51-31 CVPR’24 | VastGaussian,3D高斯大型场景重建
2024 年 2 月,清华大学、华为和中科院联合发布的 VastGaussian 模型,实现了基于 3D Gaussian Splatting 进行大型场景高保真重建和实时渲染。
Abstract
现有基于NeRF大型场景重建方法,往往在视觉质量和渲染速度方面存在局限性。虽然最近 3D Gaussians Spltting 在小规模和以对象为中心的场景中效果很好,但由于视频内存有限、优化时间长、外观变化明显,将其扩展到大型场景会带来挑战。为了应对这些挑战,我们提出了 VastGaussian,这是第一个基于 3D Gaussians Spltting 大型场景高质量重建和实时渲染方法。我们提出了一种渐进分割策略,将大型场景划分为多个单元,其中训练相机和点云根据空域感知可见度标准进行适当分布。在并行优化后,这些单元被合并为一个完整场景。我们还将解耦的外观建模引入到优化过程中,以减少渲染图像外观变化。我们的方法优于现有的基于NeRF方法,并在多个大型场景数据集上实现了最先进性能,实现了快速优化和高保真实时渲染。
Project page:https://vastgaussian.github.io.
Introduction
大型场景重建对于许多应用程序来说是必不可少的,包括自动驾驶、航空测量和虚拟现实,这需要逼真的视觉质量和实时渲染。Block-NeRF,Mega-NeRF,BungeeNeRF,Grid-NeRF,Switch-NeRF 等方法将神经辐射场NeRF扩展到大规模场景,但它们仍然缺乏细节或渲染缓慢。
3D Gaussian Splatting (3DGS) ,作为一种很有前景的方法出现了,在视觉质量和渲染速度方面取得了令人印象深刻的性能,实现1080p分辨率下照片逼真感和实时渲染。
应用于动态场景重建
- Dynamic 3D Gaussians;
- 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering;
- Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction;
- Real-time photorealistic dynamic scene representation and redering with 4D gaussian splatting。
应用3D内容生成
- TEXT-TO-3D USING GAUSSIAN SPLATTING;
- DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation;
- Fast generation from text to 3d gaussian splatting with point cloud priors。
然而,这些方法侧重于小规模和以对象为中心的场景。当应用于大规模环境时,有几个可扩展性问题。
- 首先,3D Gaussians 数量受到给定的视频内存限制,而大型场景丰富细节需要大量3D Gaussians。将3DGS天真地应用于大规模场景会导致低质量重建或内存不足错误。为了直观解释,可以使用 32 GB GPU 来优化大约 1100 万个 3D Gaussians,而 Mip-NeRF 360 中面积小于 100m2小花园场景数据集已经需要大约 580 万个 3D Gaussians 来进行高保真重建。
- 其次,它需要足够迭代来优化整个大型场景,这可能很耗时,而且在没有良好正则化情况下不稳定。
- 第三,大型场景中光照通常不均匀,捕获的图像存在明显的外观变化,如图2(a)所示。3DGS倾向于产生大3D Gaussian,具有低不透明度,以补偿不同视图之间的这些差异。例如,明亮斑点往往靠近具有高曝光图像相机,深色斑点与低曝光图像相关联。这些斑点在从新视图观察时在空气中变成了令人不快的漂浮物,如图2(b, d)所示。

图2,(a)相邻训练视图中的外观可能会有所不同。(b) 可以在具有不同亮度训练图像相机附近创建深色或明亮斑点。(c) 3D Gaussian Splatting使用这些斑点来拟合外观变化,使渲染类似于 (a) 中训练图像。(d) 这些斑点在新视图中出现为漂浮物。(e)我们的解耦外观建模使模型能够学习恒定的颜色,因此渲染图像在不同视图的外观更加一致。(f) 我们的方法大大减少了新视图中的漂浮物。
为了解决这些问题,我们提出了基于3D Gaussian Splatting大型场景重建VastGaussian。我们以分而治之的方式重建一个大场景:将大场景划分为多个单元,独立优化每个单元,最后将它们合并为一个完整场景。由于其更精细的空间尺度和更小的数据大小,更容易优化这些单元。
一种自然朴素的划分策略是根据训练数据的位置在地理上进行分布。这可能会导致两个相邻单元之间边界的伪影,因为很少有普通相机,并且可能在没有足够监督情况下产生空中漂浮物。因此,我们提出了基于可见性的数据选择,以逐步纳入更多的训练相机和点云,从而确保无缝合并并消除空中漂浮物。
我们的方法比 3DGS 具有更好的灵活性和可扩展性。每个单元中都包含较少数量的 3D Gaussians,减少了内存需求和优化时间,尤其是在与多个 GPU 并行优化时。合并场景中包含的 3D Gaussians 总数可以大大超过整体训练的场景,提高重建质量。此外,我们可以通过合并新单元或微调特定区域来扩展场景,而无需重新训练整个大场景。
为了减少由外观变化引起的浮动,基于NeRF的方法,Block-NeRF,Switch-NeRF提出了带有外观嵌入的生成潜在优化。
这种方法通过光线行进对点进行采样,并将点特征与外观嵌入一起输入到MLP中,以获得最终颜色。渲染过程与优化相同,后者仍然需要外观嵌入作为输入。
它不适合 3DGS,因为它的渲染是通过没有 MLP 逐帧光栅化执行的。我们提出了一种新的解耦外观模型,该模型仅适用于优化。我们将外观嵌入逐像素附加到渲染图像中,并将它们输入到 CNN 中以获得对渲染图像应用外观校准的转换图。
我们惩罚渲染图像与其基本真值之间的结构差异来学习恒定信息,而光度损失是在调整后的图像上计算的,以适应训练图像中的外观变化。只有一致的渲染才是我们需要的,所以这个外观建模模块可以在优化后丢弃,从而不会降低实时渲染速度。
在几个大型场景基准上,实验证实了我们的方法优于 NeRF。
我们的贡献总结如下:
- 我们提出了 VastGaussian,这是第一个基于 3D Gaussian Splatting 大型场景高保真重建和实时渲染方法。
- 我们提出了一种渐进式数据分区策略,将训练视图和点云分配给不同单元,从而实现并行优化和无缝合并。
- 我们在优化过程中引入了解耦的外观建模,从而抑制了由于外观变化而引起的漂浮物。该模块经过优化后可以丢弃,以获得实时渲染速度。
Related Work
Large Scene Reconstruction
在过去的几十年里,基于图像的大型场景重建取得了重大进展。一些作品遵循结构运动 (SfM) piepline 来估计相机位姿和稀疏点云。一些工作基于多视图立体(MVS)从SfM输出中生成密集的点云或三角形网格。
近年来,NeRF成为一种流行的用于真实感新景合成的3D表示,下面是一些基于NeRF工作汇总。
- 提高质量
- A multiscale representation for anti-aliasing neural radiance fields. In ICCV, 2021.
- Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In CVPR, 2022.
- Zip-nerf: Anti-aliased gridbased neural radiance fields. In ICCV, 2023. 3
- High-fidelity neural surface reconstruction. InCVPR, 2023
- Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In NeurIPS, 2021
- F2-nerf: Fast neural radiance field training with free camera trajectories. In CVPR, 2023.
- Neus-2:Fast learning of neural implicit surfaces for multi-view reconstruction. In ICCV, 2023. 3
- Volume rendering of neural implicit surfaces. In NeurIPS, 2021
- 提升速度
- Direct Voxel Grid Optimization: Super-fast Convergence for RadianceFields Reconstruction
- KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPS
- PlenOctrees for Real-time Rendering of Neural Radiance Fields
- Instant Neural Graphics Primitives with a Multiresolution Hash Enco ding
- Real-Time Neural Light Field on Mobile Devices
- TensoRF:Tensorial Radiance Fields
- MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
- Plenoxels: Radiance Fields without Neural Networks
- Baking Neural Radiance Fields for Real-Time View Synthesis
- MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
- 动态场景重建
- HexPlane: A Fast Representation for Dynamic Scenes
- K-Planes: Explicit Radiance Fields in Space, Time, and Appearance
- Monocular Dynamic View Synthesis: A Reality Check
- Efficient Neural Radiance Fields for Interactive Free-viewpoint Video
- Robust Dynamic Radiance Fields
- HumanNeRF: Free-viewpoint Rendering of Moving People from Monocular Video
- 大型场景重建
- Block-NeRF
- Mega-NeRF
- BungeeNeRF
- Grid-NeRF
- Switch-NeRF
BlockNeRF 将城市划分为多个块,并根据其位置分配训练视图。Mega-NeRF使用基于网格划分,并将图像每个像素分配给其光线通过不同网格。与这些启发式分区策略不同,Switch-NeRF 引入了混合 NeRF 专家框架来学习场景分解。Grid-NeRF 不执行场景分解,而是使用基于 NeRF 和基于网格方法集成。虽然与传统方法相比,这些方法的渲染质量有了显着提高,但它们仍然缺乏细节并缓慢渲染。最近,3D Gaussian Splatting 引入了一种富有表现力的显式3D表示,在1080p分辨率下具有高质量和实时渲染。然而,将其扩展到大型场景并非易事。我们的 VastGaussian 是第一个使用新颖场景分区、优化和合并设计来做到这一点的人。
Varying Appearance Modeling
在改变光照或不同相机设置(如自动曝光、自动白平衡和色调映射)下,基于图像重建的外观变化是一个常见问题。NRW以具有对比损失的数据驱动方式训练外观编码器,该编码器以延迟着色深度缓冲区作为输入并产生外观嵌入(AE)。NeRF-W将AE附加到射线行进中基于点的特征上,并将其馈送到MLP中以获得最终颜色,这在许多基于NeRF方法中成为标准做法。Ha-NeRF使AE成为跨不同视图全局表示,并以视图一致损失方式学习AE。在VastGaussian模型中,我们将AE与渲染图像连接起来,将它们馈送到CNN中以获得转换映射,并使用转换映射来调整渲染图像以适应外观变化。
Preliminaries
3DGS 通过一组 3D Gaussians G表示几何和外观。每个3D高斯的特征在于其位置、各向异性协方差、透明度和视图相关颜色的球面谐波系数。在渲染过程中,将每个 3D 高斯投影到图像空间作为 2D 高斯。投影的二维高斯分布被分配到不同的贴图上,以基于 point-based volume 方式对渲染图像进行排序和alpha混合。

Method
3DGS在小型和以对象为中心的场景中工作得很好,但当扩展到大型环境时,由于视频内存限制、长时间优化和外观变化,它会遇到困难。在本文中,我们将3DGS扩展到大型场景,以实现实时和高质量的渲染。我们建议将一个大型场景划分为多个单元,这些单元在单独优化后合并。
Progressive Data Partitioning
我们将一个大型场景划分为多个单元,并将点云P和视图V的部分分配给这些单元进行优化。这些单元中的每一个都包含较少数量的 3D 高斯,更适合内存容量较低的优化,并且并行优化时需要更少训练时间。我们的渐进数据分区策略管道如图3所示。
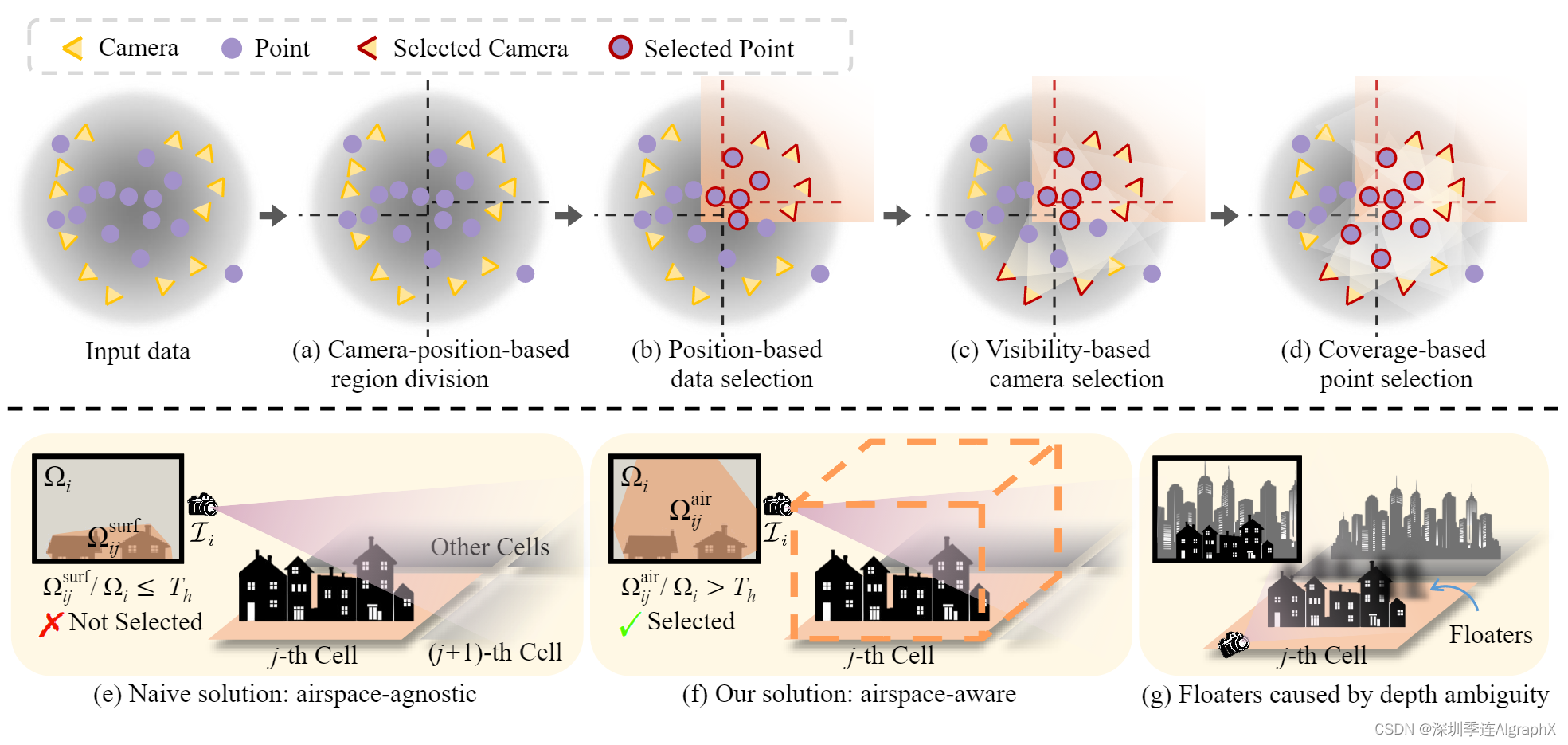
图3,渐进数据分区。上排:(a)基于投影在地平面上的2D相机位置,将整个场景划分为多个区域。(b)部分训练摄像机和点云根据其扩大的边界分配到特定区域。(c)根据空域感知能见度标准,选择更多的训练摄像机来减少漂浮物,如果摄像机在该区域具有足够的能见度,则选择该摄像机。(d)如果点云更多点被选定的相机观察到,则它们被合并以更好地初始化3D高斯。下排:两个可见度定义,以选择更多的训练相机。(e)一种朴素的方法:定义第i台摄像机在第j个单元格上的可见性为Ωsurf/ij /Ωi,其中Ωi为图像Ii的面积,Ωsurf/ij为第j个单元格中曲面点投影到Ii上形成的凸面积。(f)我们的空域感知解决方案:凸面积Ωair/ij是根据Ii中第j个单元格边界框投影计算的。(g)深度模糊和点初始化不当导致的漂浮物,如果没有训练相机的充分监督,就无法消除。
Camera-position-based region division
如图3(a)所示,我们根据地平面上投影的摄像机位置对场景进行划分,使每个单元包含相似数量的训练视图,以确保在相同迭代次数下不同单元之间的平衡优化。不失一般性,假设 m × n 单元网格很好地符合所讨论场景,我们首先将地平面沿一个轴划分为 m 个部分,每个部分包含大约 |V|/m 个视图。然后这些部分中每一个都进一步细分为沿另一个轴 n 个段,每个片段包含大约 |V|/(m × n)视图。虽然这里我们以基于网格划分为例,但划分策略也适用于其他基于地理划分方法,如扇区化和四叉树。
Position-based data selection
如图 3(b) 所示,我们在扩展其边界后为每个单元分配部分训练视图 V 和点云 P。具体来说,设第 j 个区域在 ℓh/j × ℓw/j 矩形中有界;本文中的原始边界按一定百分比扩展 20%,导致更大的矩形大小为 (ℓh/j +0.2ℓh/j )×(ℓw/j +0.2ℓw/j )。我们根据扩展的边界将训练视图 V 划分为 {Vj }m×n/j=1,并以相同方式将点云 P 分割成 {Pj }。
Visibility-based camera selection
我们发现上一步中选择的摄像机不足以进行高保真重建,这可能导致细节差或漂浮物伪影。为了解决这个问题,我们建议基于可见性标准添加更多相关相机,如图 3(c) 所示。给定一个尚未选择的相机Ci,设Ωij为图像Ii中第j个单元投影面积,设Ωi为Ii面积,可见性定义为Ωij /Ωi。选择能见度值大于预定义阈值Th的摄像机。
请注意,不同方法计算 Ωij 会导致不同的相机选择。如图3(e)所示,自然朴素的解决方案是基于分布在物体表面的3D点。它们被投影到Ii上,形成一个Ωsurf/ij区域的凸包。这种计算与空域无关,因为它只考虑表面。因此,在此计算中,由于某些相关相机对第 j 个单元的可见性较低,导致空域监督不足,无法抑制空气中的漂浮物。
我们引入了空域感知可见性计算,如图3(f)所示。具体来说,轴对齐的边界框由第 j 个单元格中的点云形成,其高度被选为最高点和地平面之间的距离。我们将边界框投影到Ii上,得到一个凸包区域Ωair/ij。这种空域感知解决方案考虑了所有可见空间,确保给定适当的可见性阈值,选择对该单元优化有重要贡献的观点,并为空域提供足够的监督。
Coverage-based point selection
在第j单元格的摄像机集Vj中添加更多相关摄像机后,我们将Vj中所有视图所覆盖的点添加到Pj中,如图3(d)所示。新选择的点可以为优化该单元提供更好的初始化。如图3(g)所示,Vj中的一些视图可以捕获第j个单元外的一些对象,并在错误的位置生成新的3D高斯来拟合这些对象,因为深度模糊而没有适当的初始化。然而,通过添加这些对象点进行初始化,可以轻松创建正确位置的新 3D 高斯来拟合这些训练视图,而不是在第 j 个单元中生成漂浮物。请注意,单元外生成的 3D 高斯在单元优化后被删除。
Decoupled Appearance Modeling
在光照不均匀情况下拍摄图像存在明显外观变化,3DGS倾向于产生漂浮物来补偿不同视图之间的这些变化,如图2(a-d)所示。
为了解决这个问题,一些基于 NeRF 方法将外观嵌入连接到像素级光线行进中基于点的特征,并将它们馈送到 MLP 以获得最终颜色。这不适用于3DGS,其渲染由没有逐帧光栅化 MLP 执行。相反,我们将解耦的外观建模引入到优化过程中,生成变换图来调整渲染图像以适应训练图像的外观变化,如图4所示。

图4,解耦外观建模。渲染后的图像Ir/i被下采样到较小分辨率,通过可优化的外观嵌入ℓi以逐像素的方式连接得到Di,然后输入CNN 生成变换映射Mi。Mi用于对Ir/i进行外观调整以得到外观变化的图像Ia/i,该图像Ia/i用于根据地面真值Ii计算损失L1,而Ir/i用于计算D-SSIM损失。
具体来说,我们首先对渲染图像Ir/i进行下采样,不仅防止变换图学习高频细节,而且减少了计算负担和内存消耗。然后,我们将长度为 m 的外观嵌入 ℓi 连接到三通道下采样图像中的每个像素,并获得具有 3 + m 通道的 2D 地图 Di。Di 被送入卷积神经网络 (CNN),它逐步对 Di 进行上采样以生成与 Ir/i 具有相同分辨率的 Mi。最后,通过对Mi的Ir/i进行像素级变换T,得到外观变化图像Ia/i:
![]()
在我们的实验中,一个简单的像素级乘法在我们使用的数据集上表现良好。使用由式(1)修正的损失函数,对外观嵌入和CNN与三维高斯函数一起进行优化:
![]()
由于 LD-SSIM 主要惩罚结构差异,将其应用于 Ir/i 和地面真值 Ii 使 Ir/i 中的结构信息接近 Ii,使外观信息由 ℓi 和 CNN 学习。损失 L1 应用于外观变化渲染 Ia/i 和 Ii 之间,用于拟合可能与其他图像外观变化的地面实况图像 Ii。训练后,Ir/i 有望与其他图像具有一致的外观,从中 3D 高斯可以学习所有输入视图的平均外观和正确的几何形状。
这种外观建模可以在优化后被丢弃,而不会减慢实时渲染速度。
Seamless Merging
在独立优化所有单元后,我们需要合并它们以获得完整场景。对于每个优化单元,我们在边界扩展之前删除原始区域(图 3(a))之外的 3D 高斯。否则,它们可以成为其他单元中的漂浮物。然后我们合并这些非重叠单元的 3D 高斯。合并场景在外观和几何形状上是无缝的,没有明显的边界伪影,因为在我们的数据分区中,一些训练视图在相邻单元之间是通用的。因此,不需要像Block-NeRF那样进行进一步的外观调整。合并场景中包含的 3D 高斯总数可以大大超过整体训练场景,从而提高重建质量。
Experiments
Experimental Setup
Implementation.我们在主要实验中用 8 个单元格评估我们的模型。可见性阈值为 25%。渲染图像在与长度为 64 的外观嵌入连接之前被下采样 32 倍。每个单元格都经过 60, 000 次迭代的优化密度控制从第 1, 000 次迭代开始,并在第 30, 000 次迭代结束,间隔为 200 次迭代。其他设置与 3DGS 的设置相同。外观嵌入和 CNN 都使用 0.001 的学习率。我们执行Manhattan世界对齐以使世界坐标轴垂直于地平面。我们附录中描述了 CNN 架构。

Datasets.实验是在五个大型场景上进行的:Rubble 和 Building 来自 Mill-19 数据集,Campus、Residence 和 Sci-Art来自 UrbanScene3D 数据集。每个场景包含数千个高分辨率图像。我们按照Mega-NeRF、Switch-NeRF的方法对图像进行4次下采样以进行训练和验证,以便进行公平的比较。
Metrics.我们使用三种量化指标评估渲染质量:SSIM、PSNR和基于AlexNet的LPIPS。上述光度变化使得评估变得困难,因为不确定应该复制哪种光度条件。为了解决这个问题,我们遵循 Mip-NeRF 360 在评估所有方法的指标之前对渲染图像执行颜色校正,这解决了每个图像最小二乘问题来对齐渲染图像与其对应的地面实况之间的 RGB 值。我们还报告了1080p分辨率的渲染速度、平均训练时间和视频内存消耗。
Compared methods.我们将VastGaussian与Mega-NeRF, Switch-NeRF, GridNeRF和3DGS四种方法进行了比较。对于 3DGS,我们需要增加优化迭代以使其在我们的主要实验中具有可比性,但朴素地这样做会导致内存不足错误。因此,我们相应地增加密度间隔以构建可行的基线(称为 Modified 3DGS)。其他配置与原始 3DGS 论文相同。对于Grid-NeRF,由于其机密性要求,其代码发布时没有渲染图像和精心调整的配置文件。这些不可用的文件对其性能至关重要,使其结果无法重现。因此,我们只使用它的代码来评估它的训练时间、内存和渲染速度,而质量指标是从它的论文中复制的。
Result Analysis

表1,定量评估。我们报告了测试视图上的SSIM↑、PSNR↑和LPIPS↓。最好和第二好的结果被突出显示。“-”表示Grid-NeRF论文中缺失的数据。

表2,训练时间、训练视频内存消耗(VRAM)和渲染速度比较

图5,与前人工作定性比较,漂浮物由绿色箭头指出。
基于NeRF的方法缺乏细节并产生模糊的结果。修改后的3DGS具有更清晰的渲染,但会产生令人不快的浮动。我们的方法实现了干净和视觉愉悦的渲染。请注意,由于某些测试图像中明显的过度曝光或曝光不足,VastGaussian表现出略低的PSNR值,但产生了明显更好的视觉质量,有时甚至比地面真值更清晰,如图5中第1行示例。VastGaussian高质量部分归功于其大量的3D高斯。以校园场景为例,Modified 3DGS中的3D高斯数为890万,而VastGaussian为2740万。
Ablation Study
我们对 Sci-Art 场景进行了消融研究,以更全面评估 VastGaussian。
Data partition. 如图 6 和表 3 所示。基于可见性相机选择(VisCam)和基于覆盖点选择(CovPoint)都可以提高视觉质量。如果没有它们中的任何一个或两个,就可以在单元的空域中创建漂浮物,以适应单元外的观察区域。
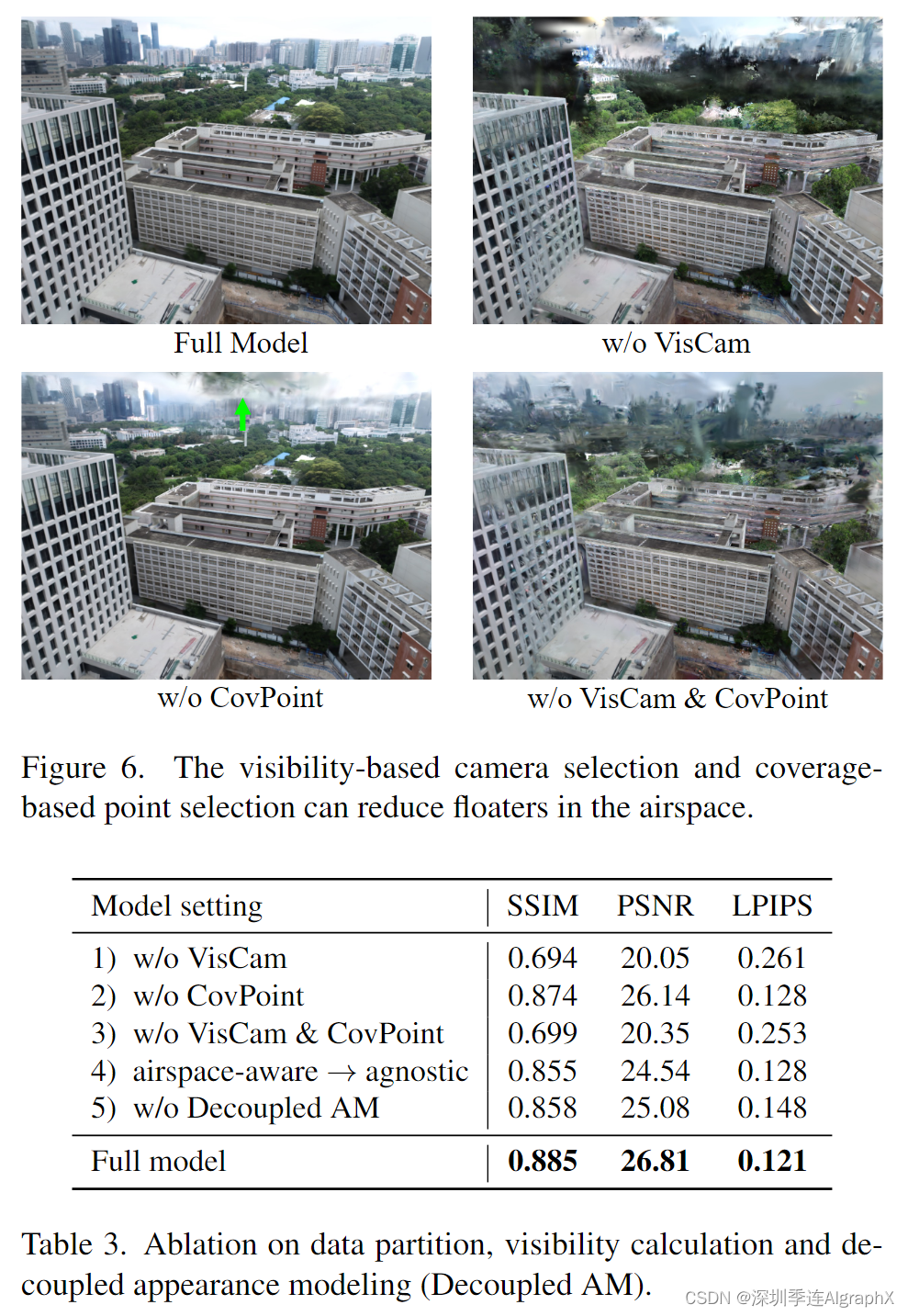
如图 7 所示,基于可见度的摄像机选择可以确保相邻单元之间有更多的公共摄像机,这消除了未实现时外观跳跃的明显边界伪影。

Airspace-aware visibility calculation. 如表 3 的第 4 行和图 8 所示。基于空域感知能见度计算而选择的摄像机为单元的优化提供了更多的监督,从而不会产生在以空域不可知的方式计算能见度时出现的漂浮物。

Decoupled appearance modeling. 如图 2 和表 3 第 5 行所示。我们的解耦外观建模减少了渲染图像的外观变化。因此,3D高斯可以从具有外观变化的训练图像中学习一致的几何和颜色,而不是创建漂浮物来补偿这些变化。另请参考附录中的视频。
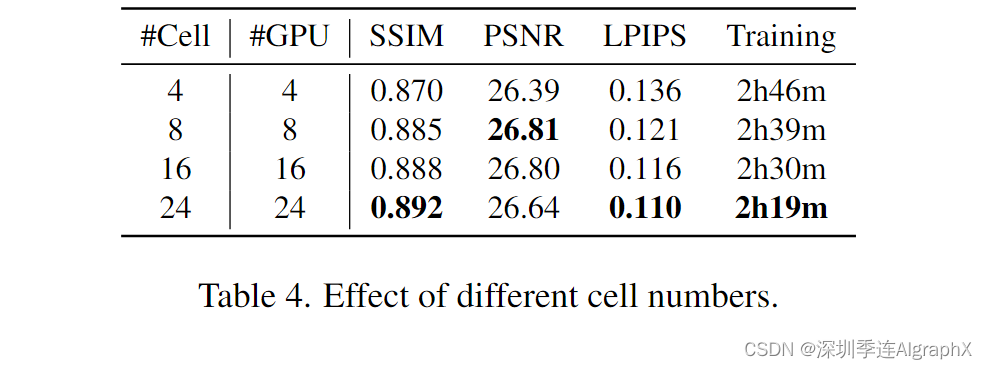
Different number of cells. 如表中 4 所示。在VastGaussian模型中,更多的单元重构出更好的细节,从而获得更好的SSIM和LPIPS值,并且在单元并行优化时可以缩短训练时间。但是,当单元数达到 16 或更大时,质量改进变为边际,而且由于距离较远的单元在渲染图像中可能会逐渐发生亮度变化,因此PSNR会略有下降。
Conclusion and Limitation
在本文中,我们提出了VastGaussian,这是第一个大规模场景下的高质量重建和实时渲染方法。引入的渐进式数据分区策略允许独立的单元优化和无缝合并,获得具有足够 3D 高斯的完整场景。我们的外观建模解耦了训练图像的外观变化,并使不同视图的一致渲染成为可能。该模块可以在优化后被丢弃,以获得更快的渲染速度。虽然我们 VastGaussian 可以应用于任何形状的空间划分,但我们没有提供应该考虑场景布局、单元数和训练相机分布的最佳划分解决方案。此外,当场景很大时,有很多 3D 高斯,这可能需要大量的存储空间并显著降低渲染速度。
本文由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑。如有错误,欢迎在评论区指正。
论文名称:VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction.
论文地址:https://arxiv.org/abs/2402.17427
相关文章:
51-31 CVPR’24 | VastGaussian,3D高斯大型场景重建
2024 年 2 月,清华大学、华为和中科院联合发布的 VastGaussian 模型,实现了基于 3D Gaussian Splatting 进行大型场景高保真重建和实时渲染。 Abstract 现有基于NeRF大型场景重建方法,往往在视觉质量和渲染速度方面存在局限性。虽然最近 3D…...

GPT-4引领AI新纪元,Claude3、Gemini、Sora能否跟上步伐?
【最新增加Claude3、Gemini、Sora、GPTs讲解及AI领域中的集中大模型的最新技术】 2023年随着OpenAI开发者大会的召开,最重磅更新当属GPTs,多模态API,未来自定义专属的GPT。微软创始人比尔盖茨称ChatGPT的出现有着重大历史意义,不亚…...

图书馆RFID(射频识别)数据模型压缩/解压缩算法实现小工具
1. 前言 最近闲来无聊,看了一下《图书馆射频识别数据模型第1部分:数据元素的设置及应用规则》以及《图书馆射频识别数据模型第2部分:基于ISO/IEC 15962的数据元素编码方案》,决定根据上面的编码方法实现一下该算法,于…...

【Java Web基础】一些网页设计基础(三)
文章目录 1. 导航栏样式进一步调整2. 入驻企业信息展示栏2.1 Title设置2.2 具体信息添加 3. 轮播图4. 注册登录按钮及其他信息5. 一些五颜六色的、丰富视觉效果的中间件…… 1. 导航栏样式进一步调整 这种导航栏,选中的时候字体变蓝色,可能还是不够美观&…...
2 使用GPU理解并行计算
2.1 简介 本章旨在对并行程序设计的基本概念及其与GPU技术的联系做一个宽泛的介绍。本章主要面向具有串行程序设计经验,但对并行处理概念缺乏了解的读者。我们将用GPU的基本知识来讲解并行程序设计的基本概念。 2.2 传统的串行代码 绝大多数程序员是在串行程序占据…...

Android什么情况下会出现内存泄漏以及怎么解决?
1.什么情况下会出现内存泄漏? (1)单例模式下为什么会造成内存泄漏? 因为单例的生命周期和应用的生命周期是一致的,如果往单例模式里面传了一个生命周期比较短的对象,比如Activity,就会导致Activity不能释放,导致内存泄漏。我们可以传context.getAppliactionContext,而…...
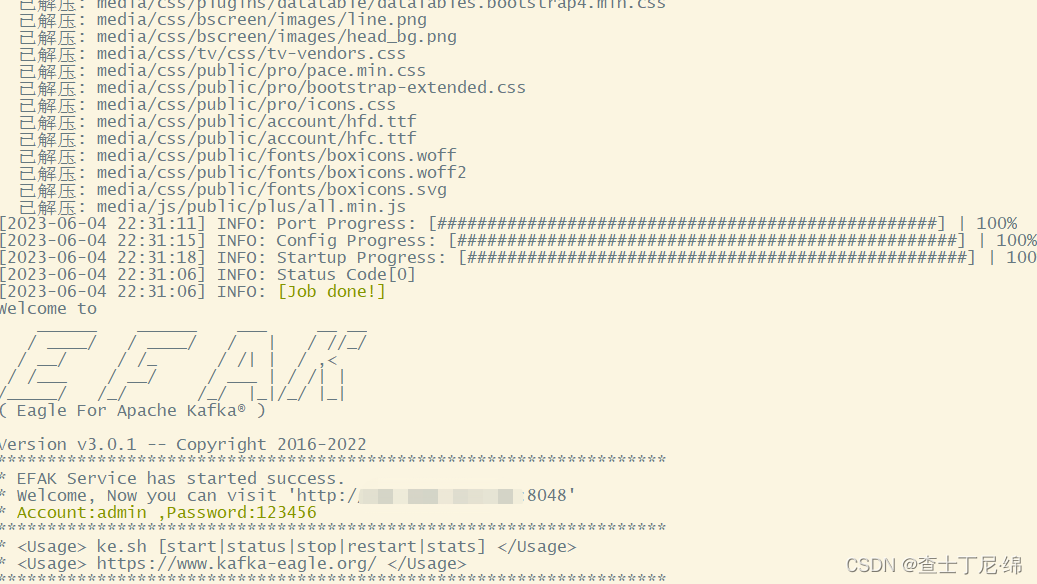
kafka集群介绍及搭建
介绍 kafka是一个高性能、低延迟、分布式的消息传递系统,特点在于实时处理数据。集群由多个成员节点broker组成,每个节点都可以独立处理消息传递和存储任务。 路由策略 发布消息由key、value组成,真正的消息是value,key是标识路…...
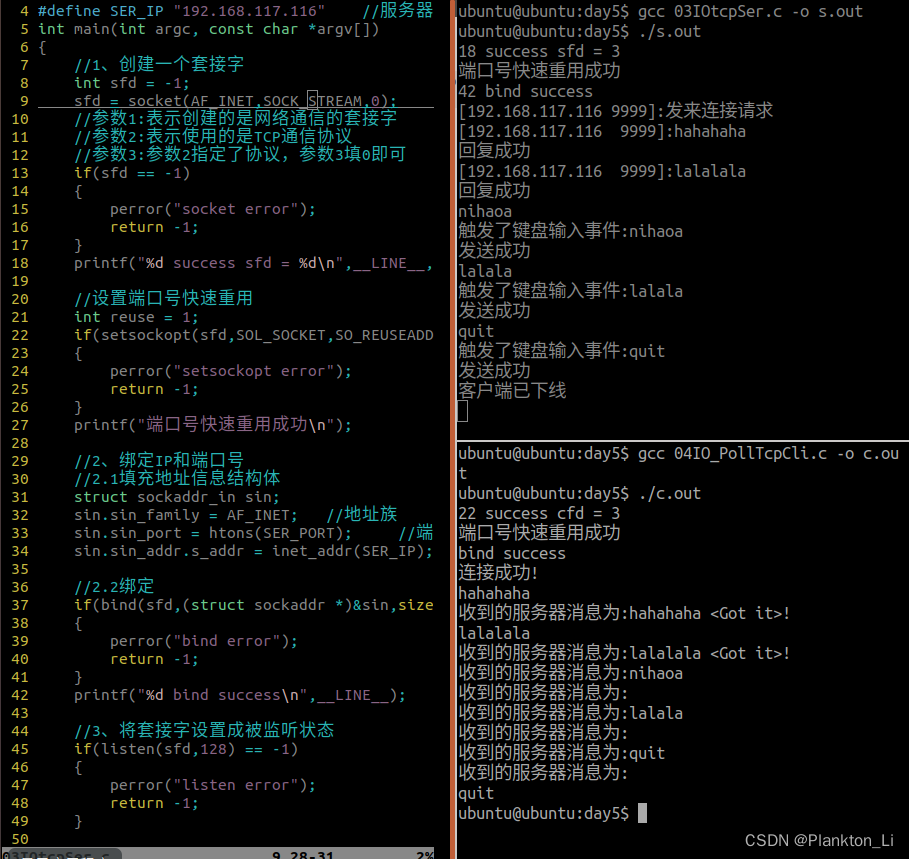
2024/03/19(网络编程·day5)
一、思维导图 二、selec函数实现TCP并发服务器 #include<myhead.h>#define SER_PORT 8888 //服务器端口号 #define SER_IP "192.168.117.116" //服务器IP int main(int argc, const char *argv[]) {//1、创建一个套接字int sfd -1;sfd socket(AF_INET,SOC…...

LeetCode解法汇总1969. 数组元素的最小非零乘积
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:. - 力扣(LeetCode) 描述: 给你一个正整数 p 。你有一个下标从 1 开…...
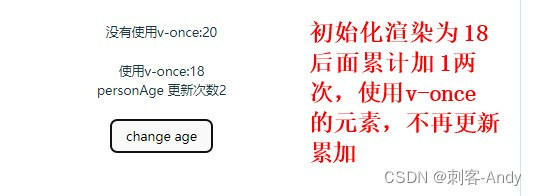
学习vue3第九节(新加指令 v-pre/v-once/v-memo/v-cloak )
1、v-pre 作用:防止编译器解析某个特定的元素及其内容,即v-pre 会跳过当前元素以及其子元素的vue语法解析,并将其保持原样输出; 用于:vue 中一些没有指令和插值表达式的节点的元素,使用 v-pre 可以提高 Vu…...
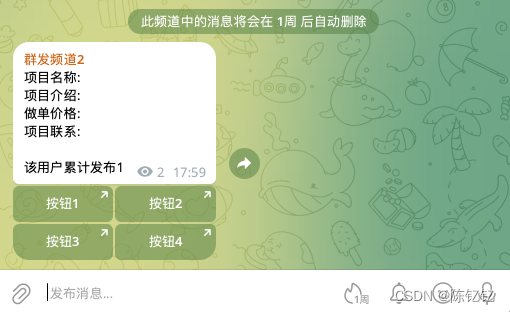
二开飞机机器人群发,实现自动给多个频道发送消息
频道1 频道2 二开代码部分: const CChatIdListprocess.env.CHANNEL_CHAT_ID_LIST; var channelChatIdArray CChatIdList.split(,);channelChatIdArray.forEach(function(item) {console.log(item); // 这里可以替换为您需要对数组中每个值进行的操作bot.sendM…...

AI如何支持慈善组织
为各种有意义的事业提供支持,无论是努力寻找治愈疾病的方法、研发使生活更轻松的技术,还是为有需要的人提供服务,都是无比崇高的使命。提供捐款或是投入时间支持的捐助者和志愿者往往对他们选择支持的事业的目标、服务和资源分配存有诸多疑虑…...
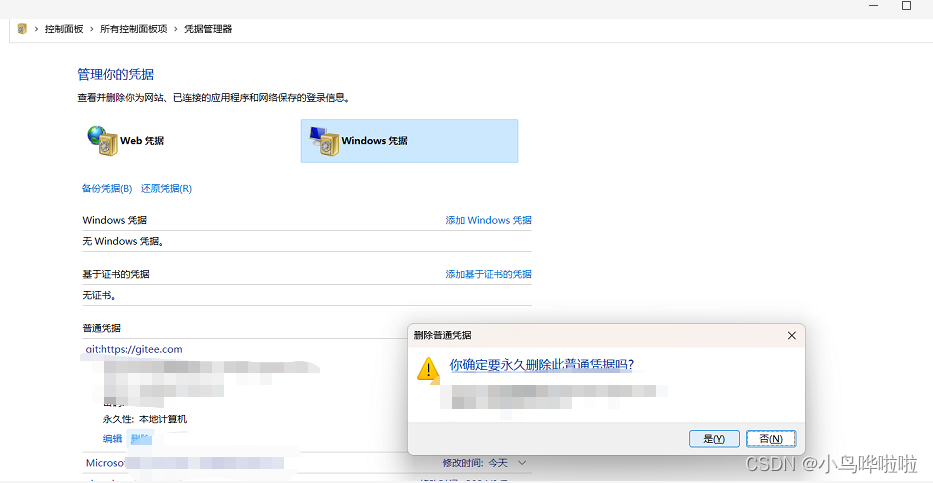
Git如何清除账户凭证
场景:一般发生在Git用户变更的情况 1.git base 操作 Git会使用凭证助手 credential.helper来储存账户凭证,通过以下命令移除: git config --system --unset credential.helper 除了system系统级外,还有 global、local范围。 查…...
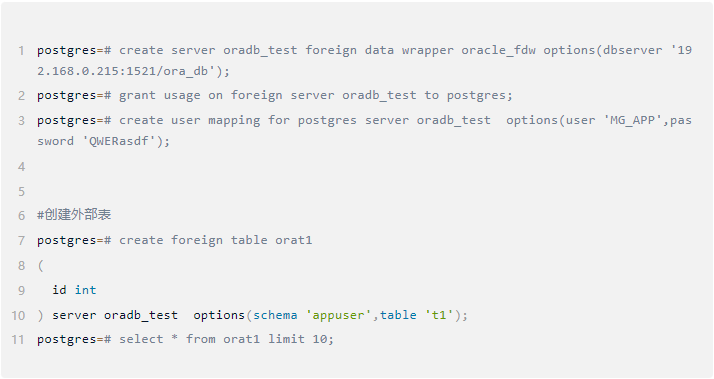
【YUNBEE云贝-PostgreSQL】FDW应用
注: 本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。 前言 Wrapper(FDW)是一项关键特性,它赋予数据库用户直接通过SQL语句访问存储于外部数据源的能…...

Spring MVC文件上传配置
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 文件上传 Spring MVC文件上传基于Servlet 3.0实现;示例代码如下: Overrideprotected void customizeRegistration(ServletRegistration.Dynamic reg…...
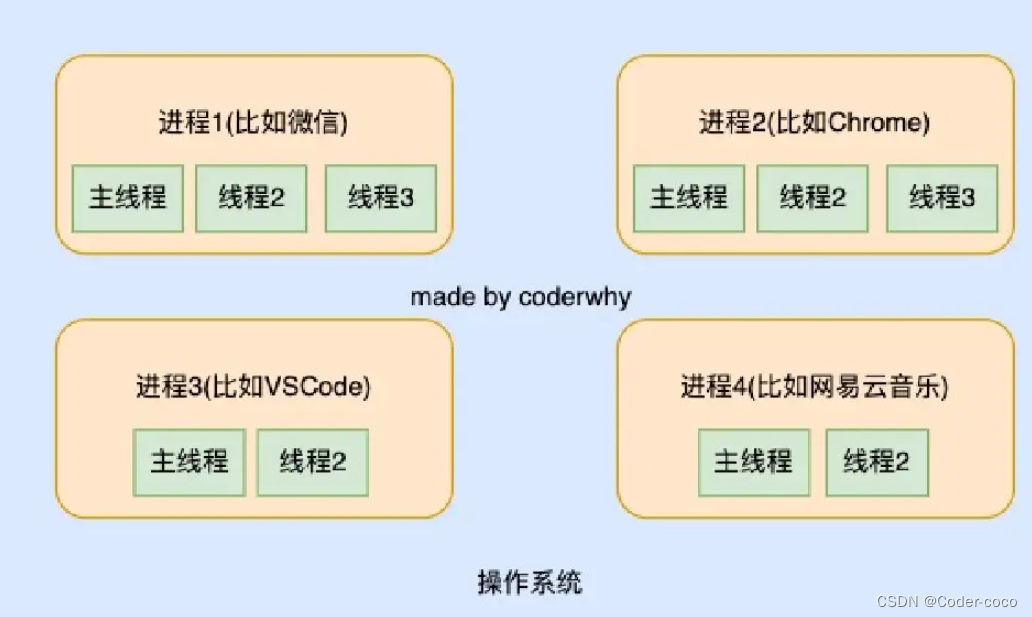
JavaScript高级(十八)---进程和线程,宏任务和微任务
进程和线程 进程(process):计算机已经运行的程序,是操作系统管理程序的一种方式,我们可以认为,启动一个应用程序,就会默认启动一个进程(也可能是多个进程)。 线程&…...

How to install mongodb on redhat 7.7
下载rpm: mongodb-enterprise-server-6.0.3-1.el7.x86_64.rpmmongodb-org-server-6.0.4-1.el7.x86_64.rpmmongodb-mms-6.0.9.100.20230201T2148Z.x86_64.rpm rpm -ivh mongodb-org-server-6.0.4-1.el7.x86_64.rpm rpm -ivh mongodb-mms-6.0.9.100.20230201T2148Z.x86_64.rpm …...
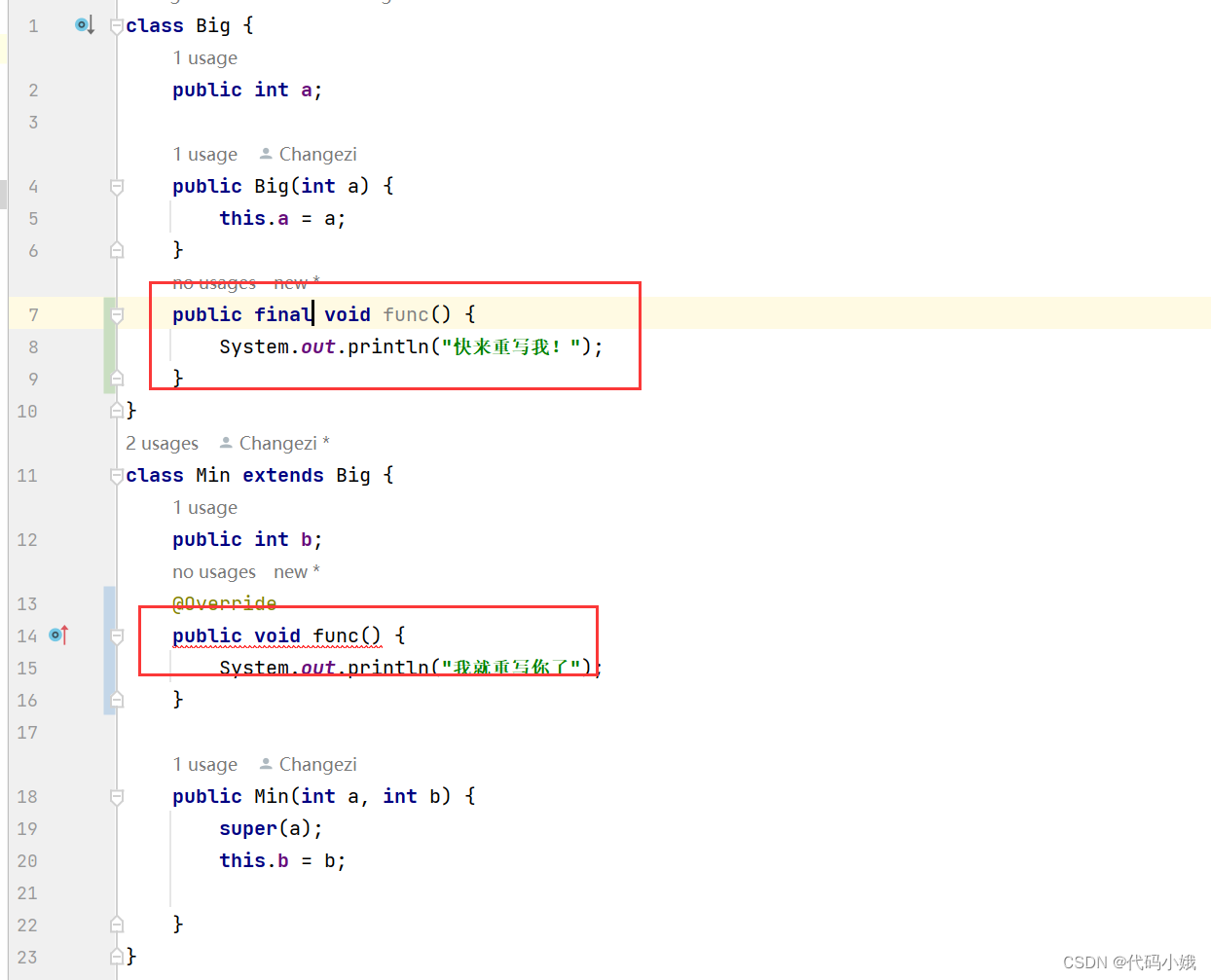
关于继承是怎么样的?那当然是很好理解之
本文描述了关于继承的大部分知识,但是并不全,每篇博客之间的知识都有互串,所以需要把几篇文章合起来看,学会融会贯通! 温馨提示:使用PC端观看,效果更佳! 目录 1.继承是什么 2.什…...
高可用系统有哪些设计原则
1.降级 主动降级:开关推送 被动降级:超时降级 异常降级 失败率 熔断保护 多级降级2.限流 nginx的limit模块 gateway redisLua 业务层限流 本地限流 gua 分布式限流 sentinel 3.弹性计算 弹性伸缩—K8Sdocker 主链路压力过大的时候可以将非主链路的机器给…...

LeetCode-回文数
LeetCode-回文数 解体思路: ①第一种:转换成字符串,使用字符串的现有api方法进行反转 ②第二种:直接使用循环除余乘10方法,进行反转 涉及知识点: 循环判断,StringBuffer,int类型…...

8大网盘直链解析神器:告别限速,轻松获取真实下载地址的完整指南
8大网盘直链解析神器:告别限速,轻松获取真实下载地址的完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 /…...

玄机靶场:供应链安全-供应链应急-Part2 通关笔记
供应链安全-供应链应急-Part2 通关笔记 题目背景 本题是供应链安全应急响应的第二部分,主要考察对Gitea代码仓库和Jenkins持续集成环境的综合分析能力。黑客通过某种手段获取了开发者的Gitea Token,进而对多个代码仓库进行了恶意篡改,并在J…...
)
Docker沙箱配置实战手册(生产环境零事故配置模板)
第一章:Docker沙箱配置的核心价值与生产级定位Docker沙箱并非仅用于开发环境的临时隔离机制,而是现代云原生基础设施中保障服务可预测性、安全边界与部署一致性的关键执行层。在生产环境中,一个经过严谨配置的Docker沙箱,实质上构…...

混合系统建模:离散与连续动态的融合与应用
1. 混合系统基础概念解析混合系统(Hybrid Systems)是同时包含离散和连续动态行为的数学模型,在信息物理系统(CPS)建模中具有核心地位。这类系统通过有限状态机描述离散的模式切换,用微分方程刻画连续状态演…...

Semi.Avalonia完整指南:5个步骤打造现代化跨平台UI界面
Semi.Avalonia完整指南:5个步骤打造现代化跨平台UI界面 【免费下载链接】Semi.Avalonia Avalonia theme inspired by Semi Design 项目地址: https://gitcode.com/gh_mirrors/se/Semi.Avalonia 你是否正在为Avalonia项目寻找一个既美观又实用的主题库&#x…...

5分钟掌握开源自动化神器:零基础快速上手指南
5分钟掌握开源自动化神器:零基础快速上手指南 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 还在为重复的鼠标…...
)
从振荡到稳定:手把手教你用Python分析运放偏置电流测量数据(附完整代码)
从振荡到稳定:Python自动化分析运放偏置电流的工程实践 在电子测量领域,运算放大器的偏置电流参数对高精度电路设计至关重要。传统手动测量方法不仅效率低下,面对多组开关状态和振荡数据时更易引入人为误差。本文将分享一套完整的Python数据分…...

C++编程语言基础与核心特性详解
1. C语言概述与基础语法C是一种通用编程语言,由Bjarne Stroustrup于1980年代在贝尔实验室开发。作为C语言的扩展,C在保持高效性的同时引入了面向对象编程(OOP)特性。它广泛应用于系统/应用软件开发、游戏引擎、高频交易等领域&…...

终极解密指南:如何快速免费解密RPG Maker加密文件?
终极解密指南:如何快速免费解密RPG Maker加密文件? 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirr…...

Arduino UNO变身迷你信号发生器:基于MCP4725 DAC的正弦波/三角波生成全攻略
Arduino UNO与MCP4725 DAC打造迷你信号发生器实战指南 在电子制作和音频实验领域,信号发生器是不可或缺的基础工具。传统台式信号发生器虽然功能强大,但价格昂贵且体积庞大。本文将展示如何用Arduino UNO搭配MCP4725 DAC模块,打造一个成本不到…...