【动态三维重建】Deformable 3D Gaussians 可变形3D GS用于单目动态场景重建(CVPR 2024)
主页:https://ingra14m.github.io/Deformable-Gaussians/
代码:https://github.com/ingra14m/Deformable-3D-Gaussians
论文:https://arxiv.org/abs/2309.13101

文章目录
- 摘要
- 一、前言
- 二、相关工作
- 2.1 动态场景的神经渲染
- 2.2 神经渲染加速
- 三、方法
- 3.1 正则空间三维GS的可微渲染
- 3.2 可变形的3D高斯
- 3.3 退火平滑训练
- 四、实验
- 4.1 实施细节
- 4.2 合成数据集的比较
- 4.3 真实数据集比较
- 4.4 消融实验
- *总结与局限性
- * 一些demo
摘要
提示:这里是大概内容:
隐式神经表示为动态场景重建和渲染的新方法铺平了道路。尽管如此,先进的动态神经渲染方法很大程度依赖这些隐式表示,经常难以捕捉场景中物体的复杂细节。此外,隐式方法在一般动态场景中实现实时渲染,限制了它们在各种任务中的使用。为了解决这一问题,我们提出了一种可变形的三维高斯分布的splatting 方法,该方法使用三维高斯分布来重建场景,并在具有变形场的规范空间中学习它们,以建模单目动态场景。我们还引入了一种没有额外开销的退火平滑训练机制,它可以减轻不准确的姿态对真实世界数据集中时间插值任务的平滑性的影响。通过微分高斯光栅化器,可变形三维高斯不仅获得更高的渲染质量,而且实时渲染速度。实验表明,我们的方法在渲染质量和速度方面都显著优于现有的方法,使其非常适合于新视图合成、时间插值和实时渲染等任务。
一、前言
从一组输入图像中获得的动态场景的高质量重建和逼真渲染对各种应用都至关重要,包括增强现实/虚拟现实(AR/VR)、3D内容制作和娱乐。以前用于建模这些动态场景的方法在很大程度上依赖于基于网格的表示,如文献[9,14,18,40]的方法所示。然而,这些策略经常面临固有的限制,如缺乏细节和真实性,缺乏语义信息,以及难以适应拓扑变化。随着神经渲染技术的引入,这种范式经历了一个重大的转变。隐式场景表示,特别是由NeRF [28]实现的,在新颖视图合成、场景重建和光分解等任务中显示出了值得称赞的功效。
为了提高基于NeRF 的静态场景中的推理效率,研究人员开发了多种加速方法,包括基于网格的结构[7,46]和预计算策略[44,52]。值得注意的是,通过合并哈希编码,Instant-NGP[29]已经实现了快速训练。在质量改进方面,MipNeRF [2]率先采用了一种有效的抗混叠方法,后来由ZipNeRF [4]将其纳入到基于网格的方法中。3D-GS [15]最近将基于点的渲染扩展到高效的三维高斯CUDA实现,它可以在匹配甚至超过Mip-NeRF [2]的质量时实现实时渲染。然而,这种方法是为表示静态场景而设计的,其高度定制的CUDA栅格化管道降低了其可伸缩性。
隐式表示已经被越来越多地用于建模动态场景。 为了处理动态场景中的运动部分,entangled(纠缠) 方法[43,49]将NeRF设置在一个时间变量上。相反,disentangled 解纠缠方法[23,30,31,34,39]通过在给定时间映射到该空间的点坐标来建模规范空间中的场景。这种解耦的建模方法可以有效地表示具有非戏剧性动作变化的场景。然而,无论如何分类,对动态场景采用隐式表示往往被证明是低效和无效的(缓慢的收敛速度,以及明显的过拟合敏感性)。从NeRF加速研究中获得灵感,许多关于动态场景建模的研究已经整合了离散的结构,如体素网格[11,38],或plane[6,36]。这种集成提高了训练速度和建模精度。然而,挑战仍然存在。 利用离散结构的技术,面临实时渲染和产生足够细节的高质量输出的双重约束问题。 多个方面支撑着这些挑战:首先,射线投射,作为一种渲染模式,经常变得低效,特别是当缩放到更高的分辨率时。其次,基于网格的方法依赖于一个低秩的假设。与静态场景相比,动态场景具有更高的秩,这阻碍了这种方法可达到的质量上限。
本文扩展了静态三维-gs,提出了一个可变形的三维高斯框架来建模动态场景。为了提高模型的适用性,我们特别关注了单目动态场景的建模。不同于逐帧重建场景,我们 以时间为3D高斯的条件,在正则空间中与可学习的三维高斯联合训练纯隐式变形场。这两个分量的梯度是由一个定制的微分高斯栅格化管道得到的。此外, 为了解决在重构过程中由于不准确的姿态而引起的时间序列抖动,我们采用了退火平滑训练(AST)机制。这种策略不仅提高了时间插值任务中帧之间的平滑性,而且还允许渲染更多的细节
二、相关工作
2.1 动态场景的神经渲染
最近,NeRF [28]通过使用MLPs促进了逼真的新视图的合成。随后的研究将NeRF的应用扩展到各种应用,包括从图像集合[20,45]中进行网格重建,反渲染[5,25,54],相机参数[21,47,48]的优化和 few-shot学习等任务
构建动态场景的辐射场是NeRF发展的一个关键分支,对重要的应用意义。渲染这些动态场景的一个主要挑战是对时间信息的编码和有效利用,特别是单目动态场景的重建,一个任务本质上涉及从单一视角的稀疏重建。 一类动态NeRF方法通过将时间 t 作为辐射场的额外输入来模拟场景形变 。然而,这种策略将由时间变化引起的位置变化与辐射场结合起来,缺乏关于时间对现场影响的几何先验信息。因此,需要大量的正则化来确保渲染结果的时间一致性。 另一类方法[30,31,34]引入了一个变形场来解耦时间和辐射场,通过变形场将点坐标映射到与时间t对应的规范空间 。这种解耦的方法有利于学习明显的刚性运动,并且足够多样化,以适应发生拓扑变化的场景。 其他方法从各个方面提高动态神经渲染的质量,包括分割场景[39,42]中的静态和动态对象,结合深度信息[1]引入几何先验,引入2D CNN编码场景先验[22,33],利用多视点视频[19]中的冗余信息设置关键帧压缩存储 ,从而加快渲染速度
然而,现有的基于MLP(多层感知器)的动态场景建模的渲染质量仍然不理想。在这项工作中,我们将专注于单眼动态场景的重建。我们继续解耦变形场和辐射场。为了提高动态场景中中间状态的可编辑性和渲染质量,我们采用了这种建模方法,以适应基于可微点的渲染框架。
2.2 神经渲染加速
实时渲染长期以来一直是计算机图形学领域的一个关键目标,这也是神经渲染领域的一个目标。许多致力于NeRF加速的研究已经细致地导航了空间和时间效率之间的权衡。
预计算的方法[12,35]利用空间加速度结构,如球谐系数[52]和特征向量[13],缓存或从隐式神经表示中提取,而不是直接使用神经表示本身。这一类中一个突出的技术[Mobilenerf]将NeRF场景转换为粗的mesh和特征纹理的合并,从而提高渲染速度。然而,这种预先计算的方法可能需要对单个场景的大量存储容量。虽然它在推理速度方面具有优势,但它需要延长的训练时间,并表现出相当大的开销。
混合方法[4,7,24,27,41,46]在显式的grid 中包含了一个神经组件,具有双重好处,即加速训练和推理阶段,同时产生与高级框架[2,3]相同的结果。这主要归因于网格的强大的表示能力。这种基于grid或plane的策略已扩展到,动态场景建模和时间条件压缩的四维动态场景建模中的时间条件四维特征的加速或表示
近年来,一些研究[16,53]已经将连续辐射场从隐式表示发展为可微的基于点的辐射场,显著提高了渲染速度。3D-GS [15]进一步创新了基于点的渲染,引入了一个定制的基于古巴的可微高斯栅格化管道。这种方法不仅在新视图合成和场景建模等任务中取得了优越的结果,而且促进了每分钟量级的快速训练时间,并支持超过100 FPS的实时渲染。然而,该方法采用了一个定制的微分高斯栅格化管道,这使其直接扩展到动态场景变得复杂。受此启发,我们的工作将利用基于点的渲染框架,3D-GS,来加快动态场景建模的训练和渲染速度
三、方法
方法的概述如图2。 输入是一组单目动态场景的图像,以及SfM [37]校准的时间标签和相应的相机 pose,也产生稀疏点云 。从这些点出发,我们 创建了一组三维高斯 G(x,r,s,σ),由中心位置x、不透明度σ和由四元数r 和 缩放s得到的三维协方差矩阵Σ。每个三维高斯的视图相关外观通过球谐波(SH)表示。为了模拟随时间变化的动态三维高斯分布,我们解耦了三维高斯分布和变形场。 变形场以三维高斯分布的位置和当前时间t作为输入,输出δx、δr和δs。随后,将变形的三维高斯 G (x+δx, r+δr, s+δs, σ) 放入高效微分高斯栅格化管道中,这是一个基于tile瓦片的光栅化器,允许各向异性splats的α混合。
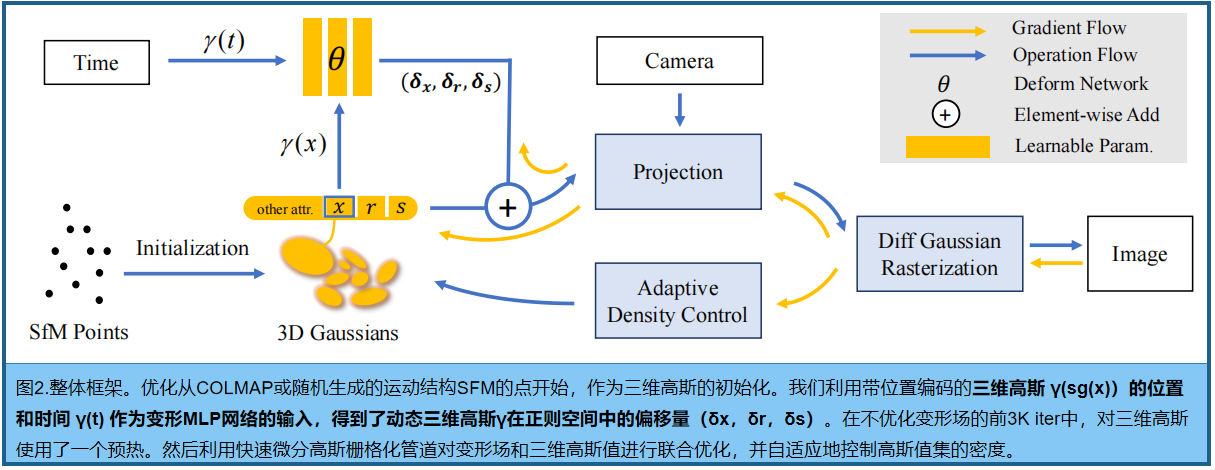
通过跟踪累积的α值,并对高斯密度进行自适应控制,共同优化了三维高斯分布和变形网络。实验结果表明,经过30k的训练迭代,三维高斯分布的形状稳定,正则空间(canonical space)也稳定,间接证明了我们设计的有效性。
3.1 正则空间三维GS的可微渲染
为了在规范空间中优化三维高斯图像的参数,必须对这些三维高斯图像的二维图像进行可微渲染 。在本工作中,我们采用了原始GS提出的微分高斯栅格化管道。按照论文[Ewa volume splatting],三维高斯分布可以被投影到二维,并使用以下二维协方差矩阵Σ‘对每个像素进行渲染:

其中,J为投影变换的仿射近似的雅可比矩阵;V表示视图矩阵,从世界坐标过渡到摄像机坐标;Σ表示三维协方差矩阵
为了使三维高斯分布的学习更容易,Σ被分为两个可学习的分量:四元数r表示旋转,三维向量s表示缩放。然后将这些分量转换为相应的旋转和缩放矩阵R和s,得到的Σ可以表示为:

图像平面上的像素的颜色,用p表示,用基于点的体渲染技术按顺序渲染:
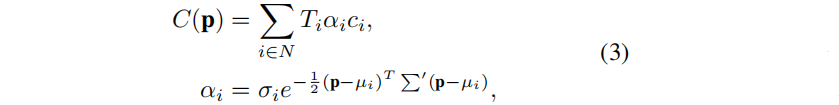
其中,Ti是由 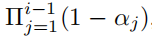 定义的透射率,ci 表示沿射线的高斯分布的颜色;µi 表示投影到二维图像平面上的三维高斯分布的uv坐标。
定义的透射率,ci 表示沿射线的高斯分布的颜色;µi 表示投影到二维图像平面上的三维高斯分布的uv坐标。
在优化过程中,自适应密度控制成为一个关键的组成部分,使三维高斯分布的渲染能够达到理想的结果。该控制具有双重目的:首先,它要求基于σ对透明高斯分布进行剪枝。其次,它对高斯分布的稠密化, 这填补了几何复杂的区域,同时细分了高斯分布较大并表现出显著重叠的区域。值得注意的是,这些区域倾向于显示出明显的位置梯度。按照原始GS,使用tpos = 0.0002给出的阈值来识别需要进行调整的三维高斯分布。对于不足以捕捉几何细节的小高斯分布,我们克隆高斯分布,并在位置梯度的方向上移动一定的距离。相反,对于那些明显大且重叠的,我们将它们分割,并除以超参数ξ = 1.6
很明显,三维高斯分布只适用于表示静态场景。对每个三维高斯分布应用一个时间条件的可学习参数,不仅与可微高斯栅格化管道的原始意图相矛盾,而且会导致 运动的时空连续性的损失 。为了使三维高斯能够表示动态场景,同时保留其个别可学习组件的实际物理意义,我们决定在规范空间中学习三维高斯,并使用一个额外的变形场来学习三维高斯的位置和形状变化。
3.2 可变形的3D高斯
使用三维高斯模型建模动态场景的一个直观解决方案是在每个时间依赖的视图集合中分别训练3D-GS集,然后在这些集之间执行插值作为后处理步骤。虽然这种方法对于离散时间的MVS捕获是可行的,但无法在一个时间序列内进行连续的单眼捕获 (it falls short for continuous monocular captures) 。
我们通过利用一个变形网络和三维高斯分布来解耦运动和几何结构,将学习过程转换为一个正则空间,以获得与时间无关的三维高斯分布。这种解耦方法引入了场景的几何先验,将三维高斯分布位置的变化,与时间和坐标联系起来。变形网络的核心是一个MLP。在我们的研究中,我们没有使用应用于静态NeRF的grid/plane来加速渲染和提高质量。这是因为这种方法是在低秩假设下运行的,而动态场景具有更高的秩。基于显式点的渲染进一步提高了场景的秩。
给定时间 t 和三维高斯的中心位置 x 作为输入,MLP产生偏移量,然后将canonical 3D GS 转换到de formed space:
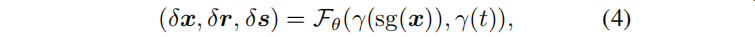
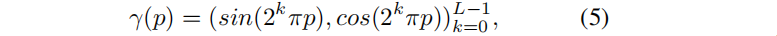
其中,sg(·) 表示停止梯度操作,γ表示位置编码。在合成场景中,x采用L = 10,t的L=6;真实场景中,x和t都为L = 10。变形网络的深度D = 8和隐藏层的维数W = 256。实验表明,对变形网络的输入端应用位置编码可以增强渲染结果的细节。
3.3 退火平滑训练
真实数据集,在不精确姿态下的训练会导致训练数据的过拟合,动态场景中非常明显。正如HyperNeRF [31]中提到的,真实数据集的不精确pose 会导致每帧的空间抖动;渲染时,测试与Groudtruth明显偏差。以前使用隐式表示的方法得益于MLP固有的平滑性,这使得这种微小的偏移量对最终渲染结果的影响相对不明显。然而,显式的基于点的渲染倾向于放大这种效果。 对于单目动态场景,在固定时间内的新视图渲染不受影响。然而,对于涉及插值时间的任务,这种不同时间的不一致场景会导致不规则的渲染抖动。
为解决问题,提出退火平滑训练(AST)机制,专门为现实世界的单目动态场景设计:
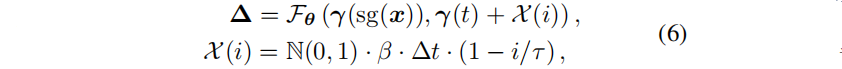
X(i)表示第i个训练步的线性衰减高斯噪声;N(0,1)是标准高斯,β是经验比例因子(0.1),∆t代表平均时间间隔,τ是退火平滑训练的iteration阈值(经验设为20k)。
与[D-nerf、Tensor4d]方法引入的平滑损失相比,我们的方法不会产生额外的计算开销。它可以在训练早期增强模型的时间泛化,防止后期过度平滑,从而保留动态场景中对象的细节。同时,它减少了在时间插值任务期间在真实数据集中观察到的抖动。
四、实验
在基准测试上评估,基准包括来自D-NeRF [34]的合成数据集和来自HyperNeRF [31]和NeRF-DS [50]的真实数据集。 训练和测试部分的划分,以及图像分辨率,与原论文完全一致。
4.1 实施细节
使用PyTorch [32]实现框架,并通过合并深度可视化来修改可微高斯栅格化。训练共40k次迭代,前3k次迭代只训练三维高斯分布来获得相对稳定的位置和形状。随后,我们联合训练三维高斯分布和变形场。对于优化,使用一个Adam优化器[17],但每个组件的学习率不同:三维高斯的学习率与官方实现完全相同,而变形网络的学习率经历指数衰减,从8e-4到1.6e-6。Adam的β值范围设置为(0.9,0.999)。合成数据集的实验都是在黑色背景下进行的,全分辨率为800x800。所有的实验都是在NVIDIA RTX 3090上进行的。
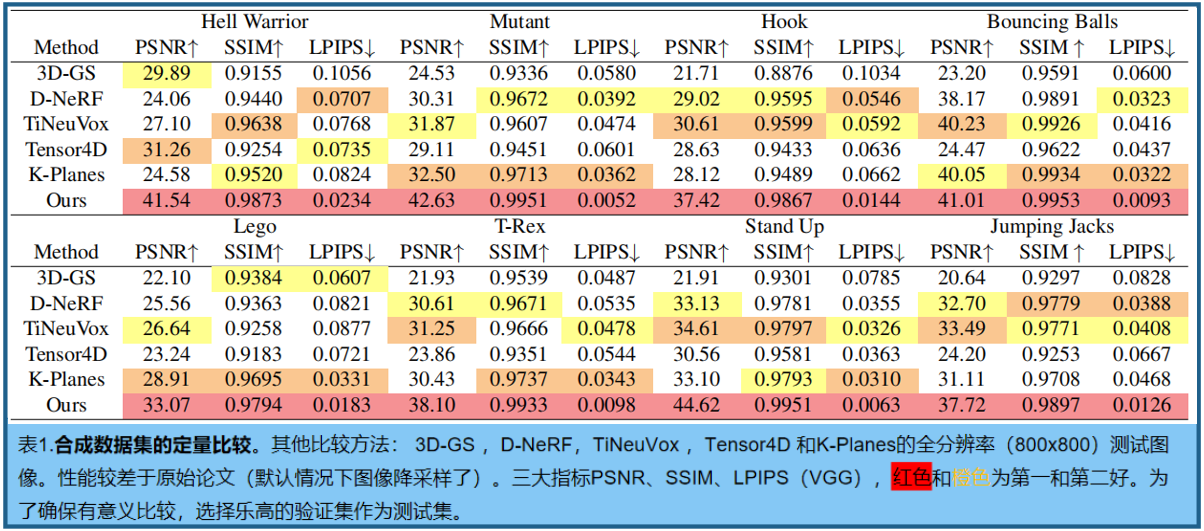
4.2 合成数据集的比较
D-NeRF 的单目合成数据集,定量比较见表1。图3中提供了定性结果,显示了高保真的动态场景建模能力(确保了增强的一致性,并在新视图渲染中捕获了复杂的渲染细节)
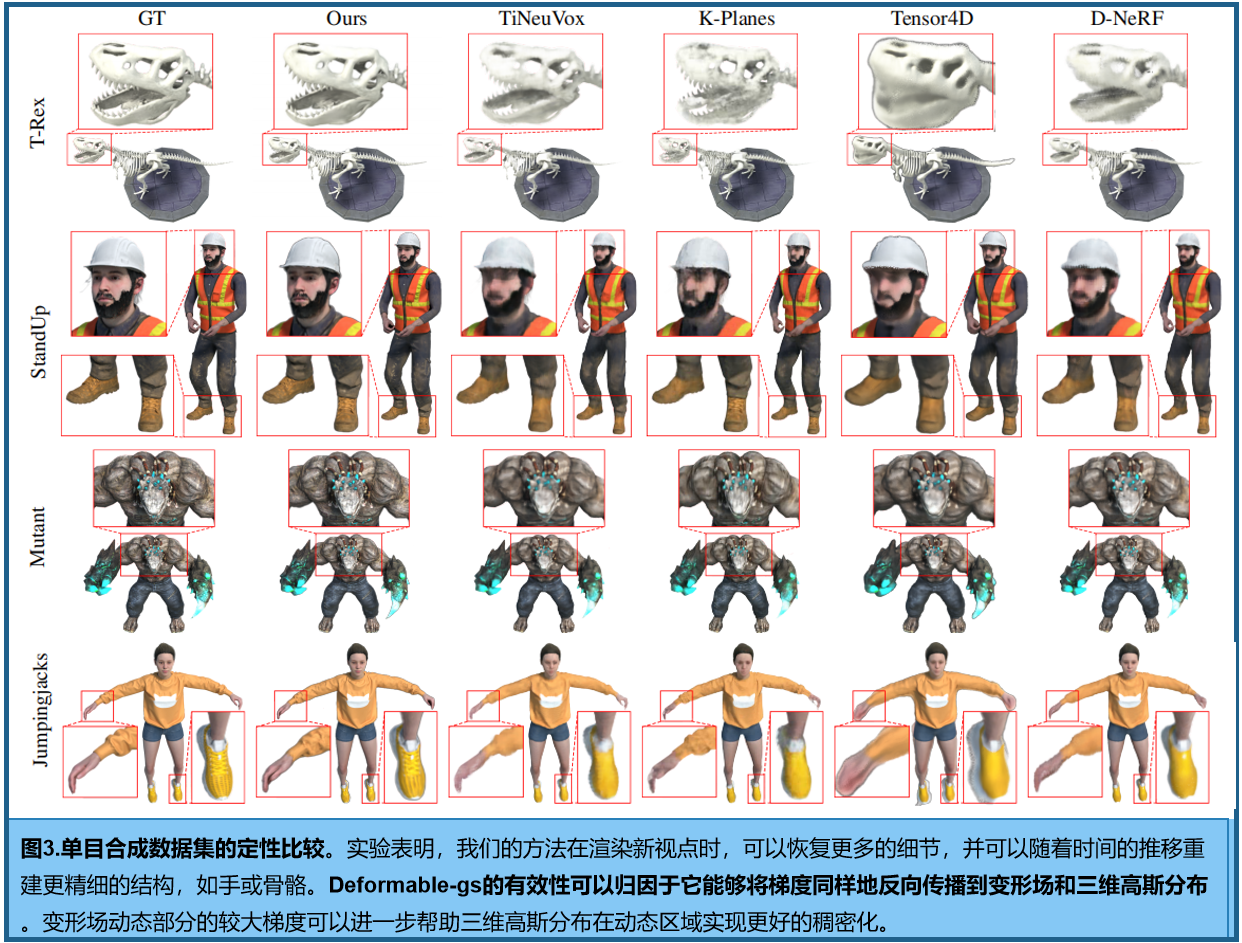
4.3 真实数据集比较
NeRF-DS [50]和HyperNeRF [31]的单目真实数据基线进行了比较。 注意,一些HyperNeRF数据集的相机姿态是非常不准确的。考虑到像PSNR这样的旨在评估图像渲染质量的指标,倾向于惩罚轻微的偏差而不是模糊,我们没有在定量分析中纳入HyperNeRF。详细信息见表2和图5。这些结果证明了我们的方法在应用于真实世界的场景时的鲁棒性,即使相关的pose并不完全准确
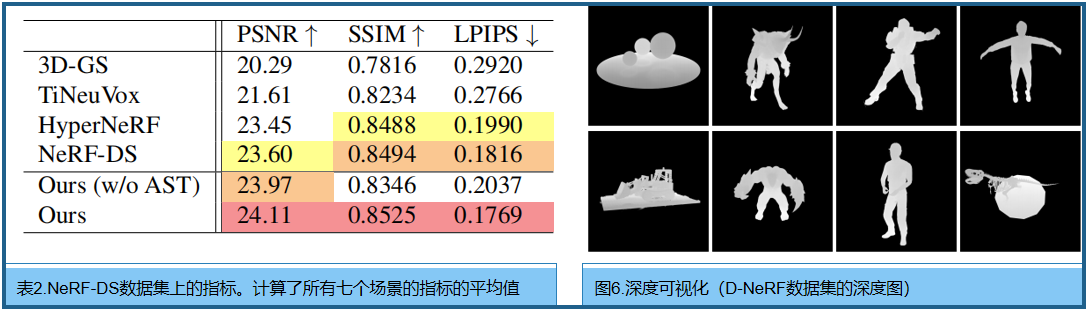

渲染效率。渲染速度与三维高斯的数量相关。总的来说,当三维高斯数低于250k时,我们的方法可以在NVIDIA RTX 3090上实现超过30 FPS的实时渲染。
深度可视化。图6中合成数据集场景的深度可视化,以证明我们的变形网络很好地适合产生 temporal transformation,而不是依赖于基于颜色的硬编码。精确的深度强调了我们的几何重建的准确性,证明了非常有利于新视图合成任务。
4.4 消融实验
退火平滑训练如图4和表2,这种机制促进了对复杂区域的收敛,有效地减轻了真实数据集中的过拟合趋势。此外,从我们的观察中可以明确地清楚地看出,这种策略显著地支持了变形场的时间平滑性。

*总结与局限性
局限性:通过实验评估,观察到三维高斯分布的收敛性受到视角多样性的深刻影响。因此,具有稀疏视点和有限视点覆盖范围特征的数据集可能会导致我们的方法遇到过拟合的挑战 。此外, 我们的方法的有效性取决于姿态估计的准确性 。当我们的方法在Nerfes/HyperNeRF数据集上没有达到最优PSNR值时,这种依赖性很明显,这归因于COLMAP姿态估计的偏差。此外, 我们的方法的时间复杂度与三维高斯分布的量成正比。在具有大量3D高斯函数数组的场景中,训练时间和记忆消耗都有潜在的升级。最后, 我们的评估主要围绕着具有中等运动动力学的场景。这种方法在处理复杂的人体动作,如微妙的面部表情,仍然是一个悬而未决的问题 。
提示:这里对文章进行总结:
本文介绍了一种新的可变形的三维GS方法,专门为单目动态场景建模而设计,它在质量和速度上都超过了现有的方法。通过在正则空间中学习三维高斯分布,我们增强了动态捕获单目场景的三维-gs可微渲染管道的通用性。与隐式表示相比,基于点的方法更加重要,它更易于编辑,更适合于后期生产任务。此外,我们的方法结合了一个退火平滑训练策略,旨在减少与时间编码相关的过拟合,同时保持复杂的场景细节,而不增加任何额外的训练开销。
* 一些demo
1.D-NeRF Datasets:


2.HyperNeRF Datasets:

3.真实场景:

相关文章:
【动态三维重建】Deformable 3D Gaussians 可变形3D GS用于单目动态场景重建(CVPR 2024)
主页:https://ingra14m.github.io/Deformable-Gaussians/ 代码:https://github.com/ingra14m/Deformable-3D-Gaussians 论文:https://arxiv.org/abs/2309.13101 文章目录 摘要一、前言二、相关工作2.1 动态场景的神经渲染2.2 神经渲染加速 三…...
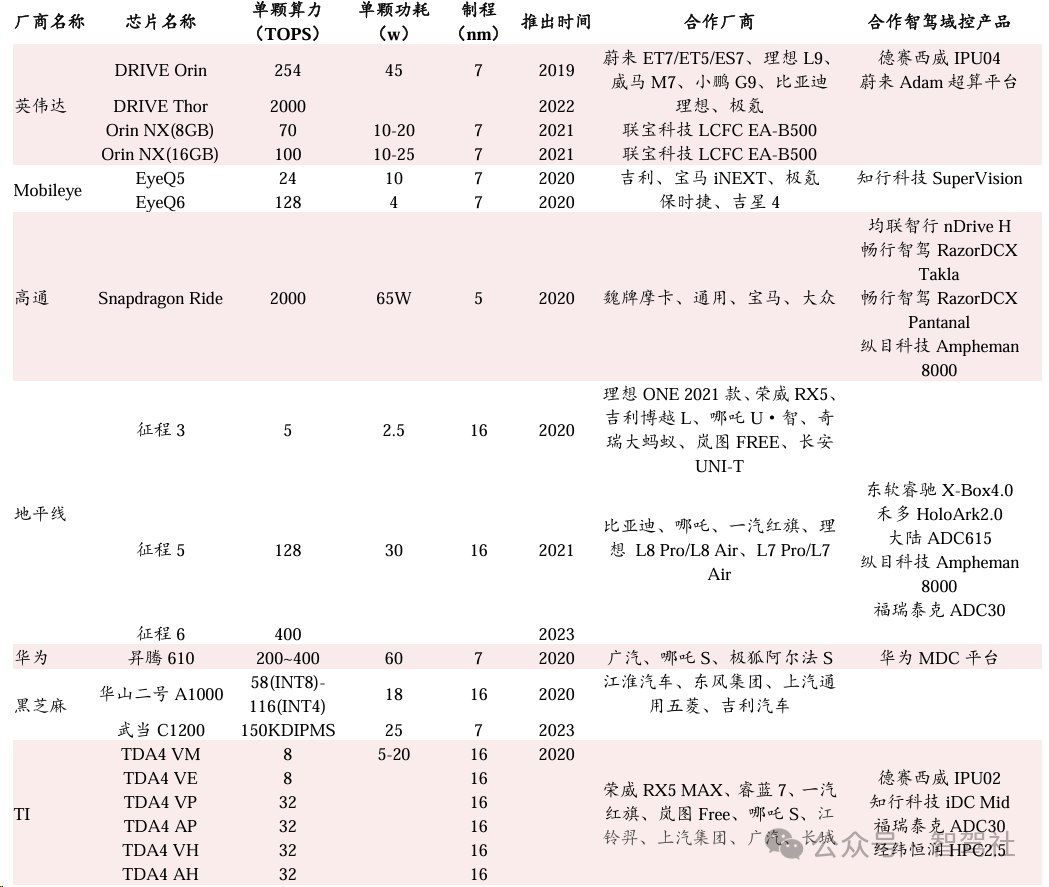
智能驾驶域控制器行业介绍
汽车智能驾驶功能持续高速渗透,带来智能驾驶域控制器市场空间快速增 长。智驾域控制器是智能驾驶决策环节的重要零部件,主要功能为处理感知 信息、进行规划决策等。其核心部件主要为计算芯片,英伟达、地平线等芯 片厂商市场地位突出。随着消费…...

[数据集][目标检测]焊接件表面缺陷检测数据集VOC+YOLO格式2292张10类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2292 标注数量(xml文件个数):2292 标注数量(txt文件个数):2292 标注…...

微信小程序的页面制作---常用组件及其属性
微信小程序里的组件就是html里的标签,但其组件都自带UI风格和特定的功能效果 一、常用组件 view(视图容器)、text(文本)、button(按钮)、image(图片)、form(…...

什么样的网站不适合使用WordPress?
WordPress作为全球应用最广泛的CMS系统,很好很强大,被从多的网站使用。但是,也不是所有的网站。下面简站WP小编从自己多年WordPress建站经验的角度,给大家讲讲,有哪些网站不适合使用WordPress搭建。 1、功能特别多的功…...
vulhub中GitLab 任意文件读取漏洞复现(CVE-2016-9086)
GitLab是一款Ruby开发的Git项目管理平台。在8.9版本后添加的“导出、导入项目”功能,因为没有处理好压缩包中的软连接,已登录用户可以利用这个功能读取服务器上的任意文件。 环境运行后,访问http://your-ip:8080即可查看GitLab主页࿰…...

【爬虫】web自动化和接口自动化
专栏文章索引:爬虫 目录 一、介绍 二、推荐 1.接口自动化 2.Web自动化 一、介绍 爬虫技术一般可以分为两种类型:接口自动化和web自动化。下面是它们的简要介绍: 1.接口自动化 接口自动化技术的主要目的是通过模拟HTTP请求来实现自动化…...

哔哩哔哩后端Java一面
前言 作者:晓宜 个人简介:互联网大厂Java准入职,阿里云专家博主,csdn后端优质创作者,算法爱好者 最近各大公司的春招和实习招聘都开始了,这里分享下去年面试B站的的一些问题,希望对大家有所帮助…...
Vue.js前端开发零基础教学(二)
目录 前言 2.1 单文件组件 2.2 数据绑定 2.2.2 响应式数据绑定 2.3 指令 2.3.1 内容渲染指令 2.3.2 属性绑定指令 编辑 2.3.3 事件绑定指令 2.3.4 双向数据绑定指令 2.3.5 条件渲染指令 2.3.6 列表渲染指令 2.4 事件对象 2.5 事件修饰符 学习目标&am…...

Bert模型输出:last_hidden_state转换为pooler_output
1. BERT模型的输出 在BERT模型中,last_hidden_state和pooler_output是两个不同的输出。 (1) last_hidden_state: last_hidden_state是指BERT模型中最后一个隐藏层的隐藏状态。它是一个三维张量,其形状为[batch_size, sequence_length, hidden_size]。其…...

Docker Compose 基本语法
services 是顶级节点,也就是你要启动的服务全部放在这里。 MySOL就是我们预期中的一个服务。 mysql8:指的是我们这个服务叫 mysql8. image:我们这个服务里运行的是什么镜像,或者说跑的是什么。这里指定了使用 mysql:8.0.29 这个版本。 command:启动命令&…...

【算法集训】基础算法:贪心
1913. 两个数对之间的最大乘积差 void insertSort(int * a, int n) {for(int i 1; i < n; i) {int temp a[i];int j i - 1;while(j > 0 && temp < a[j]) {a[j 1] a[j];j--;}a[j 1] temp;} }int maxProductDifference(int* nums, int numsSize){insert…...
Centos7部署单节点MongoDB(V4.2.25)
🎈 作者:互联网-小啊宇 🎈 简介: CSDN 运维领域创作者、阿里云专家博主。目前从事 Kubernetes运维相关工作,擅长Linux系统运维、开源监控软件维护、Kubernetes容器技术、CI/CD持续集成、自动化运维、开源软件部署维护…...
)
隐私计算笔记(1)
一、可信流通体系 建立数据来源可确认、使用范围可界定、流通过程可追溯、安全风险可防范的数据可流通体系。 二、产生信任的基石 身份可确认利益可依赖能力有预期行为有后果 三、数据流通不可信风险 内循环:在内部循环中,数据持有方在其自身的运维…...

查询方法需要使用事务吗?
当数据库隔离级别是默认的可重复读(Repeatable Read)时,如果查询语句只有一条则不需要事务. 当有多条查询sql语句且需要确保多条sql语句处于同一时间维度时则需要使用事务来确保多条SQL语句处于同一时间节点. 相关知识点 mysql查询当前事务隔…...

剑指offer面试题40 数组中只出现一次的数字
考察点 异或运算,与运算知识点 题目 分析 本题目要求数组中只出现一次的俩个数字,并且要求O(1)时间复杂度和空间复杂度。试想一下如果只有一个数字出现一次,那么针对全部元素做异或运算就可以了,因为相同元素异或为0。现在有俩…...
gitLab server version 13.12.1 is not supported
拉代码的时候,报的这个错,实际上就是因为gitLab 版本太低了,这里不准备升级版本,打算继续使用账号密码来拉取代码 在idea已经安装的插件中,去掉gitlab插件,如下: 之后再拉取代码,就…...

如何在 iPhone 上使用蓝牙鼠标
iPhone 不支持使用传统的鼠标指针。 然而,有一个名为“AssistiveTouch”的功能可以在屏幕上模拟类似光标的指针。 启用它的方法如下: 打开 iPhone 上的“设置”应用程序。转到“辅助功能”。向下滚动并选择“触摸”。点击“辅助触控”。切换开关以打开 …...
matlab simulink 电力系统同步发电机励磁系统的建模与仿真
1、内容简介 略 77-可以交流、咨询、答疑 电力系统同步发电机励磁系统的建模与仿真 建立MATLAB的同步发电机励磁调节系统仿真模型,最后建立了以PID和PSS为励磁控制方式的同步发电机励磁调节系统数学模型,在Simulink环境下进行了仿真,收到…...

AI新工具(20240320) AI创作一首属于自己的音乐; 轻松制作具有透明背景的高质量图像
✨ 1: Suno AI创作一首属于自己的音乐 Suno是一个革命性的人工智能平台,专注于音乐创作。在通俗的语言中,Suno允许用户仅通过提供歌词,自动为其创作旋律和演唱,产生完整的音乐作品。使用Suno的过程简单直观,不需要用…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...

13456
12356...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...