Spark面试重点
文章目录
- 1.简述hadoop 和 spark 的不同点(为什么spark更快)
- 2.谈谈你对RDD的理解
- 3.简述spark的shuffle过程
- 4. groupByKey和reduceByKey的区别
1.简述hadoop 和 spark 的不同点(为什么spark更快)
Hadoop 和 Spark 是两种用于大数据处理的流行框架。
-
执行方式:
- Hadoop 使用 MapReduce 编程模型进行数据处理,该模型涉及将数据切分成小块并分发到不同的计算节点上,在每个节点上执行 Map 和 Reduce 阶段的操作。
- Spark 使用 RDD(Resilient Distributed Dataset)编程模型,允许将数据缓存在内存中,并且支持多种操作,如 Map、Reduce、Filter、Join 等,这样可以在内存中进行迭代式计算,避免了频繁的磁盘读写操作。
-
内存管理:
- Hadoop 在处理数据时通常需要频繁地读写数据到磁盘,这会导致磁盘 I/O 成为性能瓶颈,尤其是在迭代式计算中。
- Spark 利用内存进行数据缓存和计算,可以将中间结果保存在内存中,从而减少了磁盘 I/O 的开销,加速了数据处理过程。
-
处理速度:
- 由于 Spark 具有更好的内存管理和迭代式计算能力,因此通常比 Hadoop MapReduce 更快。特别是在迭代式算法、机器学习、图计算等场景下,Spark 的性能优势更加明显。
- Spark 还支持 DAG(Directed Acyclic Graph)执行引擎,能够在内存中进行更有效的优化和调度,提高了任务的执行效率。
-
适用场景:
- Hadoop 适用于批处理场景,特别是大规模数据的离线处理和分析。
- Spark 不仅适用于批处理,还可以用于实时流处理、交互式查询、机器学习等多种场景,具有更广泛的适用性。
总的来说,Spark 相对于 Hadoop 具有更好的内存管理和执行效率,特别是在迭代式计算和交互式查询等场景下更为突出。Spark 的速度更快主要是由于它的内存计算和优化的执行引擎,以及支持多种操作和丰富的功能。
2.谈谈你对RDD的理解
RDD(Resilient Distributed Dataset)是 Spark 中的核心概念之一,是一种分布式的、不可变的、可并行处理的数据集合。以下是我对 RDD 的理解:
-
分布式的:RDD 是分布式存储在集群中多个节点上的数据集合。数据被切分成多个分区,每个分区可以在集群中的不同节点上进行处理。
-
不可变的:RDD 的数据是不可变的,即一旦创建后就不可修改。如果需要对 RDD 进行转换或操作,通常会生成一个新的 RDD,原始 RDD 保持不变。
-
容错的:RDD 具有容错性,即使在节点发生故障时也能够恢复数据。RDD 使用日志和血统信息来记录每个分区的转换历史,从而可以在节点失败后重新计算丢失的分区。
-
惰性计算:RDD 的转换操作是惰性计算的,即在遇到动作(Action)操作之前,并不会立即执行转换操作,而是会构建一个操作的逻辑计划图。只有当遇到动作操作时,Spark 才会执行逻辑计划图中的转换操作。
-
可持久化:RDD 可以通过持久化(Persistence)机制将数据缓存在内存或磁盘中,以便后续重用。这样可以避免重复计算和提高执行效率。
-
函数式编程模型:RDD 支持函数式编程模型,可以进行各种转换操作,如 Map、Filter、Reduce、Join 等,从而实现复杂的数据处理和分析任务。
-
并行化处理:RDD 允许在集群中并行处理数据,可以利用集群中多个节点的计算资源,加速数据处理过程。
总的来说,RDD 提供了一种灵活、高效的数据处理模型,适用于大规模数据的分布式处理和分析。它的不可变性、容错性和惰性计算等特性使得 Spark 具有高性能、高可靠性和高扩展性,成为大数据处理领域的重要工具之一。
3.简述spark的shuffle过程
Spark 的 Shuffle 过程是在执行涉及数据重分区的操作时发生的。这个过程通常会发生在需要进行数据重新分布的操作,比如在进行聚合操作(如 groupByKey、reduceByKey)或者连接操作(如 join)时。
Shuffle 过程主要包括三个阶段:
-
Map 阶段:
- 在 Map 阶段,Spark 会对每个分区的数据进行局部的处理,生成一个或多个键值对。
- 如果执行了需要数据重分区的转换操作,比如
groupByKey或者reduceByKey,则会生成一个中间结果集,其中的数据已经按照键进行了分组。
-
Partition 阶段:
- 在 Partition 阶段,Spark 将 Map 阶段生成的中间结果根据键值对的键进行分区(Partition),以便后续可以并行地对每个分区进行处理。
- 默认情况下,Spark 使用哈希分区(Hash Partitioning)将键进行哈希映射到不同的分区中。
-
Reduce 阶段:
- 在 Reduce 阶段,Spark 会将具有相同键的数据集合在一起,并进行相应的聚合操作。
- 如果执行了
groupByKey操作,那么每个分区的数据都会根据键进行分组,然后在每个分组内执行相应的聚合操作。 - 如果执行了
reduceByKey操作,那么会先对每个分区内具有相同键的数据进行局部聚合,然后再将结果合并到全局,得到最终的聚合结果。
在 Shuffle 过程中,数据的重新分区和网络传输会涉及大量的数据移动和通信,因此它是 Spark 中性能开销比较大的一个阶段。优化 Shuffle 过程可以有效提高 Spark 应用的性能,比如通过调整分区数、使用合适的数据结构、合理设置缓存等方式。
4. groupByKey和reduceByKey的区别
groupByKey 和 reduceByKey 是 Spark 中用于按键对数据进行分组和聚合的两个常用操作,它们之间的区别在于如何处理相同键的数据:
-
groupByKey:
groupByKey操作将具有相同键的数据集合在一起,形成一个键值对的迭代器。- 对于每个键,Spark 会将相同键的所有值组成一个迭代器,即使这些值分布在不同的分区上。
- 由于会生成大量的键值对迭代器,因此
groupByKey操作可能会导致大量的数据移动和内存消耗,特别是在键的基数很大时。
-
reduceByKey:
reduceByKey操作先对具有相同键的数据进行本地聚合,在每个分区内先对相同键的值进行聚合操作(比如求和、求最大值等),然后再将结果合并到全局。- 由于在每个分区内进行了本地聚合,因此
reduceByKey操作可以显著减少数据移动和内存消耗,尤其是对于大规模数据集。 reduceByKey操作需要提供一个聚合函数作为参数,以指定对相同键的值进行何种聚合操作。
因此,总的来说,reduceByKey 操作比 groupByKey 更高效,特别是对于大规模数据集和键的基数较大的情况下。在实际应用中,通常建议尽量使用 reduceByKey 而不是 groupByKey,以提高性能和减少资源消耗。
相关文章:

Spark面试重点
文章目录 1.简述hadoop 和 spark 的不同点(为什么spark更快)2.谈谈你对RDD的理解3.简述spark的shuffle过程4. groupByKey和reduceByKey的区别 1.简述hadoop 和 spark 的不同点(为什么spark更快) Hadoop 和 Spark 是两种用于大数据…...

UGUI源码分析与研究2-从底层实现的角度去分析和调优UI的性能问题和疑难杂症
从底层实现的角度去分析和调优UI的性能问题和疑难杂症,可以从以下几个方面入手: 绘制性能优化:UI的绘制是一个重要的性能瓶颈,可以通过以下方式进行优化: 减少绘制区域:只绘制可见区域,避免不必…...
OpenAI的GPT已达极限,更看好AI Agent
日前,比尔盖茨发表文章表示:AI Agent不仅会改变人与电脑的互动方式,或许还将颠覆软件行业,引领自输入命令到点击图标以来的最大计算机革命。 在数字化和技术创新的浪潮中,AI Agent作为一种前沿技术,正开启…...

【C/C++】详解 assert() 断言(什么是assert? assert有什么作用?)
目录 一、前言 二、什么是 assert ? 三、assert 的用法 四、assert 案例解析 五、assert 断言的使用原则 六、共勉 一、前言 在编写程序过程中,尤其是调试代码时,往往需要一个提醒代码漏洞/Bug的小助手,以便于程序员及时修改和完善代码…...

[C++]20:unorderedset和unorderedmap结构和封装。
unorderedset和unorderedmap结构和封装 一.哈希表:1.直接定址法:2.闭散列的开放定址法:1.基本结构:2.insert3.find4.erase5.补充:6.pair<k,v> k的数据类型: 3.开散列的拉链法/哈希桶:1.基…...
 B 跳转指令)
ARM 汇编指令:(六) B 跳转指令
目录 一.B 和 BL 1.B/BL指令的语法格式 2.示例解析 一.B 和 BL 跳转指令 B 使程序跳转到指定的地址执行程序。指令 BL 将下一条指令的地址复制到 R14(即返回地址连接寄存器 LR)寄存器中,然后跳转到指定地址运行程序。 1.B/B…...

SQLiteC/C++接口详细介绍之sqlite3类(十一)
返回目录:SQLite—免费开源数据库系列文章目录 上一篇:SQLiteC/C接口详细介绍之sqlite3类(十) 下一篇:SQLiteC/C接口详细介绍之sqlite3类(十二)(未发表) 33.sq…...
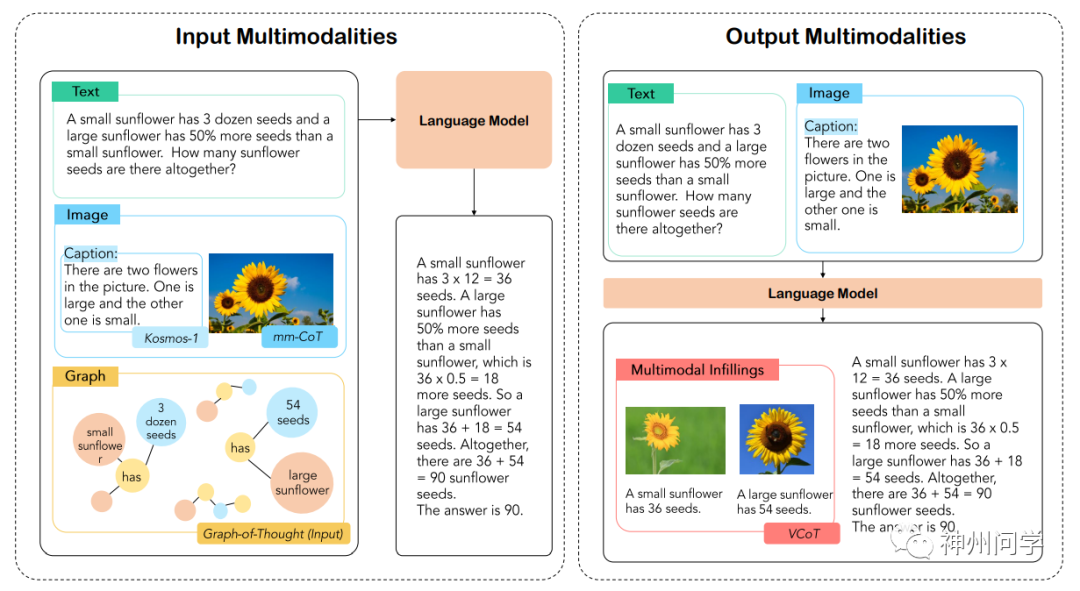
百度智能云+SpringBoot=AI对话【人工智能】
百度智能云SpringBootAI对话【人工智能】 前言版权推荐百度智能云SpringBootAI对话【人工智能】效果演示登录AI对话 项目结构后端开发pom和propertiessql_table和entitydao和mapperservice和implconfig和utilLoginController和ChatController 前端开发css和jslogin.html和chat.…...

第二十七节 Java 多态
本章主要为大家介绍java多态的概念,以及便于理解的多态简单例子。 Java 多态 多态是同一个行为具有多个不同表现形式或形态的能力。 多态性是对象多种表现形式的体现。 比如我们说"宠物"这个对象,它就有很多不同的表达或实现,比…...
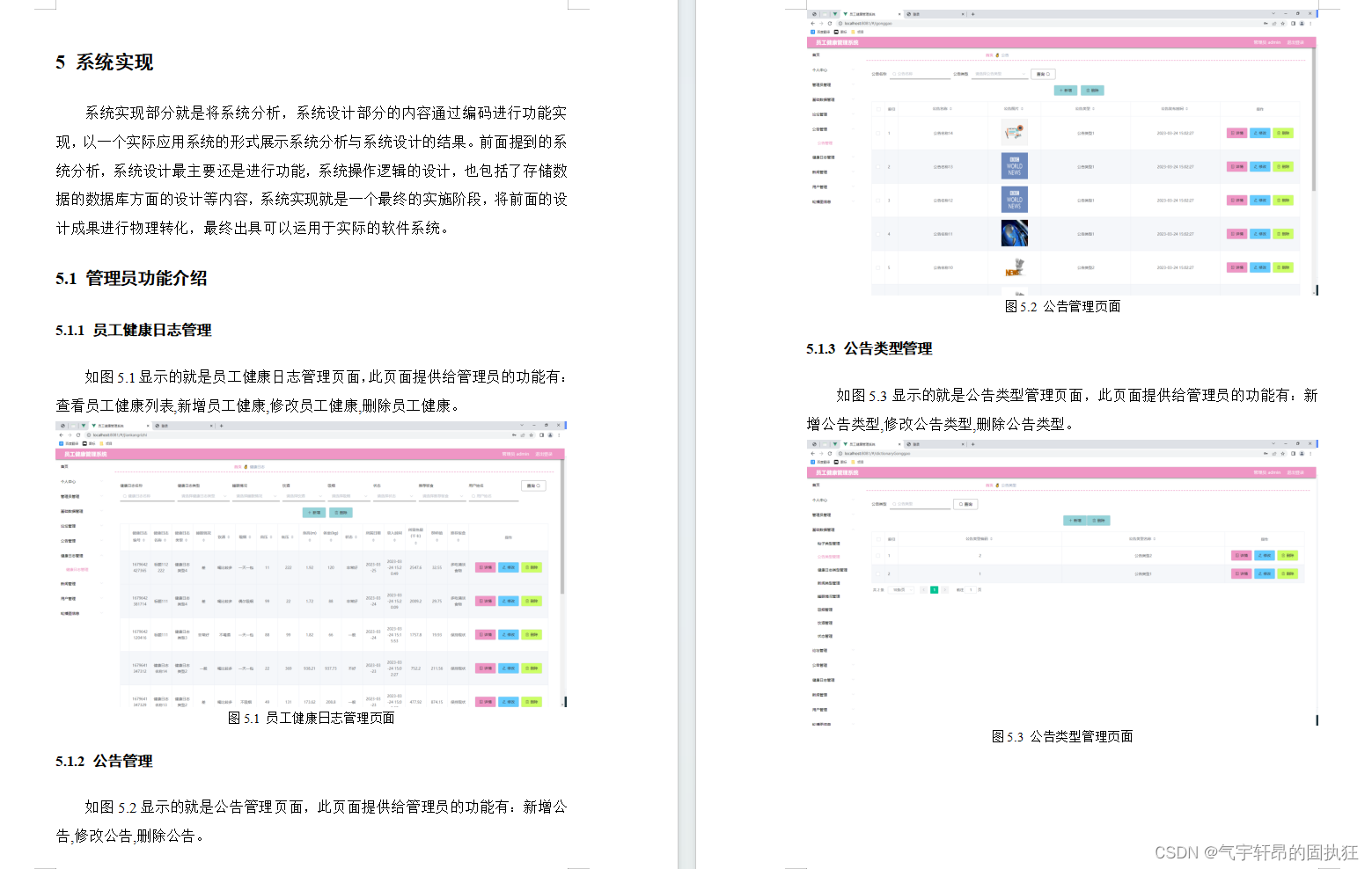
基于Springboot的员工健康管理系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的员工健康管理系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构…...

[论文精读]Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection
论文网址:[2304.08876] 用于定向微小目标检测的动态粗到细学习 (arxiv.org) 论文代码:https://github.com/ChaselTsui/mmrotate-dcfl 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误&…...

Selenium WebDriver 中用于查找网页元素的两个方法
这里提供了 Selenium WebDriver 中用于查找元素的两个方法:find_element() 和 find_elements()。 find_element(byid, value: Optional[str] None) → selenium.webdriver.remote.webelement.WebElement 这个方法用于查找满足指定定位策略(By strategy&…...

python 常用装饰器
文章目录 property的介绍与使用作用使用场景装饰方法防止属性被修改 实现setter和getter的行为 staticmethod 与 classmethod作用代码示例 两者区别使用区别代码演示 abstractmethod参考资料 property的介绍与使用 python的property是python的一种装饰器,是用来修饰…...

深入解析MySQL日志系统:Binlog、Undo Log和Redo Log
在数据库系统中,日志文件扮演着至关重要的角色,它们不仅保证了数据的完整性和一致性,还支持了数据的恢复、复制和审计等功能。MySQL数据库中最核心的日志系统包括二进制日志(Binlog)、回滚日志(Undo Log&am…...

强森算法求两点最短路径的基本流程及代码实现
对于强森算法,给定的一个图中,算法首先会构造一个新的节点s,然后从新构造的这个节点引出多条边分别连通图中的每一个节点,这些边的长度一开始是被设置为0的,然后使用贝尔曼-福德算法进行计算,算出从s到图中每一个节点的最短路径。 而在运行贝尔曼-福德算法的过程中如果发…...

数据结构入门篇 之 【双链表】的实现讲解(附完整实现代码及顺序表与线性表的优缺点对比)
一日读书一日功,一日不读十日空 书中自有颜如玉,书中自有黄金屋 一、双链表 1、双链表的结构 2、双链表的实现 1)、双向链表中节点的结构定义 2)、初始化函数 LTInit 3)、尾插函数 LTPushBack 4)、头…...

什么是零日攻击?
一、零日攻击的概念 零日攻击是指利用零日漏洞对系统或软件应用发动的网络攻击。 零日漏洞也称零时差漏洞,通常是指还没有补丁的安全漏洞。由于零日漏洞的严重级别通常较高,所以零日攻击往往也具有很大的破坏性。 目前,任何安全产品或解决方案…...

阿里云2025届春招实习生招聘
投递时间:2024年2月1日-2026年3月1日 岗位职责 负责大型客户“上云”,"用云"技术平台开发。 开发云迁移运维技术工具,帮助阿里云服务团队&&企业客户和服务商自主、高效的完成云迁移。 开发云运维技术工具,帮助…...
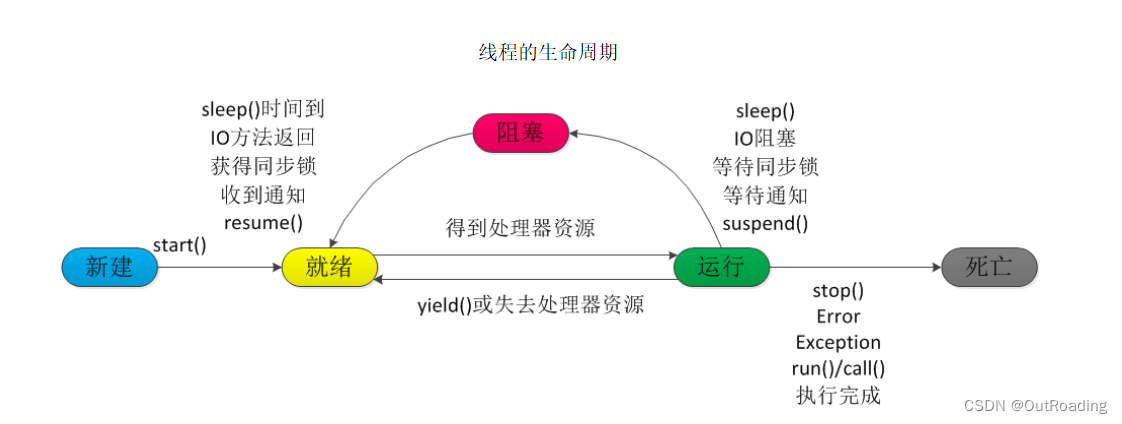
简单了解多线程
并发和并行 并发: 在同一时刻,多个指令在单一CPU上交替指向 并行:在同一时刻,多个指令在多个CPU上同时执行 2核4线程,4核8线程,8核16线程,16核32线程 基础实现线程的方式 Thread :继承类 &…...

GEE对上传并读取CSV文件
首先在Assets中上传csv csv格式如下所示: 上传好了之后,来看看这个表能否显示 var table ee.FeatureCollection("projects/a-flyllf0313/assets/dachang_2022"); var sortedTable table.sort(id); // 替换 propertyName 为你想要排序的属性…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

Nacos CVE-2021-29441漏洞深度解析:User-Agent绕过与鉴权失效
1. 这个漏洞不是“改个Header就能登录”,而是Nacos鉴权体系的一道裂缝CVE-2021-29441这个编号在Nacos社区里曾被轻描淡写地归为“低危”,直到我接手一个金融客户线上告警——他们的Nacos集群在凌晨三点被批量创建了37个高权限用户,所有操作日…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

基于Arduino Uno与MQ-2传感器的智能气体检测报警系统DIY全攻略
1. 项目概述与核心思路最近在捣鼓家里的智能安防,琢磨着能不能自己做一个成本可控、反应灵敏的气体检测报警装置。市面上成品烟雾报警器虽然成熟,但要么功能单一,要么价格不菲,而且很难根据自己的需求进行定制化调整,比…...

5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南
5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专为Windows设计的鼠…...