MySQL索引剖析【了解背后的数据结构】
文章目录
- 常用索引概念
- 聚簇索引 🎉
- 非聚簇索引(二级索引)
- 数据结构选择
- Hash结构 ⭐️
- 有序数组
- 二叉搜索树
- AVL树(平衡二叉搜索树)
- B-Tree(多路平衡查找树)
- B+Tree ⭐️
- MySQL中索引的实现
- InnoDB 索引实现
- 首先,一个简单的索引
- 迭代两次:多个目录项纪录的页
- 迭代三次:目录项记录页的目录页
- MyISAM 索引实现
- InnoDB 和 MyISAM 对比
MySQL官方对索引的定义为:索引是帮助MySQL高效获取数据的数据结构。
即索引是数据结构,可以简单的理解为“排好序的快速查找数据结构”,满足特定查找算法,这些数据结构以某种方式指向数据。索引的作用相当于图书的目录,可以根据目录中的页码快速查找到所需的内容。
在MySQL中,索引是在存储引擎中实现的,先在索引中找到对应值,然后根据匹配的索引记录找到对应的行。首先,我们需要花5分钟搞懂MySQL存储引擎
常用索引概念
聚簇索引 和 非聚簇索引(二级索引)是数据库中的两种索引类型,他们在组织和存储数据时有不同的方式。
聚簇索引 🎉
聚簇索引,简单点理解就是将数据与索引放到了一起,找到索引也就是找到了数据。对于聚簇索引来说,它的非叶子节点上存储的是索引字段的值,而它的叶子节点上存储的是这条记录的数据。

在InnoDB中,聚簇索引指的是按照每张表的主键构建的一种索引方式,它是将表数据按照主键的顺序存储在磁盘上的一种方式。这种索引方式保证了行的物理存储顺序与主键的逻辑顺序相同,因此查找聚簇索引的速度非常快。
如果我们在表结构中没有定义主键,那怎么办呢?
其实,数据库中的每行记录中,除了保存了我们自己定义的一些字段以外,还有一些重要的 db_row_id字段,其实他就是一个数据库帮我添加的隐藏主键,如果我们没有给这个表创建主键,会选择一个不为空的唯一索引来作为聚簇索引,但是如果没有合适的唯一索引,那么会以这个隐藏主键来创建聚簇索引。

非聚簇索引(二级索引)
非聚簇索引,就是将数据与索引分开存储,叶子节点存储着指向数据页数据行的逻辑指针。

在Innodb中,非聚簇索引(Non-clustered Index)是指根据非主键字段创建的索引,也就是通常所说的二级索引。它不影响表中数据的物理存储顺序,而是单独创建一张索引表,用于存储索引列和对应行的指针。
在InnoDB中,主键索引就是聚簇索引,而非主键索引,就是非聚簇索引,所以在InnoDB中:
- 对于聚簇索引来说,他的非叶子节点上存储的是索引值,而它的叶子节点上存储的是整行记录。
- 对于非聚簇索引来说,他的非叶子节点上存储的都是索引值,而它的叶子节点上存储的是主键的值+索引值。
所以,通过非聚簇索引的查询,需要进行一次回表,就是先查到主键ID,在通过ID查询所需字段。
数据结构选择
从MySQL的角度讲,不得不考虑一个现实问题那就是 磁盘IO,也就是数据页从磁盘加载至内存。如果我们能让索引的数据结构尽少的减少IO次数,那对于查询的时间消耗也是最小的。

首先说明下MySQL的索引主要是基于Hash表或者B+树~
Hash结构 ⭐️
Hash 本身是一个算法,相同的输入永远可以得到相同的输出。
数据结构定义为:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。具有以下特点:
- Key-Value存储结构,查询的复杂度为O(1)
- 无法用于范围查询、模糊、排序情景
- 当数据量过大时,容易发生Hash冲突
Hash索引适用存储引擎如表所示:
| 索引/存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| Hash索引 | 不支持 | 不支持 | 支持 |
Hash结构效率高,那为什么索引结构要设计成树型呢?
- 首先,Hash 索引仅能满足等值查找(=、!=、in)。如果进行范围查询,时间复杂度会退化至O(n),而树型的“有序”特性,依然能够保持O(log2N)的高效率。
- 其次,hash表中数据是无序的,在进行 order by 时,需要对数据重新排序。
- 最后,当数据量过大时,Hash冲突较多,需要遍历桶中行指针来进行一一比较,消耗了大量性能。

上图中,hash函数有可能将两个不同的关键字映射到相同的位置,这叫做 hash冲突(hash碰撞) ,在数据库中一般采用 链接法 来解决。在链接法中,将散列到同一槽位的元素放在一个链表中。

InnoDB支持 自适应Hash索引
另外,InnoDB本身虽然不支持Hash索引,但是提供 自适应Hash索引。在InnoDB中,如果某个数据经常被访问,当满足一定条件的时候,就会将这个数据页的地址存放到Hash表中。在下次同样查询条件的时候,就可以直接找到这个页所在位置,这样B+树也具备了Hash索引的优点。

我们可以通过 innodb_adaptive_hash_index 变量来查看是否开启了自适应 Hash,比如:
mysql> show variables like '%innodb_adaptive_hash_index';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| innodb_adaptive_hash_index | ON |
+----------------------------+-------+
1 row in set (0.06 sec)
有序数组
数组中的数据是按关键字 升序(或降序)排列的,具有以下特征:
- 更新代价大,插入和删除操作需要移动大量数据。当数据个数不确定时,难以确定存储空间的容量
- 无须为表示线性表中数据之间的逻辑关系而增加额外的存储空间。通过二分法,时间复杂度为(O(logN))查找,适用于等值,范围查找
class Solution {public int search(int[] nums, int target) {int l = 0;int r = nums.length;while(l <= r) {int i = (r-l)/2;if(nums[i] == target) {return i;} else if (nums[i] > target) {r = i;} else if (nums[i] < target) {l = i ;}}return -1;}
}
二叉搜索树
如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。为什么这样说呢,我们先来看看二叉树的特征:
- 一个节点只能有两个子节点,并且子节点也为二叉树;
- 若它的左子树不空,则左子树上所有节点的值均小于它根节点的值;
- 若它的右子树不空,则右子树上所有节点的值均大于它根节点的值。
搜索某个节点和插入节点的规则一样,我们假设插入的数值为key
- 如果 key 大于 当前节点,则在右子树中进行查找;
- 如果 key 小于 当前节点,则在左子树中进行查找;
- 如果 key 等于 当前节点,返回当前节点即可。
举个例子,我们以数列(34, 22, 89, 5, 23, 77, 91)构造一棵二叉搜索树如下图,此时查询某个值,我们仅需io 3次即可

但是在深度比较大时,比如我们给出的数据顺序是(5, 22, 23, 34, 77, 89, 91),如下图。此时性能已经退化成链表一致,时间复杂度为O(n)

为了提高查询效率,就需要 减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量 降低树的高度 ,需要把原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。
AVL树(平衡二叉搜索树)
为了防止二叉树像一个「链表」一样存在,于是在 1962 年,一个姓 AV 的大佬(G. M. Adelson-Velsky) 和一个姓 L 的大佬( Evgenii Landis)提出「平衡二叉树」(AVL) 。奇特性为:任何一个节点的左子树或者右子树都是「平衡二叉树」(左右高度差小于等于 1)

我们发现如上图五层仅能存储31节点,如果使用平衡三叉树仅需四层即可,那M叉呢?我们需要把树再变的"矮胖"些!

B-Tree(多路平衡查找树)
B树中所有节点的孩子个数的最大值称为B树的阶,用m表示。一颗m阶B树是一颗空树或者是符合一系列条件的m叉树。具有以下特征:
- m阶B树,每个节点最多有m棵子树,那么该节点最多有m-1个关键字(元素);(m阶是代表每个节点最多有m个分支/子树)
- 根节点要么没有子树,要么至少有两个子树;
- 除根节点外,其它非叶子节点至少有m/2(向上取整)棵子树,也就是至少有 【m/2(向上取整)-1 】个关键字;
- 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它;
- 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同;
- 在 B 树中,节点存储的是键值和对应的数据
- 内部节点包含一组键值和指向子节点的指针
- 叶子节点包含键值和对应的数据

如图是一棵 3 阶的 B 树。我们可以看下磁盘块 2,里面的关键字为(8,12),它有 3 个孩子 (3,5),(9,10) 和 (13,15)。我们发现(3,5) 小于 8,(9,10) 在 8 和 12 之间,而 (13,15) 大于 12,完全符合刚才我们给出的特征。
然后我们来看下如何用 B 树进行查找。假设我们想要 查找的关键字是 9 ,那么步骤可以分为以下几步:
-
我们与根节点的关键字 (26,35)进行比较,9 小于 26 那么得到指针 P1;
-
按照指针 P1 找到磁盘块 2,关键字为(8,12)。因为 9 在 8 和 12 之间,所以我们得到指针 P2;
-
按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
B 树相比于平衡二叉树来说磁盘 I/O 操作要少 ,在数据查询中比平衡二叉树效率要高。所以只要树的高度足够低,IO次数足够少,就可以提高查询性能 。
但是我们发现B 树的非叶子节点和叶子节点都存储数据,导致每个磁盘块能够容纳的键值对数量较少。除此之外,由于数据分布在内部节点和叶子节点上,执行范围查询时需要在多个层级上进行搜索和遍历。在执行顺序访问操作时需要进行多次随机磁盘访问。
B+Tree ⭐️
B+树是B树的一些变形,它具有以下特点:
- m阶B+树,每个分支节点最多有m叉(与B树相同);
- 根节点要么没有子树,要么至少有两个子树(与B树相同);
- 除根节点外,其它每个分支节点至少有m/2(向上取整)棵子树;
- 有n棵子树的节点恰好有n个关键字(B树是有n-1个关键字才有n个节点);
- 所有内部节点中仅包含它的各个子节点中最大关键字和指向子节点的指针。
- 所有叶子节点包含全部关键字和记录数据,而且叶子节点按关键字大小顺序排列。并将所有叶子节点链接起来⭐️;

MySQL中索引的实现
InnoDB 索引实现
接下来通过推演的方式讲解 InnoDB中的索引实现
页和记录的关系
CREATE TABLE index_demo(c1 INT,c2 INT,c3 CHAR(1),PRIMARY KEY(c1)
) ROW_FORMAT = C
我们新建了 index_demo 表,表中有2个INT类型的列,1个CHAR(1)类型的列,并且设定c1列为主键。指定 compact 行格式来实际存储记录的。为了便于理解,简化了index_demo表的行格式示意图:

-
record_type :记录头信息的一项属性,表示记录的类型。
0表示普通记录1表示B+树非叶节点记录2表示最小记录3表示最大记录。
-
next_record:它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。(下面示意图中我们用
箭头来表明下一条记录是谁)
-
各个列的值 :这里只记录在 index_demo 表中的三个列,分别是 c1 、 c2 和 c3 。
-
其他信息 :除了上述3种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息
那将记录格式示意图的其他信息项暂时去掉并把它竖起来的效果就是这样

它们在页中是这样(为了便于理解,我们示意图中每页仅3条记录):

我们知道的,数据页是InnoDB存储引擎中用于存储数据的基本单位。它是磁盘上的一个连续区域,通常大小为16KB(可以通过配置修改)。意味着每次读写都是以16KB为单位的,一次磁盘到内存的读取是16KB,一次从内存到磁盘的持久化也是16KB。

首先,一个简单的索引
在不设置索引之前根据某个搜索条件查找一些记录时为什么要遍历所有的数据页呢?因为各个页中的记录并没有规律,我们并不知道我们的搜索条件匹配哪些页中的记录,所以不得不依次遍历所有的数据页。
现在我们建立一个目录用于快速定位数据页,如同下图

以 页28 为例,它对应 目录项2 ,这个目录项中包含着该页的页号 28 以及该页中用户记录的最小主键值 5 。我们只需要把几个目录项在物理存储器上连续存储(比如:数组),就可以实现根据主键值快速查找某条记录的功能了。比如:查找主键值为 20 的记录,具体查找过程分两步:
-
先从目录项中根据 二分法 快速确定出主键值为 20 的记录在 目录项3 中(因为 12 < 20 < 209 ),它对应的页是 页9 。
-
再根据前边说的在页中查找记录的方式去 页9 中定位具体的记录。
至此,针对数据页做的简易目录就搞定了。这个目录有一个别名,称为 索引 。
那我们把前边使用到的目录项放到数据页中的样子就是这样(假设只能存储4条目录项记录)

我们新分配了一个编号为30的页来专门存储目录项记录。目录项记录 和 普通的用户记录 是有些不同的
- 两者的record_type 不同,目录项记录的 record_type 值是1,而 普通用户记录 的 record_type 值是0。
- 目录项记录只有 主键值和页的编号 两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列 ,另外还有InnoDB自己添加的隐藏列。
除此之外,记录头信息里还有一个叫 min_rec_mask 的属性,当前记录是目录项页中主键值最小时值是为1,其他记录该值都是 0 。
迭代两次:多个目录项纪录的页

如上图,我们插入了一条主键值为320的新记录,此时前三个用于存储记录的页容量已满(前边假设只能存储3条数据记录),需要新生成页31用于存储该用户记录。此时,原先存储目录项记录的 页30的容量已满 (前边假设只能存储4条目录项记录),所以不得不需要一个新的 页32 来存放 页31 对应的目录项。
此时我们再查找主键值为20的用户记录大致需要3个步骤
- 首先需要确定目录项记录页,根据 二分法 快速确定出在 主键值为20的记录页的目录项页30(因为 1 < 20 < 320 )
- 再通过目录项页 确定用户记录真实所在的页 9(因为 12 < 20 < 209 )
- 在真实存储用户记录的页中定位到具体的记录
迭代三次:目录项记录页的目录页

我们生成了一个存储更高级目录项的 页33 ,这个页中的两条记录分别代表页30和页32,如果用户记录的主键值在 [1, 320) 之间,则到页30中查找更详细的目录项记录,如果主键值 不小于320 的话,就到页32中查找更详细的目录项记录。
嗯哼,有没有人发现类似于某种数据结构了嘛?
没错,那就是 B+ 树。B+树的每个节点都对应着一个数据页,包括根节点、非叶子节点和叶子节点。B+树通过节点之间的指针连接了不同层级的数据页,从而构建了一个有序的索引结构。
-
B+树的非叶子节点对应着数据页,其中存储着主键+指向子节点(即其他数据页)的指针。
-
B+树的叶子节点包含实际的数据行,每个数据行存储在一个数据页中。
通过B+树的搜索过程,可以从根节点开始逐层遍历,最终到达叶子节点,找到所需的数据行所在的数据页。而数据页是存储数据行的实际物理空间,以页为单位进行磁盘读写操作。
一般情况下,我们用到的B+树都不会超过4层 ,因为以上为了便于理解我设定了非常极端的假设:存放用户记录的页 最多存放3条记录 ,存放目录项记录的页 最多存放4条记录 。其实真实环境中一个页存放的记录数量是非常大的,假设所有存放用户记录的叶子节点代表的数据页可以存放 100条用户记录 ,所有存放目录项记录的内节点代表的数据页可以存放 1000条目录项记录 ,那么:
- 如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放 100 条记录;
- 如果B+树有2层,最多能存放 1000×100=10,0000 条记录;
- 如果B+树有3层,最多能存放 1000×1000×100=1,0000,0000 条记录。
- 如果B+树有4层,最多能存放 1000×1000×1000×100=1000,0000,0000 条记录。请问,咱们的表里能存放10亿条记录嘛?
通过这种方式,InnoDB利用B+树和数据页的组合,实现了高效的数据存储和检索。B+树提供了快速的索引查找能力,而数据页提供了实际存储和管理数据行的机制。它们相互配合,使得InnoDB能够处理大规模数据的高效访问。
MyISAM 索引实现
MyISAM是采用了一种索引和数据分离的存储方式,也就是说,MyISAM中索引文件和数据文件是独立的。

因为文件独立,所以在MyISAM的索引树中,叶子节点上存储的并不是数据,而是数据所在的地址。所以,MyISAM 存储引擎实际上不支持聚簇索引的概念。在 MyISAM 中,所有索引都是非聚簇索引。
也就是说,在MyISAM中,根据索引查询的过程中,必然需要先查到数据所在的地址,然后再查询真正的数据,那么就需要有两次查询的过程。而在InnoDB中,如果基于聚簇索引查询,则不需要回表,因为叶子节点上就已经包含数据的内容了。
因为MyISAM是先出的,正式因为存在这个问题,所以后来的InnoDB 引入了聚簇索引的概念提高了数据检索的效率,特别是对于主键检索。
InnoDB 和 MyISAM 对比
首先,MyISAM的索引方式都是非聚簇的,与InnoDB包含1个主键聚簇索引。
- InnoDB存储引擎中,我们只需要根据主键值对 聚簇索引 进行一次查找就能找到对应的记录,而在MyISAM 中却需要进行一次 回表 操作 。
- InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是 分离的 ,索引文件仅保存数据记录的地址。
- InnoDB的非聚簇索引data域存储相应记录 主键的值 ,而MyISAM索引记录的是 地址 。换句话说,InnoDB的所有非聚簇索引都引用主键作为data域。
- MyISAM的回表操作是十分 快速 的,因为是拿着地址偏移量直接到文件中取数据的,反观InnoDB是通过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问。
- InnoDB要求表 必须有主键 ( MyISAM可以没有 )。如果没有显式指定,则MySQL系统会自动选择一个可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。

相关文章:
MySQL索引剖析【了解背后的数据结构】
文章目录 常用索引概念聚簇索引 🎉非聚簇索引(二级索引) 数据结构选择Hash结构 ⭐️有序数组二叉搜索树AVL树(平衡二叉搜索树)B-Tree(多路平衡查找树)BTree ⭐️ MySQL中索引的实现InnoDB 索引实…...

004——内存映射(基于鸿蒙和I.MAX6ULL)
目录 一、 ARM架构内存映射模型 1.1 页表项 1.2 一级页表映射过程 1.3 二级页表映射过程 1.4 cache 和 buffer 二、 鸿蒙内存映射代码学习 三、 为板子编写内存映射代码 3.1 内存地址范围 3.2 设备地址范围 一、 ARM架构内存映射模型 (以前我以为页表机制…...
150 Linux C++ 通讯架构实战6 服务器程序目录规划,makefile编写
从无到有产生这套 通讯架构源代码【项目/工程】 一,服务器程序目录规划 一个完整的项目 肯定会有多个源文件,头文件,会分别存放到多个目录; 我们这里要规划项目的目录结构; 注意:不固安是目录还是文件&am…...

OpenCV支持哪些类型的文件格式读写?
OpenCV支持多种类型的文件格式读写,包括但不限于以下格式: Windows位图文件:包括BMP和DIB格式。JPEG文件:支持JPEG、JPG和JPE三种扩展名。便携式网络图片:即PNG格式。便携式图像格式:包括PBM、PGM和PPM三种…...

数据库中使用IN操作效率问题
1. IN操作的基本概念 IN操作符在SQL中用于指定某个字段的值是否匹配列表中的任何值。这是一个条件操作符,用于在WHERE子句中过滤记录。 SQL语法示例: SELECT * FROM table_name WHERE column_name IN (value1, value2, ...); 2. IN操作的效率问题 当…...

unity学习(67)——控制器Joystick Pack方向
1.轮盘直接复制一个拖到右边就ok了,轮盘上是有脚本的。(只复制) 2.上面的显示窗也可以复制,但是要绑定对应的轮盘(unity中修改变量),显示窗上是有脚本的。(复制改变量) 3…...
MATLAB的使用(一)
一,MATLAB的编程特点 a,语法高度简化; b,脚本式解释型语言; c,针对矩阵的高性能运算; d,丰富的函数工具箱支持; e,通过matlab本体构建跨平台; 二,MATLAB的界面 工具栏:提供快捷操作编辑器…...

JMeter并发工具的使用
视频地址:Jmeter安装教程01_Jmeter之安装以及环境变量配置_哔哩哔哩_bilibili 一、JMeter是什么 JMeter是一款免安装包,官网下载好后直接解压缩并配置好环境变量就可以使用。 环境变量配置可参考:https://www.cnblogs.com/liulinghua90/p/…...
基于springboot+vue的毕业就业信息管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

有什么小程序适合个人开发?
在这个信息爆炸的时代,小程序已经成为了我们生活中的一部分。无论是出行、购物还是娱乐,小程序都能为我们提供便捷的服务。对于个人开发者来说,开发一个小程序不仅可以锻炼自己的技术能力,还可以为他人提供便利,甚至有…...
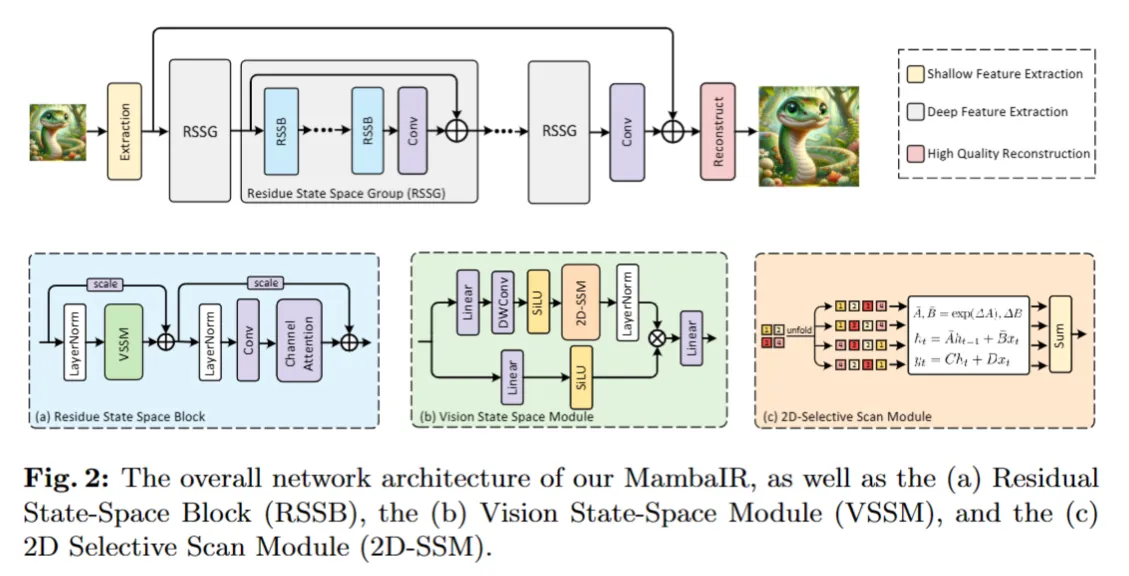
【ARXIV2402】MambaIR
这个工作首次将 Mamba 引入到图像修复任务,关于为什么 Mamba 可以用于图像修复,作者有非常详细的解释:一路向北:性能超越SwinIR!MambaIR: 基于Mamba的图像复原基准模型 作者认为Mamba可以理解为RNN和CNN的结合…...

【计算机网络篇】数据链路层(3)差错检测
文章目录 🥚误码🍔两种常见的检错技术⭐奇偶校验⭐循环冗余校验🎈例子 🥚误码 误码首先介绍误码的相关概念 🍔两种常见的检错技术 ⭐奇偶校验 奇校验是在待发送的数据后面添加1个校验位,使得添加该校验…...

软件配置管理计划
1. 配置管理目标 本软件配置管理计划的目标在于确保软件开发生命周期内的所有配置项(CI)都得到适当的标识、控制、版本管理和追踪。通过实施有效的配置管理,我们的目标是: 保持配置项的一致性和完整性。确保配置项的可追溯性。减…...

嵌入式备考错题汇总
若某条无条件转移汇编指令采用直接寻址,则该指令的功能是将指令中的地址码送入()。 A.PC(程序计数器) B.AR(地址寄存器) C.AC(累加器) D.ALU(算术逻辑运算单元) 解析:选A,直接寻址是指操作数存放在内存单元中,指令中直接给出操作数所在存储单…...

38 mars3d 对接地图图层 绘制点线面员
前言 这里主要是展示一下 mars3d 的一个基础的使用 主要是设计 接入地图服务器的 卫星地图, 普通的二维地图, 增加地区标记 基础绘制 点线面园 等等 测试用例 <template><div style"width: 1920px; height:1080px;"><div class"mars3dClas…...

什么是Webhook 和 HTTP Endpoint?
Webhook 和 HTTP Endpoint 都是基于HTTP协议的网络通信概念,但它们在使用场景和目的上有所不同。 Webhook Webhook 是一种允许一个应用程序提供实时信息给其他应用程序的方法,这种通信是基于HTTP的“回调”或“钩子”。Webhook 通常被用来在一种服务上…...

小程序跨端组件库 Mpx-cube-ui 开源:助力高效业务开发与主题定制
Mpx-cube-ui 是一款基于 Mpx 小程序框架的移动端基础组件库,一份源码可以跨端输出所有小程序平台及 Web,同时具备良好的拓展能力和可定制化的能力来帮助你快速构建 Mpx 应用项目。 Mpx-cube-ui 提供了灵活配置的主题定制能力,在组件设计开发阶…...

GDC期间LayaAir启动全球化战略
3 月 18 日至 3 月 22 日,一年一度的游戏开发者大会(GDC)在美国旧金山举行。在此期间,Layabox宣布LayaAir引擎启动全球扩张战略,这标志着引擎将步入快速发展的新阶段。此举旨在利用公司先进的3D引擎技术,将…...
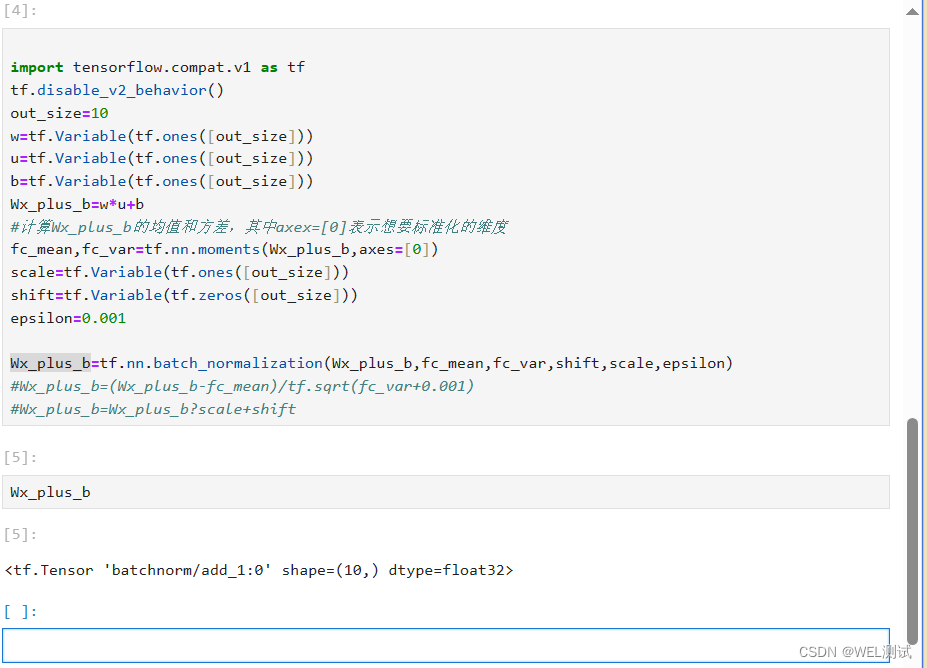
人工智能之Tensorflow批标准化
批标准化(Batch Normalization,BN)是为了克服神经网络层数加深导致难以训练而诞生的。 随着神经网络的深度加深,训练会越来越困难,收敛速度会很慢,常常会导致梯度消失问题。梯度消失问题是在神经网络中,当前…...
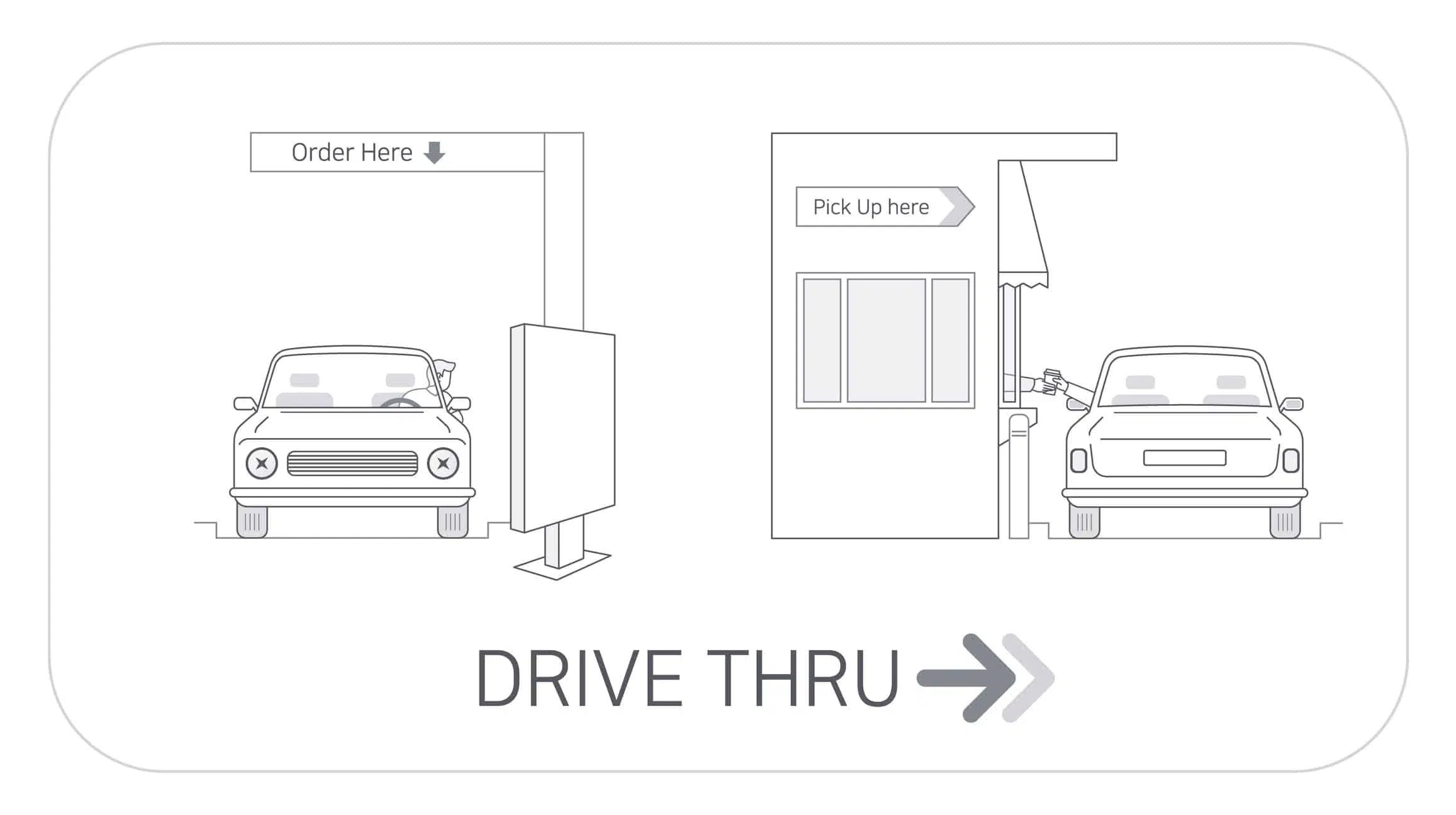
自动化的免下车服务——银行、餐厅、快餐店、杂货店
如果您在20世纪70年代和2020年分别驾车经过免下车服务餐厅(汽车穿梭餐厅),您会发现,唯一的不同是排队的车型。50多年来,免下车技术一直为我们提供着良好的服务,但现在也该对它进行现代化改造了。 乘着AI和自…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...

独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本 对于独立开发者或学生而言,在构建AI应用原型时&…...

3步精通WaveTools:鸣潮全场景性能优化终极指南
3步精通WaveTools:鸣潮全场景性能优化终极指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 开源优化工具WaveTools作为《鸣潮》玩家必备的性能调校助手,通过深度配置优化实现画质…...

监控摄像头小众场景爆发,融合类产品成新蓝海
随着户外运动热潮的持续和物联网技术的全面落地,打猎相机市场在2025年迎来了真正的爆发期,并在2026年继续向智能化、网联化深度演进。根据最新的行业监测数据,2025年全球消费类IPC(网络摄像机)出货量突破1.92亿台&…...

从伪加密ZIP到RSA解密:手把手带你复现BUUCTF那道ACTF新生赛Crypto题
从伪加密ZIP到RSA解密:手把手带你复现BUUCTF那道ACTF新生赛Crypto题 当你第一次接触CTF密码学题目时,面对一个看似普通的ZIP压缩包和一堆加密参数,很容易感到无从下手。本文将带你完整复现BUUCTF平台上那道经典的ACTF新生赛Crypto题目&#x…...

量子机器学习在时间序列预测中的表现:一项基准研究的深度解析
1. 项目概述与核心问题 时间序列预测,这个听起来有点学术的词,其实离我们并不远。从明天股市的涨跌,到下周的天气变化,再到工厂里一台机器的故障预警,背后都离不开对历史数据的分析和未来趋势的推断。在经典计算领域&a…...
从PointNet到Transformer:聊聊‘参数共享’这个省内存又提性能的炼丹技巧
从PointNet到Transformer:参数共享如何重塑深度学习效率 在深度学习模型日益复杂的今天,算法工程师们不断面临一个核心矛盾:如何在保持模型性能的同时,有效控制参数规模?当我们处理点云、序列或图结构这类不规则数据时…...