还是了解下吧,大语言模型调研汇总
大语言模型调研汇总
- 一. Basic Language Model
- T5
- GPT-3
- LaMDA
- Jurassic-1
- MT-NLG
- Gopher
- Chinchilla
- PaLM
- U-PaLM
- OPT
- LLaMA
- BLOOM
- GLM-130B
- ERNIE 3.0 Titan
- 二. Instruction-Finetuned Language Model
- T0
- FLAN
- Flan-LM
- BLOOMZ & mT0
- GPT-3.5
- ChatGPT
- GPT-4
- Alpaca
- ChatGLM
- ERNIE Bot
- Bard
自从ChatGPT出现之后,各种大语言模型是彻底被解封了,每天见到的模型都能不重样,几乎分不清这些模型是哪个机构发布的、有什么功能特点、以及这些模型的关系。比如 GPT-3.0 和 GPT 3.5 就有一系列的模型版本和索引,还有羊驼、小羊驼、骆驼 …
一. Basic Language Model
基础语言模型是指只在大规模文本语料中进行了预训练的模型,未经过指令和下游任务微调、以及人类反馈等任何对齐优化。
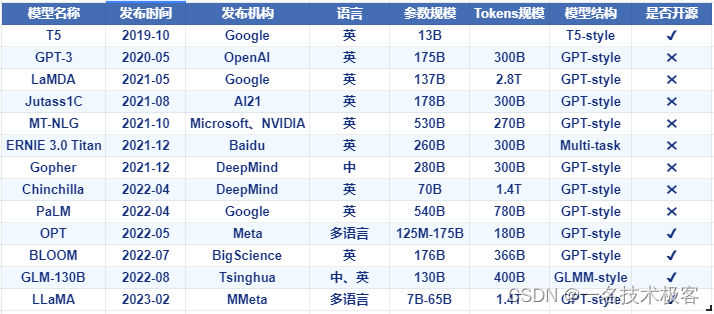
基础 LLM 基本信息表,GPT-style 表示 decoder-only 的自回归语言模型,T5-style 表示 encoder-decoder 的语言模型,GLM-style 表示 GLM 特殊的模型结构,Multi-task 是指 ERNIE 3.0 的模型结构
- 当前绝大部分的大语言模型都是 Decoder-only 的模型结构,原因请转移这个问题:为什么现在的LLM都是Decoder only的架构;
- 大部分大语言模型都不开源,而 OPT、BLOOM、LLaMA 三个模型是主要面向开源促进研究和应用的,中文开源可用的是 GLM,后续很多工作都是在这些开源的基础模型上进行微调优化的
T5
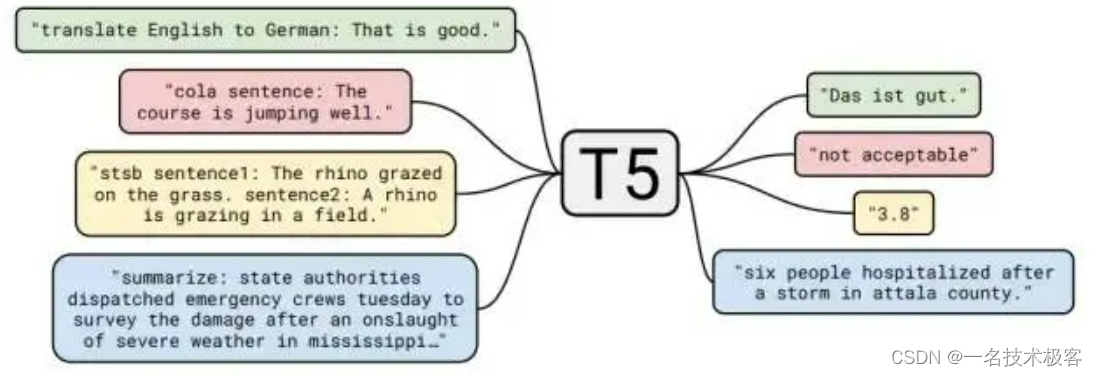
T5 是谷歌提出了一个统一预训练模型和框架,模型采用了谷歌最原始的 Encoder-Decoder Transformer结构。T5将每个文本处理问题都看成“Text-to-Text”问题,即将文本作为输入,生成新的文本作为输出。通过这种方式可以将不同的 NLP 任务统一在一个模型框架之下,充分进行迁移学习。为了告知模型需要执行的任务类型,在输入的文本前添加任务特定的文本前缀 (task-specific prefifix ) 进行提示,这也就是最早的 Prompt。也就说可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
T5 本身主要是针对英文训练,谷歌还发布了支持 101 种语言的 T5 的多语言版本 mT5
GPT-3
大语言模型中最具代表和引领性的就是发布 ChatGPT 的 OpenAI 的 GPT 系列模型 (GPT-1、GPT-2、GPT-3、GPT-3.5、GPT-4),并且当前大部分大语言模型的结构都是 GPT-style ,文章生成式预训练模型中介绍了GPT-1/2/3, 且从 GPT-3 开始才是真正意义的大模型。
GPT-3 是 OpenAI 发布的 GPT 系列模型的一个,延续了 GPT-1/2 基于Transformer Decoder 的自回归语言模型结构,但 GPT-3 将模型参数规模扩大至 175B, 是 GPT-2 的 100 倍,从大规模数据中吸纳更多的知识。GPT-3不在追求 zero-shot 的设定,而是提出 In-Context Learning ,在下游任务中模型不需要任何额外的微调,利用 Prompts 给定少量标注的样本让模型学习再进行推理生成。就能够在只有少量目标任务标注样本的情况下进行很好的泛化,再次证明大力出击奇迹,做大模型的必要性。通过大量的实验证明,在 zero-shot、one-shot 和 few-shot 设置下,GPT-3 在许多 NLP 任务和基准测试中表现出强大的性能,只有少量目标任务标注样本的情况下进行很好的泛化,再次证明大力出击奇迹,做大模型的必要性。

LaMDA
LaMDA 是谷歌在2021年开发者大会上公布的专用于对话的大语言模型,具有 137B 个参数。论文中提出三个指导模型更好训练的指标:质量/Quality(合理性/Sensibleness、特异性/Specificity、趣味性/Interestingness,SSI)、安全性/Safety、真实性/Groundedness。和其他大模型一样,LaMDA分为预训练和微调两步,在微调阶段,生成式任务(给定上下文生成响应)和判别式任务(评估模型生成响应的质量和安全性)应用于预训练模型进行微调形成 LaMDA。对话期间,LaMDA 生成器在给定多轮对话上下文时生成几个候选响应,然后 LaMDA 判别器预测每个候选响应的 SSI 和安全分数。安全分数低的候选响应首先被过滤掉,剩下的候选响应根据 SSI 分数重新排名,并选择分数最高的作为最终响应。为提升 LaMDA 生成响应的真实可靠性,收集标注用户与 LaMDA 间对话的数据集,并在适用的情况下使用检索查询和检索结果进行注释。然后,在这个数据集上微调 LaMDA,学习与用户交互期间调用外部信息检索系统,提升生成响应的真实可靠性。
Jurassic-1
Jurassic-1 是以色列的 AI 公司 AI21 Labs 发布的一对自回归语言模型,由 178B 参数模型 J1-Jumbo 和 7B 参数模型 J1-Large 组成,大致对应 GPT-3 175B 和 GPT-3 6.7B 两个模型。该模型主要对标 GPT-3,在数据补全、零样本学习和少样本学习方面对模型进行了评估,Jurassic-1 模型可以预测来自比 GPT-3 更广泛的领域的文本(网络、学术、法律、源代码等),在零样本条件中实现可比的性能,并且少样本性能优于 GPT-3,因为他们能够将更多示例放入prompt中。
MT-NLG
Megatron-Turing NLG (MT-NLG) 是由 Microsoft 和 NVIDIA 共同研发的大语言模型,具有 530B 个参数,,是 GPT-3 的三倍多,MT-NLG 在多个 benchmarks 中实现了非常好的零、一和少量样本学习性能。 研究认为训练如此大的语言模型有两个挑战,一是存储高效性,将模型参数全部拟合到及时最大GPT的内存中已不再可能;二是计算高效性,若不同时优化算法、软件和硬件堆栈,所需的大量计算操作可能会导致不切实际的长训练时间;需要需要在内存和计算上都可扩展的高效并行技术,以充分发挥数千个 GPU 的潜力。对此,论文提出了结合了 DeepSpeed 的管道并行和数据并行性以及 Megatron 的张量切片并行的高效且可扩展的 3D 并行软件系统。同时,还介绍了模型高效训练的硬件基础设施,提高训练效率和稳定性。
Gopher
Gopher 是 DeepMind 发布的大语言模型,拥有过 280B 规模的参数。在语言模型和开发过程中,DeepMind 训练了 6 个不同参数规模的系列模型,参数量包括 44M、117M、417M、1.4B、7.1B、280B(Gopher)。这些模型在 152 项不同的任务上进行了评估,在大多数任务中都实现了最先进的性能。 阅读理解、事实核查和有毒语言识别等领域性能提升最大,但对于逻辑和数学推理等问题的性能提升较小。
Chinchilla
Chinchilla(龙猫)是 DeepMind 发布的大语言模型,拥有 70B 的参数规模。Chinchilla 的研究主要关注在给定固定的 FLOPs 预算下,如何权衡模型规模大小和训练tokens的数量规模的问题。在 Chinchilla 之前的一系列大语言模型在扩展模型参数规模的同时保持训练数据量不变,导致计算资源的浪费和大语言模型的训练不足。对于计算成本最优的训练,模型规模大小和训练 tokens 的数量应该同等比例地缩放,模型参数规模的加倍时,训练 tokens 的数量也应该加倍。基于上述假设训练了计算优化模型 Chinchilla,它与 Gopher 使用相同的计算预算,但具有 70B 的参数和 4 倍多的训练数据。同时,Chinchilla 在大量下游评估任务上一致且显著优于 Gopher (280B)、GPT-3 (175B)、Jurassic-1 (178B) 和 Megatron-Turing NLG (530B)。Chinchilla 使用更少的计算来进行微调和推理,极大地促进了下游使用。
PaLM
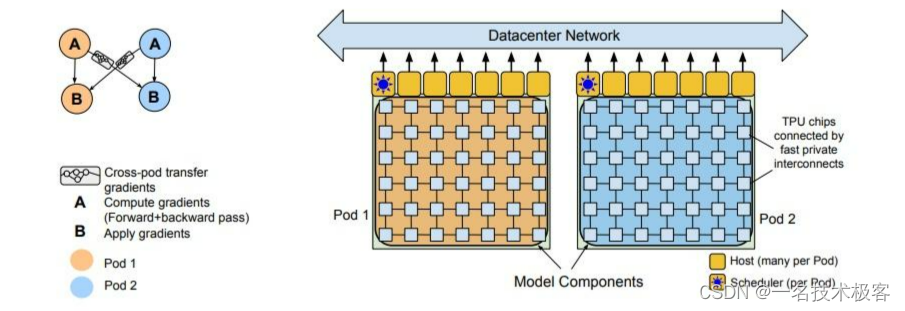
PaLM 是谷歌2022年提出的 540B 参数规模的大语言模型,它采用的是 GPT-style 的 decoder-only 的单向自回归模型结构,这种结构对于 few-shot 更有利。PaLM 是使用谷歌提出的 Pathways[10] 系统(一种新的 ML 系统,可以跨多个 TPU Pod 进行高效训练)在 6144 块TPU v4 芯片上训练完成的。作者在 Pod 级别上跨两个 Cloud TPU v4 Pods 使用数据并行对训练进行扩展,与以前的大多数 LLM 相比,是一个显著的规模增长。PaLM 实现了 57.8% 的硬件 FLOPs 利用率的训练效率,是 LLM 在这个规模上实现的最高效率。PaLM 在数百种语言理解和生成 benchmarks 上实现最先进的few-shot 学习结果,证明了scaling 模型的好处。在其中的许多任务中,PaLM 540B 实现了突破性的性能,在一组多步推理任务上的表现优于经过微调的 SOTA 模型。并且大量 BIG-bench 任务显示了模型规模的扩大带来性能的不连续提升,当模型扩展到最大规模,性能急剧提高。
U-PaLM
由于扩大语言模型可以提高性能,但会带来巨大的计算成本。 谷歌提出 UL2R 方法,在几乎可以忽略不计的额外计算成本和没有新数据的情况下,使用原始的预训练数据继续训练 PaLM 模型,能够显着改善大语言模型在下游指标上的扩展特性。使用 UL2R 训练 PaLM,引入了一组 8B、62B 和 540B 规模的新模型,称为 U-PaLM。在 540B 规模下,实现了大约 2 倍的计算节省率,其中 U-PaLM 以大约一半的计算预算实现了与最终 PaLM 540B 模型相同的性能,并且在在许多小样本条件上性能优于 PaLM。
UL2 连接了生成语言模型和双向语言模型,它提出了混合降噪器目标,在同一模型中混合前缀(非因果)语言建模和填充(跨度损坏),并利用模式提示(mode prompts)在下游任务期间切换模式。
OPT
OPT 是由 Meta AI 研究人员发布的一系列大规模预训练语言模型,模型包括125M、350M、1.3B、2.7B、6.7B、13B、30B、66B、175B 9个不同的参数规模和版本,除了 175B 的版本需要填写申请获取外,其它规模版本的模型都完全开放下载,可以免费获得。OPT-175B 和 GPT-3 的性能相当,并且部署只需要损耗 GPT-3 1/7 的能量损耗。OPT 系列模型开源的目的是为促进学术研究和交流,因为绝大多数大语言模型训练成本高昂,导致大部分研究人员都无法负担大语言模型的训练或使用;同时,各大企业发布的大语言预训练模型由于商业目的也都无法完整访问模型权重,只能通过 API 调用获取结果,阻碍了学术的交流与研究。
- Github:metaseq/projects/OPT at main · facebookresearch/metaseq;GitHub - facebookresearch/metaseq: Repo for external large-scale work
LLaMA
LLaMA 是 Meta AI 发布的包含 7B、13B、33B 和 65B 四种参数规模的基础语言模型集合,LLaMA-13B 仅以 1/10 规模的参数在多数的 benchmarks 上性能优于 GPT-3(175B),LLaMA-65B 与业内最好的模型 Chinchilla-70B 和 PaLM-540B 比较也具有竞争力。
这项工作重点关注使用比通常更多的 tokens 训练一系列语言模型,在不同的推理预算下实现最佳的性能,也就是说在相对较小的模型上使用大规模数据集训练并达到较好性能。Chinchilla 论文中推荐在 200B 的 tokens 上训练 10B 规模的模型,而 LLaMA 使用了 1.4T tokens 训练 7B的模型,增大 tokens 规模,模型的性能仍在持续上升。
- Github:https://github.com/facebookrese…
BLOOM
BLOOM 是 BigScience(一个围绕研究和创建超大型语言模型的开放协作研讨会)中数百名研究人员合作设计和构建的 176B 参数开源大语言模型,同时,还开源了BLOOM-560M、BLOOM-1.1B、BLOOM-1.7B、BLOOM-3B、BLOOM-7.1B 其他五个参数规模相对较小的模型。BLOOM 是一种 decoder-only 的 Transformer 语言模型,它是在 ROOTS 语料库上训练的,该数据集包含 46 种自然语言和 13 种编程语言(总共 59 种)的数百个数据来源。 实验证明 BLOOM 在各种基准测试中都取得了有竞争力的表现,在经过多任务提示微调后取得了更好的结果。BLOOM 的研究旨在针对当前大多数 LLM 由资源丰富的组织开发并且不向公众公开的问题,研制开源 LLM 以促进未来使用 LLM 的研究和应用。
- Transformers:https://huggingface.co/bigscien…
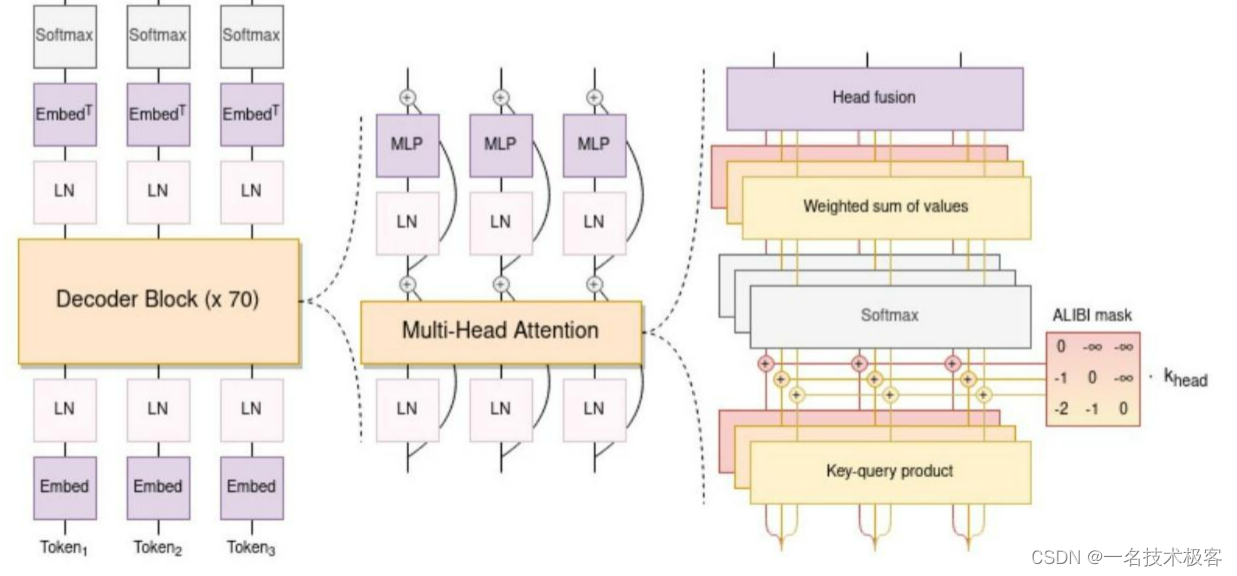
GLM-130B
GLM-130B 是清华大学与智谱AI共同研制的一个开放的双语(英汉)双向密集预训练语言模型,拥有 1300亿个参数,使用通用语言模型(General Language Model, GLM)的算法进行预训练。 2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。GLM-130B 在广泛流行的英文基准测试中性能明显优于 GPT-3 175B(davinci),而对 OPT-175B 和 BLOOM-176B 没有观察到性能优势,它还在相关基准测试中性能始终显著优于最大的中文语言模型 ERNIE 3.0 Titan 260B。GLM-130B 无需后期训练即可达到 INT4 量化,且几乎没有性能损失;更重要的是,它能够在 4×RTX 3090 (24G) 或 8×RTX 2080 Ti (11G) GPU 上有效推理,是使用 100B 级模型最实惠的 GPU 需求。
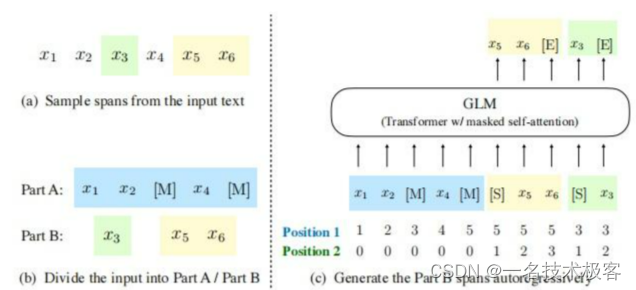
GLM 预训练方式:自回归的空白填充,并通过 GLM 通过添加 2D 位置编码和打乱片段顺序来改进空白填充预训练
- Github:https://github.com/THUDM/GLM-13…
ERNIE 3.0 Titan
ERNIE 3.0 是百度发布的知识增强的预训练大模型,参数规模为 10B。ERNIE 实现了兼顾自然语言理解和自然语言生成的统一预训练框架,使得经过训练的模型可以通过零样本学习、少样本学习或微调轻松地针对自然语言理解和生成任务进行定制。
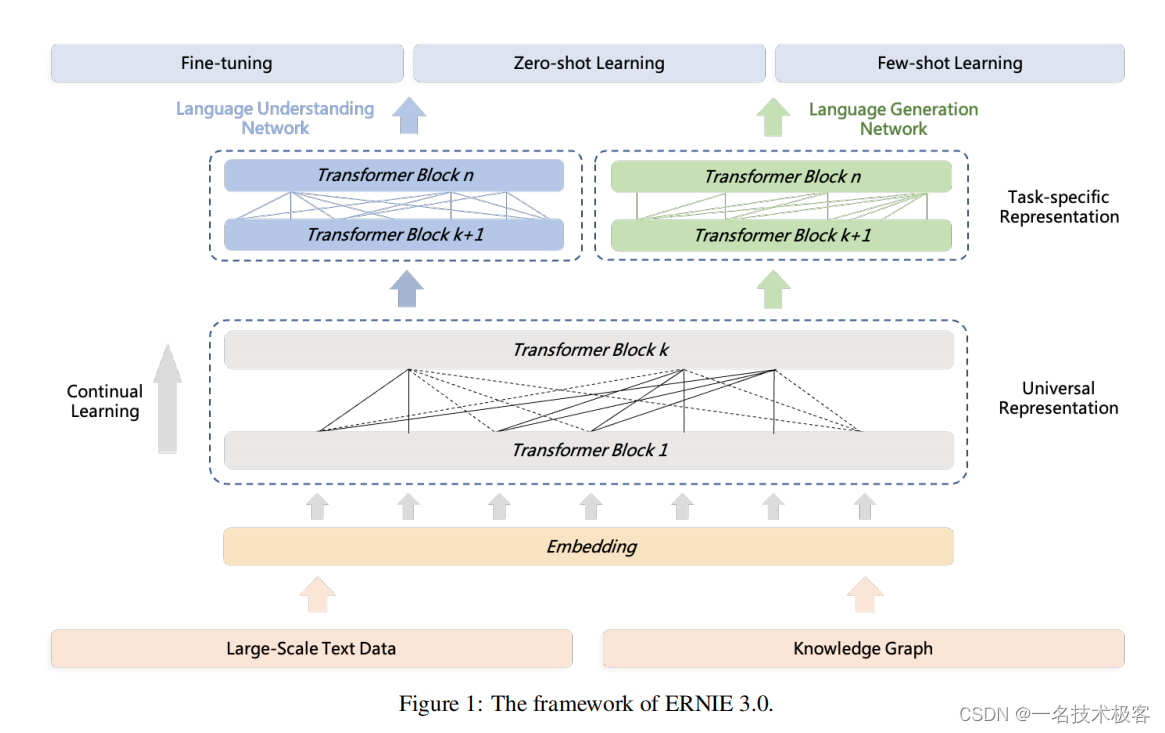
ERNIE 3.0 模型框架:模型包括统一表示模块(Universal Representation Module) 和 两个任务特定的表示模块(Task-specific Representation Modules),即自然语言理解(NLU)表示模块和自然语言生成表示模块(NLG)
ERNIE 3.0 Titan 是百度与鹏城实验室发布的目前为止全球最大的中文单体模型,它是ERNIE 3.0的扩大和升级,模型参数规模达到 260B,相对GPT-3的参数量提升50%。此外,在预训练阶段还设计了一个自监督的对抗性损失和一个可控的语言建模损失,使 ERNIE 3.0 Titan 生成可信和可控的文本(Credible and Controllable Generations)。 为了减少计算开销,ERNIE 3.0 Titan 提出了一个在线蒸馏框架,教师模型将同时教授学生模型和训练自己以更高效地利用计算资源。ERNIE 3.0 Titan 在 68 个 NLP 数据集上的表现优于最先进的模型。
二. Instruction-Finetuned Language Model
这里的 Instruction (指令)是指通过自然语言形式对任务进行描述。如下图所示,对于翻译任务,在对需要翻译的句子 “I Love You.” 前加入任务指令 “Translate the given English utterance to French script.” 告诉模型要执行的任务和要求。这种方式符合模型生成的工作模型,最重要的是对于未知任务具有较好的 zero-shot 性能表现。通过将各种不同的任务转化为指令数据形式,对语言模型进行进一步微调。
下表为经过 Instruction 微调的大模型,他们几乎都是在基础语言模型基础上进行指令微调、人类反馈、对齐等优化操作。
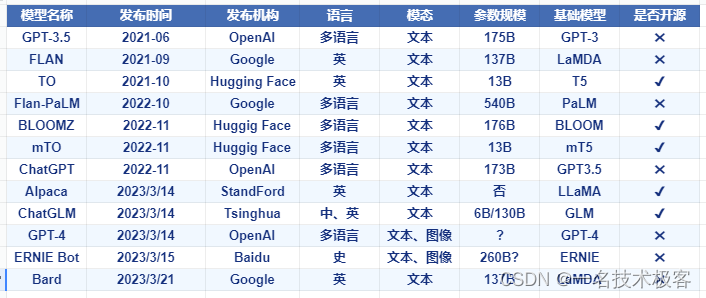
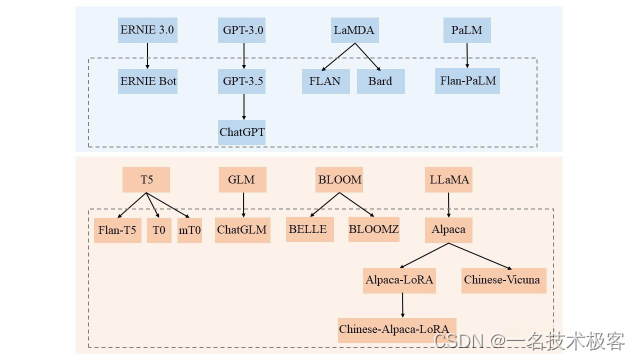
模型关系图,蓝色是未开源,黄色是开源的
T0
T0 是由 Hugging Face 牵头联合 42 位研究人员研发的一个基于 T5 模型在大规模多任务数据集上进行微调得到的模型。该研究的目的是在不需要大幅度扩大模型规模情况下引导模型更好地泛化到未知任务(zero-shot 性能),并且对 prompts 的措辞表达选择与变化更加稳健。研究开发了一个可以将任何自然语言任务映射到人类可读的 prompt 形式的系统, 并转换了大量有监督的数据集,每个数据集都有多个 prompt 和不同的措辞,在这个涵盖各种任务的多任务数据上微调 encoder-decoder 结构的 T5 模型。T0 在多个标准数据集上 zero-shot 性能大幅度超越比其大 16 倍的 GPT-3 模型。
FLAN
FLAN 是谷歌在 LaMDA 137B 模型基础上进行进一步的指令微调(Instruction tuning)得到的模型,通过指令微调提高语言模型在未知任务上的 zero-shot 性能和泛化能力。 zero-shot 实验中 FLAN 在评估的 25 个数据集中的 20 个上超过了 GPT-3 175B。 FLAN 在 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze 上的表现甚至大大优于 few-shot GPT-3。论文的消融实现表明,微调数据集的数量、模型规模和自然语言指令是指令微调成功的关键。
Flan-LM
Flan-LM 是谷歌在其已有的 T5、PaLM、U-PaLM 基础模型基础上利用指令 (Instruction) 数据集微调的一系列语言模型,包括 Flan-T5 (11B)、Flan-PaLM (540B)、Flan-U-PaLM (540B),在指令数据集上微调语言模型可以提高模型性能以及对未知任务的泛化能力。 该工作主要通过扩大模型规模和微调任务数量来研究指令微调 scaling 的效果, 通过整合 Muffiffiffin(80 tasks)、T0-SF(193 tasks)、NIV2(1554 tasks)、CoT (9 tasks) 四个之前的工作将指令微调任务扩大到 1,836 个,同时对 CoT 数据进行微调提升模型的逻辑推理能力。实验证明,指令微调可以显著提高预训练语言模型性能和可用性的通用方法,以及各种提示设置(零样本、少样本、CoT)和评估基准性能,例如,在 1.8K 任务上微调的 Flan-PaLM 540B 指令大大优于 PaLM 540B(平均 +9.4%),并在多个基准测试中实现了最先进的性能。
BLOOMZ & mT0
上述 T0 和 FLAN 等指令微调模型证明了多任务提示微调 (MTF) 可以帮助大模型在 zero-shot 条件下泛化到新任务,并且对 MTF 的探索主要集中在英语数据和模型上。 Hugging Face 将 MTF 应用于预训练的多语言 BLOOM 和 mT5 模型系列,发布了称为 BLOOMZ 和 mT0 的指令微调变体。研究实验中发现在具有英语提示的英语任务上微调多语言大模型可以将任务泛化到仅出现在预训练中的非英语任务;使用英语提示对多语言任务进行微调进一步提高了英语和非英语任务的性能,实现各种最先进的 zero-shot 结果; 论文还研究了多语言任务的微调,这些任务使用从英语翻译的提示来匹配每个数据集的语言,实验发现翻译的提示可以提高相应语言的人工提示的性能。 实验还发现模型能够对它们从未见过的语言任务进行零样本泛化,推测这些模型正在学习与任务和语言无关的更高级别的能力。
GPT-3.5
GPT-3.5 是从 GPT-3 演化来的一些列模型,如下图所示,从初始的 GPT-3 到 GPT-3.5 再到 ChatGPT 是经过了一些列的优化和演进。
- 2020年7月,发布GPT-3,最原始的 GPT-3 基础模型主要有 davinci、curie、ada 和 babbage 四个不同版本,其中 davinci 是功能最强大的,后续也都是基于它来优化的;
- 2021年7月,发布Codex,在代码数据上对 GPT-3 微调得到,对应着 code-davinci-001 和 code-cushman-001 两个模型版本;
- 2022年3月,发布 InstructGPT 论文,对 GPT-3 进行指令微调 (supervised fine-tuning on human demonstrations) 得到 davinci-instruct-beta1 模型;在指令数据和经过标注人员评分反馈的模型生成样例数据上进行微调得到 text-davinci-001,InstructGPT 论文中的原始模型对应着 davinci-instruct-beta;
- 2022年6月,发布 code-davinci-002,是功能最强大的 Codex 型号,在文本和代码数据上进行训练,特别擅长将自然语言翻译成代码和补全代码;
- 2022年6月,发布 text-davinci-002,它是在code-davinci-002 基础上进行有监督指令微调得到;
- 2022年11月,发布 text-davinci-003 和 ChatGP, 它们都是在 text-davinci-002 基础上利用人类反馈强化学习 RLHF 进一步微调优化得到。
ChatGPT
ChatGPT 是在 GPT-3.5 基础上进行微调得到的,微调时使用了从人类反馈中进行强化学习的方法(Reinforcement Learning from Human Feedback,RLHF),这里的人类反馈其实就是人工标注数据,来不断微调 LLM,主要目的是让LLM学会理解人类的命令指令的含义(比如文生成类问题、知识回答类问题、头脑风暴类问题等不同类型的命令),以及让LLM学会判断对于给定的prompt输入指令(用户的问题),什么样的答案输出是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
其实从 GPT-1到 GPT-3.5 可以发现更大的语言模型虽然有了更强的语言理解和生成的能力,但并不能从本质上使它们更好地遵循或理解用户的指令意图。例如,大型语言模型可能会生成不真实、有害或对用户没有帮助的输出,原因在于这些语言模型预测下一个单词的训练目标与用户目标意图是不一致的。为了对齐语言模型于人类意图,ChatGPT展示了一种途径,可以引入人工标注和反馈,通过强化学习算法对大规模语言模型进行微调,在各种任务上使语言模型与用户的意图保持一致,输出人类想要的内容。
GPT-4
GPT-4 是 OpenAI 继 ChatGPT 之后发布的一个大规模的多模态模型,之前的 GPT 系列模型都是只支持纯文本输入输出的语言模型,而 GPT-4 可以接受图像和文本作为输入,并产生文本输出。 GPT-4 仍然是基于 Transformer 的自回归结构的预训练模型。OpenAI 的博客中表示在随意的对话中,GPT-3.5 和 GPT-4 之间的区别可能很微妙,当任务的复杂性达到足够的阈值时,差异就会出现,即 GPT-4 比 GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。虽然在许多现实场景中的能力不如人类,但 GPT-4 在各种专业和学术基准测试中表现出人类水平的表现,包括通过模拟律师考试,得分在应试者的前 10% 左右。 和 ChatGPT RLHF 的方法类似,alignment(对齐)训练过程可以提高模型事实性和对期望行为遵循度的表现,具有强大的意图理解能力,并且对 GPT-4 的安全性问题做了很大的优化和提升。
Alpaca
Alpaca(羊驼)模型是斯坦福大学基于 Meta 开源的 LLaMA-7B 模型微调得到的指令遵循(instruction-following)的语言模型。在有学术预算限制情况下,训练高质量的指令遵循模型主要面临强大的预训练语言模型和高质量的指令遵循数据两个挑战,作者利用 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 的指令遵循样本数据,利用这些数据训练以有监督的方式训练 LLaMA-7B 得到 Alpaca 模型。在测试中,Alpaca 的很多行为表现都与 text-davinci-003 类似,且只有 7B 参数的轻量级模型 Alpaca 性能可与 GPT-3.5 这样的超大规模语言模型性能媲美。
- 博客:https://crfm.stanford.edu/2023/03/13/alpaca.html
- Github:https://github.com/tatsu-lab/stanford_alpaca
Alpaca-LoRA 使用 low-rank adaptation (LoRA) 重现 Alpaca 的结果,并且能够以一块消费级显卡,在几小时内完成 7B 模型的 fine-turning。
Alpaca 主要支持英文任务,因此许多工作在 Alpaca 基础上进一步训练其他语言的模型,比如,韩语羊 KoAlpaca,日语羊驼 Japanese-Alpaca-LoRA。对于中文任务,国内开源了参考 Alpaca 训练方式基于 LLaMA 的 Chinese-Vicuna (小羊驼)模型,以及 Luotuo(骆驼): Chinese-alpaca-lora。
ChatGLM
ChatGLM 是清华大学知识工程(KEG)实验室与其技术成果转化的公司智谱AI基于此前开源的 GLM-130B 千亿基座模型研制,是一个初具问答和对话功能的千亿中英语言模型。ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等技术实现人类意图对齐。
2023年6月14日,开源了62 亿参数的 ChatGLM-6B,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存),虽然规模不及千亿模型,但大大降低了用户部署的门槛,并且已经能生成相当符合人类偏好的回答。
2023年6月25日,二代模型 ChatGLM2-6B 模型开源,更强大的性能(MMLU [+23%]、C-Eval [+33%]、GSM8K [+571%] )、更长的上下文(2K扩展到8K)、更高效的推理(推理速度提升42%)、更开放的开源协议。同时也推出了ChatGLM2-6B、ChatGLM2-12B、ChatGLM2-32B、ChatGLM2-66B、ChatGLM2-130B不同参数规模的模型。
- 博客地址:https://chatglm.cn/blog
ERNIE Bot
EENIE Bot 就是百度的文心一言,基于 ERNIE 系列大模型构建的类 ChatGPT 的对话模型,具体细节不知道…
Bard
Bard 是谷歌基于 LaMDA 研制的对标 ChatGPT 的对话语言模型,目前应该只支持英文对话,限美国和英国用户预约访问,其他未知…
相关文章:
还是了解下吧,大语言模型调研汇总
大语言模型调研汇总 一. Basic Language ModelT5GPT-3LaMDAJurassic-1MT-NLGGopherChinchillaPaLMU-PaLMOPTLLaMABLOOMGLM-130BERNIE 3.0 Titan 二. Instruction-Finetuned Language ModelT0FLANFlan-LMBLOOMZ & mT0GPT-3.5ChatGPTGPT-4AlpacaChatGLMERNIE BotBard 自从Cha…...
Win11初始化系统遇一文解决
这个是目录 一、设置内的初始化无法使用时,使用以下工具二、将桌面移动到D盘三、解决win11桌面右键创建只有一个带盾牌的文件夹问题四、win11 系统停止更新五、office安装1、使用的是 Office Tool plus2、使用WPS 六、D盘有感叹号七、打开组策略编辑器(gpedit.msc)失…...

vr虚拟现实游戏世界介绍|数字文化展览|VR元宇宙文旅
虚拟现实(VR)游戏世界是一种通过虚拟现实技术创建的沉浸式游戏体验,玩家可以穿上VR头显,仿佛置身于游戏中的虚拟世界中。这种技术让玩家能够全方位、身临其境地体验游戏,与游戏中的环境、角色和物体互动。 在虚拟现实游…...

kotlin 程序 编译与执行
准备kotlin环境 Ubuntu安装kotlin 1. 创建一个名为 hello.kt 文件,代码如下: fun main(args: Array<String>) {println("Hello, World!") }2. 使用 Kotlin 编译器编译应用 kotlinc hello.kt -include-runtime -d hello.jar-d: 用来设…...

Python学习:注释和运算符
python 注释 在Python中,注释用于在代码中添加解释、说明或者提醒,但并不会被解释器执行。Python中的注释以#开头,直到行末为止。下面是关于Python注释的详细解释和举例: 单行注释:使用#符号在行的开头添加注释&…...
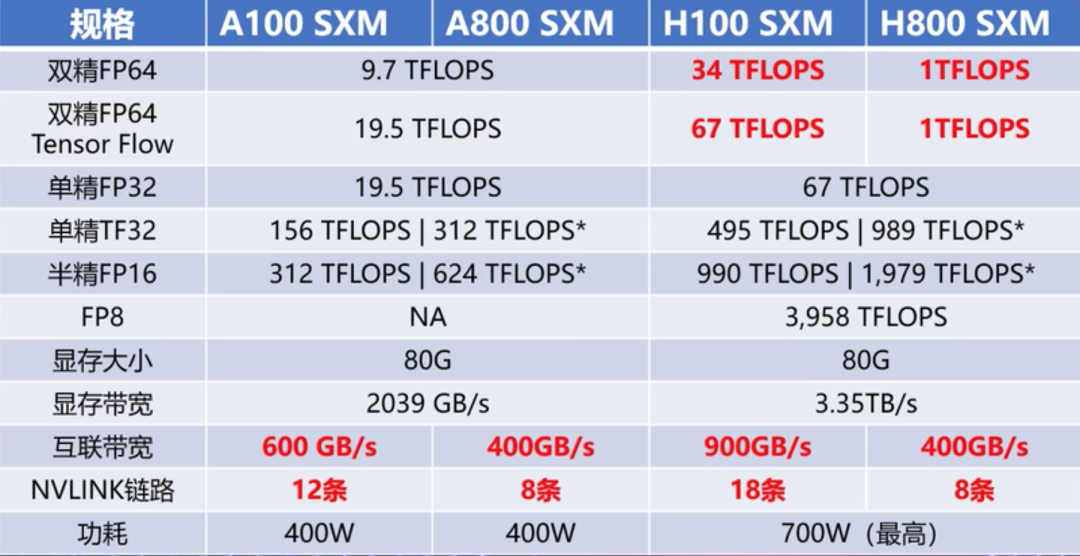
英伟达 V100、A100/800、H100/800 GPU 对比
近期,不论是国外的 ChatGPT,还是国内诸多的大模型,让 AIGC 的市场一片爆火。而在 AIGC 的种种智能表现背后,均来自于堪称天文数字的算力支持。以 ChatGPT 为例,据微软高管透露,为 ChatGPT 提供算力支持的 A…...

Spark面试重点
文章目录 1.简述hadoop 和 spark 的不同点(为什么spark更快)2.谈谈你对RDD的理解3.简述spark的shuffle过程4. groupByKey和reduceByKey的区别 1.简述hadoop 和 spark 的不同点(为什么spark更快) Hadoop 和 Spark 是两种用于大数据…...

UGUI源码分析与研究2-从底层实现的角度去分析和调优UI的性能问题和疑难杂症
从底层实现的角度去分析和调优UI的性能问题和疑难杂症,可以从以下几个方面入手: 绘制性能优化:UI的绘制是一个重要的性能瓶颈,可以通过以下方式进行优化: 减少绘制区域:只绘制可见区域,避免不必…...
OpenAI的GPT已达极限,更看好AI Agent
日前,比尔盖茨发表文章表示:AI Agent不仅会改变人与电脑的互动方式,或许还将颠覆软件行业,引领自输入命令到点击图标以来的最大计算机革命。 在数字化和技术创新的浪潮中,AI Agent作为一种前沿技术,正开启…...

【C/C++】详解 assert() 断言(什么是assert? assert有什么作用?)
目录 一、前言 二、什么是 assert ? 三、assert 的用法 四、assert 案例解析 五、assert 断言的使用原则 六、共勉 一、前言 在编写程序过程中,尤其是调试代码时,往往需要一个提醒代码漏洞/Bug的小助手,以便于程序员及时修改和完善代码…...

[C++]20:unorderedset和unorderedmap结构和封装。
unorderedset和unorderedmap结构和封装 一.哈希表:1.直接定址法:2.闭散列的开放定址法:1.基本结构:2.insert3.find4.erase5.补充:6.pair<k,v> k的数据类型: 3.开散列的拉链法/哈希桶:1.基…...
 B 跳转指令)
ARM 汇编指令:(六) B 跳转指令
目录 一.B 和 BL 1.B/BL指令的语法格式 2.示例解析 一.B 和 BL 跳转指令 B 使程序跳转到指定的地址执行程序。指令 BL 将下一条指令的地址复制到 R14(即返回地址连接寄存器 LR)寄存器中,然后跳转到指定地址运行程序。 1.B/B…...

SQLiteC/C++接口详细介绍之sqlite3类(十一)
返回目录:SQLite—免费开源数据库系列文章目录 上一篇:SQLiteC/C接口详细介绍之sqlite3类(十) 下一篇:SQLiteC/C接口详细介绍之sqlite3类(十二)(未发表) 33.sq…...
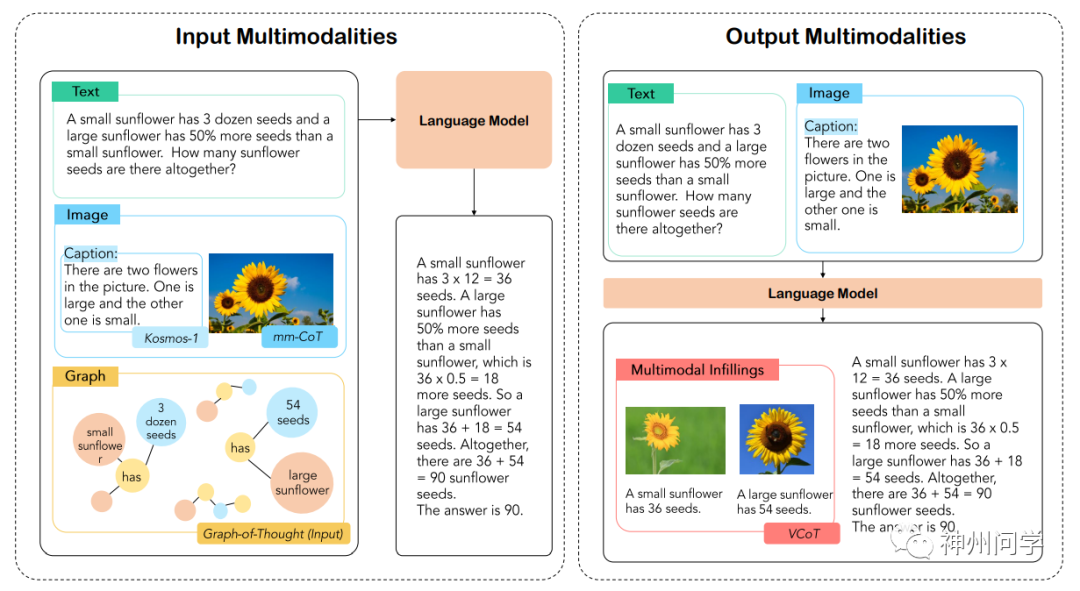
百度智能云+SpringBoot=AI对话【人工智能】
百度智能云SpringBootAI对话【人工智能】 前言版权推荐百度智能云SpringBootAI对话【人工智能】效果演示登录AI对话 项目结构后端开发pom和propertiessql_table和entitydao和mapperservice和implconfig和utilLoginController和ChatController 前端开发css和jslogin.html和chat.…...

第二十七节 Java 多态
本章主要为大家介绍java多态的概念,以及便于理解的多态简单例子。 Java 多态 多态是同一个行为具有多个不同表现形式或形态的能力。 多态性是对象多种表现形式的体现。 比如我们说"宠物"这个对象,它就有很多不同的表达或实现,比…...
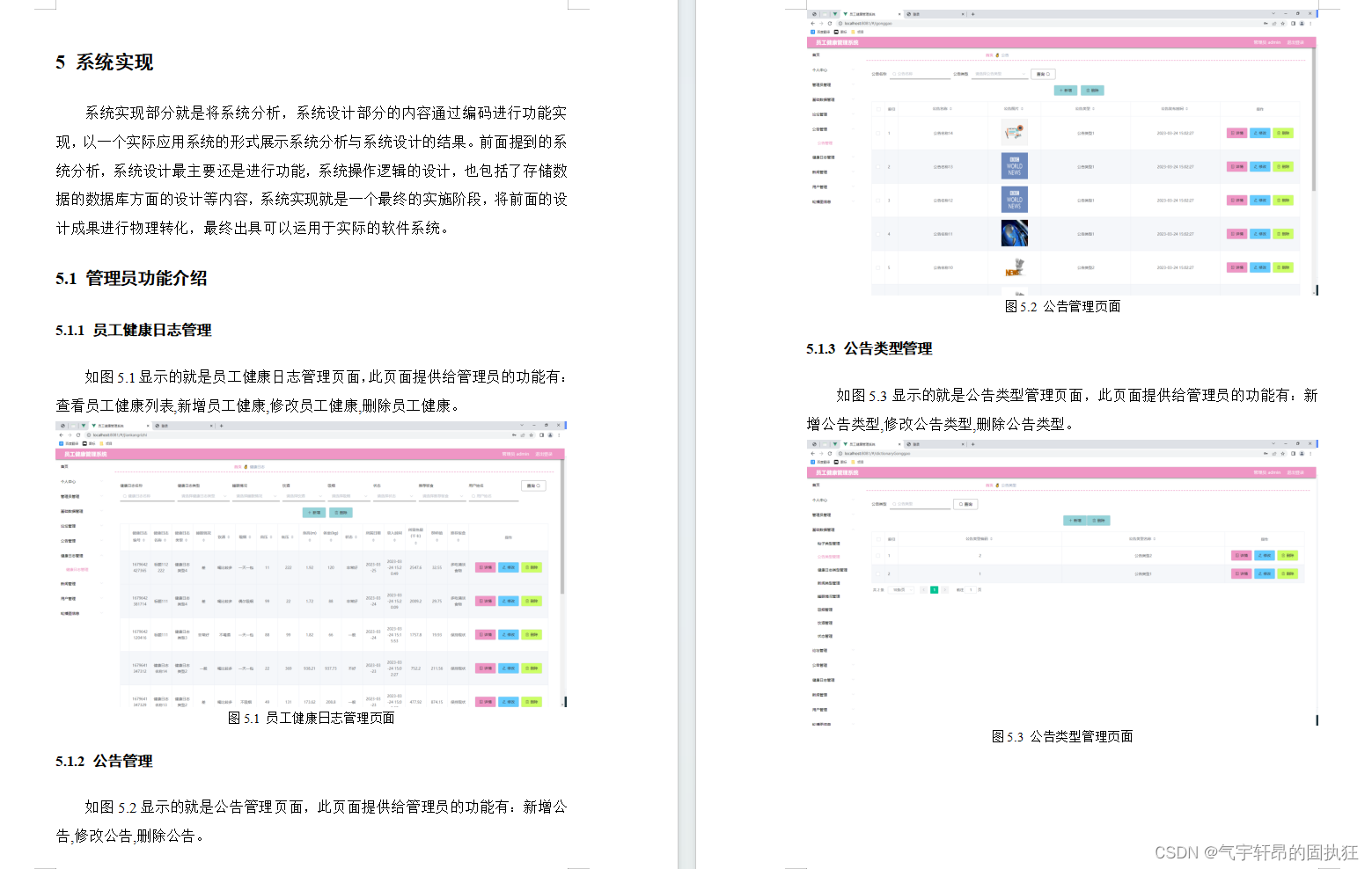
基于Springboot的员工健康管理系统(有报告)。Javaee项目,springboot项目。
演示视频: 基于Springboot的员工健康管理系统(有报告)。Javaee项目,springboot项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构…...

[论文精读]Dynamic Coarse-to-Fine Learning for Oriented Tiny Object Detection
论文网址:[2304.08876] 用于定向微小目标检测的动态粗到细学习 (arxiv.org) 论文代码:https://github.com/ChaselTsui/mmrotate-dcfl 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误&…...

Selenium WebDriver 中用于查找网页元素的两个方法
这里提供了 Selenium WebDriver 中用于查找元素的两个方法:find_element() 和 find_elements()。 find_element(byid, value: Optional[str] None) → selenium.webdriver.remote.webelement.WebElement 这个方法用于查找满足指定定位策略(By strategy&…...

python 常用装饰器
文章目录 property的介绍与使用作用使用场景装饰方法防止属性被修改 实现setter和getter的行为 staticmethod 与 classmethod作用代码示例 两者区别使用区别代码演示 abstractmethod参考资料 property的介绍与使用 python的property是python的一种装饰器,是用来修饰…...

深入解析MySQL日志系统:Binlog、Undo Log和Redo Log
在数据库系统中,日志文件扮演着至关重要的角色,它们不仅保证了数据的完整性和一致性,还支持了数据的恢复、复制和审计等功能。MySQL数据库中最核心的日志系统包括二进制日志(Binlog)、回滚日志(Undo Log&am…...

NVIDIA Container Toolkit失效、nvidia-smi不可见、AI模型加载卡死——Docker AI调试三重门全拆解
第一章:NVIDIA Container Toolkit失效、nvidia-smi不可见、AI模型加载卡死——Docker AI调试三重门全拆解当容器内执行 nvidia-smi 返回 command not found 或空白输出,PyTorch/TensorFlow 加载模型时卡在 torch.cuda.is_available() 或显存分配阶段&…...
)
STM32开发者必看:OpenBLT Bootloader移植避坑指南(Keil环境实战)
STM32开发者必看:OpenBLT Bootloader移植避坑指南(Keil环境实战) 在嵌入式系统开发中,Bootloader的重要性不言而喻。它不仅是系统启动的第一道关卡,更是实现远程固件升级的关键组件。对于STM32开发者而言,O…...

026、灾难性遗忘与持续学习:大模型如何学习新知识不忘旧技能
026、灾难性遗忘与持续学习:大模型如何学习新知识不忘旧技能 上周在部署一个客服模型升级时,我们踩了个典型的坑:用新领域的对话数据微调后,模型在新任务上表现亮眼,却把原来的产品问答能力忘得一干二净。用户问“怎么重置密码”,模型开始大谈特谈新学的保险理赔流程。团…...

国产事件相机CeleX5深度评测:1.6万预算下的科研利器到底值不值?
国产事件相机CeleX5深度评测:1.6万预算下的科研利器到底值不值? 在计算机视觉和机器人研究领域,事件相机正逐渐成为突破传统帧率限制的新兴传感器。不同于传统相机以固定帧率捕获图像,事件相机通过异步像素级响应记录光强变化&…...

从棋盘格到3D坐标:一文搞懂相机内参/外参/畸变参数在Ubuntu+ROS下的标定原理与实战
从棋盘格到3D坐标:深度解析相机标定参数体系与ROS实战应用 当我们需要让机器"看见"并理解三维世界时,相机标定就像是为机器视觉系统配上一副精准的眼镜。想象一下,当你戴上度数不匹配的眼镜时,世界会变得扭曲模糊——未…...

Mac Mouse Fix终极实战指南:从普通鼠标到专业级触控板体验
Mac Mouse Fix终极实战指南:从普通鼠标到专业级触控板体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是一款革命…...

LeaguePrank:5分钟打造你的专属英雄联盟形象
LeaguePrank:5分钟打造你的专属英雄联盟形象 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank LeaguePrank是一款基于英雄联盟官方LCU API开发的游戏个性化工具,让你在不影响账号安全的前提下,…...

终极指南:如何一键恢复B站经典界面,重温小电视播放器的美好时代
终极指南:如何一键恢复B站经典界面,重温小电视播放器的美好时代 【免费下载链接】Bilibili-Old 恢复旧版Bilibili页面,为了那些念旧的人。 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Old 你是否怀念那个简洁明了的B站界面…...
 函数5分钟搞定子串匹配(附完整代码))
别再暴力循环了!C++ string.find() 函数5分钟搞定子串匹配(附完整代码)
别再暴力循环了!C string.find() 函数5分钟搞定子串匹配(附完整代码) 在初学C或刷算法题时,字符串处理往往是第一个让人头疼的坎。特别是当遇到"验证子串"这类基础问题时,很多人的第一反应是写双重循环逐个字…...

LiveEventBus安全与混淆配置:保护Android应用数据与代码的终极指南
LiveEventBus安全与混淆配置:保护Android应用数据与代码的终极指南 【免费下载链接】LiveEventBus :mailbox_with_mail:EventBus for Android,消息总线,基于LiveData,具有生命周期感知能力,支持Sticky,支持…...