深度解析:Elasticsearch写入请求处理流程
版本 Elasticsearch 8.x
原文链接:https://mp.weixin.qq.com/s/hZ_ZOLFUoRuWyqp47hqCgQ

今天来看下 Elasticsearch 中的写入流程。
不想看过程可以直接跳转文章末尾查看总结部分。最后附上个人理解的一个图。
从我们发出写入请求,到 Elasticsearch 接收请求,处理请求,保存数据到磁盘,这个过程中经历了哪些处理呢?Elasticsearch 又做了哪些操作?对于 Elasticsearch 写入一篇文档相信大家不陌生,但是Elasticsearch 的底层究竟是如何处理的呢,让我们一起来一探究竟。
写入流程

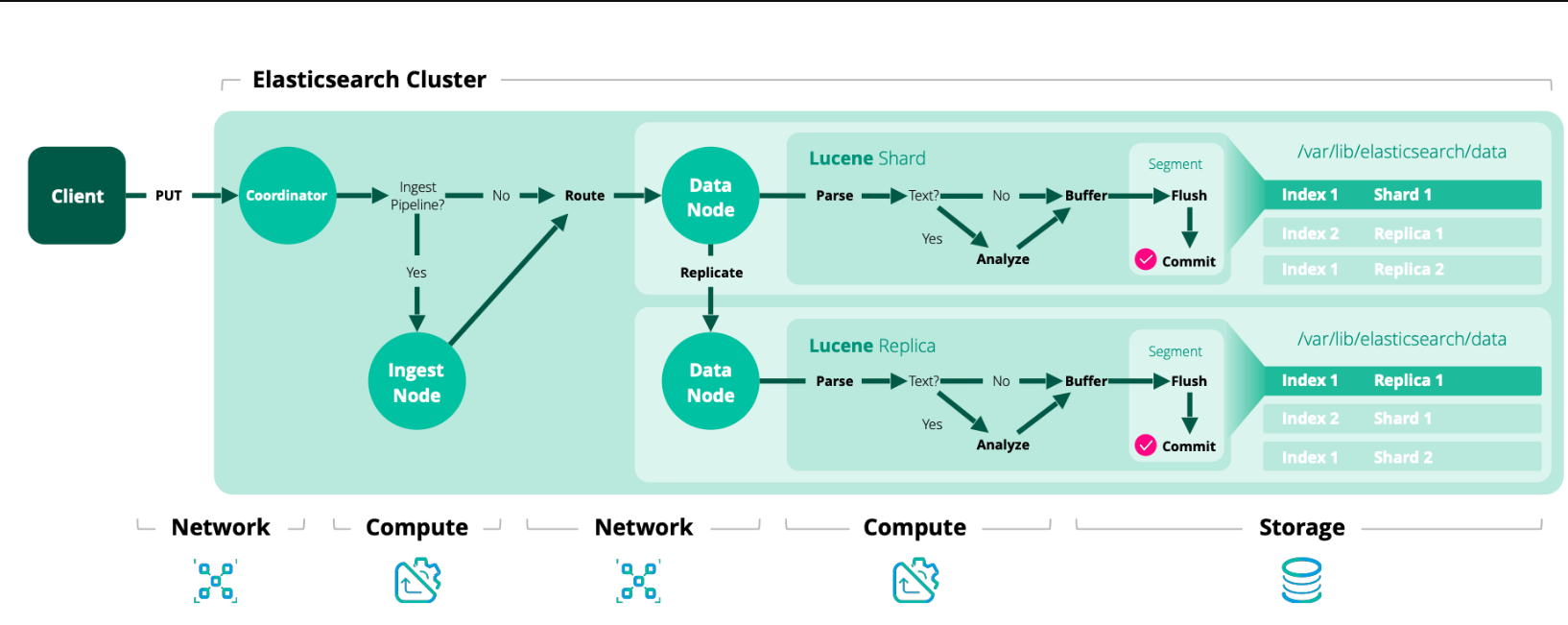
1、客户端发送写请求时,发送给任意一个节点,这个节点就是所谓的协调节点(coordinating node)。(对应图中的序号1)
2、计算文档要写入的分片位置,使用 Hash 取模算法(最新版 Hash 算法)(对应图中序号2)。
routing_factor = num_routing_shards / num_primary_shards
shard_num = (hash(_routing) % num_routing_shards) / routing_factor
3、协调节点进行路由,将请求转发给对应的 primary sharding 所在的 datanode(对应图中序号2)。
4、datanode 节点上的 primary sharding 处理请求,写入数据到索引库,并且将数据同步到对应的 replica sharding(对应图中序号3)。
5、等 primary sharding 和 replica sharding 都保存好之后返回响应(对应图中序号 4,5,6)。
路由分片算法
在7.13版本之前,计算方式如下:
shard_num = hash(_routing) % num_primary_shards
从7.13 版本开始,不包括 7.13 ,计算方式就改为了上述步骤2的计算方式。
routing_factor = num_routing_shards / num_primary_shards
shard_num = (hash(_routing) % num_routing_shards) / routing_factor
-
num_routing_shards就是配置文件中index.number_of_routing_shard的值。 -
num_primary_shard就是配置文件中index.number_of_shard的值。 -
_routing默认就是文档的ID,但是我们可以自定义该路由值。
等待激活的分片
此处以 Create index API 举例说明,其中有一个请求参数 wait_for_active_shards。
该参数的作用就是写入请求发送到ES之后,需要等待多少数量的分片处于激活状态后再继续执行后续操作。如果所需要数量的分片副本不足,则写入操作需等待并重试,直到所有的分片副本都已经启动或者发生超时。
默认情况下,写入操作仅等待主分片处于活动状态后继续执行(即 wait_for_active_shard=1)。
- (可选)的字符串值。
- 默认
1。 - 可以设置为
all,或者任意一个正整数,最多是索引的副本分片数+1(number_of_replicas+1)。
该设置极大的降低了写操作未写入所需数量分片副本的机会,但是并没有完全避免。
写入原理
先来一个官网的写入流程图(地址在文末获取)。
近实时
对于 Elasticsearch 的写入流程来说,就三部分:
1、写入到内存缓冲区。
2、写入打开新的 segment。
3、写入 disk。
为什么称为近实时,是因为在写入到内存缓冲区的时候,我们是还无法进行检索的,等到写入到segment之后,就可以进行检索到了,所以这是近实时的原因。
因为相对于写到磁盘,打开 segment 写入文件系统缓存的代价比写入磁盘的代价低的多。
第一步、写入文档到内存缓冲区(此时文档不可被检索)。

第二步、缓冲区的内容写入到 segment,但是还未提交(可被检索)。

在 Elasticsearch 中,写入和打开一个新segment的过程称为 refresh,refresh操作会自上次刷新(refresh)以来执行的所有操作都可用搜索。
refresh触发的方式有如下三种:
1、刷新间隔到了自动刷新。
2、URL增加?refresh参数,需要传空或者true。
3、调用Refresh API手动刷新
默认情况下,Elasticsearch 每秒定期刷新,但是仅限于在过去的30s内收到的一个或者多个 search请求。这个也就是近实时的一个点,文档的更改不会立即显示在下一次的检索中,需要等待 refresh 操作完成之后才可以检索出来。
我们可以通过如下方式触发refresh操作或者调整自动刷新的间隔。
POST /_refresh
POST /blogs/_refresh
调整刷新间隔,每 30s 刷新
PUT /my_logs
{"settings": {"refresh_interval": "30s" }
}
关闭自动刷新
PUT /my_logs/_settings
{ "refresh_interval": -1 }
设置为每秒自动刷新
PUT /my_logs/_settings
{ "refresh_interval": "1s"
refresh_interval需要一个 持续时间 值, 例如1s(1 秒) 或2m(2 分钟)。 一个绝对值1表示的是1毫秒--无疑会使你的集群陷入瘫痪。
段(segment)合并
由于 refresh 操作会每秒自动刷新生成一个新的段(segment),这样的话短时间内,segment会暴增,segment数量太多,每一个都会造成文件句柄、内存、CPU的大量消耗,还有一个更重要的点就是,每个检索请求也会轮流检查每一个segment,所以segment越多,检索也就越慢。
Elasticsearch 通过在后台自动合并 segment 来解决这个问题的。小的segment被合并到大的segment,然后大的segment在被合并到更大的segment。

segment 合并的时候会自动将已删除的文档从文件系统中删除,已经删除的文档或者更新文档的旧版本不会被合并到新的 segment中。

1、当 index 的时候,refresh操作会创建新的segment,并将segment打开以供检索。
2、合并进行会选择一小部分大小相似的segment,在后台将他们合并到更大的segment中,这个操作不会中断 index 与 search 操作。
optimize API
optimize API不应该用在经常更新的索引上
该 optimize API 可以控制分片最大的 segment数量,对于有的索引,例如日志,每天、每周、每月的日志被单独存在一个索引上,老得索引一般都是只读的,也不太可能发生变化,所以我们就可以使用这个 optimize API 优化老的索引,将每个分片合并为一个单独的segment。这样既可以节省资源,也可以加快检索速度。
- 合并索引中的每个分片为一个单独的段
POST /logstash-2014-10/_optimize?max_num_segments=1
持久化
上述的refresh操作是 Elasticsearch 近实时 的原因,那么数据的持久化就要看fsync操作把数据从文件系统缓冲区flush到磁盘了。所以只有当translog被fsync操作或者是提交时,translog中的数据才会持久化到磁盘。
如果没有持久化操作,当 Elasticsearch 宕机发生故障的时候,就会发生数据丢失了,所以 Elasticsearch 依赖于translog进行数据恢复。
在 Elasticsearch 进行提交操作的时候,成本是非常高的,所以策略就是在写入到内存缓冲区的时候,同步写入一份数据到translog,所有的index与delete操作都会在内部的lucene索引处理后且未确认提交之前写入teanslog。
如果发生了异常,当分片数据恢复时,已经确认提交但是并没有被上次lucene提交操作包含在内的最近操作就可以在translog中进行恢复。
Elasticsearch 的 flush操作是执行 Lucene提交并开始生成新的translog的过程,为了确保translog文件不能过大,flush操作在后台自动执行,否则在恢复的时候也会因为文件过大花费大量的时间。
对于translog有如下设置选项:
-
index.translog.durability默认设置为request,意思就是只有当主分片和副本分片fsync且提交translog之后,才会向客户端响应index,delete,update,bulk请求成功。 -
index.translog.durability设置为async,则 Elasticsearch 会在每个index.translog.sync_interval提交translog,如果遇到节点恢复,则在这个区间执行的操作就可能丢失。
对于上述的几个参数,都可以动态更新
index.translog.sync_interval
将 translog fsync到磁盘并提交的频率。默认5s,不允许小于100ms。
index.translog.durability
是否在每次index,delete,update,bulk操作之后提交translog。
request: 默认,fsync 每次请求之后提交,如果发生故障,所有已确认的写入操作到已经提交到磁盘
async: fsync在后台每个sync_interval时间间隔提交。如果发生故障,自上次提交以来所有已确认的写入操作将被丢弃。
index.translog.flush_threshold_size
防止 translog 文件过大的设置,一旦达到设置的该值,就会发生 flush 操作,并生成一个新的 commit point。默认512mb。
总结
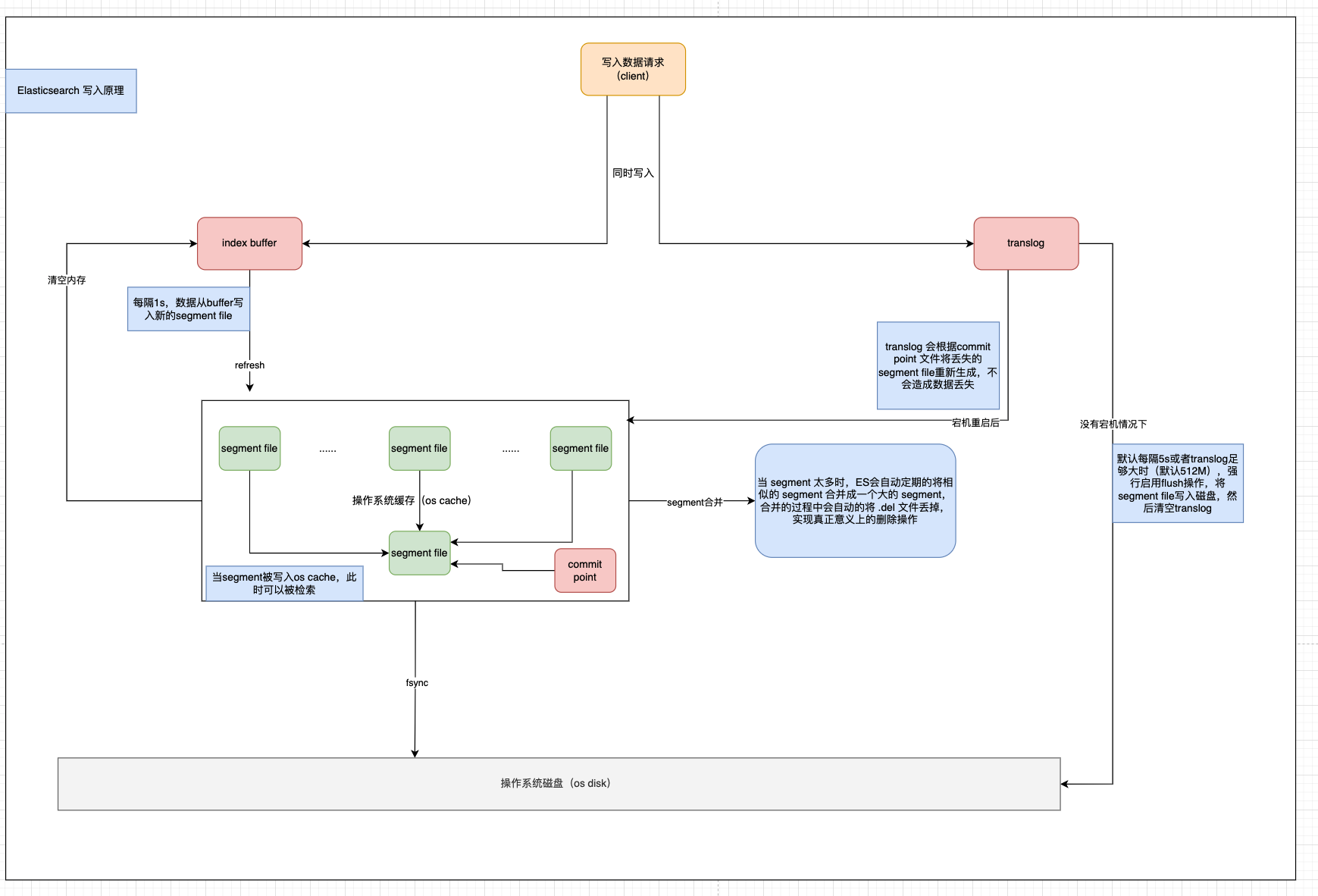
1、一个文档被index之后,添加内存缓存区,同时写入 translog。

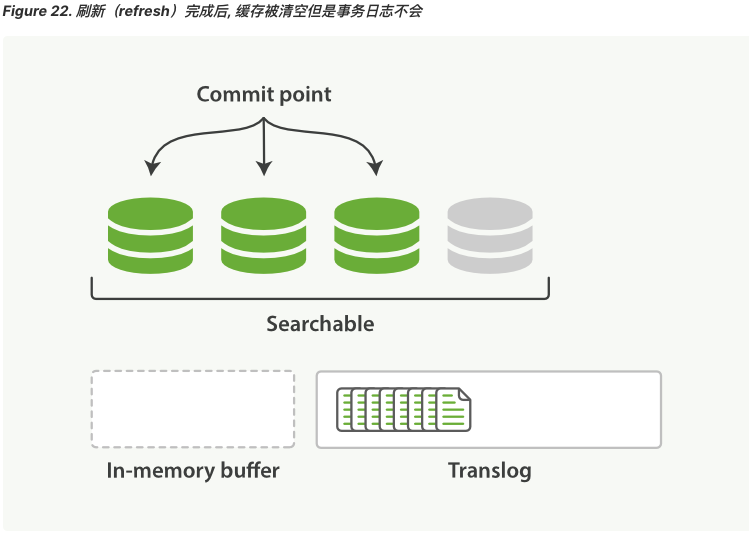
2、refresh 操作完成后,缓存被清空,但是 translog 不会
- 内存缓冲区的文档被写入到一个新的
segment中,且没有进行fsync操作。 segment打开,可供检索。- 内存缓冲区清空。
3、更多的文档被添加到内存缓冲区并追加到 translog。

4、每隔一段时间,translog 变得越来越大,索引被刷新(flush),一个新的 translog 被创建,并且一个提交执行。
- 所有内存缓冲区的文档都被写入到一个新的段。
- 缓冲区被清空。
- 一个提交点写入磁盘。
- 文件系统缓存通过
fsync被刷新(flush)。 - 老的
translog被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化记录。当 Elasticsearch 启动的时候,它会从磁盘中使用的最后一个提交点(commit point)去恢复已知的 segment ,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时的CRUD,当我们通过ID进行查询、更新、删除一个文档、它会尝试在相应的 segment 中检索之前,首先检查 translog 中任何最近的变更操作。也就是说这个是可以实时获取到文档的最新版本。

最后送上一个我自己理解的图,参考了官网的描述,以及网上画的,如有错误欢迎指出。
如果感觉写的还不错,对你有帮助,欢迎点赞、转发、收藏,也可以评论互相交流。
也可以去搜索《醉鱼Java》点个关注,一起学习进步。
参考
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/mapping-routing-field.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/indices-create-index.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/docs-index_.html#index-wait-for-active-shards
https://www.elastic.co/guide/en/elasticsearch/reference/current/images/data_processing_flow.png
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/near-real-time.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/near-real-time.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-merge.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/merge-process.html
https://blog.csdn.net/R_P_J/article/details/82254494?spm=a2c6h.12873639.article-detail.13.46227f70mJejca
http://www.uml.org.cn/bigdata/201801263.asp?spm=a2c6h.12873639.article-detail.10.46227f70mJejca&file=201801263.asp
相关文章:
深度解析:Elasticsearch写入请求处理流程
版本 Elasticsearch 8.x 原文链接:https://mp.weixin.qq.com/s/hZ_ZOLFUoRuWyqp47hqCgQ 今天来看下 Elasticsearch 中的写入流程。 不想看过程可以直接跳转文章末尾查看总结部分。最后附上个人理解的一个图。 从我们发出写入请求,到 Elasticsearch 接收请…...
数据结构:堆和二叉树遍历
堆的特征 1.堆是一个完全二叉树 2.堆分为大堆和小堆。大堆:左右节点都小于根节点 小堆:左右节点都大于根节点 堆的应用:堆排序,topk问题 堆排序 堆排序的思路: 1.升序排序,建小堆。堆顶就是这个堆最小…...
[Halcon学习笔记]在Qt上实现Halcon窗口的字体设置颜色设置等功能
1、 Halcon字体大小设置在Qt上的实现 在之前介绍过Halcon窗口显示文字字体的尺寸和样式,具体详细介绍可回看 (一)Halcon窗口界面上显示文字的字体尺寸、样式修改 当时介绍的设定方法 //Win下QString Font_win "-Arial-10-*-1-*-*-1-&q…...

ArcGis 地图文档
ArcGis官网 https://developers.arcgis.com/labs/android/create-a-starter-app/ Arcgis for android 加载谷歌、高德和天地图 https://blog.csdn.net/qq_19688207/article/details/108125778 AeroMap图层地址: API_KEY: 7e95eae2-a18d-34ce-beaa-894d6a08c5a5 街道图…...
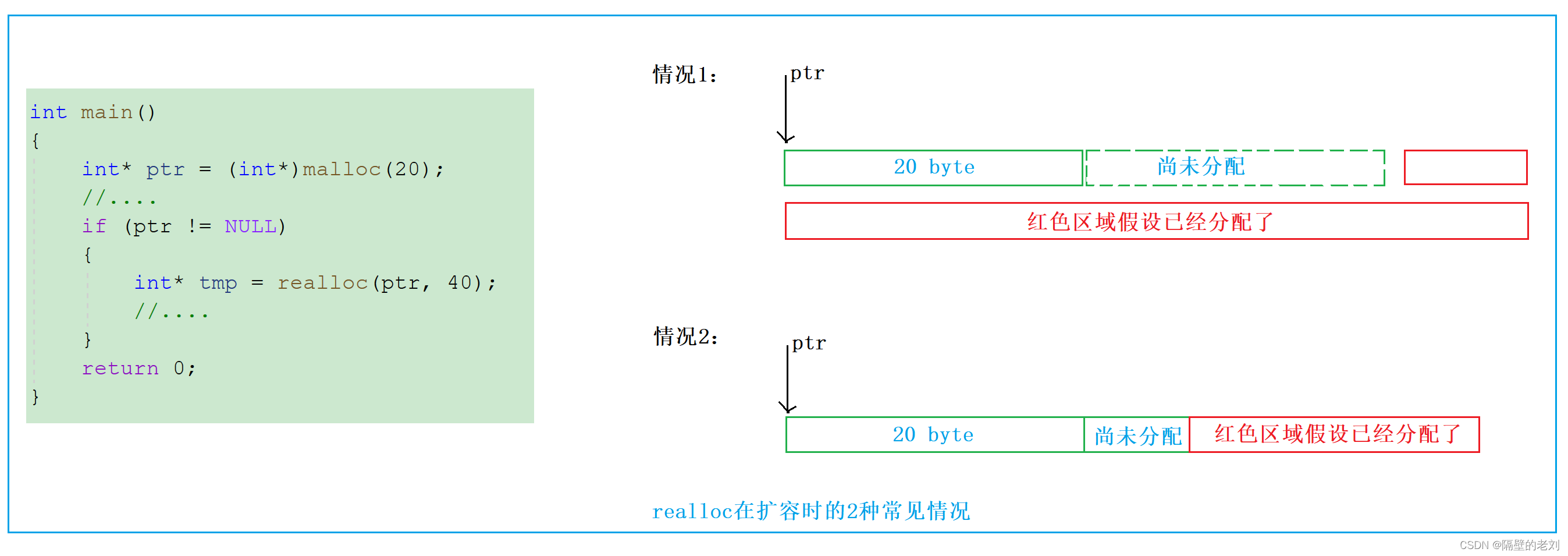
【C语言】动态内存分配
1、为什么要有动态内存分配 不管是C还是C中都会大量的使用,使用C/C实现数据结构的时候,也会使用动态内存管理。 我们已经掌握的内存开辟方式有: int val 20; //在栈空间上开辟四个字节 char arr[10] { 0 }; //在栈空间…...
算法思想总结:位运算
创作不易,感谢三连支持!! 一、常见的位运算总结 标题 二、位1的个数 . - 力扣(LeetCode) 利用第七条特性:n&(n-1)干掉最后一个1,然后每次都用count去统计ÿ…...
四、HarmonyOS应用开发-ArkTS开发语言介绍
目录 1、TypeScript快速入门 1.1、编程语言介绍 1.2、基础类型 1.3、条件语句 1.4、函数 1.5、类 1.6、模块 1.7、迭代器 2、ArkTs 基础(浅析ArkTS的起源和演进) 2.1、引言 2.2、JS 2.3、TS 2.4、ArkTS 2.5、下一步演进 3、ArkTs 开发实践…...
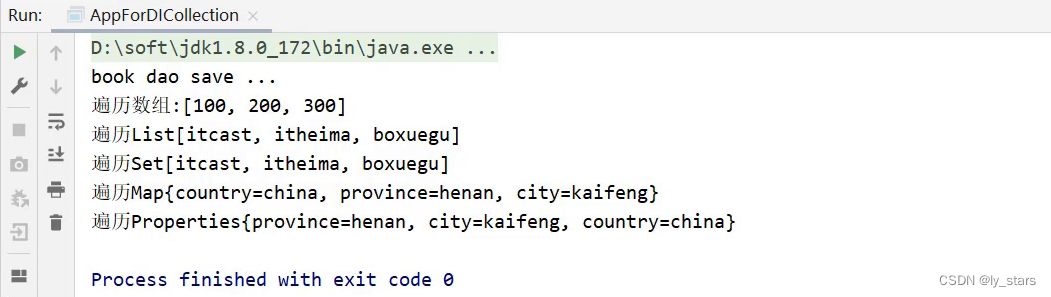
3 Spring之DI详解
5,DI相关内容 前面我们已经完成了bean相关操作的讲解,接下来就进入第二个大的模块DI依赖注入,首先来介绍下Spring中有哪些注入方式? 我们先来思考 向一个类中传递数据的方式有几种? 普通方法(set方法)构造方法 依赖注入描述了在容器中建…...
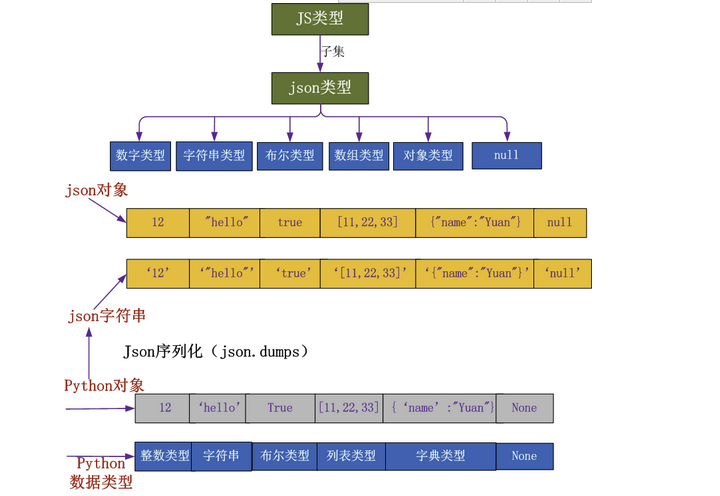
Web框架开发-Ajax
一、 Ajax准备知识:json 1、json(Javascript Obiect Notation,JS对象标记)是一种轻量级的数据交换格式 1 2 它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。 简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。…...

Python爬虫之urllib库
1、urllib库的介绍 可以实现HTTP请求,我们要做的就是指定请求的URL、请求头、请求体等信息 urllib库包含如下四个模块 request:基本的HTTP请求模块,可以模拟请求的发送。error:异常处理模块。parse:工具模块&#x…...

Docker学习笔记 - 常用命令
目录 基本概念常用命令使用docker compose启动脚本创建自己的image Docker命令文档 1. 下载一个image 从hub.docker.com下载一个image。 docker pull [image name]下载时指定image的tag。 docker pull [image name]:<tag>举例,下载postgre的tag为alpine…...
)
数学建模(Topsis python代码 案例)
目录 介绍: 模板: 案例: 极小型指标转化为极大型(正向化): 中间型指标转为极大型(正向化): 区间型指标转为极大型(正向化): 标准化处理: 公式: Topsis(优劣解距离法): 公式: 完整代码: 结果: 介绍: 在数学建模中,Topsis方法是一种多准则决策分…...

gateway网关指定路由响应超时时间
gateway网关指定路由响应超时时间 spring:cloud:gateway:httpclient:responseTimeout: 10000这个配置用于设置HttpClient的响应超时时间,单位是毫秒。具体来说,这个配置表示当Gateway向后端服务发出请求后,如果在10秒内没有收到后端服务的响…...
docker 和K8S知识分享
docker知识: 比如写了个项目,并且在本地调试没有任务问题,这时候你想在另外一台电脑或者服务器运行,那么你需要在另外一台电脑或者服务器配置相同的软件,比如数据库,web服务器,必要的插件和库等…...

MySQL--select count(*)、count(1)、count(列名) 的区别你知道吗?
MySQL select count(*)、count(1)、count(列名) 的区别? 这里我们先给出正确结论: count(*),包含了所有的列,会计算所有的行数,在统计结果时候,不会忽略列值为空的情况。count(1),忽略所有的列…...

使用verilog设计实现16位CPU及仿真
这是一个简单的16位CPU(中央处理单元)的设计实验。这个CPU包括指令存储器、数据存储器、ALU(算术逻辑单元)、寄存器文件和控制单元。 设计一个简单的16位CPU的实验通常可以分为以下几个步骤: 指令集设计:首先确定CPU支持的指令集架构,包括指令格式、寄存器组织、地址模…...
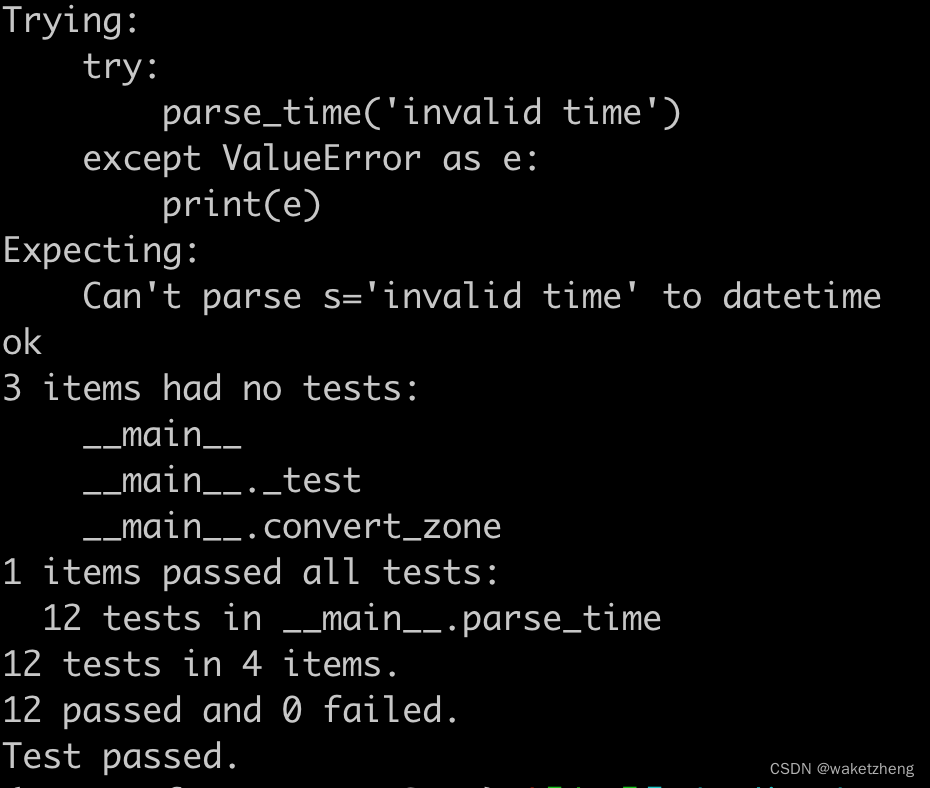
Python将字符串转换为datetime
有这样一些字符串: 1710903685 20240320110125 2024-03-20 11:01:25 要转换成Python的datetime 代码如下: import functools import re from datetime import datetime, timedelta from typing import Union# pip install python-dateutil from date…...

Vue 3 + TypeScript + Vite的现代前端项目框架
随着前端开发技术的飞速发展,Vue 3、TypeScript 和 Vite 构成了现代前端开发的强大组合。这篇博客将指导你如何从零开始搭建一个使用Vue 3、TypeScript以及Vite的前端项目,帮助你快速启动一个性能卓越且类型安全的现代化Web应用。 Vue 3 是一款渐进式Jav…...

浏览器强缓存和弱缓存的主要区别
浏览器强缓存与弱缓存 浏览器的缓存机制主要分为两种:强缓存与协商缓存(也称弱缓存)。 强缓存 强缓存是指浏览器在请求一个资源时,不与服务器发生通信,直接从本地缓存中获取资源。如果存在有效的强缓存,…...

深度学习-2.9梯度不稳定和Glorot条件
梯度不稳定和Glorot条件 一、梯度消失和梯度爆炸 对于神经网络这个复杂系统来说,在模型训练过程中,一个最基础、同时也最常见的问题,就是梯度消失和梯度爆炸。 我们知道,神经网络在进行反向传播的过程中,各参数层的梯…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...