair<const k, v>, copy_map, transition>::_iterator iterator;//1.插入:bool Insert(const pair<const k, v> x){pair<iterator, bool> ret = _t.Insert(x);return ret.second;}bool insert(const pair<const k, v> x){return _t.insert(x);}//2.迭代器iterator begin(){return _t.find_begin();}iterator end(){return _t.find_end();}//3.find()iterator _find(const k& x){return _t.Find(x);}v& operator[](const k& key){pair<iterator, bool> ret = _t.Insert(make_pair(key,v()));return ret.first->second;}private:Hash_bucket::Hash<k,pair<const k, v>, copy_map , transition> _t;};
}
3.HashTable
1.map和set去封装同一个哈希表。
2.模板:template<class k , class T, class copy, class trans>
3.copy类重载了operator()做键值的获取。
4.trans是一个类型转换,比如说string转化为一个size_t类型方便下标的使用。
1.find查找:
1.返回查找到的数据的节点或者空指针。
2.数据计算下表并且遍历单链表找到节点返回节点指针。
3.找不到节点就返回nullptr
Node* find(const k& fd){trans up;copy kot;size_t i = up(fd) % _hash.size();Node* cur = _hash[i];while (cur){if ((up(kot(cur->_date))) == up(fd))return cur;cur = cur->_next;}return nullptr;}2.迭代器:
1.基本结构:
1.迭代器肯定需要封装数据的节点。
2.封装数据的节点够吗?不够!
3.只封装数据的节点重载++在一个单链表的数据还可以,但是进行链表的跳转就无法实现了。
4.考虑封装一个哈希表到迭代器中。
5.迭代器和哈希表会相互封装(上面的类找不到下面的)—>模板+声明放到上面的那个类的上面。
struct unorderediterator{typedef Hash_Node<T> Node;typedef Hash<k, T, copy, trans> HT;typedef unorderediterator<k, T, copy, trans> self;HT* _Hash;Node* _node;unorderediterator(HT* hash, Node* x):_Hash(hash), _node(x){}};
2.operator++
1,情况一:当前节点的下一个不是空直接修改迭代器中节点的内容_node = cur->next
2.情况二:当前节点的下一个是空,求当前单链表所在节点的哈希下表使用节点访问数据进行计算,找到下标之后哈希表向后进行遍历。
2-1:找到一个不是空的就进行_node的修改。
2-2:找不到,表示哈希表一直向后进行遍历到结尾都是空指针。
//主要是要去找节点:self operator++(){trans kot;copy up;//1.情况一:当前节点有下一个节点:if (_node->_next != nullptr)_node = _node->_next;//2.哈希位置的跳转:else{size_t hashi = kot(up(_node->_date)) % _Hash->_hash.size();hashi++;while (hashi < _Hash->_hash.size()){if (_Hash->_hash[hashi]){_node = _Hash->_hash[hashi];break;}hashi++;}if (hashi == _Hash->_hash.size())_node = nullptr;}return *this;}
3.整体代码:
//迭代器:template<class k, class T, class copy, class trans>struct unorderediterator{typedef Hash_Node<T> Node;typedef Hash<k, T, copy, trans> HT;typedef unorderediterator<k, T, copy, trans> self;HT* _Hash;Node* _node;unorderediterator(HT* hash, Node* x):_Hash(hash), _node(x){}T& operator*(){return _node->_date;}T* operator->(){return &(_node->_date);}bool operator!=(const self& bitter)//self* bitter{//比较哈希表中的vector不是iterator?//迭代器==哈希+节点 比较迭代器的地址还是节点的地址?if (this->_node == bitter._node)return false;return true;}//主要是要去找节点:self operator++(){trans kot;copy up;//1.情况一:当前节点有下一个节点:if (_node->_next != nullptr)_node = _node->_next;//2.哈希位置的跳转:else{size_t hashi = kot(up(_node->_date)) % _Hash->_hash.size();hashi++;while (hashi < _Hash->_hash.size()){if (_Hash->_hash[hashi]){_node = _Hash->_hash[hashi];break;}hashi++;}if (hashi == _Hash->_hash.size())_node = nullptr;}return *this;}};
3.插入:
1.bool返回的插入:
1.正常插入:通过key计算下标值。
2.当前Hash[hashi]中已经有数据进行头插操作。
3.当前Hash[hashi]中没有有数据就修改hash[hashi]值。
4.负载因子到1就需要进行扩容操作,负载因子=单链表个数/hash.size()
5.创建一个新的大小为当前哈希表的两倍,遍历原来的链表有key求下标的方法重新进行原来数据的移动,节约了时间,结尾和_node进行哈希表的交换。
bool insert(const T& x){copy kot;trans up;//1.调find函数去查一下当前要插入的数据是否已经存在if (find(kot(x)))return false;//1.计算平衡因子:if (_num == _hash.size()){vector<Node*> newhash(_hash.size() * 2, nullptr);for (int i = 0; i < _hash.size(); i++){Node* cur = _hash[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = up(kot(cur->_date)) % (_hash.size() * 2);cur->_next = newhash[hashi];newhash[hashi] = cur;cur = next;}_hash[i] = nullptr;}_hash.swap(newhash);}else{//1.正常插入size_t hashi = up(kot(x)) % _hash.size();Node* newnode = new Node(x);//1-1:_hash[hashi]==nullptr 直接插入节点:newnode->_next = _hash[hashi];_hash[hashi] = newnode;_num++;return true;}return false;}Node* find(const k& fd){trans up;copy kot;size_t i = up(fd) % _hash.size();Node* cur = _hash[i];while (cur){if ((up(kot(cur->_date))) == up(fd))return cur;cur = cur->_next;}return nullptr;}
2.重载operator[]实现的重载unordered_map独有:
1,重载operator[]一定需要pair<iterator,bool>的插入返回。
2.operator[]不存在就插入,存在就返回value的引用可以进行修改。
3.ret.second 为false表示已经插入过对应的key值。
4.ret.second 为true表示没有插入过对应的key值这一次刚刚插入数据。
5.优化了一个find的查找返回迭代器类型的数据方便pair<iterator,bool>返回。
pair <_iterator, bool> Insert(const T& x){copy kot;trans up;//1.调find函数去查一下当前要插入的数据是否已经存在if (Find(kot(x))._node)return make_pair(Find(kot(x)),false);//1.计算平衡因子:if (_num == _hash.size()){vector<Node*> newhash(_hash.size() * 2, nullptr);for (int i = 0; i < _hash.size(); i++){Node* cur = _hash[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = up(kot(cur->_date)) % (_hash.size() * 2);cur->_next = newhash[hashi];newhash[hashi] = cur;cur = next;}_hash[i] = nullptr;}_hash.swap(newhash);}else{//1.正常插入size_t hashi = up(kot(x)) % _hash.size();Node* newnode = new Node(x);//1-1:_hash[hashi]==nullptr 直接插入节点:newnode->_next = _hash[hashi];_hash[hashi] = newnode;_num++;return make_pair(_iterator(this,newnode), true);}return make_pair(_iterator(this,nullptr),false);}_iterator Find(const k& fd){trans up;copy kot;size_t i = up(fd) % _hash.size();Node* cur = _hash[i];while (cur){if ((up(kot(cur->_date))) == up(fd))return _iterator(this, cur);cur = cur->_next;}return _iterator(this,nullptr);}
#pragma once#include<iostream>
#include<string>
#include<vector>using namespace std;template<class T>
struct transition
{size_t operator()(const T& x){return x;}
};//1.string -> string
template<>
struct transition<string>
{size_t operator()(const string& x){//1.可以计算string字符串的asia码的和并且每次*131降低哈希冲突:size_t sum = 0;for (auto& e : x){sum += (e * 131);}return sum;}
};namespace Hash_bucket
{template<class T>struct Hash_Node {typedef Hash_Node Node;Hash_Node(T x = T()):_date(x),_next(nullptr){}T _date;Node* _next;};//T() ---> int//T() ---> pair<int,int> pair类型://哈希表和迭代器相互包含需要声明迭代器到哈希表的前面://类模板的声明需要模板+struct/class + 类名:template<class k, class T, class copy, class trans>struct unorderediterator;template<class k , class T, class copy, class trans>class Hash {template<class K, class T, class copy, class Hash>friend struct unorderediterator;public:typedef Hash_Node<T> Node;typedef unorderediterator<k, T, copy, trans> _iterator;Hash(size_t n = 10){_hash.resize(n,nullptr);_num = 0;}pair <_iterator, bool> Insert(const T& x){copy kot;trans up;//1.调find函数去查一下当前要插入的数据是否已经存在if (Find(kot(x))._node)return make_pair(Find(kot(x)),false);//1.计算平衡因子:if (_num == _hash.size()){vector<Node*> newhash(_hash.size() * 2, nullptr);for (int i = 0; i < _hash.size(); i++){Node* cur = _hash[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = up(kot(cur->_date)) % (_hash.size() * 2);cur->_next = newhash[hashi];newhash[hashi] = cur;cur = next;}_hash[i] = nullptr;}_hash.swap(newhash);}else{//1.正常插入size_t hashi = up(kot(x)) % _hash.size();Node* newnode = new Node(x);//1-1:_hash[hashi]==nullptr 直接插入节点:newnode->_next = _hash[hashi];_hash[hashi] = newnode;_num++;return make_pair(_iterator(this,newnode), true);}return make_pair(_iterator(this,nullptr),false);}_iterator Find(const k& fd){trans up;copy kot;size_t i = up(fd) % _hash.size();Node* cur = _hash[i];while (cur){if ((up(kot(cur->_date))) == up(fd))return _iterator(this, cur);cur = cur->_next;}return _iterator(this,nullptr);}bool insert(const T& x){copy kot;trans up;//1.调find函数去查一下当前要插入的数据是否已经存在if (find(kot(x)))return false;//1.计算平衡因子:if (_num == _hash.size()){vector<Node*> newhash(_hash.size() * 2, nullptr);for (int i = 0; i < _hash.size(); i++){Node* cur = _hash[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = up(kot(cur->_date)) % (_hash.size() * 2);cur->_next = newhash[hashi];newhash[hashi] = cur;cur = next;}_hash[i] = nullptr;}_hash.swap(newhash);}else{//1.正常插入size_t hashi = up(kot(x)) % _hash.size();Node* newnode = new Node(x);//1-1:_hash[hashi]==nullptr 直接插入节点:newnode->_next = _hash[hashi];_hash[hashi] = newnode;_num++;return true;}return false;}Node* find(const k& fd){trans up;copy kot;size_t i = up(fd) % _hash.size();Node* cur = _hash[i];while (cur){if ((up(kot(cur->_date))) == up(fd))return cur;cur = cur->_next;}return nullptr;}bool erase(const T& fd){trans kot;copy up;size_t i = kot(up(fd)) % _hash.size();Node* cur = _hash[i];Node* prev = nullptr;while (cur){if (up(cur->_date) == fd){if (prev == nullptr){_hash[i] = cur->_next;}else{prev->_next = cur->_next;}return true;}prev = cur;cur = cur->_next;}return false;}void Some(){size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _hash.size(); i++){Node* cur = _hash[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;//平衡因子printf("load factor:%lf\n", (double)_num / _hash.size());//表长度:printf("all bucketSize:%d\n",_hash.size());//桶的个数:printf("bucketSize:%d\n", bucketSize);//最长的桶的长度printf("maxBucketLen:%d\n", maxBucketLen);//平均桶长度printf("averageBucketLen:%lf\n\n", averageBucketLen);}//找开始的节点:_iterator find_begin(){for (int i = 0; i < _hash.size(); i++){if (_hash[i]){return _iterator(this, _hash[i]);}}return _iterator(this, nullptr);}_iterator find_end(){return _iterator(this, nullptr);}private://指针数组:vector<Node*> _hash;size_t _num;};//迭代器:template<class k, class T, class copy, class trans>struct unorderediterator{typedef Hash_Node<T> Node;typedef Hash<k, T, copy, trans> HT;typedef unorderediterator<k, T, copy, trans> self;HT* _Hash;Node* _node;unorderediterator(HT* hash, Node* x):_Hash(hash), _node(x){}T& operator*(){return _node->_date;}T* operator->(){return &(_node->_date);}bool operator!=(const self& bitter)//self* bitter{//比较哈希表中的vector不是iterator?//迭代器==哈希+节点 比较迭代器的地址还是节点的地址?if (this->_node == bitter._node)return false;return true;}//主要是要去找节点:self operator++(){trans kot;copy up;//1.情况一:当前节点有下一个节点:if (_node->_next != nullptr)_node = _node->_next;//2.哈希位置的跳转:else{size_t hashi = kot(up(_node->_date)) % _Hash->_hash.size();hashi++;while (hashi < _Hash->_hash.size()){if (_Hash->_hash[hashi]){_node = _Hash->_hash[hashi];break;}hashi++;}if (hashi == _Hash->_hash.size())_node = nullptr;}return *this;}};
}相关文章:
[C++]20:unorderedset和unorderedmap结构和封装。
unorderedset和unorderedmap结构和封装 一.哈希表:1.直接定址法:2.闭散列的开放定址法:1.基本结构:2.insert3.find4.erase5.补充:6.pair<k,v> k的数据类型: 3.开散列的拉链法/哈希桶:1.基…...
 B 跳转指令)
ARM 汇编指令:(六) B 跳转指令
目录 一.B 和 BL 1.B/BL指令的语法格式 2.示例解析 一.B 和 BL 跳转指令 B 使程序跳转到指定的地址执行程序。指令 BL 将下一条指令的地址复制到 R14(即返回地址连接寄存器 LR)寄存器中,然后跳转到指定地址运行程序。 1.B/B…...

SQLiteC/C++接口详细介绍之sqlite3类(十一)
返回目录:SQLite—免费开源数据库系列文章目录 上一篇:SQLiteC/C接口详细介绍之sqlite3类(十) 下一篇:SQLiteC/C接口详细介绍之sqlite3类(十二)(未发表) 33.sq…...
百度智能云+SpringBoot=AI对话【人工智能】
百度智能云SpringBootAI对话【人工智能】 前言版权推荐百度智能云SpringBootAI对话【人工智能】效果演示登录AI对话 项目结构后端开发pom和propertiessql_table和entitydao和mapperservice和implconfig和utilLoginController和ChatController 前端开发css和jslogin.html和chat.…...

第二十七节 Java 多态
本章主要为大家介绍java多态的概念,以及便于理解的多态简单例子。 Java 多态 多态是同一个行为具有多个不同表现形式或形态的能力。 多态性是对象多种表现形式的体现。 比如我们说"宠物"这个对象,它就有很多不同的表达或实现,比…...
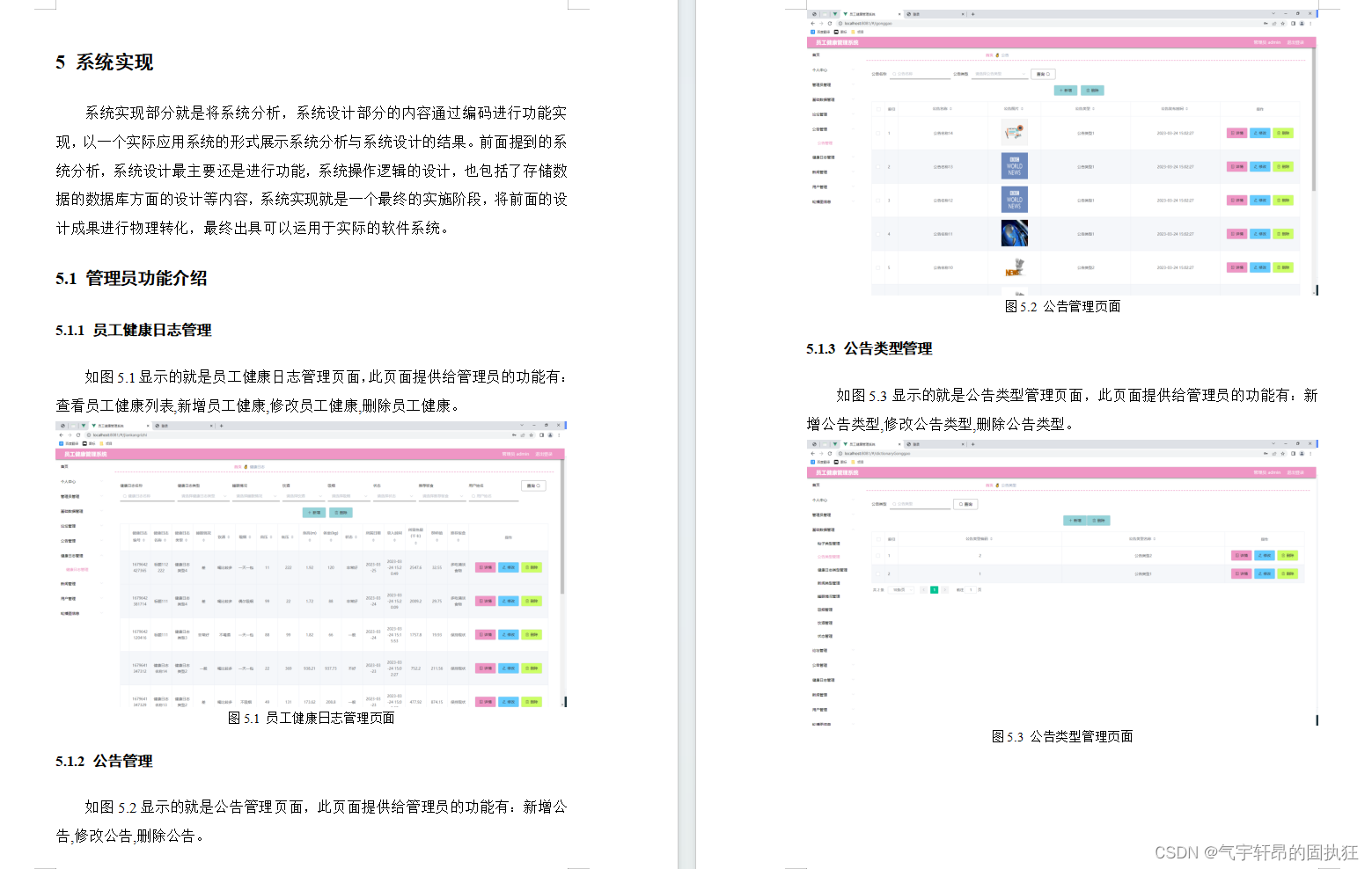
基于Springboot的员工健康管理系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的员工健康管理系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构…...

[论文精读]Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection
论文网址:[2304.08876] 用于定向微小目标检测的动态粗到细学习 (arxiv.org) 论文代码:https://github.com/ChaselTsui/mmrotate-dcfl 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误&…...

Selenium WebDriver 中用于查找网页元素的两个方法
这里提供了 Selenium WebDriver 中用于查找元素的两个方法:find_element() 和 find_elements()。 find_element(byid, value: Optional[str] None) → selenium.webdriver.remote.webelement.WebElement 这个方法用于查找满足指定定位策略(By strategy&…...

python 常用装饰器
文章目录 property的介绍与使用作用使用场景装饰方法防止属性被修改 实现setter和getter的行为 staticmethod 与 classmethod作用代码示例 两者区别使用区别代码演示 abstractmethod参考资料 property的介绍与使用 python的property是python的一种装饰器,是用来修饰…...

深入解析MySQL日志系统:Binlog、Undo Log和Redo Log
在数据库系统中,日志文件扮演着至关重要的角色,它们不仅保证了数据的完整性和一致性,还支持了数据的恢复、复制和审计等功能。MySQL数据库中最核心的日志系统包括二进制日志(Binlog)、回滚日志(Undo Log&am…...

强森算法求两点最短路径的基本流程及代码实现
对于强森算法,给定的一个图中,算法首先会构造一个新的节点s,然后从新构造的这个节点引出多条边分别连通图中的每一个节点,这些边的长度一开始是被设置为0的,然后使用贝尔曼-福德算法进行计算,算出从s到图中每一个节点的最短路径。 而在运行贝尔曼-福德算法的过程中如果发…...

数据结构入门篇 之 【双链表】的实现讲解(附完整实现代码及顺序表与线性表的优缺点对比)
一日读书一日功,一日不读十日空 书中自有颜如玉,书中自有黄金屋 一、双链表 1、双链表的结构 2、双链表的实现 1)、双向链表中节点的结构定义 2)、初始化函数 LTInit 3)、尾插函数 LTPushBack 4)、头…...

什么是零日攻击?
一、零日攻击的概念 零日攻击是指利用零日漏洞对系统或软件应用发动的网络攻击。 零日漏洞也称零时差漏洞,通常是指还没有补丁的安全漏洞。由于零日漏洞的严重级别通常较高,所以零日攻击往往也具有很大的破坏性。 目前,任何安全产品或解决方案…...

阿里云2025届春招实习生招聘
投递时间:2024年2月1日-2026年3月1日 岗位职责 负责大型客户“上云”,"用云"技术平台开发。 开发云迁移运维技术工具,帮助阿里云服务团队&&企业客户和服务商自主、高效的完成云迁移。 开发云运维技术工具,帮助…...
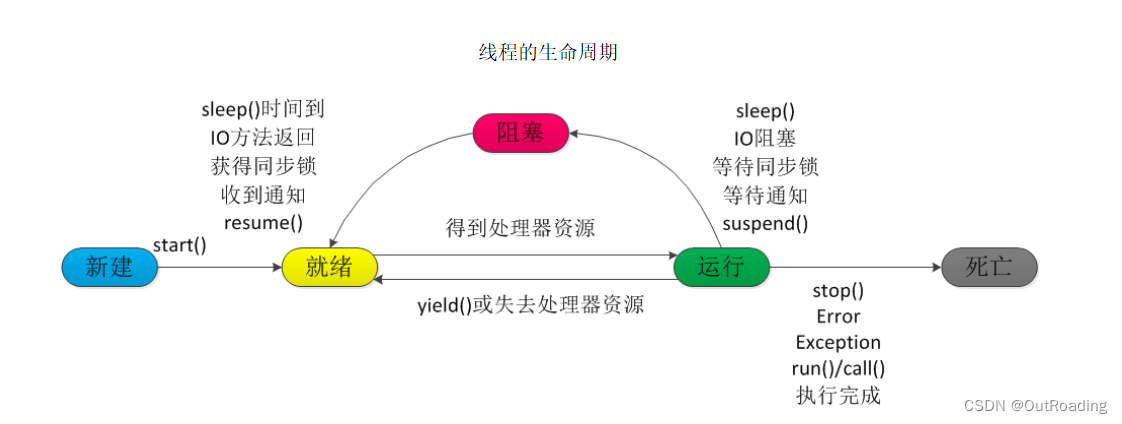
简单了解多线程
并发和并行 并发: 在同一时刻,多个指令在单一CPU上交替指向 并行:在同一时刻,多个指令在多个CPU上同时执行 2核4线程,4核8线程,8核16线程,16核32线程 基础实现线程的方式 Thread :继承类 &…...

GEE对上传并读取CSV文件
首先在Assets中上传csv csv格式如下所示: 上传好了之后,来看看这个表能否显示 var table ee.FeatureCollection("projects/a-flyllf0313/assets/dachang_2022"); var sortedTable table.sort(id); // 替换 propertyName 为你想要排序的属性…...

vulnhub-----SickOS靶机
文章目录 1.信息收集2.curl命令反弹shell提权利用POC 1.信息收集 ┌──(root㉿kali)-[~/kali/vulnhub/sockos] └─# arp-scan -l Interface: eth0, type: EN10MB, MAC: 00:0c:29:10:3c:9b, IPv4: 10.10.10.10 Starting arp-scan 1.9.8 with 256…...
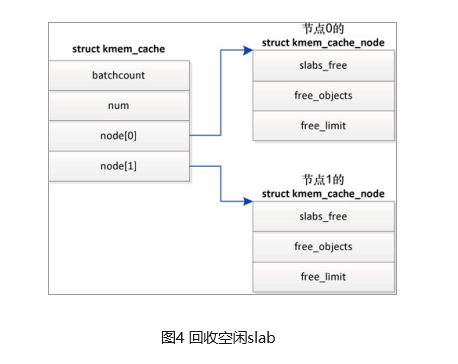
slab分配器
什么是slab分配器? 用户态程序可以使用malloc及其在C标准库中的相关函数申请内存;内核也需要经常分配内存,但无法使用标准库函数;linux内核中,伙伴分配器是一种页分配器,是以页为单位的,但这个…...

MySQL面试题之基础夯实
一、mysql当中的基本数据类型有哪些 MySQL中的基本数据类型包括但不限于以下几大类: 数值类型: 整数类型:TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)、BIGINT浮点数类型:FLOAT、DOUBLE、DECIMAL…...

feign请求添加拦截器
FeignClient 的 configuration 属性: Feign 注解 FeignClient 的 configuration 属性,可以对 feign 的请求进行配置。 包括配置Feign的Encoder、Decoder、 Interceptor 等。 feign 请求添加拦截器,也可以通过这个 configuration 属性 来指…...

浏览器书签管理的革命性解决方案:Neat Bookmarks树状扩展深度解析
浏览器书签管理的革命性解决方案:Neat Bookmarks树状扩展深度解析 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 你是否曾在数百个杂乱书…...

华为SDH传输设备时钟配置避坑指南:从单BITS到主备BITS的实战配置详解
华为SDH传输设备时钟配置实战:从基础原理到复杂组网避坑指南 时钟同步是SDH传输网络的命脉,一次错误的配置可能导致全网时钟互锁、业务闪断甚至级联故障。记得去年某运营商骨干网就因时钟ID分配冲突引发全网时钟振荡,故障定位耗时超过72小时。…...

让本地可以推流的设置
edge://flags/#enable-webrtc-hide-local-ips-with-mdns...

影刀RPA自动化上架前的数据准备怎么实现“真自动化”?AI+类目属性映射方案解析
在电商多平台矩阵铺货的实战中,许多团队引入了自动化工具,初衷是为了提升效率。但当业务真正跑起来后,往往会遇到一个尴尬的瓶颈:上架动作虽然自动化了,但上架前的数据准备依然是纯人力的“泥潭”。为了让流程跑通&…...

番茄小说下载器:构建个人离线数字图书馆的终极指南
番茄小说下载器:构建个人离线数字图书馆的终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 在数字阅读时代,你是否曾因网络中断而无法继续阅读心爱的小说&am…...

第一个shell脚本
Bash脚本: 能够监控指定名称的进程sshd 如果进程存在,则输出其PID和状态信息 如果进程不存在,则自动尝试重启该进程(可假设进程启动命令已知),并记录日志(包含时间戳)shell脚本 #!/bin/bash #要监控的进程名 namessh #日志路径 lo…...

不止于错误捕获:深入Tcl的catch命令,玩转break、continue和return的异常流
深入解析Tcl的catch命令:掌控脚本流程的终极武器 在Tcl脚本编程中,异常处理是构建健壮应用程序的关键。大多数开发者对catch命令的理解停留在简单的错误捕获层面,却忽略了它作为流程控制枢纽的强大潜力。本文将带你重新认识这个被低估的语言特…...

【Android】智能工具箱_1_1_8_Lwely
【Android】智能工具箱_1_1_8_去广告_解锁订阅版_Lwely 链接:https://pan.xunlei.com/s/VOqe5UC9mJL1rNZAeFOhIm0jA1?pwdhucf#这款智能工具箱解锁订阅版已去除广告干扰,集成超过百种实用工具于一体,从尺子、水平仪到系统优化功能一应俱全。界…...

老系统安全加固指南:以久草CMS V1.9为例,手把手教你修复后台文件写入与CSRF组合漏洞
老系统安全加固实战:从漏洞分析到修复的完整方案 当企业运维人员接手一个历史悠久的CMS系统时,面临的不仅是技术债务,更是一场与时间赛跑的安全保卫战。以某CMS V1.9为例,这个发布于多年前的系统至今仍在不少中小型网站服役&#…...

R语言metaprop函数详解:单组率Meta分析中5种数据转换方法到底怎么选?
R语言metaprop函数实战:单组率Meta分析中5种数据转换方法的选择策略 在临床研究和流行病学领域,单组率Meta分析是一种常见的数据整合方法。当我们需要合并多个研究中同一事件的发⽣率时,R语言中的metaprop()函数提供了五种不同的数据转换方法…...