C语言经典算法-7
文章目录
- 其他经典例题跳转链接
- 36.排序法 - 改良的选择排序
- 37.快速排序法(一)
- 38.快速排序法(二)
- 39.快速排序法(三)
- 40.合并排序法
其他经典例题跳转链接
C语言经典算法-1
1.汉若塔 2. 费式数列 3. 巴斯卡三角形 4. 三色棋 5. 老鼠走迷官(一)6. 老鼠走迷官(二)7. 骑士走棋盘8. 八皇后9. 八枚银币10. 生命游戏
C语言经典算法-2
字串核对、双色、三色河内塔、背包问题(Knapsack Problem)、蒙地卡罗法求 PI、Eratosthenes筛选求质数
C语言经典算法-3
超长整数运算(大数运算)、长 PI、最大公因数、最小公倍数、因式分解、完美数、阿姆斯壮数
C语言经典算法-4
最大访客数、中序式转后序式(前序式)、后序式的运算、洗扑克牌(乱数排列)、Craps赌博游戏
C语言经典算法-5
约瑟夫问题(Josephus Problem)、排列组合、格雷码(Gray Code)、产生可能的集合、m元素集合的n个元素子集
C语言经典算法-6
数字拆解、得分排行,选择、插入、气泡排序、Shell 排序法 - 改良的插入排序、Shaker 排序法 - 改良的气泡排序
C语言经典算法-7
排序法 - 改良的选择排序、快速排序法(一)、快速排序法(二)、快速排序法(三)、合并排序法
C语言经典算法-8
基数排序法、循序搜寻法(使用卫兵)、二分搜寻法(搜寻原则的代表)、插补搜寻法、费氏搜寻法
C语言经典算法-9
稀疏矩阵、多维矩阵转一维矩阵、上三角、下三角、对称矩阵、奇数魔方阵、4N 魔方阵、2(2N+1) 魔方阵
36.排序法 - 改良的选择排序
说明
选择排序法的概念简单,每次从未排序部份选一最小值,插入已排序部份的后端,其时间主要花费于在整个未排序部份寻找最小值,如果能让搜寻最小值的方式加 快,选择排序法的速率也就可以加快,Heap排序法让搜寻的路径由树根至最后一个树叶,而不是整个未排序部份,因而称之为改良的选择排序法。
解法
Heap排序法使用Heap Tree(堆积树),树是一种资料结构,而堆积树是一个二元树,也就是每一个父节点最多只有两个子节点(关于树的详细定义还请见资料结构书籍),堆积树的 父节点若小于子节点,则称之为最小堆积(Min Heap),父节点若大于子节点,则称之为最大堆积(Max Heap),而同一层的子节点则无需理会其大小关系,例如下面就是一个堆积树:
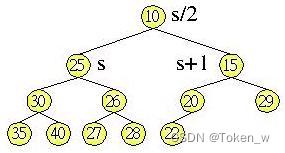
可以使用一维阵列来储存堆积树的所有元素与其顺序,为了计算方便,使用的起始索引是1而不是0,索引1是树根位置,如果左子节点储存在阵列中的索引为s,则其父节点的索引为s/2,而右子节点为s+1,就如上图所示,将上图的堆积树转换为一维阵列之后如下所示:

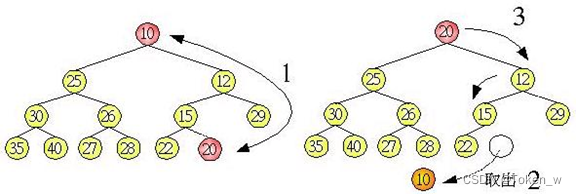
首先必须知道如何建立堆积树,加至堆积树的元素会先放置在最后一个树叶节点位置,然后检查父节点是否小于子节点(最小堆积),将小的元素不断与父节点交换,直到满足堆积树的条件为止,例如在上图的堆积加入一个元素12,则堆积树的调整方式如下所示:

建立好堆积树之后,树根一定是所有元素的最小值,您的目的就是:
将最小值取出
然后调整树为堆积树
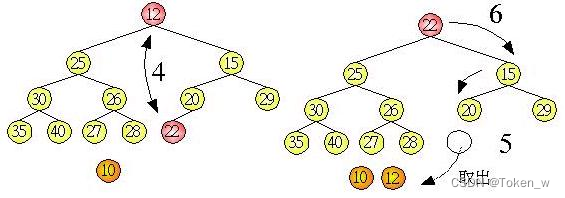
不断重复以上的步骤,就可以达到排序的效果,最小值的取出方式是将树根与最后一个树叶节点交换,然后切下树叶节点,重新调整树为堆积树,如下所示:
调整完毕后,树根节点又是最小值了,于是我们可以重覆这个步骤,再取出最小值,并调整树为堆积树,如下所示:
如此重覆步骤之后,由于使用一维阵列来储存堆积树,每一次将树叶与树根交换的动作就是将最小值放至后端的阵列,所以最后阵列就是变为已排序的状态。
其实堆积在调整的过程中,就是一个选择的行为,每次将最小值选至树根,而选择的路径并不是所有的元素,而是由树根至树叶的路径,因而可以加快选择的过程, 所以Heap排序法才会被称之为改良的选择排序法。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;} void createheap(int[]);
void heapsort(int[]); int main(void) { int number[MAX+1] = {-1}; int i, num; srand(time(NULL)); printf("排序前:"); for(i = 1; i <= MAX; i++) { number[i] = rand() % 100; printf("%d ", number[i]); } printf("\n建立堆积树:"); createheap(number); for(i = 1; i <= MAX; i++) printf("%d ", number[i]); printf("\n"); heapsort(number); printf("\n"); return 0;
} void createheap(int number[]) { int i, s, p; int heap[MAX+1] = {-1}; for(i = 1; i <= MAX; i++) { heap[i] = number[i]; s = i; p = i / 2; while(s >= 2 && heap[p] > heap[s]) { SWAP(heap[p], heap[s]); s = p; p = s / 2; } } for(i = 1; i <= MAX; i++) number[i] = heap[i]; } void heapsort(int number[]) { int i, m, p, s; m = MAX; while(m > 1) { SWAP(number[1], number[m]); m--; p = 1; s = 2 * p; while(s <= m) { if(s < m && number[s+1] < number[s]) s++; if(number[p] <= number[s]) break; SWAP(number[p], number[s]); p = s; s = 2 * p; } printf("\n排序中:"); for(i = MAX; i > 0; i--) printf("%d ", number[i]); }
}
37.快速排序法(一)
说明快速排序法(quick sort)是目前所公认最快的排序方法之一(视解题的对象而定),虽然快速排序法在最差状况下可以达O(n2),但是在多数的情况下,快速排序法的效率表现是相当不错的。
快速排序法的基本精神是在数列中找出适当的轴心,然后将数列一分为二,分别对左边与右边数列进行排序,而影响快速排序法效率的正是轴心的选择。
这边所介绍的第一个快速排序法版本,是在多数的教科书上所提及的版本,因为它最容易理解,也最符合轴心分割与左右进行排序的概念,适合对初学者进行讲解。
解法这边所介绍的快速演算如下:将最左边的数设定为轴,并记录其值为 s
廻圈处理:
令索引 i 从数列左方往右方找,直到找到大于 s 的数
令索引 j 从数列左右方往左方找,直到找到小于 s 的数
如果 i >= j,则离开回圈
如果 i < j,则交换索引i与j两处的值
将左侧的轴与 j 进行交换
对轴左边进行递回
对轴右边进行递回
透过以下演算法,则轴左边的值都会小于s,轴右边的值都会大于s,如此再对轴左右两边进行递回,就可以对完成排序的目的,例如下面的实例,表示要交换的数,[]表示轴:
[41] 24 76 11 45 64 21 69 19 36*
[41] 24 36 11 45* 64 21 69 19* 76
[41] 24 36 11 19 64* 21* 69 45 76
[41] 24 36 11 19 21 64 69 45 76
21 24 36 11 19 [41] 64 69 45 76
在上面的例子中,41左边的值都比它小,而右边的值都比它大,如此左右再进行递回至排序完成。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;} void quicksort(int[], int, int); int main(void) { int number[MAX] = {0}; int i, num; srand(time(NULL)); printf("排序前:"); for(i = 0; i < MAX; i++) { number[i] = rand() % 100; printf("%d ", number[i]); } quicksort(number, 0, MAX-1); printf("\n排序后:"); for(i = 0; i < MAX; i++) printf("%d ", number[i]); printf("\n"); return 0;
} void quicksort(int number[], int left, int right) { int i, j, s; if(left < right) { s = number[left]; i = left; j = right + 1; while(1) { // 向右找while(i + 1 < number.length && number[++i] < s) ; // 向左找 while(j -1 > -1 && number[--j] > s) ; if(i >= j) break; SWAP(number[i], number[j]); } number[left] = number[j]; number[j] = s; quicksort(number, left, j-1); // 对左边进行递回 quicksort(number, j+1, right); // 对右边进行递回 }
}
38.快速排序法(二)
说明在快速排序法(一)中,每次将最左边的元素设为轴,而之前曾经说过,快速排序法的加速在于轴的选择,在这个例子中,只将轴设定为中间的元素,依这个元素作基准进行比较,这可以增加快速排序法的效率。
解法在这个例子中,取中间的元素s作比较,同样的先得右找比s大的索引 i,然后找比s小的索引 j,只要两边的索引还没有交会,就交换 i 与 j 的元素值,这次不用再进行轴的交换了,因为在寻找交换的过程中,轴位置的元素也会参与交换的动作,例如:
41 24 76 11 45 64 21 69 19 36
首先left为0,right为9,(left+right)/2 = 4(取整数的商),所以轴为索引4的位置,比较的元素是45,您往右找比45大的,往左找比45小的进行交换:
41 24 76* 11 [45] 64 21 69 19 36
41 24 36 11 45 64 21 69 19* 76
41 24 36 11 19 64* 21* 69 45 76
[41 24 36 11 19 21] [64 69 45 76]
完成以上之后,再初别对左边括号与右边括号的部份进行递回,如此就可以完成排序的目的。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;} void quicksort(int[], int, int); int main(void) { int number[MAX] = {0}; int i, num; srand(time(NULL)); printf("排序前:"); for(i = 0; i < MAX; i++) { number[i] = rand() % 100; printf("%d ", number[i]); } quicksort(number, 0, MAX-1); printf("\n排序后:"); for(i = 0; i < MAX; i++) printf("%d ", number[i]); printf("\n"); return 0;
} void quicksort(int number[], int left, int right) { int i, j, s; if(left < right) { s = number[(left+right)/2]; i = left - 1; j = right + 1; while(1) { while(number[++i] < s) ; // 向右找 while(number[--j] > s) ; // 向左找 if(i >= j) break; SWAP(number[i], number[j]); } quicksort(number, left, i-1); // 对左边进行递回 quicksort(number, j+1, right); // 对右边进行递回 }
}
39.快速排序法(三)
说明
之前说过轴的选择是快速排序法的效率关键之一,在这边的快速排序法的轴选择方式更加快了快速排序法的效率,它是来自演算法名书 Introduction to Algorithms 之中。
解法
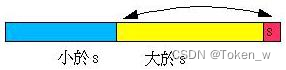
先说明这个快速排序法的概念,它以最右边的值s作比较的标准,将整个数列分为三个部份,一个是小于s的部份,一个是大于s的部份,一个是未处理的部份,如下所示 :

在排序的过程中,i 与 j 都会不断的往右进行比较与交换,最后数列会变为以下的状态:
然后将s的值置于中间,接下来就以相同的步骤会左右两边的数列进行排序的动作,如下所示:
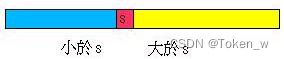
整个演算的过程,直接摘录书中的虚拟码来作说明:
QUICKSORT(A, p, r) if p < r then q <- PARTITION(A, p, r) QUICKSORT(A, p, q-1) QUICKSORT(A, q+1, r)
end QUICKSORT PARTITION(A, p, r) x <- A[r] i <- p-1 for j <- p to r-1 do if A[j] <= x then i <- i+1 exchange A[i]<->A[j] exchange A[i+1]<->A[r] return i+1
end PARTITION
一个实际例子的演算如下所示:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;} int partition(int[], int, int);
void quicksort(int[], int, int); int main(void) { int number[MAX] = {0}; int i, num; srand(time(NULL)); printf("排序前:"); for(i = 0; i < MAX; i++) { number[i] = rand() % 100; printf("%d ", number[i]); } quicksort(number, 0, MAX-1); printf("\n排序后:"); for(i = 0; i < MAX; i++) printf("%d ", number[i]); printf("\n"); return 0;
} int partition(int number[], int left, int right) { int i, j, s; s = number[right]; i = left - 1; for(j = left; j < right; j++) { if(number[j] <= s) { i++; SWAP(number[i], number[j]); } } SWAP(number[i+1], number[right]); return i+1;
} void quicksort(int number[], int left, int right) { int q; if(left < right) { q = partition(number, left, right); quicksort(number, left, q-1); quicksort(number, q+1, right); }
}
40.合并排序法
说明之前所介绍的排序法都是在同一个阵列中的排序,考虑今日有两笔或两笔以上的资料,它可能是不同阵列中的资料,或是不同档案中的资料,如何为它们进行排序?
解法可以使用合并排序法,合并排序法基本是将两笔已排序的资料合并并进行排序,如果所读入的资料尚未排序,可以先利用其它的排序方式来处理这两笔资料,然后再将排序好的这两笔资料合并。
有人问道,如果两笔资料本身就无排序顺序,何不将所有的资料读入,再一次进行排序?排序的精神是尽量利用资料已排序的部份,来加快排序的效率,小笔资料的 排序较为快速,如果小笔资料排序完成之后,再合并处理时,因为两笔资料都有排序了,所有在合并排序时会比单纯读入所有的资料再一次排序来的有效率。
那么可不可以直接使用合并排序法本身来处理整个排序的动作?而不动用到其它的排序方式?答案是肯定的,只要将所有的数字不断的分为两个等分,直到最后剩一个数字为止,然后再反过来不断的合并,就如下图所示:
不过基本上分割又会花去额外的时间,不如使用其它较好的排序法来排序小笔资料,再使用合并排序来的有效率。
下面这个程式范例,我们使用快速排序法来处理小笔资料排序,然后再使用合并排序法处理合并的动作。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX1 10
#define MAX2 10
#define SWAP(x,y) {int t; t = x; x = y; y = t;} int partition(int[], int, int);
void quicksort(int[], int, int);
void mergesort(int[], int, int[], int, int[]); int main(void) { int number1[MAX1] = {0}; int number2[MAX1] = {0}; int number3[MAX1+MAX2] = {0}; int i, num; srand(time(NULL)); printf("排序前:"); printf("\nnumber1[]:"); for(i = 0; i < MAX1; i++) { number1[i] = rand() % 100; printf("%d ", number1[i]); } printf("\nnumber2[]:"); for(i = 0; i < MAX2; i++) { number2[i] = rand() % 100; printf("%d ", number2[i]); } // 先排序两笔资料 quicksort(number1, 0, MAX1-1); quicksort(number2, 0, MAX2-1); printf("\n排序后:"); printf("\nnumber1[]:"); for(i = 0; i < MAX1; i++) printf("%d ", number1[i]); printf("\nnumber2[]:"); for(i = 0; i < MAX2; i++) printf("%d ", number2[i]); // 合并排序 mergesort(number1, MAX1, number2, MAX2, number3); printf("\n合并后:"); for(i = 0; i < MAX1+MAX2; i++) printf("%d ", number3[i]); printf("\n"); return 0;
} int partition(int number[], int left, int right) { int i, j, s; s = number[right]; i = left - 1; for(j = left; j < right; j++) { if(number[j] <= s) { i++; SWAP(number[i], number[j]); } } SWAP(number[i+1], number[right]); return i+1;
} void quicksort(int number[], int left, int right) { int q; if(left < right) { q = partition(number, left, right); quicksort(number, left, q-1); quicksort(number, q+1, right); }
} void mergesort(int number1[], int M, int number2[], int N, int number3[]) { int i = 0, j = 0, k = 0; while(i < M && j < N) { if(number1[i] <= number2[j]) number3[k++] = number1[i++]; else number3[k++] = number2[j++]; } while(i < M) number3[k++] = number1[i++]; while(j < N) number3[k++] = number2[j++];
}
系列好文,点击链接即可跳转
C语言经典算法-6
数字拆解、得分排行,选择、插入、气泡排序、Shell 排序法 - 改良的插入排序、Shaker 排序法 - 改良的气泡排序
C语言经典算法-8
基数排序法、循序搜寻法(使用卫兵)、二分搜寻法(搜寻原则的代表)、插补搜寻法、费氏搜寻法
相关文章:
C语言经典算法-7
文章目录 其他经典例题跳转链接36.排序法 - 改良的选择排序37.快速排序法(一)38.快速排序法(二)39.快速排序法(三)40.合并排序法 其他经典例题跳转链接 C语言经典算法-1 1.汉若塔 2. 费式数列 3. 巴斯卡三…...
)
设计模式(结构型设计模式——桥接模式)
设计模式(结构型设计模式——桥接模式) 桥接模式 基本定义 桥接模式将继承关系转化成关联关系,它降低了类与类之间的耦合度,减少了系统中类的数量,也减少了代码量。 降低了类与类之间的耦合度:脱耦就是将…...

Java的三大特性之一——继承
前言 http://t.csdnimg.cn/uibg3 在上一篇中我们已经讲解过封装,这里就主要讲解继承与多态 继承 1.为什么需要继承 Java中使用类对现实世界中实体来进行描述,类经过实例化之后的产物对象,则可以用来表示现实中的实体,但是现实…...

Java复习05 Spring 概念
Java复习05 Spring 概念 初学 Spring 的时候 我的问题是 什么是Spring? Spring的底层实现是什么?为什么现在Java都在用sping框架? 1.把Spring类比成乐高说明书 想象一下你有一个超级大的乐高积木盒子,里面有各种各样的积木。你…...

初级爬虫实战——哥伦比亚大学新闻
文章目录 发现宝藏一、 目标二、简单分析网页1. 寻找所有新闻2. 分析模块、版面和文章 三、爬取新闻1. 爬取模块2. 爬取版面3. 爬取文章 四、完整代码五、效果展示 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不…...
【JS】深度学习JavaScript
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录文章:【JS】深度学习JavaScript 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 一:JavaScript1.1 JavaScript是什么1.2 JS的引入方式1.3 JS变量1.4 数据类型1.5 …...
云原生相关知识
一、kubernetes 1 概述 Kubernetes(也称 k8s 或 “kube”)是一 个开源的容器编排平台,可以自动完成在部署、管理和扩展容器化应用过程中涉及的许多手动操作。 我们常说的编排的英文单词为 “Orchestration”,它常被解释…...
【多线程】有了解过 CAS 和原子操作吗?
SueWakeup 个人主页:SueWakeup 系列专栏:学习Java 个性签名:人生乏味啊,我欲令之光怪陆离 本文封面由 凯楠📷 友情赞助! 目录 前言 悲观锁和乐观锁 什么是 CAS ? 什么是原子操作? CAS 执行流…...

Linux 服务升级:Nginx 热升级 与 平滑回退
目录 一、实验 1.环境 2.Kali Linux 使用nmap扫描CentOS 3.Kali Linux 远程CentOS 4.Kali Linux 使用openvas 扫描 CentOS 5.Nginx 热升级 6.Nginx 平滑回退 二、问题 1.kill命令的信号有哪些 2.平滑升级与回退的信号 一、实验 1.环境 (1)主机…...

能降低嵌入式系统功耗的三个技术
为电池寿命设计嵌入式系统已经成为许多团队重要的设计考虑因素。优化电池寿命的能力有助于降低现场维护成本,并确保客户不需要不断更换或充电电池,从而获得良好的产品体验。 团队通常使用一些标准技术来提高电池寿命,例如将处理器置于低功耗…...

暴力快速入门强化学习
强化学习算法的基本思想(直觉) 众所周知,强化学习是能让智能体实现某个具体任务的强大算法。 强化学习的基本思想是让智能体跟环境交互,通过环境的反馈让智能体调整自己的策略,从反馈中学习,不断学习来得到…...

vue中v-if和v-show的区别
手段:v-if是动态的向DOM树内添加或者删除DOM元素;v-show是通过设置DOM元素的display样式属性控制显隐;编译过程:v-if切换有一个局部编译/卸载的过程,切换过程中合适地销毁和重建内部的事件监听和子组件;v-s…...
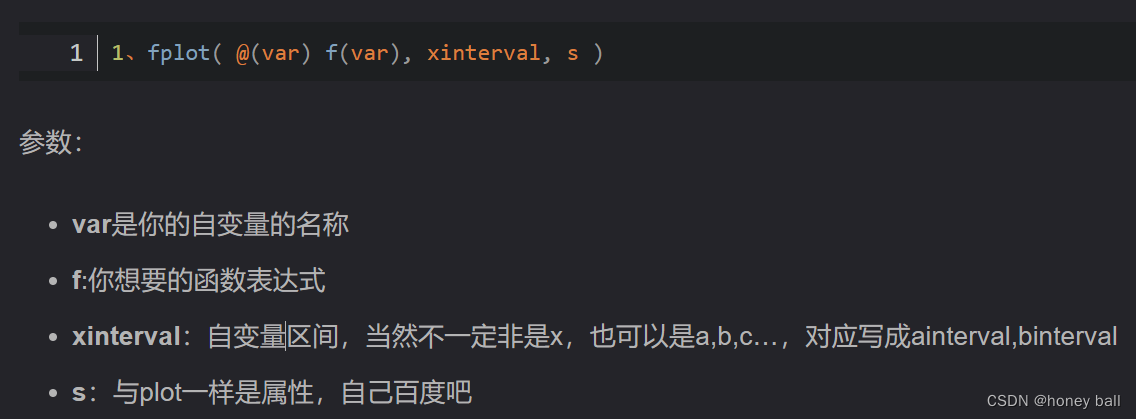
MATLAB绘图
现学现用,用时再学。 plot函数:有两个向量被指定为参数,plot(x,y) 会生成 y 对 x 的图形 添加轴标签和标题: 通过调用一次 plot,多个 x-y 对组参数会创建多幅图形: 在每十个数据点处放置标记: 一个窗口绘制多个图形; 可在弹窗的插入选项上添加…...

嵌入式学习-ARM-Day4
嵌入式学习-ARM-Day4 实现三个LED灯亮灭 .text .global _start _start: 使能GPIOE的外设时钟 RCC_MP_AHB4ENSETR的第[4]设置为1即可使能GPIOE时钟 LED1 LDR R0,0X50000A28 指定寄存器地址 LDR R1,[R0] 将寄存器原来的数值读取出来,保存到R1中 ORR R1,R1,#(0x…...

MySQL 中的事务和存储引擎
目录 事务的 ACID 特性 MySQL 的四种隔离机制和问题 MySQL 的四种隔离机制: MySQL 的存储引擎 InnoDB 存储引擎 MyISAM 存储引擎 Memory 存储引擎 通过 ALTER TABLE 语句更改存储引擎 在创建表时指定存储引擎 通过修改配置文件设置默认存储引擎 在数据库系…...
echarts多个折线图共用一个x轴和tooltip组件
实现效果 根据接口传来的数据,使用echarts绘制出,共用一个x轴的图表 功能:后端将所有数据传送过来,前端通过监听选中值来展示对应的图表数据 数据格式: 代码: <template><div><div clas…...

wireshark数据捕获实验简述
Wireshark是一款开源的网络协议分析工具,它可以用于捕获和分析网络数据包。是一款很受欢迎的“网络显微镜”。 实验拓扑图: 实验基础配置: 服务器: ip:172.16.1.88 mask:255.255.255.0 r1: sys sysname r1 undo info enable in…...

如何利用RunnerGo简化性能测试流程
在软件开发过程中,测试是一个重要的环节,需要投入大量时间和精力来确保应用程序或网站的质量和稳定性。但是,随着应用程序变得更加复杂和庞大,传统的测试工具在面对比较繁琐的项目时非常费时费力。这时,一些自动化测试…...

继承和深拷贝封装
继承和深拷贝封装 今日目标: 1.es5寄生组合式继承 2.es6类的继承 3.深拷贝函数封装 00-回顾 # 不同数据类型赋值时的区别: 基本数据类型,赋的就是值,相互之间不再有任何影响 引用数据类型,赋的是地址,…...
《定时执行专家》:Nircmd 的超级搭档,解锁自动化新境界
目录 Nircmd 简介 《定时执行专家》与 Nircmd 的结合 示例: 自动清理电脑垃圾: 定时发送邮件: 定时关闭电脑: 《定时执行专家》的优势: 总结: 以下是一些其他使用示例: 立即下载《定时执行专家》: Nircmd 官方网站: 更…...

3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐
3分钟快速上手:用BetterNCM安装器彻底改造你的网易云音乐 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在使用功能单一的网易云音乐吗?想不想让你的播放器拥…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

从NLP到RAG:AI标书生成系统的技术架构与落地路径深度剖析
引言2026年2月,国家发改委等八部门联合印发《关于加快招标投标领域人工智能推广应用的实施意见》,明确到2026年底招标文件检测、智能辅助评标、围串标识别等重点场景在部分省市实现全覆盖。同一时期,《招标投标法》修订草案经国务院常务会议原…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...