huggingface的transformers训练gpt
目录
1.原理
2.安装
3.运行
编辑
4.数据集
编辑
4.代码
4.1 model
init编辑
forward:
总结:
关于loss和因果语言模型:
编辑
交叉熵:编辑
记录一下transformers库训练gpt的过程。
transformers/examples/pytorch/language-modeling at main · huggingface/transformers (github.com)
1.原理
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的生成式预训练模型。下面是GPT的基本原理: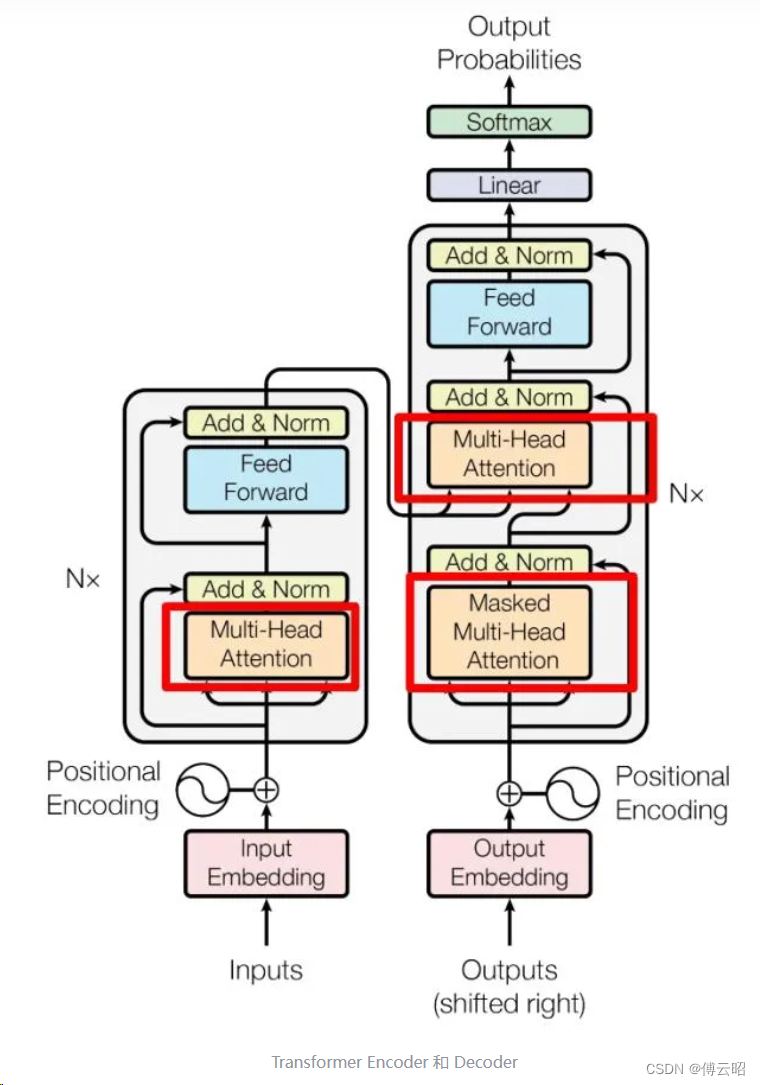
-
Transformer架构:GPT基于Transformer架构,它是一种使用自注意力机制(self-attention)的神经网络模型。Transformer通过在输入序列中的各个位置之间建立相互作用,从而对序列进行并行处理。这种架构在处理长序列和捕捉全局依赖关系方面表现出色。
-
预训练:GPT使用无监督的预训练方式进行训练,这意味着它在大规模的文本数据上进行训练,而无需标注的人工标签。在预训练阶段,GPT模型通过自我监督任务来学习语言的基本特征。常见的预训练任务是语言模型,即根据上下文预测下一个词。
-
多层堆叠:GPT由多个Transformer编码器decoder组成,这些编码器堆叠在一起形成一个深层模型。每个编码器由多个相同结构的自注意力层和前馈神经网络层组成。堆叠多个编码器可以帮助模型学习更复杂的语言特征和抽象表示。
-
自注意力机制:自注意力机制是Transformer的核心组件之一。它允许模型在处理输入序列时对不同位置之间的关系进行建模。通过计算每个位置与其他所有位置之间的相对重要性,自注意力机制能够为每个位置生成一个上下文感知的表示。
-
解码和生成:在预训练阶段,GPT模型学习了输入序列的表示。在生成时,可以使用该表示来生成与输入相关的文本。通过将已生成的词作为输入传递给模型,可以逐步生成连续的文本序列。

能大致讲一下ChatGPT的原理吗? - 知乎 (zhihu.com)
总之,GPT通过使用Transformer架构和自注意力机制,通过大规模无监督的预训练学习语言的基本特征,并能够生成与输入相关的文本序列。这使得GPT在许多自然语言处理任务中表现出色,如文本生成、机器翻译、问题回答等。
2.安装
git clone https://github.com/huggingface/transformers
cd transformers
pip install .cd examples/pytorch/language-modelingpip install -r requirements.txt3.运行
transformers/examples/pytorch/language-modeling at main · huggingface/transformers (github.com)

python run_clm.py \--model_name_or_path openai-community/gpt2 \--dataset_name wikitext \--dataset_config_name wikitext-2-raw-v1 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 8 \--do_train \--do_eval \--output_dir /tmp/test-clm
训练开始。
训练结束。
4.数据集
数据集使用的是wikitext
https://security.feishu.cn/link/safety?target=https%3A%2F%2Fblog.csdn.net%2Fqq_42589613%2Farticle%2Fdetails%2F130357215&scene=ccm&logParams=%7B"location"%3A"ccm_docs"%7D&lang=zh-CN
 上面是默认的下载地址
上面是默认的下载地址
数据集就是这样,全部是.json和.arrow文件
读取看一下:
# https://huggingface.co/docs/datasets/v2.18.0/en/loading#arrow
from datasets import Dataset
path = r'C:\Users\PaXini_035\.cache\huggingface\datasets\wikitext\wikitext-2-raw-v1\0.0.0\b08601e04326c79dfdd32d625aee71d232d685c3\wikitext-test.arrow'
dataset = Dataset.from_file(path)
print(1)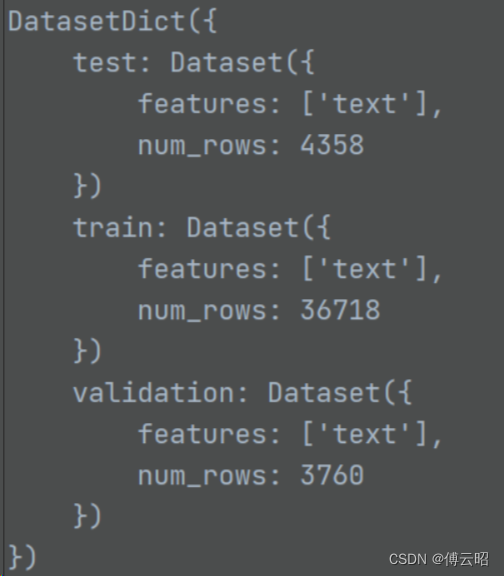
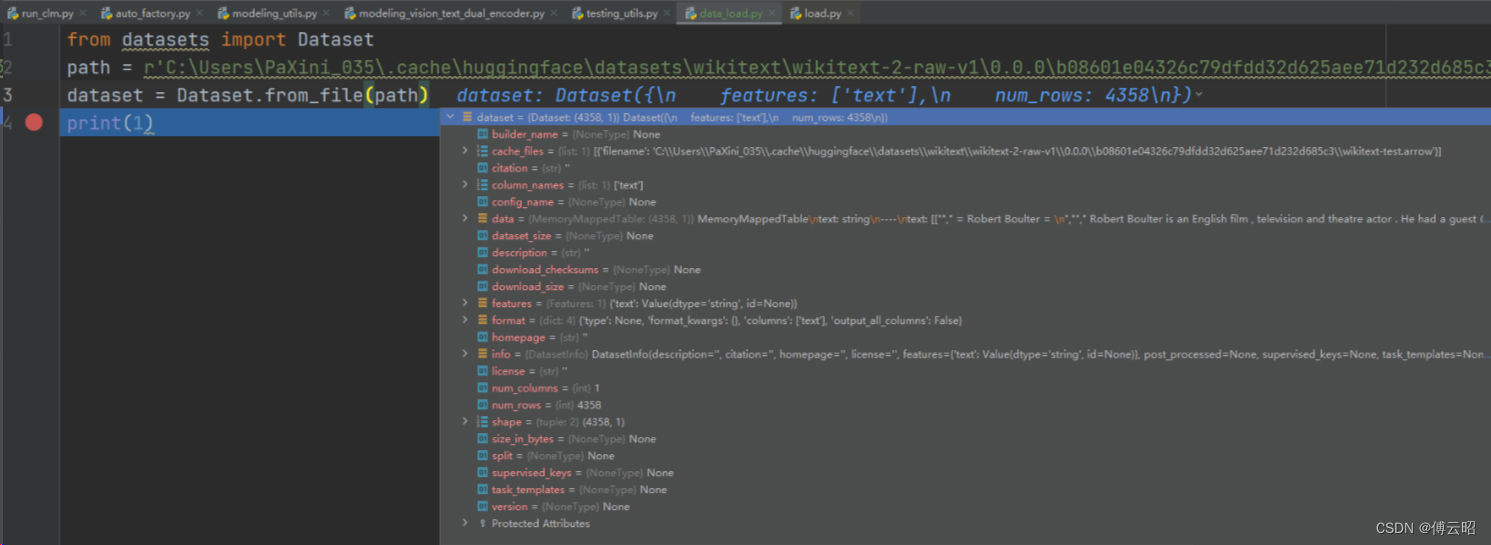

就是文本。
4.代码
4.1 model
init






forward:
class GPT2LMHeadModel(GPT2PreTrainedModel):_tied_weights_keys = ["lm_head.weight"]def __init__(self, config):super().__init__(config)self.transformer = GPT2Model(config)self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)# Model parallelself.model_parallel = Falseself.device_map = None# Initialize weights and apply final processingself.post_init()def forward( self,) -> Union[Tuple, CausalLMOutputWithCrossAttentions]:return_dict = return_dict if return_dict is not None else self.config.use_return_dicttransformer_outputs = self.transformer(input_ids,past_key_values=past_key_values,attention_mask=attention_mask,token_type_ids=token_type_ids,position_ids=position_ids,head_mask=head_mask,inputs_embeds=inputs_embeds,encoder_hidden_states=encoder_hidden_states,encoder_attention_mask=encoder_attention_mask,use_cache=use_cache,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)hidden_states = transformer_outputs[0]lm_logits = self.lm_head(hidden_states)loss = Nonereturn CausalLMOutputWithCrossAttentions(loss=loss,logits=lm_logits,past_key_values=transformer_outputs.past_key_values,hidden_states=transformer_outputs.hidden_states,attentions=transformer_outputs.attentions,cross_attentions=transformer_outputs.cross_attentions,)GPT2LMHeadModel = self.transformer + CausalLMOutputWithCrossAttentions
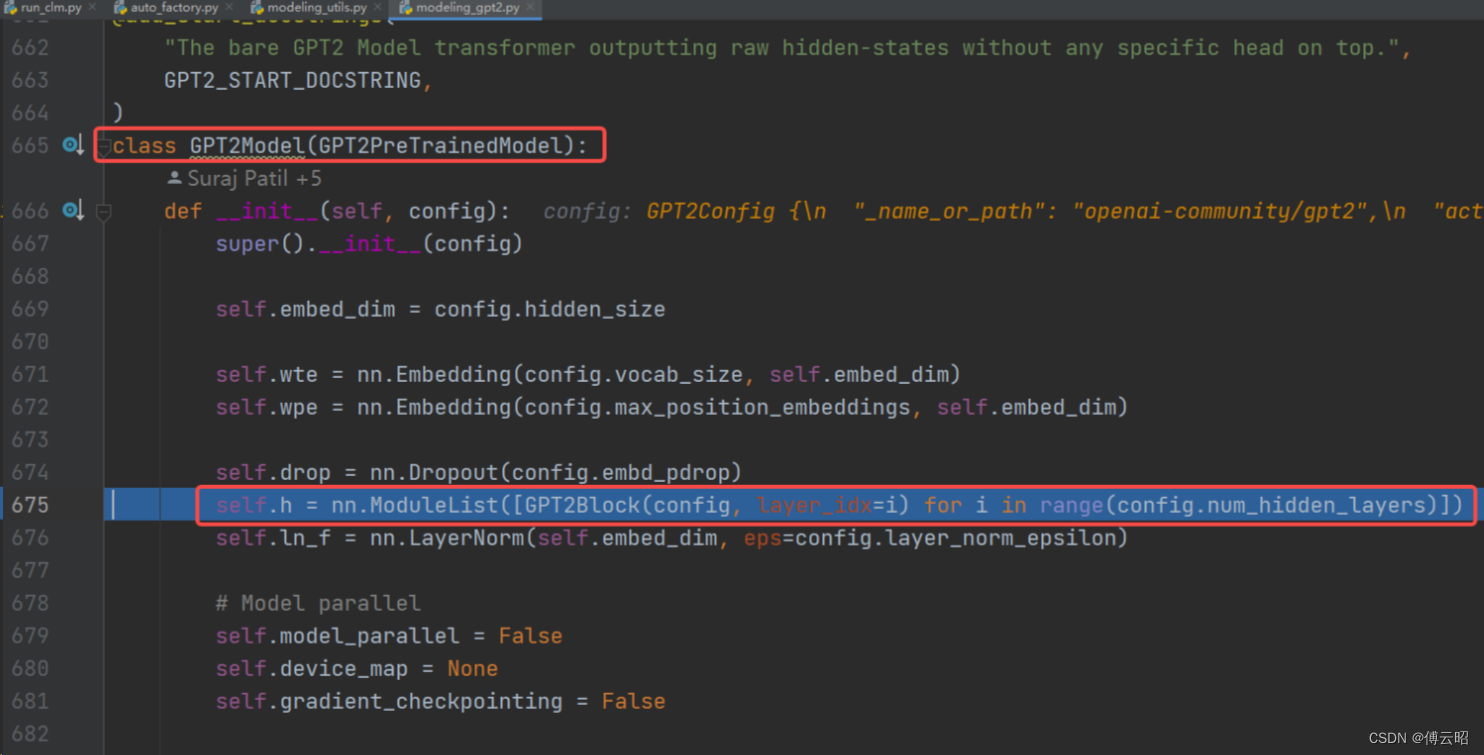
self.transformer = GPT2Model(config)
class GPT2Model(GPT2PreTrainedModel):def __init__(self, config):super().__init__(config)self.embed_dim = config.hidden_sizeself.wte = nn.Embedding(config.vocab_size, self.embed_dim)self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)self.drop = nn.Dropout(config.embd_pdrop)self.h = nn.ModuleList([GPT2Block(config, layer_idx=i) for i in range(config.num_hidden_layers)])self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)# Model parallelself.model_parallel = Falseself.device_map = Noneself.gradient_checkpointing = False# Initialize weights and apply final processingself.post_init()def forward():head_mask = self.get_head_mask(head_mask, self.config.n_layer)if inputs_embeds is None:inputs_embeds = self.wte(input_ids) # bs,1024-->bs,1024,768position_embeds = self.wpe(position_ids) # 1,1024-->1,1024,768hidden_states = inputs_embeds + position_embeds # bs,1024,768hidden_states = self.drop(hidden_states)for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):outputs = block(hidden_states,layer_past=layer_past,attention_mask=attention_mask,head_mask=head_mask[i],encoder_hidden_states=encoder_hidden_states,encoder_attention_mask=encoder_attention_mask,use_cache=use_cache,output_attentions=output_attentions,)hidden_states = outputs[0]if use_cache is True:presents = presents + (outputs[1],)hidden_states = self.ln_f(hidden_states)hidden_states = hidden_states.view(output_shape)# Add last hidden stateif output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)if not return_dict:return tuple(vfor v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions]if v is not None)return BaseModelOutputWithPastAndCrossAttentions(last_hidden_state=hidden_states,past_key_values=presents,hidden_states=all_hidden_states,attentions=all_self_attentions,cross_attentions=all_cross_attentions,)GPT2Model = inputs_embeds + position_embeds + 12*GPT2Block+BaseModelOutputWithPastAndCrossAttentions

class GPT2Block(nn.Module):def __init__(self, config, layer_idx=None):super().__init__()hidden_size = config.hidden_sizeinner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_sizeself.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)self.attn = GPT2Attention(config, layer_idx=layer_idx)self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)if config.add_cross_attention:self.crossattention = GPT2Attention(config, is_cross_attention=True, layer_idx=layer_idx)self.ln_cross_attn = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)self.mlp = GPT2MLP(inner_dim, config)def forward():residual = hidden_stateshidden_states = self.ln_1(hidden_states)attn_outputs = self.attn( # multi_head attentionhidden_states,layer_past=layer_past,attention_mask=attention_mask,head_mask=head_mask,use_cache=use_cache,output_attentions=output_attentions,)attn_output = attn_outputs[0] # output_attn: a, present, (attentions)outputs = attn_outputs[1:]# residual connection 1 addhidden_states = attn_output + residualresidual = hidden_stateshidden_states = self.ln_2(hidden_states)feed_forward_hidden_states = self.mlp(hidden_states) # Feed Forward# residual connection 2 addhidden_states = residual + feed_forward_hidden_statesif use_cache:outputs = (hidden_states,) + outputs return outputs # hidden_states, present, (attentions, cross_attentions)GPT2Block = ln_1(layernorm) + self.attn(GPT2Attention) + residual + ln_2 + mlp(GPT2MLP) + residual
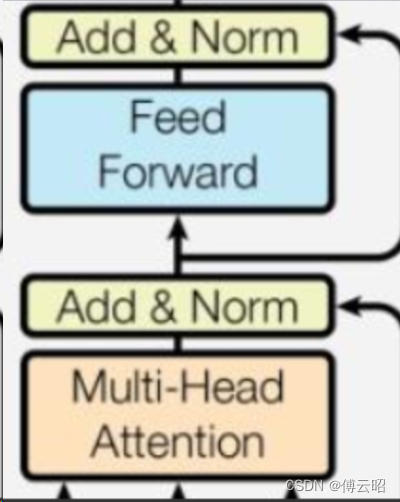
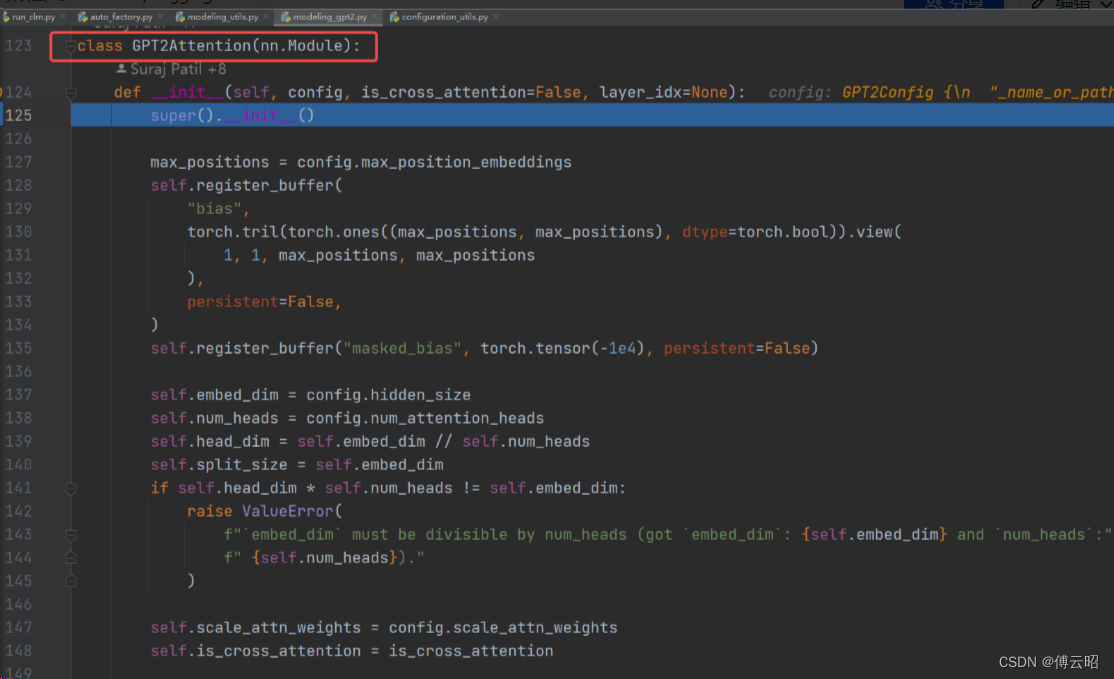
class GPT2Attention(nn.Module):def __init__(self, config, is_cross_attention=False, layer_idx=None):super().__init__()max_positions = config.max_position_embeddingsself.register_buffer("bias",torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(1, 1, max_positions, max_positions),persistent=False,)self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)self.embed_dim = config.hidden_sizeself.num_heads = config.num_attention_headsself.head_dim = self.embed_dim // self.num_headsself.split_size = self.embed_dimif self.head_dim * self.num_heads != self.embed_dim:raise ValueError(f"`embed_dim` must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"f" {self.num_heads}).")self.scale_attn_weights = config.scale_attn_weightsself.is_cross_attention = is_cross_attention# Layer-wise attention scaling, reordering, and upcastingself.scale_attn_by_inverse_layer_idx = config.scale_attn_by_inverse_layer_idxself.layer_idx = layer_idxself.reorder_and_upcast_attn = config.reorder_and_upcast_attnif self.is_cross_attention:self.c_attn = Conv1D(2 * self.embed_dim, self.embed_dim)self.q_attn = Conv1D(self.embed_dim, self.embed_dim)else:self.c_attn = Conv1D(3 * self.embed_dim, self.embed_dim)self.c_proj = Conv1D(self.embed_dim, self.embed_dim)self.attn_dropout = nn.Dropout(config.attn_pdrop)self.resid_dropout = nn.Dropout(config.resid_pdrop)self.pruned_heads = set()def forward(self,hidden_states: Optional[Tuple[torch.FloatTensor]],layer_past: Optional[Tuple[torch.Tensor]] = None,attention_mask: Optional[torch.FloatTensor] = None,head_mask: Optional[torch.FloatTensor] = None,encoder_hidden_states: Optional[torch.Tensor] = None,encoder_attention_mask: Optional[torch.FloatTensor] = None,use_cache: Optional[bool] = False,output_attentions: Optional[bool] = False,
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:# bs,1024,768-->Conv1D-->q,k,v:bs,1024,768query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2) # Conv1D# Splits hidden_size dim into attn_head_size and num_heads query = self._split_heads(query, self.num_heads, self.head_dim) key = self._split_heads(key, self.num_heads, self.head_dim) # 768 = 12 heads * 64 dimsvalue = self._split_heads(value, self.num_heads, self.head_dim)present = (key, value)# 计算q*k-->scale-->atten_weight[atten_mask]-->softmax-->*valueattn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)# 12*64-->768attn_output = self.c_proj(attn_output) # CONV1Dattn_output = self.resid_dropout(attn_output) # dropoutoutputs = (attn_output, present)if output_attentions:outputs += (attn_weights,)return outputs # a, present, (attentions)def _attn(self, query, key, value, attention_mask=None, head_mask=None):"""实际的attention计算:q*k-->scale-->atten_weight[atten_mask]-->softmax-->*value"""attn_weights = torch.matmul(query, key.transpose(-1, -2))if self.scale_attn_weights:attn_weights = attn_weights / torch.full([], value.size(-1) ** 0.5, dtype=attn_weights.dtype, device=attn_weights.device )if not self.is_cross_attention:query_length, key_length = query.size(-2), key.size(-2)causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]mask_value = torch.finfo(attn_weights.dtype).minmask_value = torch.full([], mask_value, dtype=attn_weights.dtype, device=attn_weights.device)attn_weights = torch.where(causal_mask, attn_weights.to(attn_weights.dtype), mask_value)if attention_mask is not None:attn_weights = attn_weights + attention_maskattn_weights = nn.functional.softmax(attn_weights, dim=-1)attn_weights = attn_weights.type(value.dtype)attn_weights = self.attn_dropout(attn_weights)attn_output = torch.matmul(attn_weights, value)return attn_output, attn_weightsclass Conv1D(nn.Module):def __init__(self, nf, nx):super().__init__()self.nf = nfself.weight = nn.Parameter(torch.empty(nx, nf)) # 768*768self.bias = nn.Parameter(torch.zeros(nf)) # 768nn.init.normal_(self.weight, std=0.02) def forward(self, x):size_out = x.size()[:-1] + (self.nf,) # BS,1024,768x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight) # X * W + biasx = x.view(size_out) # BS,1024,768return xGPT2Attention = Conv1D+ 计算q*k-->scale-->atten_weight[atten_mask]-->softmax-->*value + Conv1D
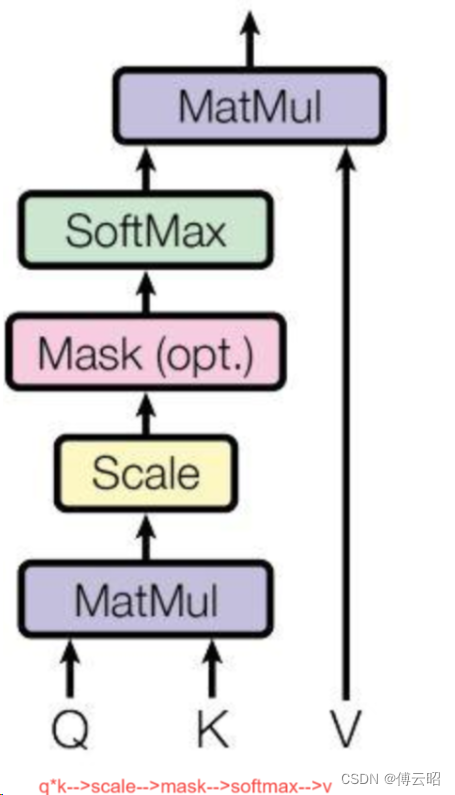
class GPT2MLP(nn.Module):def __init__(self, intermediate_size, config):super().__init__()embed_dim = config.hidden_sizeself.c_fc = Conv1D(intermediate_size, embed_dim)self.c_proj = Conv1D(embed_dim, intermediate_size)self.act = ACT2FN[config.activation_function]self.dropout = nn.Dropout(config.resid_pdrop)def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.FloatTensor:hidden_states = self.c_fc(hidden_states)hidden_states = self.act(hidden_states)hidden_states = self.c_proj(hidden_states)hidden_states = self.dropout(hidden_states)return hidden_statesGPT2MLP = conv1d * 2+ 激活函数 + dropout
总结:
GPT2LMHeadModel = self.transformer(GPT2Model) + CausalLMOutputWithCrossAttentions(head+loss)
GPT2Model = inputs+position_embeds + 12*GPT2Block+BaseModelOutputWithPastAndCrossAttentions
GPT2Block = ln_1(layernorm) + self.attn(GPT2Attention) + residual + ln_2 + mlp(GPT2MLP) + residual
GPT2Attention = Conv1D+ 计算q*k-->scale-->atten_weight[atten_mask]-->softmax-->*value + Conv1D
GPT2MLP = conv1d * 2+ 激活函数 + dropout
GPT2Block等价于transformer的decoder,12层GPT2Block就是12层decoder
GPT2LMHeadModel = embeds+12层decoder + head
简单解释一下:
gpt的decoder和transformer的decoder是有一点区别的,下图中红色的qkv是output的qkv,而蓝色的kv是来自input的经过encoder的kv,q是来自output经过mask multi head attention的q,第1个attention可以看作output自己的self attention,而第二个attention可以看作是input的kv和ouput的q的cross attention。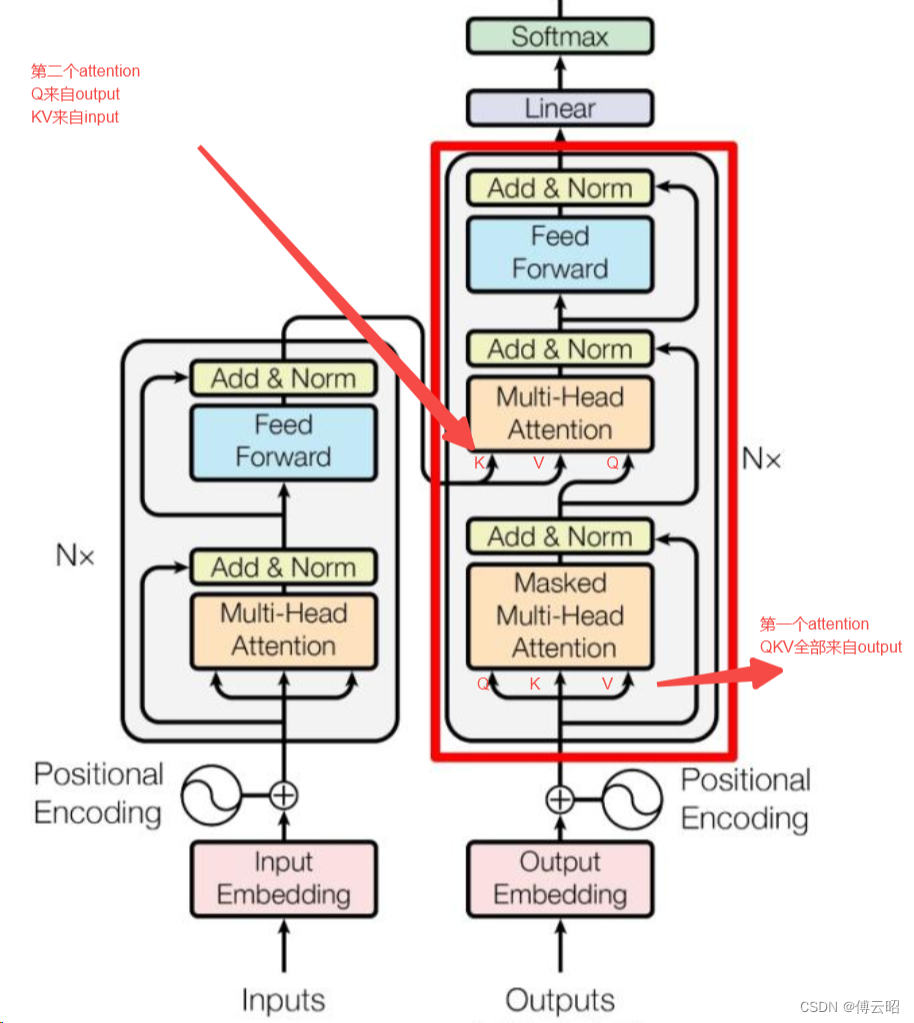
但是gpt2的全部都是self attention,所以不需要cross attention
https://zhuanlan.zhihu.com/p/338817680
关于loss和因果语言模型:

https://huggingface.co/docs/transformers/model_summary
GPT模型的训练过程中使用的损失函数是语言模型的损失函数,通常是交叉熵损失(Cross-Entropy Loss)。
在预训练阶段,GPT模型的目标是根据上下文预测下一个词。给定一个输入序列,模型会根据前面的词来预测下一个词的概率分布。损失函数的作用是衡量模型的预测结果与真实下一个词的分布之间的差异。
具体地,对于每个位置上的词,GPT模型会计算预测的概率分布和真实下一个词的分布之间的交叉熵。交叉熵损失函数对于两个概率分布之间的差异越大,损失值就越高。
在训练过程中,GPT模型通过最小化整个序列上所有位置的交叉熵损失来优化模型的参数。这样,模型就能够逐渐学习到语言的统计规律和上下文的依赖关系,从而提高生成文本的质量和准确性。
需要注意的是,GPT模型的预训练阶段使用的是无监督学习,没有人工标注的标签。因此,损失函数在这个阶段是根据自身预测和输入序列来计算的,而不需要与外部标签进行比较。
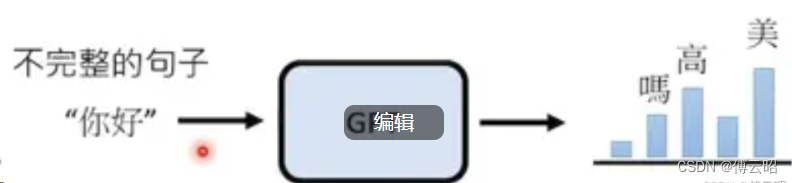
你好_
把上面的第三个字预测的概率分布和真实词的分布之间的交叉熵
_是一个被mask的词,假如真是的词是高,即你好高,那么真实词的概率分布应该是高这个词无限接近1,其他无限接近0,然后拿这个真实词汇的分布和预测分布计算交叉熵。
交叉熵: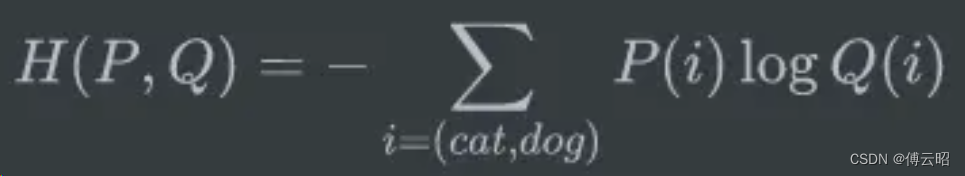
真实标签为[1, 0, 0, 0 ] P(i)
预测结果1为[0.7, 0.2, 0.05, 0.05] Q(i)
交叉熵计算:
-( 1*log0.7 + 0*log0.2 + 0*long0.05 + 0*log0.05) = 0.155
预测结果2为[0.1, 0.5, 0.3 ,0.1]
计算:
-(1*log0.1 + 0*log0.5 +0*log0.3 +0*log0.1) = 0.999
明显0.999>0.155,就是说预测结果2的loss更大,比较合理
相关文章:
huggingface的transformers训练gpt
目录 1.原理 2.安装 3.运行 编辑 4.数据集 编辑 4.代码 4.1 model init编辑 forward: 总结: 关于loss和因果语言模型: 编辑 交叉熵:编辑 记录一下transformers库训练gpt的过程。 transformers/examples/…...

第六十一回 放冷箭燕青救主 劫法场石秀跳楼-编译安装飞桨paddlepaddle@openKylin+RISCV
卢俊义在水里被张顺抓住,用轿子抬到了梁山。宋江等人下马跪在地上迎接,请他坐第一把交椅。卢俊义宁死不从,大家只好说留他在山寨几天,先让李固带着马车货物回去。吴用对李固说,你的主人已经答应坐第二把交椅了…...

白话讲人工智能、机器学习、深度学习
人工智能(Artificial Intelligence,AI) 定义: 想象一个聪明的机器人,它能思考、决策和学习,就像电影里的智能角色那样。人工智能就是努力打造这样的智能实体的学科,它试图模仿、扩展乃至超越人…...
ssm项目(tomcat项目),定时任务(每天运行一次)相同时间多次重复运行job 的bug
目录标题 一、原因 一、原因 debug本地调试没有出现定时任务多次运行的bug,上传到服务器就出现多次运行的bug。(war的方式部署到tomcat) 一开始我以为是代码原因,或者是linux和win环境不同运行定时任务的方式不一样。 但是自己…...
vue3 + ts +element-plus + vue-router + scss + axios搭建项目
本地环境: node版本:20.10.0 目录 一、搭建环境 二、创建项目 三、修改页面 四、封装路由vue-router 五、element-plus 六、安装scss 七、封装axios 一、搭建环境 1、安装vue脚手架 npm i -g vue/cli 2、查看脚手架版本 vue -V3、切换路径到需…...

二叉树试题解析
一、单项选择题 01.下列关于二叉树的说法中,正确的是( C ). A.度为2的有序树就是二叉树 B.含有n个结点的二叉树的高度为 C.在完全二叉树中,若一个结点没有左孩子,则它必是叶结点 D.含有n个结点的完全二叉树的高度为解析:A 二叉树…...

计算机服务器中了faust勒索病毒怎么办,faust勒索病毒解密工具流程
网络是一把利剑,可以方便企业开展各项工作业务,为企业提供极大的便利,但随着网络技术的不断发展与应用,网络数据安全威胁也在不断增加,给企业的正常生产运营带来了极大困扰,近日,云天数据恢复中…...

初次部署麒麟V10系统需要的配置,快速完成测试环境的搭建
配置麒麟V10 设置“root”登录密码 sudo su -passwd # 设置登录密码允许“root”远程登录 sudo vim /etc/ssh/sshd_configsshd_config # ↓↓↓↓修改的内容↓↓↓↓ PermitRootLogin yes # ↑↑↑↑修改的内容↑↑↑↑重启服务 sudo systemctl restart sshd允许通过图像界…...

DOcker in Docker 原理与实战代码详解
Docker in Docker(DinD)指的是在Docker容器内部运行另一个Docker守护进程和客户端。这种技术可以用于创建嵌套的Docker环境,例如在持续集成/持续部署(CI/CD)管道中构建和测试Docker镜像。然而,需要注意的是…...

公司系统中了.rmallox勒索病毒如何恢复数据?
早晨上班时刻: 当阳光逐渐洒满大地,城市的喧嚣开始涌动,某公司的员工们纷纷踏入办公大楼,准备开始新的一天的工作。他们像往常一样打开电脑,准备接收邮件、查看日程、浏览项目进展。 病毒悄然发作: 就在员…...
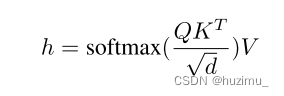
论文阅读:Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models 论文链接 代码链接 这篇文章提出了Forget-Me-Not (FMN),用来消除文生图扩散模型中的特定内容。FMN的流程图如下: 可以看到,FMN的损失函数是最小化要消除的概念对应的…...

html5cssjs代码 036 CSS默认值
html5&css&js代码 036 CSS默认值 一、代码二、解释 CSS默认值(也称为浏览器默认样式)是指当HTML元素没有应用任何外部CSS样式时,浏览器自动为这些元素赋予的一组基本样式。这些样式是由浏览器的默认样式表(User Agent sty…...

小米路由器4A千兆版刷回官方固件
原文链接:小米路由器4A千兆版刷回官方固件及修改SN绑定APP-小米无线路由器及小米网络设备-恩山无线论坛 (right.com.cn) 进入breed 由于openwrt工作不稳定,决定重新刷回官方固件。 由于当前路由器已经刷过breed,不再重新刷入。 如何刷入b…...
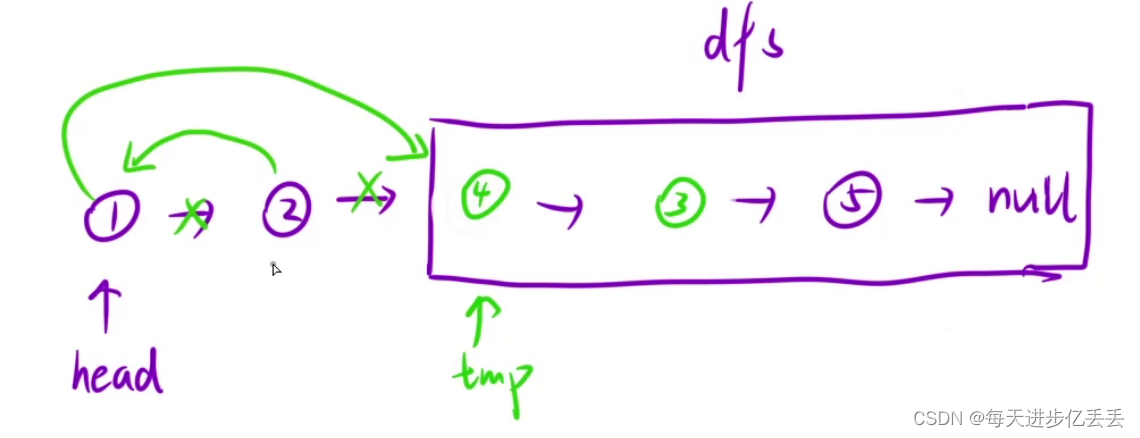
【Leetcode每日一题】 递归 - 两两交换链表中的节点(难度⭐)(38)
1. 题目解析 题目链接:24. 两两交换链表中的节点 这个问题的理解其实相当简单,只需看一下示例,基本就能明白其含义了。 2.算法原理 一、理解递归函数的含义 首先,我们需要明确递归函数的任务:给定一个链表…...
如何部署GPT模型至自有服务器:从零开始搭建你的智能聊天机器人
引言 GPT模型是自然语言处理领域的重要突破,它能够通过生成式的文本生成方式,实现与用户的智能交互。本文将详细介绍如何将GPT模型部署到自有服务器上,并编写一个基本的API接口来实现与聊天机器人的交互。 目录 引言 一、准备工作 首先&am…...
)
uniapp 之 一些常用方法的封装(页面跳转,页面传参等)
util.js 提示:permission.js是uniapp插件市场由官方DCloud_heavensoft提供的App权限判断和提示插件。 import permision from "/js_sdk/wa-permission/permission.js"/*** uni.toast 封装* param {String} msg toast 提示内容* param {Number} duration …...

flutter 单列选择器
引入 flutter_pickers: ^2.1.9 import package:flutter_pickers/pickers.dart; import package:flutter_pickers/style/default_style.dart; import package:flutter_pickers/style/picker_style.dart;List<String> _numberList [99,98,97,96,95,94,93,92,91,90,89,88,…...

管理类联考–复试–英文面试–问题–WhatWhyHow--纯英文汇总版
文章目录 Do you have any hobbies? What are you interested in? What do you usually do in your spare time? Could you tell me something about your family? Could you briefly introduce your family? What is your hometown like? Please tell me so…...
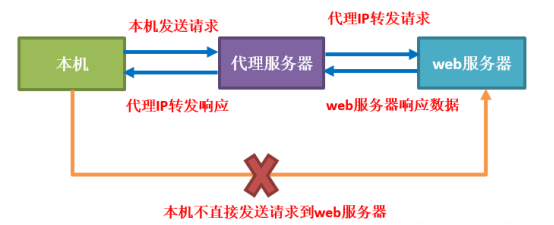
亮数据代理IP轻松解决爬虫数据采集痛点
文章目录 一、爬虫数据采集痛点二、为什么使用代理IP可以解决?2.1 爬虫和代理IP的关系2.2 使用代理IP的好处 一、爬虫数据采集痛点 爬虫数据采集可能会面临一些挑战和痛点,其中包括: 爬虫代码维护难:网站的结构可能会经常变化&am…...
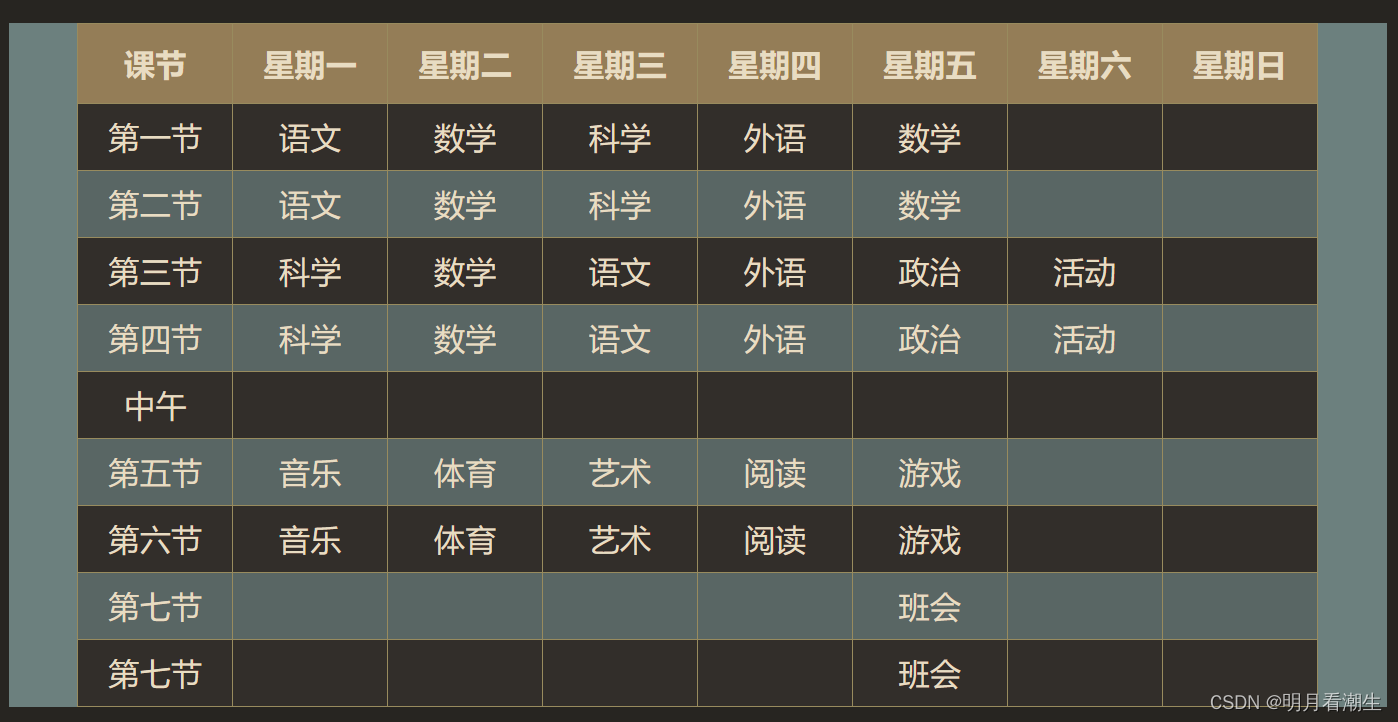
html5cssjs代码 035 课程表
html5&css&js代码 035 课程表 一、代码二、解释基本结构示例代码常用属性样式和装饰响应式表格辅助技术 一个具有亮蓝色背景的网页,其中包含一个样式化的表格用于展示一周课程安排。表格设计了交替行颜色、鼠标悬停效果以及亮色表头,并对单元格设…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

终极崩坏星穹铁道自动化指南:3分钟掌握解放双手的智能游戏伴侣
终极崩坏星穹铁道自动化指南:3分钟掌握解放双手的智能游戏伴侣 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | 基于模拟按键 项目地址: https://git…...

将deepseek v4 pro集成到codex桌面APP中使用
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域…...