Spark-Scala语言实战(4)
在之前的文章中,我们学习了如何在scala中定义无参,带参以及匿名函数。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(3)-CSDN博客文章浏览阅读654次,点赞19次,收藏14次。今天我会给大家带来如何在Scala中使用函数,了解函数。望在本篇文章中,大家有所收获。也欢迎朋友们到评论区下一起交流学习,共同进步。https://blog.csdn.net/qq_49513817/article/details/136839079?spm=1001.2014.3001.5501
目录
一、知识回顾
二、集合
1.List
a.字符串列表
b.整形
c.::Nil
2.set
a.set创建
b.set操作
c.遍历set
3.map
三、元组
拓展-集合方法
1.List集合方法
2.set集合方法
3.map集合方法
一、知识回顾
在上一篇文章中,我们讲了如和创建一个无参,带参以及匿名函数。
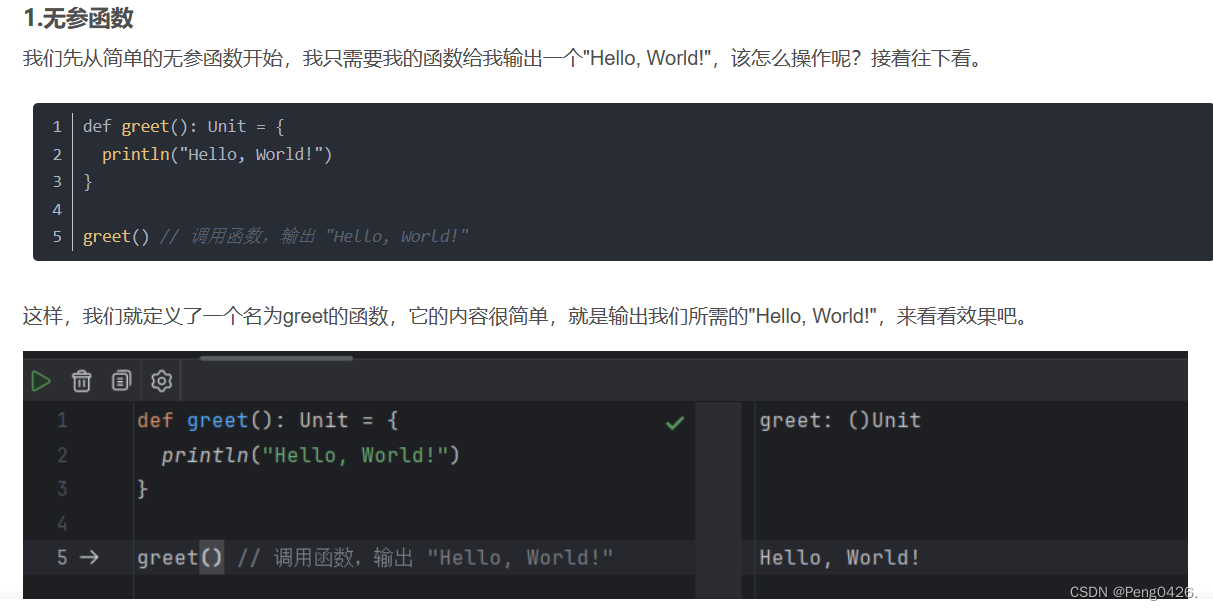
无参并不难理解,直接定义直接输出。

带参函数多注重调用方法

匿名函数就要花心思去理解了,但多实操,也肯定能搞懂。
那么,开启今天的学习吧。
二、集合
scala中,集合分为三大类: List、set以及Map
现在,我们逐个讲解。
1.List
在Scala中,List是一种常用的不可变集合。它代表了一个有序的元素集合,你可以通过索引访问其元素,并且其大小是固定的。由于它是不可变的,所以一旦创建,就不能改变其内容(如添加或删除元素)。
如果要定义可变列表,需要导入 import scala.collection.mutable.ListBuffer 包
a.字符串列表
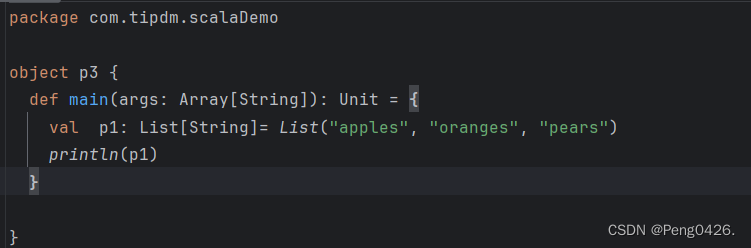
可以看到,我定义了一个类型为List的字符串集合,并赋给了他"apples", "oranges", "pears"三个字符串,现在我们来运行以下我们的代码看看效果。

运行成功,输出了我们赋予的东西。
package com.tipdm.scalaDemoobject p3 {def main(args: Array[String]): Unit = {val p1: List[String]= List("apples", "oranges", "pears")println(p1)}}b.整形

和上面的区别不大,仅仅改了赋予值的数据类型而已,现在运行试试。
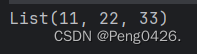
package com.tipdm.scalaDemoobject p3 {def main(args: Array[String]): Unit = {val p1 = List(11, 22, 33)println(p1)}}c.::Nil
在scala中,可以使用“Nil”和“::”操作符来定义列表
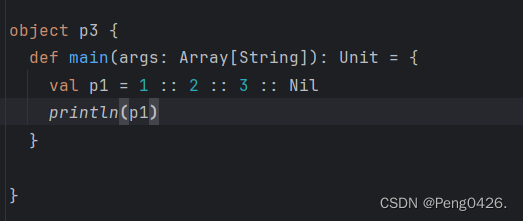
可以看到,我们并没有定义p1的类型,只是在数值后面加上了::Nil,那输出会是什么呢?
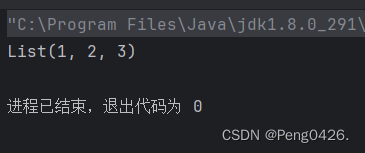
显而易见,我放到这里,那肯定是List,那为什么会这样呢?
Nil代表一个空的List,它是List的结束标记。使用::操作符可以将元素添加到List的前面。 在之前的文章中,我也说过了,这也是Scala的语言的特点,它会自己识别,这正是Scala语言灵活的体现。
2.set
a.set创建
在Scala中,Set是一种不可变的集合,它包含的元素是唯一的,也就是说它不允许有重复的元素。Scala 使用不可变Set集合,若想使用可变的Set集合则需要引入 scala.collection.mutable.Set包。
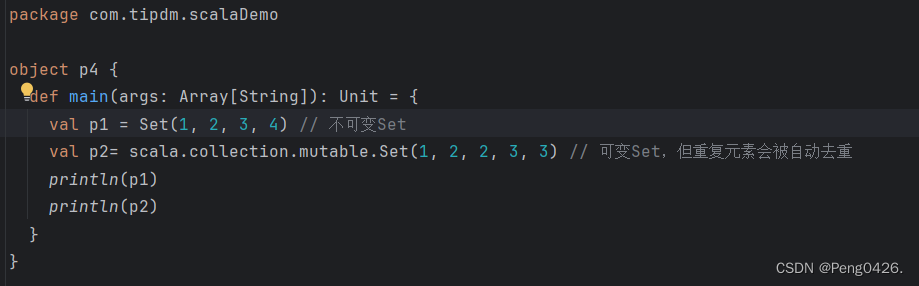
在运用scala.collection.mutable.Set包创建一个可变集合后,重复元素会直接强制降重,我们来看下输出。
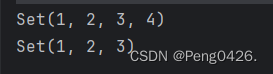
可以看到p2原先的值应该是1,2,2,3,3。现在输出直接变成1,2,3了,它完成了一个降重工作。
b.set操作
你可以使用+和-操作符来添加和删除元素

来看看输出。

对于不可变的Set,添加或删除元素会返回一个新的Set,而原始的Set不会被改变。对于可变的Set,添加或删除元素会修改原来的Set。
c.遍历set
在Scala中,我们可以使用foreach方法来遍历Set中的元素

输出看看

咱们的newp1被遍历输出了。
package com.tipdm.scalaDemoobject p4 {def main(args: Array[String]): Unit = {val p1 = Set(1, 2, 3, 4) val newp1= p1 + 5newp1.foreach(println)}
}
3.map
在Scala中,Map是一种可迭代的键值对(key/value)结构集合,并且键在Map中是唯一的。
创建map,输出map

那该怎么输出呢?
可以通过键来访问Map中的值,也可以直接打印,还可以用for遍历输出

三种方法,我们来看下输出效果

package com.tipdm.scalaDemoobject p4 {def main(args: Array[String]): Unit = {val p1 = Map("one" -> 1, "two" -> 2, "three" -> 3)val p2 = p1("one")println(p2)println(p1)for ((key, value) <- p1) {println(s"$key -> $value")}}
}
三、元组
在Scala中,元组(Tuple)是一种固定大小的有序集合,可以包含不同类型的元素。元组是轻量级的,用于将多个项组合成一个单一的对象,而不必创建自定义的类。
val p1 = (1, "Hello")这是两种元素的元组
val p2 = (1, "Hello", true, 3.14)这是四种元素的元组
在元组中,我们可以通过使用下划线 _1、_2、_3 等来访问元组中的元素,其中数字表示元素的位置(从1开始)。也可以直接打印。

来看看运行效果
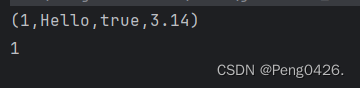
可以看到_1下的元素1被成功赋给了s1
package com.tipdm.scalaDemoobject p4 {def main(args: Array[String]): Unit = {val p1 = (1, "Hello", true, 3.14)println(p1)val s1 = p1._1println(s1)}}
拓展-集合方法
1.List集合方法
| 方法名 | 描述 | 示例 |
|---|---|---|
::: | 连接两个或多个列表 | val list1 = List(1, 2, 3); val list2 = List(4, 5, 6); val result = list1 ::: list2 |
+: 或 :: | 在列表开头添加元素 | val list = 1 :: (2 :: (3 :: Nil)) |
isEmpty | 判断列表是否为空 | val list = List(); val isEmpty = list.isEmpty |
head | 获取列表的第一个元素 | val list = List(1, 2, 3); val firstElement = list.head |
tail | 获取列表除第一个元素外的其余部分 | val list = List(1, 2, 3); val rest = list.tail |
take(n) | 取出列表的前n个元素 | val list = List(1, 2, 3, 4, 5); val taken = list.take(3) |
takeRight(n) | 取出列表的后n个元素 | val list = List(1, 2, 3, 4, 5); val takenRight = list.takeRight(2) |
drop(n) | 删除列表的前n个元素 | val list = List(1, 2, 3, 4, 5); val dropped = list.drop(2) |
dropRight(n) | 删除列表的后n个元素 | val list = List(1, 2, 3, 4, 5); val droppedRight = list.dropRight(2) |
filter(predicate) | 过滤出符合条件的元素 | val list = List(1, 2, 3, 4, 5); val filtered = list.filter(_ % 2 == 0) |
indexOf(element, [from]) | 从指定位置开始查找元素的索引 | val list = List(1, 2, 3, 4, 5); val index = list.indexOf(3) |
intersect(other) | 计算两个集合的交集 | val list1 = List(1, 2, 3); val list2 = List(2, 3, 4); val intersection = list1.intersect(list2) |
length | 返回列表的长度 | val list = List(1, 2, 3, 4, 5); val length = list.length |
mkString([sep]) | 将列表元素转换为字符串,可以用指定的分隔符 | val list = List(1, 2, 3); val str = list.mkString(", ") |
toArray | 将列表转换为数组 | val list = List(1, 2, 3); val array = list.toArray |
sorted | 对列表进行排序,默认为升序 | val list = List(3, 1, 4, 1, 5, 9); val sortedList = list.sorted |
2.set集合方法
| 方法名 | 描述 | 示例 |
|---|---|---|
+ 或 ++= | 向集合中添加元素 | val set = Set(1, 2, 3); set += 4 |
- 或 --= | 从集合中移除元素 | val set = Set(1, 2, 3, 4); set -= 3 |
contains | 检查集合是否包含某元素 | val set = Set(1, 2, 3); val isContained = set.contains(2) |
isEmpty | 判断集合是否为空 | val set = Set(); val isEmpty = set.isEmpty |
size | 返回集合的元素数量 | val set = Set(1, 2, 3); val size = set.size |
intersect | 计算两个集合的交集 | val set1 = Set(1, 2, 3); val set2 = Set(2, 3, 4); val intersection = set1.intersect(set2) |
diff 或 -- | 计算两个集合的差集 | val set1 = Set(1, 2, 3); val set2 = Set(2, 3, 4); val diff = set1.diff(set2) |
union 或 ++ | 计算两个集合的并集 | val set1 = Set(1, 2, 3); val set2 = Set(2, 3, 4); val union = set1.union(set2) |
subsetOf | 判断一个集合是否为另一个集合的子集 | val set1 = Set(1, 2); val set2 = Set(1, 2, 3); val isSubset = set1.subsetOf(set2) |
filter | 过滤出符合条件的元素 | val set = Set(1, 2, 3, 4, 5); val filtered = set.filter(_ % 2 == 0) |
foreach | 遍历集合中的每个元素并执行操作 | val set = Set(1, 2, 3); set.foreach(println) |
mkString | 将集合元素转换为字符串,可用指定的分隔符 | val set = Set(1, 2, 3); val str = set.mkString(", ") |
3.map集合方法
| 方法名 | 描述 | 示例 |
|---|---|---|
+ 或 ++= | 向Map中添加键值对 | val map = Map("a" -> 1); map += ("b" -> 2) |
- 或 --= | 从Map中移除键值对 | val map = Map("a" -> 1, "b" -> 2); map -= "a" |
get | 根据键获取对应的值(返回Option类型) | val map = Map("a" -> 1); val value = map.get("a") |
contains | 检查Map是否包含某个键 | val map = Map("a" -> 1); val isContained = map.contains("a") |
isEmpty | 判断Map是否为空 | val map = Map(); val isEmpty = map.isEmpty |
size | 返回Map中的键值对数量 | val map = Map("a" -> 1, "b" -> 2); val size = map.size |
keys | 获取Map中所有的键 | val map = Map("a" -> 1, "b" -> 2); val keys = map.keys |
values | 获取Map中所有的值 | val map = Map("a" -> 1, "b" -> 2); val values = map.values |
foreach | 遍历Map中的每个键值对并执行操作 | val map = Map("a" -> 1, "b" -> 2); map.foreach { case (key, value) => println(s"$key -> $value") } |
mapValues | 对Map中的每个值应用函数,返回新的Map | val map = Map("a" -> 1, "b" -> 2); val newMap = map.mapValues(_ * 2) |
filterKeys | 根据键的条件过滤Map中的键值对 | val map = Map("a" -> 1, "b" -> 2); val filtered = map.filterKeys(_ == "a") |
filter 或 withFilter | 根据键值对的条件过滤Map中的键值对 | val map = Map("a" -> 1, "b" -> 2); val filtered = map.filter { case (key, value) => value > 1 } |
相关文章:
Spark-Scala语言实战(4)
在之前的文章中,我们学习了如何在scala中定义无参,带参以及匿名函数。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。 Spark-Scala语言…...

ffmpeg不常用命令整理
最近做了许多有关音视频方面的工作,接触了一些不常用的命令,整理分享出来。 1.剪辑视频 ffmpeg -ss 1 -to 4 -accurate_seek -i input.mp4 -c:v copy output.mp4指定从视频中的第1秒开始,到第4秒结束的部分剪辑。 ss:指定开始时…...
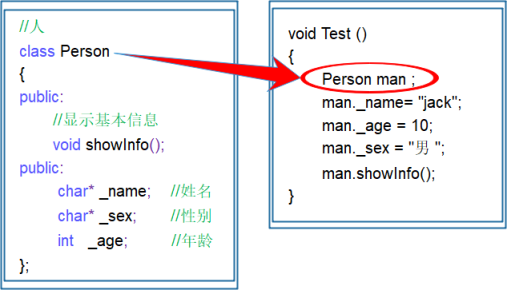
怎么理解面向对象?一文带你全面理解
文章目录 1、类和对象(1)面向过程和面向对象初步认识(2)类的引入(3)类的定义(4)类的访问限定符及封装4.1 访问限定符4.2 封装 (5)类的作用域(6&am…...
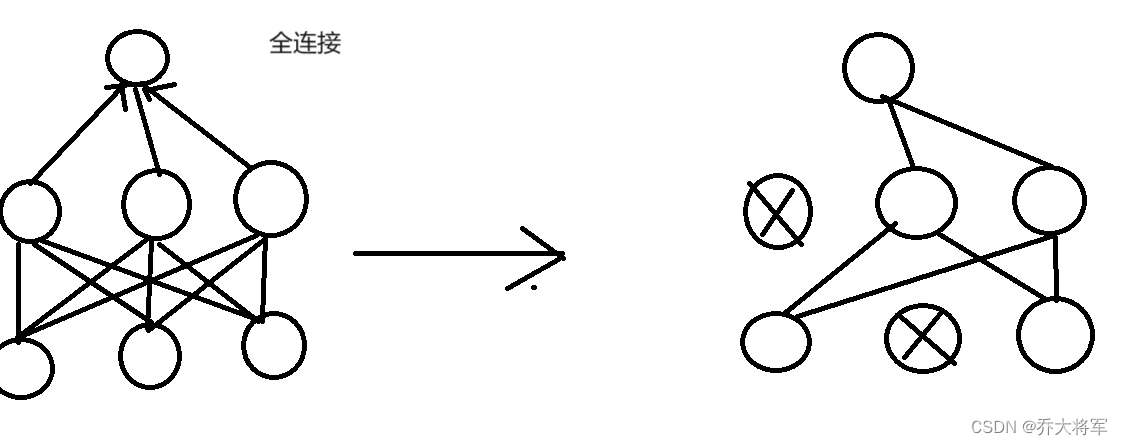
神经网络(深度学习,计算机视觉,得分函数,损失函数,前向传播,反向传播,激活函数)
目录 一、神经网络简介 二、深度学习要解决的问题 三、深度学习的应用 四、计算机视觉 五、计算机视觉面临的挑战 六、得分函数 七、损失函数 八、前向传播 九、反向传播 十、神经元的个数对结果的影响 十一、正则化与激活函数 一、神经网络简介 神经网络是一种有监督…...

Tomcat的Host Manager页面403的原因和解决办法
目录 背景 原因: 解决方案 背景 一直报错 403 Access Denied You are not authorized to view this page.By default the Host Manager is only accessible from a browser running on the same machine as Tomcat. If you wish to modify this restriction, youll need to…...

零基础学华为ip认证难吗?华为认证费用多少?
零基础学华为ip认证难吗? 首先,零基础的学习者可以通过系统的学习,逐步掌握网络基础知识和技能。可以通过阅读教材、参加培训课程、进行实践操作等方式,不断提升自己的知识和技能水平。同时,学习者还可以利用华为提供的…...

[C语言]——内存函数
目录 一.memcpy使用和模拟实现(内存拷贝) 二.memmove 使用和模拟实现 三.memset 函数的使用(内存设置) 四.memcmp 函数的使用 C语言中规定: memcpy拷贝的就是不重叠的内存memmove拷贝的就是重叠的内存但是在VS202…...

QGIS编译(跨平台编译)056:PDAL编译(Windows、Linux、MacOS环境下编译)
点击查看专栏目录 文章目录 1、PDAL介绍2、PDAL下载3、Windows下编译4、linux下编译5、MacOS下编译1、PDAL介绍 PDAL(Point Data Abstraction Library)是一个开源的地理空间数据处理库,它专注于点云数据的获取、处理和分析。PDAL 提供了丰富的工具和库,用于处理激光扫描仪、…...

计算机三级——网络技术(综合题第二题)
路由器工作模式 用户模式 当通过Console或Telnet方式登录到路由器时,只要输入的密码正确,路由器就直接进入了用户模式。在该模式下,系统提示符为一个尖括号(>)。如果用户以前为路由器输入过名称,则该名称将会显示在尖指号的前…...

Python 深度学习第二版(GPT 重译)(二)
四、入门神经网络:分类和回归 本章涵盖 您的第一个真实世界机器学习工作流示例 处理矢量数据上的分类问题 处理矢量数据上的连续回归问题 本章旨在帮助您开始使用神经网络解决实际问题。您将巩固从第二章和第三章中获得的知识,并将所学应用于三个新…...
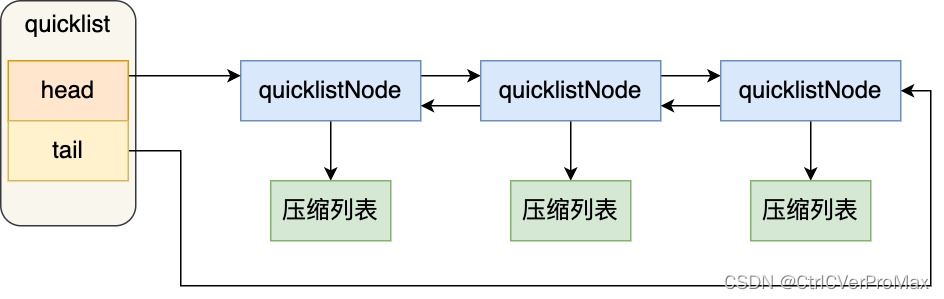
【Redis】Redis常见原理和数据结构
Redis 什么是redis redis是一款基于内存的k-v数据结构的非关系型数据库,读写速度非常快,常用于缓存,消息队列、分布式锁等场景。 redis的数据类型 string:字符串 缓存对象,分布式ID,token,se…...

3个Tips,用“AI”开启新生活
相信最近,很多朋友们都回归到了忙碌的生活节奏中。生活模式的切换,或多或少会带来身体或情绪状况的起伏。新技术正在为人们生活的方方面面带来便利。3个小Tips或许能让你也从新技术中获益,从身到心,用“AI”开启新生活。 关”A…...

【ROS | OpenCV】在ROS中实现多版本OpenCV、cv_bridge共存:安装与配置指南
在 Ubuntu 20.04 中,ROS Noetic 默认安装的 OpenCV 版本为 4.2.0。如果您需要确认系统中已安装的 OpenCV 版本,可以使用以下命令: sudo find / -iname "*opencv*"然而,许多开源算法都是基于 OpenCV 3 编写的࿰…...
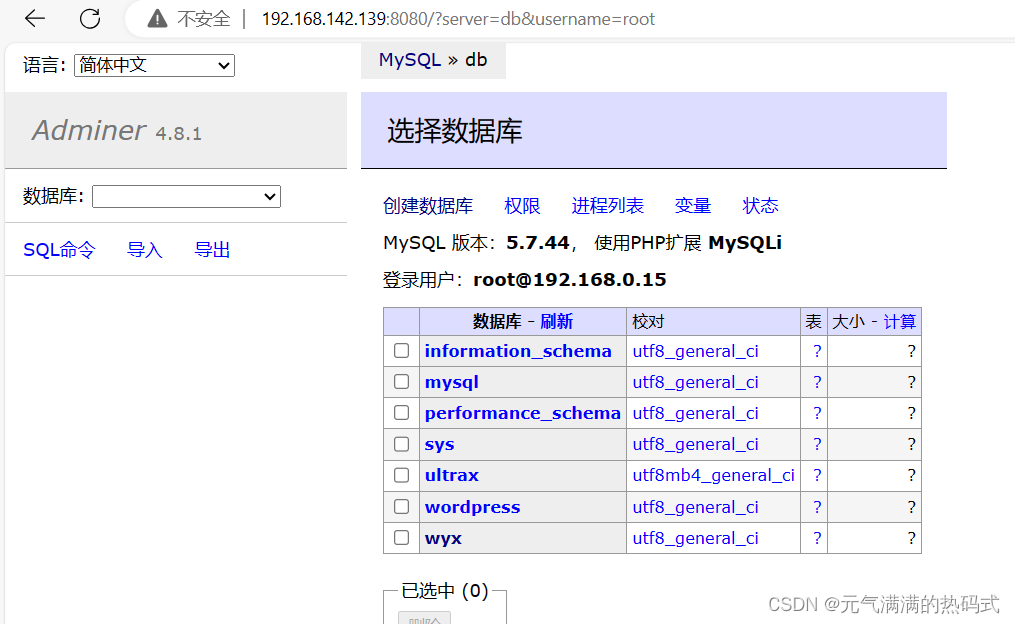
Docker容器化技术(docker-compose示例:部署discuz论坛和wordpress博客,使用adminer管理数据库)
安装docker-compose [rootservice ~]# systemctl stop firewalld [rootservice ~]# setenforce 0 [rootservice ~]# systemctl start docker[rootservice ~]# wget https://github.com/docker/compose/releases/download/v2.5.0/docker-compose-linux-x86_64创建目录 [rootse…...

微分学<6>——Taylor公式
索引 Taylor公式Taylor公式的定性分析定理6.1 Taylor公式(Peano余项) Taylor公式的定量分析定理6.2 Taylor公式(Lagrange余项) Taylor公式 Taylor公式的定性分析 定理6.1 Taylor公式(Peano余项) 若函数 f ( x ) f\left ( x \right ) f(x)在 x 0 x_{0} x0处的 n n n阶导数均…...
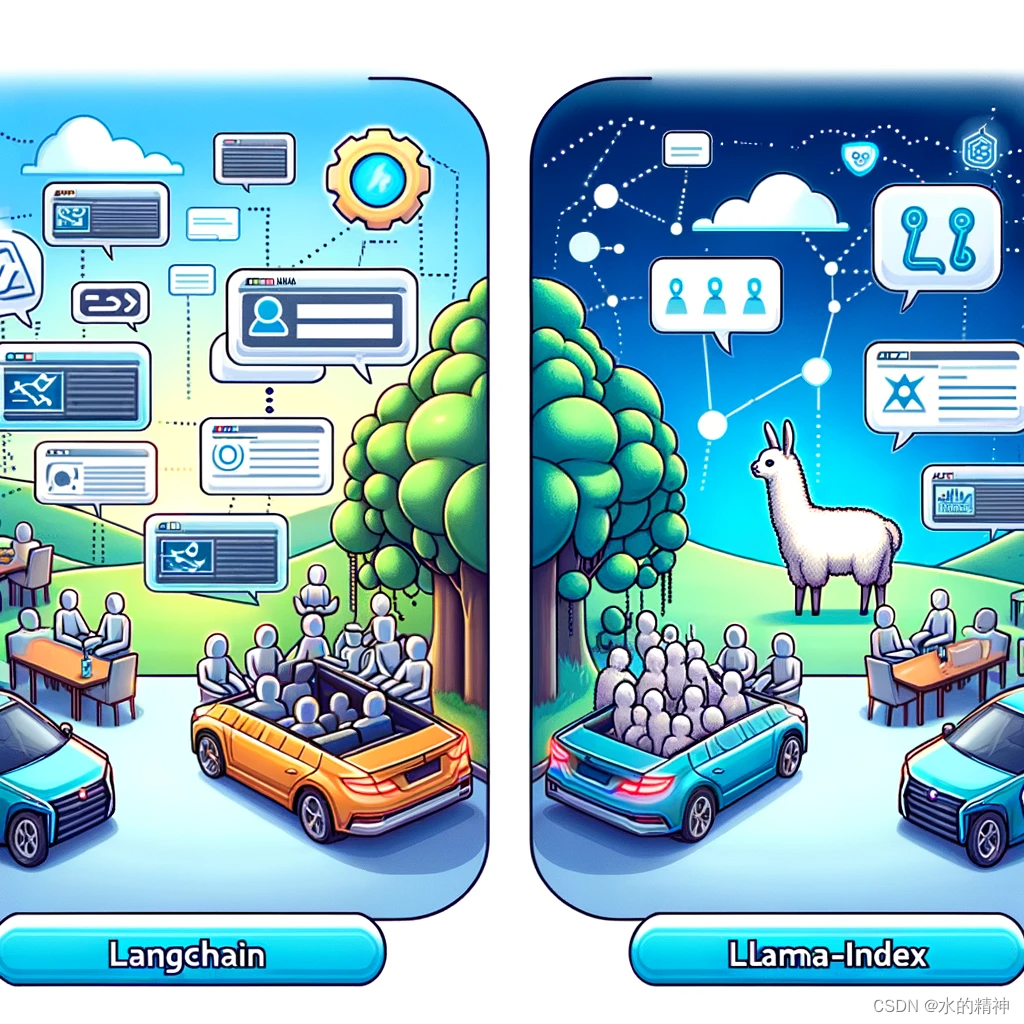
检索增强生成(RAG)应用的构建:LangChain与LlamaIndex的比较与选择
对于我要做RAG应用,我应该使用两者中的哪一个。或者说还是都使用? 在人工智能领域,检索增强生成(RAG)应用正变得越来越受欢迎,因为它们能够结合大型语言模型(LLMs)的自然语言处理能力…...
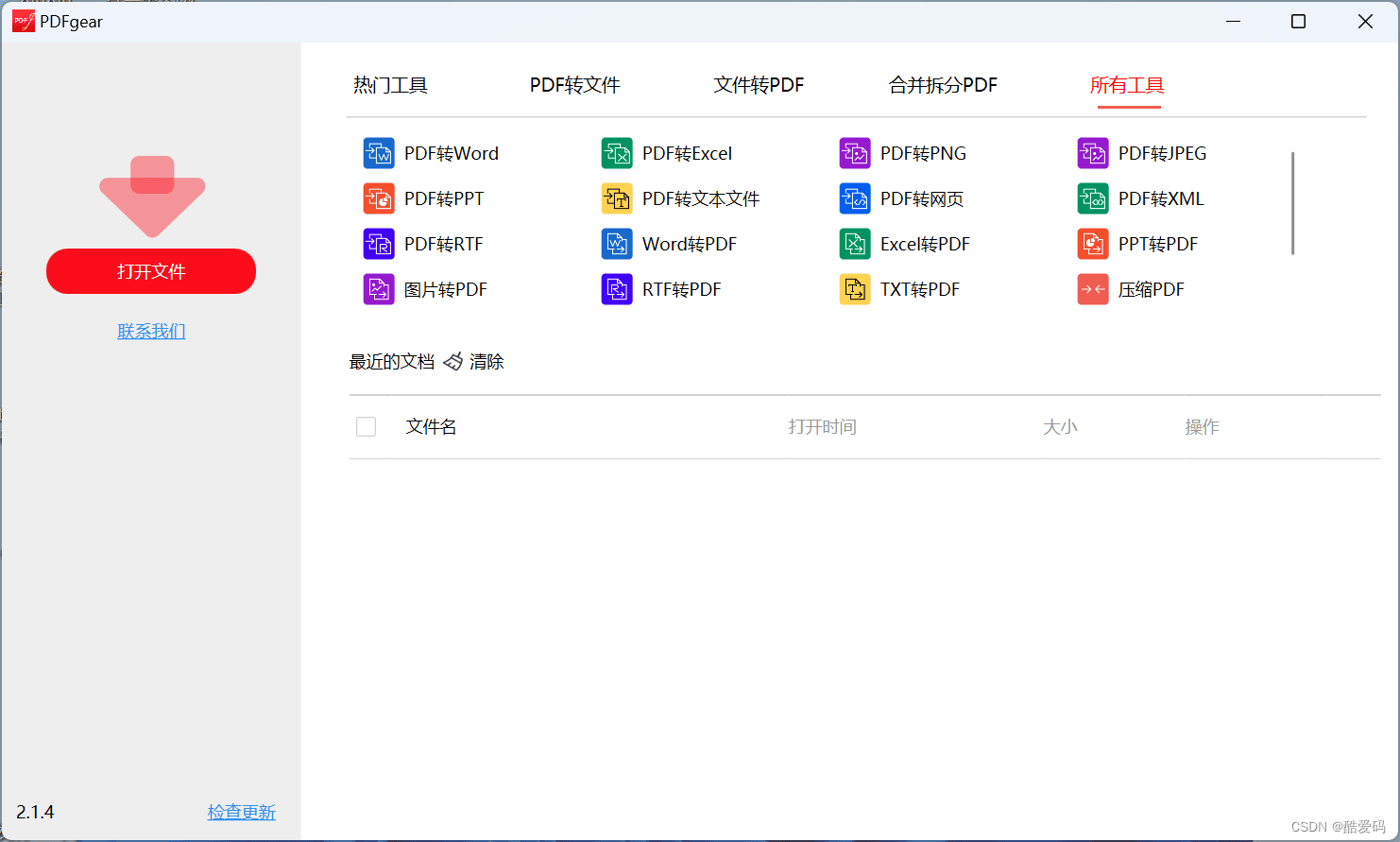
免费PDF转换和编辑工具 PDFgear 2.1.4
PDFgear是一款功能强大的 PDF 阅读及转换软件。 它支持多种文件格式的转换和编辑,同时还提供了丰富的功能模块,如签名、表单填写等,方便用户进行多样化的操作。 该软件界面简洁美观,操作简单易懂,适合不同层次的用户…...

uniapp,导航栏(切换项)有多项,溢出采取左滑右滑的形式展示
一、实现效果 当有多项的导航,或者说切换项,超出页面的宽度,我们采取可滑动的方式比较好一些!并且在页面右边加个遮罩,模拟最右边有渐变效果! 二、实现代码 html代码: <!-- 头部导航栏 --…...

计算机网络面经-什么是IPv4和IPv6?
前言 Internet协议(IP)是为连接到Internet网络的每个设备分配的数字地址。它类似于电话号码,是一种独特的数字组合,允许用户与他人通信。IP地址主要有两个主要功能。首先,有了IP,用户能够在Internet上被识别…...

彻底讲透:如何写sql能够有效的使用到复合索引?
在MySQL中,有效的使用复合索引需要确保查询条件按照索引定义的列顺序进行。以下是一个具体的例子: 假设我们有一个sales表,它有四个字段:customer_id、product_category、sale_date和amount。为了优化包含这些字段查询的性能&…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

昇腾CANN cmake 实战:CANN CMake 构建系统——跨平台编译配置与模块化管理
8 个 CANN 仓库各需独立构建(ops-transformer/ops-nn/hccl/ge/…)→ 手写 8 套 CMakeLists.txt(CANN 路径判断、跨 NPU 型号编译、第三方库兼容)。cmake 仓库提供统一的 FindCANN.cmake CANNConfig.cmake 模板——任何仓库只需 f…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Window…...

鼎讯AM-601光纤熔接机:交通通信建设与维护的可靠伙伴
在铁路、高速公路等交通基础设施的智能化建设中,稳定高效的光纤网络是指挥调度、安全监控等核心系统运行的生命线。鼎讯AM-601光纤熔接机,作为一款专为严苛环境设计的六马达便携式熔接设备,正成为保障这些关键通信链路畅通无阻的可靠选择。无…...

TII投稿避坑指南:LaTeX模板编译报错‘xxx-eps-converted-to.pdf not found’的终极解决方案
TII投稿LaTeX避坑实战:从编译报错到完美PDF生成的终极指南 凌晨三点的实验室,屏幕上闪烁的xxx-eps-converted-to.pdf not found错误提示仿佛在嘲笑你连续八小时的徒劳尝试。这不是科幻场景,而是每位用LaTeX撰写TII论文的研究者都可能遭遇的真…...