ClickHouse01-什么是ClickHouse
- 什么是ClickHouse?
- 关于发展历史
- 存在的优势与劣势
- 什么是它风靡的原因?
什么是ClickHouse?
官方给出的回答是,它是一个高性能、列式存储、基于SQL、供在线分析处理的数据库管理系统
当然这边不得不提到OLAP(Online Analytical Processing)概念的出现
随着大数据的风吹起,传统数据库在险中求生,新生的大数据分析引擎如雨后春笋般出现。
为了更好地利用数据,发挥数据的价值,让静默的数据会"说话",就需要分析引擎具备能够快速读取、分析、产出统计结果的能力,那么大数据量、快速实时查询此外还需要尽可能低成本使用成为市场需求。
与ClickHouse类似的市场产品有:
- Apache Cassandra(特别是配合CQL查询时,用于大规模分布式环境)
- Apache Kylin(针对大数据OLAP分析而设计,与Hadoop生态集成紧密)
- IBM Db2 BLU(支持列式存储和内存计算,适用于数据仓库场景)
- Actian Vector(高性能列式数据库,专为快速数据分析打造)
- Kyligence(基于Apache Kylin构建的企业级智能数据平台)
- Apache Pinot(实时 OLAP 数据库,面向低延迟和高并发场景)
- Druid(专为实时事件流处理和快速聚合查询设计的列式数据库)
- Vertica(HP开发的列式MPP数据库,后被Micro Focus收购)
- Presto(开源的分布式SQL查询引擎,适合交互式分析查询)
- Cloudera Impala(在Hadoop之上提供快速SQL查询功能)
- Oracle Exadata(Oracle优化的数据库机器,特别针对数据仓库场景
- Microsoft SQL Server Analysis Services (SSAS) 或 Azure Synapse Analytics
- Teradata(专长于大规模数据仓库解决方案)
- Greenplum Database(开源MPP数据仓库系统)
那么ClickHouse有哪些历史,在市场竞争力上又有哪些优劣势呢?
关于发展历史
ClickHouse是由俄罗斯搜索引擎巨头Yandex内部开发的数据存储和分析系统。
该项目始于2008年,其初始设计目标是为了支持Yandex Metrica产品,这是一个Web流量分析服务,需要处理海量数据并实现快速的在线分析查询(OLAP)。随着技术的发展和完善,ClickHouse逐渐成为一个独立且功能强大的列式数据库管理系统。
在2016年6月15日,Yandex正式将ClickHouse作为开源项目对外发布
截至2024年,ClickHouse持续保持快速迭代,定期发布新版本,它已成为OLAP领域的重要参与者之一,与Apache Druid、Vertica、Greenplum以及其他现代数据仓库解决方案共同竞争市场,并在许多实际应用案例中展现出卓越的性价比和稳定性。
存在的优势与劣势
正如官网简单介绍的突出几点
优势1:高性能查询处理
特别适合大数据分析场景下的实时或近实时 OLAP 查询。它通过列式存储、向量化执行引擎和高度优化的数据压缩算法,能够快速处理大规模数据集。
优势2:列式存储与高效压缩
数据按列存储,使得在进行聚合计算时仅需读取相关列,大大减少了I/O成本,并且同列数据类型相同的情况下可以实现高倍率的压缩,进一步减少存储空间和提升读取速度。
优势3:分布式架构
分布式无主架构,支持灵活的扩缩容,成为企业生产的重要考量之一。
优势4:SQL兼容性
相较于传统大数据引擎,对SQL的兼容性不足上,ClickHouse 提供了丰富的 SQL 支持,积极与SpringBoot大框架靠拢,能够像查询传统数据库那样查询ClickHouse,降低技术门槛,更快地获得市场的认可。此外针对数据分析需求增加了许多高级特性,比如窗口函数、数组和其他复杂数据类型的支持,以及用于数据预处理的内置聚合函数和表引擎。
优势5:开源
ClickHouse 是活跃的开源项目,允许用户根据具体业务需求自由定制,这绝对是中小型企业生产选型的重要考量之一。

对于它的不足也是情理之中
劣势1:不支持事务
它无法做到传统数据库的事务特性,它更适合那些对最终一致性容忍度较高的分析型工作负载。
劣势2:DML的效率不高
正如它的自我介绍,它是适用于OLAP的引擎,数据分析引擎主要面向大数据读进行优化,对于写入、更新、删除的DML操作生效效率都是相对偏低的,不适合于大数据量实时写入的场景。
劣势3:管理、监控与安全性功能不足
总体发展的时间还不长,对于外围的管理、监控与安全性上面稍显不足,但是相信用的人、贡献的人越多,会发展地越来越完善。
什么是它风靡的原因?
OLAP引擎那么多,列式存储的数据库也很多,到底为什么它的受众如此之多?Github star 33.3K
核心的两个原因体现在了官网:查询快 & 占用小
查询快是OLAP技术选型首要考虑的点,不快怎么能做在线实时分析呢?查询快取决于几点:
-
列式存储:ClickHouse采用了列式存储格式,相比于传统的行式存储,列式存储在进行大数据分析时具有显著优势。当查询仅涉及部分列时,只需要读取相关的列数据,大大减少了磁盘I/O和内存带宽消耗
-
向量化执行引擎:ClickHouse使用向量化执行模型,在处理查询时一次性操作一整批数据,更充分地利用CPU缓存,提高计算效率。
-
高度优化的算法与代码库:由C++编写,代码经过深度优化以追求极致性能,包括但不限于高效的压缩算法、索引结构以及函数库等。
-
稀疏索引与并发处理能力:支持稀疏索引,采用MPP架构
-
SQL解析,查询优化,预聚合表和物化视图
占用小则是另一个重要的点。对于传统的存储,冷数据尝尝放起来备份不被使用,占用很多存储介质,一旦要用就还需要经历痛苦的恢复,这也是历史数据用不起来,数据分析受限的点。相比市面其他的分析引擎,它可以在有限的存储内放下更多的数据,数据分析范围扩大,分析结果的准确性和全面性一定会有所提升,那就在有限空间带来更大的价值。占用小则取决于:
- 依旧是列式存储,不仅结合查询的特点做到了查询效率的提升,还更有效地利用了数据块的存储,数据在物理上是连续存放的,同类型数据具有更好的局部性规律,更适合进行高效的压缩
- 高效的压缩算法:支持多种压缩算法,如LZ4、ZSTD等
- 排序和字典编码优化:利用排序和字典编码技术进一步压缩数据量
- 数据块压缩:每个数据块独立进行压缩
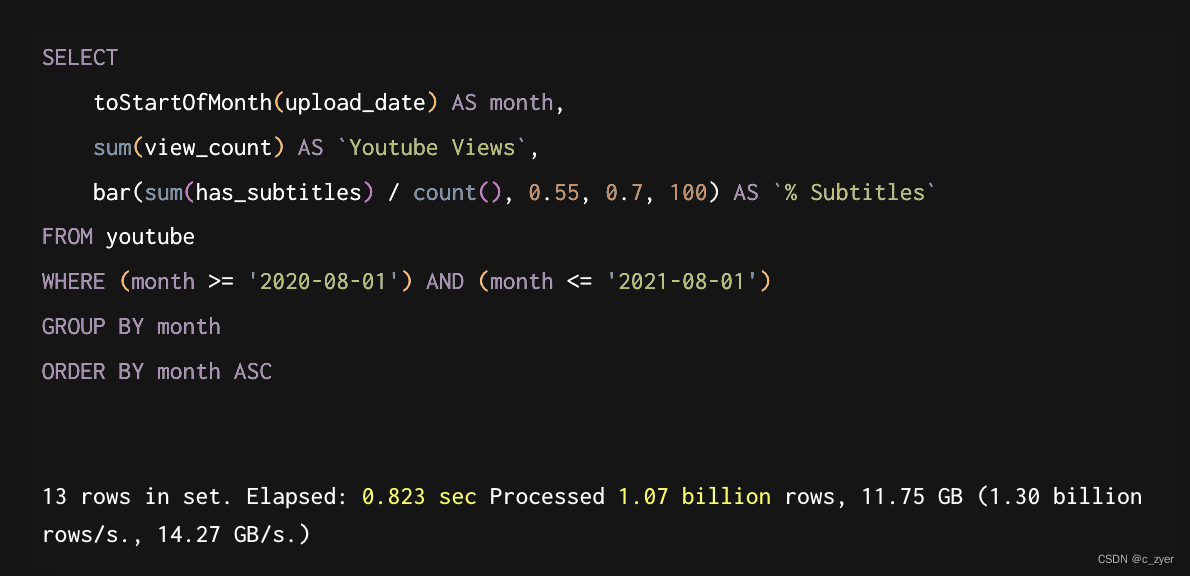
关于列式和行式DB的写入性能的比对官网有详细的数据,可以移步了解点这里>>
如果喜欢我的文章的话,可以去GitHub上给一个免费的关注吗?
相关文章:
ClickHouse01-什么是ClickHouse
什么是ClickHouse? 关于发展历史存在的优势与劣势什么是它风靡的原因? 什么是ClickHouse? 官方给出的回答是,它是一个高性能、列式存储、基于SQL、供在线分析处理的数据库管理系统 当然这边不得不提到OLAP(Online Analytical Pr…...

使用Docker搭建Nascab
使用Docker来部署Nascab能够让这个过程变得更加灵活和便捷,因为Docker可以在隔离的环境中运行应用程序,简化了部署和配置的复杂性。 使用Docker CLI部署Nascab docker run -d \ --name nascab \ -p 18080:80 \ -p 18443:443 \ -p 18090:90 \ -p 18021:…...
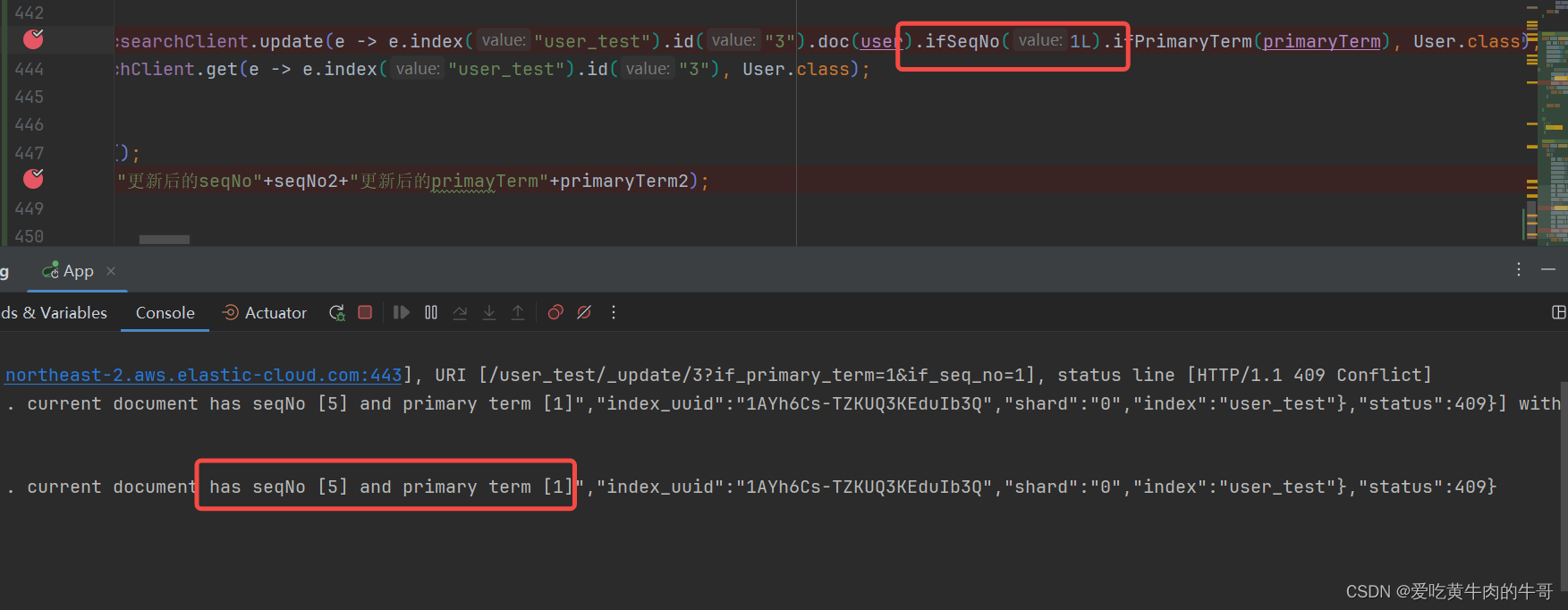
Elasticsearch8.x版本Java客户端Elasticsearch Java API 如何并发修改
前言 并发控制,一般有两种方案,悲观锁和乐观锁,其中悲观锁是默认每次更新操作肯定会冲突,所以每次操作都要先获取锁,操作完毕再释放锁,适用于写比较多的场景。而乐观锁是默认每次更新操作都不会冲突&#…...
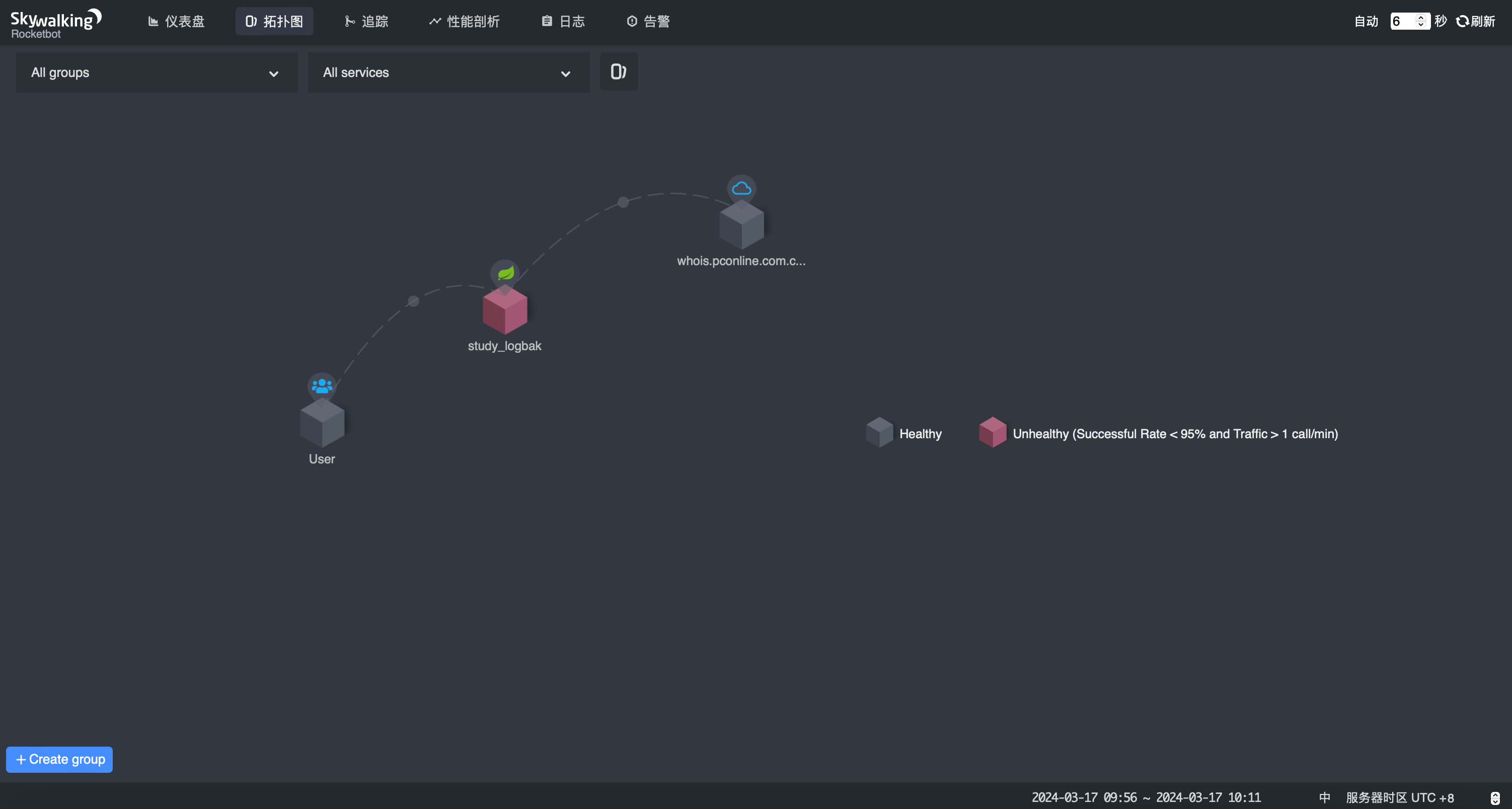
Docker 安装 Skywalking以及UI界面
关于Skywalking 在现代分布式系统架构中,应用性能监控(Application Performance Monitoring, APM)扮演着至关重要的角色。本文将聚焦于一款备受瞩目的开源APM工具——Apache Skywalking,通过对其功能特性和工作原理的详细介绍&am…...

mysql 空间查询 多边形内的点
数据库查询 # 1新增空间point类型坐标字段 ALTER TABLE gaoxin_isdp.business_master ADD COLUMN location2 point NULL AFTER location;# 2从原字段更新点位字段,原字段poi1是字符串106.474596,29.464360 UPDATE business_master SET location POINT(substr(poi…...

实际开发中,git版本切换操作
业务场景 客户环境需要部署当前分支的之前的一个版本代码,所以需要从当前的commit切换到之前的commit 版本切换步骤 查看版本提交日志 $ git reflog切换版本 git reset --hard 七位数的版本id在切换后的版本上更改代码后 执行完暂存 git commit 把回退后的代码提…...
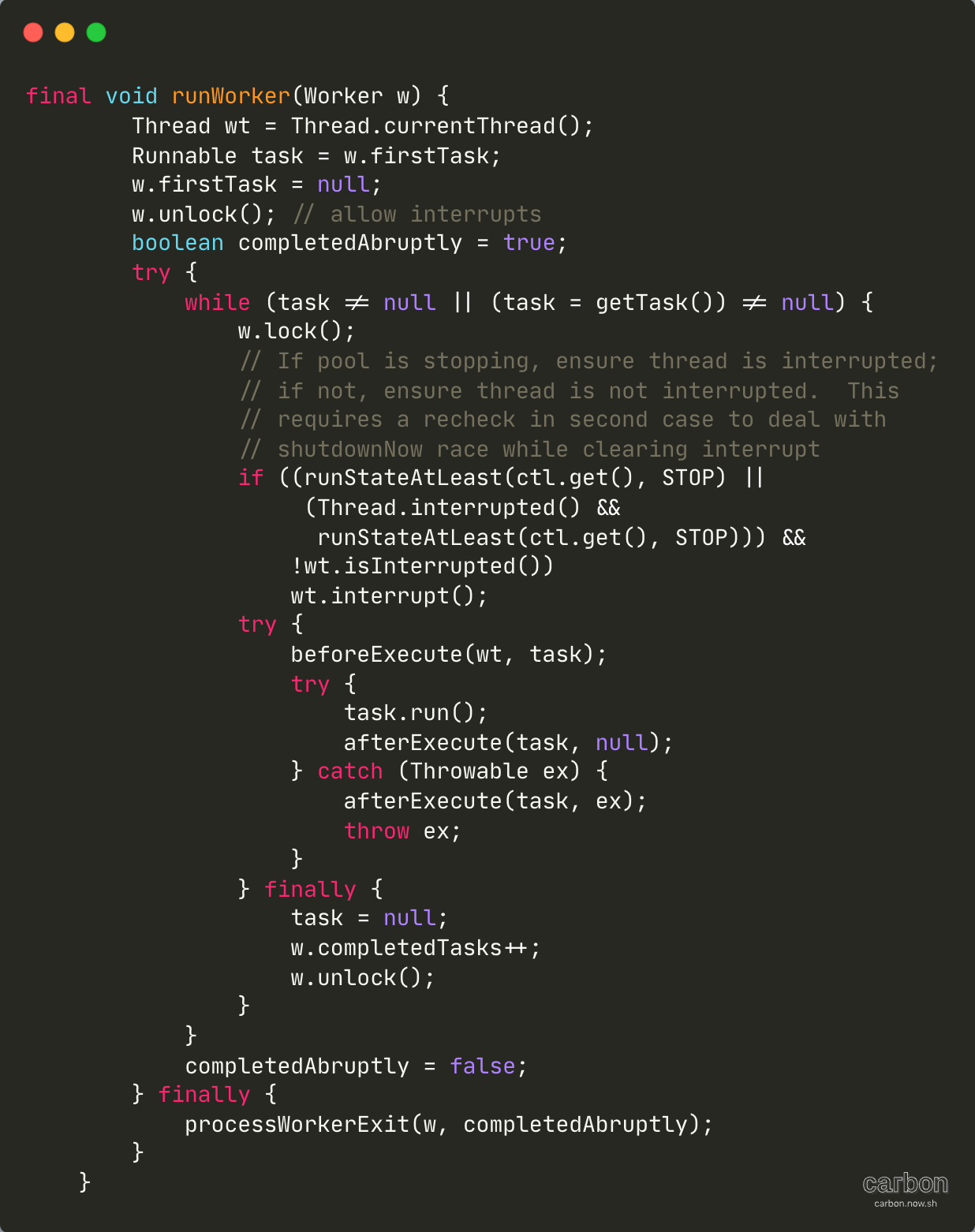
线程池实现“线程复用”的原理
线程池实现“线程复用”的原理 学习线程复用的原理,以及对线程池的 execute 这个非常重要的方法进行源码解析。 线程复用原理 我们知道线程池会使用固定数量或可变数量的线程来执行任务,但无论是固定数量或可变数量的线程,其线程数量都远远…...
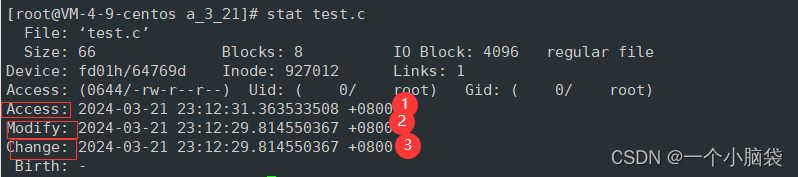
[Linux开发工具]——make/Makefile的使用
Linux项目自动化构建工具——make/Makefile 前言:一、背景二、认识make和makefile2.1 创建Makefile文件2.2 创建test.c文件,并打开Makefile2.3 我们想要test.c生成test文件2.4 编译2.5 清理可执行文件 三、理解依赖关系和依赖方法3.1 依赖关系3.2 依赖方…...

C++中的动态数组vector的基本操作
文章目录 前言一、vector数组的声明二、vector数组的初始化三、vector数组的大小1. 在声明时设置大小2. 修改大小3. 查看大小 四、添加元素与删除元素1. 添加元素2. 删除元素 总结 前言 在 C 中,std::vector 是一个标准库中的容器类型。它是一个动态数组࿰…...
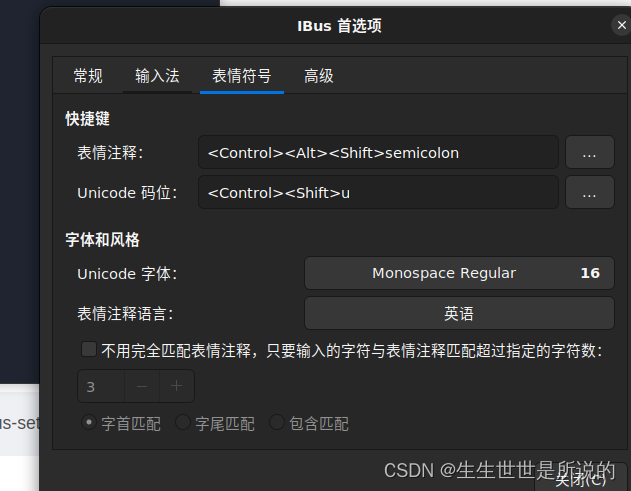
vsc ctrl+. 无效的问题
描述 ubuntu ibus 输入法 vsc ctrl.快捷键无效 输出 _e 解决方案: 运行 ibus-setup 把表情符号这里的快捷键改了...

科大讯飞开放平台-python语音转文字教程
文章目录 简介实际使用代码coding简介 科大讯飞的语音转写(Long Form ASR)——基于深度全序列卷积神经网络,将长段音频(5小时以内)数据转换成文本数据,为信息处理和数据挖掘提供基础。 转写的是已录制音频(非实时),音频文件上传成功后进入等待队列,待转写成功后用户…...

【LeetCode: 433. 最小基因变化 + BFS】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
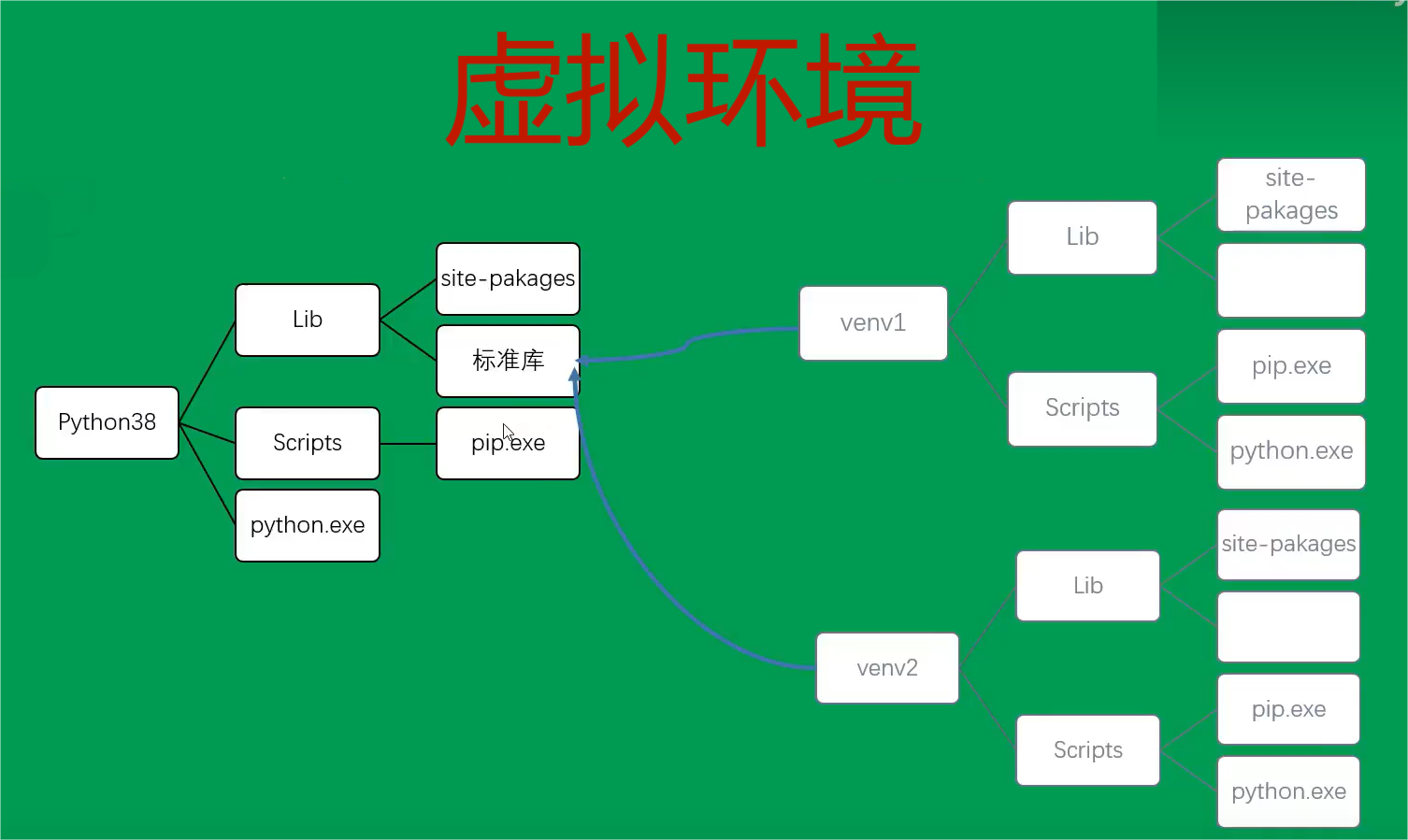
Python 安装目录及虚拟环境详解
Python 安装目录 原文链接:https://blog.csdn.net/xhyue_0209/article/details/106661191 Python 虚拟环境 python 虚拟环境图解 python 虚拟环境配置与详情 原文链接:https://www.cnblogs.com/hhaostudy/p/17321646.html...

linux sh脚本编写
linux中bash Shell 是 Linux 的核心部分,它允许你使用各种诸如 cd、ls、cat 等的命令与 Linux 内核进行交互。Bash脚本和Shell脚本实际上是指同一种类型的脚本,只不过Bash是其中最常用的一种Shell。除了Bash之外,常见的Shell解释器还有C She…...
|28. 实现 strStr()、459.重复的子字符串、KMP算法)
代码随想录笔记|C++数据结构与算法学习笔记-字符串(二)|28. 实现 strStr()、459.重复的子字符串、KMP算法
文章目录 卡码网.右旋字符串28. 实现 strStr()KMP算法(理论)KMP算法(代码)C代码 459.重复的子字符串暴力解法移动匹配KMP解法 卡码网.右旋字符串 卡码网题目链接 略 28. 实现 strStr() 力扣题目链接 文字链接:28. 实现 strStr() 视频链接:帮你把KMP算法…...
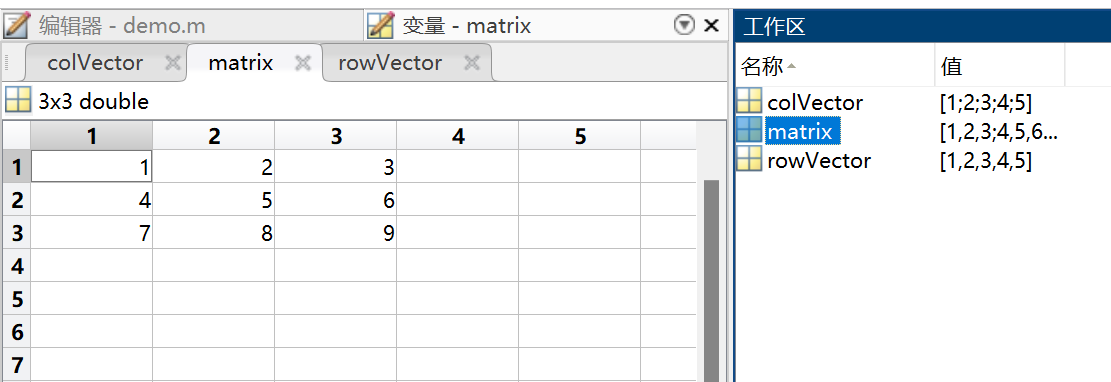
【复杂网络建模】——建模工具Matlab入门
目录 一、认识MATLAB 二、认识工具箱 三、基本操作和函数 3.1 算术操作符 3.2 数学函数 3.3 矩阵操作 3.4 索引和切片 3.5 逻辑操作 3.6 控制流程 3.7 数据输入输出 四、变量和数据类型 4.1 数值类型 4.2 整型 4.3 复数 4.4 字符串 4.5 逻辑类型 4.6 结构体&a…...

JVM面试篇
面试篇就是复习前面学的 什么是JVM 1.定义:JVM指的是Java虚拟机,本质是一个运行在计算机上的程序 2.作用:为了支持Java中Write Once ,Run Anywhere 编写一次 到处运行的跨平台特性 功能: 1.解释和运行 2.内存管理…...
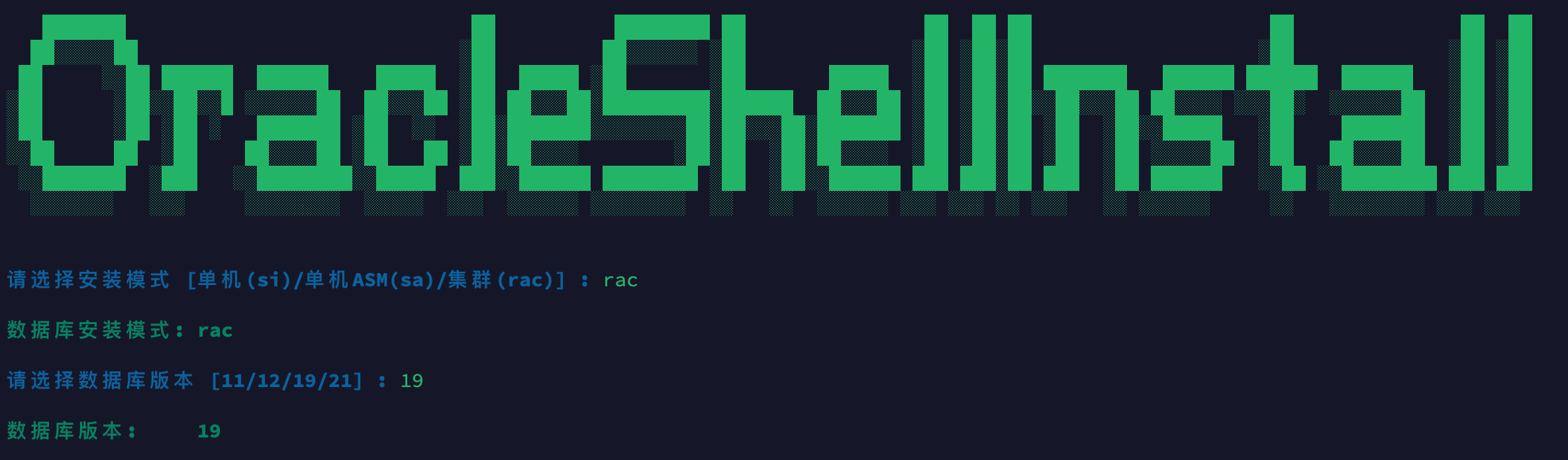
openEuler 22.03(华为欧拉)一键安装 Oracle 19C RAC(19.22) 数据库
前言 Oracle 一键安装脚本,演示 openEuler 22.03 一键安装 Oracle 19C RAC 过程(全程无需人工干预):(脚本包括 ORALCE PSU/OJVM 等补丁自动安装) ⭐️ 脚本下载地址:Shell脚本安装Oracle数据库…...

蓝桥杯刷题记录之数字王国之军训排队
记录 卡了半天,check函数中的temp % ele 0写成了ele % temp 0就挺无语的 思路 这个晚上在补 代码 import java.util.*; public class Main{static List<List<Integer>> que new ArrayList<>();static int MIN Integer.MAX_VALUE;static i…...
Go语言学习Day1:什么是Go?
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 1、走近Go①Go语言的Logo②Go语言的创始人③Go语…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

全球无障碍宣传日:iOS 26 辅助功能大升级,这些实用小功能你用过吗?
辅助功能发展与升级很多人对辅助功能的印象还停留在 "小白点",但随着 iPhone 进入全面屏时代,它逐渐变得陌生。实际上,Apple 每年都会为其增添功能,方便身体有障人士使用 iPhone。而且,这些功能不仅惠及有障…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

如何快速无损转换B站m4s视频:完整工具使用指南
如何快速无损转换B站m4s视频:完整工具使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他设备…...

从XAI到HXAI:构建以人为中心的可解释AI框架与实践
1. 项目概述:从“黑箱”到“白盒”,构建可信AI的演进之路在机器学习项目里摸爬滚打了十几年,我见过太多因为模型“说不清道不明”而引发的信任危机。一个在测试集上表现完美的信用评分模型,可能因为无法向风控专家解释“为什么拒绝…...

终极艾尔登法环存档迁移指南:3分钟学会角色无损转移
终极艾尔登法环存档迁移指南:3分钟学会角色无损转移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档迁移而烦恼吗?当游戏版本更新后,你辛辛苦苦培…...

语音AI落地最后一公里卡点,PlayAI质量波动真相:采样率适配缺陷、韵律断层、情感衰减三大隐性陷阱
更多请点击: https://intelliparadigm.com 第一章:PlayAI语音质量评测报告总览 PlayAI语音质量评测体系基于客观指标与主观听感双维度构建,覆盖清晰度、自然度、时延、抗噪性及情感一致性五大核心能力。本报告汇总了在标准测试集(…...