MySQL表内容的增删查改
在前面几章的内容中我们学习了数据库的增删查改,表的增删查改,这一篇我们来学习一下对表中的内容做增删查改。
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
1.创建Create
我们先创建一张表
mysql> create table student(-> id int unsigned primary key auto_increment,-> sn int unique comment '学号',-> name varchar(20) not null,-> qq varchar(20)-> );
Query OK, 0 rows affected (0.01 sec)
1.1 单行插入
- 全列插入
mysql> insert into student values(100, 10000, '张三', null);
Query OK, 1 row affected (0.00 sec)mysql> insert into student values(101, 10001, '李四', null);
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+-----+-------+--------+------+
| id | sn | name | qq |
+-----+-------+--------+------+
| 100 | 10000 | 张三 | NULL |
| 101 | 10001 | 李四 | NULL |
+-----+-------+--------+------+
2 rows in set (0.00 sec)
这里的into是可以省略的。
-
指定列插入
数量必须和指定列数量及顺序一致
mysql> insert into student(sn, name) values(10002, '王五');
Query OK, 1 row affected (0.00 sec)mysql> insert into student(sn, name) values(10003, '赵六');
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+-----+-------+--------+------+
| id | sn | name | qq |
+-----+-------+--------+------+
| 100 | 10000 | 张三 | NULL |
| 101 | 10001 | 李四 | NULL |
| 102 | 10002 | 王五 | NULL |
| 103 | 10003 | 赵六 | NULL |
+-----+-------+--------+------+
4 rows in set (0.00 sec)
1.2 多行插入
mysql> insert into student(id, sn, name) values
mysql> (120, 10004, '曹操'),
mysql> (121, 10005, '孙权');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0mysql> select * from student;
+-----+-------+--------+------+
| id | sn | name | qq |
+-----+-------+--------+------+
| 100 | 10000 | 张三 | NULL |
| 101 | 10001 | 李四 | NULL |
| 102 | 10002 | 王五 | NULL |
| 103 | 10003 | 赵六 | NULL |
| 120 | 10004 | 曹操 | NULL |
| 121 | 10005 | 孙权 | NULL |
+-----+-------+--------+------+
6 rows in set (0.00 sec)
1.3 插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败
mysql> insert into student (id, sn, name) values (100, 10010, '张飞');
ERROR 1062 (23000): Duplicate entry '100' for key 'PRIMARY'mysql> insert into student(sn, name) values (10004, '曹阿瞒');
ERROR 1062 (23000): Duplicate entry '10004' for key 'sn'
第一个是主键冲突,第二个是唯一键冲突。
如果我们想插入新的数据,旧的数据不再关心(如果没有直接插入,如果有就更新),并且不会插入失败,那我们可以使用插入否则更新
insert... on duplicate key update 要更新的数据mysql> insert into student (id, sn, name) values (100, 10010, '张飞') on duplicate key update sn=10083, name='张飞';
Query OK, 2 rows affected (0.00 sec)mysql> insert into student(sn, name) values (10004, '曹阿瞒') on duplicate key update sn=10056, name='曹阿瞒';
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+-----+-------+-----------+------+
| id | sn | name | qq |
+-----+-------+-----------+------+
| 100 | 10083 | 张飞 | NULL |
| 101 | 10001 | 李四 | NULL |
| 102 | 10002 | 王五 | NULL |
| 103 | 10003 | 赵六 | NULL |
| 120 | 10012 | 曹操 | NULL |
| 121 | 10005 | 孙权 | NULL |
| 124 | 10004 | 曹阿瞒 | NULL |
+-----+-------+-----------+------+
7 rows in set (0.00 sec)-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新
1.4替换
替换的原理是:
如果主键或者唯一键没有发生冲突,则直接插入,
如果主键或者唯一键发生了冲突,则删除后再次插入
mysql> select * from student;
+-----+-------+-----------+------+
| id | sn | name | qq |
+-----+-------+-----------+------+
| 100 | 10083 | 张飞 | NULL |
| 101 | 10001 | 李四 | NULL |
| 102 | 10002 | 王五 | NULL |
| 103 | 10003 | 赵六 | NULL |
| 120 | 10012 | 曹操 | NULL |
| 121 | 10005 | 孙权 | NULL |
| 124 | 10004 | 曹阿瞒 | NULL |
+-----+-------+-----------+------+
7 rows in set (0.00 sec)mysql> replace into student values(128, 10013, '孙策', null);
Query OK, 1 row affected (0.00 sec)mysql> replace into student values(124, 10014, '曹操', null);
Query OK, 2 rows affected (0.00 sec)mysql> select * from student;
+-----+-------+--------+------+
| id | sn | name | qq |
+-----+-------+--------+------+
| 100 | 10083 | 张飞 | NULL |
| 101 | 10001 | 李四 | NULL |
| 102 | 10002 | 王五 | NULL |
| 103 | 10003 | 赵六 | NULL |
| 120 | 10012 | 曹操 | NULL |
| 121 | 10005 | 孙权 | NULL |
| 124 | 10014 | 曹操 | NULL |
| 128 | 10013 | 孙策 | NULL |
+-----+-------+--------+------+
8 rows in set (0.00 sec)
2.读取Retrieve
我们先创建一个表并插入一些数据
mysql> create table exam_result (-> id int unsigned primary key auto_increment,-> name varchar(20) not null comment '同学姓名',-> chinese float default 0.0 comment '语文成绩',-> math float default 0.0 comment '数学成绩',-> english float default 0.0 comment '英语成绩'-> );
Query OK, 0 rows affected (0.01 sec)mysql> insert into exam_result (name, chinese, math, english) values-> ('唐三藏', 67, 98, 56),-> ('孙悟空', 87, 78, 77),-> ('猪悟能', 88, 98, 90),-> ('曹孟德', 82, 84, 67),-> ('刘玄德', 55, 85, 45),-> ('孙权', 70, 73, 78),-> ('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0
2.1 select 查询
2.1.1全列查询
通常情况下不建议使用 * 进行全列查询
1. 查询的列越多,意味着需要传输的数据量越大;
2. 可能会影响到索引的使用。(索引待后面课程讲解)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)
2.1.2 指定列查询
mysql> select id, name, english from exam_result;
+----+-----------+---------+
| id | name | english |
+----+-----------+---------+
| 1 | 唐三藏 | 56 |
| 2 | 孙悟空 | 77 |
| 3 | 猪悟能 | 90 |
| 4 | 曹孟德 | 67 |
| 5 | 刘玄德 | 45 |
| 6 | 孙权 | 78 |
| 7 | 宋公明 | 30 |
+----+-----------+---------+
7 rows in set (0.00 sec)
2.1.3 查询字段为表达式
查询字段也可以为一个表达式。
mysql> select id, name, chinese+math+english from exam_result;\
+----+-----------+----------------------+
| id | name | chinese+math+english |
+----+-----------+----------------------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+----------------------+
7 rows in set (0.00 sec)
2.1.4 为查询结果指定别名
mysql> select id, name, chinese+math+english 总分 from exam_result;
+----+-----------+--------+
| id | name | 总分 |
+----+-----------+--------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 5 | 刘玄德 | 185 |
| 6 | 孙权 | 221 |
| 7 | 宋公明 | 170 |
+----+-----------+--------+
7 rows in set (0.00 sec)
2.1.5 结果去重distinct
mysql> select * from num;
+------+
| a |
+------+
| 10 |
| 10 |
| 10 |
| 10 |
| 20 |
| 20 |
+------+
6 rows in set (0.00 sec)mysql> select distinct a from num;
+------+
| a |
+------+
| 10 |
| 20 |
+------+
2 rows in set (0.00 sec)2.2where条件判断
- 比较运算符
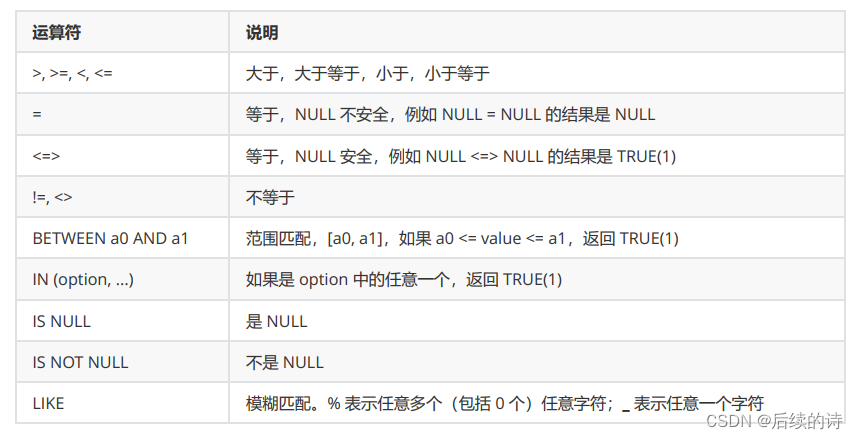
- 逻辑运算符

案例:
- 1.英语不及格的同学及英语成绩 ( < 60 )
select name, english from exam_result where english < 60;
+-----------+--------+
| name | english|
+-----------+--------+
| 唐三藏 | 56 |
| 刘玄德 | 45 |
| 宋公明 | 30 |
+-----------+--------+
3 rows in set (0.01 sec)-
2.语文成绩在 [80, 90] 分的同学及语文成绩
方法一: 使用 AND 进行条件连接
mysql> select name, chinese from exam_result where chinese >= 80 and chinese <= 90;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
3 rows in set (0.00 sec)
方法二: 使用 BETWEEN ... AND ... 条件
mysql> select name, chinese from exam_result where chinese between 80 and 90;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
3 rows in set (0.00 sec)
-
3.数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
方法一: 使用 OR 进行条件连接
mysql> select name, math from exam_result where math=58 or math=59 or math=98 or math=99;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
2 rows in set (0.00 sec)方法二: 使用 IN 条件
mysql> select name, math from exam_result where math in (58,59,98,99);
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
2 rows in set (0.00 sec)
- 4.姓孙的同学 及 孙某同学
% 匹配任意多个(包括 0 个)任意字符
mysql> select name from exam_result where name like '孙%';
+-----------+
| name |
+-----------+
| 孙悟空 |
| 孙权 |
+-----------+
2 rows in set (0.00 sec)
_ 匹配严格的一个任意字符
mysql> select name from exam_result where name like '孙_';
+--------+
| name |
+--------+
| 孙权 |
+--------+
1 row in set (0.00 sec)-
5.语文成绩好于英语成绩的同学
mysql> select name, chinese, english from exam_result where chinese > english;
+-----------+---------+---------+
| name | chinese | english |
+-----------+---------+---------+
| 唐三藏 | 67 | 56 |
| 孙悟空 | 87 | 77 |
| 曹孟德 | 82 | 67 |
| 刘玄德 | 55 | 45 |
| 宋公明 | 75 | 30 |
+-----------+---------+---------+
5 rows in set (0.00 sec)
- 6.总分在 200 分以下的同学
mysql> select name, chinese, math, english, chinese+math+english total from exam_result where total < 200;
ERROR 1054 (42S22): Unknown column 'total' in 'where clause'
别名在where语句中是无法使用的。
主要还是执行顺序不同。
1.执行from
2.执行where语句
3.执行要打印的信息
而别名total是出现在第三步,要打印的信息里面的,第二步的时候还没有出现,所以在where中不能使用total
mysql> select name, chinese, math, english, chinese+math+english total from exam_result where chinese+math+english < 200;
+-----------+---------+------+---------+-------+
| name | chinese | math | english | total |
+-----------+---------+------+---------+-------+
| 刘玄德 | 55 | 85 | 45 | 185 |
| 宋公明 | 75 | 65 | 30 | 170 |
+-----------+---------+------+---------+-------+
2 rows in set (0.00 sec)
- 7.语文成绩 > 80 并且不姓孙的同学
mysql> select name, chinese from exam_result where name not like '孙%' and chinese > 80;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
2 rows in set (0.00 sec)
-
8.NULL 的查询
查询表中qq号不为空的同学
错误示范:
mysql> select * from exam_result;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+--------+
| 1 | 唐三藏 | 67 | 98 | 56 | NULL |
| 2 | 孙悟空 | 87 | 78 | 77 | NULL |
| 3 | 猪悟能 | 88 | 98 | 90 | NULL |
| 4 | 曹孟德 | 82 | 84 | 67 | NULL |
| 5 | 刘玄德 | 55 | 85 | 45 | NULL |
| 6 | 孙权 | 70 | 73 | 78 | NULL |
| 7 | 宋公明 | 75 | 65 | 30 | NULL |
| 8 | 张翼德 | 34 | 84 | 48 | 11111 |
| 9 | 关云长 | 75 | 31 | 84 | 222222 |
+----+-----------+---------+------+---------+--------+
9 rows in set (0.00 sec)mysql> select name, qq from exam_result where qq != null;
Empty set (0.00 sec)
可以看到直接使用!=这种方式是是错误的,因为null是不会参与运算的。where后面的结果就是null。
正确写法:
mysql> select name, qq from exam_result where qq is not null;
+-----------+--------+
| name | qq |
+-----------+--------+
| 张翼德 | 11111 |
| 关云长 | 222222 |
+-----------+--------+
2 rows in set (0.00 sec)
那如果是查询表中qq号为空的同学呢
方法一: <=>
mysql> select name, qq from exam_result where qq <=> null;
+-----------+------+
| name | qq |
+-----------+------+
| 唐三藏 | NULL |
| 孙悟空 | NULL |
| 猪悟能 | NULL |
| 曹孟德 | NULL |
| 刘玄德 | NULL |
| 孙权 | NULL |
| 宋公明 | NULL |
+-----------+------+
7 rows in set (0.00 sec)
方法二: is
mysql> select name, qq from exam_result where qq is null;
+-----------+------+
| name | qq |
+-----------+------+
| 唐三藏 | NULL |
| 孙悟空 | NULL |
| 猪悟能 | NULL |
| 曹孟德 | NULL |
| 刘玄德 | NULL |
| 孙权 | NULL |
| 宋公明 | NULL |
+-----------+------+
7 rows in set (0.00 sec)
方法三:!+ is not
mysql> select name, qq from exam_result where !(qq is not null);
+-----------+------+
| name | qq |
+-----------+------+
| 唐三藏 | NULL |
| 孙悟空 | NULL |
| 猪悟能 | NULL |
| 曹孟德 | NULL |
| 刘玄德 | NULL |
| 孙权 | NULL |
| 宋公明 | NULL |
+-----------+------+
7 rows in set (0.00 sec)
-- NULL 和 NULL 的比较,= 和 <=> 的区别SELECT NULL = NULL, NULL = 1, NULL = 0;
+-------------+----------+----------+
| NULL = NULL | NULL = 1 | NULL = 0 |
+-------------+----------+----------+
| NULL | NULL | NULL |
+-------------+----------+----------+
1 row in set (0.00 sec)SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;
+---------------+------------+------------+
| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |
+---------------+------------+------------+
| 1 | 0 | 0 |
+---------------+------------+------------+
1 row in set (0.00 sec)
2.3 order by排序
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
ASC为升序(从小到大)
DESC为降序(从大到小)
默认为ASC
- 同学及数学成绩,按数学成绩升序显示
mysql> select * from exam_result order by math;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+--------+
| 9 | 关云长 | 75 | 31 | 84 | 222222 |
| 7 | 宋公明 | 75 | 65 | 30 | NULL |
| 6 | 孙权 | 70 | 73 | 78 | NULL |
| 2 | 孙悟空 | 87 | 78 | 77 | NULL |
| 4 | 曹孟德 | 82 | 84 | 67 | NULL |
| 8 | 张翼德 | 34 | 84 | 48 | 11111 |
| 5 | 刘玄德 | 55 | 85 | 45 | NULL |
| 1 | 唐三藏 | 67 | 98 | 56 | NULL |
| 3 | 猪悟能 | 88 | 98 | 90 | NULL |
+----+-----------+---------+------+---------+--------+
9 rows in set (0.00 sec)
- 同学及 qq 号,按 qq 号排序显示
mysql> select name, qq from exam_result order by qq desc;
+-----------+--------+
| name | qq |
+-----------+--------+
| 关云长 | 222222 |
| 张翼德 | 11111 |
| 唐三藏 | NULL |
| 孙悟空 | NULL |
| 猪悟能 | NULL |
| 曹孟德 | NULL |
| 刘玄德 | NULL |
| 孙权 | NULL |
| 宋公明 | NULL |
+-----------+--------+
9 rows in set (0.00 sec)
NULL 视为比任何值都小,降序出现在最下面
- 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
mysql> select name,math,english,chinese from exam_result order by math desc, english asc, chinese asc;
+-----------+------+---------+---------+
| name | math | english | chinese |
+-----------+------+---------+---------+
| 唐三藏 | 98 | 56 | 67 |
| 猪悟能 | 98 | 90 | 88 |
| 刘玄德 | 85 | 45 | 55 |
| 张翼德 | 84 | 48 | 34 |
| 曹孟德 | 84 | 67 | 82 |
| 孙悟空 | 78 | 77 | 87 |
| 孙权 | 73 | 78 | 70 |
| 宋公明 | 65 | 30 | 75 |
| 关云长 | 31 | 84 | 75 |
+-----------+------+---------+---------+
9 rows in set (0.00 sec)
- 查询同学及总分,由高到低
mysql> select name, chinese+math+english total from exam_result order by total desc;
+-----------+-------+
| name | total |
+-----------+-------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 关云长 | 190 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
| 张翼德 | 166 |
+-----------+-------+
9 rows in set (0.00 sec)前面的where语句不能使用别名是因为顺序问题,这里可以使用别名也是因为顺序问题。
执行顺序:
- 找到具体是哪一张表
- where语句
- select要打印的信息
- order by排序
- limit显示n行
2.4筛选分页结果limit
语法:
-- 从 0 开始,筛选 n 条结果
select ... from table_name [where...] [order by ...] limit n;-- 从 s 开始,筛选 n 条结果
select ... from table_name [where...] [order by ...] limit s, n;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
select ... from table_name [where...] [order by ...] limit n offset s;mysql> select * from exam_result;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+--------+
| 1 | 唐三藏 | 67 | 98 | 56 | NULL |
| 2 | 孙悟空 | 87 | 78 | 77 | NULL |
| 3 | 猪悟能 | 88 | 98 | 90 | NULL |
| 4 | 曹孟德 | 82 | 84 | 67 | NULL |
| 5 | 刘玄德 | 55 | 85 | 45 | NULL |
| 6 | 孙权 | 70 | 73 | 78 | NULL |
| 7 | 宋公明 | 75 | 65 | 30 | NULL |
| 8 | 张翼德 | 34 | 84 | 48 | 11111 |
| 9 | 关云长 | 75 | 31 | 84 | 222222 |
+----+-----------+---------+------+---------+--------+
9 rows in set (0.00 sec)
当数据不多的情况下可以全部显示,但是如果数据很多,有几万十几万行,如果全部显示,不但不方便看,而且要耗费很多的资源。
所以我们可以使用limit。
- 从第一含开始
mysql> select * from exam_result limit 5;
+----+-----------+---------+------+---------+------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+------+
| 1 | 唐三藏 | 67 | 98 | 56 | NULL |
| 2 | 孙悟空 | 87 | 78 | 77 | NULL |
| 3 | 猪悟能 | 88 | 98 | 90 | NULL |
| 4 | 曹孟德 | 82 | 84 | 67 | NULL |
| 5 | 刘玄德 | 55 | 85 | 45 | NULL |
+----+-----------+---------+------+---------+------+
5 rows in set (0.00 sec)
- 从中间开始
mysql> select * from exam_result limit 3, 4;
+----+-----------+---------+------+---------+------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+------+
| 4 | 曹孟德 | 82 | 84 | 67 | NULL |
| 5 | 刘玄德 | 55 | 85 | 45 | NULL |
| 6 | 孙权 | 70 | 73 | 78 | NULL |
| 7 | 宋公明 | 75 | 65 | 30 | NULL |
+----+-----------+---------+------+---------+------+
4 rows in set (0.00 sec)mysql> select * from exam_result limit 4 offset 3;
+----+-----------+---------+------+---------+------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+------+
| 4 | 曹孟德 | 82 | 84 | 67 | NULL |
| 5 | 刘玄德 | 55 | 85 | 45 | NULL |
| 6 | 孙权 | 70 | 73 | 78 | NULL |
| 7 | 宋公明 | 75 | 65 | 30 | NULL |
+----+-----------+---------+------+---------+------+
4 rows in set (0.00 sec)建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
3. 更新Update
update table_name set column = expr;直接举个例子:将孙悟空同学的数学成绩变更为 80 分
mysql> update exam_result set math=80 where name='孙悟空';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name, math from exam_result where name='孙悟空';
+-----------+------+
| name | math |
+-----------+------+
| 孙悟空 | 80 |
+-----------+------+
1 row in set (0.00 sec)
- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
mysql> update exam_result set math=60,chinese=70 where name='曹孟德';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name, math, chinese from exam_result where name='曹孟德';
+-----------+------+---------+
| name | math | chinese |
+-----------+------+---------+
| 曹孟德 | 60 | 70 |
+-----------+------+---------+
1 row in set (0.00 sec)
- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
mysql> select * from exam_result order by chinese+math+english limit 3;
+----+-----------+---------+------+---------+-------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+-------+
| 8 | 张翼德 | 34 | 84 | 48 | 11111 |
| 7 | 宋公明 | 75 | 65 | 30 | NULL |
| 5 | 刘玄德 | 55 | 85 | 45 | NULL |
+----+-----------+---------+------+---------+-------+
3 rows in set (0.00 sec)mysql> update exam_result set math=math+30 order by chinese+math+english limit 3;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0mysql> select * from exam_result order by chinese+math+english limit 3;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+--------+
| 9 | 关云长 | 75 | 31 | 84 | 222222 |
| 8 | 张翼德 | 34 | 114 | 48 | 11111 |
| 4 | 曹孟德 | 70 | 60 | 67 | NULL |
+----+-----------+---------+------+---------+--------+
3 rows in set (0.00 sec)
注意:更新全表的语句慎用
4.删除delete
4.1删除数据
delete from table_name [where ...] [order by ...] [limit ...]注意:删除整表操作要慎用
- 删除孙悟空同学的考试成绩
mysql> delete from exam_result where name='孙悟空';
Query OK, 1 row affected (0.00 sec)mysql> select name from exam_result;
+-----------+
| name |
+-----------+
| 唐三藏 |
| 猪悟能 |
| 曹孟德 |
| 刘玄德 |
| 孙权 |
| 宋公明 |
| 张翼德 |
| 关云长 |
+-----------+
8 rows in set (0.00 sec)
4.2删除整张表数据
delete from table_name;
只是将表的数据全部清空,但是还是会存在AUTO_INCREMENT自增长约束(不会随着数据被清空而被置0)再次插入就是在上一次的自增值+1
4.3截断表
truncate [TABLE] table_name1. 只能对整表操作,不能像 delete一样针对部分数据操作;
2. 实际上 MySQL 不对数据操作,所以比 delete更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
3. 会重置 AUTO_INCREMENT 项
5. 插入查询结果
insert into table_name [(column [, column ...])] select ...案例:删除表中的的重复复记录,重复的数据只能有一份
先创建一些数据
mysql> create table duplicate_table(-> id int,-> name varchar(20)-> );
Query OK, 0 rows affected (0.02 sec)mysql> insert into duplicate_table values-> (100, 'a'),-> (100, 'a'),-> (200, 'a'),-> (200, 'b'),-> (200, 'b'),-> (200, 'b'),-> (300, 'c');
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0
去重思路:
- 1.创建一个属性和原表相同的表
mysql> create table no_duplicate_table like duplicate_table;
Query OK, 0 rows affected (0.02 sec)mysql> desc duplicate_table;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)mysql> desc no_duplicate_table;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)- 2.insert+distinct去重后插入新表
mysql> insert into no_duplicate_table select distinct * from duplicate_table;
Query OK, 4 rows affected (0.03 sec)
Records: 4 Duplicates: 0 Warnings: 0mysql> select * from no_duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | a |
| 200 | a |
| 200 | b |
| 300 | c |
+------+------+
4 rows in set (0.00 sec)
- 3.将原表名字改为其他的,将新表名字改为旧表名字
mysql> rename table duplicate_table to old_duplicate_table;
Query OK, 0 rows affected (0.00 sec)mysql> rename table no_duplicate_table to duplicate_table;
Query OK, 0 rows affected (0.01 sec)mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | a |
| 200 | a |
| 200 | b |
| 300 | c |
+------+------+
4 rows in set (0.00 sec)
6.聚合函数

- 1.统计班级共有多少同学
mysql> select * from exam_result;
+----+-----------+---------+------+---------+--------+
| id | name | chinese | math | english | qq |
+----+-----------+---------+------+---------+--------+
| 1 | 唐三藏 | 67 | 98 | 56 | NULL |
| 3 | 猪悟能 | 88 | 98 | 90 | NULL |
| 4 | 曹孟德 | 70 | 60 | 67 | NULL |
| 5 | 刘玄德 | 55 | 115 | 45 | NULL |
| 6 | 孙权 | 70 | 73 | 78 | NULL |
| 7 | 宋公明 | 75 | 95 | 30 | NULL |
| 8 | 张翼德 | 34 | 114 | 48 | 11111 |
| 9 | 关云长 | 75 | 31 | 84 | 222222 |
+----+-----------+---------+------+---------+--------+
8 rows in set (0.00 sec)mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)- 2.统计数学成绩总分
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 684 |
+-----------+
1 row in set (0.00 sec)- 3.统计平均总分
mysql> select avg(chinese+math+english) from exam_result;
+---------------------------+
| avg(chinese+math+english) |
+---------------------------+
| 214.5 |
+---------------------------+
- 4.返回英语最高分
mysql> select max(english) from exam_result;
+--------------+
| max(english) |
+--------------+
| 90 |
+--------------+
1 row in set (0.00 sec)
- 5.返回 > 70 分以上的数学最低分
mysql> select min(math) from exam_result where math>70;
+-----------+
| min(math) |
+-----------+
| 73 |
+-----------+
1 row in set (0.00 sec)
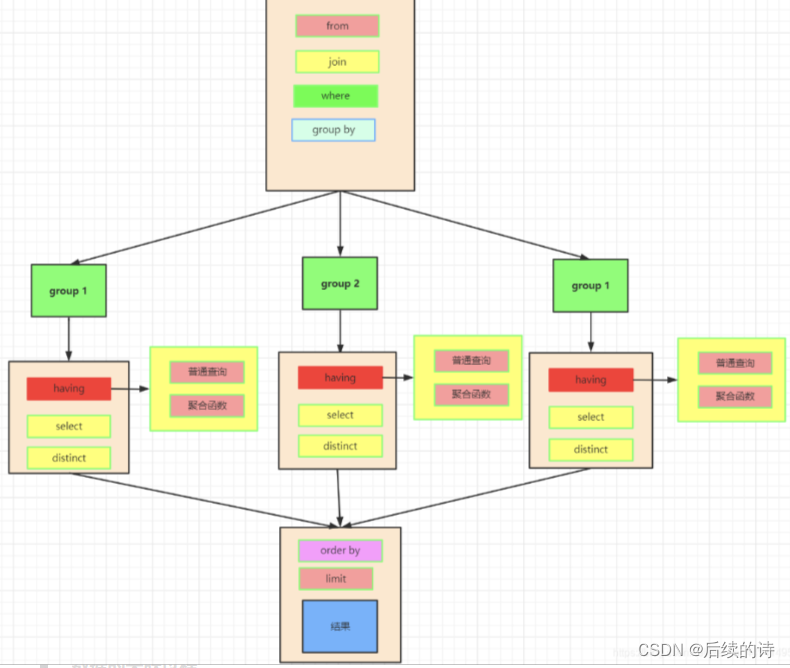
7. group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;准备工作,创建一个雇员信息表
EMP员工表
DEPT部门表
SALGRADE工资等级表
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)mysql> select * from dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)mysql> select * from salgrade;
+-------+-------+-------+
| grade | losal | hisal |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+
5 rows in set (0.00 sec)
- 如何显示每个部门的平均工资和最高工资
我们先试一下找到所有员工中最高工资和平均工资
mysql> select max(sal) 最高, avg(sal) 平均 from emp;
+---------+-------------+
| 最高 | 平均 |
+---------+-------------+
| 5000.00 | 2073.214286 |
+---------+-------------+
1 row in set (0.00 sec)如果想要找到每一组的最高工资和平均工资,就要分组
mysql> select max(sal) 最高, avg(sal) 平均 from emp group by deptno;
+---------+-------------+
| 最高 | 平均 |
+---------+-------------+
| 5000.00 | 2916.666667 |
| 3000.00 | 2175.000000 |
| 2850.00 | 1566.666667 |
+---------+-------------+
3 rows in set (0.00 sec)
- 显示每个部门的每种岗位的平均工资和最低工资
mysql> select deptno, job, avg(sal) 平均, min(sal)最低 from emp group by deptno, job;
+--------+-----------+-------------+---------+
| deptno | job | 平均 | 最低 |
+--------+-----------+-------------+---------+
| 10 | CLERK | 1300.000000 | 1300.00 |
| 10 | MANAGER | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | 5000.000000 | 5000.00 |
| 20 | ANALYST | 3000.000000 | 3000.00 |
| 20 | CLERK | 950.000000 | 800.00 |
| 20 | MANAGER | 2975.000000 | 2975.00 |
| 30 | CLERK | 950.000000 | 950.00 |
| 30 | MANAGER | 2850.000000 | 2850.00 |
| 30 | SALESMAN | 1400.000000 | 1250.00 |
+--------+-----------+-------------+---------+
注意:select后面的字段在group by中必须要出现。
mysql> select deptno, job, ename, avg(sal) 平均, min(sal)最低 from emp group by deptno, job;
ERROR 1055 (42000): Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'scott.emp.ename' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_bymysql> select deptno, job, ename, avg(sal) 平均, min(sal)最低 from emp group by deptno, job, ename;
+--------+-----------+--------+-------------+---------+
| deptno | job | ename | 平均 | 最低 |
+--------+-----------+--------+-------------+---------+
| 10 | CLERK | MILLER | 1300.000000 | 1300.00 |
| 10 | MANAGER | CLARK | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | KING | 5000.000000 | 5000.00 |
| 20 | ANALYST | FORD | 3000.000000 | 3000.00 |
| 20 | ANALYST | SCOTT | 3000.000000 | 3000.00 |
| 20 | CLERK | ADAMS | 1100.000000 | 1100.00 |
| 20 | CLERK | SMITH | 800.000000 | 800.00 |
| 20 | MANAGER | JONES | 2975.000000 | 2975.00 |
| 30 | CLERK | JAMES | 950.000000 | 950.00 |
| 30 | MANAGER | BLAKE | 2850.000000 | 2850.00 |
| 30 | SALESMAN | ALLEN | 1600.000000 | 1600.00 |
| 30 | SALESMAN | MARTIN | 1250.000000 | 1250.00 |
| 30 | SALESMAN | TURNER | 1500.000000 | 1500.00 |
| 30 | SALESMAN | WARD | 1250.000000 | 1250.00 |
+--------+-----------+--------+-------------+---------+
14 rows in set (0.00 sec)
- 显示平均工资低于2000的部门和它的平均工资
可以分为两步:
- 统计各个部门的平均工资
- having和group by配合使用,对group by结果进行过滤
having的作用就是对聚合后的数据进行条件筛选,类似于where。
1.统计各个部门平均工资。
mysql> select deptno, avg(sal) 平均 from emp group by deptno;
+--------+-------------+
| deptno | 平均 |
+--------+-------------+
| 10 | 2916.666667 |
| 20 | 2175.000000 |
| 30 | 1566.666667 |
+--------+-------------+
3 rows in set (0.00 sec)2.having和group by配合使用,对group by结果进行过滤
mysql> select deptno, avg(sal) as myavg from emp group by deptno having myavg<2000;
+--------+-------------+
| deptno | myavg |
+--------+-------------+
| 30 | 1566.666667 |
+--------+-------------+
1 row in set (0.00 sec)
where和having的区别:
- where是对任意列进行条件筛选(筛选之后才会进行分组)
- having是分组聚合之后才会筛选(分组之后才会筛选)
执行顺序:
1.数据来源于哪个表中from
2.对数据进行条件筛选where
3.group up进行分组
4.having条件筛选
5.select进行聚合统计
6.distinct去重
7.order by排序
8.limit得到需要行数
相关文章:
MySQL表内容的增删查改
在前面几章的内容中我们学习了数据库的增删查改,表的增删查改,这一篇我们来学习一下对表中的内容做增删查改。 CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除) 1.创建Create 我们先创建…...

Java的三大特性之一——多态(完)
前言 http://t.csdnimg.cn/0CAuc 在上一篇我们已经详讲了继承特性,在这我们将进行最后一个也是最重要的特性讲解——多态 在讲解之前我们需要具备对向上转型以及方法重写的初步了解,这有助于我们对多态的认识 1.向上转型 即实际就是创建一个子类对象…...
算法-最短路径
图的最短路径问题是一个经典的计算机科学和运筹学问题,旨在找到图中两个顶点之间的最短路径。这种问题在多种场景中都有应用,如网络路由、地图导航等。 解决图的最短路径问题有多种算法,其中最著名的包括: 1.迪杰斯特拉算法 (1).…...
【软考---系统架构设计师】特殊的操作系统介绍
目录 一、嵌入式系统(EOS) (1)嵌入式系统的特点 (2)硬件抽象层 (3)嵌入式系统的开发设计 二、实时操作系统(RTOS) (1)实时性能…...
)
大模型: 提示词工程(prompt engineering)
文章目录 一、什么是提示词工程二、提示词应用1、提示技巧一:表达清晰2、提示词技巧2:设置角色 一、什么是提示词工程 提示词工程主要是用于优化与大模型交互的提示或查询操作,其目的在于能够更加准确的获取提问者想要获取的答案,…...

RabbitMQ的事务机制
想要保证发送者一定能把消息发送给RabbitMQ,一种是通过Confirm机制,另一种就是通过事务机制。 RabbitMQ的事务机制,允许生产者将一组操作打包成一个原子事务单元,要么全部执行成功,要么全部失败。事务提供了一种确保消…...
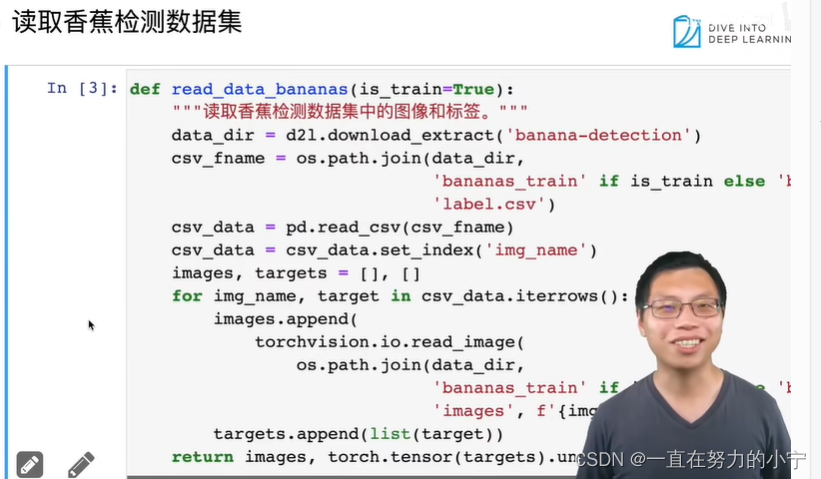
41 物体检测和目标检测数据集【李沐动手学深度学习v2课程笔记】
目录 1. 物体检测 2. 边缘框实现 3.数据集 4. 小结 1. 物体检测 2. 边缘框实现 %matplotlib inline import torch from d2l import torch as d2ld2l.set_figsize() img d2l.plt.imread(../img/catdog.jpg) d2l.plt.imshow(img);#save def box_corner_to_center(boxes):&q…...
)
软件包管理(rpm+yum)
1.介绍软件包安装方式 rpm包安装: rpm是个软件包管理工具,通过.rpm后缀来操作 -i #安装 -q #查询 -l #列出软件包下的文件 -e #卸载 -h, #软件包安装的时候列出哈希标记 (和 -v 一起使用效果更好) -v, #提供更多的详细信息输出 rpm的痛点&#…...

网关层针对各微服务动态修改Ribbon路由策略
目录 一、介绍 二、常规的微服务设置路由算法方式 三、通过不懈努力,找到解决思路 四、验证 五、总结 一、介绍 最近,遇到这么一个需求: 1、需要在网关层(目前使用zuul)为某一个服务指定自定义算法IP Hash路由策…...
)
如何从零开始拆解uni-app开发的vue项目(二)
昨天书写了一篇如何从零开始uni-app开发的vue项目,今天准备写一篇处理界面元素动态加载的案例: 背景:有不同类别的设备,每个设备有每日检查项目、每周检查项目、每年检查项目,需要维保人员,根据不同设备和检查类别对检查项目进行处理,提交数据。 首先看一下界面: &l…...
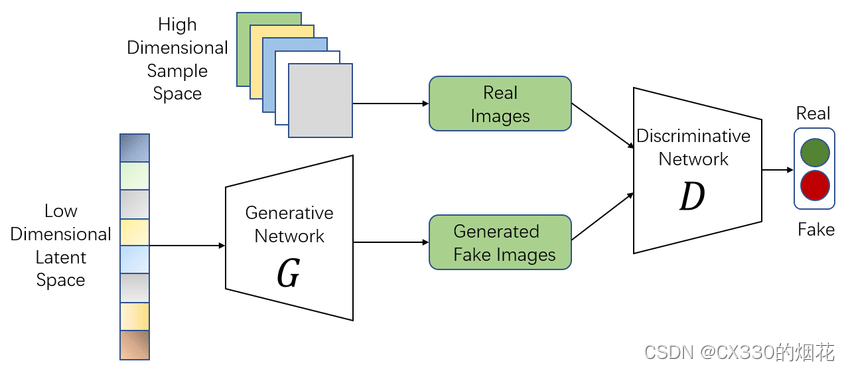
【生成对抗网络GAN】一篇文章讲透~
目录 引言 一、生成对抗网络的基本原理 1 初始化生成器和判别器 2 训练判别器 3 训练生成器 4 交替训练 5 评估和调整 二、生成对抗网络的应用领域 1 图像生成与编辑 2 语音合成与音频处理 3 文本生成与对话系统 4 数据增强与隐私保护 三、代码事例 四、生成对抗…...

【设计模式】Java 设计模式之模板命令模式(Command)
命令模式(Command)的深入分析与实战解读 一、概述 命令模式是一种将请求封装为对象从而使你可用不同的请求把客户端与接受请求的对象解耦的模式。在命令模式中,命令对象使得发送者与接收者之间解耦,发送者通过命令对象来执行请求…...

如何在Flutter中实现一键登录
获取到当前手机使用的手机卡号,直接使用这个号码进行注册、登录,这就是一键登录。 可以借助极光官方的极光认证实现 1、注册账户成为开发者 2、创建应用开通极光认证 (注意开通极光认证要通过实名审核) 3、创建应用获取appkey、 …...

Amazon SageMaker + Stable Diffusion 搭建文本生成图像模型
如果我们的计算机视觉系统要真正理解视觉世界,它们不仅必须能够识别图像,而且必须能够生成图像。文本到图像的 AI 模型仅根据简单的文字输入就可以生成图像。 近两年,以ChatGPT为代表的AIGC技术崭露头角,逐渐从学术研究的象牙塔迈…...

FPGA数字信号处理前沿
生活在这个色彩斑斓的世界里,大家的身边存在太多模拟信号比如光能、电压、电流、压力、声音、流速等。数字信号处理作为嵌入式研发的一个经久不衰热门话题,可以说大到军工武器、航空航天,小到日常仪器、工业控制,嵌入式SOC芯片数字…...

【Android】系统启动流程分析 —— init 进程启动过程
本文基于 Android 14.0.0_r2 的系统启动流程分析。 一、概述 init 进程属于一个守护进程,准确的说,它是 Linux 系统中用户控制的第一个进程,它的进程号为 1,它的生命周期贯穿整个 Linux 内核运行的始终。Android 中所有其它的进程…...

抖音视频批量下载软件可导出视频分享链接|手机网页视频提取|视频爬虫采集工具
解锁抖音视频无水印批量下载新姿势! 在快节奏的生活中,抖音作为时下最热门的短视频平台之一,吸引着广大用户的目光。而如何高效地获取喜欢的视频内容成为了许多人关注的焦点。Q:290615413现在,我们推出的抖音视频批量下载软件&…...

鸿蒙Harmony应用开发—ArkTS-@Observed装饰器和@ObjectLink装饰器:嵌套类对象属性变化
上文所述的装饰器仅能观察到第一层的变化,但是在实际应用开发中,应用会根据开发需要,封装自己的数据模型。对于多层嵌套的情况,比如二维数组,或者数组项class,或者class的属性是class,他们的第二…...
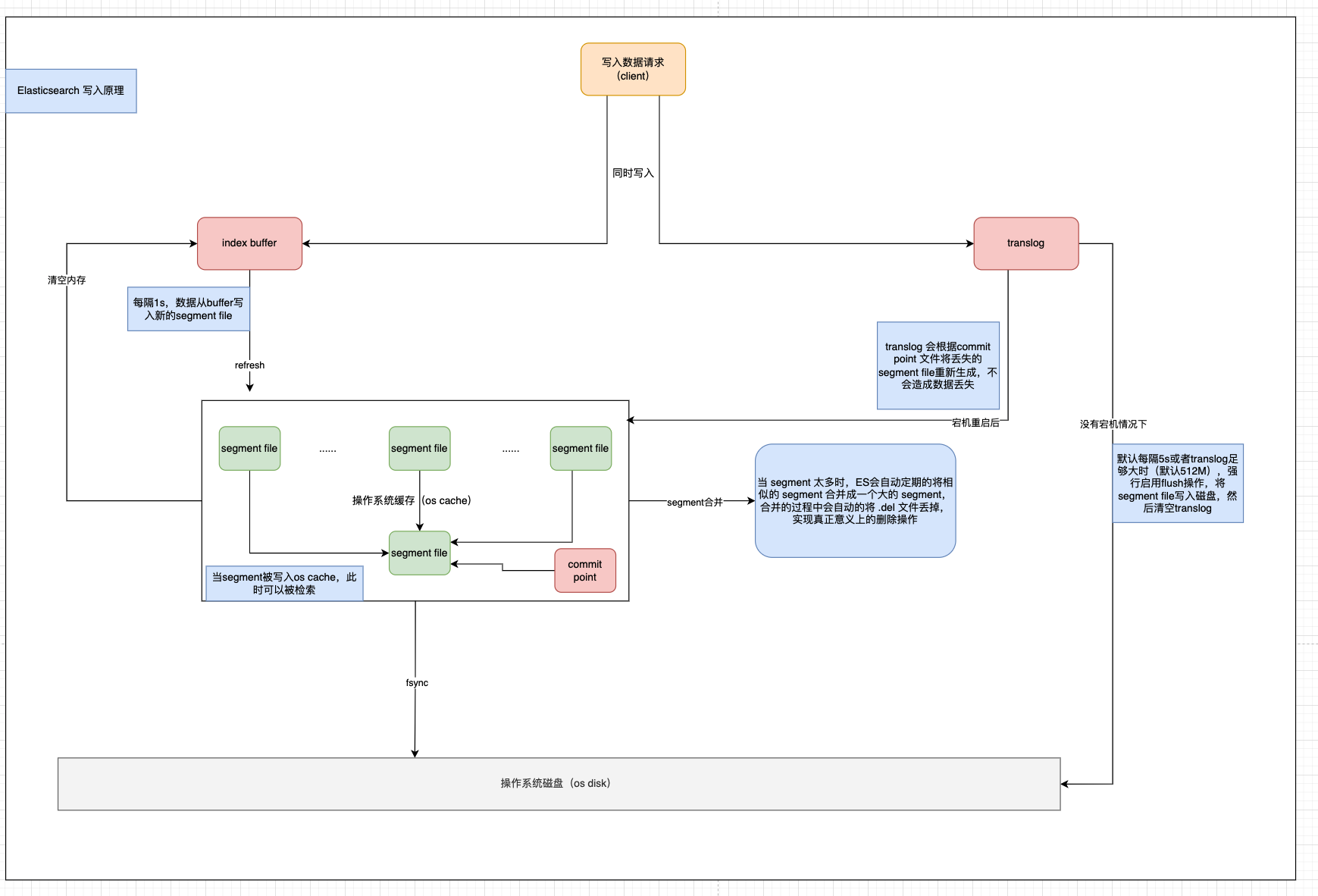
深度解析:Elasticsearch写入请求处理流程
版本 Elasticsearch 8.x 原文链接:https://mp.weixin.qq.com/s/hZ_ZOLFUoRuWyqp47hqCgQ 今天来看下 Elasticsearch 中的写入流程。 不想看过程可以直接跳转文章末尾查看总结部分。最后附上个人理解的一个图。 从我们发出写入请求,到 Elasticsearch 接收请…...
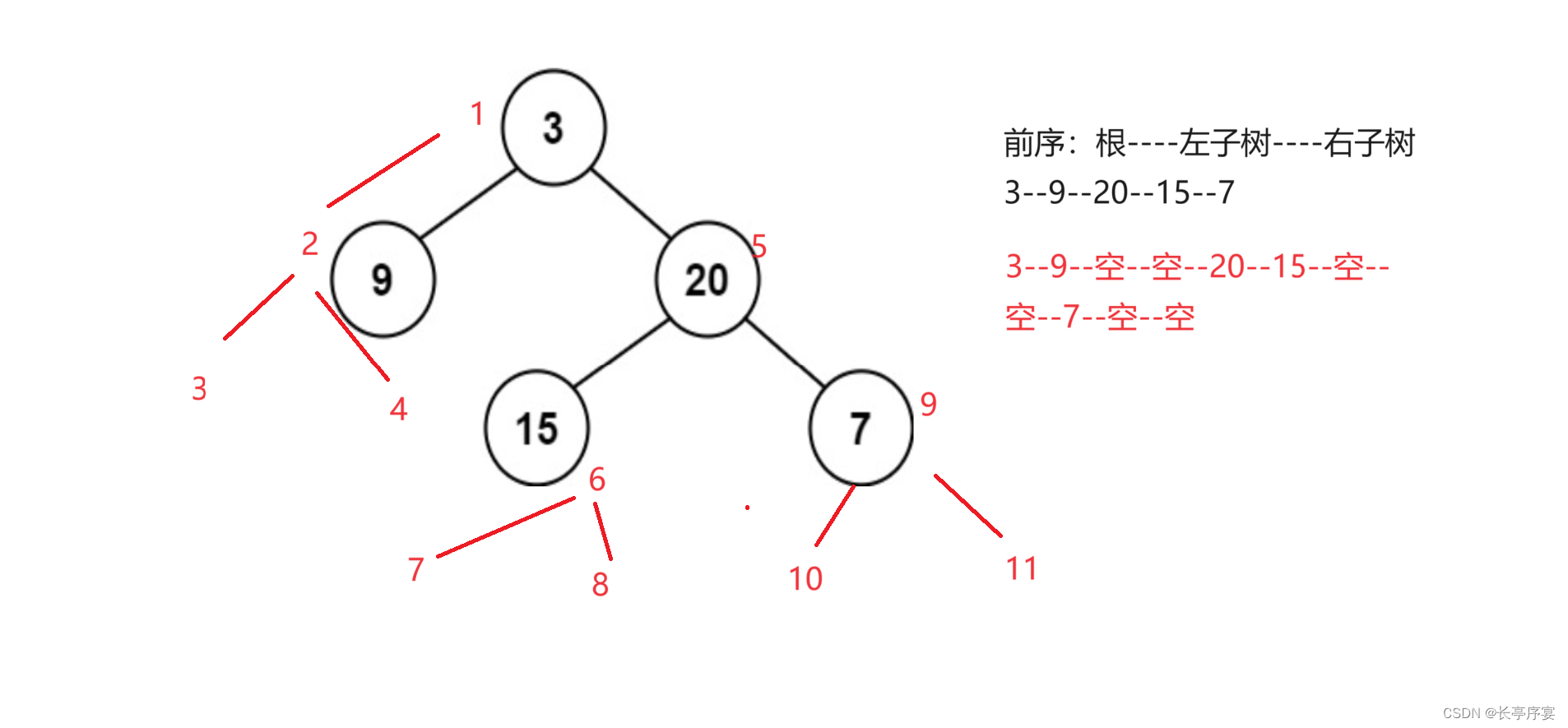
数据结构:堆和二叉树遍历
堆的特征 1.堆是一个完全二叉树 2.堆分为大堆和小堆。大堆:左右节点都小于根节点 小堆:左右节点都大于根节点 堆的应用:堆排序,topk问题 堆排序 堆排序的思路: 1.升序排序,建小堆。堆顶就是这个堆最小…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

举一个具体例子说明为什么索引不是越多越好,举具体字段
文章目录1. 核心舞台:笔记表 (t_note) 结构设计🚨 错误的操作:2. 结合具体字段,拆解三大翻车现场现场一:给 view_count(浏览量)加索引 —— 导致写放大,拖垮数据库现场二:…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...