大模型提示学习样本量有玄机,自适应调节方法好
引言:探索文本分类中的个性化示例数量
在自然语言处理(NLP)领域,预测模型已经从零开始训练演变为使用标记数据对预训练模型进行微调。这种微调的极端形式涉及到上下文学习(In-Context Learning, ICL),其中预训练生成模型的输出(冻结的解码器参数)仅通过输入字符串(称为指令或提示)的变化来控制。ICL的一个重要组成部分是在提示中使用少量标记数据实例作为示例。尽管现有工作在推理过程中对每个数据实例使用固定数量的示例,但本研究提出了一种根据数据动态调整示例数量的新方法。这类似于在k-最近邻(k-NN)分类器中使用可变大小的邻域。 该研究提出的自适应ICL(Adaptive ICL, AICL)工作流程中,在特定数据实例上的推理过程中,通过分类器的Softmax后验概率来预测使用多少示例。这个分类器的参数是基于ICL中正确推断每个实例标签所需的最佳示例数量来拟合的,假设与训练实例相似的测试实例应该使用相同(或接近匹配)的少量示例数量。实验表明,AICL方法在多个标准数据集上的文本分类任务中取得了改进。
论文标题:
‘One size doesn’t fit all’: Learning how many Examples to use for In-Context Learning for Improved Text Classification
论文链接:
https://arxiv.org/pdf/2403.06402.pdf
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
理解在上下文学习中使用示例的动机
上下文学习(In-Context Learning, ICL),通过改变输入字符串(称为指令或提示)来控制预训练生成模型(冻结的解码器参数)的输出。ICL的一个重要组成部分是在提示中使用少量标记数据实例作为示例。
动机来源于信息检索(IR),不同的查询由于信息需求的固有特性或查询的制定质量,表现出不同的检索性能。将IR中的查询类比为ICL中的测试实例,以及将本地化示例视为潜在相关文档,假设某些测试实例与训练示例的关联更好(即包含它们作为提示的一部分可以导致正确预测),因此包含少量示例就足够了。另一方面,某些测试实例作为查询的检索质量不佳,因此需要进一步查看排名列表以收集有用的示例。这意味着需要替换查询与文档相关性的概念,以及测试实例对示例的下游有用性。
选择可变数量的本地化示例的想法也类似于为k-NN分类选择可变大小的邻域,关键是同质邻域可能只需要相对较小的邻域就能做出正确预测,而非同质邻域可能需要更大的邻域。这个想法可以应用于ICL,其中一个测试实例如果与多个具有冲突标签的训练实例相似,可能需要更多的示例。

上下文学习(ICL)方法介绍
1. ICL的定义和工作原理
上下文学习(ICL)与监督学习不同,不涉及在标记示例上训练一组参数θ。相反,后验概率是以下因素的函数:a) 输入测试实例的文本,b) 预训练LLM的解码器参数,c) 提示指令,d) 可选的一组k个输入示例(通常称为k-shot学习)。在这里,与监督设置不同,函数f没有参数化表示,可以使用带有梯度下降的训练集进行学习。函数本身依赖于预训练的LLM参数,当前输入的标签预测,以及由Nk(x)表示的k个文本单元组成的提示。
由于LLM的解码器生成一系列单词w1, ..., wl(l是序列的最大长度),类别后验概率通过将p个可能的类别映射到p组不同的等效单词集V(y)来计算,其中y ∈ Zp,这些集合通常称为verbalisers。
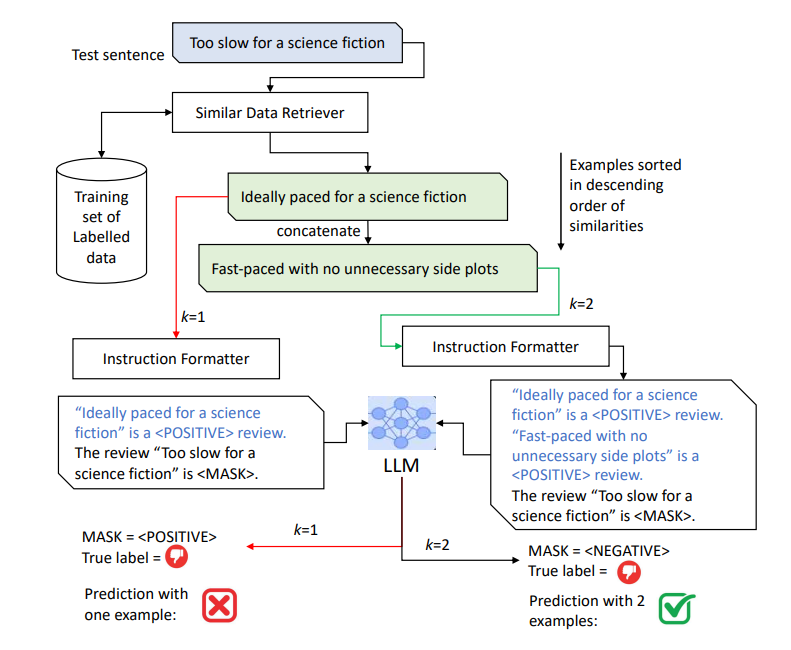
2. ICL中的示例选择和其重要性
ICL的一个最重要的组成部分是搜索组件,它输出训练集中与当前实例相似的top-k候选集。虽然原则上可以在提示中包含来自训练集的随机示例,但已经证明本地化示例(即与当前实例主题相似的示例)可以提供更好的性能。
上下文学习中的自适应(AICL)
1. AICL的动机和理论基础
自适应在上下文学习(Adaptive In-Context Learning,简称AICL)的动机源自信息检索(IR)领域的实践,其中不同的查询由于信息需求的固有特性或查询的构造方式而表现出不同的检索性能。类似地,在自然语言处理(NLP)中,特定的测试实例在使用上下文学习(In-Context Learning,简称ICL)时,可能会因为训练示例的选择而影响预测结果。AICL的理论基础与k-最近邻(k-NN)分类器中使用可变大小邻域的概念相似,即对于同质的邻域,可能只需要较小的邻域就能做出正确的预测,而对于非同质的邻域,则可能需要更大的邻域。AICL的目标是动态地适应每个数据实例所需的示例数量,以提高文本分类任务的性能。
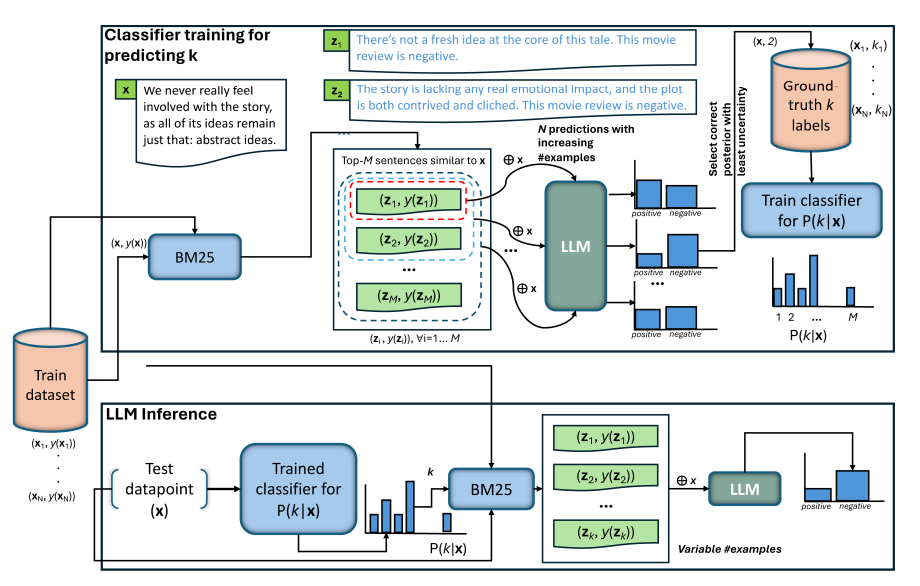
2. AICL工作流程
ICL的工作流程包括两个主要阶段:训练和推理。在训练阶段,首先对训练集中的每个实例执行k-shot推理,逐步增加k的值,然后基于一些标准(例如最少示例数量导致正确预测)来确定最佳的示例数量。这个最佳示例数量随后用于训练一个分类器,该分类器能够根据训练数据中的相似实例预测测试实例所需的示例数量。在推理阶段,给定一个测试实例,首先使用训练好的分类器预测所需的示例数量,然后将这些示例作为额外上下文输入到预训练的语言模型(LLM)中,以进行下游任务的预测。
3. 选择示例数量的方法
选择示例数量的方法是通过监督学习来解决的。对于训练集中的每个实例,首先使用逐渐增加的示例数量进行k-shot推理,然后根据一些启发式标准(例如最小示例数量或分类置信度)来确定理想的示例数量。这些理想的示例数量随后用于训练一个分类器,该分类器能够泛化到未见过的数据上,预测测试实例所需的示例数量。

实验设计与数据集
1. 使用的数据集和任务说明
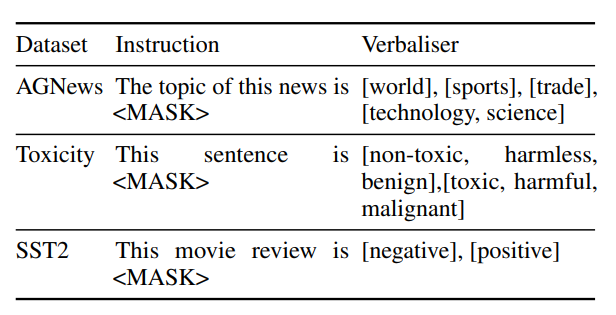
实验使用了三个文本分类数据集:AGNews、Jigsaw Toxic Comment和SST2。AGNews是一个主题分类数据集,包含来自网络的新闻文章,分为世界、体育、商业和科技四个类别。Jigsaw Toxic Comment数据集包含从维基百科的讨论页中提取的评论,这些评论被人类评估者按照六个代表有害行为的类别进行了注释。SST2是一个情感分析数据集,包含从电影评论中提取的句子,用于二元分类任务。
2. AICL的不同变体和比较方法
AICL的变体包括AICL-L和AICL-U,分别应用最小示例数量和基于置信度的启发式来训练预测示例数量的分类器。此外,还比较了0-shot、静态ICL(SICL)和随机ICL(RICL)方法。SICL使用固定数量的示例作为输入,而RICL使用从训练集中随机采样的固定数量的示例。这些方法的性能通过精确度、召回率和F分数等指标进行评估,并考虑了平均输入大小(AIS)和相对运行时间(RRT)作为效率指标。


实验分析
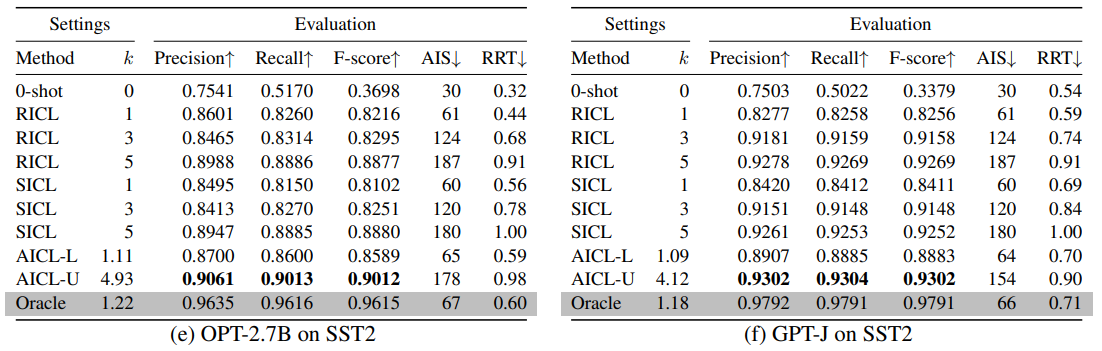
1. AICL与其他基线方法比较
实验结果表明,自适应上下文学习(AICL)方法在文本分类任务上优于静态ICL(SICL)和随机ICL(RICL)等基线方法。AICL通过动态调整用于推断的示例数量,避免了非相关(无用)示例的负面影响。AICL学习了主题内容与所需上下文量之间的潜在关系,有效地指导了解码器输出的正确方向。
2. AICL在不同数据集上的表现
在AGNews、Toxicity和SST2等标准数据集上的实验显示,AICL在不同的文本分类任务中均表现出色。例如,在AGNews数据集上,AICL的平均精度、召回率和F分数均超过了SICL和RICL。这表明AICL能够自动适应特定领域,而无需进行领域特定的调整。
3. AICL的效率和准确性分析
AICL不仅在准确性上表现出色,而且在效率上也有所提升。AICL能够使用更少的输入大小(平均k值和AIS值),这意味着在与SICL相匹配的示例数量下,AICL的计算速度更快。此外,AICL与测试集标签访问的oracle方法相比,仅在有效性和效率上略有落后,尤其是在主题分类和电影评论检测任务(AGNews和SST2)上。
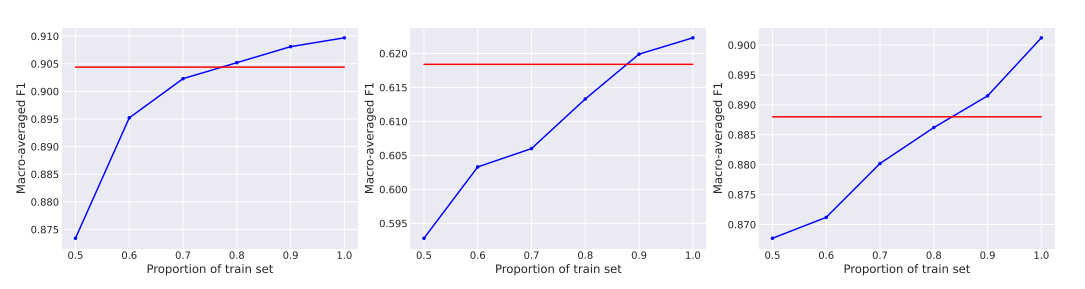
AICL的实际应用
1. 训练κ分类器的实际性
训练κ分类器以预测测试实例的理想示例数量可能在大型训练数据集上不切实际。然而,实验表明,使用训练数据的80%就足以超过SICL的性能,这表明κ分类器可以在较小的数据集上有效地训练。
2. AICL在不同训练数据规模下的表现
在不同比例的训练数据上进行的实验表明,即使在训练数据较少的情况下,AICL也能够保持良好的性能。这为在资源受限的环境中部署AICL提供了可能性,同时也表明AICL对训练数据的规模不太敏感。
结论与未来展望
1. AICL方法总结
本研究提出了一种新颖的自适应上下文学习(Adaptive In-Context Learning, AICL)方法,旨在改进文本分类任务的性能。AICL方法的核心思想是动态调整用于推理的示例数量,而不是在所有测试实例中使用固定数量的示例。这种方法类似于k-最近邻(k-NN)分类器中使用可变大小的邻域。通过预测每个测试实例所需的示例数量,AICL能够根据数据本身的特性来调整示例的数量,从而提高预测的准确性和运行时效率。
实验结果表明,AICL在多个标准数据集上的文本分类任务中,相比静态上下文学习(Static ICL, SICL)方法,能够取得更好的效果。AICL通过学习训练集中每个实例所需的最佳示例数量,并将这一信息泛化到未见过的数据上,从而实现了对测试实例的有效推理。此外,AICL在计算效率上也表现出色,因为使用较少的示例可以减少输入字符串的长度,从而缩短解码时间。
2. 未来展望
未来的研究将探索自适应上下文学习(AICL)方法的其他潜在改进方向,例如调整语言模型的提示模板和口令(verbaliser)。此外,研究将考虑如何在不同的任务和数据集上进一步优化AICL方法,以及如何将AICL与其他类型的学习策略(例如主动学习或元学习)结合起来,以提高模型的泛化能力和适应性。
考虑到在大型训练数据集上进行语言模型推理可能在实践中不太可行,未来的工作还将探讨如何在较小的数据集上有效地训练κ分类器。初步的实验结果表明,使用训练数据的80%就足以超过静态上下文学习(SICL)的性能,这为在资源受限的情况下训练κ分类器提供了可能性。
总之,AICL方法为自然语言处理中的上下文学习提供了一种有效的改进策略,未来的研究将继续在这一方向上深入探索,以实现更加智能和高效的文本处理能力。


相关文章:
大模型提示学习样本量有玄机,自适应调节方法好
引言:探索文本分类中的个性化示例数量 在自然语言处理(NLP)领域,预测模型已经从零开始训练演变为使用标记数据对预训练模型进行微调。这种微调的极端形式涉及到上下文学习(In-Context Learning, ICL)&…...

Redis监控工具
Redis 是一种 NoSQL 数据库系统,以其速度、性能和灵活的数据结构而闻名。Redis 在许多领域都表现出色,包括缓存、会话管理、游戏、排行榜、实时分析、地理空间、叫车、聊天/消息、媒体流和发布/订阅应用程序。Redis 数据集完全存储在内存中,这…...

低代码表单设计器为企业数字转型强劲赋能!
想要实现数字化转型,创造流程化办公,让企业在信息高速发展的社会中抢占更多市场份额,进一步提升市场竞争力,就需要借助专业的软件平台提高效率。低代码开发平台拥有易操作、灵活、可视化的发展优势,作为一种新型的应用…...
最佳实践和准则)
【C#】Conventions(惯例)最佳实践和准则
在C#中,Conventions(惯例)是指编写代码时的一套最佳实践和准则。这些惯例旨在提高代码的可读性、一致性和可维护性。虽然这些惯例不是语言的强制规则,但遵循它们可以使你的代码更加清晰和专业。 以下是一些常见的C#编码惯例: 命名约定: 使用有意义的、描述性的名称。类名和公…...

vue3中使用cesium
vue3中使用cesium Cesium是一个开源的JavaScript库,专门用于创建3D地球和2D地图的Web应用程序。它提供了丰富的功能和工具,使得开发人员能够轻松地构建出高质量的地理空间可视化应用。 1. 安装cesium包 npm install cesium2. 复制node_modules中的Ces…...
arduino ide 开发esp8266注意事项
1.引脚序列号必须是常量来定义,否则会无限重启。 #define p2 2 const int Pin2p2; pinMode(Pin2, OUTPUT); 2.关于wifi的模式,ap,sta,apsta三种模式的初始化必须放在void set_up(){}这个函数里,不能额外搞个自定义函数…...

RTC协议与算法基础 - RTP/RTCP
首先,需要说明下,webrtc的核心音视频传输是通过RTP/RTCP协议实现的,源码位于src/modules/rtp_rtcp目录下: 下面让我们对相关的内容基础进行简要分析与说明: 一、TCP与UDP协议 1.1、TCP协议 TCP为了实现数据传输的可…...
:飞机大作战)
c语言游戏实战(8):飞机大作战
前言: 飞机大作战游戏是一种非常受欢迎的射击类游戏,玩家需要控制一架战斗机在屏幕上移动,击落敌机以获得分数。本游戏使用C语言编写,旨在帮助初学者了解游戏开发的基本概念和技巧。 在开始编写代码之前,我们需要先了…...

docker 部署k8s相关命令操作
1.安装docket 可参考其他网站 2.docker ps 3.docker images 4.docker ps -all 5.docker pull openjdk:8 安装jdk8 6.docker load < jdk.tar 自己有jdk8 7.打包jar服务 ,需要依赖一个打包文件Dockerfile,如下 文件内容如下 FROM openjdk:8u275-j…...

使用Tesseract识别中文 并提高精度
1. 使用中文训练数据 在使用pytesseract进行中文文本识别时,确保安装了中文的训练数据文件。在Tesseract的安装目录下的tessdata文件夹中应包含一个名为chi_sim.traineddata(简体中文)或chi_tra.traineddata(繁体中文)…...
基于Jenkins + Argo 实现多集群的持续交付
作者:周靖峰,青云科技容器顾问,云原生爱好者,目前专注于 DevOps,云原生领域技术涉及 Kubernetes、KubeSphere、Argo。 前文概述 前面我们已经掌握了如何通过 Jenkins Argo CD 的方式实现单集群的持续交付,…...
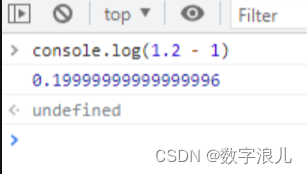
关于javascript数字精度丢失的解决办法
分析原因 众所周知,在JavaScript中计算两个十进制数的和,有时候会出现令人惊讶的结果,主要原因是计算机将数据存储为二进制所引起的,所以这并不是javascript存在的缺陷,而在其他语言中也有类似的问题。 例如下面的例子…...

每日一题 第二十一期 洛谷 组合的输出
组合的输出 题目描述 排列与组合是常用的数学方法,其中组合就是从 n n n 个元素中抽出 r r r 个元素(不分顺序且 r ≤ n r \le n r≤n),我们可以简单地将 n n n 个元素理解为自然数 1 , 2 , … , n 1,2,\dots,n 1,2,…,n&a…...

JavaScript 面试题
问题 1 // 请解释什么是 JavaScript 中的原型继承,以及原型链的概念答案 1 原型继承是 JavaScript 中实现继承的一种方式,每个对象都有一个指向另一个对象的引用,这个对象就是原型。当访问对象的属性或方法时,如果对象本身没有该…...

java输入语句scanner
在Java中,Scanner 类是 java.util 包中的一个类,它用于获取用户的输入。要使用 Scanner 类,你首先需要导入这个类,然后创建一个 Scanner 对象,通常命名为 scanner。你可以使用这个对象来读取用户从键盘输入的数据。 以…...

Python从入门到精通秘籍十一
一、Python之自定义模块并导入 在Python中,我们可以自定义模块并将其导入到其他Python程序中使用。自定义模块可以包含函数、类、常量等,便于组织和重用代码。 下面是使用Python代码详细讲解自定义模块的创建和导入的例子: 假设我们有两个…...
WRF模型教程(ububtu系统)-WPS(WRF Pre-Processing System)概述
一、WPS简介 WRF 预处理系统 (WRF Pre-Processing System,WPS) ,集成了基于Fortran和C编写的程序,这些程序主要用于处理输入到real.exe的数据。WPS主要有三个程序和一些辅助程序。 二、各程序介绍 主要的程序为geogrid.exe、ungrib.exe、met…...
)
C语言向C++过渡的基础知识(一)
目录 C关键字 C命名空间 命名空间的介绍 域作用限定符 命名空间的使用 C的输入以及输出 C中的缺省参数 缺省参数的介绍 缺省参数的使用 缺省参数的分类 全缺省参数 半缺省参数 C关键字 在C中,有63个关键字,而C语言只有32个关键字 asm do i…...
GEE遥感云大数据林业应用典型案例及GPT模型应用
近年来遥感技术得到了突飞猛进的发展,航天、航空、临近空间等多遥感平台不断增加,数据的空间、时间、光谱分辨率不断提高,数据量猛增,遥感数据已经越来越具有大数据特征。遥感大数据的出现为相关研究提供了前所未有的机遇…...
macOS Ventura 13.6.5 (22G621) Boot ISO 原版可引导镜像下载
macOS Ventura 13.6.5 (22G621) Boot ISO 原版可引导镜像下载 3 月 8 日凌晨,macOS Sonoma 14.4 发布,同时带来了 macOS Ventru 13.6.5 和 macOS Monterey 12.7.4 安全更新。 macOS Ventura 13.6 及更新版本,如无特殊说明皆为安全更新&…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题
Windows Cleaner:终极免费系统清理工具,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘爆红、…...

基于TESS光变曲线与深度学习的O型星物理参数预测研究
1. 项目概述与核心挑战在恒星天体物理研究中,大质量O型星扮演着至关重要的角色。它们不仅是宇宙中光度最高的天体之一,其强烈的辐射、恒星风和最终的超新星爆发,更是驱动星系化学演化和能量注入星际介质的关键引擎。然而,深入理解…...