[Spark SQL]Spark SQL读取Kudu,写入Hive
SparkUnit
Function:用于获取Spark Session
package com.example.unitlimport org.apache.spark.sql.SparkSessionobject SparkUnit {def getLocal(appName: String): SparkSession = {SparkSession.builder().appName(appName).master("local[*]").getOrCreate()}def getLocal(appName: String, supportHive: Boolean): SparkSession = {if (supportHive) getLocal(appName,"local[*]",true)else getLocal(appName)}def getLocal(appName:String,master:String,supportHive:Boolean): SparkSession = {if (supportHive) SparkSession.builder().appName(appName).master(master).enableHiveSupport().getOrCreate()else SparkSession.builder().appName(appName).master(master).getOrCreate()}def stopSs(ss:SparkSession): Unit ={if (ss != null) {ss.stop()}}
}log4j.properties
Function:设置控制台输出级别
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
KTV
Function:读取kudu,写入hive。Kudu_To_Hive,简称KTV
package com.example.daoimport com.example.unitl.SparkUnit
import org.apache.spark.sql.SparkSessionobject KTV {def getKuduTableDataFrame(ss: SparkSession): Unit = {// 读取kudu// 获取tb对象val kuduTb = ss.read.format("org.apache.kudu.spark.kudu").option("kudu.master", "10.168.1.12:7051").option("kudu.table", "impala::realtimedcs.bakup_db") // Tips:注意指定库.load()// create viewkuduTb.createTempView("v1")val kudu_unit1_df = ss.sql("""|SELECT * FROM `sources_tb1`|WHERE `splittime` = "2021-07-11"|""".stripMargin)// printkudu_unit1_df.printSchema()kudu_unit1_df.show()// load of memorykudu_unit1_df.createOrReplaceTempView("v2")}def insertHive(ss: SparkSession): Unit = {// create tabless.sql("""|USE `bakup_db`|""".stripMargin)ss.sql("""| CREATE TABLE IF NOT EXISTS `bak_tb1`(| `id` int,| `packtimestr` string,| `dcs_name` string,| `dcs_type` string,| `dcs_value` string,| `dcs_as` string,| `dcs_as2` string)| PARTITIONED BY (| `splittime` string)|""".stripMargin)println("创建表成功!")// create viewss.sql("""|INSERT INTO `bakup_db`|SELECT * FROM bak_tb1|""".stripMargin)println("保存成功!")}def main(args: Array[String]): Unit = {//get ssval ss = SparkUnit.getLocal("KTV", true)// 做动态分区, 所以要先设定partition参数// default是false, 需要额外下指令打开这个开关ss.sqlContext.setConf("hive.exec.dynamic.partition;","true");ss.sqlContext.setConf("hive.exec.dynamic.partition.mode","nonstrict");// 调用方法getKuduTableDataFrame(ss)insertHive(ss)// 关闭连接SparkUnit.stopSs(ss)}
}
运行:
运行时请将hive的配置文件 hive-site.xml文件,复制到项目resource下。
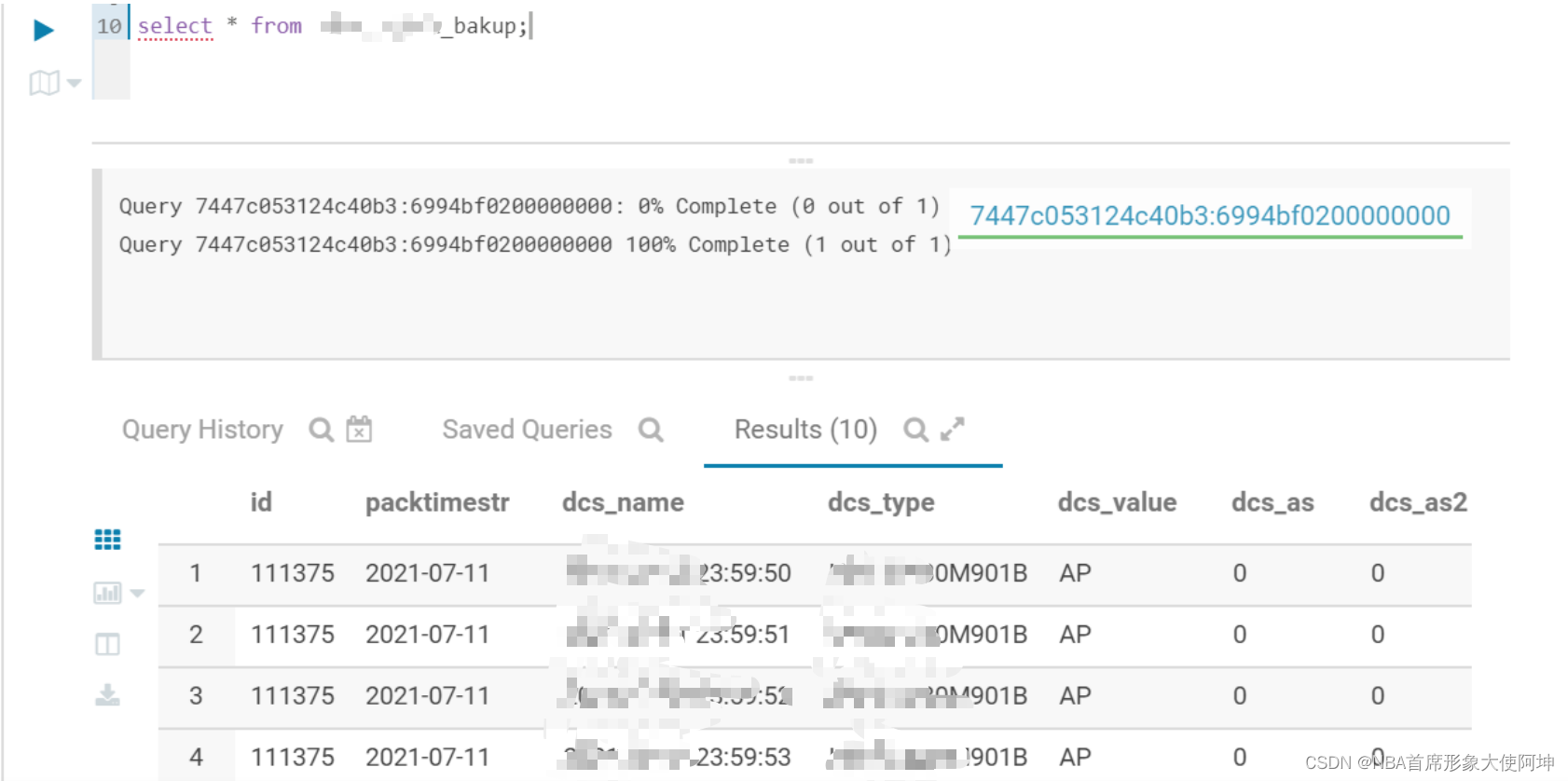
hue查看写入的数据:
相关文章:
[Spark SQL]Spark SQL读取Kudu,写入Hive
SparkUnit Function:用于获取Spark Session package com.example.unitlimport org.apache.spark.sql.SparkSessionobject SparkUnit {def getLocal(appName: String): SparkSession {SparkSession.builder().appName(appName).master("local[*]").getO…...
python统计分析——t分布、卡方分布、F分布
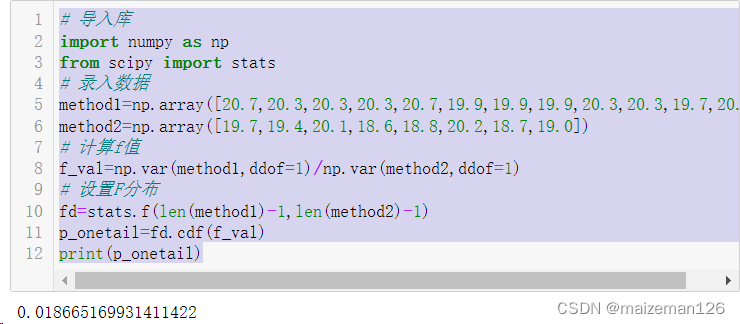
参考资料:python统计分析【托马斯】 一些常见的连续型分布和正态分布分布关系紧密。 t分布:正态分布的总体中,样本均值的分布。通常用于小样本数且真实的均值/标准差不知道的情况。 卡方分布:用于描述正态分布数据的变异程度。 F分…...
onlyoffice创建excel文档
前提 安装好onlyoffice然后尝试api开发入门 编写代码 <html> <head><meta charset"UTF-8"><meta name"viewport"content"widthdevice-width, user-scalableno, initial-scale1.0, maximum-scale1.0, minimum-scale1.0"&…...

交通事故档案管理系统|基于JSP技术+ Mysql+Java+Tomcat的交通事故档案管理系统设计与实现(可运行源码+数据库+设计文档)
推荐阅读100套最新项目 最新ssmjava项目文档视频演示可运行源码分享 最新jspjava项目文档视频演示可运行源码分享 最新Spring Boot项目文档视频演示可运行源码分享 2024年56套包含java,ssm,springboot的平台设计与实现项目系统开发资源(可…...
Chrome 114 带着侧边栏扩展来了
效果展示 manifest.json {"manifest_version": 3,"name": "ChatGPT学习","version": "0.0.2","description": "ChatGPT,GPT-4,Claude3,Midjourney,Stable Diffusion,AI,人工智能,AI","icons"…...

【论文笔记】RobotGPT: Robot Manipulation Learning From ChatGPT
【论文笔记】RobotGPT: Robot Manipulation Learning From ChatGPT 文章目录 【论文笔记】RobotGPT: Robot Manipulation Learning From ChatGPTAbstractI. INTRODUCTIONII. RELATED WORK1. LLMs for Robotics2. Robot Learning III. METHODOLOGY1. ChatGPT Prompts for Robot …...

深度学习 Lecture 4 Adam算法、全连接层与卷积层的区别、图计算和反向传播
一、Adam算法(自适应矩估计) 全名:Adapative Moment Estimation 目的:最小化代价函数(和梯度下降一样) 本质:根据更新学习率后的情况自动更新学习率的值(可能是自动增大,也可能是…...

uniApp中使用小程序XR-Frame创建3D场景(1)环境搭建
1.XR-Frame简介 XR-Frame作为微信小程序官方推出的3D框架,是目前所有小程序平台中3D效果最好的一个,由于其本身针对微信小程序做了优化,在性能方面比其他第三方库都要高很多。 2.与Three.js的区别 做3D小程序的同学们对Three.js一定不陌生…...

AI基础知识(4)--贝叶斯分类器
1.什么是贝叶斯判定准则(Bayes decision rule)?什么是贝叶斯最优分类器(Bayes optimal classifier)? 贝叶斯判定准则:为最小化总体风险,只需在每个样本上选择那个能使条件风险最小的…...

填补市场空白,Apache TsFile 如何重新定义时序数据管理
欢迎全球开发者参与到 Apache TsFile 项目中。 刚刚过去的 2023 年,国产开源技术再次获得国际认可。 2023 年 11 月 15 日,经全球最大的开源软件基金会 ASF 董事会投票决议,时序数据文件格式 TsFile 正式通过,直接晋升为 Apache T…...

Docker 笔记(七)--打包软件生成镜像
目录 1. 背景2. 参考3. 文档3.1 使用docker container commit命令构建镜像3.1.1 [Docker官方文档-docker container commit](https://docs.docker.com/reference/cli/docker/container/commit/)Description(概述)Options(选项)Exa…...
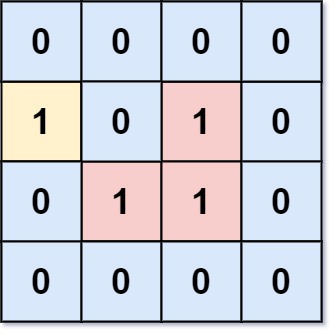
图论06-飞地的数量(Java)
6.飞地的数量 题目描述 给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。 一次 移动 是指从一个陆地单元格走到另一个相邻(上、下、左、右)的陆地单元格或跨过 grid 的边界。 返回网格中 无法…...

Java设计模式之单例设计模式
单例设计模式就是保证整个软件系统中,某个类只能存在一个对象实例,并且该类只提供一个取得该对象的方法。 单例设计模式包括两种:饿汉式和懒汉式。 饿汉式: 含义: 在类加载时就创建并初始化单例对象。这种方式确保了…...

多维时序 | MATLAB实现BiTCN-selfAttention自注意力机制结合双向时间卷积神经网络多变量时间序列预测
多维时序 | MATLAB实现BiTCN-selfAttention自注意力机制结合双向时间卷积神经网络多变量时间序列预测 目录 多维时序 | MATLAB实现BiTCN-selfAttention自注意力机制结合双向时间卷积神经网络多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.M…...

深入了解Android垃圾回收机制
文章目录 一、内存分配二、垃圾回收触发条件三、GC算法3.1 Dalvik虚拟机的GC算法3.2 ART的GC算法 四、优化GC性能五、监控GC耗时情况六、总结 在Android应用开发中,内存管理和垃圾回收(GC)对于应用性能和稳定性至关重要。理解GC机制有助于我们…...

如何学好Python语言
学习Python:一场充满探索与实践的编程之旅 Python,作为一种解释型、交互式和面向对象的编程语言,近年来在数据科学、人工智能、Web开发等多个领域得到了广泛的应用。掌握Python,不仅可以提升个人的编程技能,还能够为未…...

计算机408网课评测+资料分享
408当然有比较好的网课推荐,比如王道的视频课 现在大部分人备战408基本都用王道的讲义,然后再搭配王道408的课程来听,可以学的很好。 其中408视频课中,我认为讲的比较好的是数据结构,和操作系统,计算机组…...

使用 ZipArchiveInputStream 读取压缩包内文件总数
读取压缩包内文件总数 简介 ZipArchiveInputStream 是 Apache Commons Compress 库中的一个类,用于读取 ZIP 格式的压缩文件。在处理 ZIP 文件时,编码格式是一个重要的问题,因为它决定了如何解释文件中的字符数据。通常情况下,Z…...

JavaScript对象修饰教程
在JavaScript中,对象修饰是一种常见的编程模式,用于动态地向对象添加新的功能或修改现有功能,同时保持对象的原始结构不变。对象修饰可以帮助我们实现代码的复用、扩展和维护,让代码更加灵活和可扩展。本文将深入探讨JavaScript对…...

转置卷积(transposed-conv)
一、什么是转置卷积 1、转置卷积的背景 通常,对图像进行多次卷积运算后,特征图的尺寸会不断缩小。而对于某些特定任务 (如图像分割和图像生成等),需将图像恢复到原尺寸再操作。这个将图像由小分辨率映射到大分辨率的尺寸恢复操作,…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...