初级爬虫实战——哥伦比亚大学新闻
文章目录
- 发现宝藏
- 一、 目标
- 二、简单分析网页
- 1. 寻找所有新闻
- 2. 分析模块、版面和文章
- 三、爬取新闻
- 1. 爬取模块
- 2. 爬取版面
- 3. 爬取文章
- 四、完整代码
- 五、效果展示
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。

一、 目标
爬取news.columbia.edu的字段,包含标题、内容,作者,发布时间,链接地址,文章快照 (可能需要翻墙才能访问)
二、简单分析网页
1. 寻找所有新闻
- 按照如下步骤,找到全部新闻
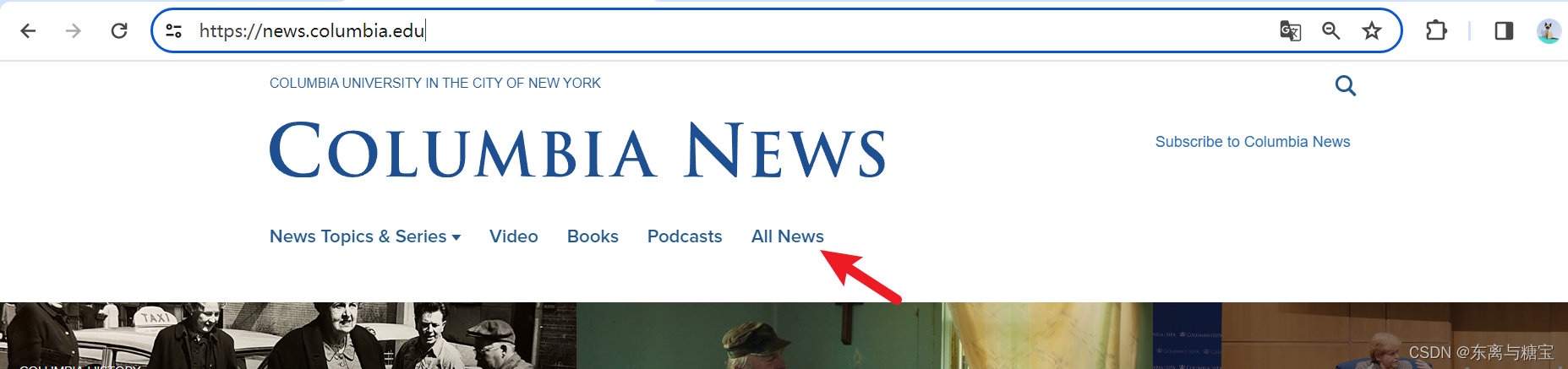
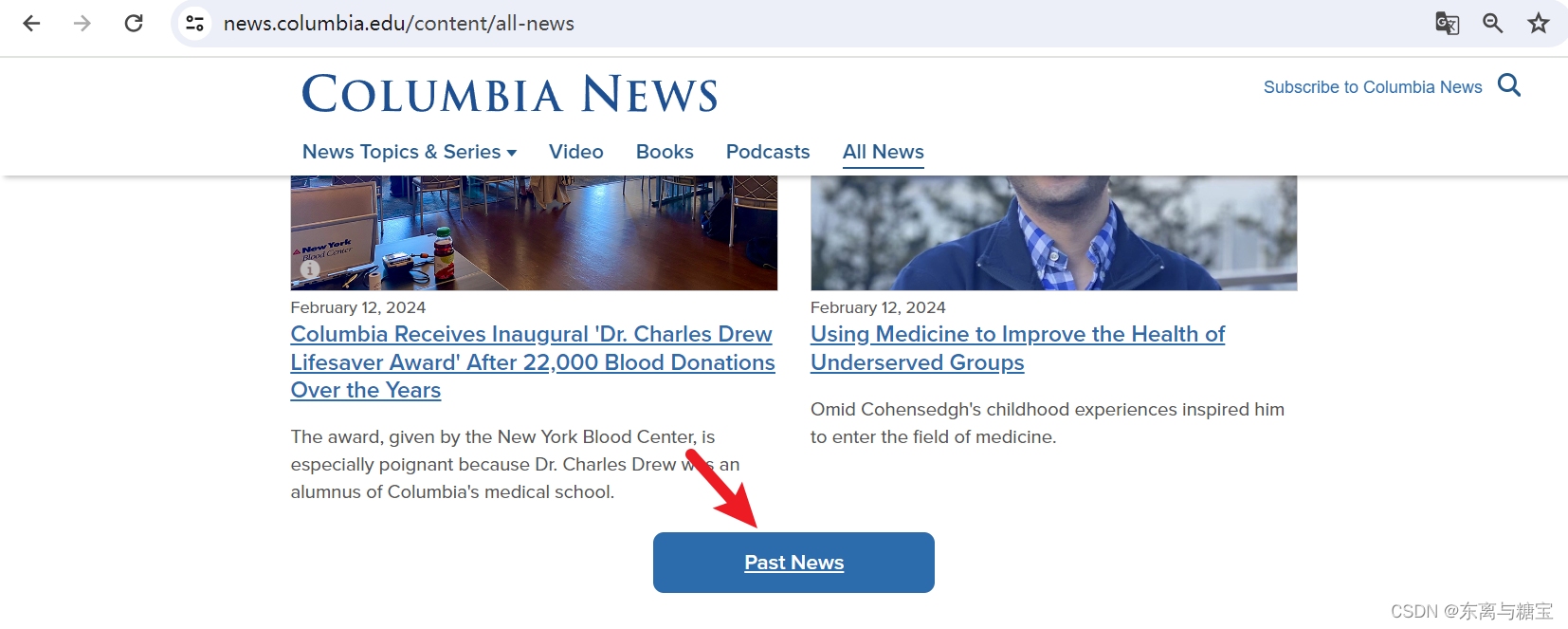
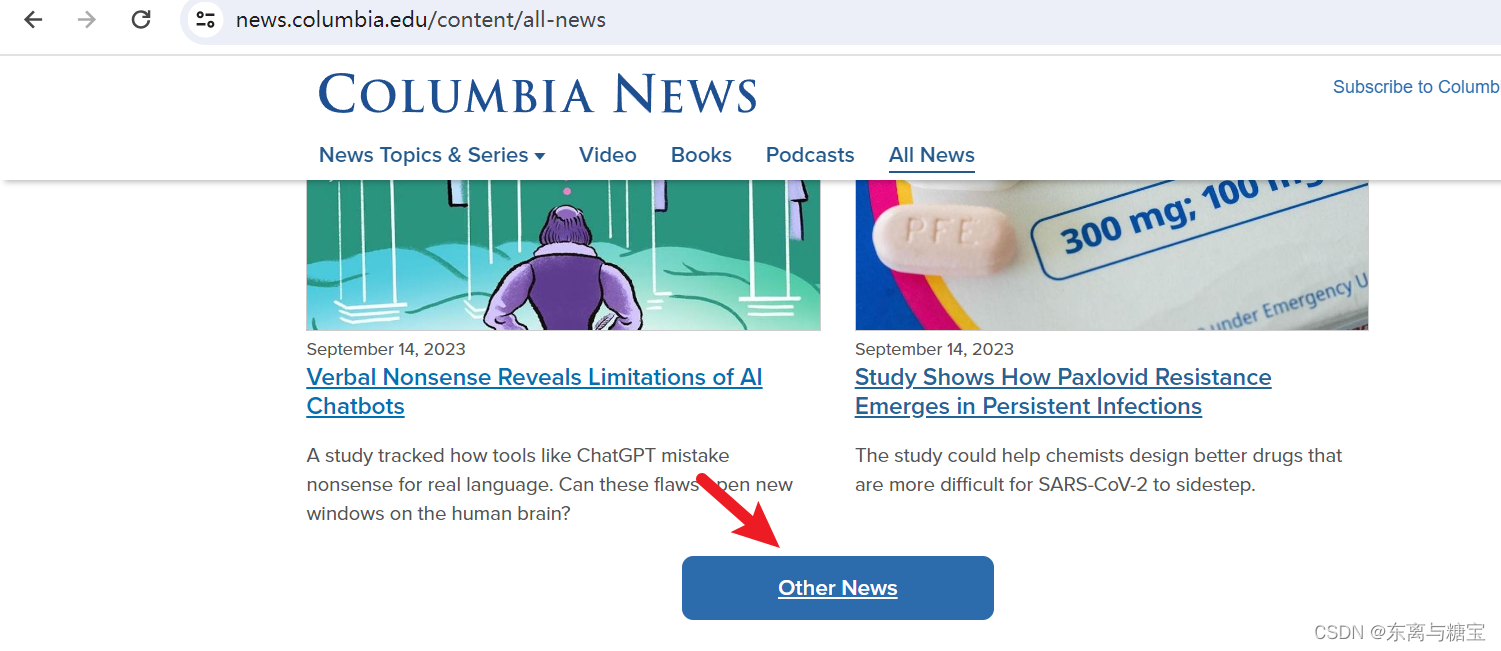
2. 分析模块、版面和文章
-
为了规范爬取的命名与逻辑,我们分别用模块、版面、文章三部分来进行爬取,具体如下
-
一个网站的全部新闻由数个模块组成,只要我们遍历爬取了所有模块就获得的该网站的所有新闻,由于该网站所有新闻都在该路径下,所有该路径就是唯一的模块
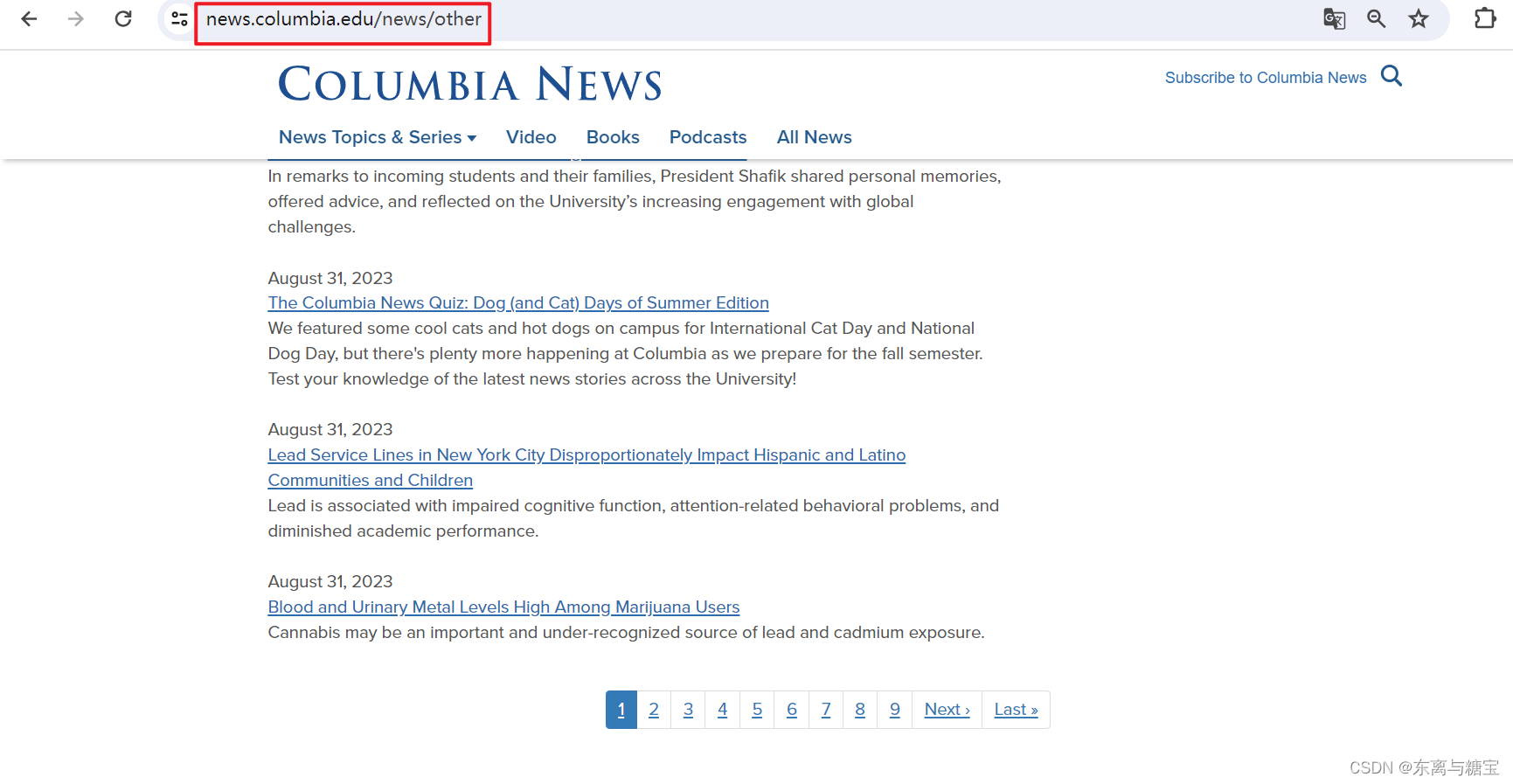
- 一个模块由数页版面组成,只要遍历了所有版面,我们就爬取了一个模块
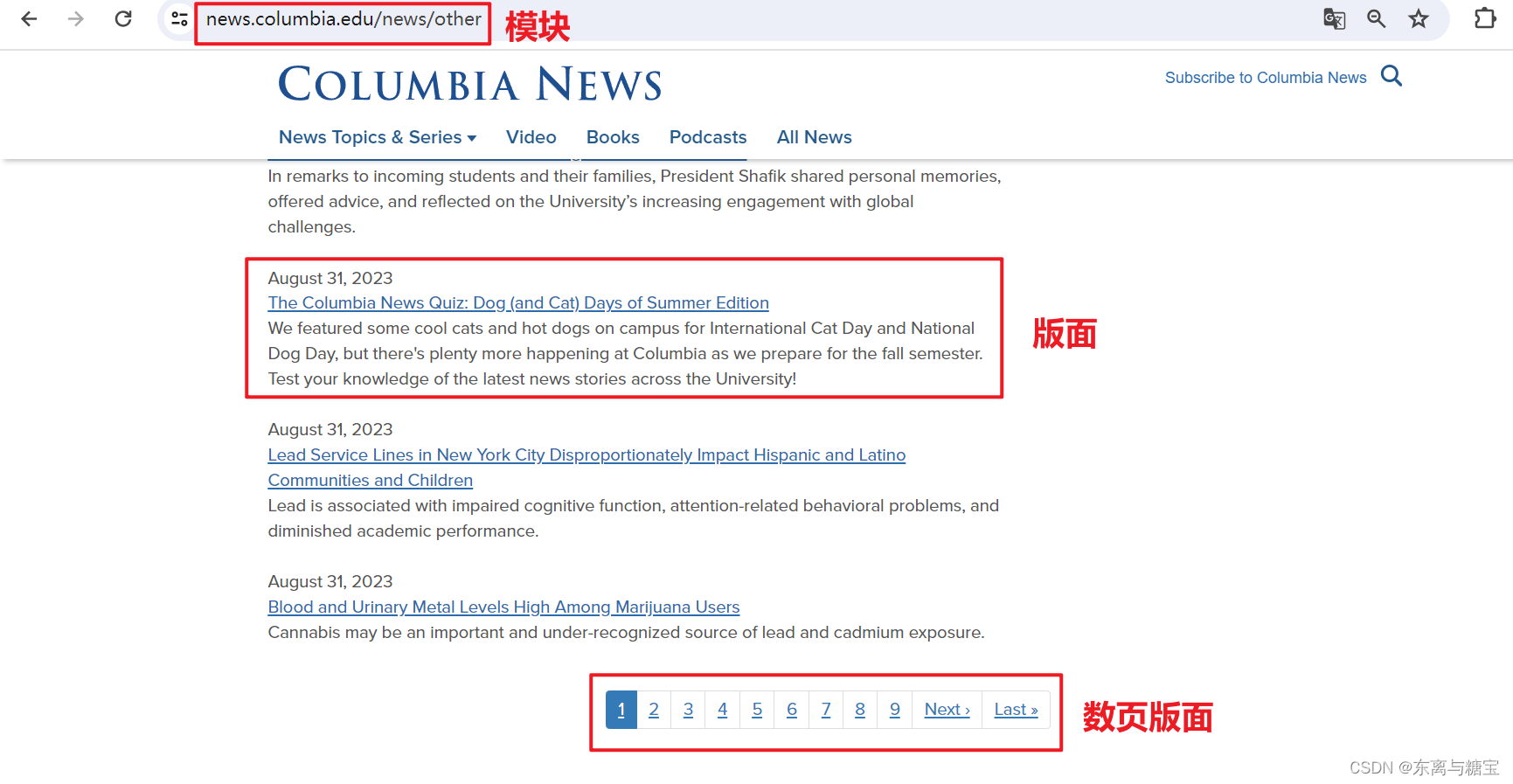
- 一个版面里有数页文章,由于该网站模块下的列表同时也是一篇文章,所以一个版面里只有一篇文章
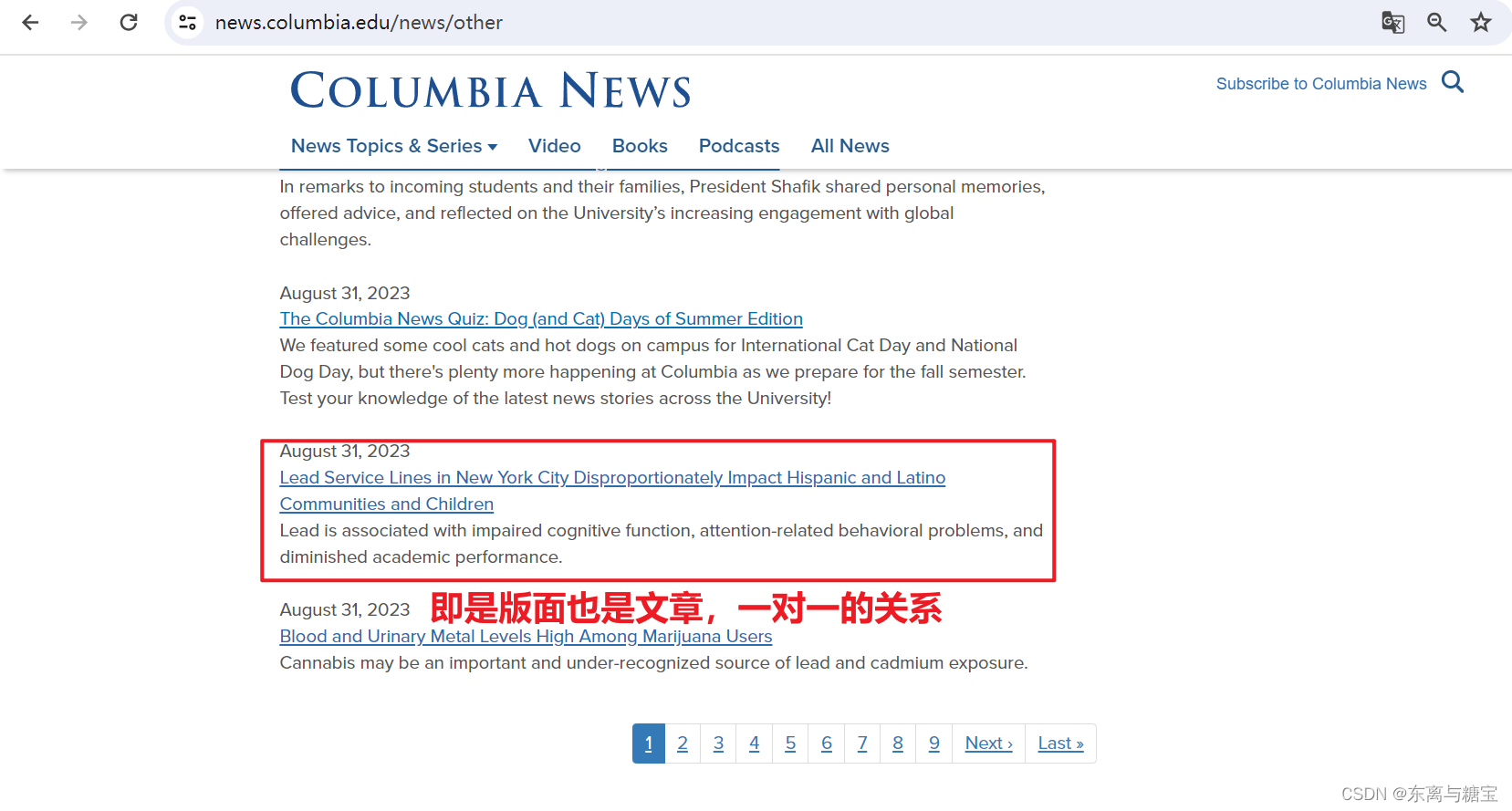
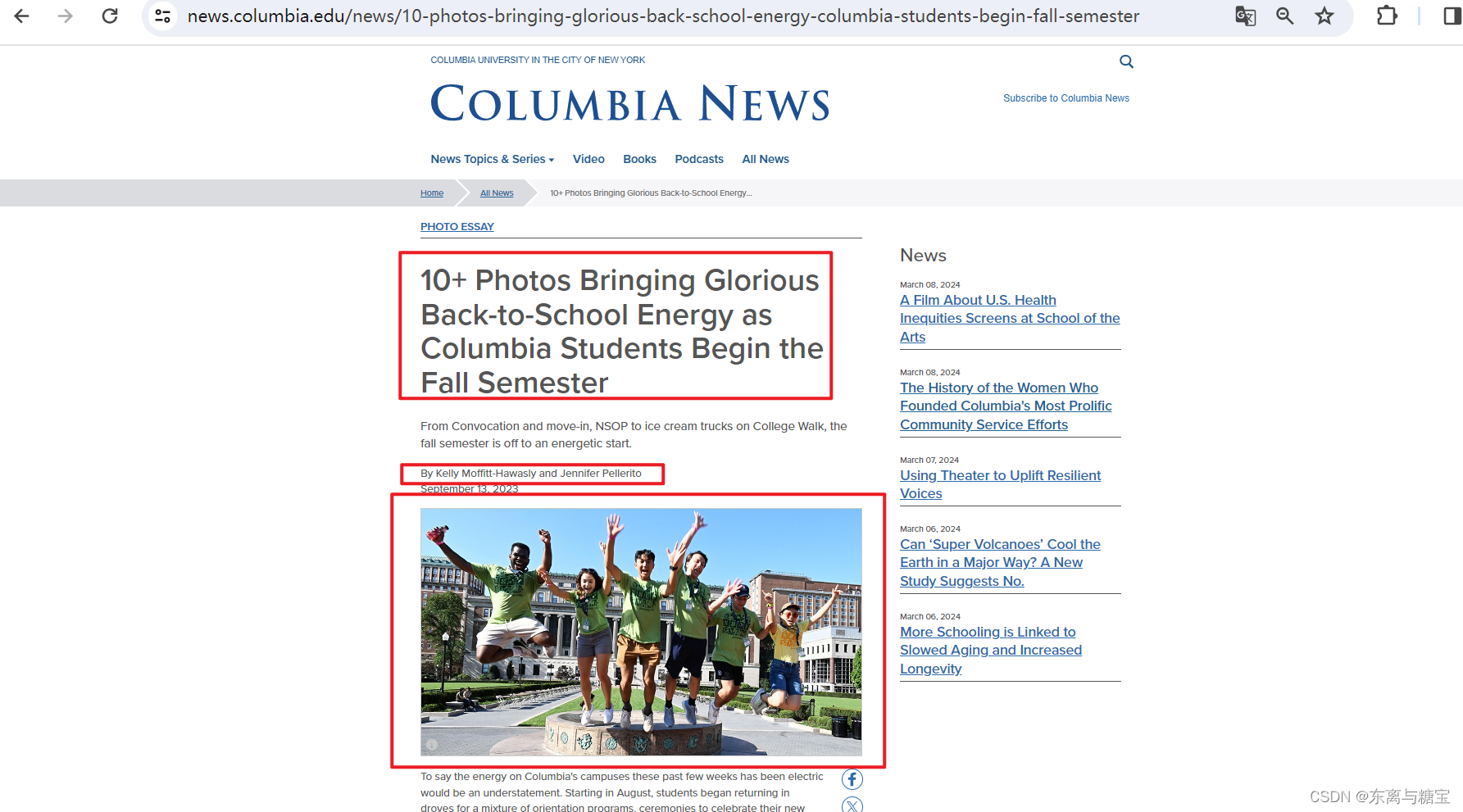
- 一篇文章有标题、出版时间和作者信息、文章正文和文章图片等信息
三、爬取新闻
1. 爬取模块
- 由于该新闻只有一个模块,所以直接请求该模块地址即可获取该模块的所有信息,但是为了兼容多模块的新闻,我们还是定义一个数组存储模块地址
class ColumbianewsScraper::def __init__(self, root_url, model_url, img_output_dir):self.root_url = root_urlself.model_url = model_urlself.img_output_dir = img_output_dirself.headers = {'Referer': 'https://news.columbia.edu/news/other?page=194','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/122.0.0.0 Safari/537.36','Cookie': ''}def run():# 网站根路径root_url = 'https://news.columbia.edu/'# 文章图片保存路径output_dir = 'D://imgs//columbia-news'# 模块地址数组model_urls = ['https://news.columbia.edu/news/other']for model_url in model_urls:# 初始化类scraper = ColumbianewsScraper(root_url, model_url, output_dir)# 遍历版面scraper.catalogue_all_pages()if __name__ == "__main__":run()
2. 爬取版面
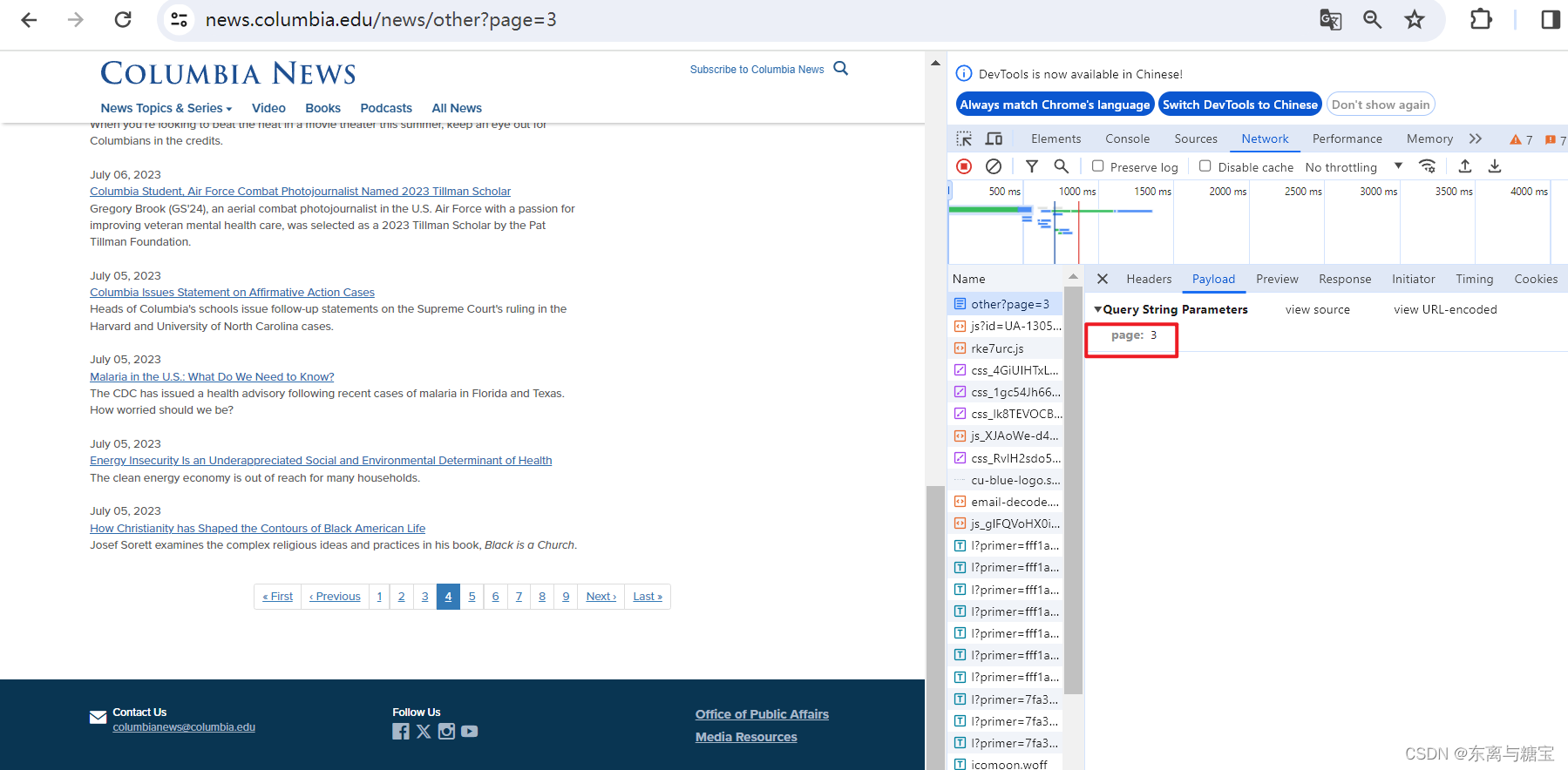
- 首先我们确认模块下版面切页相关的参数传递,通过切换页面我们不难发现切换页面是通过传递参数 page 来实现的
- 于是我们接着寻找模块下有多少页版面,通过观察控制台我们发现最后一页是在 类名为 的 ul 标签里的最后一个 a 标签文本里
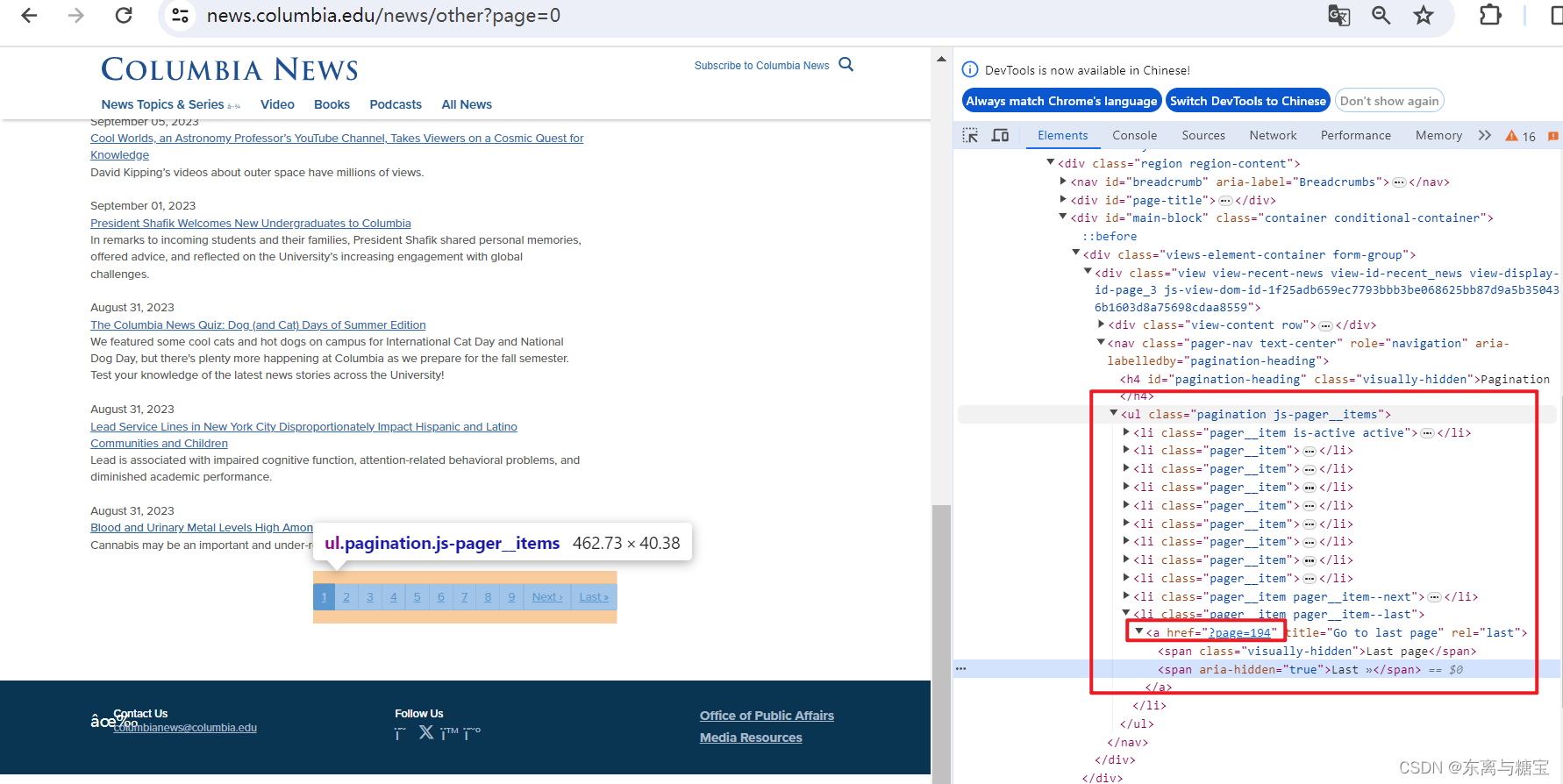
# 获取一个模块有多少版面def catalogue_all_pages(self):response = requests.get(self.model_url, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')try:num_page_str=soup.find('ul', 'pagination js-pager__items').find('a', title='Go to last page').get('href')# 使用正则表达式匹配数字match = re.search(r'\d+', num_page_str)num_pages = int(match.group()) + 1print(self.model_url + ' 模块一共有' + str(num_pages) + '页版面')for page in range(0, num_pages):print(f"========start catalogues page {page+1}" + "/" + str(num_pages) + "========")self.parse_catalogues(page)print(f"========Finished catalogues page {page+1}" + "/" + str(num_pages) + "========")except Exception as e:print(f'Error: {e}')traceback.print_exc()
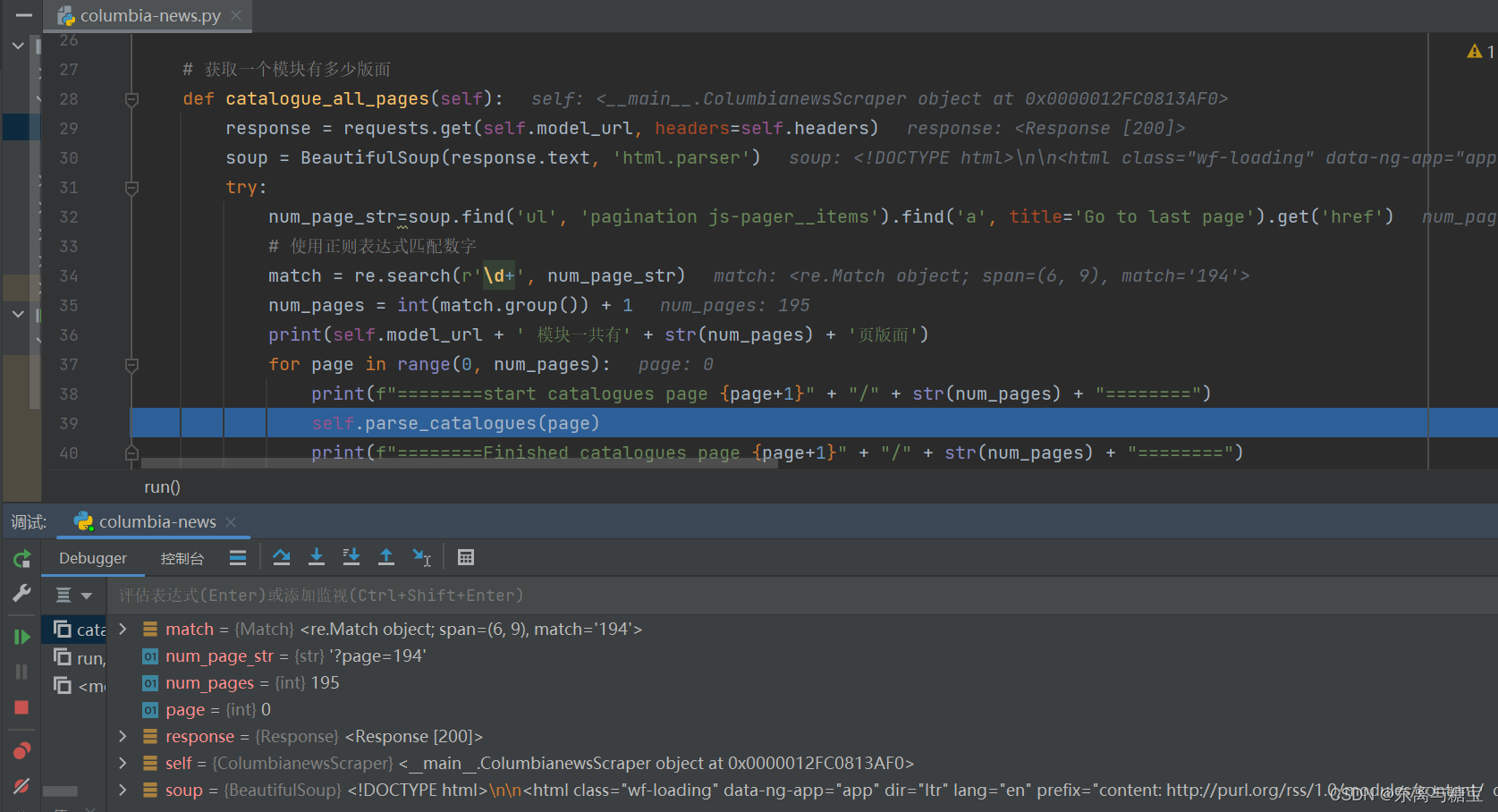
- 根据模块地址和page参数传递完整版面地址,访问并解析找到对应的版面列表
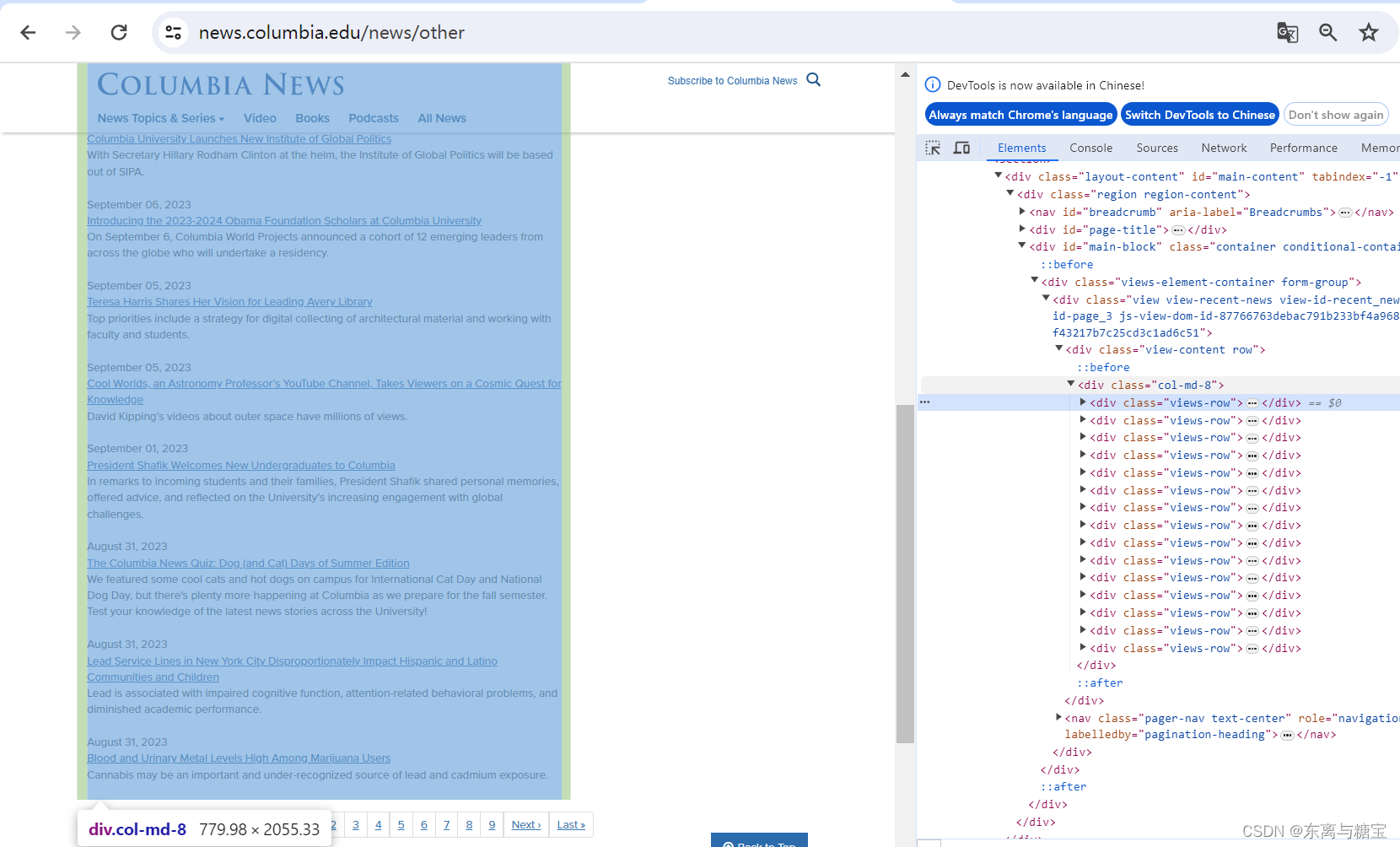
# 解析版面列表里的版面def parse_catalogues(self, page):params = {'page': page}response = requests.get(self.model_url, headers=self.headers, params=params)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')catalogue_list = soup.find('div', 'col-md-8')catalogues_list = catalogue_list.find_all('div', 'views-row')for index, catalogue in enumerate(catalogues_list):
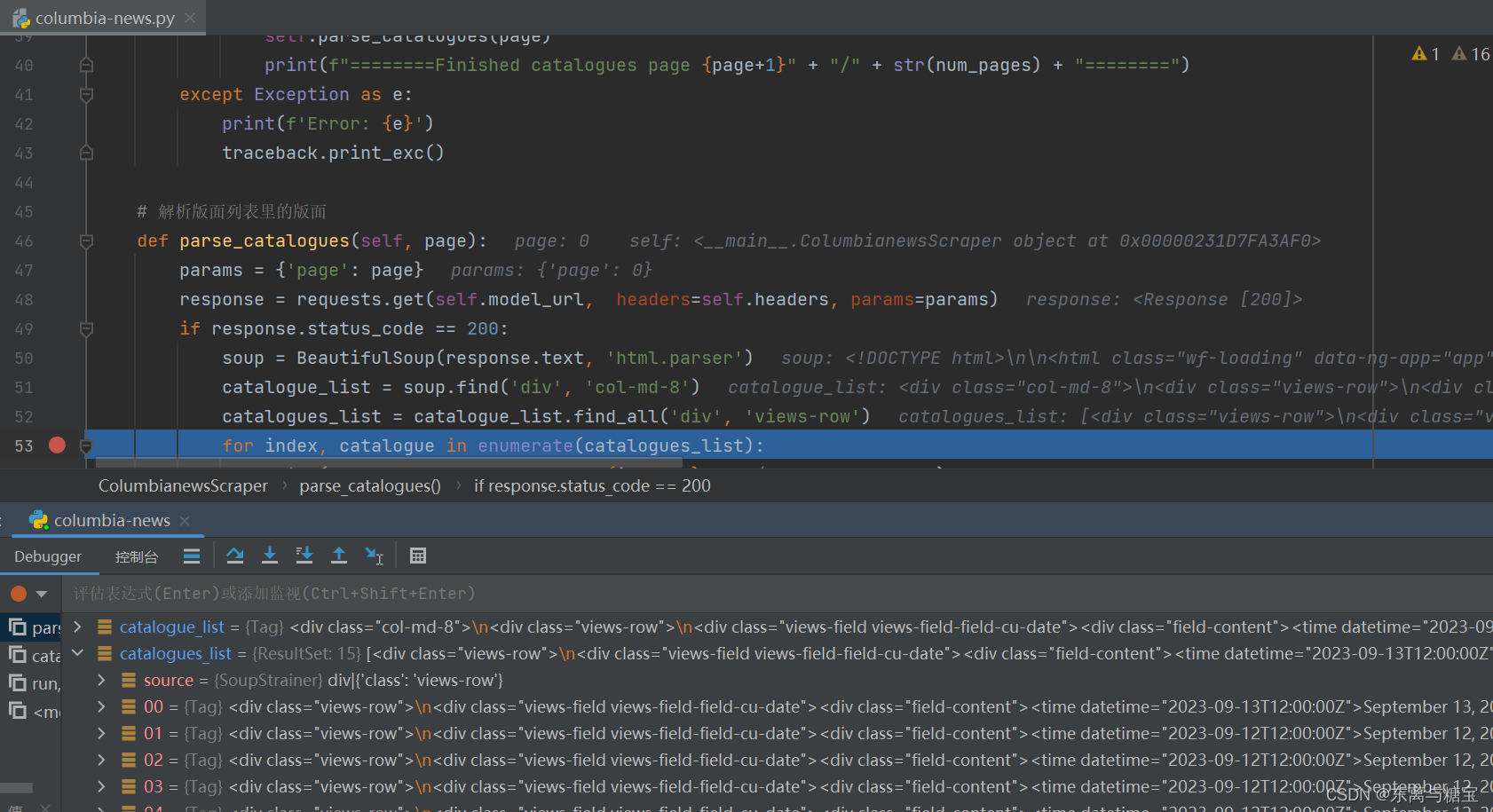
- 遍历版面列表,获取版面标题
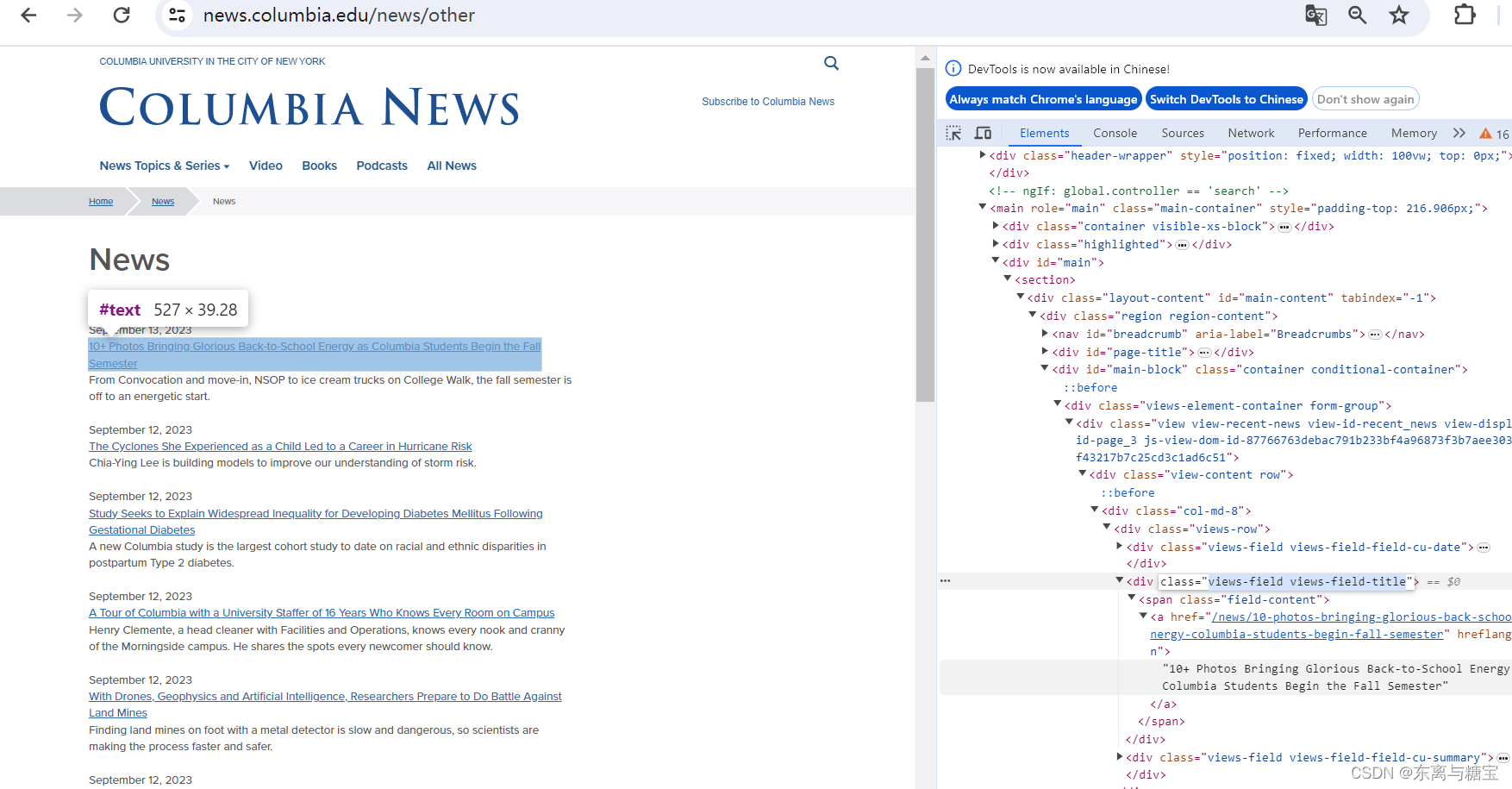
catalogue_title = catalogue.find('div', 'views-field views-field-title').find('a').get_text(strip=True)
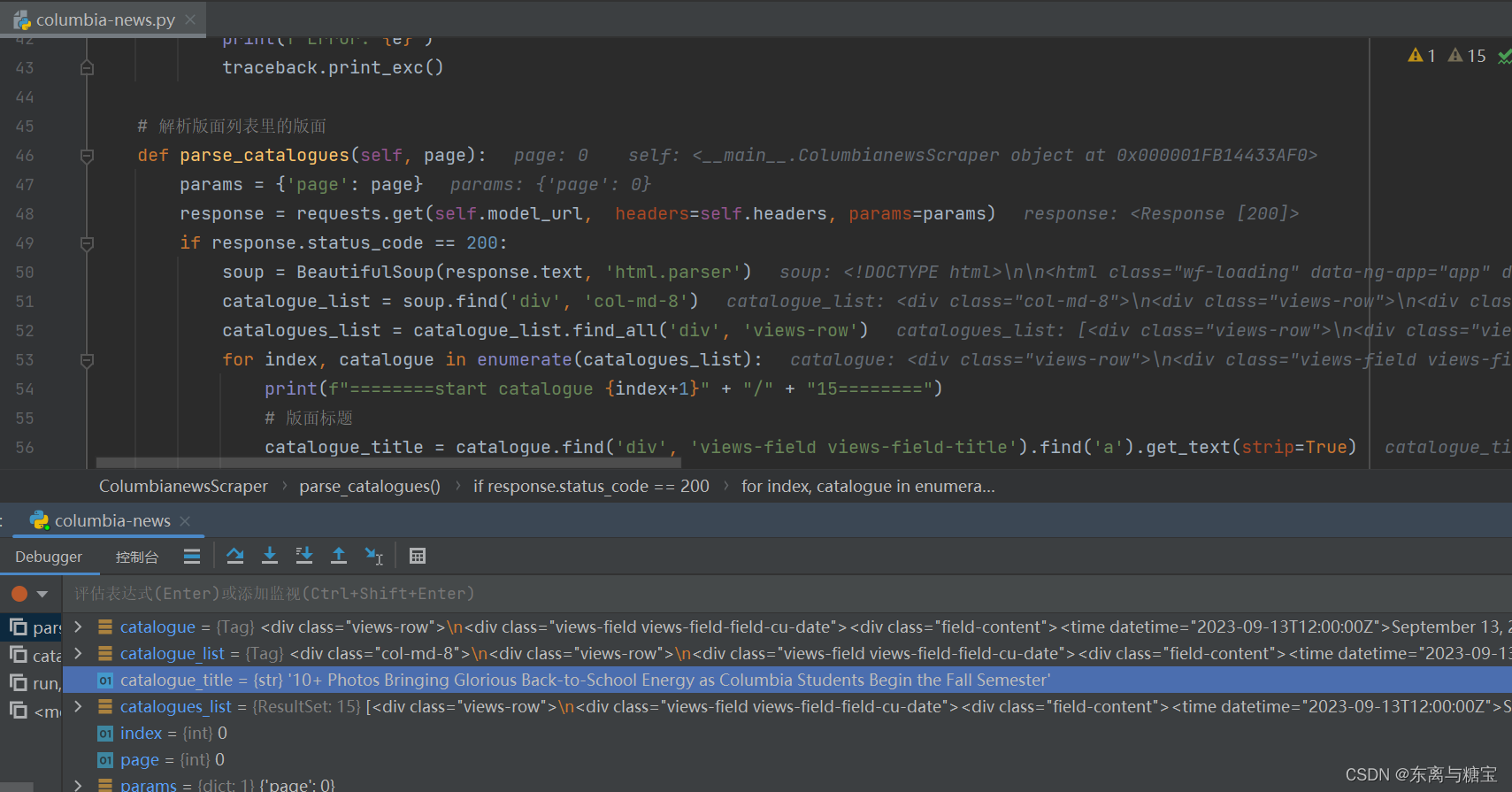
- 获取出版时间和操作时间
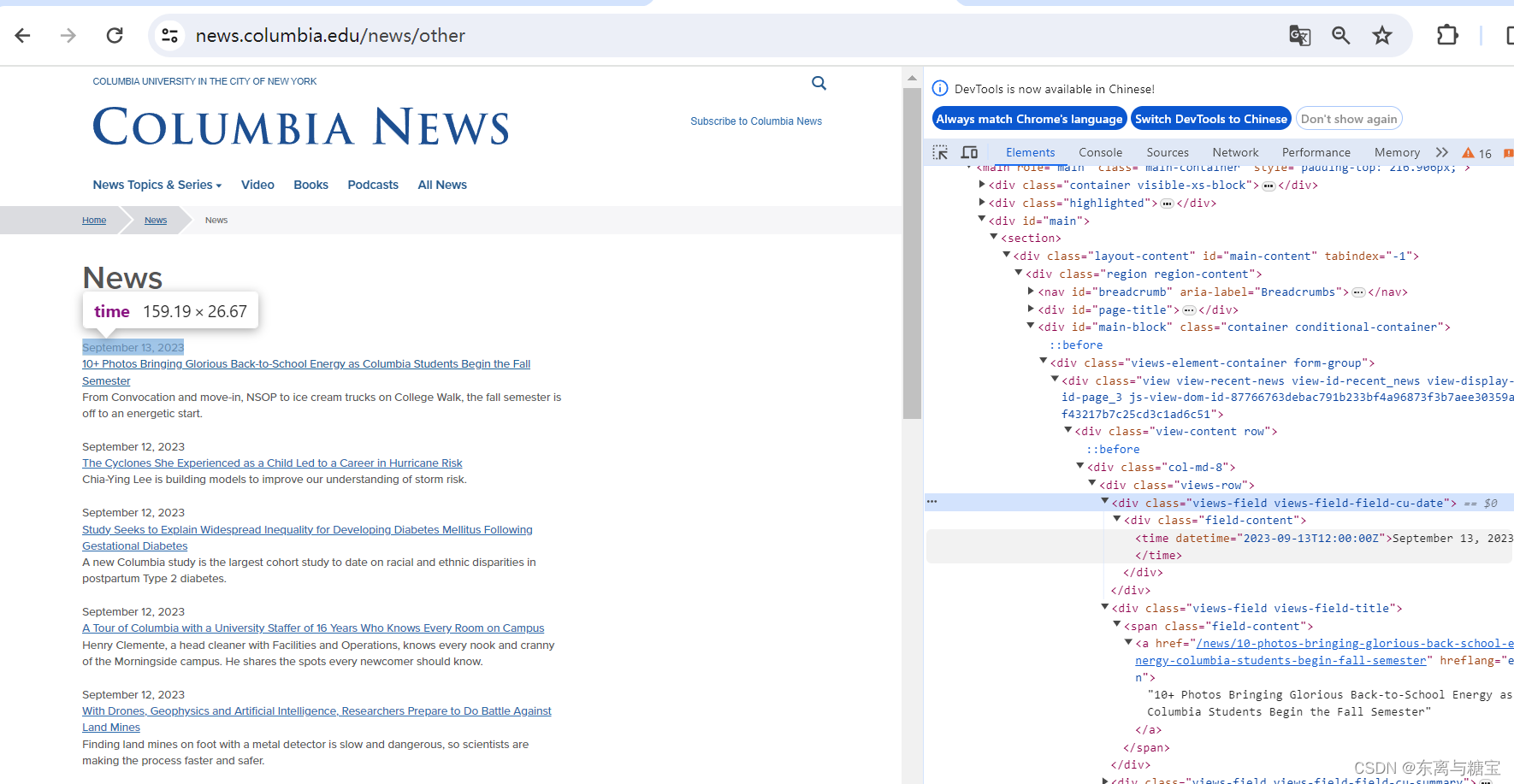
date = datetime.now()# 更新时间publish_time = catalogue.find('div', 'views-field views-field-field-cu-date').find('time').get('datetime')# 将日期字符串转换为datetime对象# 去除时区信息,得到不带时区的时间字符串date_string_no_tz = publish_time.replace('Z', '')# 使用 strptime 函数将字符串转换为时间对象updatetime = datetime.strptime(date_string_no_tz, '%Y-%m-%dT%H:%M:%S')
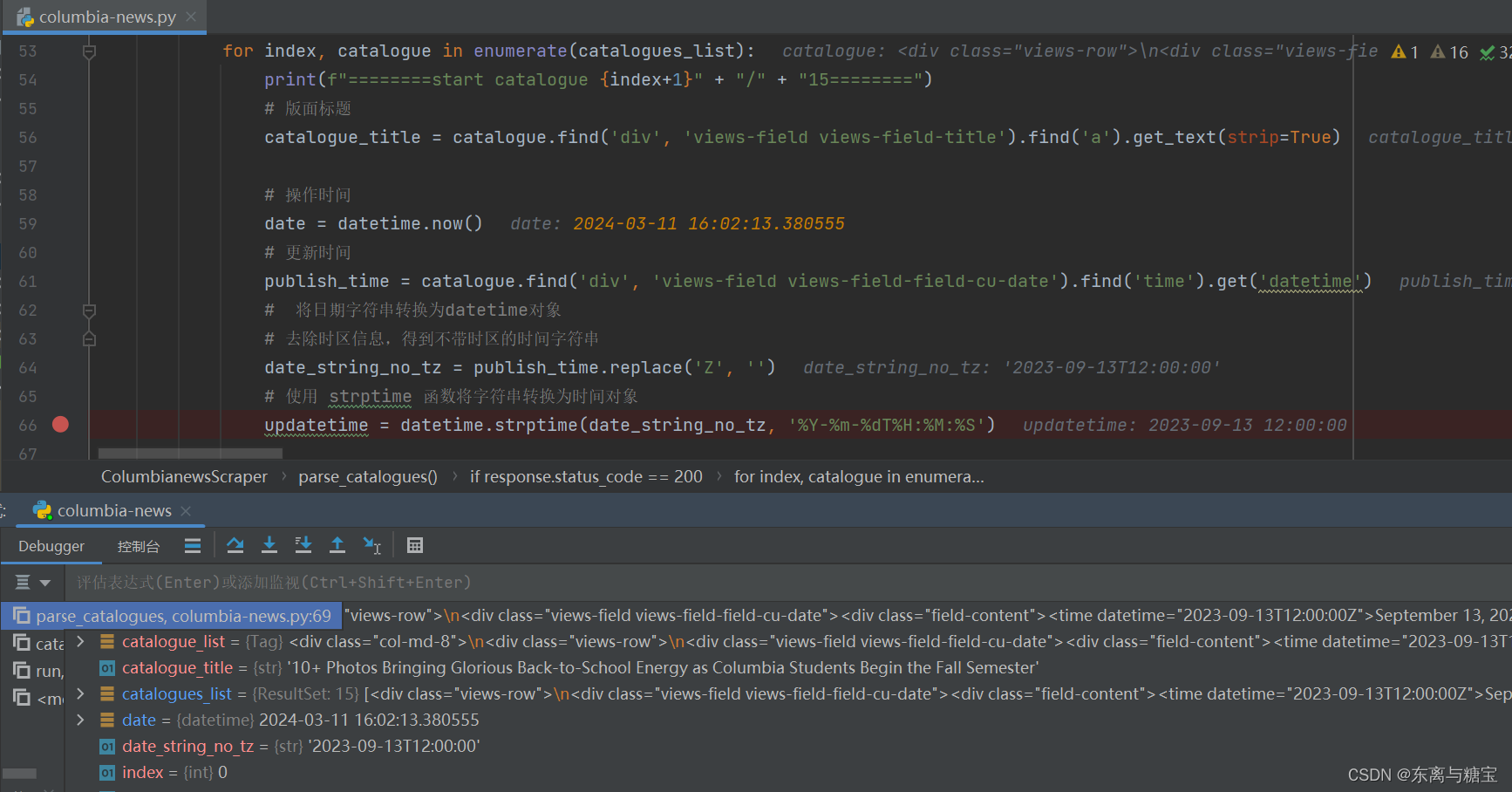
- 保存版面url和版面id, 由于该新闻是一个版面对应一篇文章,所以版面url和文章url是一样的,而且文章没有明显的标识,我们把地址后缀作为文章id,版面id则是文章id后面加上个01
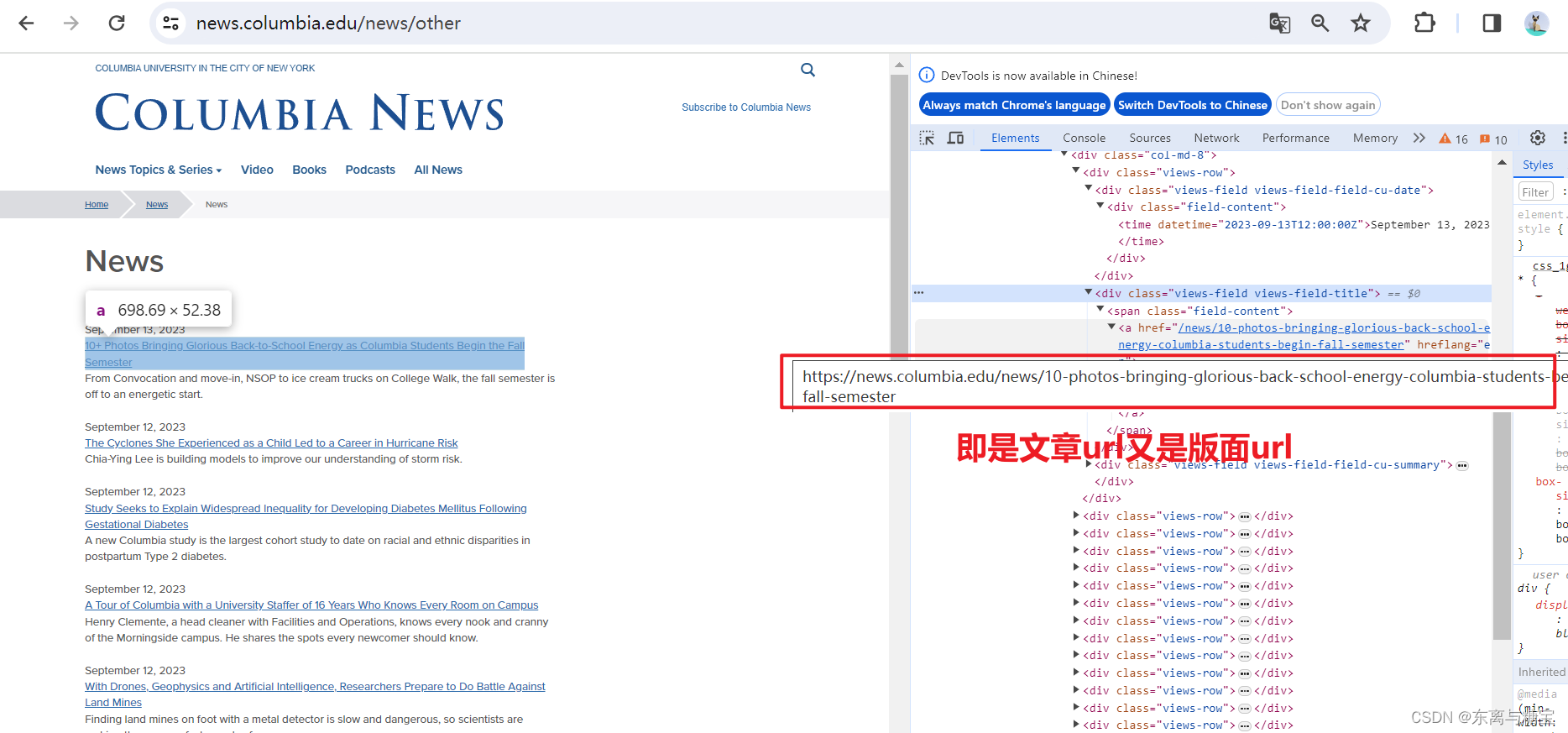
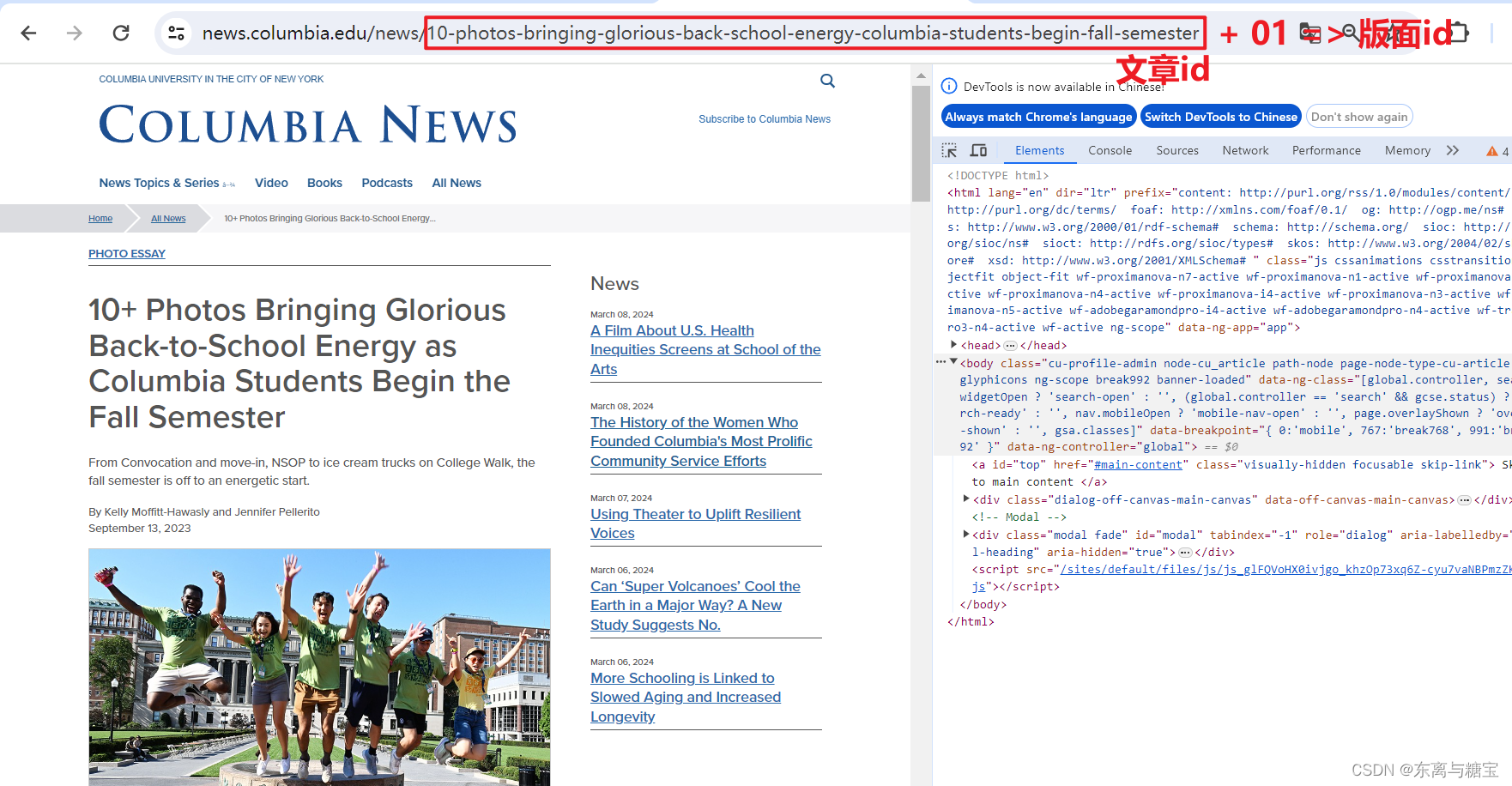
# 版面urlcatalogue_href = catalogue.find('div', 'views-field views-field-title').find('a').get('href')catalogue_url = self.root_url + catalogue_href# 使用正则表达式提取最后一个斜杠后的路径部分match = re.search(r'/([^/]+)/?$', catalogue_url)# 版面idcatalogue_id = str(match.group(1))
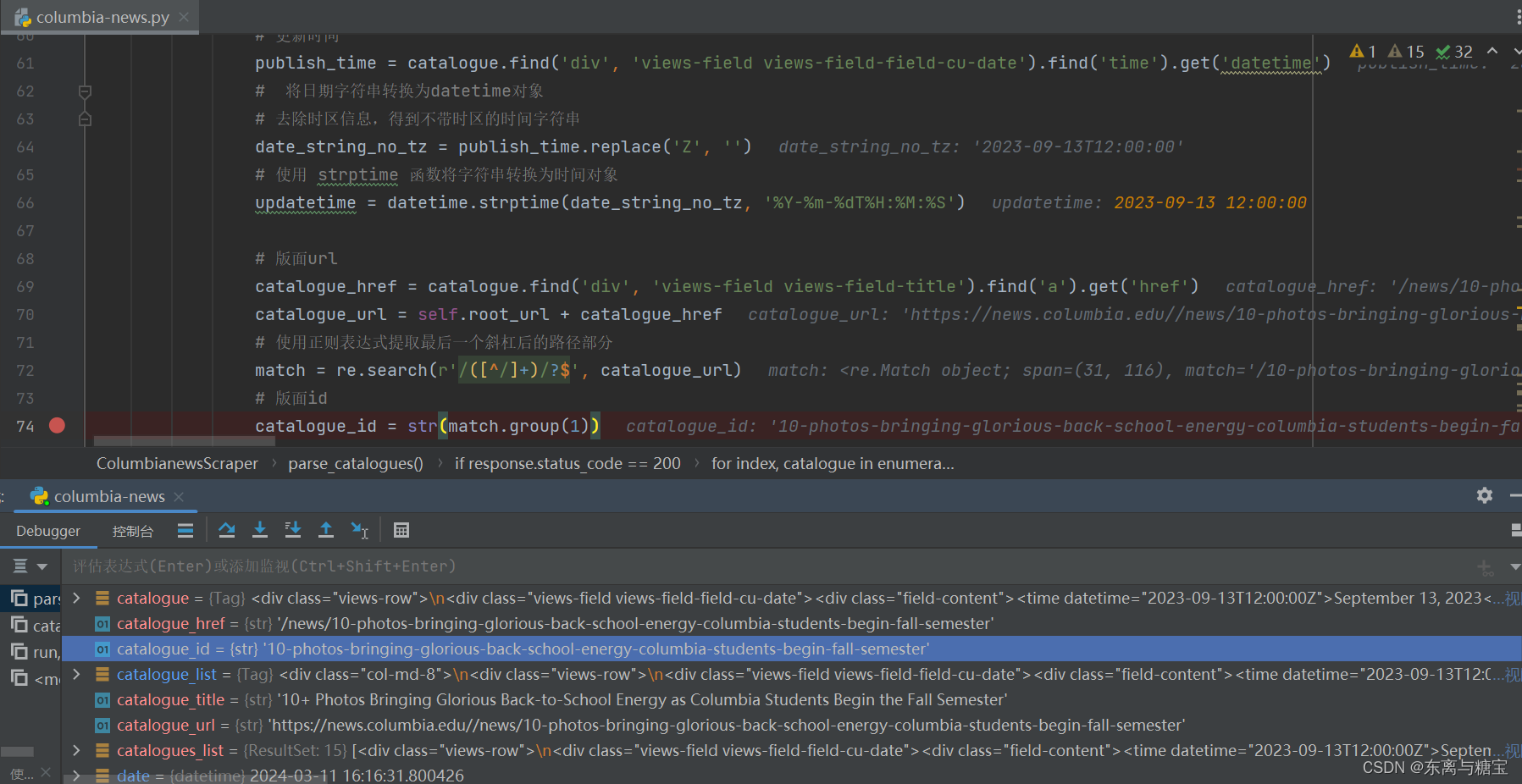
- 保存版面信息到mogodb数据库(由于每个版面只有一篇文章,所以版面文章数量cardsize的值赋为1)
# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['columbia-news']# 创建或选择集合catalogues_collection = db['catalogues']# 插入示例数据到 catalogues 集合catalogue_data = {'id': catalogue_id,'date': date,'title': catalogue_title,'url': catalogue_url,'cardSize': 1,'updatetime': updatetime}# 在插入前检查是否存在相同id的文档existing_document = catalogues_collection.find_one({'id': catalogue_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:catalogues_collection.insert_one(catalogue_data)print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")else:print("[爬取版面]版面 " + catalogue_url + " 已存在!")print(f"========finsh catalogue {index+1}" + "/" + "15========")
3. 爬取文章
-
由于一个版面对应一篇文章,所以版面url 、更新时间、标题和文章是一样的,并且按照设计版面id和文章id的区别只是差了个01,所以可以传递版面url、版面id、更新时间和标题四个参数到解析文章的函数里面
-
获取文章id,文章url,文章更新时间和当下操作时间
# 解析版面列表里的版面def parse_catalogues(self, page):...self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)...# 解析文章列表里的文章def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):card_response = requests.get(url, headers=self.headers)soup = BeautifulSoup(card_response.text, 'html.parser')# 对应的版面idcard_id = catalogue_id# 文章标题card_title = cardtitle# 文章更新时间updateTime = cardupdatetime# 操作时间date = datetime.now()
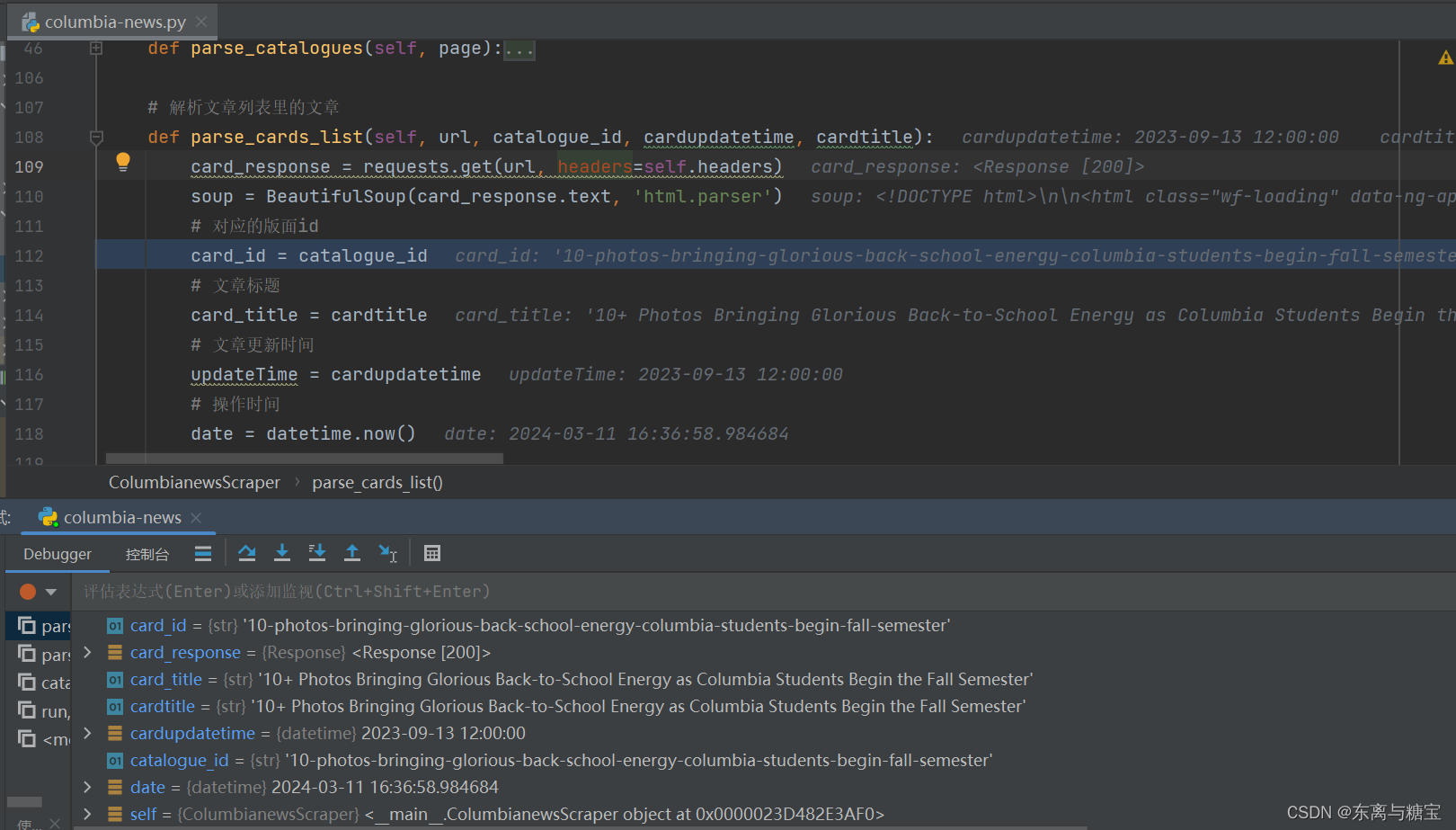
- 获取文章作者
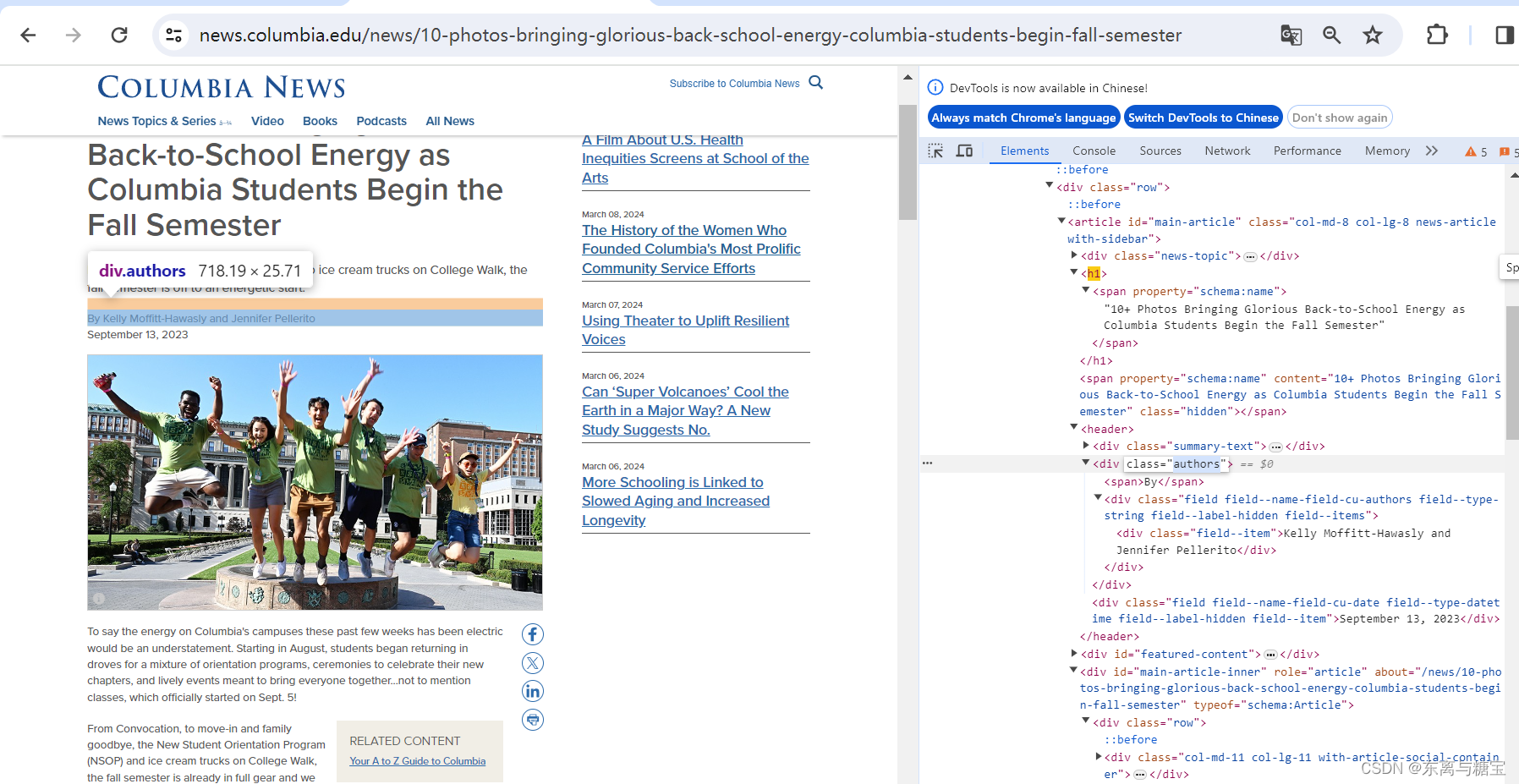
# 文章作者author = soup.find('article', id='main-article').find('div', 'authors').get_text().replace('\n', '').replace('By', '')
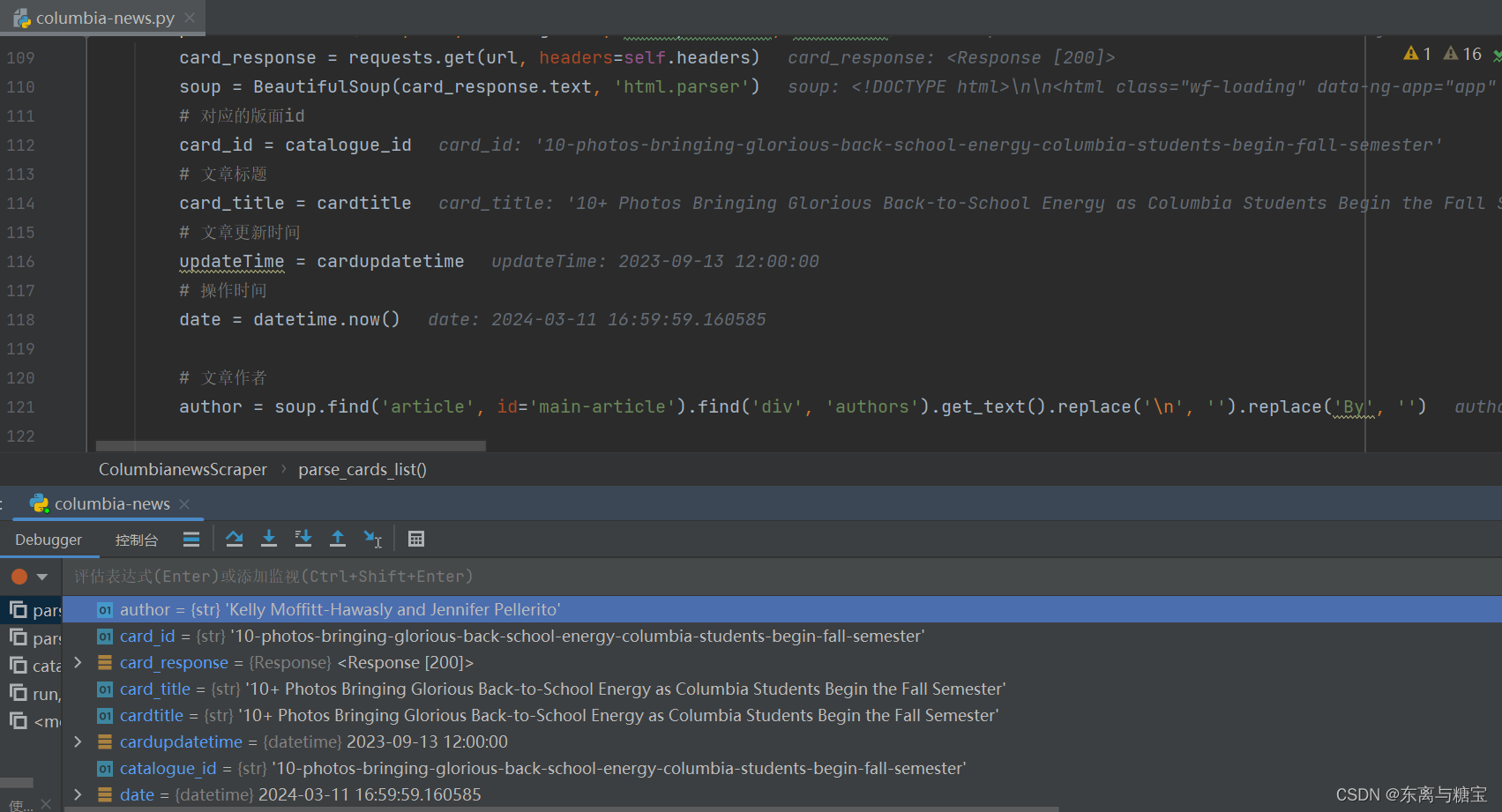
- 获取文章原始htmldom结构,并删除无用的部分(以下仅是部分举例),用html_content字段保留原始dom结构
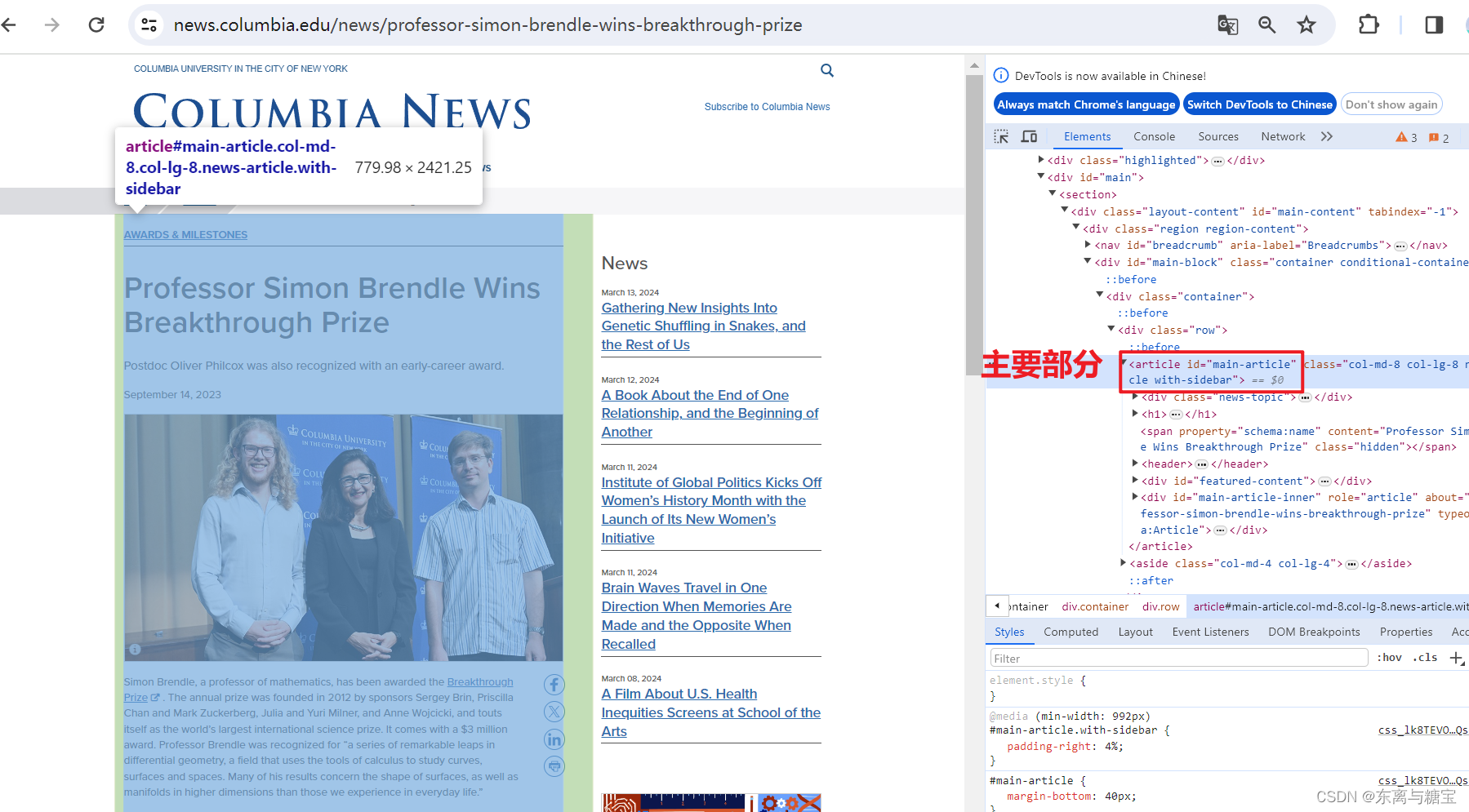
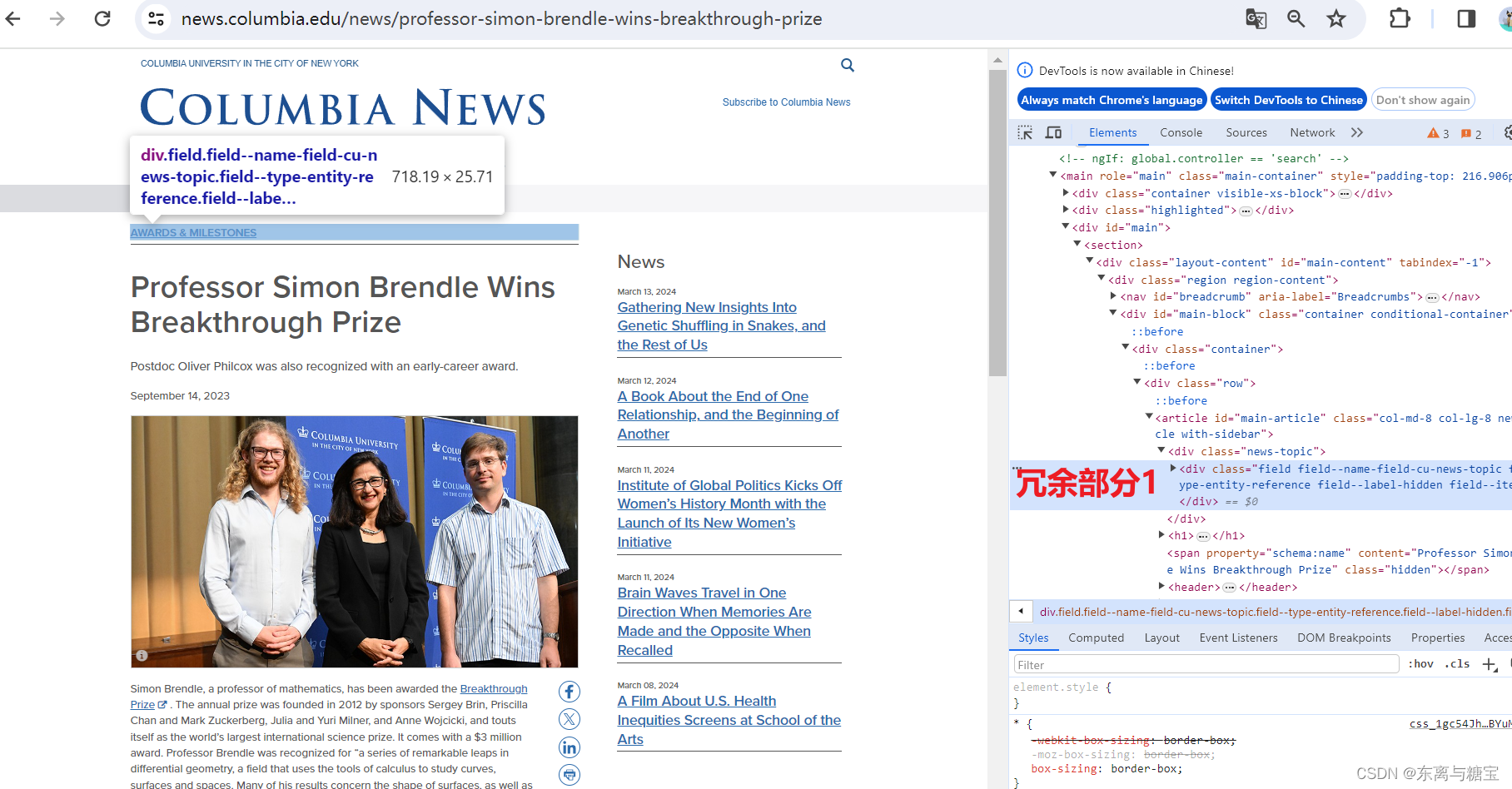
# 原始htmldom结构html_dom = soup.find('article', id='main-article')html_cut1 = html_dom.find('div', 'news-topic')html_cut2 = html_dom.find('div', id='cu_related_block-19355')html_cut3 = html_dom.find('div', id='sub-frame-error')# 移除元素if html_cut1:html_cut1.extract()if html_cut2:html_cut2.extract()if html_cut3:html_cut3.extract()
- 进行文章清洗,保留文本,去除标签,用content保留清洗后的文本
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):...# 增加保留html样式的源文本origin_html = html_dom.prettify() # String# 转义网页中的图片标签str_html = self.transcoding_tags(origin_html)# 再包装成temp_soup = BeautifulSoup(str_html, 'html.parser')# 反转译文件中的插图str_html = self.translate_tags(temp_soup.text)# 绑定更新内容content = self.clean_content(str_html)...# 工具 转义标签def transcoding_tags(self, htmlstr):re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义return s# 工具 转义标签def translate_tags(self, htmlstr):re_img = re.compile(r'@@##(img.*?)##@@', re.M)s = re_img.sub(r'<\1>', htmlstr) # IMG 转义return s# 清洗文章def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)content = content.replace('<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')content = content.replace(''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''','') \.replace(' <!--enpcontent', '').replace('<TABLE>', '')content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return content
- 下载保存文章图片,保存到d盘目录下的imgs/nd-news文件夹下,每篇文章图片用一个命名为文章id的文件夹命名,并用字段illustrations保存图片的绝对路径和相对路径
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):...# 下载图片imgs = []img_array = soup.find('div', id='featured-content').find_all('img')if len(img_array) is not None:for item in img_array:img_url = self.root_url + item.get('src')imgs.append(img_url)if len(imgs) != 0:# 下载图片illustrations = self.download_images(imgs, card_id)# 下载图片
def download_images(self, img_urls, card_id):result = re.search(r'[^/]+$', card_id)last_word = result.group(0)# 根据card_id创建一个新的子目录images_dir = os.path.join(self.img_output_dir, str(last_word)) if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for index, img_url in enumerate(img_urls):try:response = requests.get(img_url, stream=True, headers=self.headers)if response.status_code == 200:# 从URL中提取图片文件名img_name_with_extension = img_url.split('/')[-1]pattern = r'^[^?]*'match = re.search(pattern, img_name_with_extension)img_name = match.group(0)# 保存图片with open(os.path.join(images_dir, img_name), 'wb') as f:f.write(response.content)downloaded_images.append([img_url, os.path.join(images_dir, img_name)])print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')except requests.exceptions.RequestException as e:print(f'请求图片时发生错误:{e}')except Exception as e:print(f'保存图片时发生错误:{e}')return downloaded_images# 如果文件夹存在则跳过else:print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')return []
- 保存文章数据到数据库
# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['nd-news']# 创建或选择集合cards_collection = db['cards']# 插入示例数据到 cards 集合card_data = {'id': card_id,'catalogueId': catalogue_id,'type': 'nd-news','date': date,'title': card_title,'author': author,'updatetime': updateTime,'url': url,'html_content': str(html_content),'content': content,'illustrations': illustrations,}# 在插入前检查是否存在相同id的文档existing_document = cards_collection.find_one({'id': card_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:cards_collection.insert_one(card_data)print("[爬取文章]文章 " + url + " 已成功插入!")else:print("[爬取文章]文章 " + url + " 已存在!")
四、完整代码
import os
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import re
import tracebackclass ColumbianewsScraper:def __init__(self, root_url, model_url, img_output_dir):self.root_url = root_urlself.model_url = model_urlself.img_output_dir = img_output_dirself.headers = {'Referer': 'https://news.columbia.edu/news/other?page=194','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/122.0.0.0 Safari/537.36','Cookie': '__cf_bm=_takFcwXmltRp7BQJYSUHhfc9SXRPZdt1QnDSdY3Og8-1710139489-1.0.1.1''-wX_2br0GXQiqc5vxjaOTTg34kdk.o9tCITBFF5O6X1Q9WY_2nvwFju21xbXXvSemuQmqWnyoUko6kKS23kRidg; ''_gid=GA1.2.1882013722.1710139491; cuPivacyNotice=1; _ga=GA1.1.1680128029.1708481980; ''BIGipServer~CUIT~drupaldistprod.cc.columbia.edu-443-pool=!omWlyZA9uxfUxy0HrSyr''/NyatqktDOUd6d8QEy32oKHvcMAczidbyADWBSz0qWS+aS7plRl8MVECTKw=; ''_gcl_au=1.1.1784812938.1710140087; _ga_E1ZMHWNYYH=GS1.1.1710139491.3.1.1710140162.60.0.0 '}# 获取一个模块有多少版面def catalogue_all_pages(self):response = requests.get(self.model_url, headers=self.headers)soup = BeautifulSoup(response.text, 'html.parser')try:num_page_str = soup.find('ul', 'pagination js-pager__items').find('a', title='Go to last page').get('href')# 使用正则表达式匹配数字match = re.search(r'\d+', num_page_str)num_pages = int(match.group()) + 1print(self.model_url + ' 模块一共有' + str(num_pages) + '页版面')for page in range(0, num_pages):print(f"========start catalogues page {page + 1}" + "/" + str(num_pages) + "========")self.parse_catalogues(page)print(f"========Finished catalogues page {page + 1}" + "/" + str(num_pages) + "========")except Exception as e:print(f'Error: {e}')traceback.print_exc()# 解析版面列表里的版面def parse_catalogues(self, page):params = {'page': page}response = requests.get(self.model_url, headers=self.headers, params=params)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')catalogue_list = soup.find('div', 'col-md-8')catalogues_list = catalogue_list.find_all('div', 'views-row')for index, catalogue in enumerate(catalogues_list):print(f"========start catalogue {index + 1}" + "/" + "15========")# 版面标题catalogue_title = catalogue.find('div', 'views-field views-field-title').find('a').get_text(strip=True)# 操作时间date = datetime.now()# 更新时间publish_time = catalogue.find('div', 'views-field views-field-field-cu-date').find('time').get('datetime')# 将日期字符串转换为datetime对象# 去除时区信息,得到不带时区的时间字符串date_string_no_tz = publish_time.replace('Z', '')# 使用 strptime 函数将字符串转换为时间对象updatetime = datetime.strptime(date_string_no_tz, '%Y-%m-%dT%H:%M:%S')# 版面urlcatalogue_href = catalogue.find('div', 'views-field views-field-title').find('a').get('href')catalogue_url = self.root_url + catalogue_href# 使用正则表达式提取最后一个斜杠后的路径部分match = re.search(r'/([^/]+)/?$', catalogue_url)# 版面idcatalogue_id = str(match.group(1))self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['columbia-news']# 创建或选择集合catalogues_collection = db['catalogues']# 插入示例数据到 catalogues 集合catalogue_data = {'id': catalogue_id,'date': date,'title': catalogue_title,'url': catalogue_url,'cardSize': 1,'updatetime': updatetime}# 在插入前检查是否存在相同id的文档existing_document = catalogues_collection.find_one({'id': catalogue_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:catalogues_collection.insert_one(catalogue_data)print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")else:print("[爬取版面]版面 " + catalogue_url + " 已存在!")print(f"========finsh catalogue {index + 1}" + "/" + "15========")return Trueelse:raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")# 解析文章列表里的文章def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):card_response = requests.get(url, headers=self.headers)soup = BeautifulSoup(card_response.text, 'html.parser')# 对应的版面idcard_id = catalogue_id# 文章标题card_title = cardtitle# 文章更新时间updateTime = cardupdatetime# 操作时间date = datetime.now()try:# 文章作者author = soup.find('article', id='main-article').find('div', 'authors').get_text().replace('\n', '')except:author = None# 原始htmldom结构html_dom = soup.find('article', id='main-article')html_cut1 = html_dom.find('div', 'news-topic')html_cut2 = html_dom.find('div', id='cu_related_block-19355')html_cut3 = html_dom.find('div', id='sub-frame-error')# 移除元素if html_cut1:html_cut1.extract()if html_cut2:html_cut2.extract()if html_cut3:html_cut3.extract()html_content = html_dom# 增加保留html样式的源文本origin_html = html_dom.prettify() # String# 转义网页中的图片标签str_html = self.transcoding_tags(origin_html)# 再包装成temp_soup = BeautifulSoup(str_html, 'html.parser')# 反转译文件中的插图str_html = self.translate_tags(temp_soup.text)# 绑定更新内容content = self.clean_content(str_html)# 下载图片imgs = []img_array = soup.find('div', id='featured-content').find_all('img')if len(img_array) is not None:for item in img_array:img_url = self.root_url + item.get('src')imgs.append(img_url)if len(imgs) != 0:# 下载图片illustrations = self.download_images(imgs, card_id)# 连接 MongoDB 数据库服务器client = MongoClient('mongodb://localhost:27017/')# 创建或选择数据库db = client['columbia-news']# 创建或选择集合cards_collection = db['cards']# 插入示例数据到 cards 集合card_data = {'id': card_id,'catalogueId': catalogue_id,'type': 'nd-news','date': date,'title': card_title,'author': author,'updatetime': updateTime,'url': url,'html_content': str(html_content),'content': content,'illustrations': illustrations,}# 在插入前检查是否存在相同id的文档existing_document = cards_collection.find_one({'id': card_id})# 如果不存在相同id的文档,则插入新文档if existing_document is None:cards_collection.insert_one(card_data)print("[爬取文章]文章 " + url + " 已成功插入!")else:print("[爬取文章]文章 " + url + " 已存在!")# 下载图片def download_images(self, img_urls, card_id):result = re.search(r'[^/]+$', card_id)last_word = result.group(0)# 根据card_id创建一个新的子目录images_dir = os.path.join(self.img_output_dir, str(last_word))if not os.path.exists(images_dir):os.makedirs(images_dir)downloaded_images = []for index, img_url in enumerate(img_urls):try:response = requests.get(img_url, stream=True, headers=self.headers)if response.status_code == 200:# 从URL中提取图片文件名img_name_with_extension = img_url.split('/')[-1]pattern = r'^[^?]*'match = re.search(pattern, img_name_with_extension)img_name = match.group(0)# 保存图片with open(os.path.join(images_dir, img_name), 'wb') as f:f.write(response.content)downloaded_images.append([img_url, os.path.join(images_dir, img_name)])print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')except requests.exceptions.RequestException as e:print(f'请求图片时发生错误:{e}')except Exception as e:print(f'保存图片时发生错误:{e}')return downloaded_images# 如果文件夹存在则跳过else:print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')return []# 工具 转义标签def transcoding_tags(self, htmlstr):re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义return s# 工具 转义标签def translate_tags(self, htmlstr):re_img = re.compile(r'@@##(img.*?)##@@', re.M)s = re_img.sub(r'<\1>', htmlstr) # IMG 转义return s# 清洗文章def clean_content(self, content):if content is not None:content = re.sub(r'\r', r'\n', content)content = re.sub(r'\n{2,}', '', content)content = re.sub(r' {6,}', '', content)content = re.sub(r' {3,}\n', '', content)content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)content = content.replace('<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')content = content.replace(''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''','') \.replace(' <!--enpcontent', '').replace('<TABLE>', '')content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')return contentdef run():# 网站根路径root_url = 'https://news.columbia.edu/'# 文章图片保存路径output_dir = 'D://imgs//columbia-news'# 模块地址数组model_urls = ['https://news.columbia.edu/news/other']for model_url in model_urls:# 初始化类scraper = ColumbianewsScraper(root_url, model_url, output_dir)# 遍历版面scraper.catalogue_all_pages()if __name__ == "__main__":run()五、效果展示
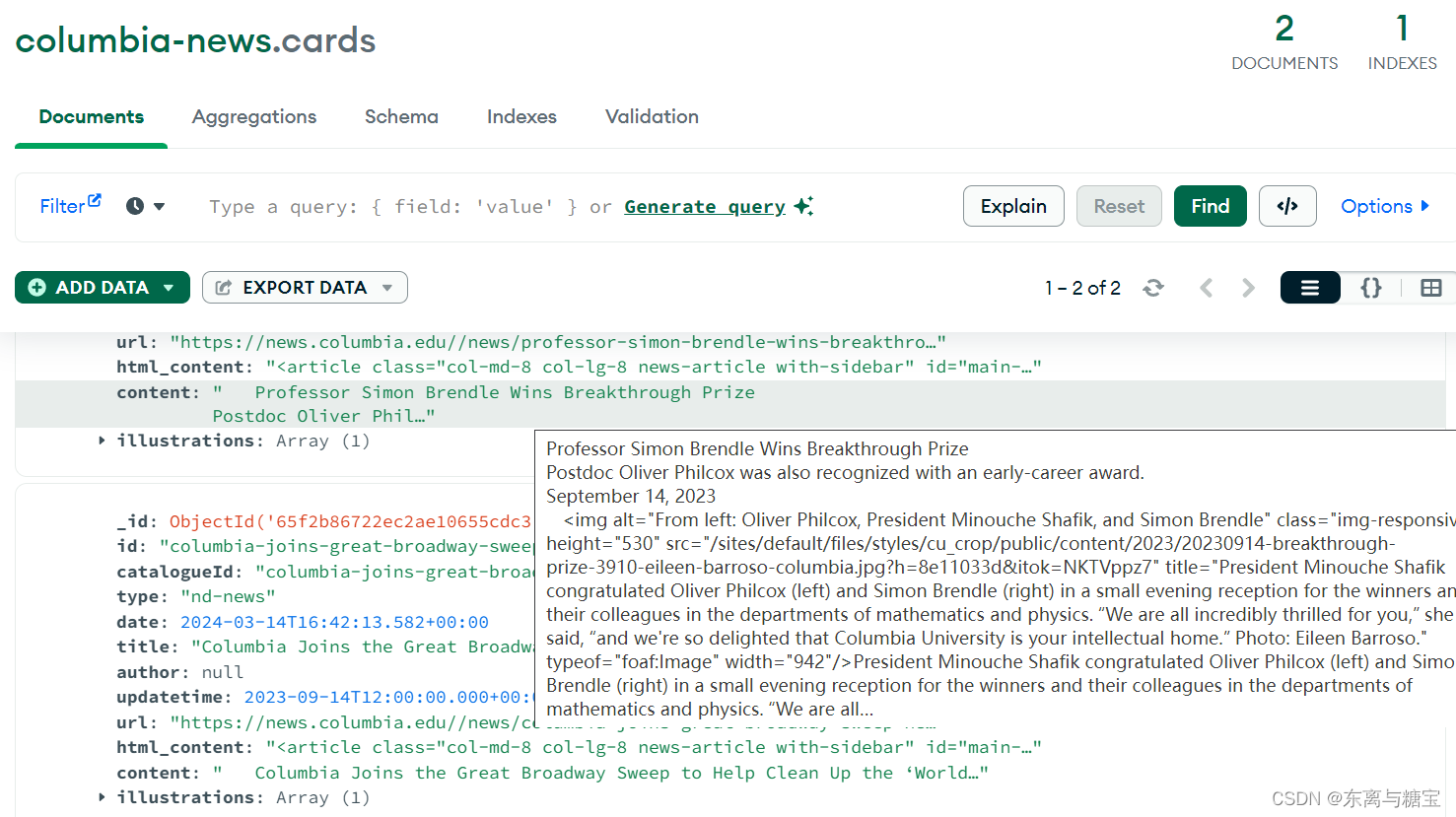
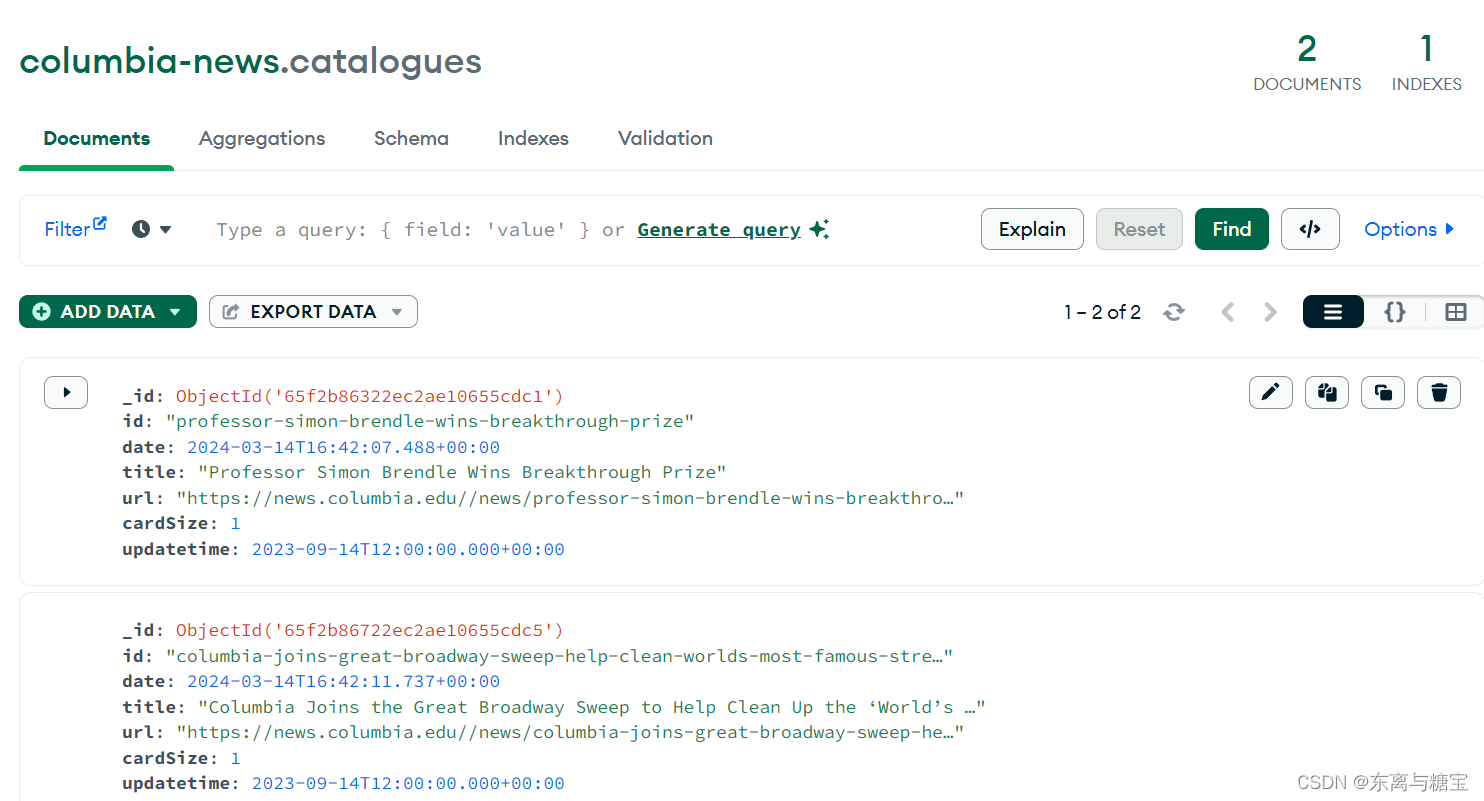
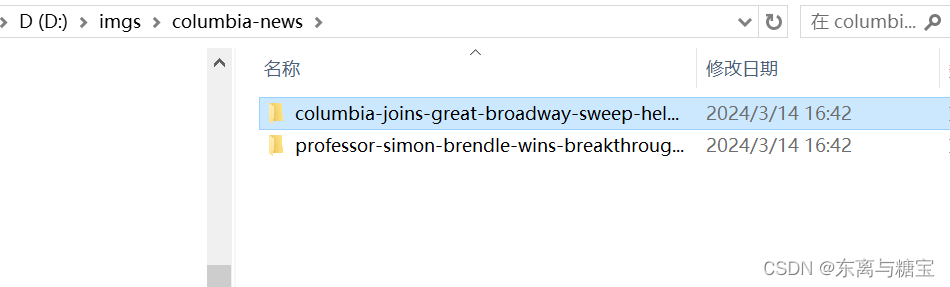

相关文章:
初级爬虫实战——哥伦比亚大学新闻
文章目录 发现宝藏一、 目标二、简单分析网页1. 寻找所有新闻2. 分析模块、版面和文章 三、爬取新闻1. 爬取模块2. 爬取版面3. 爬取文章 四、完整代码五、效果展示 发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不…...
【JS】深度学习JavaScript
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录文章:【JS】深度学习JavaScript 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 一:JavaScript1.1 JavaScript是什么1.2 JS的引入方式1.3 JS变量1.4 数据类型1.5 …...
云原生相关知识
一、kubernetes 1 概述 Kubernetes(也称 k8s 或 “kube”)是一 个开源的容器编排平台,可以自动完成在部署、管理和扩展容器化应用过程中涉及的许多手动操作。 我们常说的编排的英文单词为 “Orchestration”,它常被解释…...
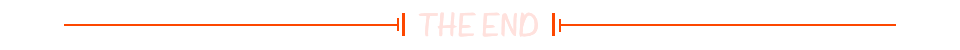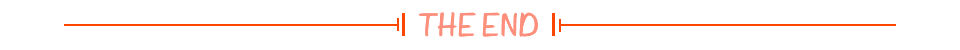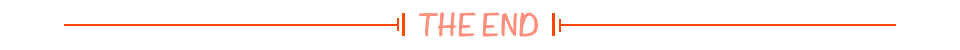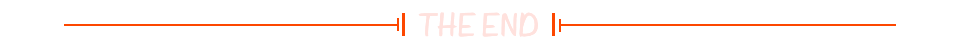
【多线程】有了解过 CAS 和原子操作吗?
SueWakeup 个人主页:SueWakeup 系列专栏:学习Java 个性签名:人生乏味啊,我欲令之光怪陆离 本文封面由 凯楠📷 友情赞助! 目录 前言 悲观锁和乐观锁 什么是 CAS ? 什么是原子操作? CAS 执行流…...

Linux 服务升级:Nginx 热升级 与 平滑回退
目录 一、实验 1.环境 2.Kali Linux 使用nmap扫描CentOS 3.Kali Linux 远程CentOS 4.Kali Linux 使用openvas 扫描 CentOS 5.Nginx 热升级 6.Nginx 平滑回退 二、问题 1.kill命令的信号有哪些 2.平滑升级与回退的信号 一、实验 1.环境 (1)主机…...

能降低嵌入式系统功耗的三个技术
为电池寿命设计嵌入式系统已经成为许多团队重要的设计考虑因素。优化电池寿命的能力有助于降低现场维护成本,并确保客户不需要不断更换或充电电池,从而获得良好的产品体验。 团队通常使用一些标准技术来提高电池寿命,例如将处理器置于低功耗…...

暴力快速入门强化学习
强化学习算法的基本思想(直觉) 众所周知,强化学习是能让智能体实现某个具体任务的强大算法。 强化学习的基本思想是让智能体跟环境交互,通过环境的反馈让智能体调整自己的策略,从反馈中学习,不断学习来得到…...

vue中v-if和v-show的区别
手段:v-if是动态的向DOM树内添加或者删除DOM元素;v-show是通过设置DOM元素的display样式属性控制显隐;编译过程:v-if切换有一个局部编译/卸载的过程,切换过程中合适地销毁和重建内部的事件监听和子组件;v-s…...
MATLAB绘图
现学现用,用时再学。 plot函数:有两个向量被指定为参数,plot(x,y) 会生成 y 对 x 的图形 添加轴标签和标题: 通过调用一次 plot,多个 x-y 对组参数会创建多幅图形: 在每十个数据点处放置标记: 一个窗口绘制多个图形; 可在弹窗的插入选项上添加…...

嵌入式学习-ARM-Day4
嵌入式学习-ARM-Day4 实现三个LED灯亮灭 .text .global _start _start: 使能GPIOE的外设时钟 RCC_MP_AHB4ENSETR的第[4]设置为1即可使能GPIOE时钟 LED1 LDR R0,0X50000A28 指定寄存器地址 LDR R1,[R0] 将寄存器原来的数值读取出来,保存到R1中 ORR R1,R1,#(0x…...

MySQL 中的事务和存储引擎
目录 事务的 ACID 特性 MySQL 的四种隔离机制和问题 MySQL 的四种隔离机制: MySQL 的存储引擎 InnoDB 存储引擎 MyISAM 存储引擎 Memory 存储引擎 通过 ALTER TABLE 语句更改存储引擎 在创建表时指定存储引擎 通过修改配置文件设置默认存储引擎 在数据库系…...
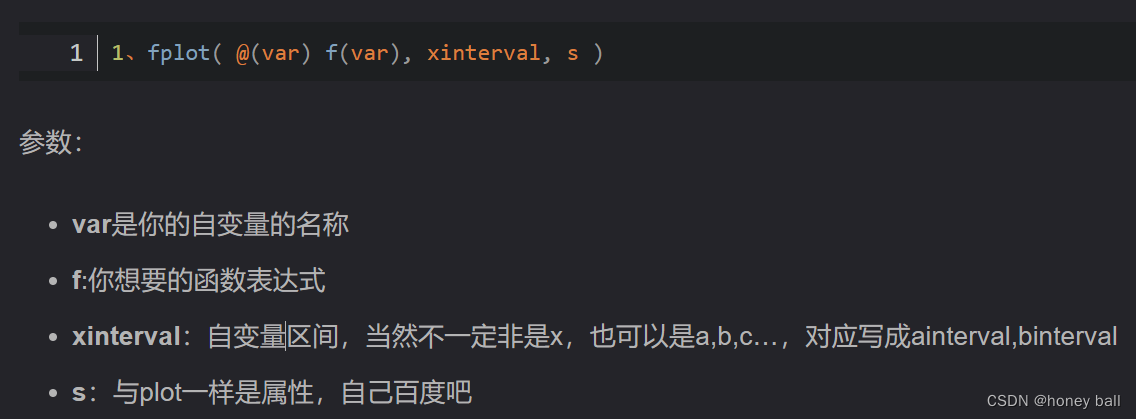
echarts多个折线图共用一个x轴和tooltip组件
实现效果 根据接口传来的数据,使用echarts绘制出,共用一个x轴的图表 功能:后端将所有数据传送过来,前端通过监听选中值来展示对应的图表数据 数据格式: 代码: <template><div><div clas…...

wireshark数据捕获实验简述
Wireshark是一款开源的网络协议分析工具,它可以用于捕获和分析网络数据包。是一款很受欢迎的“网络显微镜”。 实验拓扑图: 实验基础配置: 服务器: ip:172.16.1.88 mask:255.255.255.0 r1: sys sysname r1 undo info enable in…...

如何利用RunnerGo简化性能测试流程
在软件开发过程中,测试是一个重要的环节,需要投入大量时间和精力来确保应用程序或网站的质量和稳定性。但是,随着应用程序变得更加复杂和庞大,传统的测试工具在面对比较繁琐的项目时非常费时费力。这时,一些自动化测试…...

继承和深拷贝封装
继承和深拷贝封装 今日目标: 1.es5寄生组合式继承 2.es6类的继承 3.深拷贝函数封装 00-回顾 # 不同数据类型赋值时的区别: 基本数据类型,赋的就是值,相互之间不再有任何影响 引用数据类型,赋的是地址,…...
《定时执行专家》:Nircmd 的超级搭档,解锁自动化新境界
目录 Nircmd 简介 《定时执行专家》与 Nircmd 的结合 示例: 自动清理电脑垃圾: 定时发送邮件: 定时关闭电脑: 《定时执行专家》的优势: 总结: 以下是一些其他使用示例: 立即下载《定时执行专家》: Nircmd 官方网站: 更…...

Android 封装的工具类
文章目录 日志封装类-MyLog线程封装类-LocalThreadPools自定义进度条-LoadProgressbar解压缩类-ZipUtils本地数据库类-MySQLiteHelper访问webservice封装-HttpUtilsToolbar封装类-MaterialToolbar网络请求框架-OkGo网络请求框架-OkHttp 日志封装类-MyLog 是对android log的封装…...
linux下线程分离属性
linux下线程分离属性 一、线程的属性---分离属性二、线程属性设置2.1 线程创建前设置分离属性2.2 线程创建后设置分离属性 一、线程的属性—分离属性 什么是分离属性? 首先分离属性是线程的一个属性,有了分离属性的线程,不需要别的线程去接合…...

Leetcode 208. 实现 Trie (前缀树)
心路历程: 一道题干进去了一个下午,单纯从解题角度可以直接用python的集合就很简单地解决(不知道是不是因为python底层的set()类)。后来从网上看到这道题应该从前缀树的角度去做,于是花了半个多小时基于字典做了前缀树…...
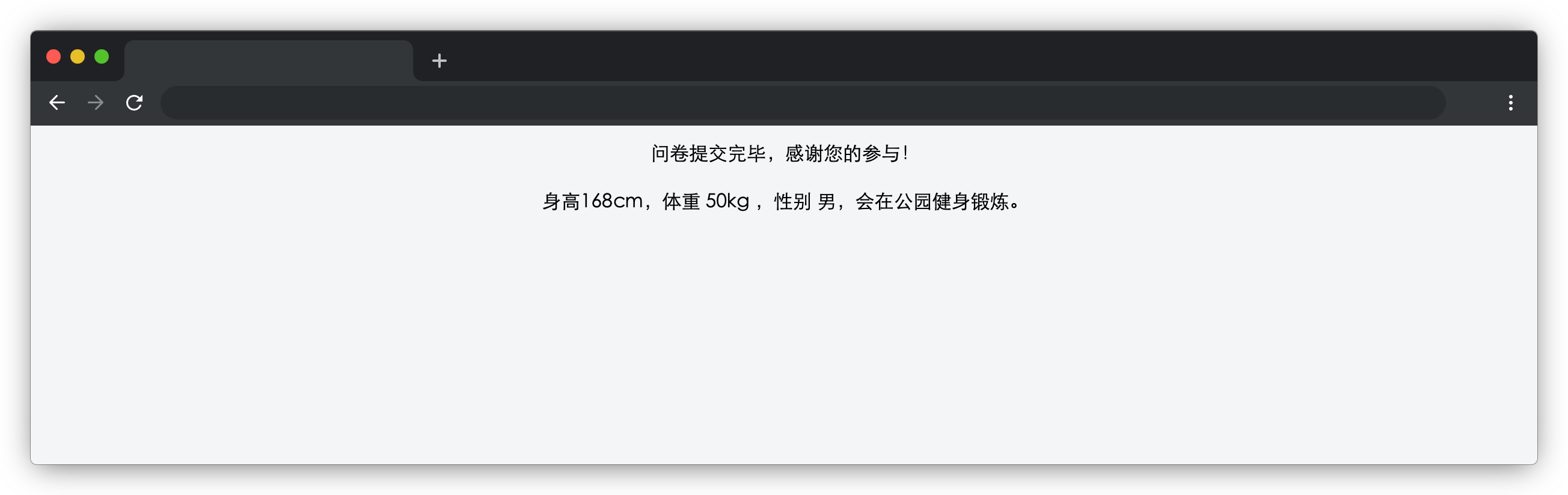
蓝桥杯练习题——健身大调查
在浏览器中预览 index.html 页面效果如下: 目标 完成 js/index.js 中的 formSubmit 函数,用户填写表单信息后,点击蓝色提交按钮,表单项隐藏,页面显示用户提交的表单信息(在 id 为 result 的元素显示&#…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

在数据预处理与分析流水线中集成大模型API进行智能标注与摘要
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据预处理与分析流水线中集成大模型API进行智能标注与摘要 对于数据工程师而言,处理海量非结构化文本数据是一项常见…...

Python爬虫避坑手册:10年爬取经验总结,看完再也不会被封IP
做爬虫这么多年,我见过太多新手从入门到放弃,不是因为学不会Python,而是被各种反爬机制虐得怀疑人生。 我刚入行的时候,写的第一个爬虫是爬某电商网站的商品价格。当时觉得爬虫不就是发个请求,解析个HTML吗?结果代码刚跑了5分钟,IP就被封了。我当时还傻乎乎地重启路由器…...

CVE-2026-35397深度解析:Jupyter Server路径遍历漏洞,CVSS 8.8高危威胁数据科学全生态
一、引言:数据科学基础设施的"心脏出血" Jupyter生态是全球数据科学与AI开发领域的事实标准,据Stack Overflow 2026年开发者调查显示,超过87%的数据科学家和AI工程师日常使用Jupyter Notebook/Lab进行代码开发、数据分析和模型训练…...

突破百度网盘速度壁垒:Python直链解析工具的技术实现与应用
突破百度网盘速度壁垒:Python直链解析工具的技术实现与应用 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享的时代,百度网盘作为国内主流…...