目标检测---IOU计算详细解读(IoU、GIoU、DIoU、CIoU、EIOU、Focal-EIOU、SIOU、WIOU)

常见IoU解读与代码实现
- 一、✒️IoU(Intersection over Union)
- 1.1 🔥IoU原理
- ☀️ 优点
- ⚡️缺点
- 1.2 🔥IoU计算
- 1.3 📌IoU代码实现
- 二、✒️GIoU(Generalized IoU)
- 2.1 GIoU原理
- ☀️优点
- ⚡️缺点
- 2.2 🔥GIoU计算
- 2.3 📌GIoU代码实现
- 三、✒️DIoU(Distance-IoU)
- 3.1 DIoU原理
- ☀️优点
- ⚡️缺点
- 3.2 DIoU计算
- 3.3 📌DIoU代码实现
- 四、✒️CIoU(Complete-IoU)
- 4.1 CIoU原理
- ☀️优点
- ⚡️缺点
- 4.2 CIoU计算
- 4.3 📌CIoU代码实现
- 五、✒️EIOU(Efficient-IoU)
- 5.1原理
- 5.2 代码实现
- 六、✒️Focal-EIOU
- 6.1 原理
- ☀️优点
- ⚡️缺点
- 📌6.2 代码实现
- 七、✒️SIOU(Soft Intersection over Union)
- 7.1原理
- 八、✒️Wise-IoU
一、✒️IoU(Intersection over Union)
1.1 🔥IoU原理
🚀交并比(IoU, Intersection over Union)是一种计算不同图像相互重叠比例的算法,经常被用于深度学习领域的目标检测或语义分割任务中。
在我们得到模型输出的预测框位置后,也可以计算输出框与真实框(Ground Truth Bound)之间的 IoU,此时,这个框的取值范围为 0~1,0 表示两个框不相交,1 表示两个框正好重合。
1-IOU 表示真实框与预测框之间的差异,如果用 1-IOU,这时的取值范围还是 0~1,但是变成了 0 表示两个框重合,1 表示两个框不相交,这样也就符合了模型自动求极小值的要求。因此,可以使用1-IOU来表示模型的损失函数(Loss 函数)。
🎯IoU 的定义如下:

✨直观来讲,IoU 就是两个图形面积的交集和并集的比值

☀️ 优点
使用IoU来计算预测框和目标框之间的损失有以下优点:
- 具有尺度不变性;
- 满足非负性;
- 满足对称性;
⚡️缺点
如果只使用IoU交并比来计算目标框损失的话会有以下问题:
- 预测框与真实框之间不相交的时候,如果|A∩B|=0,IOU=0,无法进行梯度计算;
- 相同的IOU反映不出实际预测框与真实框之间的情况,虽然这三个框的IoU值相等,但是预测框与真实框之间的相对位置却完全不一样;

也就是说,IoU 初步满足了计算两个图像的几何图形相似度的要求,简单实现了图像重叠度的计算,但无法体现两个图形之间的距离以及图形长宽比的相似性。
1.2 🔥IoU计算
上面介绍了IoU原理,下面是IoU简单计算的原理图,我们需要先计算出相交部分黄色的面积,然后再计算蓝框的面积与绿框围成面积的总和,然后计算两者的比值,如下:假设一个格子的面积是1,交集黄色部分的面积为2x2=4,蓝框与绿框围成面积总和为3x3+4x4-2x2=21,所以IOU=4/21=0.19;

在代码中并不是采用上面的计算方法,而是使用坐标进行计算,如下图,矩形 AC 与矩形 BD 相交,它们的顶点A、B、C、D,分别是:A(0,0)、B(3,2)、C(6,8)、D(9,10)

📟此时 IoU 的计算公式应为:

带入 A、B、C、D 四点的实际坐标后,可以得到:

1.3 📌IoU代码实现
import numpy as npdef IoU(box1, box2):# 计算中间矩形的宽高in_w = min(box1[2], box2[2]) - max(box1[0], box2[0])in_h = min(box1[3], box2[3]) - max(box1[1], box2[1])# 计算交集、并集面积inter = 0 if in_w <= 0 or in_h <= 0 else in_h * in_wunion = (box2[2] - box2[0]) * (box2[3] - box2[1]) +\(box1[2] - box1[0]) * (box1[3] - box1[1]) - inter# 计算IoUiou = inter / unionreturn iouif __name__ == "__main__":box1 = [0, 0, 6, 8] # [左上角x坐标,左上角y坐标,右下角x坐标,右下角y坐标]box2 = [3, 2, 9, 10]print(IoU(box1, box2))运行结果:
0.23076923076923078
二、✒️GIoU(Generalized IoU)
2.1 GIoU原理
📜 CVPR2019中论文《Generalized Intersection over Union: A Metric and A Loss for Bounding BoxRegression》提出了GIOU的思想。
GIoU(Generalized Intersection over Union) 相较于 IoU 多了一个“Generalized”,通过引入预测框和真实框的最小外接矩形来获取预测框、真实框在闭包区域中的比重,从而解决了两个目标没有交集时梯度为零的问题。
引入了最小封闭形状C (可以把A,B包含在内)

公式定义如下:

其中C是两个框的最小外接矩形的面积。原有 IoU 取值区间为 [0,1],而 GIoU 的取值区间为[-1,1] ;在两个图像完全重叠时IoU=GIoU=1,当两个图像不相交的时候IoU=0,GIOU=-1;
☀️优点
- 与IoU只关注重叠区域不同,GIOU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度;
- GIOU是一种IoU的下界,取值范围[ − 1 , 1 ] 。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1。因此,与IoU相比,GIoU是一个比较好的距离度量指标,解决了不重叠情况下,也就是IOU=0的情况,也能让训练继续进行下去。
⚡️缺点
但是目标框与预测框重叠的情况依旧无法判断:

2.2 🔥GIoU计算
上面我们已经计算出IOU的值,这里还需要计算由AD构成C的面积,也就是9x10=90;由GIOU公式可以计算出:


2.3 📌GIoU代码实现
import numpy as npdef GIoU(box1, box2):# 计算两个图像的最小外接矩形的面积x1, y1, x2, y2 = box1x3, y3, x4, y4 = box2area_c = (max(x2, x4) - min(x1, x3)) * (max(y4, y2) - min(y3, y1))# 计算中间矩形的宽高in_w = min(box1[2], box2[2]) - max(box1[0], box2[0])in_h = min(box1[3], box2[3]) - max(box1[1], box2[1])# 计算交集、并集面积inter = 0 if in_w <= 0 or in_h <= 0 else in_h * in_wunion = (box2[2] - box2[0]) * (box2[3] - box2[1]) + \(box1[2] - box1[0]) * (box1[3] - box1[1]) - inter# 计算IoUiou = inter / union# 计算空白面积blank_area = area_c - union# 计算空白部分占比blank_count = blank_area / area_cgiou = iou - blank_countreturn giouif __name__ == "__main__":box1 = [0, 0, 6, 8]box2 = [3, 2, 9, 10]print(GIoU(box1, box2))输出结果:
0.09743589743589745
三、✒️DIoU(Distance-IoU)
3.1 DIoU原理
🔥该原理是在19年⽂章Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression提出的
基于IoU和GIoU存在的问题,作者提出了两个问题:
- 直接最⼩化anchor框与⽬标框之间的归⼀化距离是否可⾏,以达到更快的收敛速度?
- 如何使回归在与⽬标框有重叠甚⾄包含时更准确、更快?
GIoU 虽然解决了 IoU 的一些问题,但是它并不能直接反映预测框与目标框之间的距离,DIoU(Distance-IoU)即可解决这个问题,它将两个框之间的重叠度、距离、尺度都考虑了进来,使得⽬标框回归变得更加稳定。DIoU的计算公式如下:

其中、b和bgt分别表示预测框与真实框的中心点坐标,p2(b,bgt)表示两个中心点的欧式距离(指在欧几里得空间中两点之间的距离),C 代表两个图像的最小外接矩形的对角线长度。

☀️优点
DIoU 相较于其他两种计算方法的优点是:
- DIoU 可直接最小化两个框之间的距离,所以作为损失函数时 Loss 收敛更快。
- 与GIoU loss类似,DIoU loss在与⽬标框不重叠时,仍然可以为边界框提供移动⽅向。
- 在两个框完全上下排列或左右排列时,没有空白区域,此时 GIoU 几乎退化为了 IoU,但是 DIoU 仍然有效。
- DIOU还可以替换普通的IOU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。

⚡️缺点
DIoU 在完善图像重叠度的计算功能的基础上,实现了对图形距离的考量,但仍无法对图形长宽比的相似性进行很好的表示。
3.2 DIoU计算
通过计算可得,中心点 b、中心点 bgt的坐标分别为:(3,4)、(6,6)

此时的 DIoU 计算公式为:

3.3 📌DIoU代码实现
import numpy as npdef calculate_diou(box1, box2):# 计算两个图像的最小外接矩形的面积x1, y1, x2, y2 = box1x3, y3, x4, y4 = box2area_c = (max(x2, x4) - min(x1, x3)) * (max(y4, y2) - min(y3, y1))# 计算中间矩形的宽高in_w = min(box1[2], box2[2]) - max(box1[0], box2[0])in_h = min(box1[3], box2[3]) - max(box1[1], box2[1])# 计算交集、并集面积inter = 0 if in_w <= 0 or in_h <= 0 else in_h * in_wunion = (box2[2] - box2[0]) * (box2[3] - box2[1]) + \(box1[2] - box1[0]) * (box1[3] - box1[1]) - inter# 计算IoUiou = inter / union# 计算中心点距离的平方center_dist = np.square((x1 + x2) / 2 - (x3 + x4) / 2) + \np.square((y1 + y2) / 2 - (y3 + y4) / 2)# 计算对角线距离的平方diagonal_dist = np.square(max(x1, x2, x3, x4) - min(x1, x2, x3, x4)) + \np.square(max(y1, y2, y3, y4) - min(y1, y2, y3, y4))# 计算DIoUdiou = iou - center_dist / diagonal_distreturn dioubox1 = [0, 0, 6, 8]
box2 = [3, 2, 9, 10]
print(calculate_diou(box1, box2))输出结果:
0.1589460263493413
四、✒️CIoU(Complete-IoU)
4.1 CIoU原理
📜 AAAI 2020(与DIOU同一篇文章) 论文链接:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
论⽂考虑到bbox回归三要素中的⻓宽⽐还没被考虑到计算中,为此,进⼀步在DIoU的基础上提出了CIoU,同时考虑两个矩形的长宽比,也就是形状的相似性。所以CIOU在DIOU的基础上添加了长宽比的惩罚项。

其中, α \alpha α 是权重函数, ν \nu ν而用来度量长宽比的相似性。计算公式为:

☀️优点
- 更准确的相似性度量:CIOU考虑了边界框的中心点距离和对角线距离,因此可以更准确地衡量两个边界框之间的相似性,尤其是在目标形状和大小不规则的情况下。
- 鲁棒性更强:相比传统的IoU,CIOU对于目标形状和大小的变化更具有鲁棒性,能够更好地适应各种尺寸和形状的目标检测任务。
⚡️缺点
- 计算复杂度增加:CIOU引入了额外的中心点距离和对角线距离的计算,因此相比传统的IoU,计算复杂度有所增加,可能会增加一定的计算成本。
- 实现难度较高:CIOU的计算方式相对复杂,需要对边界框的坐标进行更多的处理和计算,因此在实现上可能会相对困难一些,需要更多的技术和经验支持。
4.2 CIoU计算
中心点 b、中心点 bgt的坐标分别为:(3,4)、(6,6),由此CIoU计算公式如下:

4.3 📌CIoU代码实现
import numpy as np
import IoU
import DIoU
# box : [左上角x坐标,左上角y坐标,右下角x坐标,右下角y坐标]
box1 = [0, 0, 6, 8]
box2 = [3, 2, 9, 10]
# CIoU
def CIoU(box1, box2):x1, y1, x2, y2 = box1x3, y3, x4, y4 = box2# box1的宽:box1_w,box1的高:box1_h,box1_w = x2 - x1box1_h = y2 - y1# box2的宽:box2_w,box2的高:box2_h,box2_w = x4 - x3box2_h = y4 - y3iou = IoU(box1, box2)diou = DIoU(box1, box2)# v用来度量长宽比的相似性v = (4 / (np.pi) ** 2) * (np.arctan(int(box2_w / box2_h)) - np.arctan(int(box1_w / box1_h)))# α是权重函数a = v / ((1 + iou) + v)ciou = diou - a * vreturn ciouprint(CIoU(box1, box2))
输出结果:
0.1589460263493413
五、✒️EIOU(Efficient-IoU)
5.1原理
📜发表在arXiv2022年:《Focal and Efficient IOU Loss for Accurate Bounding Box Regression》上的论文
EIOU是在 CIOU 的惩罚项基础上将预测框和真实框的纵横比的影响因子拆开,分别计算预测框和真实框的长和宽,并且加入Focal聚焦优质的锚框,来解决 CIOU 存在的问题。先前基于iou的损失,例如CIOU和GIOU,不能有效地测量目标盒和锚点之间的差异,这导致BBR(边界框回归)模型优化的收敛速度慢,定位不准确。

针对上述问题,对CIOU损失进行了修正,提出了一种更有效的IOU损失,即EIOU损失,定义如下:

其中wc和hc是覆盖两个盒子的最小围框的宽度和高度。也就是说,我们将损失函数分为三个部分:IOU损失LIOU,距离损失Ldis和方向损失Lasp。这样,我们可以保留CIOU损失的有效特点。同时,EIOU损失直接使目标盒与锚盒宽度和高度的差值最小化,从而使收敛速度更快,定位效果更好。
5.2 代码实现
import numpy as npdef calculate_eiou(box1, box2):# 计算嵌入向量(这里简化为使用中心点坐标作为嵌入向量)center1 = np.array([(box1[0] + box1[2]) / 2, (box1[1] + box1[3]) / 2])center2 = np.array([(box2[0] + box2[2]) / 2, (box2[1] + box2[3]) / 2])# 计算嵌入向量之间的欧式距离euclidean_distance = np.linalg.norm(center1 - center2)# 计算目标框的面积area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])# 计算交集和并集的面积intersection = max(0, min(box1[2], box2[2]) - max(box1[0], box2[0])) * \max(0, min(box1[3], box2[3]) - max(box1[1], box2[1]))union = area_box1 + area_box2 - intersection# 计算EIOUeiou = 1 - intersection / union + euclidean_distancereturn eioubox1 = [0, 0, 6, 8]
box2 = [3, 2, 9, 10]
print(calculate_eiou(box1, box2))输出结果
4.374782044694758
六、✒️Focal-EIOU
6.1 原理
🔥高质量的 anchor 总是比低质量的 anchor 少很多,这也对训练过程有害无利。所以,需要研究如何让高质量的 anchor 起到更大的作用。
贡献:
- 总结了现有回归 loss 的问题:最重要的是没有直接优化需要优化的参数
- 提出了现有方法收敛速度较慢的问题,很多的低质量样本贡献了大部分的梯度,限制了框的回归
- 提出了 Focal-EIoU,平衡高质量样本和低质量样本对 loss 的贡献,也就是提升高质量(IoU 大)样本的贡献,抑制低质量(IoU 小)样本的贡献
简单的方法不能直接适用于基于IOU的损失。因此,我们最后提出Focal-EIOU损失来改善EIOU损失的性能。使用IOU的值来重新加权EIOU损失,并获得Focal-EIOU损失,通过对难以分类的样本进行更加重视的损失函数设计,从而进一步提高目标检测算法的性能。如下所示:

其中 γ \gamma γ为控制异常值抑制程度的参数。该损失中的Focal与传统的Focal Loss有一定的区别,传统的Focal Loss针对越困难的样本损失越大,起到的是困难样本挖掘的作用;而根据上述公式:IOU越高的损失越大,相当于加权作用,给越好的回归目标一个越大的损失,有助于提高回归精度。
☀️优点
- EIOU在CIOU的基础上分别计算宽高的差异值取代了纵横比,宽高损失直接使预测框与真实框的宽度和高度之差最小,使得收敛速度更快;
- 在处理难以分类的样本时表现更好,能够进一步提高目标检测算法的鲁棒性和准确性。
⚡️缺点
在一般情况下可能会增加一定的计算复杂度,同时需要更多的参数调优和训练策略设计。
📌6.2 代码实现
import numpy as npdef calculate_focal_eiou(box1, box2, alpha=0.25, gamma=2):# 计算嵌入向量(这里简化为使用中心点坐标作为嵌入向量)center1 = np.array([(box1[0] + box1[2]) / 2, (box1[1] + box1[3]) / 2])center2 = np.array([(box2[0] + box2[2]) / 2, (box2[1] + box2[3]) / 2])# 计算嵌入向量之间的欧式距离euclidean_distance = np.linalg.norm(center1 - center2)# 计算目标框的面积area_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])area_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])# 计算交集和并集的面积intersection = max(0, min(box1[2], box2[2]) - max(box1[0], box2[0])) * \max(0, min(box1[3], box2[3]) - max(box1[1], box2[1]))union = area_box1 + area_box2 - intersection# 计算Focal Lossiou = intersection / unionfocal_loss = -alpha * (1 - iou) ** gamma# 计算Focal-EIOUfocal_eiou = 1 - iou + euclidean_distance + focal_lossreturn focal_eioubox1 = [0, 0, 6, 8]
box2 = [3, 2, 9, 10]
print(calculate_focal_eiou(box1, box2))输出结果:
4.2268530506119175
七、✒️SIOU(Soft Intersection over Union)
7.1原理
📜论文链接:《More Powerful Learning for Bounding Box Regression》
该论文中提出了一种新的损失函数 SIoU,其中考虑到所需回归之间的向量角度,重新定义了惩罚指标。应用于传统的神经网络和数据集,表明 SIoU 提高了训练的速度和推理的准确性。
在许多模拟和测试中揭示了所提出的损失函数的有效性。特别是,将 SIoU 应用于 COCO-train/COCO-val 与其他损失函数相比,提高了 +2.4% (mAP@0.5:0.95) 和 +3.6%(mAP@0.5)。
SIoU损失函数由4个Cost代价函数组成:
- Angle cost
- Distance cost
- Shape cost
- IoU cost
➤ Angle cost(角度代价)
如果 α \alpha α<=45°的时候,需要先最小化 α \alpha α;如果 α \alpha α>45°,则需要最小化 β \beta β=90°- α \alpha α,从公式化简之后的结果可以得出,如果预测框和真实框沿着x轴或者y轴对齐的时候,此时 ⋀ \bigwedge ⋀=0,如果中心点角度为45°的时候,此时 ⋀ \bigwedge ⋀=1;

论文中计算公式:
Λ = 1 − 2 ∗ sin 2 ( arcsin ( x ) − π 4 ) \Lambda=1-2 * \sin ^2\left(\arcsin (x)-\frac{\pi}{4}\right) Λ=1−2∗sin2(arcsin(x)−4π)
x = c h σ = sin ( α ) σ = ( b c x g t − b c x ) 2 + ( b c y g t − b c y ) 2 c h = max ( b c y g t , b c y ) − min ( b c y g t , b c y ) \begin{gathered}x=\frac{c_h}{\sigma}=\sin (\alpha) \\ \sigma=\sqrt{\left(b_{c_x}^{g t}-b_{c_x}\right)^2+\left(b_{c_y}^{g t}-b_{c_y}\right)^2} \\ c_h=\max \left(b_{c_y}^{g t}, b_{c_y}\right)-\min \left(b_{c_y}^{g t}, b_{c_y}\right)\end{gathered} x=σch=sin(α)σ=(bcxgt−bcx)2+(bcygt−bcy)2ch=max(bcygt,bcy)−min(bcygt,bcy)
可以将x和 α \alpha α的值带入公式进行化简,其中 C h C_h Ch 为真实框和预测框中心点的高度差, σ \sigma σ 为真实框和预测框中心点的距离。
Λ = 1 − 2 ∗ sin 2 ( arcsin ( C h σ ) − π 4 ) = 1 − 2 ∗ sin 2 ( α − π 4 ) = cos 2 ( α − π 4 ) − sin 2 ( α − π 4 ) = cos ( 2 α − π 2 ) = sin ( 2 α ) \begin{aligned} & \Lambda=1-2 * \sin ^2\left(\arcsin \left(\frac{C_h}{\sigma}\right)-\frac{\pi}{4}\right) \\ & =1-2 * \sin ^2\left(\alpha-\frac{\pi}{4}\right) \\ & =\cos ^2\left(\alpha-\frac{\pi}{4}\right)-\sin ^2\left(\alpha-\frac{\pi}{4}\right) \\ & =\cos \left(2 \alpha-\frac{\pi}{2}\right) \\ & =\sin (2 \alpha)\end{aligned} Λ=1−2∗sin2(arcsin(σCh)−4π)=1−2∗sin2(α−4π)=cos2(α−4π)−sin2(α−4π)=cos(2α−2π)=sin(2α)
➤ Distance cost(距离成本)
真实值边界框与边界框预测值之间距离的计算方案。

根据上面定义的角度成本重新定义距离成本:
Δ = ∑ t = x , y ( 1 − e − γ ρ t ) \Delta=\sum_{t=x, y}\left(1-e^{-\gamma \rho_t}\right) Δ=t=x,y∑(1−e−γρt)
where
ρ x = ( b c x g t − b c x c w ) 2 , ρ y = ( b c y g t − b c y c h ) 2 , γ = 2 − Λ \rho_x=\left(\frac{b_{c_x}^{g t}-b_{c_x}}{c_w}\right)^2, \rho_y=\left(\frac{b_{c_y}^{g t}-b_{c_y}}{c_h}\right)^2, \gamma=2-\Lambda ρx=(cwbcxgt−bcx)2,ρy=(chbcygt−bcy)2,γ=2−Λ
当 α → 0 \alpha \rightarrow 0 α→0,距离成本的贡献大大减少.与之相反 α \alpha α 越接近 π 4 \frac{\pi}{4} 4π, Δ \Delta Δ就越大,随着角度的增加,问题变得更加困难。 所以,随着角度的增加 γ \gamma γ 的时间优先于距离值。当 α → 0 \alpha \rightarrow 0 α→0,距离成本将变为常规成本。
➤ Shape cost(形状成本)
形状成本定义为:
Ω = ∑ t = w , h ( 1 − e − ω t ) θ \Omega=\sum_{t=w, h}\left(1-e^{-\omega_t}\right)^\theta Ω=t=w,h∑(1−e−ωt)θ
其中:
ω w = ∣ w − w g t ∣ max ( w , w g t ) , ω h = ∣ h − h g t ∣ max ( h , h g t ) \omega_w=\frac{\left|w-w^{g t}\right|}{\max \left(w, w^{g t}\right)}, \omega_h=\frac{\left|h-h^{g t}\right|}{\max \left(h, h^{g t}\right)} ωw=max(w,wgt)∣w−wgt∣,ωh=max(h,hgt)∣h−hgt∣
𝜃 的值定义了形状的成本,并且其值对于每个数据集都是唯一的。 𝜃 的值是这个方程中非常重要的一项,它控制着对形状成本的关注程度。如果𝜃的值设置为1,它将立即优化形状,从而损害形状的自由运动。为了计算 𝜃 的值,对每个数据集使用遗传算法,实验上 𝜃 的值接近 4,作者为此参数定义的范围是从 2 到 6。
➤ SIOU最后的回归损失为:
L b o x = 1 − I o U + Δ + Ω 2 L_{b o x}=1-I o U+\frac{\Delta+\Omega}{2} Lbox=1−IoU+2Δ+Ω
八、✒️Wise-IoU
论文摘要:
📜近年来的研究大多假设训练数据中的示例有较高的质量,致力于强化边界框损失的拟合能力。但我们注意到目标检测训练集中含有低质量示例,如果一味地强化边界框对低质量示例的回归,显然会危害模型检测性能的提升。Focal-EIoU v1 被提出以解决这个问题,但由于其聚焦机制是静态的,并未充分挖掘非单调聚焦机制的潜能。基于这个观点,我们提出了动态非单调的聚焦机制,设计了 Wise-IoU (WIoU)。动态非单调聚焦机制使用“离群度”替代 IoU 对锚框进行质量评估,并提供了明智的梯度增益分配策略。该策略在降低高质量锚框的竞争力的同时,也减小了低质量示例产生的有害梯度。这使得 WIoU 可以聚焦于普通质量的锚框,并提高检测器的整体性能。将WIoU应用于最先进的单级检测器 YOLOv7 时,在 MS-COCO 数据集上的 AP-75 从 53.03% 提升到 54.50%
关于Wise-IoU的详细介绍可以观看这篇论文:Wise-IoU 作者导读:基于动态非单调聚焦机制的边界框损失
WIOU主要有以下几点优势:
- 相对面积加权
Wiou损失函数的计算中引入了交集与并集的比值,从而对不同大小的目标框进行了相对面积加权。这样可以避免小目标对损失函数的影响过大,提升了对小目标的检测效果。 - 解决类别不平衡问题
在目标检测任务中,经常会遇到类别不平衡的情况,即某些类别的目标数量明显少于其他类别。Wiou损失函数通过引入权重因子,可以对不同类别的目标进行不同程度的加权,从而解决了类别不平衡问题。 - 高度可定制化
Wiou损失函数的计算中,可以根据实际需求调整交集和并集的权重因子,从而对不同任务和数据集进行高度定制化的适配。这使得Wiou损失函数在实际应用中具有更广泛的适用性。
相关文章:
目标检测---IOU计算详细解读(IoU、GIoU、DIoU、CIoU、EIOU、Focal-EIOU、SIOU、WIOU)
常见IoU解读与代码实现 一、✒️IoU(Intersection over Union)1.1 🔥IoU原理☀️ 优点⚡️缺点 1.2 🔥IoU计算1.3 📌IoU代码实现 二、✒️GIoU(Generalized IoU)2.1 GIoU原理☀️优点⚡️缺点 2…...

探索并发编程:深入理解线程池
文章目录 前言一、线程池是什么?二、如何创建线程池1.使用Executors类2.使用ThreadPoolExecutor类手动配置线程池 总结 前言 随着计算机系统的不断发展和进步,我们需要处理更多的并发任务和复杂的操作。而线程池作为一种高效的线程管理机制,…...
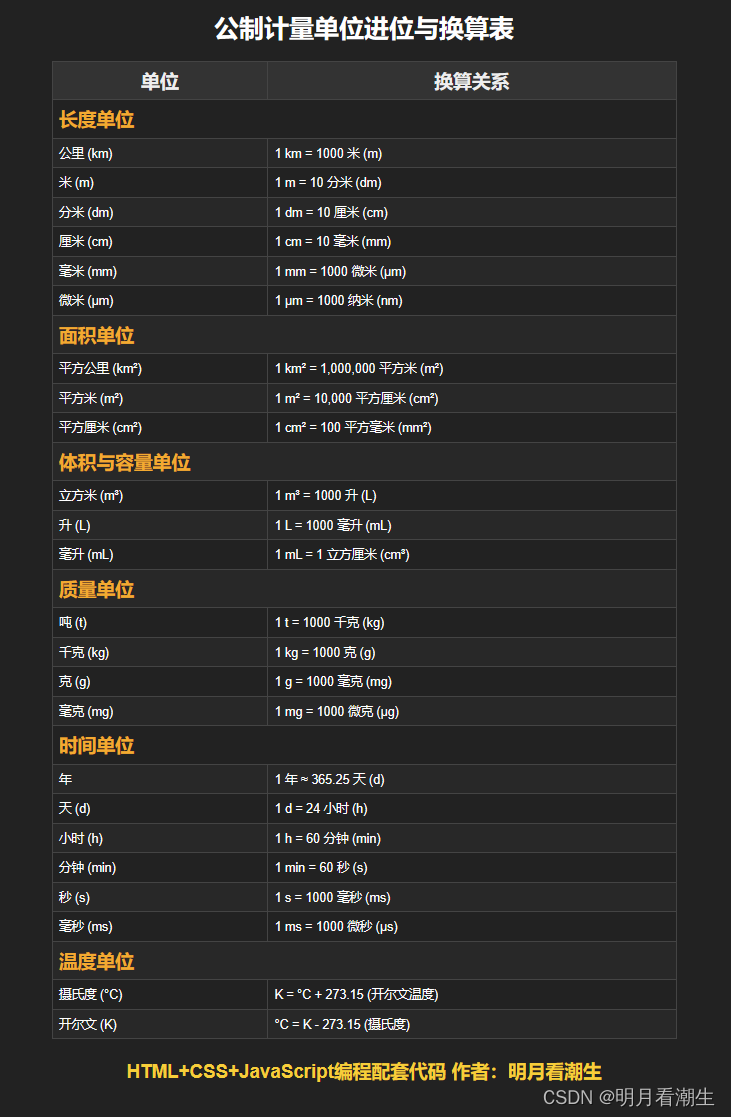
html5cssjs代码 023 公制计量单位进位与换算表
html5&css&js代码 023 公制计量单位进位与换算表 一、代码二、解释 这段HTML代码定义了一个网页,用于展示公制计量单位的进位与换算表。 一、代码 <!DOCTYPE html> <html lang"zh-cn"> <head><meta charset"utf-8&quo…...

UE5.3 StateTree使用实践
近期浏览UE的CitySample(黑客帝国Demo),发现有不少逻辑用到了StateTree学习一下,StateTree是多层状态机实现,以组件的形式直接挂载在蓝图中运行。 与平时常见的一些FSM库不同,StateTree并不会返回给外界当…...
【09】进阶JavaScript事件循环Promise
一、事件循环 浏览器的进程模型 何为进程? 程序运行需要有它自己专属的内存空间,可以把这块内存空间简单的理解为进程 每个应用至少有一个进程,进程之间相互独立,即使要通信,也需要双方同意。 何为线程? 有了进程后,就可以运行程序的代码了。 运行代码的「人」称之…...

蓝桥备赛----基本语法总结
文章目录 输入输出知识点总结 输入 单个 #单个输入n input() #无参数 默认返回字符串n input("有提示参数的输入") #有提示性输入语句的输入,仍是以str类型返回n int(input()) #根据给定的类型输入,返回值类型intn float(input()) #根据…...
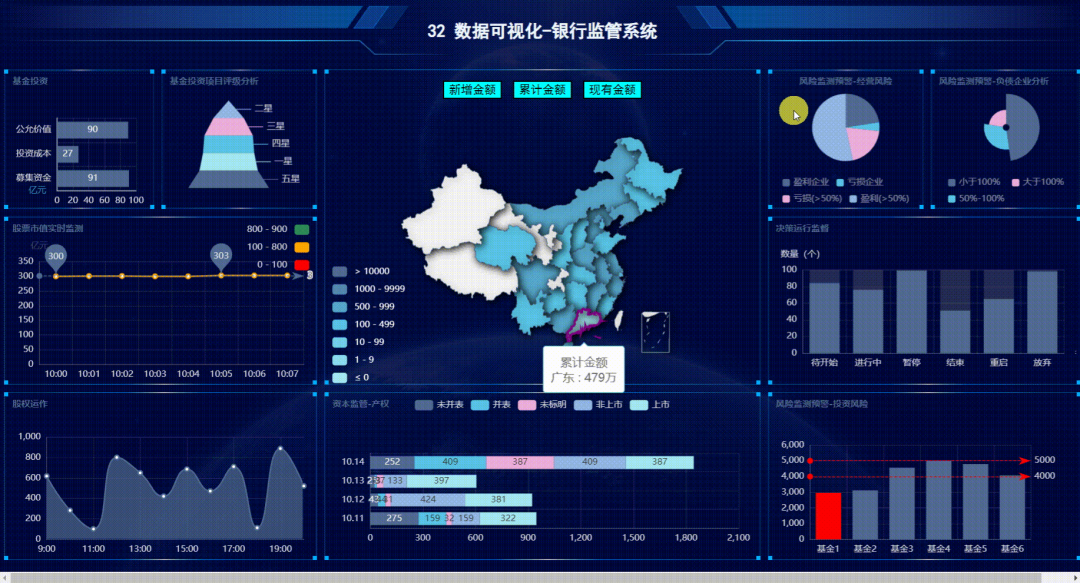
基于 Echarts + Python Flask ,我搭建了一个动态实时大屏监管系统
一、效果展示 1. 动态实时更新数据效果图 2. 鼠标右键切换主题 二、确定需求方案 支持Windows、Linux、Mac等各种主流操作系统;支持主流浏览器Chrome,Microsoft Edge,360等;服务器采用python语言编写,配置好python环…...

针对教育行业的网络安全方案有哪些
智慧校园”是教育信息化进入高级阶段的表现形式,比“数字校园”更先进。集体知识共融、共生、业务应用融合创新、移动互联网物联网高速泛在是其重要特征。特别是在互联网教育的大环境下,为了更好的发挥智慧化教学服务和智慧化教学管理功能,需…...

C++ 编程入门指南:深入了解 C++ 语言及其应用领域
C 简介 什么是 C? C 是一种跨平台的编程语言,可用于创建高性能应用程序。 C 是由 Bjarne Stroustrup 开发的,作为 C 语言的扩展。 C 为程序员提供了对系统资源和内存的高级控制。 该语言在 2011 年、2014 年、2017 年和 2020 年进行了 4…...

latex变量上下加自适应长度箭头
latex变量上下加自适应长度箭头 在变量上加箭头的代码如下 % 在上 \overrightarrow{A B} \overleftarrow{A B} % 在下 \underrightarrow{A B} \underleftarrow{A B}得出的结果依次如下 A B → , A B ← , A B → , A B ← \overrightarrow{A B},\overleftarrow{A B}, \under…...
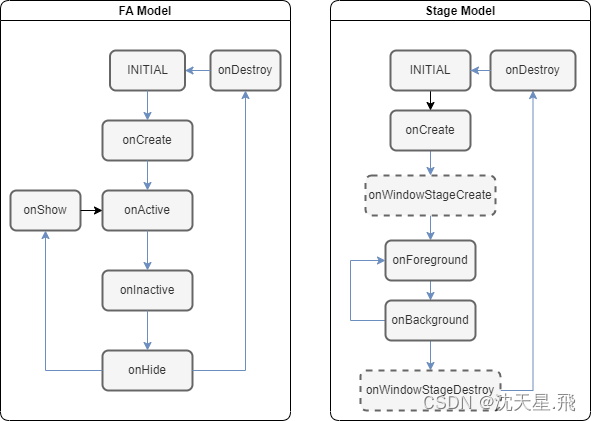
鸿蒙4.0ArkUI快速入门(一)应用模型
ArkUI篇 应用模型Stage模型FA模型模型对比 应用模型 应用模型是HarmonyOS为开发者提供的应用程序所需能力的抽象提炼,它提供了应用程序必备的组件和运行机制。 HarmonyOS先后提供了两种应用模型: FA(Feature Ability)模型&…...
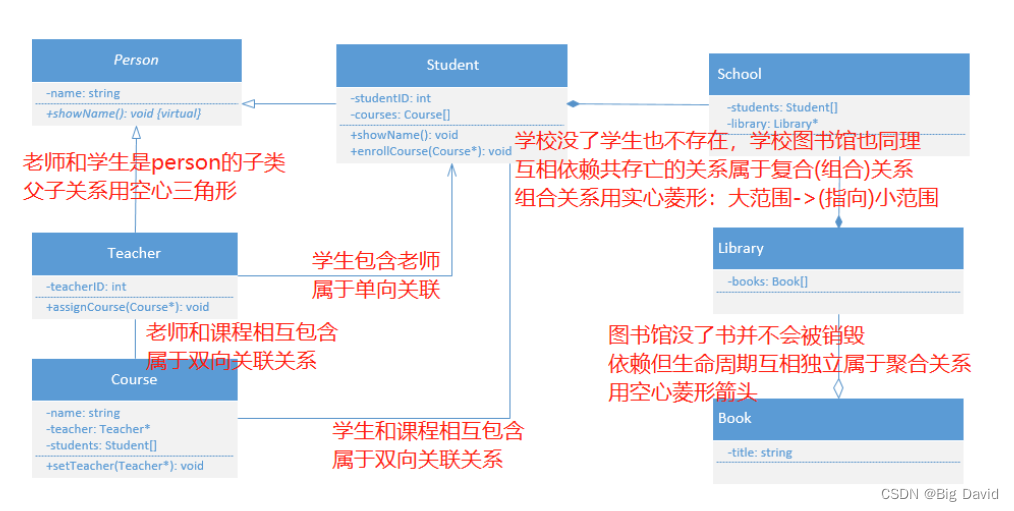
C++ UML类图
参考文章: (1)C UML类图详解 (2)C基础——用C实例理解UML类图 (3)C设计模式——UML类图 (4)[UML] 类图介绍 —— 程序员(灵魂画手)必备画图技能之…...
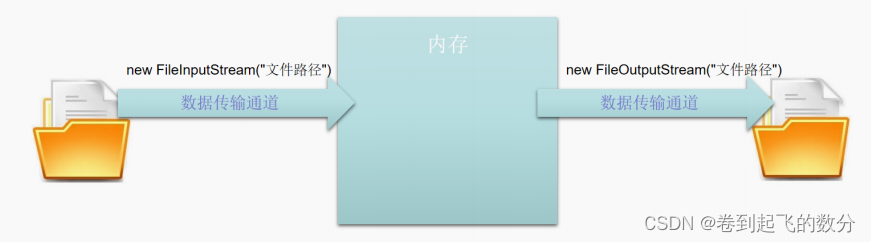
Java SE入门及基础(44)
目录 I / O流(上) 1. 什么是I / O流 过程分析 I / O的来源 Java 中的 I / O流 2. 字节流 OutputStream 常用方法 文件输出流 FileOutputStream 构造方法 示例 InputStream 常用方法 文件输入流 FileInputStream 构造方法 示例 综合练习 字节流应用场景 Java SE文…...
基于Wechaty的微信机器人
git地址:GitHub - wechaty/getting-started: A Starter Project Template for Wechaty works out-of-the-boxhttps://github.com/wechaty/getting-started 在 Terminal中npm install 下载node包 加载完成后。npm start 启动 扫描二维码,即可登录微信web端…...
【C++ leetcode】双指针问题(续)
3. 202 .快乐数 题目 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果这个过程 结…...
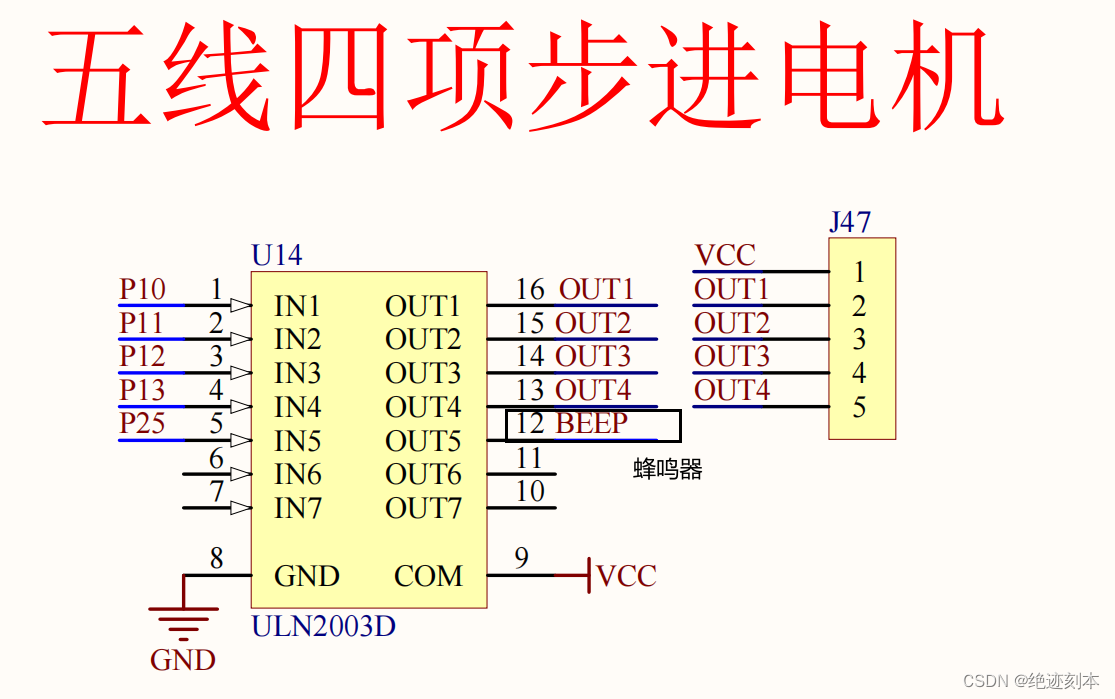
51单片机-蜂鸣器
1.蜂鸣器的介绍 无源蜂鸣器不能一直通电,无源蜂鸣器内部的线圈较小,易烧坏 蜂鸣器的驱动 达林顿晶体管(npn型) 应用: 按下独立按键同时蜂鸣器响起提示音,数码管显示对应的独立按键键码 #include <REG…...

【MySQL】学习和总结使用列子查询查询员工工资信息
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-5odctDvQ0AHJJc1C {font-family:"trebuchet ms",verdana,arial,sans-serif;font-siz…...
)
突破编程_C++_STL教程( stack 的实战应用)
1 std::stack 应用于自定义数据结构 通常,std::stack 用于存储基本数据类型,如 int、float、char 等。然而,std::stack 同样可以存储自定义的数据结构,只要这些数据结构满足一定的要求。 (1)存储自定义数…...

Spring Data访问Elasticsearch----其他Elasticsearch操作支持
Spring Data访问Elasticsearch----其他Elasticsearch操作支持 一、索引设置二、索引映射三、Filter Builder四、为大结果集使用滚动Scroll五、排序选项六、运行时字段6.1 索引映射中的运行时字段定义6.2 在查询上设置的运行时字段定义 七、Point In Time (PIT) API八、搜索模板…...
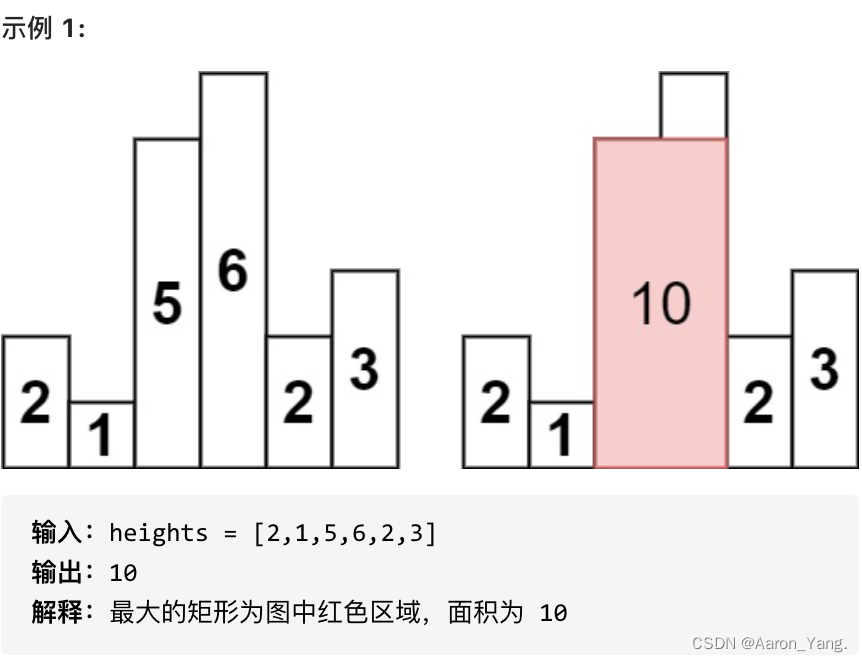
代码随想录算法训练营第60天 | 84.柱状图中最大的矩形
单调栈章节理论基础: https://leetcode.cn/problems/daily-temperatures/ 84.柱状图中最大的矩形 题目链接:https://leetcode.cn/problems/largest-rectangle-in-histogram/description/ 思路: 本题双指针的写法整体思路和42. 接雨水是一…...

把 SAP S/4HANA 的 system conversion 讲透, 它不是简单升级, 而是一场保留家底的系统级转身
很多人一听到 SAP S/4HANA 的 system conversion,脑子里冒出来的第一个画面,就是把老的 ECC 系统升一下版本,装一套新软件,业务就继续跑下去。这个理解只对了一小半。SAP 官方对它的定义其实很明确,system conversion 是把现有 SAP ERP 系统做一个 1:1 的技术性转换,目标…...

BepInEx:解锁Unity游戏无限可能的模组框架
BepInEx:解锁Unity游戏无限可能的模组框架 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 你是否曾经玩过一款Unity游戏,觉得某些功能不够完善,…...

rust 1.95.0 最新版发布:语言特性、编译器、平台支持、标准库、Rustdoc 与兼容性变更全解析
rust 1.95.0 最新版发布:语言特性、编译器、平台支持、标准库、Rustdoc 与兼容性变更全解析 2026年4月16日,Rust 1.95.0 正式发布。作为一次重要版本更新,这一版在语言层、编译器、平台支持、标准库、Rustdoc 以及兼容性方面都带来了相当丰富…...

植物大战僵尸PC版终极修改器:PvZ Toolkit完全使用指南
植物大战僵尸PC版终极修改器:PvZ Toolkit完全使用指南 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 你是否厌倦了《植物大战僵尸》PC版一成不变的玩法?想挑战极限生存模式…...

如何解决暗黑破坏神2存档编辑的复杂性问题:d2s-editor可视化解决方案深度解析
如何解决暗黑破坏神2存档编辑的复杂性问题:d2s-editor可视化解决方案深度解析 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 面对暗黑破坏神2存档编辑的复杂十六进制操作和技术门槛,传统方法让普通玩家望…...

别再空谈RAG了!手把手教你用LangChain + Chroma + 本地SearXng,从零搭建一个能联网搜索的智能问答助手
从零构建智能问答系统:LangChain Chroma SearXng实战指南 引言 在信息爆炸的时代,如何快速获取准确答案成为技术团队面临的共同挑战。传统搜索引擎返回的是海量网页链接,而大语言模型虽然能生成流畅回答,却存在信息滞后和幻觉问…...
)
手把手教你用Cadence仿真验证Charge Pump的current mismatch与deviation(以65nm PDK为例)
手把手教你用Cadence仿真验证Charge Pump的current mismatch与deviation(以65nm PDK为例) 电荷泵(Charge Pump)作为锁相环(PLL)中的关键模块,其电流匹配性能直接影响整个系统的相位噪声和杂散水…...
实战选型与电路设计避坑)
别再只盯着LoRaWAN了!智能水表数据采集的三种传感器(干簧管/霍尔/光电)实战选型与电路设计避坑
智能水表传感器选型实战:干簧管、霍尔与光电技术的深度对比 在物联网智能水表的设计中,传感器选型直接决定了产品的核心性能与市场竞争力。面对市面上主流的干簧管、霍尔元件和光电转换三种技术方案,硬件团队需要从实际应用场景出发ÿ…...
)
保姆级教程:用ABB RobotStudio和TCP客户端搞定视觉引导机器人(含避坑点)
工业机器人视觉引导全流程实战:从Socket通信到姿态转换的深度解析 第一次在RobotStudio里配置视觉引导机器人时,我盯着那个报错的Rz参数整整两小时——明明相机数据已经通过Socket传过来了,机器人就是不肯按预期运动。后来才发现,…...
对生成质量与耗时权衡)
FLUX.小红书极致真实V2参数调优:不同采样步数(20/25/30)对生成质量与耗时权衡
FLUX.小红书极致真实V2参数调优:不同采样步数(20/25/30)对生成质量与耗时权衡 想用AI生成小红书风格的精美图片,却发现要么画质不够好,要么等得花儿都谢了?这可能是你没调对“采样步数”这个关键参数。 今…...