MyBatis3源码深度解析(十七)MyBatis缓存(一)一级缓存和二级缓存的实现原理
文章目录
- 前言
- 第六章 MyBatis缓存
- 6.1 MyBatis缓存实现类
- 6.2 MyBatis一级缓存实现原理
- 6.2.1 一级缓存在查询时的使用
- 6.2.2 一级缓存在更新时的清空
- 6.3 MyBatis二级缓存的实现原理
- 6.3.1 实现的二级缓存的Executor类型
- 6.3.2 二级缓存在查询时使用
- 6.3.3 二级缓存在更新时清空
前言
缓存是MyBatis中非常重要的特性。合理使用缓存,可以减少数据库IO,显著提升系统性能;但在分布式环境下,如果使用不当则会带来数据一致性问题。
在上一节【MyBatis3源码深度解析(十六)SqlSession的创建与执行(三)Mapper方法的调用过程】中提到,MyBatis提供了一级缓存和二级缓存来提升查询效率,一级缓存在BaseExecutor类中完成,二级缓存在CachingExecutor类中完成。
第六章 MyBatis缓存
6.1 MyBatis缓存实现类
MyBatis缓存基于JVM堆内存实现,即所有的缓存数据都存放在Java对象中。 MyBatis通过Cache接口定义缓存对象的行为,其定义如下:
源码1:org.apache.ibatis.cache.Cachepublic interface Cache {// 获取缓存IDString getId();// 将一个Java对象添加到缓存中void putObject(Object key, Object value);// 根据key获取一个缓存对象Object getObject(Object key);// 根据key移除一个缓存对象Object removeObject(Object key);// 清空缓存void clear();// 获取缓存中存放的数据数量int getSize();// 3.2.6版本后不再使用default ReadWriteLock getReadWriteLock() {return null;}
}
Cache接口采用装饰器模式设计。它有一个基本的实现类PerpetualCache。
源码2:org.apache.ibatis.cache.impl.PerpetualCachepublic class PerpetualCache implements Cache {private final String id;// 内部维护了一个HashMap容器以保存缓存数据private final Map<Object, Object> cache = new HashMap<>();public PerpetualCache(String id) {this.id = id;}@Overridepublic String getId() {return id;}@Overridepublic int getSize() {return cache.size();}@Overridepublic void putObject(Object key, Object value) {cache.put(key, value);}@Overridepublic Object getObject(Object key) {return cache.get(key);}@Overridepublic Object removeObject(Object key) {return cache.remove(key);}@Overridepublic void clear() {cache.clear();}@Overridepublic boolean equals(Object o) {if (getId() == null) {throw new CacheException("Cache instances require an ID.");}if (this == o) {return true;}if (!(o instanceof Cache)) {return false;}Cache otherCache = (Cache) o;// 当两个缓存对象的ID相同时,即认为缓存对象相同return getId().equals(otherCache.getId());}@Overridepublic int hashCode() {if (getId() == null) {throw new CacheException("Cache instances require an ID.");}// 仅以缓存对象的ID作为因子生成hashCodereturn getId().hashCode();}
}
由 源码2 可知,PerpetualCache的实现非常简单,内部仅仅维护了一个HashMap实例存放缓存对象。
需要注意的是,PerpetualCache类重写了Object类的equals()方法和hashCode()方法。由equals()方法可知,当两个缓存对象的ID相同时,即认为缓存对象相同;由hashCode()方法可知,仅以缓存对象的ID作为因子生成hashCode。
除了基础的PerpetualCache实现类,MyBatis还提供了许多其他的实现,对PerpetualCache类的功能进行增强。借助IDE,可以列出Cache的全部实现类:

MyBatis的一级缓存,使用的是PerpetualCache;二级缓存使用的是TransactionalCache。
6.2 MyBatis一级缓存实现原理
MyBatis一级缓存默认是开启的,而且不能关闭。
至于一级缓存不能关闭的原因,MyBatis核心开发人员做出了解释:MyBatis的一些关键特性(例如通过<association>和<collextion>建立级联映射、避免循环引用(circular references)、加速重复嵌套查询等)都是基于MyBatis一级缓存实现的,而且MyBatis结果集映射相关代码重度依赖CacheKey,所以MyBatis一级缓存不支持关闭。
在MyBatis主配置文件中,有这样一个配置属性:<setting name="localCacheScope" value="SESSION"/>,用于控制一级缓存的级别。该属性的取值为SESSION、STATEMENT。
当指定localCacheScope参数值为SESSION时,缓存对整个SqlSession有效,只有执行DML语句(更新语句)时,缓存才会被清除;当指定localCacheScope参数值为STATEMENT时,缓存仅对当前执行的SQL语句有效,当语句执行完毕后,缓存就会被清除。
前面提到,一级缓存在BaseExecutor类中完成:
源码3:org.apache.ibatis.executor.BaseExecutorpublic abstract class BaseExecutor implements Executor {// ...// 一级缓存对象protected PerpetualCache localCache;// 存储过程输出参数缓存protected PerpetualCache localOutputParameterCache;// ...protected BaseExecutor(Configuration configuration, Transaction transaction) {// ...this.localCache = new PerpetualCache("LocalCache");this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");// ...}
}
由 源码3 可知,一级缓存使用PerpetualCache来实现,BaseExecutor中维护了两个PerpetualCache属性,localCache用于缓存MyBatis查询结果,localOutputParameterCache用于缓存存储过程输出参数。 这两个属性均在BaseExecutor的构造方法中初始化,并指定其ID。
MyBatis通过CacheKey对象来描述缓存的Key值。如果两次查询操作的CacheKey对象相同,就认为这两次查询执行的是相同的SQL语句。 CacheKey对象通过BaseExecutor的createCacheKey()方法来创建。
源码4:org.apache.ibatis.executor.BaseExecutor@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {if (closed) {throw new ExecutorException("Executor was closed.");}CacheKey cacheKey = new CacheKey();// Mapper的IDcacheKey.update(ms.getId());// 偏移量cacheKey.update(rowBounds.getOffset());// 查询条数cacheKey.update(rowBounds.getLimit());// SQL语句cacheKey.update(boundSql.getSql());// ......// SQL语句中的参数cacheKey.update(value);// ......// 配置文件中的<environment>标签的ID属性值if (configuration.getEnvironment() != null) {cacheKey.update(configuration.getEnvironment().getId());}return cacheKey;
}
由 源码4 可知,与CacheKey相关的因素包括:Mapper的ID、偏移量、查询条数、SQL语句、SQL语句中的参数、配置文件中的<environment>标签的ID属性值。
执行两次查询时,只有以上因素完全相同,才会认为这两次查询执行的是相同的SQL语句,才会直接从缓存中获取查询结果。
6.2.1 一级缓存在查询时的使用
解析来研究一下BaseExecutor的query()方法中是如何使用一级缓存的。
源码5:org.apache.ibatis.executor.BaseExecutor@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,CacheKey key, BoundSql boundSql) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());if (closed) {throw new ExecutorException("Executor was closed.");}if (queryStack == 0 && ms.isFlushCacheRequired()) {// 如果<select>标签的flushCache属性为true,则直接清除缓存// 默认为falseclearLocalCache();}List<E> list;try {queryStack++;// 从一级缓存中根据CacheKey获取缓存结果list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;if (list != null) {// 对存储过程输出参数的处理handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);} else {// 没有获取到缓存结果,则从数据库查询list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);}} finally {queryStack--;}if (queryStack == 0) {for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601deferredLoads.clear();if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {// 如果localCacheScope参数值为STATEMENT,缓存仅对当前执行的SQL语句有效,当语句执行完毕后,缓存就会被清除clearLocalCache();}}return list;
}private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {List<E> list;localCache.putObject(key, EXECUTION_PLACEHOLDER);try {list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);} finally {localCache.removeObject(key);}// 将从数据库查询的结果保存到一级缓存中localCache.putObject(key, list);if (ms.getStatementType() == StatementType.CALLABLE) {localOutputParameterCache.putObject(key, parameter);}return list;
}
由 源码5 可知,在BaseExecutor的query()方法中,首先会判断<select>标签的flushCache属性值,如果该属性为true,说明任何SQL语句被调用都需要先清除缓存,因此直接调用clearLocalCache()方法清除缓存。该属性在<select>标签中的默认值为false。
接着根据CacheKey从一级缓存中查找是否有缓存对象。如果查找不到,则调用queryFromDatabase()方法从数据库查询数据,并将查询结果保存到一级缓存中;如果查找到了,则直接返回。
最后,该方法还会判断主配置文件中的localCacheScope参数的值是否为STATEMENT,如果是STATEMENT,缓存仅对当前执行的SQL语句有效,因此当语句执行完毕后,直接调用clearLocalCache()方法清除缓存。
6.2.2 一级缓存在更新时的清空
除了flushCache属性和localCacheScope属性可以控制一级缓存的清空,MyBatis会在执行任意更新语句时清空缓存,即BaseExecutor的update()方法:
源码6:org.apache.ibatis.executor.BaseExecutor@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());if (closed) {throw new ExecutorException("Executor was closed.");}// 清空缓存clearLocalCache();// 执行任意更新语句return doUpdate(ms, parameter);
}
由 源码6 可知,MyBatis在调用doUpdate()方法执行更新语句之前,会调用clearLocalCache()方法清除缓存。
下面做个简单的测试。有以下单元测试代码,两次调用相同的selectAll()方法:
@Test
public void testCache() throws IOException, NoSuchMethodException {Reader reader = Resources.getResourceAsReader("mybatis-config.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);SqlSession sqlSession = sqlSessionFactory.openSession();UserMapper userMapper = sqlSession.getMapper(UserMapper.class);// 第一次调用selectAlluserMapper.selectAll();// 第二次调用selectAlluserMapper.selectAll();
}
借助Debug工具,可以发现第一次调用selectAll()方法是一级缓存中没有数据,程序会调用queryFromDatabase()方法从数据库查询数据,并存放到一级缓存中:

第二次调用selectAll()方法时,一级缓存中已经保存了第一次查询的数据,这次直接从缓存中就可以取到数据,而不需要再去数据库查询:

6.3 MyBatis二级缓存的实现原理
6.3.1 实现的二级缓存的Executor类型
在 MyBatis的官方文档 中说,默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。要启用全局的二级缓存,只需要在你的SQL映射文件中添加一行:<cache/>。
官方文档意思是,默认情况下,一级缓存是打开的,二级缓存是关闭的。要开启二级缓存,需要在SQL映射文件中添加一行:<cache/>。
源码7:org.apache.ibatis.builder.xml.XMLConfigBuilderprivate void settingsElement(Properties props) {// ......configuration.setCacheEnabled(booleanValueOf(props.getProperty("cacheEnabled"), true));// ......configuration.setDefaultExecutorType(ExecutorType.valueOf(props.getProperty("defaultExecutorType", "SIMPLE")));// ......
}
由 源码7 可知,在解析MyBatis主配置文件时,cacheEnabled属性的默认值是true,即默认使用二级缓存(允许使用不代表开启);defaultExecutorType属性的默认值是SIMPLE,即默认创建的Executor类型是SimpleExecutor。
前面提到,二级缓存是在CachingExecutor类中完成的。因此,MyBatis在创建Executor时,会根据主配置文件中的cacheEnabled属性和defaultExecutorType属性来判断创建哪种Executor。
该创建工作在Configuration对象的工厂方法newExecutor()中完成:
源码8:org.apache.ibatis.session.Configuration// 默认创建SimpleExecutor
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
// 默认开启二级缓存
protected boolean cacheEnabled = true;public Executor newExecutor(Transaction transaction) {return newExecutor(transaction, defaultExecutorType);
}// 指定Executor类型
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {executorType = executorType == null ? defaultExecutorType : executorType;Executor executor;if (ExecutorType.BATCH == executorType) {executor = new BatchExecutor(this, transaction);} else if (ExecutorType.REUSE == executorType) {executor = new ReuseExecutor(this, transaction);} else {executor = new SimpleExecutor(this, transaction);}// 如果cacheEnabled属性为true,则创建CachingExecutorif (cacheEnabled) {executor = new CachingExecutor(executor);}return (Executor) interceptorChain.pluginAll(executor);
}
由 源码8 可知,MyBatis默认允许使用二级缓存,其实现在CachingExecutor类中。
源码9:org.apache.ibatis.executor.CachingExecutorpublic class CachingExecutor implements Executor {private final Executor delegate;private final TransactionalCacheManager tcm = new TransactionalCacheManager();// ......
}
由 源码9 可知,CachingExecutor类中维护了一个TransactionalCacheManager实例,用于管理所有的二级缓存对象。
源码10:org.apache.ibatis.cache.TransactionalCacheManagerpublic class TransactionalCacheManager {// 通过HashMap对象维护二级缓存对应的TransactionalCache实例private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();// 清空缓存public void clear(Cache cache) {getTransactionalCache(cache).clear();}// 获取二级缓存对应的TransactionalCache对象// 根据根据缓存Key获取缓存对象public Object getObject(Cache cache, CacheKey key) {return getTransactionalCache(cache).getObject(key);}// 添加缓存public void putObject(Cache cache, CacheKey key, Object value) {getTransactionalCache(cache).putObject(key, value);}// 只有调用commit()方法后缓存对象才会真正添加到TransactionalCache中public void commit() {for (TransactionalCache txCache : transactionalCaches.values()) {txCache.commit();}}// 当调用rollback()方法时,写入操作将被回滚public void rollback() {for (TransactionalCache txCache : transactionalCaches.values()) {txCache.rollback();}}// 如果二级缓存对应的TransactionalCache获取不到,则创建一个新的private TransactionalCache getTransactionalCache(Cache cache) {return MapUtil.computeIfAbsent(transactionalCaches, cache, TransactionalCache::new);}}
由 源码10 可知,TransactionalCacheManager类中组合了一个HashMap对象,用于维护二级缓存实例对应的TransactionalCache对象。getObject()和putObject()方法均要先调用getTransactionalCache()方法获取到TransactionalCache对象,再对TransactionalCache对象进行操作。
源码11:org.apache.ibatis.cache.decorators.TransactionalCachepublic class TransactionalCache implements Cache {// 缓存对象,内部组合了一个HashMap实例private final Cache delegate;// 一个标志,为true时表示提交数据时要清空缓存对象,默认为falseprivate boolean clearOnCommit;// 保存即将存入二级缓存的数据private final Map<Object, Object> entriesToAddOnCommit;// 保存从二级缓存中没有取出的数据时的缓存Keyprivate final Set<Object> entriesMissedInCache;public TransactionalCache(Cache delegate) {this.delegate = delegate;this.clearOnCommit = false;this.entriesToAddOnCommit = new HashMap<>();this.entriesMissedInCache = new HashSet<>();}@Overridepublic Object getObject(Object key) {// 从二级缓存Cache对象中获取缓存数据Object object = delegate.getObject(key);if (object == null) {// 从二级缓存中没有取出数据,则将这个缓存Key保存下来entriesMissedInCache.add(key);}if (clearOnCommit) {return null;}return object;}@Overridepublic void putObject(Object key, Object object) {// 将要缓存的数据保存到HashMap集合(还没有真正加入到二级缓存中)entriesToAddOnCommit.put(key, object);}// 提交数据public void commit() {if (clearOnCommit) {delegate.clear();}// 刷新待处理的数据flushPendingEntries();// 清空两个容器的数据reset();}// 回滚数据public void rollback() {unlockMissedEntries();reset();}private void flushPendingEntries() {// 将entriesToAddOnCommit容器中的数据一一添加到Cache对象中for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {delegate.putObject(entry.getKey(), entry.getValue());}// 遍历entriesMissedInCache容器中的缓存Key// 去重后将Value值置空,添加到Cache对象中for (Object entry : entriesMissedInCache) {if (!entriesToAddOnCommit.containsKey(entry)) {delegate.putObject(entry, null);}}}private void reset() {clearOnCommit = false;entriesToAddOnCommit.clear();entriesMissedInCache.clear();}private void unlockMissedEntries() {// 遍历entriesMissedInCache容器中的缓存Key// 逐一从Cache对象中移除for (Object entry : entriesMissedInCache) {try {delegate.removeObject(entry);} // catch ...}}
}
由 源码11 可知,TransactionalCache类对Cache类进行了增强,除了组合一个Cache对象以保存缓存对象,还分别组合了一个HashMap容器和一个HashSet容器,分别用于保存即将存入Cache对象的数据,以及保存从二级缓存中没有取出的数据时的缓存Key。
(1)如果要将数据存入二级缓存,则调用putObject()方法。 该方法将要缓存的数据保存到entriesToAddOnCommit容器。注意此时数据还没有真正保存到Cache对象中。
要想数据真正保存到Cache对象中,还需要调用commit()方法,该方法会将entriesToAddOnCommit容器中的数据一一添加到Cache对象中,还会以entriesMissedInCache容器中的缓存Key(去重后的)也添加到Cache对象中,只是它的Value值为null。
这样做的目的在于,即使某个缓存Key的查询结果为null,也要缓存,下次相同的缓存Key查询时,直接返回null即可。
(2)如果要将数据从二级缓存中取出来,则调用getObject()方法,该方法会根据缓存Key从Cache对象中取数据,如果没有取到数据,则将当前缓存Key保存到entriesMissedInCache容器中;取到数据则直接返回。
6.3.2 二级缓存在查询时使用
执行查询SQL语句时,会调用CachingExecutor类的query()方法中:
源码12:org.apache.ibatis.executor.CachingExecutor@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler)throws SQLException {BoundSql boundSql = ms.getBoundSql(parameterObject);// 构造缓存KeyCacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler,CacheKey key, BoundSql boundSql) throws SQLException {// 获取MappedStatement对象中维护的二级缓存对象Cache cache = ms.getCache();if (cache != null) {// 判断是否需要刷新二级缓存flushCacheIfRequired(ms);// 主配置文件中的cacheEnabled属性为true时使用二级缓存if (ms.isUseCache() && resultHandler == null) {ensureNoOutParams(ms, boundSql);// 从二级缓存中获取缓存数据@SuppressWarnings("unchecked")List<E> list = (List<E>) tcm.getObject(cache, key);if (list == null) {// 二级缓存中没有获取到数据,则从数据库中查询list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);// 将数据库查询结果保存到二级缓存中tcm.putObject(cache, key, list); // issue #578 and #116}return list;}}// 没有二级缓存时,直接从数据库中查询return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}private void flushCacheIfRequired(MappedStatement ms) {Cache cache = ms.getCache();if (cache != null && ms.isFlushCacheRequired()) {// 如果<select>标签的flushCache属性为true,则直接清除缓存。默认为falsetcm.clear(cache);}
}
由 源码12 可知,CachingExecutor类的query()方法的逻辑如下:
(1)调用createCacheKey()方法创建缓存Key对象;
(2)调用MappedStatement对象的getCache()方法获取维护的二级缓存对象。如果有,则进入使用二级缓存的逻辑,如果没有则直接从数据库中查询。
(3)判断是否需要刷新二级缓存。如果<select>标签的flushCache属性为true(<select>标签中默认为false),则直接调用TransactionalCacheManager的clear()方法清除缓存。
(4)判断主配置文件中的cacheEnabled属性,为true时真正使用二级缓存。
(5)根据缓存Key从二级缓存中获取缓存数据,如果获取到了则直接返回,如果二级缓存中没有获取到数据,则从数据库中查询,再将数据库查询结果保存到二级缓存中。
6.3.3 二级缓存在更新时清空
和一级缓存一样,二级缓存也会在执行更新语句时被清空,即CachingExecutor类的update()方法:
源码13:org.apache.ibatis.executor.CachingExecutor@Override
public int update(MappedStatement ms, Object parameterObject) throws SQLException {// 必要时清空二级缓存flushCacheIfRequired(ms);// 执行更新语句return delegate.update(ms, parameterObject);
}
由 源码13 可知,在执行更新SQL语句之前,会根据<select|insert|update|delete>标签的flushCache属性来判断是否需要清空二级缓存。
而<select>标签的flushCache属性值默认为false,<insert|update|delete>标签的flushCache属性值默认为true,因此在执行更新语句时会清空二级缓存。
…
下面做个简单的测试。沿用上面的单元测试代码,两次调用相同的selectAll()方法,不一样的是,查询后需要手动调用commit()方法(SELECT语句不会自动调用commit()方法):
@Test
public void testCache() throws IOException, NoSuchMethodException {Reader reader = Resources.getResourceAsReader("mybatis-config.xml");SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);SqlSession sqlSession = sqlSessionFactory.openSession();UserMapper userMapper = sqlSession.getMapper(UserMapper.class);// 第一次调用selectAll并手动提交userMapper.selectAll();sqlSession.commit();// 第二次调用selectAll并手动提交userMapper.selectAll();sqlSession.commit();
}
另外,还需要在SQL映射文件中添加一行:<cache/>。
借助Debug工具,可以发现第一次调用selectAll()方法时二级缓存中没有数据,程序会调用query()方法从数据库查询数据,并存放到二级缓存中:

第二次调用selectAll()方法时,二级缓存中已经保存了第一次查询的数据,这次直接从缓存中就可以取到数据,而不需要再去数据库查询:

注意,如果单元测试中没有sqlSession.commit();这一行代码,会发现数据不会保存到二级缓存中。
…
本节完,更多内容请查阅分类专栏:MyBatis3源码深度解析
相关文章:
MyBatis3源码深度解析(十七)MyBatis缓存(一)一级缓存和二级缓存的实现原理
文章目录 前言第六章 MyBatis缓存6.1 MyBatis缓存实现类6.2 MyBatis一级缓存实现原理6.2.1 一级缓存在查询时的使用6.2.2 一级缓存在更新时的清空 6.3 MyBatis二级缓存的实现原理6.3.1 实现的二级缓存的Executor类型6.3.2 二级缓存在查询时使用6.3.3 二级缓存在更新时清空 前言…...

Go --- Go语言垃圾处理
概念 垃圾回收(GC-Garbage Collection)暂停程序业务逻辑SWT(stop the world)程序根节点:程序中被直接或间接引用的对象集合,能通过他们找出所有可以被访问到的对象,所以Go程序的根节点通常包括…...

力扣每日一题30:串联所有单词的子串
题目描述 给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。 例如,如果 words ["ab","cd","ef"], 那么 &q…...

vim | vim的快捷命令行
快捷进入shell界面 -> :nnoremap <F8> :sh<CR> -> 绑定到了F8 :nnoremap <F8> :sh<CR> 快捷执行 -> :nnoremap <F5> :wa<CR>:!g % -o a.out && ./a.out<CR> -> 绑定到了F5 :nnoremap <F5> :wa<CR>…...

项目管理平台-01-BugClose 入门介绍
拓展阅读 Devops-01-devops 是什么? Devops-02-Jpom 简而轻的低侵入式在线构建、自动部署、日常运维、项目监控软件 代码质量管理 SonarQube-01-入门介绍 项目管理平台-01-jira 入门介绍 缺陷跟踪管理系统,为针对缺陷管理、任务追踪和项目管理的商业…...
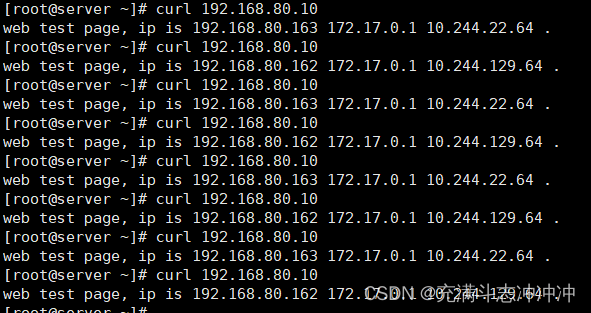
web集群-lvs-DR模式基本配置
目录 环境: 一、配置RS 1、安装常见软件 2、配置web服务 3、添加vip 4、arp抑制 二、配置LVS 1、添加vip 2、安装配置工具 3、配置DR 三、测试 四、脚本方式配置 1、LVS-DR 2、LVS-RS 环境: master lvs 192.168.80.161 no…...

基于深度学习的面部情绪识别算法仿真与分析
声明:以下内容均属于本人本科论文内容,禁止盗用,否则将追究相关责任 基于深度学习的面部情绪识别算法仿真与分析 摘要结果分析1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若…...
)
C语言经典面试题目(十六)
1、什么是C语言中的指针常量和指针变量?它们有什么区别? 在C语言中,指针常量和指针变量是指针的两种不同类型。它们的区别在于指针的指向和指针本身是否可以被修改。 指针常量:指针指向的内存地址不可变,但指针本身的…...
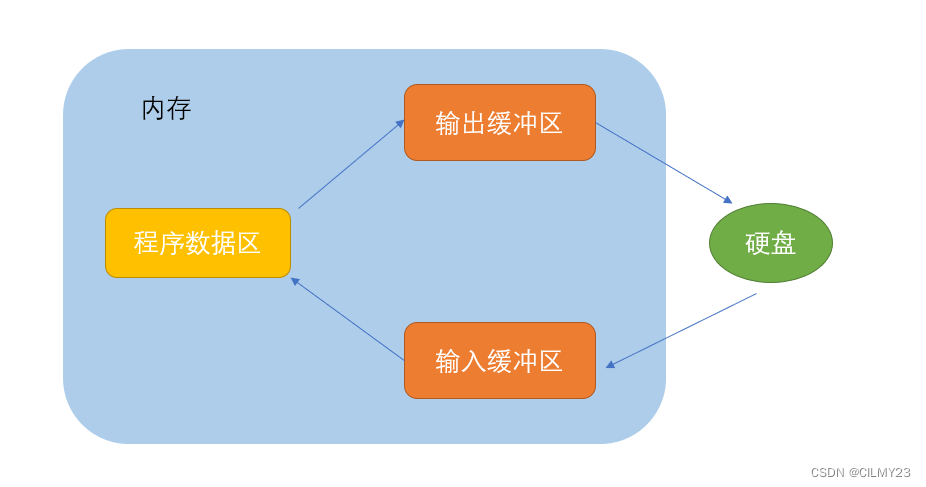
【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】
欢迎来CILMY23的博客喔,本篇为【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】,感谢观看,支持的可以给个一键三连,点赞关注收藏。 前言 欢迎来到本篇博客&…...

JAVA八股文面经问题整理第6弹
文章目录 目录 文章目录 提问问题 问题1 问题2 问题3 问题4 问题5 问题6 问题7 问题8 问题9 问题10 问题11 问题12 写在最后 提问问题 介绍一下Linux常⽤命令,例如:Vim快捷键,常⽤查看Log的命令,路径相关&#x…...

pytest相关面试题
pytest是什么?它有什么优点? pytest是一个非常流行的Python测试框架,它具有简洁、易用、高校等优点。他可以帮助测试人员方便地编写和运行测试用例,并且提供了丰富的插件和扩展,支持各种测试需求介绍下pytest常用的库 …...

Keras库搭建神经网络
Keras并非简单的神经网络库,而是一个基于Theano的强大的深度学习库,利用它不仅仅可以搭建普通的神经网络,还可以搭建各种深度学习模型,如自编码器、循环神经网络、递归神经网络、卷积神经网络等。 安装代码: pip ins…...

适配器模式与桥接模式-灵活应对变化的两种设计策略大比拼
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自:设计模式深度解析:适配器模式与桥接模式-灵活应对变…...

Elasticsearch8搭建及Springboot中集成使用
1.搭建 1.1.下载地址 Elasticsearch:https://www.elastic.co/cn/downloads/elasticsearch Kibana:https://www.elastic.co/cn/downloads/kibana 1.2.具体过程 下载安装包:访问上述链接,下载适合你操作系统的Elasticsearch和Ki…...
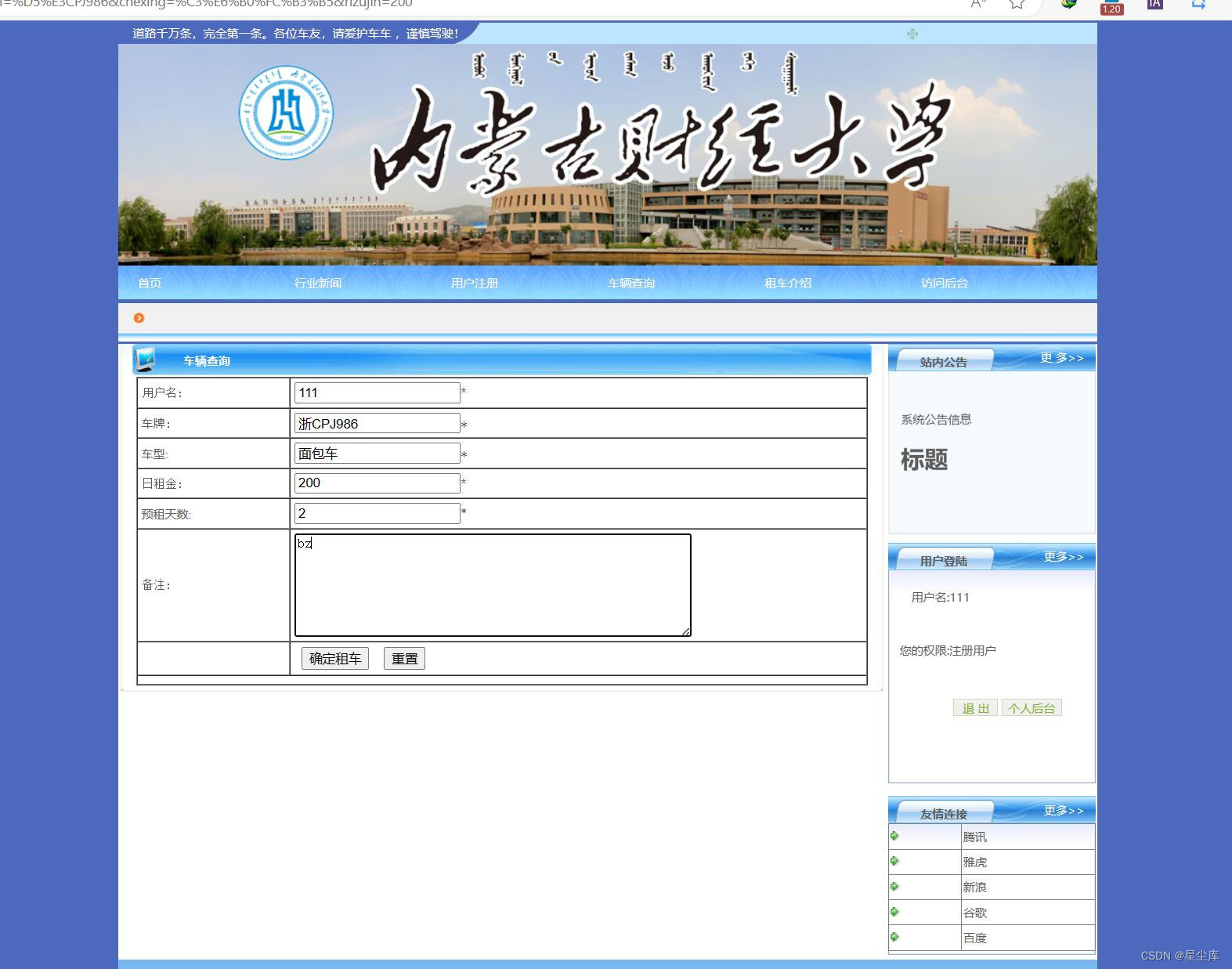
asp.net在线租车平台
说明文档 运行前附加数据库.mdf(或sql生成数据库) 主要技术: 基于asp.net架构和sql server数据库 功能模块: asp.net在线租车平台 用户功能有首页 行业新闻用户注册车辆查询租车介绍访问后台 后台管理员可以进行用户管理 管…...
Beamer模板——基于LaTeX制作学术PPT
Beamer模板——基于LaTeX制作学术PPT 介绍Beamer的基本使用安装和编译用于学术汇报的模板项目代码模板效果图 Beamer的高级特性动态效果分栏布局定理环境 介绍 在学术领域,演示文稿是展示和讨论研究成果的重要方式。传统的PowerPoint虽然方便,但在处理复…...
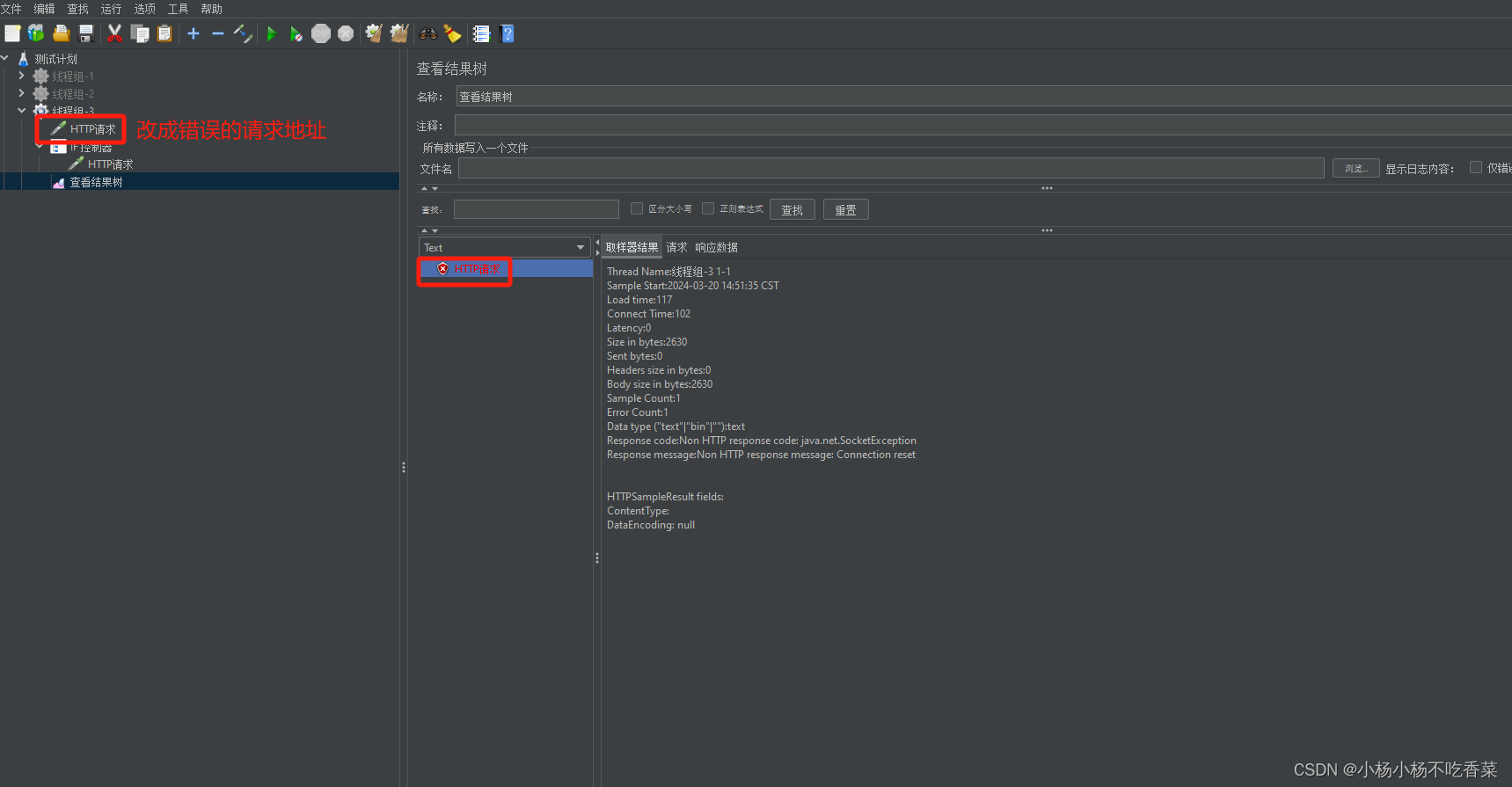
性能测试-Jmeter中IF控制器使用
一、Jmeter控制器 分为两种类型: 控制测试计划执行过程中节点的逻辑执行顺序,如:循环控制器,if控制器等对测试计划中的脚本进行分组,方便Jmeter统计执行结果以及进行脚本的运行时控制等,如:吞…...
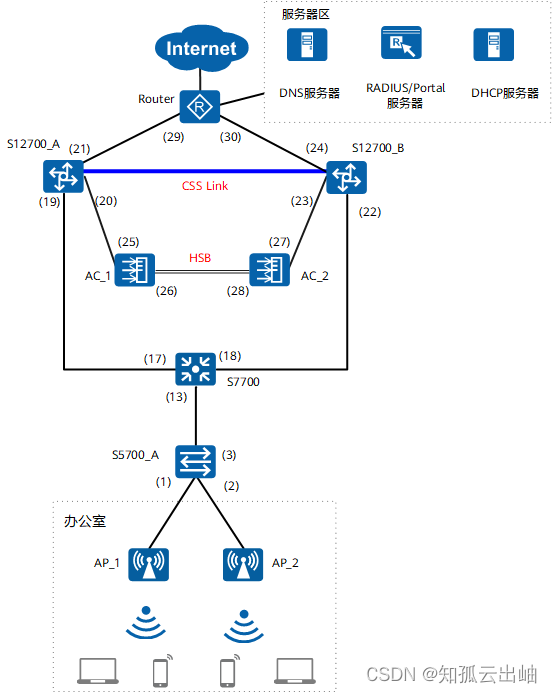
华为综合案例-普通WLAN全覆盖配置(2)
组网图 结果验证 在AC_1和AC_2上执行display ap all命令,检查当前AP的状态,显示以下信息表示AP上线成功。[AC_1] display ap all Total AP information: nor : normal [1] ExtraInfo : Extra information P : insufficient power supply ---…...

这里是一本关于 DevOps 企业级 CI/CD 实战的书籍...
文章目录 📋 前言🎯 什么是 DevOps🎯 什么是 CI/CD🎯什么是 Jenkins🧩 Jenkins 简单案例 🎯 DevOps 企业级实战书籍推荐🔥 参与方式 📋 前言 企业级 CI/CD 实战是一个涉及到软件开发…...

机器学习 - save和load训练好的模型
如果已经训练好了一个模型,你就可以save和load这模型。 For saving and loading models in PyTorch, there are three main methods you should be aware of. PyTorch methodWhat does it do?torch.saveSaves a serialized object to disk using Python’s pickl…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...
)
保姆级教程:手把手教你搞定ESXi 6.7安装前的BIOS设置(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7安装前的BIOS设置终极指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我记得自己第一次在Dell PowerEdge服务器上安装ESXi时,光是搞清楚BIOS里那些晦涩的选项就花了整整一…...