Spring Data访问Elasticsearch----其他Elasticsearch操作支持
Spring Data访问Elasticsearch----其他Elasticsearch操作支持
- 一、索引设置
- 二、索引映射
- 三、Filter Builder
- 四、为大结果集使用滚动Scroll
- 五、排序选项
- 六、运行时字段
- 6.1 索引映射中的运行时字段定义
- 6.2 在查询上设置的运行时字段定义
- 七、Point In Time (PIT) API
- 八、搜索模板(Template)支持
- 九、嵌套排序Nested sort
本文介绍了对Elasticsearch操作的额外支持,这些操作无法通过存储库接口直接访问。建议将这些操作添加为自定义实现,如“ 自定义存储库实现”中所述。
一、索引设置
当使用Spring Data创建Elasticsearch索引时,可以使用@Setting注解定义不同的索引设置。以下参数可用:
- useServerConfiguration 不发送任何设置参数,因此由Elasticsearch服务器配置决定。
- settingPath指的是一个JSON文件,该文件定义了必须在类路径中解析的设置
- shards要使用的分片数,默认为1
- replicas复制副本的数量,默认为1
- refreshIntervall,默认为“1s”
- indexStoreType,默认为“fs”
也可以定义索引排序(查看链接的Elasticsearch文档中可能的字段类型和值):
@Document(indexName = "entities")
@Setting(sortFields = { "secondField", "firstField" }, --------1 sortModes = { Setting.SortMode.max, Setting.SortMode.min }, --------2 sortOrders = { Setting.SortOrder.desc, Setting.SortOrder.asc },sortMissingValues = { Setting.SortMissing._last, Setting.SortMissing._first })
class Entity {@Nullable@Id private String id;@Nullable@Field(name = "first_field", type = FieldType.Keyword)private String firstField;@Nullable @Field(name = "second_field", type = FieldType.Keyword)private String secondField;// getter and setter...
}1. 定义排序字段时,请使用Java属性的名称(firstField),而不是可能为Elasticsearch定义的名称(first_field)
2. sortModes、sortOrders和sortMissingValues是可选的,但如果设置了它们,则条目的数量必须与sortFields元素的数量相匹配
二、索引映射
当Spring Data Elasticsearch使用IndexOperations.createMapping()方法创建索引映射时,它会使用Mapping Annotation Overview中描述的注解,尤其是@Field注解。除此之外,还可以将@Mapping注解添加到类中。此注解具有以下属性:
- mappingPath JSON格式的类路径资源;如果这不是空的,它将用作映射,则不进行其他映射处理。
- enabled 当设置为false时启用,该标志将被写入映射,并且不进行进一步处理。
- dateDetection和numericDetection在未设置为DEFAULT时设置映射中的相应属性。
- dynamicDateFormats当此字符串数组不为空时,它定义用于自动日期检测的日期格式。
- runtimeFieldsPath JSON格式的类路径资源,包含写入索引映射的运行时字段的定义,例如:
{"day_of_week": {"type": "keyword","script": {"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"}}
}
三、Filter Builder
Filter Builder提高查询速度。
private ElasticsearchOperations operations;IndexCoordinates index = IndexCoordinates.of("sample-index");Query query = NativeQuery.builder().withQuery(q -> q.matchAll(ma -> ma)).withFilter( q -> q.bool(b -> b.must(m -> m.term(t -> t.field("id").value(documentId))))).build();SearchHits<SampleEntity> sampleEntities = operations.search(query, SampleEntity.class, index);
四、为大结果集使用滚动Scroll
Elasticsearch有一个滚动API,用于获取大块的结果集。Spring Data Elasticsearch内部使用它来提供<T> SearchHitsIterator<T> SearchOperations.searchForStream(Query query, Class<T> clazz, IndexCoordinates index)方法的实现。
IndexCoordinates index = IndexCoordinates.of("sample-index");Query searchQuery = NativeQuery.builder().withQuery(q -> q.matchAll(ma -> ma)).withFields("message").withPageable(PageRequest.of(0, 10)).build();SearchHitsIterator<SampleEntity> stream = elasticsearchOperations.searchForStream(searchQuery, SampleEntity.class,
index);List<SampleEntity> sampleEntities = new ArrayList<>();
while (stream.hasNext()) {sampleEntities.add(stream.next());
}stream.close();
在SearchOperations API中没有方法来访问滚动id,如果有必要访问它,可以使用AbstractElasticsearchTemplate的以下方法(这是不同ElasticsearchOperations实现的基础实现):
@Autowired ElasticsearchOperations operations;AbstractElasticsearchTemplate template = (AbstractElasticsearchTemplate)operations;IndexCoordinates index = IndexCoordinates.of("sample-index");Query query = NativeQuery.builder().withQuery(q -> q.matchAll(ma -> ma)).withFields("message").withPageable(PageRequest.of(0, 10)).build();SearchScrollHits<SampleEntity> scroll = template.searchScrollStart(1000, query, SampleEntity.class, index);String scrollId = scroll.getScrollId();
List<SampleEntity> sampleEntities = new ArrayList<>();
while (scroll.hasSearchHits()) {sampleEntities.addAll(scroll.getSearchHits());scrollId = scroll.getScrollId();scroll = template.searchScrollContinue(scrollId, 1000, SampleEntity.class);
}
template.searchScrollClear(scrollId);
要将Scroll API与存储库方法一起使用,返回类型必须在Elasticsearch存储库中定义为Stream。然后,该方法的实现将使用ElasticsearchTemplate中的scroll方法。
interface SampleEntityRepository extends Repository<SampleEntity, String> {Stream<SampleEntity> findBy();}
五、排序选项
除了分页和排序中描述的默认排序选项外,Spring Data Elasticsearch还提供了从“org.springframework.Data.domain.sort.Order”派生而来的类“org.springframework.Data.reasticsearch.core.query”。它提供了额外的参数,在指定结果排序时可以将这些参数发送到Elasticsearch(请参见这里)。
还有“org.springframework.data.aelasticsearch.core.query.GeoDistanceOrder”类,可用于按地理距离排序搜索操作的结果。
如果要检索的类具有名为location的GeoPoint属性,则以下排序将按到给定点的距离对结果进行排序:
Sort.by(new GeoDistanceOrder("location", new GeoPoint(48.137154, 11.5761247)))
六、运行时字段
从7.12版本开始,Elasticsearch增加了运行时字段的功能。Spring Data Elasticsearch通过两种方式支持这一点:
6.1 索引映射中的运行时字段定义
定义运行时字段的第一种方法是将定义添加到索引映射中(请参见这里)。要在Spring Data Elasticsearch中使用这种方法,用户必须提供一个包含相应定义的JSON文件,例如:
例1:runtime-fields.json
{"day_of_week": {"type": "keyword","script": {"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"}}
}
这个JSON文件的路径必须出现在类路径中,然后必须在实体的@Mapping注解中设置:
@Document(indexName = "runtime-fields")
@Mapping(runtimeFieldsPath = "/runtime-fields.json")
public class RuntimeFieldEntity {// properties, getter, setter,...
}
6.2 在查询上设置的运行时字段定义
定义运行时字段的第二种方法是将定义添加到搜索查询中(请参见这里)。以下代码示例展示了如何使用Spring Data Elasticsearch进行此操作:
所使用的实体是一个具有price属性的简单对象:
@Document(indexName = "some_index_name")
public class SomethingToBuy {private @Id @Nullable String id;@Nullable @Field(type = FieldType.Text) private String description;@Nullable @Field(type = FieldType.Double) private Double price;// getter and setter
}
下面的查询使用一个运行时字段,该字段通过将价格添加19%来计算priceWithTax值,并在搜索查询中使用该值来查找priceWithTax高于或等于给定值的所有实体:
RuntimeField runtimeField = new RuntimeField("priceWithTax", "double", "emit(doc['price'].value * 1.19)");
Query query = new CriteriaQuery(new Criteria("priceWithTax").greaterThanEqual(16.5));
query.addRuntimeField(runtimeField);SearchHits<SomethingToBuy> searchHits = operations.search(query, SomethingToBuy.class);
这适用于Query接口的每一个实现。
七、Point In Time (PIT) API
ElasticsearchOperations支持Elasticsearch的point in time API(请参见这里)。以下代码片段显示了如何将此功能与虚构的Person类一起使用:
ElasticsearchOperations operations; // autowired
Duration tenSeconds = Duration.ofSeconds(10);String pit = operations.openPointInTime(IndexCoordinates.of("person"), tenSeconds); --------1// create query for the pit
Query query1 = new CriteriaQueryBuilder(Criteria.where("lastName").is("Smith")).withPointInTime(new Query.PointInTime(pit, tenSeconds)) --------2.build();
SearchHits<Person> searchHits1 = operations.search(query1, Person.class);
// do something with the data// create 2nd query for the pit, use the id returned in the previous result
Query query2 = new CriteriaQueryBuilder(Criteria.where("lastName").is("Miller")).withPointInTime(new Query.PointInTime(searchHits1.getPointInTimeId(), tenSeconds)) --------3 .build();
SearchHits<Person> searchHits2 = operations.search(query2, Person.class);
// do something with the dataoperations.closePointInTime(searchHits2.getPointInTimeId()); --------41. 为索引(可以是多个名称)和keep-alive持续时间创建一个point in time,并检索其id
2. 将该id传递到查询中,以便与下一个keep-alive一起进行搜索
3. 对于下一个查询,使用上一次搜索返回的id
4. 完成后,使用最后返回的id关闭point in time
八、搜索模板(Template)支持
支持使用搜索模板Template API。要使用它,首先需要创建一个存储的脚本。ElasticsearchOperations接口扩展了提供必要功能的ScriptOperations。这里使用的示例假设我们有一个名为firstName的属性的Person实体。搜索模板脚本可以这样保存:
operations.putScript( --------1 Script.builder().withId("person-firstname") --------2 .withLanguage("mustache") --------3 .withSource(""" --------4 {"query": {"bool": {"must": [{"match": {"firstName": "{{firstName}}" --------5 }}]}},"from": "{{from}}", --------6 "size": "{{size}}" --------7 }""").build()
);1. 使用putScript()方法存储搜索模板脚本
2. 脚本的名称/id
3. 搜索模板中使用的脚本必须是mustache语言。
4. 脚本源
5. 脚本中的搜索参数
6. 分页请求偏移
7. 分页请求大小
为了在搜索查询中使用搜索模板,Spring Data Elasticsearch提供了SearchTemplateQuery,这是“org.springframework.data.elasticsearch.core.query.Query”接口的实现。
在下面的代码中,我们将使用搜索模板查询向自定义存储库实现添加一个调用(请参阅自定义存储库实现),作为如何将其集成到存储库调用中的示例。
我们首先定义自定义存储库片段接口:
interface PersonCustomRepository {SearchPage<Person> findByFirstNameWithSearchTemplate(String firstName, Pageable pageable);
}
这个存储库片段的实现看起来像这样:
public class PersonCustomRepositoryImpl implements PersonCustomRepository {private final ElasticsearchOperations operations;public PersonCustomRepositoryImpl(ElasticsearchOperations operations) {this.operations = operations;}@Overridepublic SearchPage<Person> findByFirstNameWithSearchTemplate(String firstName, Pageable pageable) {var query = SearchTemplateQuery.builder() --------1.withId("person-firstname") --------2.withParams(Map.of( --------3"firstName", firstName,"from", pageable.getOffset(),"size", pageable.getPageSize())).build();SearchHits<Person> searchHits = operations.search(query, Person.class); --------4return SearchHitSupport.searchPageFor(searchHits, pageable);}
}1. 创建SearchTemplateQuery
2. 提供搜索模板的id
3. 参数在Map<String,Object>中传递
4. 以与其他查询类型相同的方式进行搜索。
九、嵌套排序Nested sort
Spring Data Elasticsearch支持在嵌套对象内排序(见这里)下面的例子,摘自org.springframework.data.elasticsearch.core.query.sort.NestedSortIntegrationTests类,展示了如何定义嵌套排序。
var filter = StringQuery.builder("""{ "term": {"movies.actors.sex": "m"} }""").build();
var order = new org.springframework.data.elasticsearch.core.query.Order(Sort.Direction.DESC,"movies.actors.yearOfBirth").withNested(Nested.builder("movies").withNested(Nested.builder("movies.actors").withFilter(filter).build()).build());var query = Query.findAll().addSort(Sort.by(order));
关于filter查询:这里不可能使用CriteriaQuery,因为此查询将被转换为Elasticsearch嵌套查询,该查询在filter上下文中不起作用。所以这里只能使用StringQuery或NativeQuery。当使用其中一个时,如上面的term查询,必须使用Elasticsearch字段名,所以当使用@Field(name=“…”)定义重新定义这些字段时要小心。
对于排序路径和嵌套路径的定义,应使用Java实体属性名称。
相关文章:

Spring Data访问Elasticsearch----其他Elasticsearch操作支持
Spring Data访问Elasticsearch----其他Elasticsearch操作支持 一、索引设置二、索引映射三、Filter Builder四、为大结果集使用滚动Scroll五、排序选项六、运行时字段6.1 索引映射中的运行时字段定义6.2 在查询上设置的运行时字段定义 七、Point In Time (PIT) API八、搜索模板…...
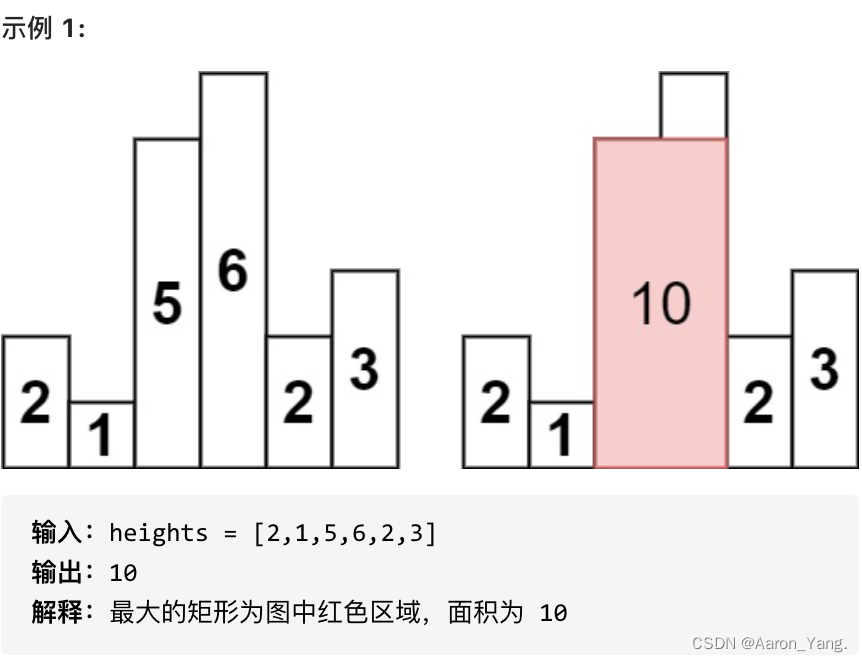
代码随想录算法训练营第60天 | 84.柱状图中最大的矩形
单调栈章节理论基础: https://leetcode.cn/problems/daily-temperatures/ 84.柱状图中最大的矩形 题目链接:https://leetcode.cn/problems/largest-rectangle-in-histogram/description/ 思路: 本题双指针的写法整体思路和42. 接雨水是一…...

【讲解Node.js常用的命令】进阶版
Node.js常用命令 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,它使得可以在服务器端运行 JavaScript 代码。Node.js 采用了事件驱动、非阻塞 I/O 模型,非常适用于构建高效的网络应用程序。以下是一些Node.js开发中常用的命令࿱…...

软考81-上午题-【面向对象技术3-设计模式】-行为型设计模式01
一、行为型设计模式一览 二、责任链模式 2-1、意图 使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。 1-2、结构 1-3、代码实现 1-4、适…...
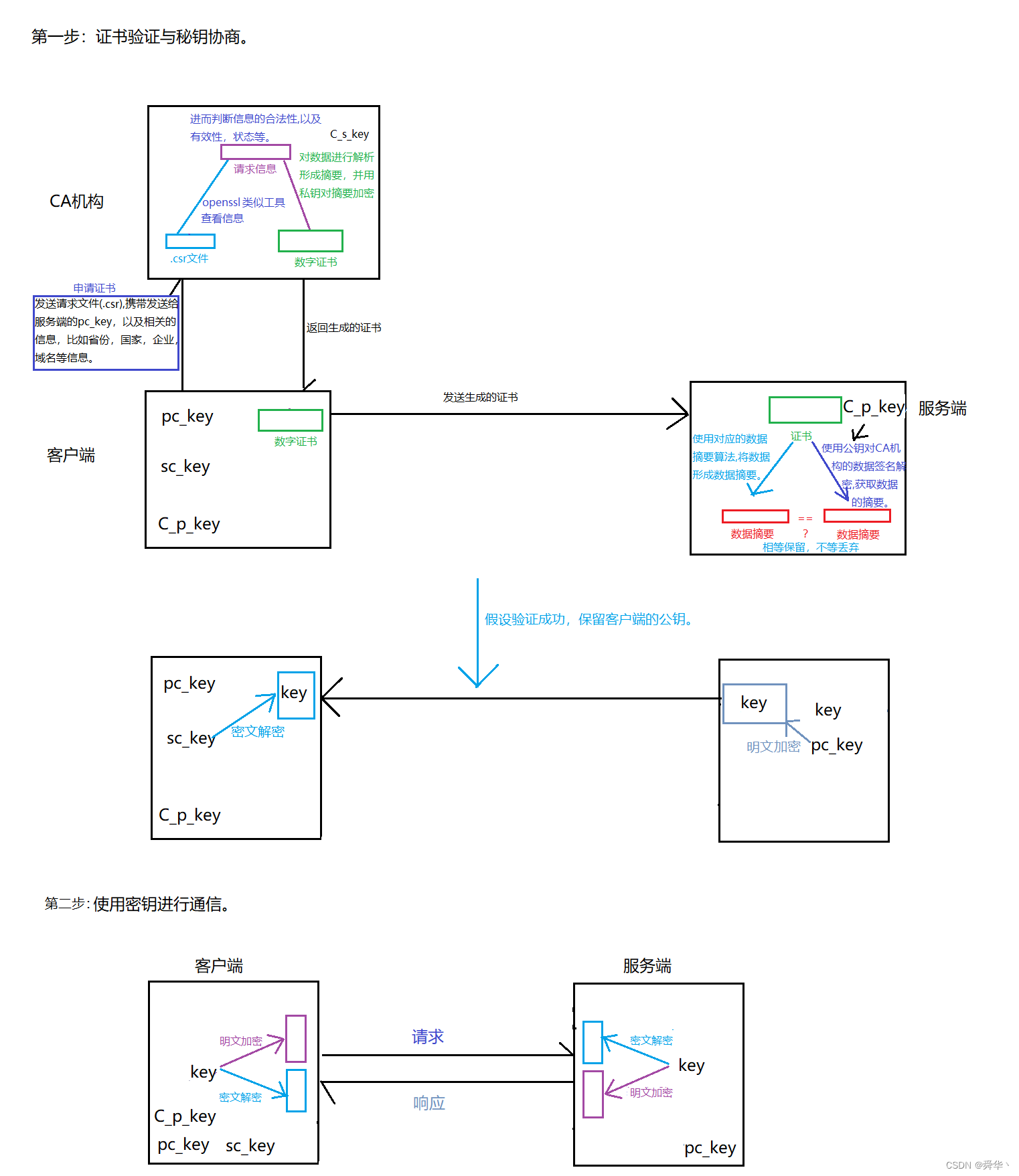
【Linux进阶之路】HTTPS = HTTP + S
文章目录 一、概念铺垫1.Session ID2.明文与密文3.公钥与私钥4.HTTPS结构 二、加密方式1. 对称加密2.非对称加密3.CA证书 总结尾序 一、概念铺垫 1.Session ID Session ID,即会话ID,用于标识客户端与服务端的唯一特定会话的标识符。会话,即客…...
51-31 CVPR’24 | VastGaussian,3D高斯大型场景重建
2024 年 2 月,清华大学、华为和中科院联合发布的 VastGaussian 模型,实现了基于 3D Gaussian Splatting 进行大型场景高保真重建和实时渲染。 Abstract 现有基于NeRF大型场景重建方法,往往在视觉质量和渲染速度方面存在局限性。虽然最近 3D…...

GPT-4引领AI新纪元,Claude3、Gemini、Sora能否跟上步伐?
【最新增加Claude3、Gemini、Sora、GPTs讲解及AI领域中的集中大模型的最新技术】 2023年随着OpenAI开发者大会的召开,最重磅更新当属GPTs,多模态API,未来自定义专属的GPT。微软创始人比尔盖茨称ChatGPT的出现有着重大历史意义,不亚…...

图书馆RFID(射频识别)数据模型压缩/解压缩算法实现小工具
1. 前言 最近闲来无聊,看了一下《图书馆射频识别数据模型第1部分:数据元素的设置及应用规则》以及《图书馆射频识别数据模型第2部分:基于ISO/IEC 15962的数据元素编码方案》,决定根据上面的编码方法实现一下该算法,于…...

【Java Web基础】一些网页设计基础(三)
文章目录 1. 导航栏样式进一步调整2. 入驻企业信息展示栏2.1 Title设置2.2 具体信息添加 3. 轮播图4. 注册登录按钮及其他信息5. 一些五颜六色的、丰富视觉效果的中间件…… 1. 导航栏样式进一步调整 这种导航栏,选中的时候字体变蓝色,可能还是不够美观&…...
2 使用GPU理解并行计算
2.1 简介 本章旨在对并行程序设计的基本概念及其与GPU技术的联系做一个宽泛的介绍。本章主要面向具有串行程序设计经验,但对并行处理概念缺乏了解的读者。我们将用GPU的基本知识来讲解并行程序设计的基本概念。 2.2 传统的串行代码 绝大多数程序员是在串行程序占据…...

Android什么情况下会出现内存泄漏以及怎么解决?
1.什么情况下会出现内存泄漏? (1)单例模式下为什么会造成内存泄漏? 因为单例的生命周期和应用的生命周期是一致的,如果往单例模式里面传了一个生命周期比较短的对象,比如Activity,就会导致Activity不能释放,导致内存泄漏。我们可以传context.getAppliactionContext,而…...
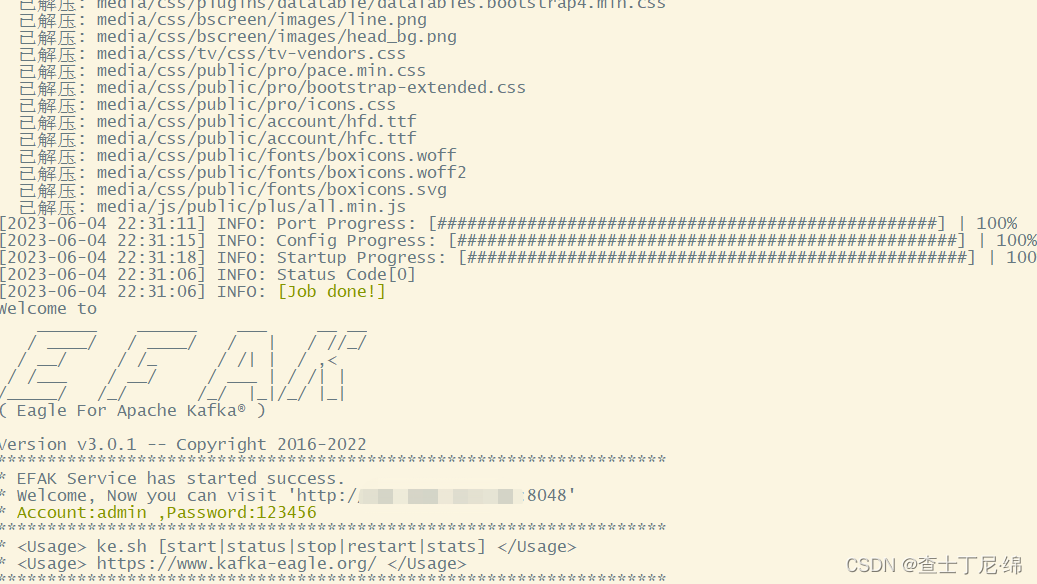
kafka集群介绍及搭建
介绍 kafka是一个高性能、低延迟、分布式的消息传递系统,特点在于实时处理数据。集群由多个成员节点broker组成,每个节点都可以独立处理消息传递和存储任务。 路由策略 发布消息由key、value组成,真正的消息是value,key是标识路…...
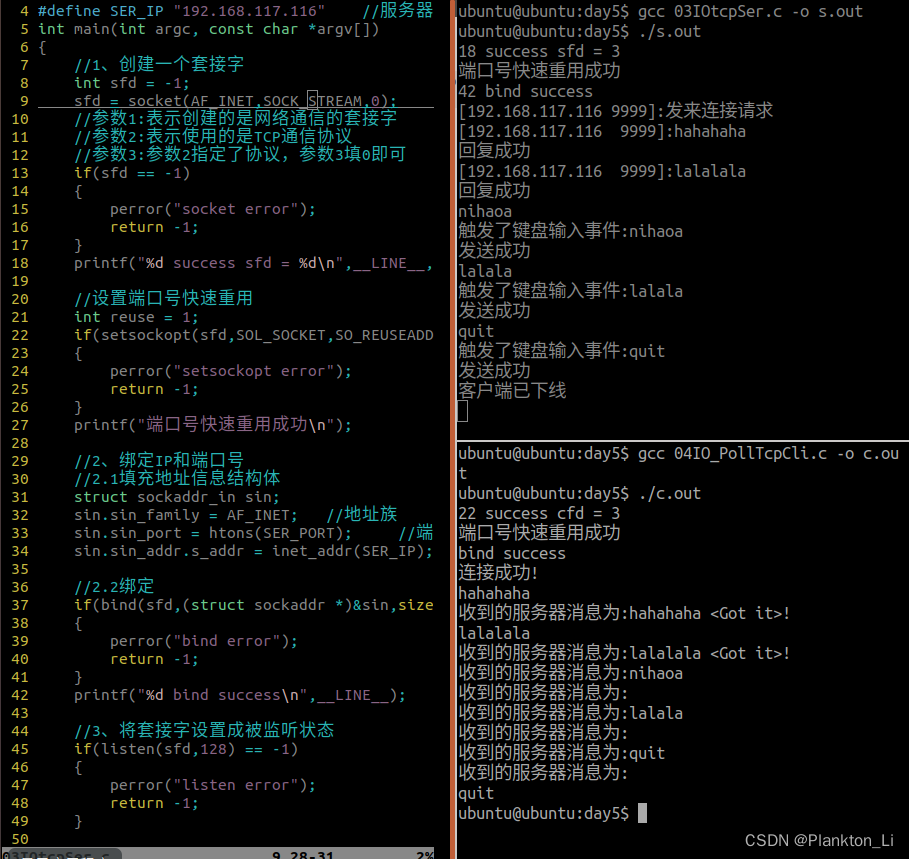
2024/03/19(网络编程·day5)
一、思维导图 二、selec函数实现TCP并发服务器 #include<myhead.h>#define SER_PORT 8888 //服务器端口号 #define SER_IP "192.168.117.116" //服务器IP int main(int argc, const char *argv[]) {//1、创建一个套接字int sfd -1;sfd socket(AF_INET,SOC…...

LeetCode解法汇总1969. 数组元素的最小非零乘积
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:. - 力扣(LeetCode) 描述: 给你一个正整数 p 。你有一个下标从 1 开…...
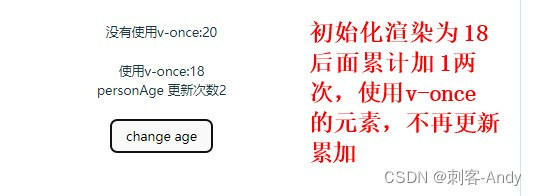
学习vue3第九节(新加指令 v-pre/v-once/v-memo/v-cloak )
1、v-pre 作用:防止编译器解析某个特定的元素及其内容,即v-pre 会跳过当前元素以及其子元素的vue语法解析,并将其保持原样输出; 用于:vue 中一些没有指令和插值表达式的节点的元素,使用 v-pre 可以提高 Vu…...
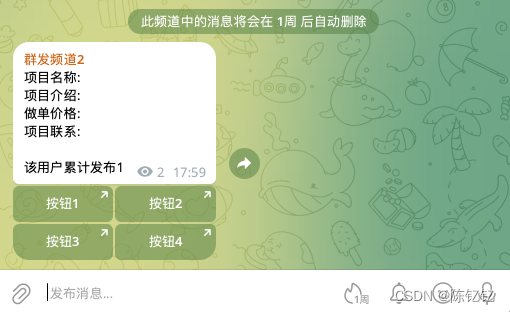
二开飞机机器人群发,实现自动给多个频道发送消息
频道1 频道2 二开代码部分: const CChatIdListprocess.env.CHANNEL_CHAT_ID_LIST; var channelChatIdArray CChatIdList.split(,);channelChatIdArray.forEach(function(item) {console.log(item); // 这里可以替换为您需要对数组中每个值进行的操作bot.sendM…...

AI如何支持慈善组织
为各种有意义的事业提供支持,无论是努力寻找治愈疾病的方法、研发使生活更轻松的技术,还是为有需要的人提供服务,都是无比崇高的使命。提供捐款或是投入时间支持的捐助者和志愿者往往对他们选择支持的事业的目标、服务和资源分配存有诸多疑虑…...
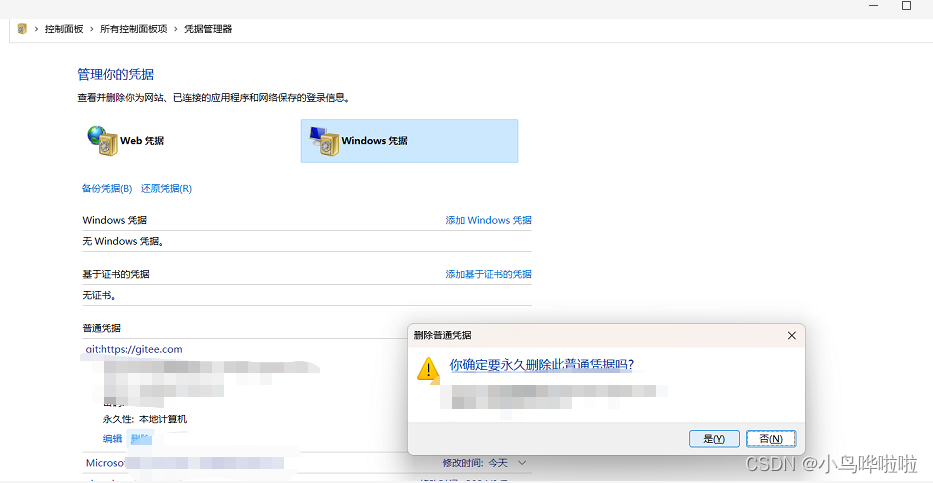
Git如何清除账户凭证
场景:一般发生在Git用户变更的情况 1.git base 操作 Git会使用凭证助手 credential.helper来储存账户凭证,通过以下命令移除: git config --system --unset credential.helper 除了system系统级外,还有 global、local范围。 查…...
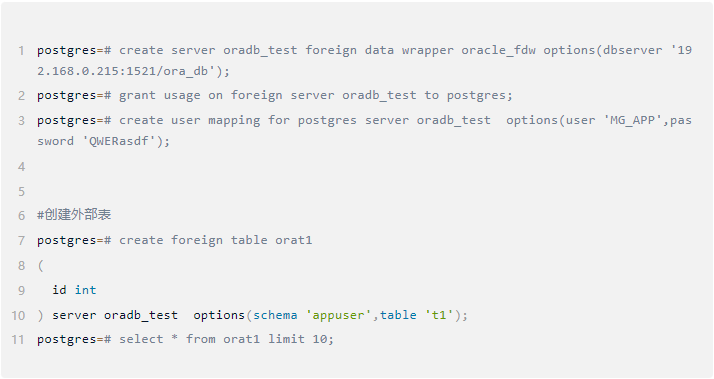
【YUNBEE云贝-PostgreSQL】FDW应用
注: 本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。 前言 Wrapper(FDW)是一项关键特性,它赋予数据库用户直接通过SQL语句访问存储于外部数据源的能…...

Spring MVC文件上传配置
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 文件上传 Spring MVC文件上传基于Servlet 3.0实现;示例代码如下: Overrideprotected void customizeRegistration(ServletRegistration.Dynamic reg…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...

QKeyMapper终极指南:Windows上最强大的开源按键映射工具
QKeyMapper终极指南:Windows上最强大的开源按键映射工具 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠ÿ…...

Wand-Enhancer:3步解锁WeMod专业版功能的完整用户指南
Wand-Enhancer:3步解锁WeMod专业版功能的完整用户指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否厌倦了WeMod免费版的种种限制&a…...

JMeter中稳定获取与传递Token的三种实战方案
1. 为什么token获取总在JMeter脚本里“掉链子”做接口测试的同行应该都踩过这个坑:明明API文档写得清清楚楚,Postman里一调一个准,可一到JMeter里,登录接口返回了token,后续请求却始终401——Header里token字段空着、变…...