Python爬虫之urllib库
1、urllib库的介绍
可以实现HTTP请求,我们要做的就是指定请求的URL、请求头、请求体等信息
urllib库包含如下四个模块
- request:基本的HTTP请求模块,可以模拟请求的发送。
- error:异常处理模块。
- parse:工具模块:如拆分、解析、合并
- robotparse:主要用来识别网站的rebots.txt文件。(用的较少)
2、发送请求
2.1、urlopen
urllib.request模块提供了基本的构造HTTP请求的方法,可以模拟浏览器的请求发起过程,同时还具有处理授权验证(Authentication)、重定向(Redireaction)、浏览器Cookie以及一些其他功能。
import urllib.requestresponse = urllib.request.urlopen('https://www.baidu.com')
print(response.read().decode('utf-8'))
print(type(response)) #输出响应的类型 HTTPResponse类型
print(response.status) #输出响应的状态码 200
print(response.getheaders()) #输出响应的头信息
print(response.getheader('Server')) #调用getheader方法,传参server得其值2.1.1、data参数
data参数是可选的。在添加该参数时,需要使用bytes方法将参数转化为字节流编码格式的内容,即bytes类型。如果传递了这个参数,那么它的请求方式就不再是GET,而是POST。
import urllib.parse
import urllib.request# www.httpbin.org可以提供HTTP请求测试
data = bytes(urllib.parse.urlencode({'name':'germey'}),encoding='utf-8')
response = urllib.request.urlopen('https://www.httpbin.org/post',data=data)
print(response.read().decode('utf-8'))# {..."form":{"name":"germey"...}}表明是模拟表单提交
# 这里传递了一个参数name,值是germey,需要将其转码成bytes类型。转码时采用了bytes方法,该方法的第一个参数得是str类型,因此用urllib.parse模块李的urlencode方法将字典参数转化为字符串;第二个参数用于指定编码格式。2.1.2、timeout参数
timeout参数用于设置超时时间,单位为秒,意思是如果请求超出了设置的这个时间,还没有得到响应,就会抛出异常。如果不指定该参数,则会使用全局默认时间。这个参数支持HTTP、HTTPS、FTP请求。
import urllib.requestresponse = urllib.request.urlopen('https://www.httpbin.org/get',timeout=0.1)
print(response.read())# urllib.error.URLError: <urlopen error timed out> 超时
# 通过设置此超时时间,实现当一个网页长时间未响应时,跳过对它的抓取。2.1.3、其他参数
- context参数,该参数必须是ss1.SSLContext类型,用来指定SSL的设置。
- cafile和capath这两个参数分别用来指定CA证书和其路径,这两个在请求HTTPS链接会有用
- cadefault参数已经弃用,默认值为False
2.2、Request
通过构造Request类型的对象,一方面可以将请求独立成一个对象,另一方面可更加丰富灵活的配置参数。
import urllib.requestrequest = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))构造方法:
class urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)- 第一个参数 url用于请求URL,这是必传参数,其他都是可选参数。
- 第二个参数data如果要传参数,必须是bytes类型的。如果数据是字典,先用urllib.parse模块里的urlencode方法进行编码。
- 第三个参数headers是一个字典这就是请求头,构造请求时,既可以通过headers参数直接狗仔此项,也可以通过调用请求实例的add_header方法添加。
- 添加请求头最常见的方法就是修改User-Agent来伪装成浏览器。默认为Python-usrllib。若伪装成火狐浏览器,则设置User-Agent为:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36
- 第四个参数origin_req_host值的是请求方的host名称或IP地址。
- 第五个参数unverifiable表示请求是否是无法验证的,默认为False,意思是用户没有足够的权限来接受这个请求的结果。
- 第六个参数method是一个字符串,用来指示请求使用的方法,例:GET、POST、PUT等。
2.3、高级用法
各种处理器Handler。会有各种Handler子类继承BaseHandler类:
- HTTPDefaultErrorHandler用来处理HTTP响应错误,所以错误类型都会抛出HTTPRrror类型的异常。
- HTTPRedirectHandler用于处理重定向。
- HTTPCookieProcessor用于处理Cookie。
- ProxyHandler用于设置代理,代理默认为空。
- HTTPPasswordMgr用于管理密码,它维护用户名密码对照表。
- HTTPBasicAuthHandler用于管理认证,比如一个链接在打开时需要认证。
另一个重要类OpenerDirector,简称opener、Opener类可以提供open方法。利用Handler类来构建Opener类。
2.3.1、验证*
# 处理访问时需要用户名密码登录验证的方法。
from urllib.request import HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler,build_opener
from urllib.error import URLErrorusername = 'admin'
password = 'admin'
url = 'https://ssr3.scrape.center/'p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None,url,username,password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)try:result = opener.open(url)html = result.read().decode('utf-8')print(html)
except URLError as e:print(e.reason)# 首先实例化了一个HTTPBasicAuthHandler对象auth_handler,其参数是HTTPPasswordMgrWithDefaultRealm对象,它利用add_password方法添加用户名和密码。这样就建立了用来处理验证的Handler类。2.3.2、代理*
# 添加代理
from urllib.error import URLError
from urllib.request import ProxyHandler,build_openerproxy_handler = ProxyHandler({'http':'http//127.0.0.1:8080','https':'https://127.0.0.1:8080'
})
opener = build_opener(proxy_handler)
try:response = opener.open('https://www.baidu.com')print(response.read().decode('utf-8'))
except URLError as e:print(e.reason)2.3.3、Cookie*
# 1、获取网站的Cookie
import http.cookiejar,urllib.requestcookie = http.cookiejar.CookieJar() # 声明Cookiejar对象,
handler = urllib.request.HTTPCookieProcessor(cookie) # 构建一个handler
opener = urllib.request.build_opener(handler) # 构建opener
response = opener.open('https://www.baidu.com')
for item in cookie:print(item.name + "=" + item.value) # 2、输出文件格式的内容cookie
import urllib.request,http.cookiejarfilename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
# 若要保存LWP格式,修改为
cookie = http.cookiejar.LWPCookieJar(filename)handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)# 3、读取内容、以LWP格式为例:
import urllib.request,http.cookiejarcookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True) # 获取cookie内容
handler = urllib.request.HTTPCookieProcessor(cookie) # 构建handler类和opener类
opener = urllib.request.build_opener(handler)
response = opener.open('https://www.baidu.com')
print(response.read().decode('utf-8'))3、异常处理
urllib库中的error模块定义了由request模块产生的异常。出现问题request则抛出error模块定义的异常。
3.1、URLError
URLError类来自urllib库中的error模块,继承自OSError类,是error异常模块处理的基类,由request模块产生的异常都可以来处理。
具有一个属性reason,返回错误的原因。
from urllib import request,error
try:response = request.urlopen('https://cuiqingcai.com/404')
except error.URLError as e:print(e.reason) # Not Found
# 捕获异常,避免程序中止3.2、HTTPError
HTTPError是URLError的子类,专门来处理HTTP请求的错误,例如认证请求失败等,有三个属性:
- code:返回HTTP状态码。
- reason:返回错误原因。
- headers:返回请求头。
from urllib import request,error
try:response = request.urlopen('https://cuiqingcai.com/404')
except error.HTTPError as e:print(e.reason,e.code,e.headers,sep='\n')# 这里捕获了HTTPError的异常,输出了reason、code和headers属性。
# 有时、reason属性返回的不一定是字符串,也可能是一个对象。4、解析链接-parse模块
urllib库里还提供parse模块,此模块定义了处理URL的标准接口,例如实现URL各部分的抽取、合并以及链接转换。
4.1、urlparse*
该方法可以实现URL的识别和分段。
from urllib.parse import urlparse
result = urlparse('htps://www.baidu.com/index.html;user?id=5#comment')
print(type(result))
print(result)# <class 'urllib.parse.ParseResult'>
# ParseResult(scheme='htps', netloc='www.baidu.com', path='/index.html;user', params='', query='id=5', fragment='comment')
# 解析结果是一个ParseResult类型的对象,包含六部分:scheme、netloc、path、params、query和fragment。urlparse的API用法:
urllib.parse.urlparse(urlstring,scheme='',allow_fragment=True)- urlstring:待解析的URL。
- scheme:默认的协议(例如http或https)。
- allow_fragment:是否忽略fragment。
4.2、urlunparse*
对立方法urlunparse,用于构造URL。接收的参数是一个可迭代对象,其长度必须是6,否则抛出参数数量不足或过多的问题。
from urllib.parse import urlunparsedata = ['https','www.baidu.com','index.html','user','a=6','comment'] #列表类型,也可其它
print(urlunparse(data)) # https://www.baidu.com/index.html;user?a=6#comment
# 成功构造URL4.3、urlsplit*
此方法和urlparse方法相似,不再单独解析params这一部分(params会合并到path中),返回5个结果。
from urllib.parse import urlsplitresult = urlsplit('https://www.baidu.com/index.html;user?id=5#comment')
print(result) # SplitResult(scheme='https', netloc='www.baidu.com', path='/index.html;user', query='id=5', fragment='comment')# 也是一个元组,可以用属性名和索引获取
print(result.scheme,result[0]) # https https4.5、urlunsplit*
将链接各部分组成完整链接。传入的参数为可迭代对象,例如列表、元组,参数长度为5
from urllib.parse import urlunsplitdata = ['https','www.baidu.com','index.html','a=6','comment']
print(urlunsplit(data)) # https://www.baidu.com/index.html?a=6#comment4.6、urljoin
生成链接方法。先提供一个base_url(基础链接)作为第一个参数,将新的链接作为第二个参数。urljoin会解析base_url的scheme、netloc和path这三个内容。
from urllib.parse import urljoinprint(urljoin('https://www.baidu.com','FAQ.html'))
print(urljoin('https://www.baidu.com','https://cuiqingcai.com/FAQ.html'))
print(urljoin('https://www.baidu.com/about.html','https://cuiqingcai.com/FAQ.html'))
print(urljoin('https://www.baidu.com/about.html','https://cuiqingcai.com/FAQ.html?question=2'))
print(urljoin('https://www.baidu.com','https://cuiqingcai.com/FAQ.html/index.php'))
print(urljoin('https://www.baidu.com','?category=2#comment'))
print(urljoin('www.baidu.com','?category=2#comment'))
print(urljoin('www.baidu.com?#comment','?category=2'))#若干新链接不存在base_url中的三项,就予以补充;如果存在就用新链接里的,base_url是不起作用的。 4.7、urlencode
urlencode构造GET请求参数。
from urllib.parse import urlencodeparams = {'name':'germey','age':25
}
base_url = 'https://www.baidu.com?'
url = base_url + urlencode(params)
print(url) # https://www.baidu.com?name=germey&age=25 成功将字段类型转化为GET请求参数4.8、parse_qs
反序列化。可以将一串GET请求参数转回字典。
from urllib.parse import parse_qsquery = 'name=germy&age=25'
print(parse_qs(query))#{'name': ['germy'], 'age': ['25']}4.9、parse_qsl
将参数转化为由元组组成的列表
from urllib.parse import parse_qslquery = 'name=germy&age=25'
print(parse_qsl(query))# [('name', 'germy'), ('age', '25')]4.10、quote
将内容转化为URL编码格式。当URL中带有中文参数时,有可能导致乱码问题,此时用quote方法可以将中文字符转为URL编码。
from urllib.parse import quotekeyword = '壁纸'
url = 'https://www.baidu.com/?wd=' + quote(keyword)
print(url)# https://www.baidu.com/?wd=%E5%A3%81%E7%BA%B84.11、unquote
进行URL解码
url = https://www.baidu.com/?wd=%E5%A3%81%E7%BA%B8
print(unquote(url))
# https://www.baidu.com/?wd=壁纸5、分析Robots协议
5.1、Robots协议
Robots协议也称作爬虫协议、机器人协议,全名为网**络爬虫排除标准**,用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以!通常叫做robots.txt文件,在网站根目录下。
搜索爬虫在访问一个网站时,先检查这个站点根目录下是否存在robots.txt文件,若存在,则根据其中定义的爬取范围来爬取。若无,则访问能访问到的页面。
# robots.txt文件样例:
# 限定搜索爬虫只能爬取public目录:
User-agent:* # 搜索爬虫名称,*代表此文件对所有爬虫有效
Disallow:/ # 不允许爬虫爬取的目录,/代表不允许爬取所有页面
Allow:/public/ # 允许爬取的页面,和Disallow一起使用,用来排除限制。此表示可爬取public目录# 禁止所有爬虫访问所有目录:
User-agent:*
Disallow:/# 允许所有爬虫访问所有目录: robots.txt文件留空也是可以的
User-agent:*
Disallow:# 禁止所有爬虫访问网站某些目录:
User-agent:*
Disallow:/private/
Disallow:/tmp/# 只允许某一个爬虫访问所有目录:
User-agent:WebCrawler
Disallw:
User-agent:*
Disallw:/5.2、爬虫名称
其实,爬虫有固定名字。例如:
| 爬虫名称 | 网站名称 |
|---|---|
| BaiduSpider | 百度 |
| Googlebot | 谷歌 |
| 360Spider | 369搜索 |
| YodaoBot | 有道 |
| ia_archiver | Alexa |
| Scooter | altavista |
| Bingbot | 必应 |
5.3、rebotparser模块
rebotparser模块解析robots.txt文件。该模块提供一个类RobotFileParser,它可以根据网站的robots.txt文件判断是否有权限爬取。
# 用法:在构造方法里串robots.txt文件链接即可
urllib.rebotparser.RobotFileParser(url='')下面列出RobotFileParser类的几个常用方法:
- set_url:设置tobots.txt的文件链接
- read:读取robots.txt文件进行分析。记得调用,否则接下来的判断都为False
- parse:解析tobots.txt文件
- can_fetch:有两个参数,第一个是User-agent,第二个是要抓取的URL。返回结果True或False。表示User-agent指示的搜索引擎是否可以抓取这个URL
- mtime:返回上次抓取和分析robots.txt文件的时间,这对长时间分析和抓取robots.txt文件的搜索爬虫很有必要。
- modified:对于长时间分析和抓取的搜索爬虫重要,可以将当前时间设置为上次抓取和分析robots.txt文件的时间。
from urllib.robotparser import RobotFileParserrp = RobotFileParser()
rp.set_url('https://www.baidu.com/robots.txt')
rp.read()
print(rp.can_fetch('Baiduspider','https://www.baidu.com')) # True
print(rp.can_fetch('Baiduspider','https://www.baidu.com/homepage/')) # True
print(rp.can_fetch('Googlebot','https://www.baidu.com/homepage/')) # False相关文章:

Python爬虫之urllib库
1、urllib库的介绍 可以实现HTTP请求,我们要做的就是指定请求的URL、请求头、请求体等信息 urllib库包含如下四个模块 request:基本的HTTP请求模块,可以模拟请求的发送。error:异常处理模块。parse:工具模块&#x…...

Docker学习笔记 - 常用命令
目录 基本概念常用命令使用docker compose启动脚本创建自己的image Docker命令文档 1. 下载一个image 从hub.docker.com下载一个image。 docker pull [image name]下载时指定image的tag。 docker pull [image name]:<tag>举例,下载postgre的tag为alpine…...
)
数学建模(Topsis python代码 案例)
目录 介绍: 模板: 案例: 极小型指标转化为极大型(正向化): 中间型指标转为极大型(正向化): 区间型指标转为极大型(正向化): 标准化处理: 公式: Topsis(优劣解距离法): 公式: 完整代码: 结果: 介绍: 在数学建模中,Topsis方法是一种多准则决策分…...

gateway网关指定路由响应超时时间
gateway网关指定路由响应超时时间 spring:cloud:gateway:httpclient:responseTimeout: 10000这个配置用于设置HttpClient的响应超时时间,单位是毫秒。具体来说,这个配置表示当Gateway向后端服务发出请求后,如果在10秒内没有收到后端服务的响…...
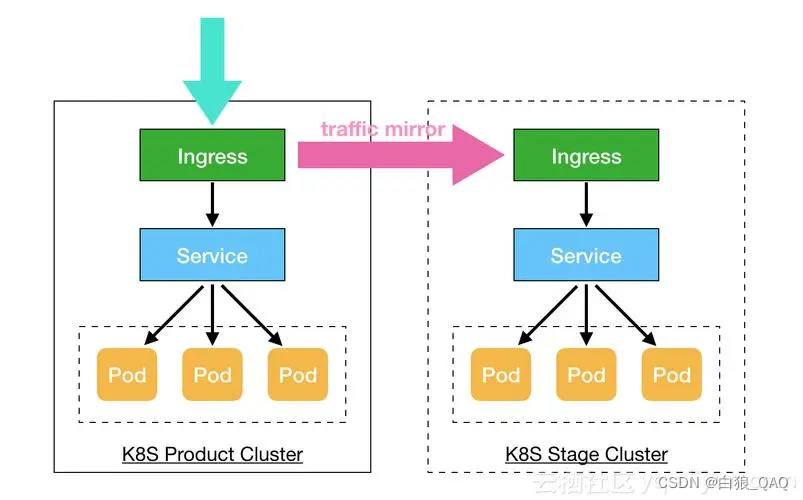
docker 和K8S知识分享
docker知识: 比如写了个项目,并且在本地调试没有任务问题,这时候你想在另外一台电脑或者服务器运行,那么你需要在另外一台电脑或者服务器配置相同的软件,比如数据库,web服务器,必要的插件和库等…...

MySQL--select count(*)、count(1)、count(列名) 的区别你知道吗?
MySQL select count(*)、count(1)、count(列名) 的区别? 这里我们先给出正确结论: count(*),包含了所有的列,会计算所有的行数,在统计结果时候,不会忽略列值为空的情况。count(1),忽略所有的列…...

使用verilog设计实现16位CPU及仿真
这是一个简单的16位CPU(中央处理单元)的设计实验。这个CPU包括指令存储器、数据存储器、ALU(算术逻辑单元)、寄存器文件和控制单元。 设计一个简单的16位CPU的实验通常可以分为以下几个步骤: 指令集设计:首先确定CPU支持的指令集架构,包括指令格式、寄存器组织、地址模…...
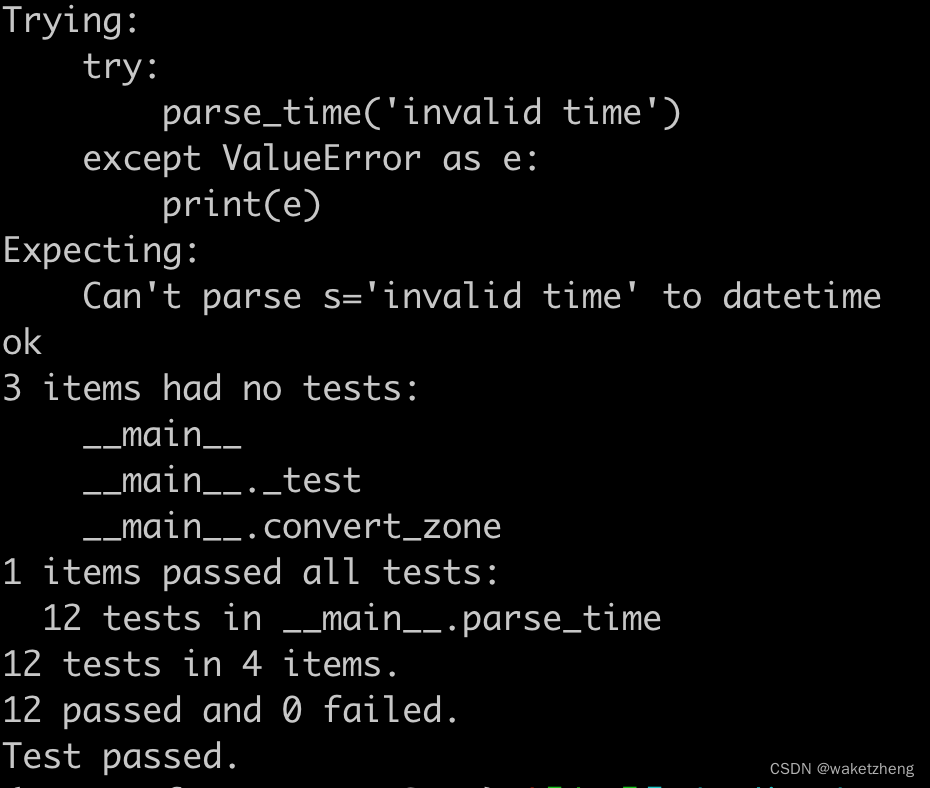
Python将字符串转换为datetime
有这样一些字符串: 1710903685 20240320110125 2024-03-20 11:01:25 要转换成Python的datetime 代码如下: import functools import re from datetime import datetime, timedelta from typing import Union# pip install python-dateutil from date…...

Vue 3 + TypeScript + Vite的现代前端项目框架
随着前端开发技术的飞速发展,Vue 3、TypeScript 和 Vite 构成了现代前端开发的强大组合。这篇博客将指导你如何从零开始搭建一个使用Vue 3、TypeScript以及Vite的前端项目,帮助你快速启动一个性能卓越且类型安全的现代化Web应用。 Vue 3 是一款渐进式Jav…...

浏览器强缓存和弱缓存的主要区别
浏览器强缓存与弱缓存 浏览器的缓存机制主要分为两种:强缓存与协商缓存(也称弱缓存)。 强缓存 强缓存是指浏览器在请求一个资源时,不与服务器发生通信,直接从本地缓存中获取资源。如果存在有效的强缓存,…...

深度学习-2.9梯度不稳定和Glorot条件
梯度不稳定和Glorot条件 一、梯度消失和梯度爆炸 对于神经网络这个复杂系统来说,在模型训练过程中,一个最基础、同时也最常见的问题,就是梯度消失和梯度爆炸。 我们知道,神经网络在进行反向传播的过程中,各参数层的梯…...

地宫取宝dfs
分析: 矩阵里的每一个位置都有标记,要求的问题是:有几种方法能完成这个规定。 那么,我们只需要计算从开始(1,1)到最后(n,m)的深度优先搜索中,有几个是满足要求的即为正确答案。 有个要求是,如果一个格子中…...

Ollama 运行 Cohere 的 command-r 模型
Ollama 运行 Cohere 的 command-r 模型 0. 引言1. 安装 MSYS22. 安装 Golang3. Build Ollama4. 运行 command-r 0. 引言 Command-R Command-R 是一种大型语言模型,针对对话交互和长上下文任务进行了优化。它针对的是“可扩展”类别的模型,这些模型在高…...

2024年C语言最新经典面试题汇总(11-20)
C语言文章更新目录 C语言学习资源汇总,史上最全面总结,没有之一 C/C学习资源(百度云盘链接) 计算机二级资料(过级专用) C语言学习路线(从入门到实战) 编写C语言程序的7个步骤和编程…...

arm linux应用程序crash分析一般方法
目录: 前言一、定位问题的基本方法论1.1 生产环境下系统崩溃的日志信息示例 二、 分析这类什么都没有的app crash的一般方法论:附录:附录1 pmap -p 进程PID 查看进程的内存分配情况附录2 cat /proc/pid/maps 总结 前言 linux的应用程序app开…...

Web安全防护技术解决方案
1、防止爆破 限制请求ip访问次数,超过设定访问次数后,拒绝访问或锁定N分钟后可再次请求 2、调用短信验证码时 加入验证码采用防爆破策略 3、上传后的文件防止被猜出爬取 保存在物理磁盘可进行加密防护文件不能存储在站点目录,防止通过ur…...
流畅的 Python 第二版(GPT 重译)(十一)
第二十章:并发执行器 抨击线程的人通常是系统程序员,他们心中有着典型应用程序员终其一生都不会遇到的用例。[…] 在 99%的用例中,应用程序员可能会遇到的情况是,生成一堆独立线程并将结果收集到队列中的简单模式就是他们需要了解…...
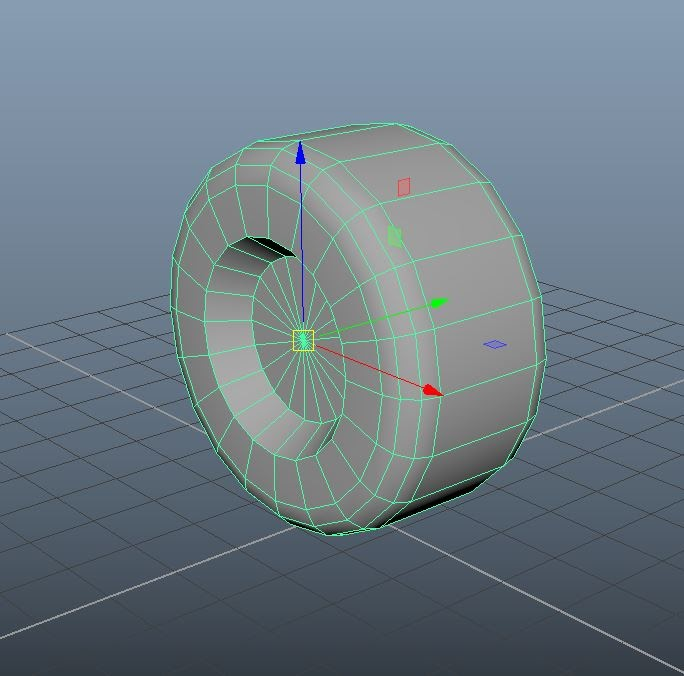
Blender 3D建模要点
3d模型可以为场景的仿真模拟带来真实感,它还有助于更轻松地识别场景中的所有内容。 例如,如果场景中的所有对象都是简单的形状,如立方体和圆形,则很难在仿真中区分对象。 1、碰撞形状与视觉形状 像立方体和球体这样的简单形状&a…...
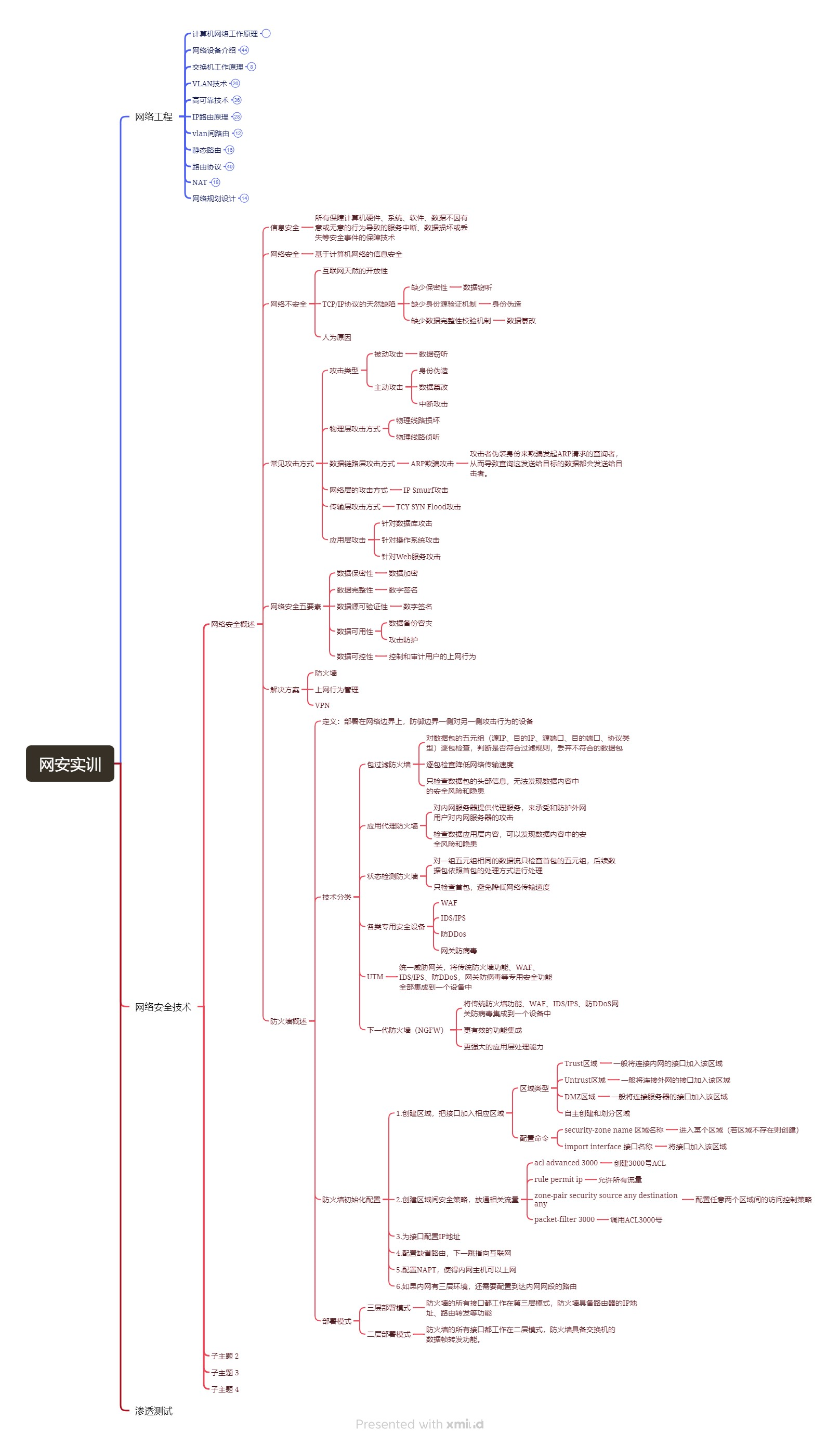
网络安全实训Day8
写在前面 网络工程终于讲完了。这星期到了网络安全技术部分。 网络安全实训-网络安全技术 网络安全概述 信息安全:所有保障计算机硬件、系统、软件、数据不因有意或无意的行为导致的服务中断、数据损坏或丢失等安全事件的保障技术 网络安全:基于计算机…...

GB28181 —— 5、C++编写GB28181设备端,完成将USB摄像头视频实时转发至GB28181服务并可播放(附源码)
被测试的USB摄像头 效果 源码说明 主要功能模拟设备端,完成注册、注销、心跳等,同时当服务端下发指令播放视频时 设备端实时读取USB摄像头视频并通过OpenCV处理后实时转ps格式后封包rtp进行推送给服务端播放。 源码 /****@remark: pes头的封装,里面的具体数据的填写已经占…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

统信UOS浏览器书签同步难题?一招搞定所有新用户默认书签配置
统信UOS浏览器书签批量配置:系统管理员的高效部署指南在企业或教育机构的IT运维工作中,统信UOS作为国产操作系统的代表,其浏览器书签的统一管理常常成为系统管理员面临的挑战。想象一下,每当有新员工入职或学生入学,都…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

AutoPentest:面向红队的渗透测试决策引擎架构解析
1. 这不是又一个“自动化扫描器”,而是一套能替你做决策的渗透测试工作流引擎AutoPentest这个名字,第一眼容易让人联想到Nmap加个for循环、或者Burp Suite里点几下Intruder——但实际用过的人很快会意识到:它根本不在同一个维度上。我第一次在…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...