【计算机视觉】三、图像处理——实验:图像去模糊和去噪、提取边缘特征
文章目录
- 0. 实验环境
- 1. 理论基础
- 1.1 滤波器(卷积核)
- 1.2 PyTorch:卷积操作
- 2. 图像处理
- 2.1 图像读取
- 2.2 查看通道
- 2.3 图像处理
- 3. 图像去模糊
- 4. 图像去噪
- 4.1 添加随机噪点
- 4.2 图像去噪

0. 实验环境
本实验使用了PyTorch深度学习框架,相关操作如下:
conda create -n DL python==3.11
conda activate DL
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
conda install matplotlib
conda install pillow numpy
| 软件包 | 本实验版本 |
|---|---|
| matplotlib | 3.8.0 |
| numpy | 1.26.3 |
| pillow | 10.0.1 |
| python | 3.11.0 |
| torch | 2.1.2 |
| torchaudio | 2.1.2 |
| torchvision | 0.16.2 |
1. 理论基础
二维卷积运算是信号处理和图像处理中常用的一种运算方式,当给定两个二维离散信号或图像 f ( x , y ) f(x, y) f(x,y) 和 g ( x , y ) g(x, y) g(x,y),其中 f ( x , y ) f(x, y) f(x,y) 表示输入信号或图像, g ( x , y ) g(x, y) g(x,y) 表示卷积核。二维卷积运算可以表示为: h ( x , y ) = ∑ m ∑ n f ( m , n ) ⋅ g ( x − m , y − n ) h(x, y) = \sum_{m}\sum_{n} f(m, n) \cdot g(x-m, y-n) h(x,y)=m∑n∑f(m,n)⋅g(x−m,y−n)其中 ∑ m ∑ n \sum_{m}\sum_{n} ∑m∑n 表示对所有 m , n m, n m,n 的求和, h ( x , y ) h(x, y) h(x,y) 表示卷积后的输出信号或图像。
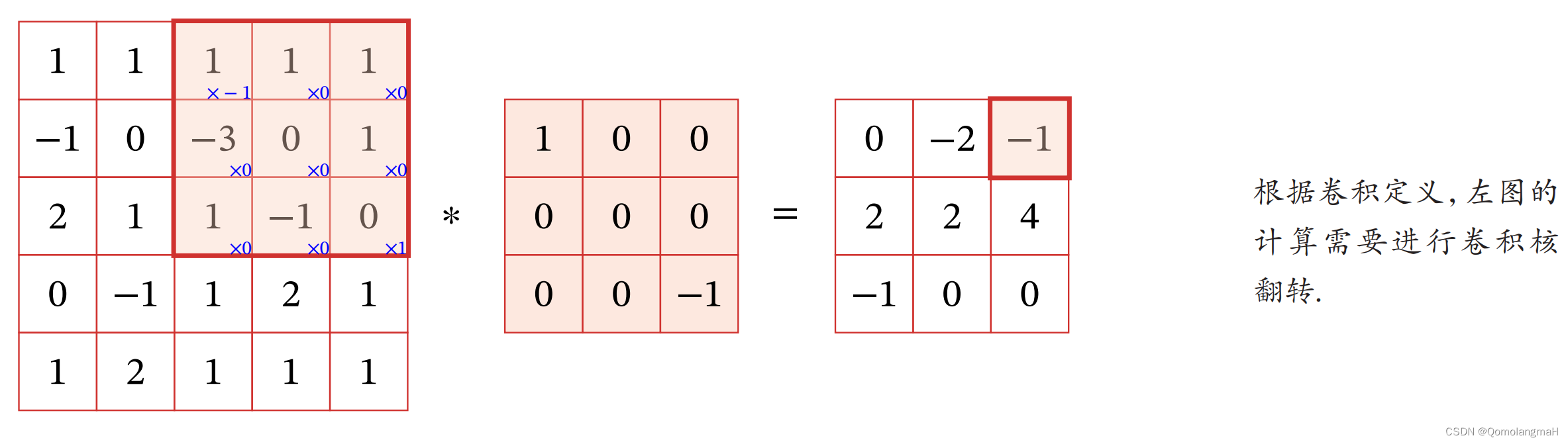
在数学上,二维卷积运算可以理解为将输入信号或图像 f ( x , y ) f(x, y) f(x,y) 和卷积核 g ( x , y ) g(x, y) g(x,y) 进行对应位置的乘法,然后将所有乘积值相加得到输出信号或图像 h ( x , y ) h(x, y) h(x,y)。这个过程可以用于实现一些信号处理和图像处理的操作,例如模糊、边缘检测、图像增强等。
详见:【深度学习】Pytorch 系列教程(七):PyTorch数据结构:2、张量的数学运算(5):二维卷积及其数学原理
1.1 滤波器(卷积核)
在图像处理中,卷积经常作为特征提取的有效方法.一幅图像在经过卷积操作后得到结果称为特征映射(Feature Map)。图5.3给出在图像处理中几种常用的滤波器,以及其对应的特征映射.图中最上面的滤波器是常用的高斯滤波器,可以用来对图像进行平滑去噪;中间和最下面的滤波器可以用来提取边缘特征。

# 高斯滤波~平滑去噪
conv_kernel1 = torch.tensor([[1/16, 1/8, 1/16],[1/8, 1/4, 1/8],[1/16, 1/8, 1/16]], dtype=torch.float).unsqueeze(0).unsqueeze(0)
# 提取边缘特征
conv_kernel2 = torch.tensor([[0, 1, 0],[1, -4, 1],[0, 1, 0]], dtype=torch.float).unsqueeze(0).unsqueeze(0)
conv_kernel3 = torch.tensor([[0, 1, 1],[-1, 0, 1],[-1, -1, 0]], dtype=torch.float).unsqueeze(0).unsqueeze(0)
print(conv_kernel1.size())
- 上述均为3x3的单通道卷积核,需要拓展为四维张量(PyTorch就是这么设计的~)
1.2 PyTorch:卷积操作
def conv2d(img_tensor, conv_kernel):convolved_channels = []for i in range(3):channel_input = img_tensor[:, i, :, :] # 取出每个通道的输入convolved = F.conv2d(channel_input, conv_kernel, padding=1) convolved_channels.append(convolved)# 合并各通道卷积后的结果output = torch.cat(convolved_channels, dim=1)# 将张量转换为NumPy数组,进而转换为图像output_img = output.squeeze().permute(1, 2, 0).numpy().astype(np.uint8)output_img = Image.fromarray(output_img)return output_img
2. 图像处理
2.1 图像读取
img = Image.open('1.jpg')
# img = img.resize((128, 128)) # 调整图像大小img_tensor = torch.tensor(np.array(img), dtype=torch.float).permute(2, 0, 1).unsqueeze(0)print(img_tensor.shape)
- 将图像转换为PyTorch张量:将通道顺序从HWC转换为CHW,并在第一个维度上增加一个维度~卷积操作使用四维张量
2.2 查看通道
本部分内容纯属没事儿闲的~
img = Image.open('1.jpg')
img_tensor = torch.tensor(np.array(img), dtype=torch.float).permute(2, 0, 1).unsqueeze(0)
channel1 = img_tensor[:, 0, :, :] # 提取每个通道
channel2 = img_tensor[:, 1, :, :]
channel3 = img_tensor[:, 2, :, :]
plt.figure(figsize=(12, 12))
plt.subplot(1, 4, 1)
plt.imshow(img)
plt.axis('off')
plt.subplot(1, 4, 2)
channel1_img = channel1.squeeze().numpy().astype(np.uint8)
channel1_img = Image.fromarray(channel1_img)
plt.imshow(channel1_img)
plt.axis('off')
plt.subplot(1, 4, 3)
channel2_img = channel2.squeeze().numpy().astype(np.uint8)
channel2_img = Image.fromarray(channel2_img)
plt.imshow(channel2_img)
plt.axis('off')
plt.subplot(1, 4, 4)
channel3_img = channel3.squeeze().numpy().astype(np.uint8)
channel3_img = Image.fromarray(channel3_img)
plt.imshow(channel3_img)
plt.axis('off')


2.3 图像处理
def plot_img(img_tensor): output_img1 = conv2d(img_tensor, conv_kernel1)output_img2 = conv2d(img_tensor, conv_kernel2)output_img3 = conv2d(img_tensor, conv_kernel3)plt.subplot(2, 2, 1)plt.title('原始图像', fontproperties=font)plt.imshow(img)plt.axis('off') plt.subplot(2, 2, 2)plt.title('平滑去噪', fontproperties=font)plt.imshow(output_img1)plt.axis('off') plt.subplot(2, 2, 3)plt.imshow(output_img2)plt.title('边缘特征1', fontproperties=font) plt.axis('off') plt.subplot(2, 2, 4)plt.imshow(output_img3)plt.title('边缘特征2', fontproperties=font) plt.axis('off') plt.show()
font = FontProperties(fname='C:\Windows\Fonts\simkai.ttf', size=16) # 使用楷体
plt.figure(figsize=(12, 12)) # 设置图大小12*12英寸
plot_img(img_tensor)


- 如图所示,图像提取边缘特征效果明显
- 但图片过于高清,plt输出的(12英寸)原始图像、平滑去噪图像都很模糊~,下面会先降低像素,然后进行去模糊去噪实验
- 原图为

3. 图像去模糊
img = Image.open('2.jpg')
img = img.resize((480, 480)) # 调小图像~先使原图变模糊
img_tensor = torch.tensor(np.array(img), dtype=torch.float).permute(2, 0, 1).unsqueeze(0)
conv_kernel4 = torch.tensor([[0, 0, 0],[0, 2, 0],[0, 0, 0]], dtype=torch.float).unsqueeze(0).unsqueeze(0)
conv_kernel5 = torch.ones(3, 3).unsqueeze(0).unsqueeze(0)/9
# print(conv_kernel4-conv_kernel5)
font = FontProperties(fname='C:\Windows\Fonts\simkai.ttf', size=32)
plt.figure(figsize=(32, 32))
plt.subplot(2, 2, 1)
plt.title('原始图像', fontproperties=font)
plt.imshow(img)
plt.axis('off')
plt.subplot(2, 2, 2)
plt.title('线性滤波-2', fontproperties=font)
plt.imshow(conv2d(img_tensor, conv_kernel4))
plt.axis('off')
plt.subplot(2, 2, 3)
plt.imshow(conv2d(img_tensor, conv_kernel5))
plt.title('均值滤波器:模糊', fontproperties=font)
plt.axis('off')
plt.subplot(2, 2, 4)
plt.imshow(conv2d(img_tensor, conv_kernel4-conv_kernel5))
plt.title('锐化滤波器:强调局部差异', fontproperties=font)
plt.axis('off')
plt.show()

4. 图像去噪
4.1 添加随机噪点
img = Image.open('1.jpg')
img = img.resize((640, 640)) # 调小图像~先使原图变模糊
img_tensor = torch.tensor(np.array(img), dtype=torch.float).permute(2, 0, 1).unsqueeze(0)noise = torch.randn_like(img_tensor) # 与图像相同大小的随机标准正态分布噪点
noisy_img_tensor = img_tensor + noise # 将噪点叠加到图像上
noisy_img = noisy_img_tensor.squeeze(0).permute(1, 2, 0).to(dtype=torch.uint8)
noisy_img = Image.fromarray(noisy_img.numpy())
4.2 图像去噪
# conv_kernel1 = torch.tensor([[1/16, 1/8, 1/16],
# [1/8, 1/4, 1/8],
# [1/16, 1/8, 1/16]], dtype=torch.float).unsqueeze(0).unsqueeze(0)
# # 生成随机3x3高斯分布
# random_gaussian = torch.randn(3, 3).unsqueeze(0).unsqueeze(0)
# print(random_gaussian)
font = FontProperties(fname='C:\Windows\Fonts\simkai.ttf', size=32) # 使用楷体
plt.figure(figsize=(32, 32))
plt.subplot(1, 3, 1)
plt.title('原始图像', fontproperties=font)
plt.imshow(img)
plt.axis('off')
plt.subplot(1, 3, 2)
plt.title('噪点图像', fontproperties=font)
plt.imshow(noisy_img)
plt.axis('off')
plt.subplot(1, 3, 3)
plt.title('去噪图像', fontproperties=font)
plt.imshow(conv2d(noisy_img_tensor, conv_kernel1))
plt.axis('off')
plt.show()

相关文章:
【计算机视觉】三、图像处理——实验:图像去模糊和去噪、提取边缘特征
文章目录 0. 实验环境1. 理论基础1.1 滤波器(卷积核)1.2 PyTorch:卷积操作 2. 图像处理2.1 图像读取2.2 查看通道2.3 图像处理 3. 图像去模糊4. 图像去噪4.1 添加随机噪点4.2 图像去噪 0. 实验环境 本实验使用了PyTorch深度学习框架,相关操作…...
用css滤镜做颜色不同的数据卡片(背景图对于css滤镜的使用)
<template> <div class"xx_modal_maincon"><div class"xx_model_bt">履约起始日至计算日配额及履约情况</div><el-row><el-col :span"6"><div class"xx_modal_mod"><div class"mod…...

2024年第六届区块链与物联网国际会议(BIOTC 2024)即将召开!
2024年第六届区块链与物联网国际会议(简称:BIOTC 2024)将于2024 年 7 月 19 日至 21 日在日本福冈召开,旨在为来自行业、学术界和政府的研究人员、从业者和专业人士提供一个论坛,就研发区块链和物联网的专业实践进行交…...
Django动态路由实例
Django动态路由实例 先说需求: 比如我前端有两个按钮,点击按钮1跳转到user1的用户信息页面,按钮2跳转user2用户信息页面,但是他俩共用同一个视图层 直接上代码 路由层 urlpatterns [path(user/<str:username>/, views…...

基于Vue.js和D3.js的智能停车可视化系统
引言 随着物联网技术的发展,智能停车系统正逐渐普及。前端作为用户交互的主要界面,对于提供直观、实时的停车信息至关重要。 目录 引言 一、系统设计 二、代码实现 1. 环境准备 首先,确保您的开发环境已经安装了Node.js和npm。然后&…...
数据之王国:解析Facebook的大数据应用
引言 作为全球最大的社交媒体平台之一,Facebook拥有庞大的用户群体和海量的数据资源。这些数据不仅包括用户的个人信息和社交行为,还涵盖了广告点击、浏览记录等多方面内容。Facebook通过巧妙地利用这些数据,构建了强大的大数据应用系统&…...
)
前端小白的学习之路(ES6 一)
提示:关键字声明:let与const,长度单位:em与rem,vw与wh,解构赋值,箭头函数(简介) 目录 一、ES6介绍 二、let&const 1.let 1) 用 let 关键字声明的变量不能提前引用 2) 不允许重复声明变量 3) 可以产生块级作用…...

Linux CentOS 7.6安装Redis 6.2.6 详细保姆级教程
1、安装依赖 //检查是否有依赖 gcc -v //没有则安装 yum install -y gcc2、下载redis安装包 //进入home目录 cd /home //通过wget下载redis安装包 wget https://download.redis.io/releases/redis-6.2.6.tar.gz //解压安装包 tar -zxvf redis-6.2.6.tar.gz3、编译 //进入解压…...

Android 优化 - 数据结构
一、概念 数据结构:数据存储在内存中的顺序和位置关系,选择合适的数据结构能提高内存的利用率。 线性结构链表结构树形结构 二、线性结构 结构优点缺点数组数据呈线性排列,初始化时就要指定长度且无法更改,会开辟一块连续的内…...
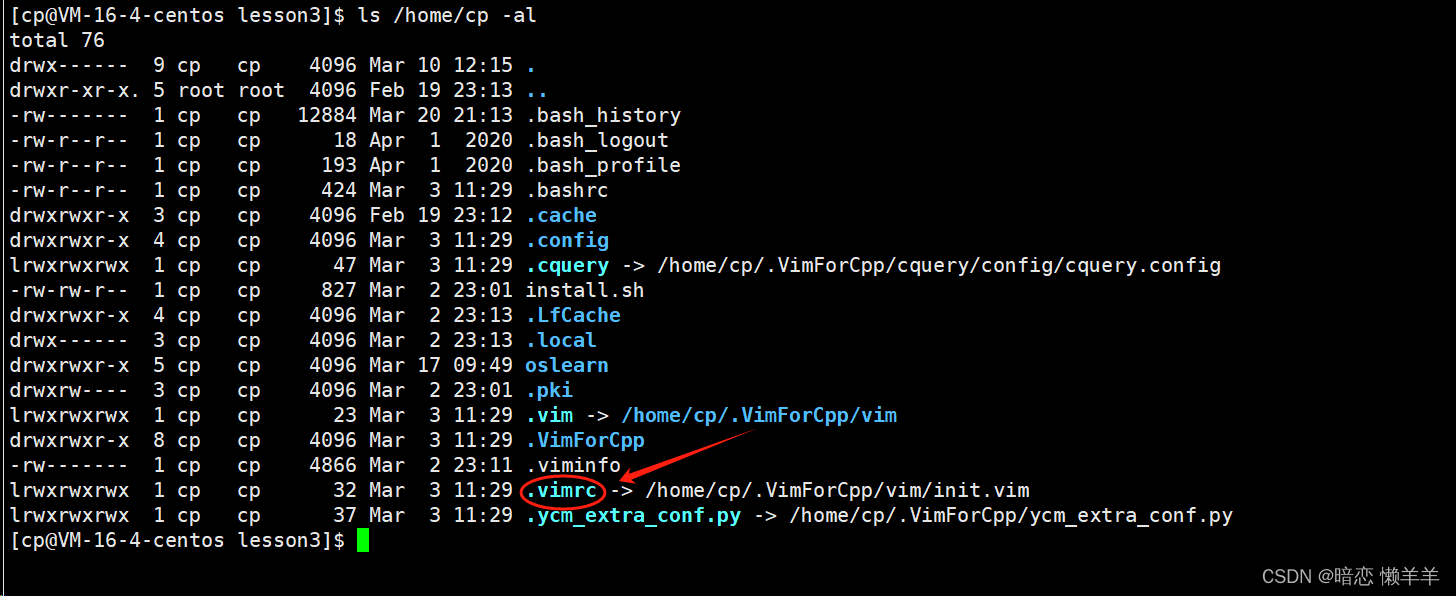
Linux环境开发工具之vim
前言 上一期我们已经介绍了软件包管理器yum, 已经可以在linux上查找、安装、卸载软件了,本期我们来介绍一下文本编辑器vim。 本期内容介绍 什么是vim vim的常见的模式以及切换 vim命令模式常见的操作 vim底行模式常见的操作 解决普通用户无法执行sudo问…...

「Linux系列」Shell介绍及起步
文章目录 一、Shell简介二、Shell脚本三、Shell解释器四、相关链接 一、Shell简介 Shell本身是一个用C语言编写的程序,它既是一种命令语言,又是一种程序设计语言。作为命令语言,它交互式地解释和执行用户输入的命令;作为程序设计…...
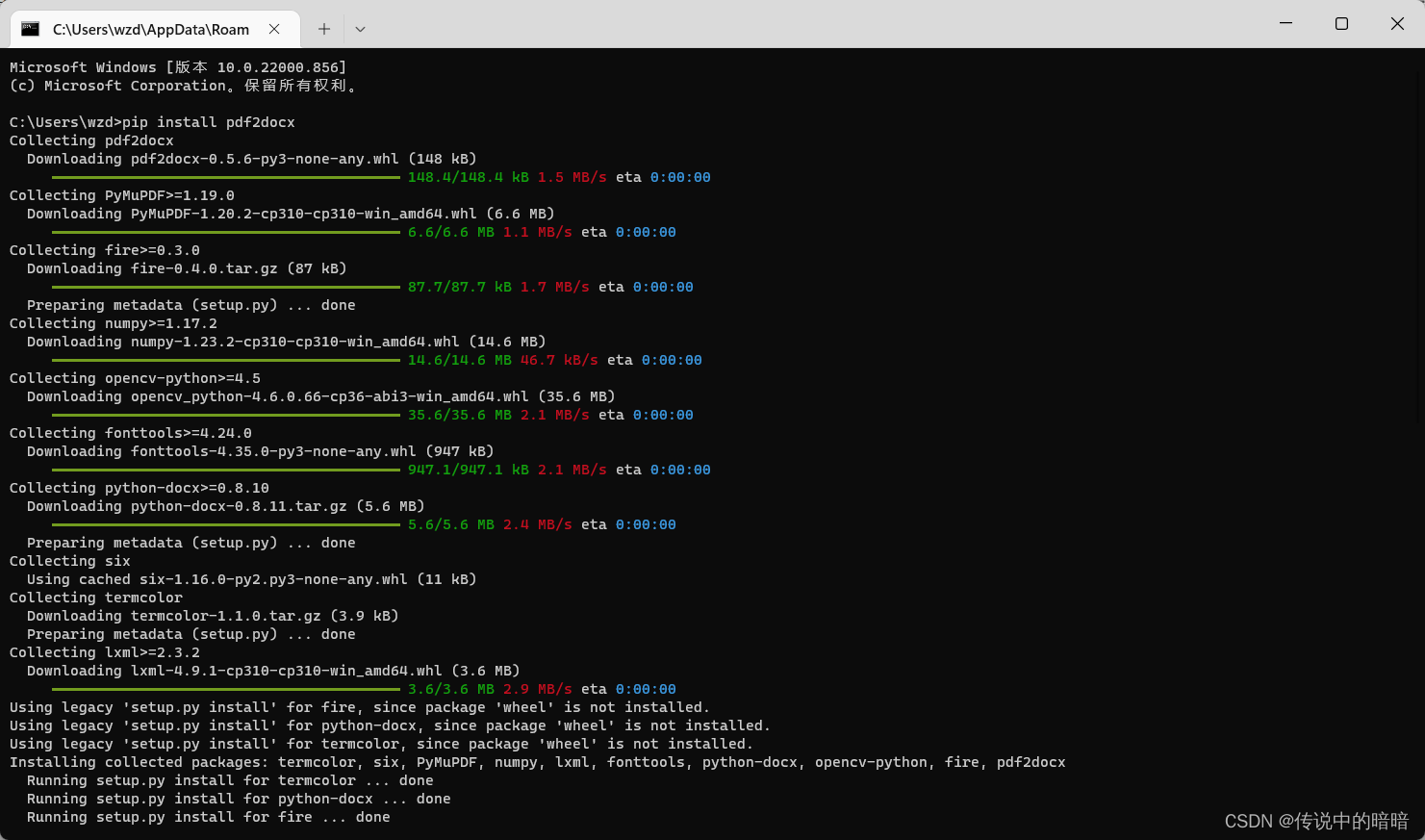
用pdf2docx将PDF转换成word文档
pdf2docx是一个Python模块,可以将PDF文件转换为docx格式的Word文档。 pdf2docx模块基于Python的pdfminer和python-docx库开发,可以在Windows、Linux和Mac系统上运行。它可以从PDF文件中提取文本和图片,并将其转换成可编辑的Word文档…...
STM32U5 ADC 自校准不成功的问题分析
1、引言 很多 STM32 系列中的 ADC 都带有自校准的功能。它提供了一个自动校准的过程,用于驱动包括 ADC 上电/掉电序列在内的所有校准动作。在这个过程中,ADC 计算出一个校准因子,并在内部应用到此 ADC 模块,直到下一次 ADC 掉电。…...
使用光标精灵更换电脑鼠标光标样式,一键安装使用
想要让自己在使用电脑时更具个性化,让工作和娱乐更加愉快,改变你的电脑指针光标皮肤可能是一个简单而有效的方法。很多人或许并不清楚如何轻松地调整电脑光标样式,下面我就来分享一种简单的方法。 电脑光标在系统里通常只有几种默认图案&…...
微服务day04(上)-- RabbitMQ学习与入门
1.初识MQ 1.1.同步和异步通讯 微服务间通讯有同步和异步两种方式: 同步通讯:就像打电话,需要实时响应。 异步通讯:就像发邮件,不需要马上回复。 两种方式各有优劣,打电话可以立即得到响应,但…...

Halcon 3D 平面拟合(区域采样、Z值过滤、平面拟合、平面移动)
Halcon 3D 平面拟合(区域采样、Z值过滤、平面拟合、平面移动) 链接:https://pan.baidu.com/s/1UfFyZ6y-EFq9jy0T_DTJGA 提取码:ewdi * 1.读取图片 ****************...
npm 插件 中 版本号为 星号 是什么意思
npm 插件 中 版本号为 星号 是什么意思 "dependencies": {"hstool/side-adaptor": "*","hsui/core": "*","h_ui": "*" }, "devDependencies": {"plugin-jsx": "*","…...
)
Codeforces\ Round\ 930(C.Bitwise Operation Wizard)
C o d e f o r c e s R o u n d 930 ( C . B i t w i s e O p e r a t i o n W i z a r d ) \Huge{Codeforces\ Round\ 930(C.Bitwise Operation Wizard)} Codeforces Round 930(C.BitwiseOperationWizard) 文章目录 题意思路注意 标程 题目链接:[B.Bitwise Operati…...

监控系统prometheus+grafana+发送告警信息
1、基础环境准备两台或更多的主机 2、关闭selinux vi /etc/selinux/config,修改SELINUX的值为disabled 3、关闭防火墙 systemctl disable firewalld systemctl stop firewalld 4、prometheus官网下载 https://prometheus.io/download/ 5、grafana官网下载 https…...

IoT 物联网场景中如何应对安全风险?——青创智通
工业物联网解决方案-工业IOT-青创智通 随着物联网(IoT)技术的快速发展,越来越多的设备、系统和应用被连接到互联网上,从而构建了一个庞大的物联网生态系统。然而,这种连接性也带来了前所未有的安全风险。在物联网场景…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

为什么92%的数据库重构失败?Claude设计辅助如何在48小时内规避反范式陷阱?
更多请点击: https://codechina.net 第一章:为什么92%的数据库重构失败?——反范式陷阱的本质溯源 数据库重构失败率高达92%,其核心症结并非技术能力不足,而是对“反范式”这一设计策略的误读与滥用。许多团队在性能压…...

AI Agent 为什么必须有“记忆系统”?
导语:大模型不是没有智商,而是经常没有“记性”。真正能长期干活的 Agent,不是靠无限拉长上下文,而是靠一套会压缩、会检索、会遗忘、会治理的外置记忆系统。一、先给结论:Agent 的记忆系统,本质是“上下文…...

Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼
Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼 【免费下载链接】sharpkeys SharpKeys is a utility that manages a Registry key that allows Windows to remap one key to any other key. 项目地址: https://gitcode.com/gh_mirrors/sh…...

3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能
3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

基于ATmega328P与TFT屏的园艺环境监控系统:硬件选型与软件架构详解
1. 项目概述:打造你的家庭园艺数据监控中心如果你和我一样,是个喜欢在阳台或后院捣鼓花草的园艺爱好者,同时又对电子DIY有点兴趣,那么这个项目绝对会让你兴奋。我们不是在简单地种花,而是在用数据“聆听”植物的需求。…...