基于深度学习的面部情绪识别算法仿真与分析
声明:以下内容均属于本人本科论文内容,禁止盗用,否则将追究相关责任
基于深度学习的面部情绪识别算法仿真与分析
- 摘要
- 结果分析
- 1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若干张,图4.1是获取的部分原始网络图片示例(以厌恶情绪为例)。
- 2、数据的预处理
- 4.2 MTCNN算法仿真
- 1、数据集选择
- 2、仿真结果
- 4.3 面部情绪识别算法仿真
- 4.4 算法性能分析
- 4.4.1 FERA-C算法在自制数据集上的loss、acc分析
- 4.4.2 FERA-C算法在自制数据集上的混淆矩阵分析
- 4.4.3 CK+数据集上的算法对比分析
摘要
面部情绪是人们表达情感的直观画板,随着当代社会计算机视觉领域的不断发展,面部情绪识别已经成为图像识别领域的研究热点,在智能驾驶、智慧医疗、市场营销等公共领域有极大的应用价值。基于机器学习的传统面部情绪识别算法存在特征提取困难、泛化性能不好、训练样本过大、对噪声和变形敏感等劣势。相比之下,基于深度学习的面部情绪识别算法可以自动学习图像特征,并具有更好的泛化能力和鲁棒性。
本次设计结合深度学习中的人脸检测方法和图像识别方法,提出了一种将经典人脸检测算法MTCNN和加入混合注意力机制CBAM的残差神经网络组合起来的面部情绪识别算法,并且进行模型裁剪操作来减小模型参数计算量。主要从人脸检测、面部情绪识别分类、算法对比三个阶段来完成面部情绪识别算法总体设计。
第一个阶段采用经典人脸检测模型MTCNN训练出人脸检测模型权重,并进行人脸检测和人脸关键点的提取验证。第二个阶段在制作完成的七种面部情绪数据集上进行面部情绪识别模型的训练,调用训练权重及人脸检测权重进行图片、视频检测。通过损失率、准确率以及混淆矩阵统计识别结果,进行算法性能分析。最后与残差神经网络模型ResNet和通道注意力模型SENet进行模型性能对比。
仿真结果表明,设计的组合算法在算法整体评价中取得了不错的效果,验证了本次设计提出的组合算法的合理性和可行性。
关键词:卷积神经网络;混合注意力机制;残差结构;人脸检测;面部情绪
结果分析
1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若干张,图4.1是获取的部分原始网络图片示例(以厌恶情绪为例)。
图 4.1 “厌恶”原始图片
通过网络获取的原始图片存在大小不一、肢体遮挡、表情图片混入等问题,需要进行数据的第一次清洗去除以上提到的不符合要求的图片。
2、数据的预处理
获取到原始数据集后,考虑到后期面部情绪识别模型主要是针对面部情绪进行训练,为了尽可能减小面部之外的其他人体部位对模型训练的影响,需要对原始数据图片进行人脸裁剪操作,完成数据集归一化处理,并再次进行数据集清洗,去除裁剪不到位和面部遮挡严重的图片,图4.2是数据预处理后得到的部分数据集展示(以厌恶情绪为例)。

图 4.2 数据预处理后的“厌恶”图片
以上图片都设置成100*100的图像大小,七种面部情绪以此为基准依次操作,经过数据增强最终制作出每类1500张的数据集。
4.2 MTCNN算法仿真
由于本次设计重心在于面部情绪识别分类算法的设计,MTCNN人脸检测算法不作为算法设计详细介绍的重点,在算法仿真阶段进行调用即可。在第二章的第二小节已经对MTCNN算法原理进行了阐述,并且在第三章算法设计中明确了MTCNN算法流程,本章节不再过多叙述。
1、数据集选择
为了生成的人脸检测权重更加精确,选择WIDER FACE数据集作为MTCNN模型训练的数据集,WIDER FACE数据集包含32,203个图片,其中有128,80张用作训练,6,971张用作验证,6,946张用作测试。数据集中的图片来自于各种实际场景,包括社交场合、视频剪辑、电视截图、名人图片等,具有大量的姿态、遮挡和背景变化,是一个比较具有挑战性的数据集。
2、仿真结果
由MTCNN算法流程可知要依次进行P-Net、R-Net、O-Net的训练,最终完成人脸和面部关键点的检测,保存生成的P-Net、R-Net、O-Net模型训练的权重以便后期面部情绪识别仿真阶段进行权重调用。图4.3是MTCNN在图片上的仿真验证。

图4.3 人脸及关键点图片仿真
在仿真时会首先生成图片中人脸框的左上角和右下角的位置信息以及人脸框置信度,同时生成人脸五个关键点的位置信息,如果图片是非人脸则会返回image not have face的提示。用实时摄像头进行仿真,输出结果与图片仿真一致。
4.3 面部情绪识别算法仿真
通过训练权重在面部情绪识别仿真阶段的调用可以得到仿真结果。图4.4是仿真阶段总体设计流程图。
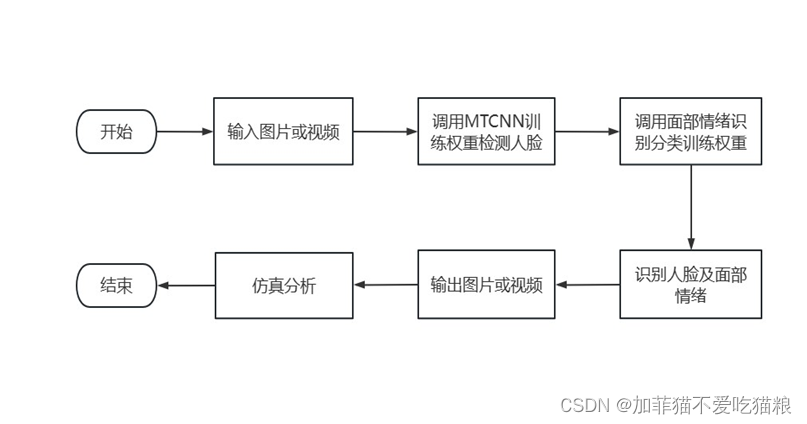
图4.4 仿真整体流程
图4.5是面部情绪识别模型在图片上的仿真结果展示,可以看出其能够识别人脸情绪,并标注人脸五个关键点,同时也存在个别情绪识别不准确的情况。
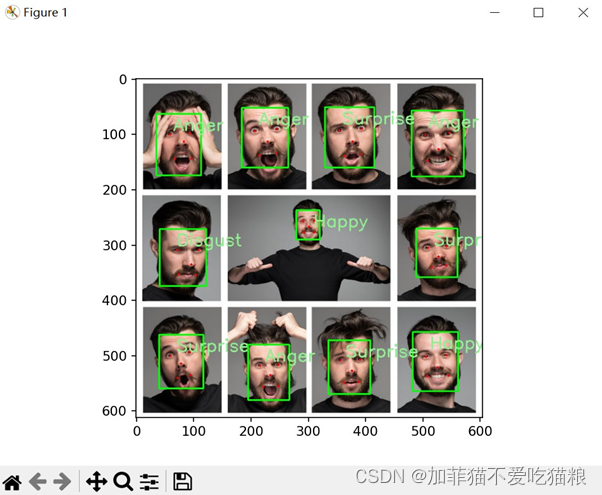
图4.5 面部情绪识别图片仿真
图4.6是面部情绪识别模型在视频中的仿真结果

图4.6 面部情绪识别视频仿真
4.4 算法性能分析
4.4.1 FERA-C算法在自制数据集上的loss、acc分析
图4.7是FERA-C模型在自制数据集上的训练结果展示。
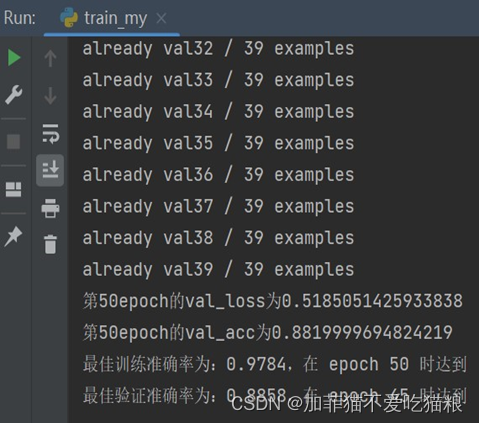
图4.7 FERA-C模型在自制数据集上的训练结果
图4.8是FERA-C模型在自制数据集上训练得到的loss变化过程。
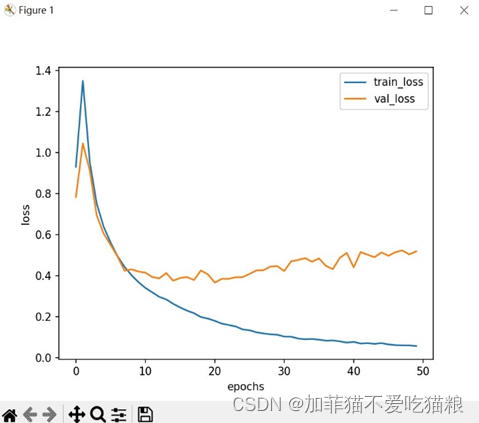
图4.8 FERA-C在自制数据集上的loss变化
由于模型学到了一些数据集的简单特征,导致train_loss和val_loss前期出现转折,后期模型学到更复杂的特征后,两者变化趋于稳定,但切合度较低。
图4.9是FERA-C模型在自制数据集上训练得到的acc变化过程。
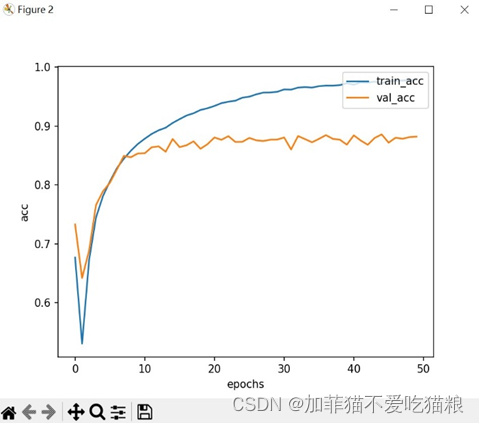
图4.9 FERA-C在自制数据集上的acc变化
从上图可以看出自制数据集在训练集上的准确率较高且acc变化平滑,但数据集在验证集上的准确率较低,变化波动较为平滑,前期acc转折与自制数据集上loss转折一致。
根据对面部情绪识别算法和训练模型模块的分析,以下问题是导致训练集和验证集在模型训练时loss、acc变化曲线不紧密的一般原因,每一个原因在经过分析后都给出了合理推测。
(1)数据集过小
当数据集较小时,模型会对训练集过拟合,不能很好地泛化到未知数据上,从而导致验证集上的损失波动较大。
自制数据集是每类1500张,总量为10500。其中训练集8400张,验证集2100张,由于在模型训练过程中进行了一定的数据增强,所以数据集过小导致训练集和验证集的loss和acc变化曲线不紧密的可能性较小,后续在算法对比阶段会使用CK+公开数据集进行验证。
(2)模型复杂度较高
过于复杂的模型会更容易对训练集过拟合。当模型过于复杂时,它很可能会在训练集上表现得很好,但在验证集上表现不佳。
本次设计使用的面部情绪识别算法FERA-C主要由残差块、混合注意力机制、基本卷积结构构成,为了避免出现模型复杂度高、参数计算量大的问题,对模型进行了裁剪处理,通过训练得到的权重大小可知此类原因导致训练集和验证集的loss、acc变化曲线不紧密依旧不成立。
(3)学习率过高
学习率过高可能导致模型参数更新过于快速,容易跳过最优解,从而使验证集准确率和损失值跟不上训练集的变化。
本次设计中,在训练模型时,为了获得合适的精确度,设置了不同学习率进行训练,从0.001到0.01不等,实验分析表明0.001较为适合,学习率过高不是导致出现上述训练问题的原因。
(4)训练次数不足
当训练次数不足时,模型可能没有充分收敛,使得验证集上的损失表现波动较大。
在模型训练阶段,将模型训练轮次设置成50轮,batch_size设置为16,通过loss和acc变化可知训练轮次已经达到训练稳定阶段,因此此类原因同样不成立。
(5)数据集缺少代表性
如果数据集缺少代表性,比如数据分布与实际情况有较大出入,则会导致模型对数据集过拟合,进而导致验证集上的损失波动较大,验证集准确率与训练集准确率相差较大。
通过对数据集的仔细分析,发现数据集中存在背景色彩差异度较大、面部化妆严重、不同类数据辨识度较低等问题,此类原因导致出现上述问题较为符合实际情况。
4.4.2 FERA-C算法在自制数据集上的混淆矩阵分析
通过混淆矩阵可以分析单一类别在验证集上的准确率,因为本次设计是七分类问题,故混淆矩阵是7*7的方阵,图4.10是通过自制数据集中的验证集调用面部情绪识别模型训练权重画出的混淆矩阵。
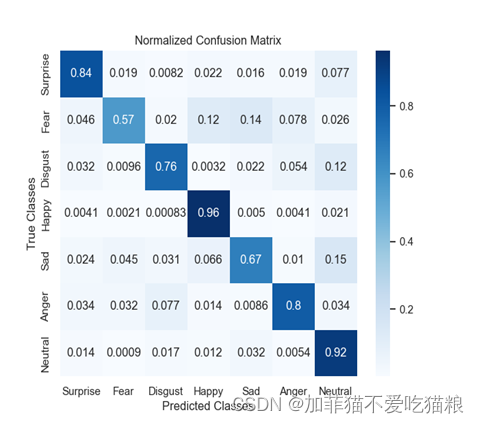
图4.10 FERA-C算法在自制数据集上的混淆矩阵
通过上图混淆矩阵可以看出七类面部情绪中,只有fear类与sad类的验证准确率较低,主要原因是两类数据集与其他类数据集区分程度较低。
4.4.3 CK+数据集上的算法对比分析
在算法对比阶段,为了验证模型效果,统一采用公开数据集CK+来进行模型训练。由于在设计FERA-C模型结构时参考了ResNet残差结构并使用了CBAM模块,故选择经典卷积神经网络中的ResNet模型和SENet模型来进行算法对比分析。
(1)ResNet模型
ResNet是一种深度卷积神经网络,通过残差块(Residual Block)连接来实现网络的深度。在传统卷积神经网络中,随着网络的加深,出现了梯度爆炸和梯度消失问题。为了解决这些问题,ResNet提出了残差学习的概念,即通过将恒等映射添加到残差块的输出路径上,这使得ResNet可以比传统卷积神经网络更深,并具有更高的准确率。
(2)SENet模型
SENet是一种用于神经网络的注意力机制模型,其核心思想是通过增强网络的注意力机制来提高网络的表现和泛化能力。
SENet模型的通道注意力机制由两个操作组成:Squeeze操作和Excitation操作。Squeeze操作通过使用全局平均池化操作将每个通道的特征压缩成一个数值,然后使用一个非线性激活函数对该数值进行激活,以获得该通道的重要性权重。Excitation操作通过使用一个全连接层对这些权重进行线性变换,并使用Sigmoid函数对变换结果进行激活,从而得到该通道的注意力权重。通过将这些注意力权重乘以原始的特征图,SENet模型可以加强网络对重要的特征信息的关注,提高网络的表现和泛化能力。
(3)CK+数据集
CK+数据集是在 CK数据集的基础上扩展来的,其数据集单张图片大小皆为48*48尺寸的黑白图像,图4.11是CK+数据集部分展示,这个数据集是人脸表情识别中比较流行的一个数据集。
图4.11 CK+数据集
三种模型训练时的超参数保持一致,训练轮次设置为100轮、batch_size设置为16、优化器选择Adam、学习率设置为0.001。三种模型在CK+数据集上分别进行模型训练,并对比模型效果参数,验证设计的FERA-C模型的可行性和合理性。
图4.12是FERA-C模型在CK+数据集上的loss变化。
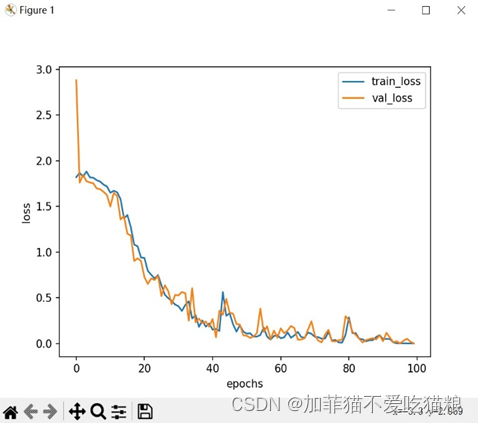
图4.12 FERA-C在CK+数据集上的loss变化
通过上图可知FERA-C模型在CK+数据集上训练得到的train_loss和val_loss变化曲线较为紧密,上一小节中的推测成立。
图4.13是FERA-C模型在CK+数据集上训练得到的acc变化结果。
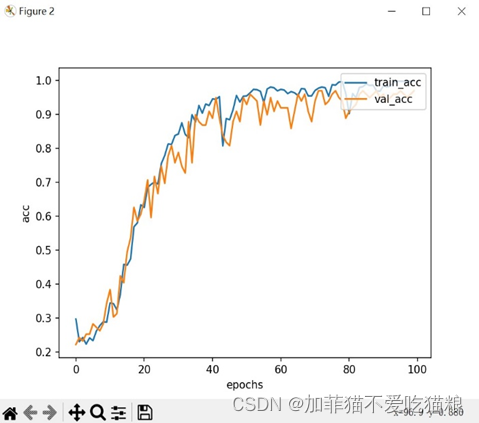
图4.13 FERA-C在CK+数据集上的acc变化
通过上图可以看出FERA-C模型在CK+数据集上的训练集准确度与验证集准确度十分接近,证明模型没有出现过拟合或欠拟合风险。图4.14是FERA-C模型训练100轮所用的训练总时间以及最高train_acc和val_acc结果显示。
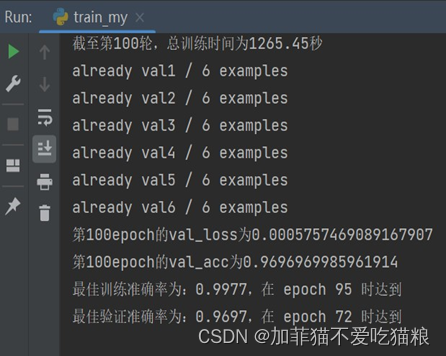
图4.14 FERA-C在CK+数据集上的训练结果
通过上图可以看出,FERA-C模型训练在第95轮获得最佳训练准确率:0.9977,在第72轮获得最佳验证准确率:0.9697,总训练时间1265.45s。
图4.15是ResNet模型在CK+数据集上训练得到的loss变化。
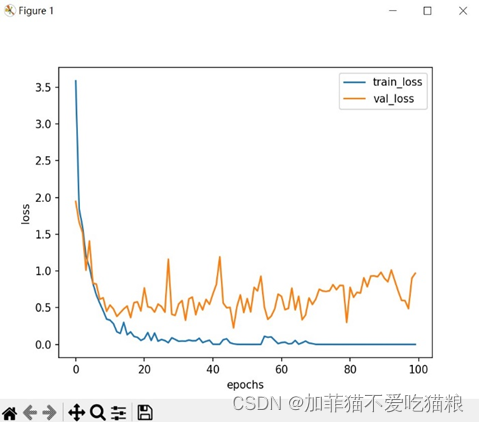
图4.15 ResNet在CK+数据集上的loss变化
通过上图可以看出ResNet在CK+数据集上训练得到的train_loss和val_loss变化曲线同样较为紧密,图4.16是ResNet模型在CK+数据集上训练得到的acc变化。
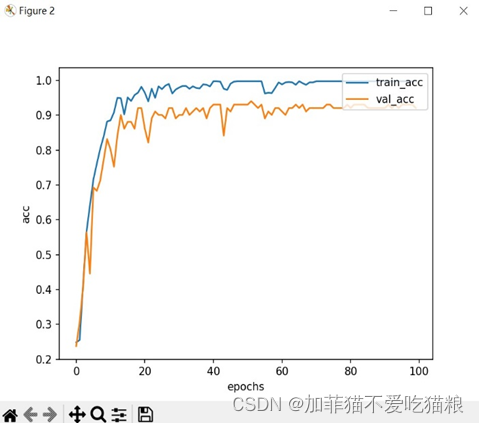
图4.16 ResNet在CK+数据集上的acc变化
通过上图可以看出ResNet在CK+数据集上的acc变化符合loss变化。图4.17是ResNet模型训练100轮所用的训练总时间以及最高train_acc和val_acc结果显示。
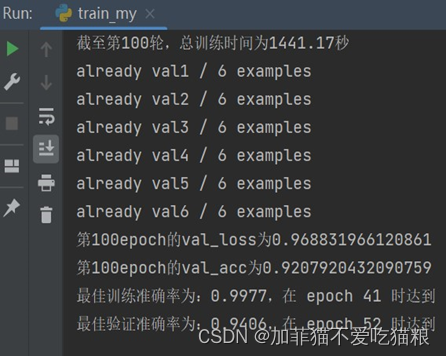
图4.17 ResNet在CK+数据集上的训练结果
通过上图可以看出,ResNet模型训练在第41轮获得最佳训练准确率:0.9977,在第52轮获得最佳验证准确率:0.9406,总训练时间1441.17s。
图4.18是SENet模型在CK+数据集上训练得到的loss变化。
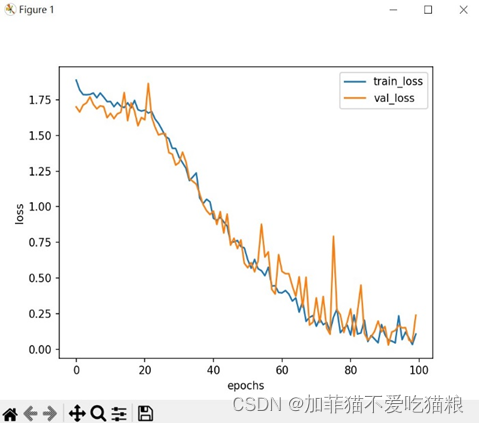
图4.18 SENet在CK+数据集上的loss变化
通过上图可以看出SENet模型在CK+数据集上得到的train_loss和val_loss并行变化。图4.19是SENet模型在CK+数据集上训练得到的acc变化。
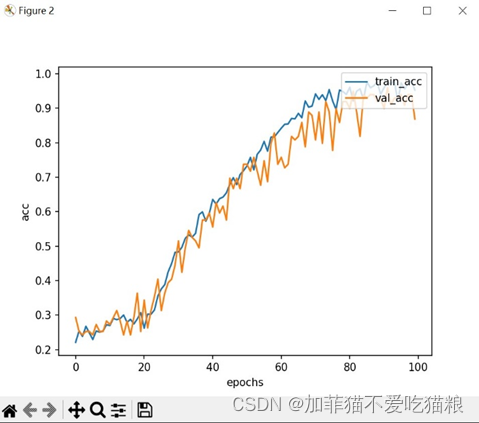
图4.19 SENet在CK+数据集上的acc变化
通过上图可以看出SENet模型在CK+数据集上训练得到的train_acc和val_acc并行变化,在80轮附近趋于稳定。图4.20是SENet模型在CK+数据集上的训练结果。
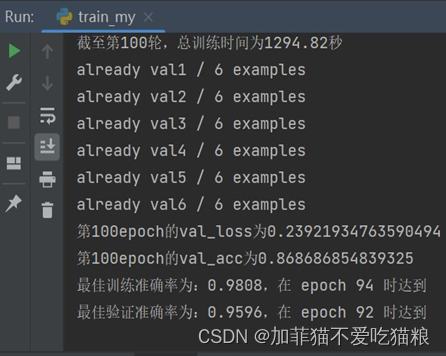
图4.20 SENet在CK+数据集上的训练结果
通过上图可以看出,SENet模型训练在第94轮获得最佳训练准确率:0.9808,在第92轮获得最佳验证准确率:0.9596,总训练时间1294.82s。
(4)整体对比总结
三种模型对比分析如表4.1表述

在对比分析阶段,由于ResNet模型网络深度较深,硬件处理设备无法符合实验要求,故选择三种模型在统一浅层卷积数量中训练。
通过上表可知三种模型在CK+数据集上的最好验证集准确率分别是0.9697、0.9406、0.9596,FERA-C模型在验证集上的最高准确率略高于另外两种模型,由于FERA-C设计时使用了模型裁剪技术减小了参数计算量,故FERA-C模型的总训练时间不算太长,SENet模型作为ResNet模型的升级版,其总训练时间比ResNet模型总训练时间短。
相关文章:
基于深度学习的面部情绪识别算法仿真与分析
声明:以下内容均属于本人本科论文内容,禁止盗用,否则将追究相关责任 基于深度学习的面部情绪识别算法仿真与分析 摘要结果分析1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若…...
)
C语言经典面试题目(十六)
1、什么是C语言中的指针常量和指针变量?它们有什么区别? 在C语言中,指针常量和指针变量是指针的两种不同类型。它们的区别在于指针的指向和指针本身是否可以被修改。 指针常量:指针指向的内存地址不可变,但指针本身的…...
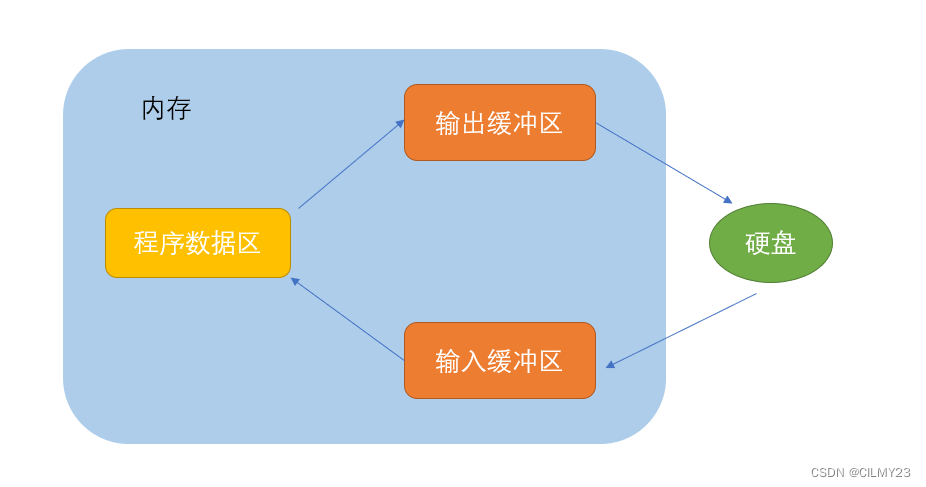
【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】
欢迎来CILMY23的博客喔,本篇为【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】,感谢观看,支持的可以给个一键三连,点赞关注收藏。 前言 欢迎来到本篇博客&…...

JAVA八股文面经问题整理第6弹
文章目录 目录 文章目录 提问问题 问题1 问题2 问题3 问题4 问题5 问题6 问题7 问题8 问题9 问题10 问题11 问题12 写在最后 提问问题 介绍一下Linux常⽤命令,例如:Vim快捷键,常⽤查看Log的命令,路径相关&#x…...

pytest相关面试题
pytest是什么?它有什么优点? pytest是一个非常流行的Python测试框架,它具有简洁、易用、高校等优点。他可以帮助测试人员方便地编写和运行测试用例,并且提供了丰富的插件和扩展,支持各种测试需求介绍下pytest常用的库 …...

Keras库搭建神经网络
Keras并非简单的神经网络库,而是一个基于Theano的强大的深度学习库,利用它不仅仅可以搭建普通的神经网络,还可以搭建各种深度学习模型,如自编码器、循环神经网络、递归神经网络、卷积神经网络等。 安装代码: pip ins…...

适配器模式与桥接模式-灵活应对变化的两种设计策略大比拼
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自:设计模式深度解析:适配器模式与桥接模式-灵活应对变…...

Elasticsearch8搭建及Springboot中集成使用
1.搭建 1.1.下载地址 Elasticsearch:https://www.elastic.co/cn/downloads/elasticsearch Kibana:https://www.elastic.co/cn/downloads/kibana 1.2.具体过程 下载安装包:访问上述链接,下载适合你操作系统的Elasticsearch和Ki…...
asp.net在线租车平台
说明文档 运行前附加数据库.mdf(或sql生成数据库) 主要技术: 基于asp.net架构和sql server数据库 功能模块: asp.net在线租车平台 用户功能有首页 行业新闻用户注册车辆查询租车介绍访问后台 后台管理员可以进行用户管理 管…...
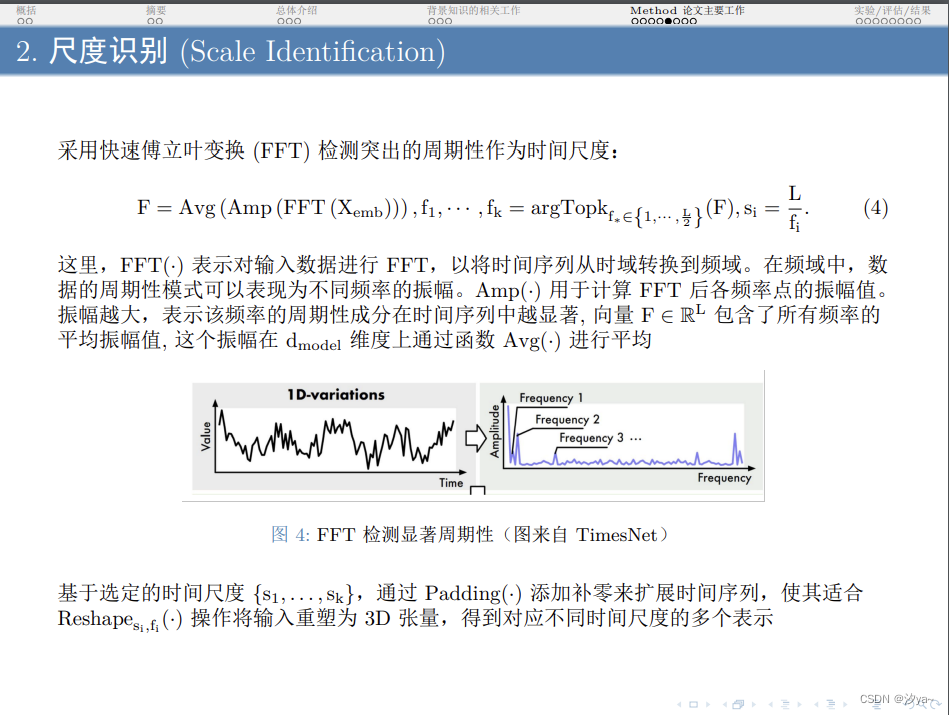
Beamer模板——基于LaTeX制作学术PPT
Beamer模板——基于LaTeX制作学术PPT 介绍Beamer的基本使用安装和编译用于学术汇报的模板项目代码模板效果图 Beamer的高级特性动态效果分栏布局定理环境 介绍 在学术领域,演示文稿是展示和讨论研究成果的重要方式。传统的PowerPoint虽然方便,但在处理复…...
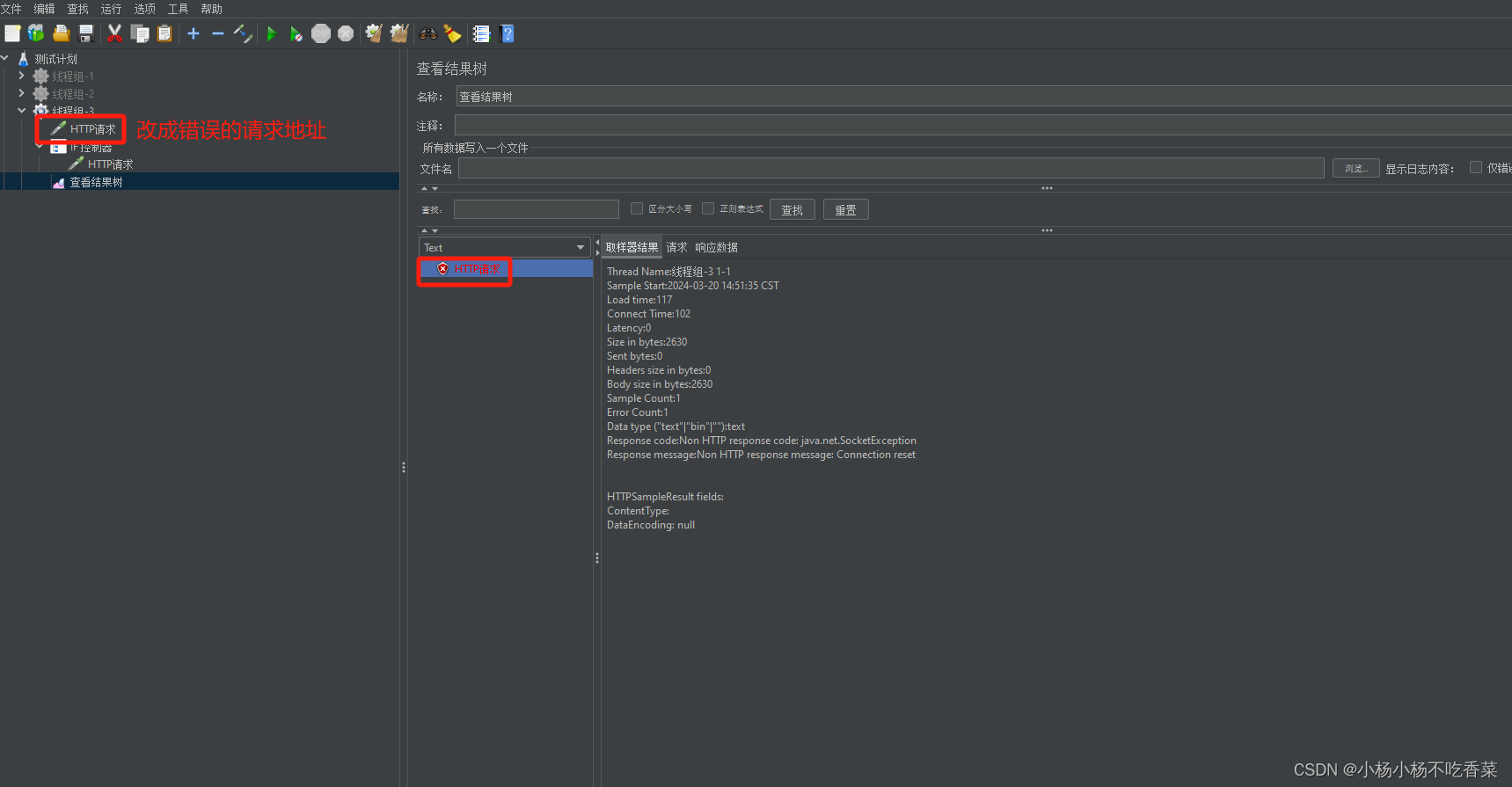
性能测试-Jmeter中IF控制器使用
一、Jmeter控制器 分为两种类型: 控制测试计划执行过程中节点的逻辑执行顺序,如:循环控制器,if控制器等对测试计划中的脚本进行分组,方便Jmeter统计执行结果以及进行脚本的运行时控制等,如:吞…...
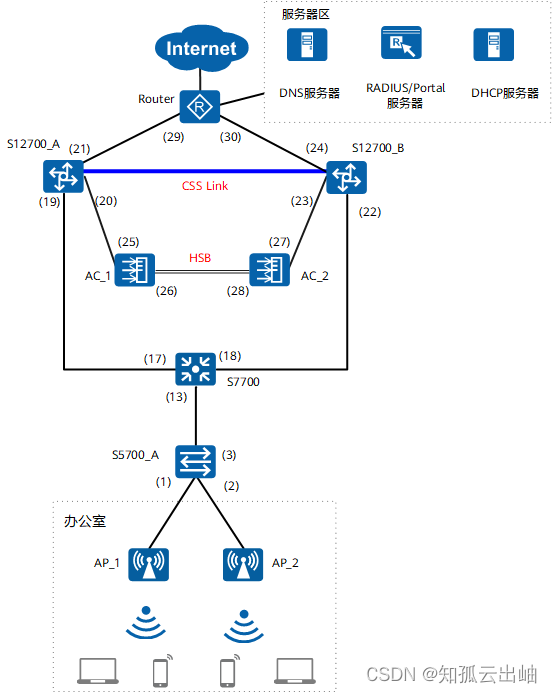
华为综合案例-普通WLAN全覆盖配置(2)
组网图 结果验证 在AC_1和AC_2上执行display ap all命令,检查当前AP的状态,显示以下信息表示AP上线成功。[AC_1] display ap all Total AP information: nor : normal [1] ExtraInfo : Extra information P : insufficient power supply ---…...

这里是一本关于 DevOps 企业级 CI/CD 实战的书籍...
文章目录 📋 前言🎯 什么是 DevOps🎯 什么是 CI/CD🎯什么是 Jenkins🧩 Jenkins 简单案例 🎯 DevOps 企业级实战书籍推荐🔥 参与方式 📋 前言 企业级 CI/CD 实战是一个涉及到软件开发…...

机器学习 - save和load训练好的模型
如果已经训练好了一个模型,你就可以save和load这模型。 For saving and loading models in PyTorch, there are three main methods you should be aware of. PyTorch methodWhat does it do?torch.saveSaves a serialized object to disk using Python’s pickl…...

【动态规划】【同余前缀和】【多重背包】[推荐]2902. 和带限制的子多重集合的数目
本文涉及知识点 动态规划汇总 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 C算法:滑动窗口总结 多重背包 LeetCode2902. 和带限制的子多重集合的数目 给你一个下标从 0 开始的非负整数数组 nums 和两个整数 l 和 r 。 请你…...

nginx介绍及搭建
架构模型 Nginx是由一个master管理进程、多个worker进程组成的多进程模型。master负责管理worker进程,worker进程负责处理网络事件,整个框架被设计为一种依赖事件驱动、异步、非阻塞的模式。 优势: 1、充分利用多核,增强并发处理…...

树莓派夜视摄像头拍摄红外LED灯
NoIR相机是一种特殊类型的红外摄像头,其名称来源于"No Infrared"的缩写。与普通的彩色摄像头不同,NoIR相机具备红外摄影和低光条件下摄影的能力。 一般摄像头能够感知可见光,并用于普通摄影和视频拍摄。而NoIR相机则在设计上去除了…...

Oracle19C静默安装教程
文章目录 一、安装前的准备1、安装Linux操作系统2、配置网络源或者本地源3、hosts文件配置 二、准备安装环境1、安装依赖包2、创建oracle用户组3、配置系统内核参数4、关闭selinux5、配置oracle用户环境6、修改用户的Shell限制 三、静默安装Oracle数据库1、创建oracle安装目录2…...
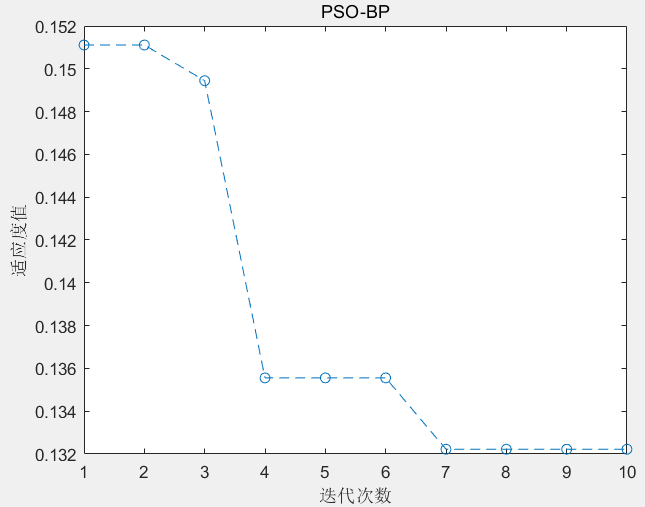
【机器学习】基于粒子群算法优化的BP神经网络分类预测(PSO-BP)
目录 1.原理与思路2.设计与实现3.结果预测4.代码获取 1.原理与思路 【智能算法应用】智能算法优化BP神经网络思路【智能算法】粒子群算法(PSO)原理及实现 2.设计与实现 数据集: 多输入多输出:样本特征24,标签类别4…...

Sora后时代文生视频的探索
一、写在前面 按常理,这里应该长篇大论地介绍一下Sora发布对各行业各方面产生的影响。不过,这类文章已经很多了,我们今天主要聊聊那些已经成熟的解决方案、那些已经可以“信手拈来”的成果,并以此为基础,看看Sora发布…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

Jetson Orin上TVA模型DLA精准卸载配置
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...