现代卷积神经网络
深度卷积神经网络(AlexNet)
经典机器学习的流水线:
①获取一个有趣的数据集;
②根据光学、几何学,手动对特征数据集进行预处理;
③通过标准的特征提取算法,如SIFT(尺度不变特征变换)和SURF(加速鲁棒特征)或其他手动调整的流水线来输入数据;
④将提取的特征送入最喜欢的分类器中
学习表征
特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。
在机器视觉中,底层可能检测边缘、颜色和纹理。在网络的底层,模型学习到了一些类似于传统滤波器的特征提取器
AlexNet比较小的LeNet要深得多
- AlexNet由8层组成:5个卷积层、2个全连接隐藏层和1个全连接输出层
- AlexNet使用ReLU而不是sigmoid作为其激活函数
LeNet简介
模型设计
- 在AlexNet的第一层,卷积窗口的形状是11*11,由于ImageNet中大多数图像的高和宽比MNIST图像的大10倍以上,因此需要一个更大的卷积窗口来捕获目标。第二层中的卷积窗口形状被缩减为5*5,然后是3*3.
- 在第1层、第二层、第五层卷积层之后,加入窗口形状为3*3、步幅为2的最大池化层。
- AlexNet的卷积通道数是LeNet的10倍
容量控制和预处理
暂退法:在前向传播过程中,计算每一内部层的同时注入噪声。
AlexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 减小卷积窗口,使用填充为2来使得输入和输出的高和宽一致nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 使用3个连续的卷积层和较小的卷积窗口;除了最后的卷积层,输出通道数进一步增加nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),# 全连接层的输出数量是LeNet中的好几倍,使用暂退层来缓解过拟合nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10)
)接下来,我们构造高度和宽度都为224的单通道数据,来观察每一层输出的形状
x = torch.randn(1, 1, 224, 224)
print(x)
for layer in net:x = layer(x)print(layer.__class__.__name__, 'output shape:\t', x.shape)读取数据集
batch_size = 128
# resize=224是因为Fashion-MNIST图像的分辨率(28*28像素)低于ImageNet图像(224*224)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)训练AlexNet
相比于LeNet,我们需要使用更低的学习率训练,因为网络更深更广、图像分辨率更高,训练卷积神经网络的成本更高
使用块的网络(VGG)
经典卷积神经网络的基本组成是:
(1)带填充以保持分辨率的卷积层
(2)非线性激活函数
(3)池化层
一个VGG块:由一系列卷积层组成,后面再加上用于空间降采样的最大池化层。
# num_convs:卷积层的数量
# in_channels:输入通道的数量、out_channels:输出通道的数量
def vgg_block(num_convs, in_channels, out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))layers.append(nn.ReLU())in_channels = out_channels# 向 layers 列表添加一个最大池化层,其池化核大小为 2x2,步长为 2。这将使空间尺寸减半layers.append(nn.MaxPool2d(kernel_size=2, stride=2))return nn.Sequential(*layers)VGG网络
第一部分由卷积层和池化层组成,第二部分由全连接层组成
- 原始VGG网络有5个卷积块,其中前2个块各包含1个卷积层,后3个块各包含2个卷积层
- 第一个块有64个输出通道,后续每个块将输出通道数翻倍,直到输出通道数为512
- 由于该网络使用8个卷积层和3个全连接层,因此称为VGG-11
# conv_arch指定了每个VGG块中卷积层个数和输出通道数
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))def vgg(conv_arch):conv_blks = []in_channels = 1# 卷积层部分for (num_convs, out_channels) in conv_arch:conv_blks.append(vgg_block(num_convs, in_channels, out_channels))in_channels = out_channelsreturn nn.Sequential(*conv_blks, nn.Flatten(),# nn.Dropout(0.5) 时,它会在训练过程中随机将输入张量中的一半(50%)的元素设置为 0# dropout 只在训练过程中使用。在评估或测试模型时,通常不使用 dropout,因此所有神经元都会被激活# 全连接层部分nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(4096, 10))
net = vgg(conv_arch)接下来,我们构建一个高度和宽度都为224的单通道数据样本,以观察每个层输出的形状
x = torch.randn(size=(1, 1, 224, 224))
for blk in net:x = blk(x)print(blk.__class__.__name__,'output shape:\t', x.shape)我们要将每个块的高度和宽度减半,最后高度和宽度都为7。最后,展平表示,进入全连接层处理
训练模型
# 由于VGG-11比AlexNet的计算量更大,# 因此构建一个通道数较少的网络,足够用于训练Fashion-MNIST数据集
ratio = 4
# 对于conv_arch中的每个元组对pair,它都会创建一个新的元组对,
# 其中第一个元素保持不变(即卷积层个数),而第二个元素则是原始通道数除以ratio(即4)。
# //是Python中的整数除法,所以结果将是一个整数。
# 这行代码的目的是减少每个卷积层的输出通道数,从而得到一个“较小”的卷积架构
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)网络中的网络(NiN)
在每个像素的通道上分别使用多层感知机
NiN块
卷积层的输入和输出由四维张量组成,张量的每个轴分别对应样本、通道、高度和宽度。另外,全连接层的输入和输出通常是分别对应于样本和特征的二维张量。
NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。如果将权重连接到每个空间位置,我们可以将其视为1*1卷积层;将空间维度中的每个像素视为单个样本,将通道维度视为不同特征
NiN块以一个普通卷积层开始,后面是两个1*1的卷积层。这两个1*1卷积层充当带有ReLU激活函数的逐像素全连接层。第一层的卷积窗口形状通常由用户设置,随后的卷积窗口形状固定为1*1
import torch
from torch import nn
from d2l import torch as d2ldef nin_block(in_channels, out_channels, kernel_size, strides, padding):return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())NiN模型
NiN使用窗口形状为11*11,5*5和3*3的卷积层,输出通道数与AlexNet中的相同。每个NiN块后有一个最大池化层,池化窗口形状为3*3,步幅为2
- NiN和AlexNet之间的一个显著区别是NiN模型完全取消了全连接层,而使用一个NiN块,其输出通道数等于标签类别数
- 最后放一个全局平均池化层,生成一个对数几率;
- NiN显著减少了模型所需参数的数量,但是会增加训练模型的时间
net = nn.Sequential(nin_block(1, 96, kernel_size=11, strides=4, padding=0),nn.MaxPool2d(3, stride=2),nin_block(96, 256, kernel_size=5, strides=1, padding=2),nn.MaxPool2d(3, stride=2),nin_block(256, 384, kernel_size=3, strides=1, padding=1),nn.MaxPool2d(3, stride=2),nn.Dropout(0.5),# 标签类别数是10nin_block(384, 10, kernel_size=3, strides=1, padding=1),# nn.AdaptiveAvgPool2d((1, 1)) 是一个自适应平均池化层,# 它会根据输入张量的大小自适应地调整池化窗口的大小,以产生一个特定大小(在此例中是 1x1)的输出。# 这通常用于在卷积神经网络的末尾,将不同尺寸的特征图转换为固定尺寸的表示,以便于后续的全连接层处理nn.AdaptiveAvgPool2d((1, 1)),# 将四维的输出转为二维的输出,其形状为(批量大小, 10)nn.Flatten()
)模型块的输出
# 创建一个数据样本来查看每个块的输出形状
x = torch.rand(size=(1, 1, 224, 224))
for layer in net:x = layer(x)print(layer.__class__.__name__,'output shape:\t', x.shape)含并行连接的网络(GoogLeNet)
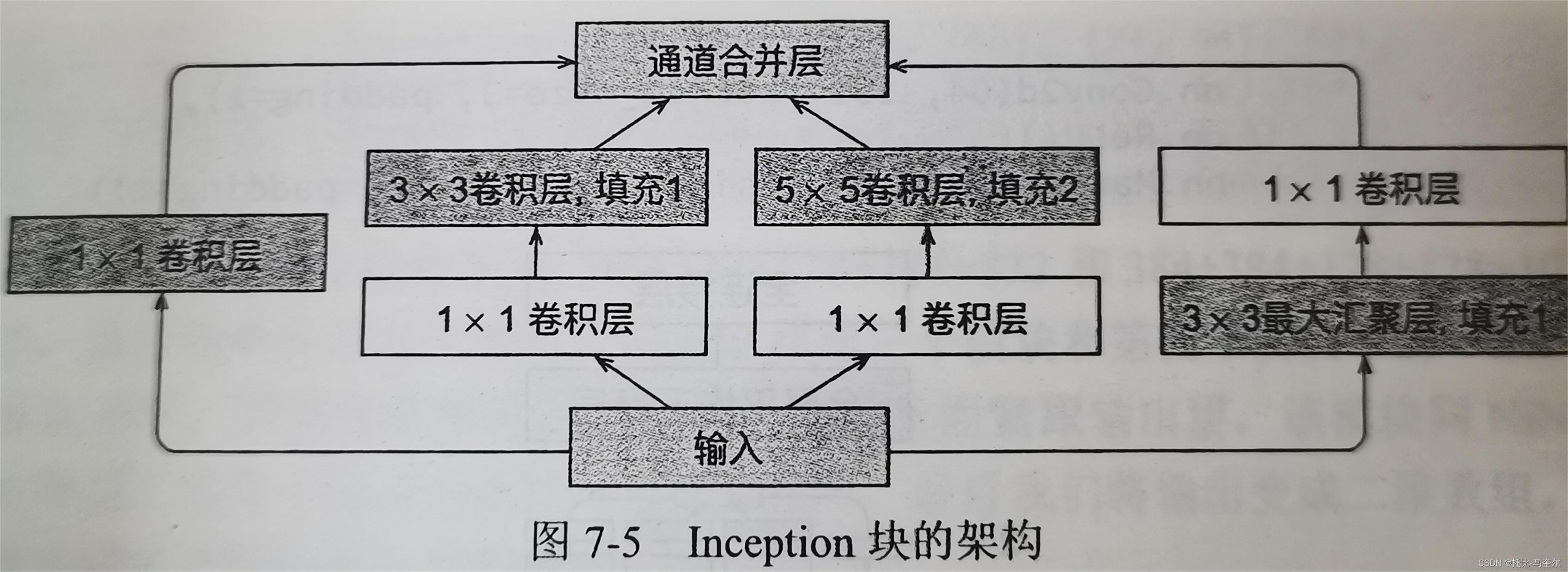
Inception块
在GoogLeNet中,基本的卷积块称为Inception块。
- 4条并行路径组成。前3条路径使用窗口大小为1*1,3*3和5*5的卷积层;从不同空间大小中提取信息
- 中间的2条路径在输入上执行1*1卷积,以减少通道数,从而降低模型的复杂度
- 第4条路径使用3*3最大池化层,然后使用1*1卷积层来改变通道数
- 这4条路径都使用合适的填充以使输入与输出的高度和宽度一致,最后将多条路径的输出在通道维度上合并
- Inception块中,通常调整的超参数是每层输出通道数
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Inception(nn.Module):# c1--c4是每条路径的输出通道数def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):super(Inception, self).__init__(**kwargs)# 路径1,单1*1卷积层self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)# 路径2, 1*1卷积层后接3*3卷积层self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)# 路径3, 1*1卷积层后接5*5卷积层self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)# 路径4, 3*3卷积层后接1*1卷积层self.p4_1 = nn.MaxPool2d( kernel_size=1, stride=1, padding=1)self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)def forward(self, x):p1 = F.relu(self.p1_1(x))p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))p4 = F.relu(self.p4_2(self.p4_1(x)))# 在通道维度上连接输出return torch.cat((p1, p2, p3, p4), dim=1)GoogleNet模型
GoogleNet模型一共使用9个Inception块和全局平均池化层的堆叠来生成其估计值
Inception块之间的最大池化层可降低维度
全局平均池化层避免了在最后使用全连接层
GoogleNet模块
第一个模块:输出64个通道,7*7卷积层
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))第二个模块:使用两个卷积层:第一个卷积层是64个通道、1*1卷积层; 第二个卷积层使用将通道数增加为3的3*3卷积层
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),nn.ReLU(),nn.Conv2d(64, 192, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))第三个模块:串联两个完整的Inception块。第一个Inception块的输出通道数为64+128+32+32=256;
4条路径的输出通道数之比为64:128:32:32 = 2:4:1:1
第二条和第三条路径首先将输入通道数分别减少到96/192=1/2,和16/192=1/12,然后连接第二个卷积层。第二个Inception块的输出通道数增加到128+192+96+64=480,4条路径的输出通道数之比为128:192:96:64 = 4:6:3:2。第二条路径和第三条路径先将输入通道数分别减少到128/256=1/2和32/256=1/8
# 输入通道数: 192
# 第一条路径的输出通道数: 164
# 第二条路径的输出通道数(两个数字表示两个卷积层的输出通道数): (96, 128)
# 第三条路径的输出通道数(两个数字表示两个卷积层的输出通道数): (16, 32)
# 第四条路径的输出通道数: 32
# 256 = 64 + 128 + 32 + 32
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),Inception(256, 128, (128, 92), (32, 96), 64),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))第四个模块
# 第四个模块更加复杂,它串联了5个Inception块,其输出通道数分别是192+208+48+64=512、160+224+64+64=512、128+256+64+64=512
# 112+288+64+64=528和256+320+128+128=832
# 这些路径通道数的分配和第三个模块中的类似,首先是输出通道数最多的含3*3卷积层的第二条路径,其次是仅含1*1卷积层的第一条路经,
# 最后是含5*5卷积层的第三条路经和含3*3最大池化层的第四条路径,其中第二条和第三条路径都会先按比例减少通道数
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),Inception(512, 160, (112, 224), (24, 96), 64),Inception(512, 128, (128, 256), (24, 64), 64),Inception(512, 112, (144, 288), (32, 64), 64),Inception(528, 256, (160, 320), (32, 128), 128),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))第五个模块
# 第五个模块包含输出通道数为256+320+128+128=832、384+384+128+128=1024的两个Inception块
# 第五个模块的后面紧跟输出层,该模块同NiN一样使用全局平均池化层,将每个通道的高度和宽度变为1
# 最后我们将输出变为二维数组,再连接一个输出个数为标签类别数的全连接层
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),Inception(832, 384, (192, 384), (48, 128), 128),# 无论输入特征图的大小如何,输出都将是一个 1x1 的张量nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten())net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))如果我们要在Fashion-MNIST数据集上进行训练,需要将输入的高度和宽度从224降到96.
GoogLeNet模型的计算比较复杂,不如VGG一样便于修改通道数
x = torch.rand(size=(1, 1, 96, 96))
for layer in net:x = layer(x)print(layer.__class__.__name__,'output shape:\t',x.shape)批量规范化
为什么需要批量规范化层?
(1)数据预处理的方式通常会对最终结果产生巨大影响
(2)对于典型的多层感知机或卷积神经网络,当训练时,中间层中的变量可能具有更广的变化范围
(3)更深层的网络更复杂,容易过拟合
训练深层网络
从形式上来说,用表示一个来自小批量B的输入,批量规范化BN根据以下表达式转换x:
是小批量B的样本均值,
是小批量B的样本标准差。应用标准化后,生成的小批量的均值为0,单位方差为1.
和
的形状与 x 相同。
批量规范化层
批量规范化层和其他层之间的一个关键区别是,由于批量规范化在完整的小批量上执行,因此我们不能像之前在引入其他层时那样忽略批量大小。
全连接层
假设全连接层的输入是x,权重参数和偏置参数分别是W和b,激活函数为,批量规范化的运算符为BN。
从零开始实现批量规范化层
def batch_norm(x, gamma, beta, moving_mean, moving_var, eps, momentum):# 通过is_grad_enabled方法来判断当前模式是训练模式还是预测模式if not torch.is_grad_enabled():# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差# 移动平均均值/方差:在训练过程中计算并保存的;# eps指的是一个很小的常数,用于防止分母为0或防止数值不稳定# torch.sqrt计算的是每个元素的平方根x_hat = (x - moving_mean) / torch.sqrt(moving_var + eps)# 数据大致会被归一化到均值为0、方差为1的分布else:# 确保输入张量的维度是2或4assert len(x.shape) in (2, 4)# 输入的张量是2维的if len(x.shape) == 2:# 在全连接层的情况,计算每个特征维上的均值和方差# dim=0意味着沿着批次维度计算均值和方差mean = x.mean(dim=0)var = ((x - mean) ** 2).mean(dim=0)else:# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差# 我们需要保持x的形状以便后面可以做广播运算# dim=(0, 2, 3)意味着沿着批次、高度和宽度维度计算均值和方差。# keepdim=True确保输出的均值和方差张量具有与输入相同的维度mean = x.mean(dim=(0, 2, 3), keepdim=True)var = ((x - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)# 训练模式下,用当前的均值和方差做标准化x_hat = (x - mean) / torch.sqrt(var + eps)# 更新移动平均的均值和方差moving_mean = momentum * moving_mean + (1.0 - momentum) * meanmoving_var = momentum * moving_var + (1.0 - momentum) * vary = gamma * x_hat + beta #缩放和移位return y, moving_mean.data, moving_var.data我们可以创建一个正确的BatchNorm()层,这个层将保持伸拉参数gamma和偏移参数beta,这两个参数将在训练过程中更新。此外,我们的层将保持均值和方差的移动平均值
class BatchNorm(nn.Module):# num_features:全连接层的输出数量或卷积层的输出通道数# num_dims:2表示完全连接层,4表示卷积层def __init__(self, num_features, num_dims):super().__init__()if num_dims == 2:shape = (1, num_features)else:shape = (1, num_features, 1, 1)# 参与求梯度和迭代的拉伸参数和偏移参数,其分别初始化为1和0self.gamma = nn.Parameter(torch.ones(shape))self.beta = nn.Parameter(torch.zeros(shape))# 非模型参数的变量初始化为0和1self.moving_mean = torch.zeros(shape)self.moving_var = torch.ones(shape)def forward(self, x):# 如果x不在内存上,将moving_mean和moving_var复制到x所在的显存上if self.moving_mean.device != x.device:self.moving_mean = self.moving_mean.to(x.device)self.moving_var = self.moving_var.to(x.device)# 保存更新过的moving_mean和moving_vary, self.moving_mean, self.moving_var = batch_norm(x, self.gamma, self.beta, self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9)return y使用批量规范化层的LeNet
批量规范化是应用在卷积层或全连接层之后、相应的激活函数之前
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),nn.Linear(84, 10)
)残差网络
只有当复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能
对于深度神经网络,如果我们能将新添加的层训练为恒等函数f(x)=x,新模型和原模型同样有效
残差网络(ResNet)的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一
残差块
残差块里首先有2个有相同输出通道数的3*3卷积层,每个卷积层后接一个批量规范化层和ReLU激活函数,之后,我们通过跨层数据通道,跳过这两个卷积运算,将输入直接加在最后的ReLU激活函数前;这样的设计要求2个卷积层的输出与输入形状相同,从而使它们可以相加。
残差网络是由多个残差块组成的,每个残差块都包含多个卷积层、批量归一化层和激活函数等
在残差块中,输入数据会经过多个卷积层的处理,然后再与原始输入数据进行相加,得到最终的输出数据
残差块的代码实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l# 该类是PyTorch中nn.Module的子类,用于实现残差块(Residual Block)
class Residual(nn.Module): #@save# 输入张量的通道数、卷积层输出的通道数、是否使用1*1卷积来改变输入张量的通道数# strides是卷积的步长,默认为1def __init__(self, input_channels, num_channels, use_1x1conv=False,strides=1):# 调用父类nn.Module的初始化函数super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)# 默认步长为1self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)else:self.conv3 = None# 定义两个批量归一化层,它们分别用于conv1和conv2的输出self.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, x):# 将输入x通过conv1卷积层,然后通过bn1批量归一化层,最后应用ReLU激活函数y = F.relu(self.bn1(self.conv1(x)))y = self.bn2(self.conv2(y))if self.conv3:x = self.conv3(x)# 执行残差连接y += xreturn F.relu(y)# 查看输入和输出形状一致的情况
blk = Residual(3, 3)
x = torch.rand(4, 3, 6, 6)
y = blk(x)
y.shape# 在增加输出通道的同时,减半输出的高度和宽度
blk = Residual(3, 6, use_1x1conv=True, strides=2)
blk(x).shapeResNet模型
# ResNet的前两层和之前介绍的GoogleNet中的一样:在输出通道数为64、步幅为2的7*7卷积层后,
# 接步幅为2的3*3的最大池化层
# 不同之处在于:ResNet的每个卷积层后增加了批量规范化层
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))- ResNet使用4个由残差块组成的模块,每个模块使用若干输出通道数相同的残差块
- 第一个模块的通道数同输入通道数一致;但是之前使用了步幅为2的最大池化层,因此无需减少高度和宽度
- 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高度和宽度减半
# num_residuals指的是残差单元的数量
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):# blk是一个列表,用于存储构成该块的残差单元blk = []for i in range(num_residuals):if i == 0 and not first_block:# 下采样,减少特征图的大小blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))else:# 创建一个标准的残差单元blk.append(Residual(num_channels, num_channels))return blk# 接着在ResNet加入所有残差块,每个模块使用两个残差块
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))# 最后,与GoogleNet一样,在ResNet中加入全局平均池化层以及全连接层输出
net = nn.Sequential(b1, b2, b3, b4, b5,# 适应性池化,经过池化层之后变为指定的大小nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(), nn.Linear(512, 10))# 在之前的架构中,分辨率降低、通道数增加、直到平均池化层聚合所有特征
x = torch.rand(size=(1, 1, 224, 224))
for layer in net:x = layer(x)print(layer.__class__.__name__,'output shape:\t', x.shape)稠密连接网络(DenseNet)
ResNet将函数展开为f(x) = x + g(x)
ResNet将f分解为两部分:一个简单的线性项和一个复杂的非线性项
DenseNet和ResNet的关键区别在于:DenseNet输出是连接,而不是简单相加
稠密网络主要由两部分组成:稠密块和过渡层。前者定义如何连接输入和输出,后者则控制通道数
稠密连接网络使用了残差连接网络的“批量规范化层、激活层和卷积层”架构
import torch
from torch import nn
from d2l import torch as d2ldef conv_block(input_channels, num_channels):return nn.Sequential(nn.BatchNorm2d(input_channels), nn.ReLU(),nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道
在前向传播中,我们将每个卷积块的输入和输出在通道维度上连接
class DenseBlock(nn.Module):def __init__(self, num_convs, input_channels, num_channels):super(DenseBlock, self).__init__()layer = []for i in range(num_convs):layer.append(conv_block(num_channels * i + input_channels, num_channels))self.net = nn.Sequential(*layer)def forward(self, x):for blk in self.net:y = blk(x)# 连接通道维度上每个卷积的输入和输出x = torch.cat((x, y), dim=1)return x定义一个有2个输出通道数为10的DenseBlock,使用通道数为3的输入时,我们会得到通道数为3+2*10=23的输出
# 卷积块的通道数控制了输出通道数相对于输入通道数的增长程度;也被称为增长率
blk = DenseBlock(2, 3, 10)
x = torch.randn(4, 3, 8, 8)
y = blk(x)
y.shape过渡层
由于每个稠密快都会带来通道数的增加,因此使用过多会过于复杂化模型.而过渡层可以用来控制模型复杂度
通过1*1卷积层来减小通道数,并使用步幅为2的平均池化层减半高度和宽度
def transition_block(input_channels, num_channels):return nn.Sequential(nn.BatchNorm2d(input_channels), nn.ReLU(),nn.Conv2d(input_channels, num_channels, kernel_size=1),nn.AvgPool2d(kernel_size=2, stride=2))# 对稠密块的输出使用通道数为10的过渡层.此时输出的通道数减为10,高度和宽度均减半
blk = transition_block(23, 10)
blk(y).shape
torch.Size([4, 10, 4, 4])DenseNet模型
# 首先,DenseNet使用同ResNet一样的单卷积层和最大池化层
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))num_channels, growth_rate = 64, 32
# growth_rate: DenseNet中每一层增加的新通道数
num_convs_in_dense_blocks = [4, 4, 4, 4]
# num_convs_in_dense_blocks: 一个列表,表示每个稠密块中卷积层的数量
blks = []
# 初始化一个空列表blks,用于存储DenseNet中的各个块
for i, num_convs in enumerate(num_convs_in_dense_blocks):# num_convs表示的是卷积层个数blks.append(DenseBlock(num_convs, num_channels, growth_rate))# 上一个稠密块的输出通道数num_channels += num_convs * growth_rate# 在稠密块之间添加一个过渡层,使通道数减半if i != len(num_convs_in_dense_blocks) - 1:# 当前通道数(num_channels)和下一阶段的通道数(num_channels // 2,即当前通道数的一半)blks.append(transition_block(num_channels, num_channels // 2))num_channels = num_channels // 2# 与ResNet类似,最后连接全局池化层和全连接层来输出结果
net = nn.Sequential(b1, *blks,nn.BatchNorm2d(num_channels), nn.ReLU(),nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Linear(num_channels, 10)
)相关文章:
现代卷积神经网络
深度卷积神经网络(AlexNet) 经典机器学习的流水线: ①获取一个有趣的数据集; ②根据光学、几何学,手动对特征数据集进行预处理; ③通过标准的特征提取算法,如SIFT(尺度不变特征变…...
【wubuntu】披着Win11皮肤主题的Ubuntu系统
wubuntu - 一款外观类似于 Windows 的 Linux 操作系统,没有任何硬件限制。以下是官方的描述 Wubuntu is an operating system based on Ubuntu LTS that has a similar appearance to Windows using the open-source themes. Wubuntu also comes with a set of adva…...
Kubernetes自动化配置部署
在新建工程中,使用k8s的devops服务,自动化部署项目 1、在搭建好k8s的集群中,确认已开启devops服务; 2、新建Maven项目之后,创建dockerfile、deploy和Jenkins文件 例如: Dockerfile FROM bairong.k8s.m…...

2024年奥莱利科技趋势报告解析
2024年O’Reilly技术趋势报告解读 概述 在快速发展的技术领域,跟上最新趋势对行业内的任何人来说都至关重要。2024年O’Reilly技术趋势报告在此方面提供了关键的指导,全面概述了最重要的技术进步和模式。该年度报告基于O’Reilly著名在线学习平台280万…...
算法打卡Day14
今日任务: 1)104.二叉树的最大深度 2)559.n叉树的最大深度 3)111.二叉树的最小深度 4)222.完全二叉树的节点个数 104.二叉树的最大深度 题目链接:104. 二叉树的最大深度 - 力扣(LeetCode&#…...

Android Kotlin版封装EventBus
文章目录 Android Kotlin版封装EventBus代码封装添加依赖库定义消息类定义常量值定义注解定义工具类 使用在Activity中在Fragment中发送事件 源码下载 Android Kotlin版封装EventBus 代码封装 添加依赖库 implementation("org.greenrobot:eventbus:3.3.1")定义消息…...

VUE父子组件的传参问题
1.父组件向子组件传参 1)这是一个父组件 //这是一个父组件 <div> <port :port-List"portList" ></port> </div> //port 这是子组件的名称export default{components: {},props: {},data() {return{portList:,}},computed: {}…...
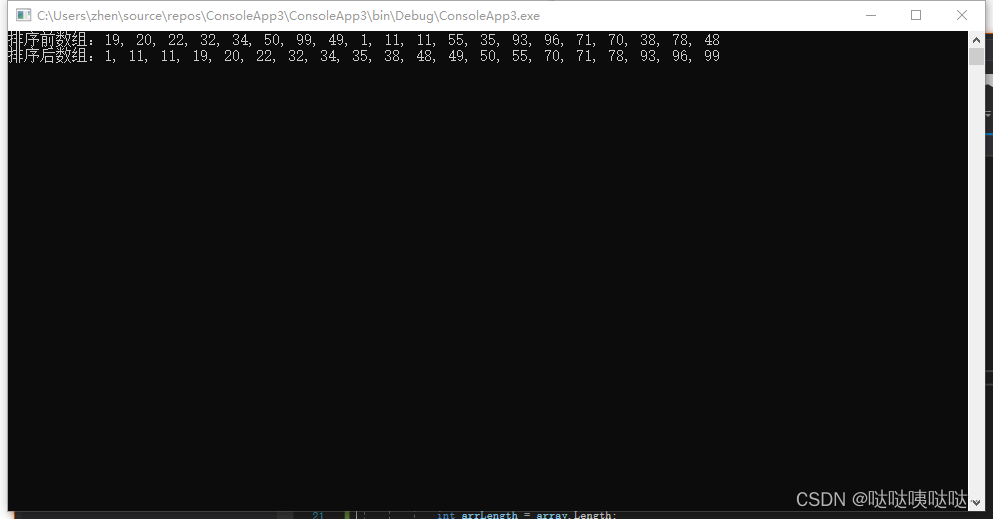
四、C#希尔排序算法
简介 希尔排序简单的来说就是一种改进的插入排序算法,它通过将待排序的元素分成若干个子序列,然后对每个子序列进行插入排序,最终逐步缩小子序列的间隔,直到整个序列变得有序。希尔排序的主要思想是通过插入排序的优势࿰…...

华为认证网络工程师的市场需求大吗?
华为认证网络工程师的市场需求非常旺盛,这主要得益于信息技术的快速发展和网络建设的不断扩展。随着云计算、大数据、物联网等新兴技术的普及,企业对于数据通信和网络技术的需求日益增长,为网络工程师提供了广阔的就业空间。 从行业发展趋势来…...
 和nn.ConvTranspose2d())
Pytorch:nn.Upsample() 和nn.ConvTranspose2d()
nn.Upsample 原理 nn.Upsample 是一个在PyTorch中进行上采样(增加数据维度)的层,其通过指定的方法(如nearest邻近插值或linear、bilinear、trilinear线性插值等)来增大tensor的尺寸。这个层可以在二维或三维数据上按…...
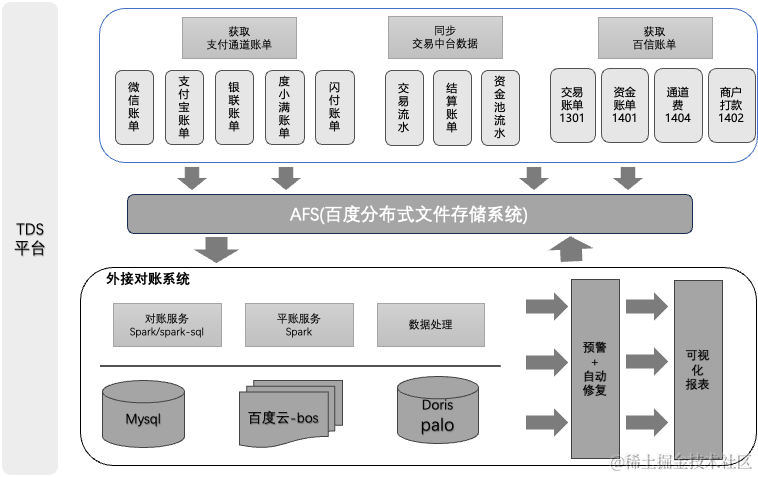
百度交易中台之系统对账篇
作者 | 天空 导读 introduction 百度交易中台作为集团移动生态战略的基础设施,面向收银交易与清分结算场景,赋能业务、提供高效交易生态搭建。目前支持百度体系内多个产品线,主要包括:度小店、小程序、地图打车、文心一言等。本文…...
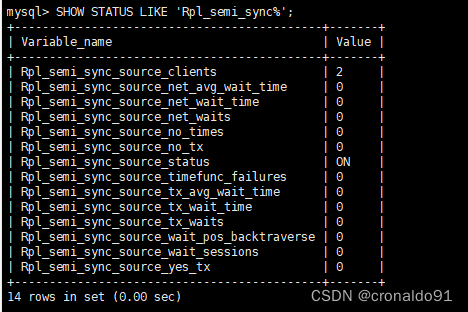
Linux 服务升级:MySQL 主从(半同步复制) 平滑升级
目录 一、实验 1.环境 2.Mysql-shell 检查工具兼容性 3.逻辑备份MySQL数据 4.备份MySQL 数据目录、安装目录、配置文件 5.MySQL 升级 6.master节点 使用systemd管理mysql8 7. slave1 节点升级 8. slave2 节点升级 9.半同步设置 二、问题 1.mysqldump备份报错 2.Inn…...
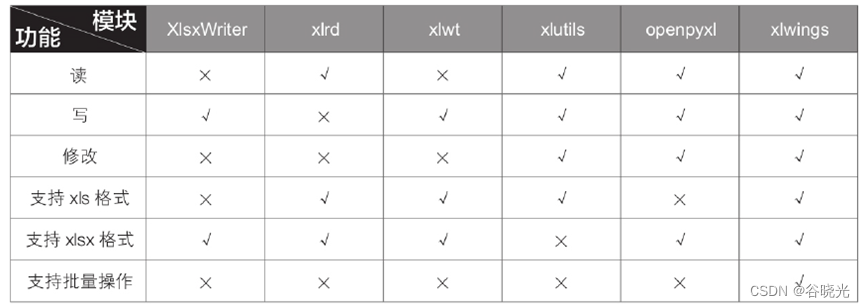
python与excel第一节
python与excel第一节 由于excel在日常办公中大量使用,我们工作中常常会面对高频次或者大量数据的情况。使用python语言可以更加便捷的处理excel。 python与vba的比较 python语法更加简洁,相较于vba冗长复杂的语法,python更加容易学习。 p…...

开发者必备神器 | 全能AI工具助你免费提升开发效率,每日轻松编写代码
全能AI工具助你免费提升开发效率,每日轻松编写代码 前提介绍CodeGeex多语言生成模型支持的编程语言适配多种主流IDE多种IDE插件支持安装VS Code的CodeGeeX插件安装Jetbrains IDEs插件(IntelliJ IDEA,PyCharm)功能实现1. 自动生成和补全代码2. 多语言的代码翻译3. 自动添加注释…...

【RabbitMQ | 第七篇】RabbitMQ实现JSON、Map格式数据的发送与接收
文章目录 7.RabbitMQ实现JSON、Map格式数据的发送与接收7.1消息发送端7.1.1引入依赖7.1.2yml配置7.1.3RabbitMQConfig配置类——(非常重要)(1)创建交换器方法(2)创建队列方法(3)绑定…...
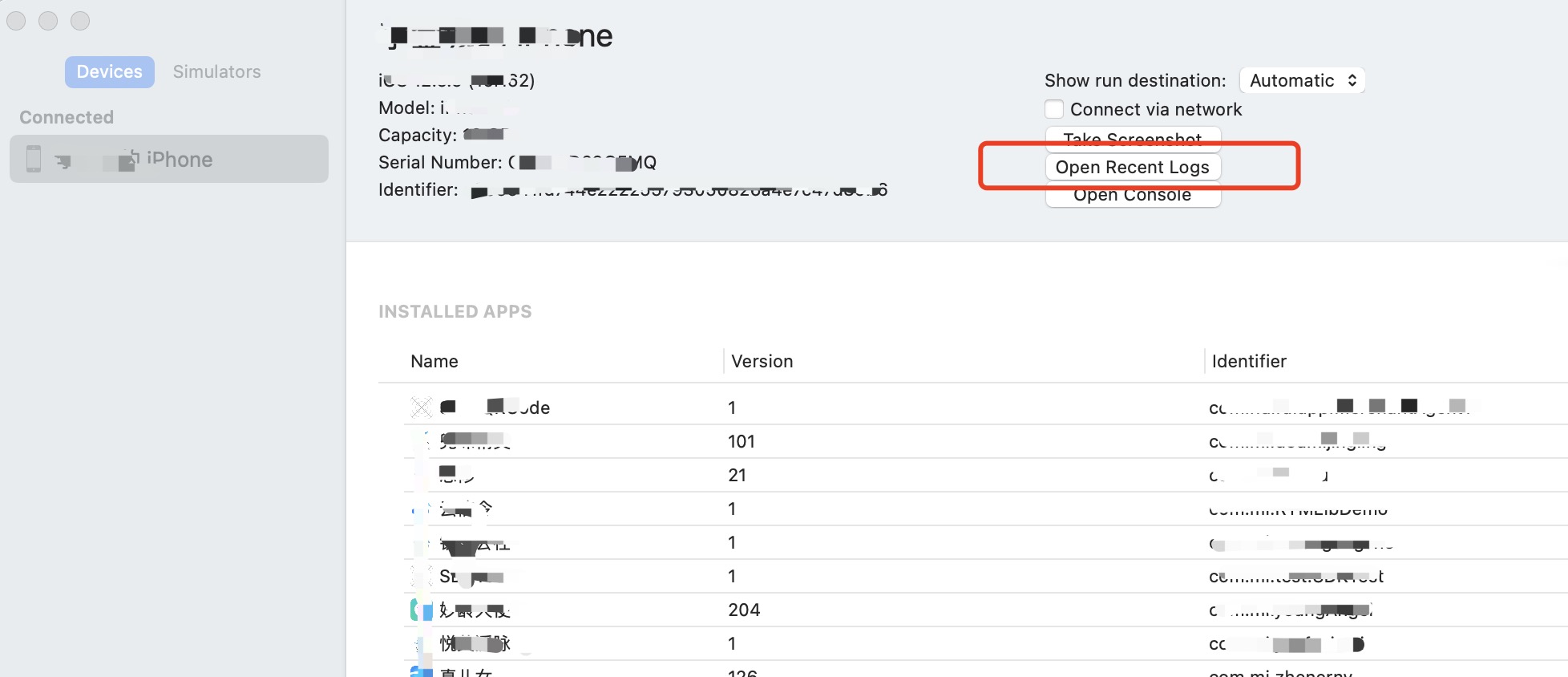
ios symbolicatecrash 符号化crash
一、准备 1.1 .crash 文件获取 设备连接电脑 打开XCode, 依次 XCode -> Windows -> Device and Simulator -> Open Recent Logs 找到 (对应app名+时间点) -> 右键 Show in Finder 1.2 .dSYM 和 .app 文件获取 .dSYM是十六进制函数地址映射信息的中转文件,调试的…...

Rust 语言的 HashMap
HashMap 在 Rust 中是一个非常常用且强大的数据结构,它允许你存储键值对(key-value pairs),并且能够快速地基于键检索值。 下面是使用 HashMap 的一些基本示例: 首先,你需要在你的文件中引入 HashMap: use std::col…...

【目标检测基础篇】目标检测评价指标:mAP计算的超详细举例分析以及coco数据集标准详解(AP/AP50/APsmall.....))
学习视频: 霹雳吧啦Wz-目标检测mAP计算以及coco评价标准 【目标检测】指标介绍:mAP 1 TP/FP/FN TP(True Positive) : IoU>0.5的检测框数量(同一Ground truth只计算一次)FP(False Positive) : IoU<0.5的检测框(或者是检测到同一个GT的多余检测框的…...

服务器与普通电脑的区别,普通电脑是否可以作为服务器使用
服务器在我们日常应用中非常常见,手机APP、手机游戏、PC游戏、小程序、网站等等都需要部署在服务器上,为我们提供各种计算、应用服务。服务器也是计算机的一种,虽然内部结构相差不大,但是服务器的运行速度更快、负载更高、成本更高…...

长安链Docker Java智能合约引擎的架构、应用与规划
#功能发布 长安链3.0正式版发布了多个重点功能,包括共识算法切换、支持java智能合约引擎、支持后量子密码、web3生态兼容等。我们接下来为大家详细介绍新功能的设计、应用与规划。 在《2022年度长安链开源社区开发者调研报告》中,对Java合约语言支持是开…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

机器学习在射电天文数据分类中的应用:以MIGHTEE巡天SFG/AGN分类为例
1. 项目概述:当机器学习遇见深空射电巡天在射电天文学领域,我们正经历一场数据洪流。以MeerKAT望远镜阵列主导的MIGHTEE巡天项目为例,其在COSMOS天区的一次早期科学数据释放,就在不到1平方度的天区内探测到了超过6000个射电源。传…...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...