Spark spark-submit 提交应用程序
Spark spark-submit 提交应用程序
Spark支持三种集群管理方式
- Standalone—Spark自带的一种集群管理方式,易于构建集群。
- Apache Mesos—通用的集群管理,可以在其上运行Hadoop MapReduce和一些服务应用。
- Hadoop YARN—Hadoop2中的资源管理器。
注意:
1、在集群不是特别大,并且没有mapReduce和Spark同时运行的需求的情况下,用Standalone模式效率最高。
2、Spark可以在应用间(通过集群管理器)和应用中(如果一个SparkContext中有多项计算任务)进行资源调度。
Running Spark on YARN
cluster mode
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
lib/spark-examples*.jar \
10
client mode
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
lib/spark-examples*.jar \
10
spark-submit 详细参数说明
| 参数名 | 参数说明 |
|---|---|
| —master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local。具体指可参考下面关于Master_URL的列表 |
| —deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| —class | 应用程序的主类,仅针对 java 或 scala 应用 |
| —name | 应用程序的名称 |
| —jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| —packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 |
| —exclude-packages | 为了避免冲突 而指定不包含的 package |
| —repositories | 远程 repository |
| —conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions=”-XX:MaxPermSize=256m” |
| —properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| —driver-memory | Driver内存,默认 1G |
| —driver-java-options | 传给 driver 的额外的 Java 选项 |
| —driver-library-path | 传给 driver 的额外的库路径 |
| —driver-class-path | 传给 driver 的额外的类路径 |
| —driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| —executor-memory | 每个 executor 的内存,默认是1G |
| —total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用 |
| —num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 |
| —executor-core | 每个 executor 的核数。在yarn或者standalone下使用 |
Master_URL的值
| Master URL | 含义 |
|---|---|
| local | 使用1个worker线程在本地运行Spark应用程序 |
| local[K] | 使用K个worker线程在本地运行Spark应用程序 |
| local | 使用所有剩余worker线程在本地运行Spark应用程序 |
| spark://HOST:PORT | 连接到Spark Standalone集群,以便在该集群上运行Spark应用程序 |
| mesos://HOST:PORT | 连接到Mesos集群,以便在该集群上运行Spark应用程序 |
| yarn-client | 以client方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver在client运行。 |
| yarn-cluster | 以cluster方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver也在集群中运行。 |
区分client,cluster,本地模式
下图是典型的client模式,spark的drive在任务提交的本机上。

下图是cluster模式,spark drive在yarn上。
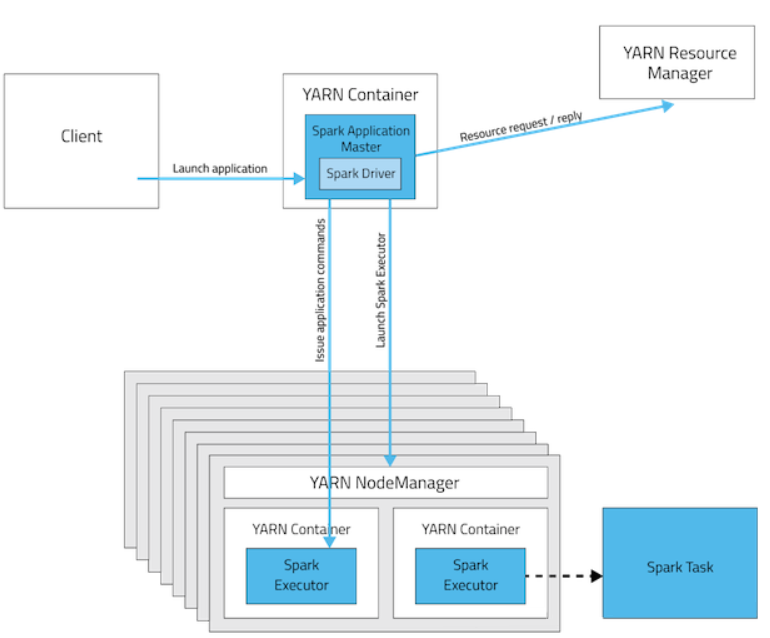
三种模式的比较
| Yarn Cluster | Yarn Client | Spark Standalone | |
|---|---|---|---|
| Driver在哪里运行 | Application Master | Client | Client |
| 谁请求资源 | Application Master | Application Master | Client |
| 谁启动executor进程 | Yarn NodeManager | Yarn NodeManager | Spark Slave |
| 驻内存进程 | 1.Yarn ResourceManager 2.NodeManager | 1.Yarn ResourceManager 2.NodeManager | 1.Spark Master 2.Spark Worker |
| 是否支持Spark Shell | No | Yes | Yes |
spark-submit提交应用程序示例
# Run application locally on 8 cores(本地模式8核)
./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master local[8] \/path/to/examples.jar \100
# Run on a Spark standalone cluster in client deploy mode(standalone client模式)
./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://207.184.161.138:7077 \--executor-memory 20G \--total-executor-cores 100 \/path/to/examples.jar \1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise(standalone cluster模式使用supervise)
./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://207.184.161.138:7077 \--deploy-mode cluster \--supervise \--executor-memory 20G \--total-executor-cores 100 \/path/to/examples.jar \1000
# Run on a YARN cluster(YARN cluster模式)
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \ # can be client for client mode--executor-memory 20G \--num-executors 50 \/path/to/examples.jar \1000
# Run on a Mesos cluster in cluster deploy mode with supervise(Mesos cluster模式使用supervise)
./bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master mesos://207.184.161.138:7077 \--deploy-mode cluster \--supervise \--executor-memory 20G \--total-executor-cores 100 \http://path/to/examples.jar \1000
# Run a Python application on a Spark standalone cluster(standalone cluster模式提交python application)
./bin/spark-submit \--master spark://207.184.161.138:7077 \examples/src/main/python/pi.py \1000一个例子
spark-submit \
--master yarn \
--queue root.sparkstreaming \
--deploy-mode cluster \
--supervise \
--name spark-job \
--num-executors 20 \
--executor-cores 2 \
--executor-memory 4g \
--conf spark.dynamicAllocation.maxExecutors=9 \
--files commons.xml \
--class com.***.realtime.helper.HelperHandle \
BSS-ONSS-Spark-Realtime-1.0-SNAPSHOT.jar 500
相关文章:
Spark spark-submit 提交应用程序
Spark spark-submit 提交应用程序 Spark支持三种集群管理方式 Standalone—Spark自带的一种集群管理方式,易于构建集群。Apache Mesos—通用的集群管理,可以在其上运行Hadoop MapReduce和一些服务应用。Hadoop YARN—Hadoop2中的资源管理器。 注意&…...

IOS面试题编程机制 51-55
51. 在iPhone应用中如何保存数据?有以下几种保存机制: 1).通过web服务,保存在服务器上 2).通过NSCoder固化机制,将对象保存在文件中 3).通过SQlite或CoreData保存在文件数据库中52. 阐述Block 的理解?并写出一个使用Block执行UIVew动画?Block是可以获取其他函数局部变量的…...

话题——AI大模型学习
AI大模型学习 在当前技术环境下,AI大模型学习不仅要求研究者具备深厚的数学基础和编程能力,还需要对特定领域的业务场景有深入的了解。通过不断优化模型结构和算法,AI大模型学习能够不断提升模型的准确性和效率,为人类生活和工作…...

MySQL基础复习
目录 一、简单的命令 二、SQL语句分类 三、简单查询 四、条件查询 五、排序 一、简单的命令 net start 服务名称 net stop 服务名称 mysql -uroot -p123456 显示密码形式 mysql -uroot -p 隐藏密码形式 exit 退出 show databases; 查看MySQL中的数据库有哪些 use test…...
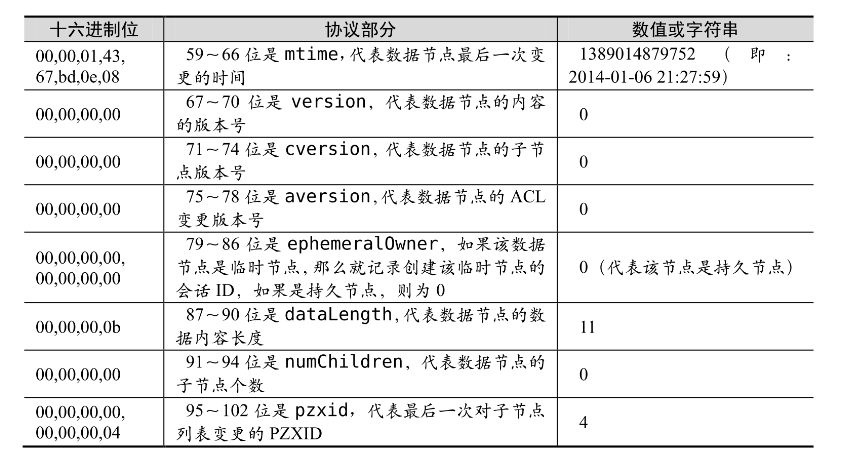
Zookeeper(八)序列化与协议
目录 一 序列化与反序列化1.1 Jute序列化工具1.1 Recor接口1.2 OutputArchive和InputArchive 二 通信协议2.1 请求部分2.1.1 请求头2.2.2 请求体2.1.3 案例分析 2.2 响应部分2.2.1 响应头2.2.2 响应内容2.2.3 案例分析 官网:Apache ZooKeeper 一 序列化与反序列化 …...
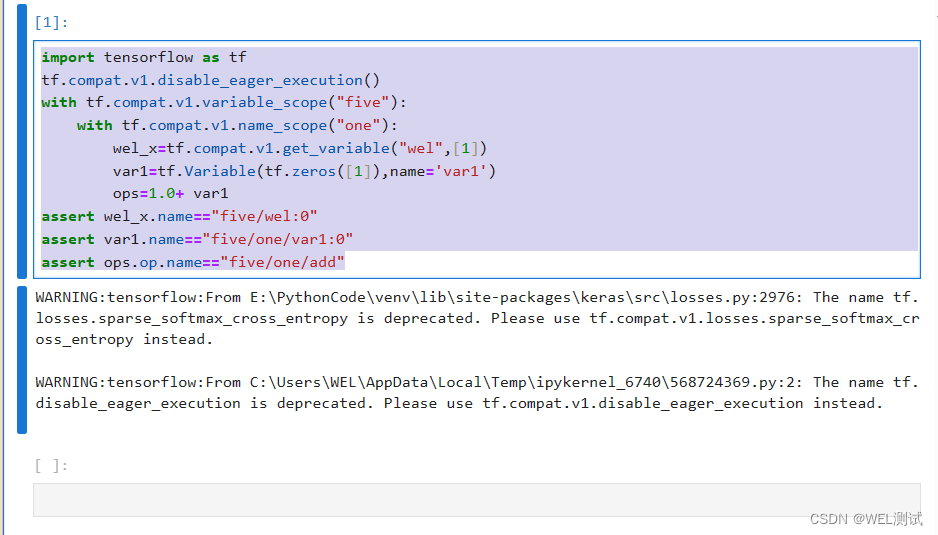
人工智能之Tensorflow变量作用域
在TensoFlow中有两个作用域(Scope),一个时name_scope ,另一个是variable_scope。variable_scope主要给variable_name加前缀,也可以给op_name加前缀;name_scope给op_name加前缀。 variable_scope 通过所给的名字创建或…...

ElasticSearch插件安装及配置
Docker安装ElasticSearch docker compose 安装直接看步骤三:新建索引 1、安装elasticsearch (1)下载elasticsearch和kibana docker pull elasticsearch:7.9.1 docker pull kibana:7.9.1(2)配置 mkdir -p /mydata/…...
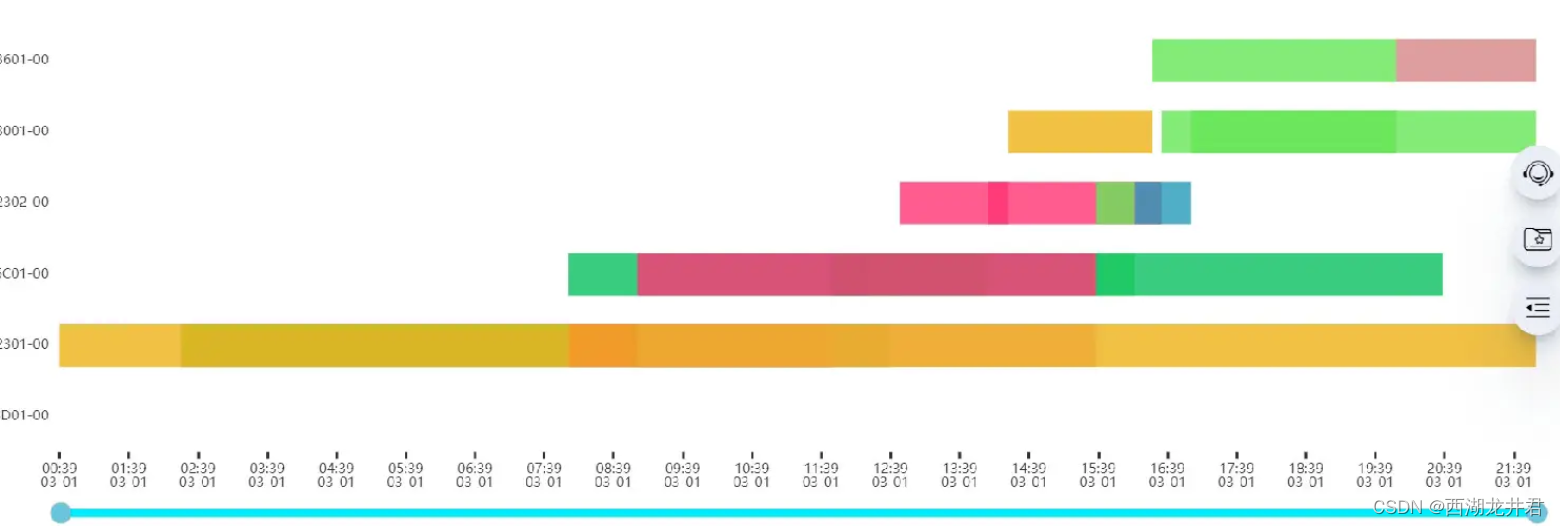
vue+Echarts实现多设备状态甘特图
目录 1.效果图 2.代码 3.注意事项 Apache ECharts ECharts官网,可在“快速上手”处查看详细安装方法 1.效果图 可鼠标滚轮图表和拉动下方蓝色的条条调节时间细节哦 (注:最后一个设备没有数据,所以不显示任何矩形)…...

STM32使用滴答定时器实现delayms
在STM32上使用SysTick实现jiffies(时间戳)并且实现delay_ms 代码实现: volatile uint32_t jiffies 0; // 用于记录系统运行的jiffies数 void SysTick_Handler(void) {/* 每次SysTick中断,jiffies增加 */jiffies; }uint32_t tick…...

k8s的volumn解析
背景 k8s中有一套自己的存储逻辑,它和docker中的volumn类似,本文就来看一下k8s的volunm的存储设计 k8s的volumn 1.EmptyDir类型的volumn 这种类型的volumn是Pod内的容器共享的,volumn的生命周期和Pod的生命周期是一致的,不过大…...

Golang获取音视频时长信息
文章目录 一、工具简介二、使用golang获取时间长 一、工具简介 这些工具都是与多媒体处理和流媒体相关的开源工具,它们都属于 FFmpeg 多媒体框架。 FFmpeg 是一个用于处理多媒体内容(音频、视频、图像等)的命令行工具。它可以执行各种各样…...

LeetCode 面试经典150题 14.最长公共前缀
题目: 编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 ""。 思路: 代码: class Solution {public String longestCommonPrefix(String[] strs) {if (strs.length 0) {return &…...
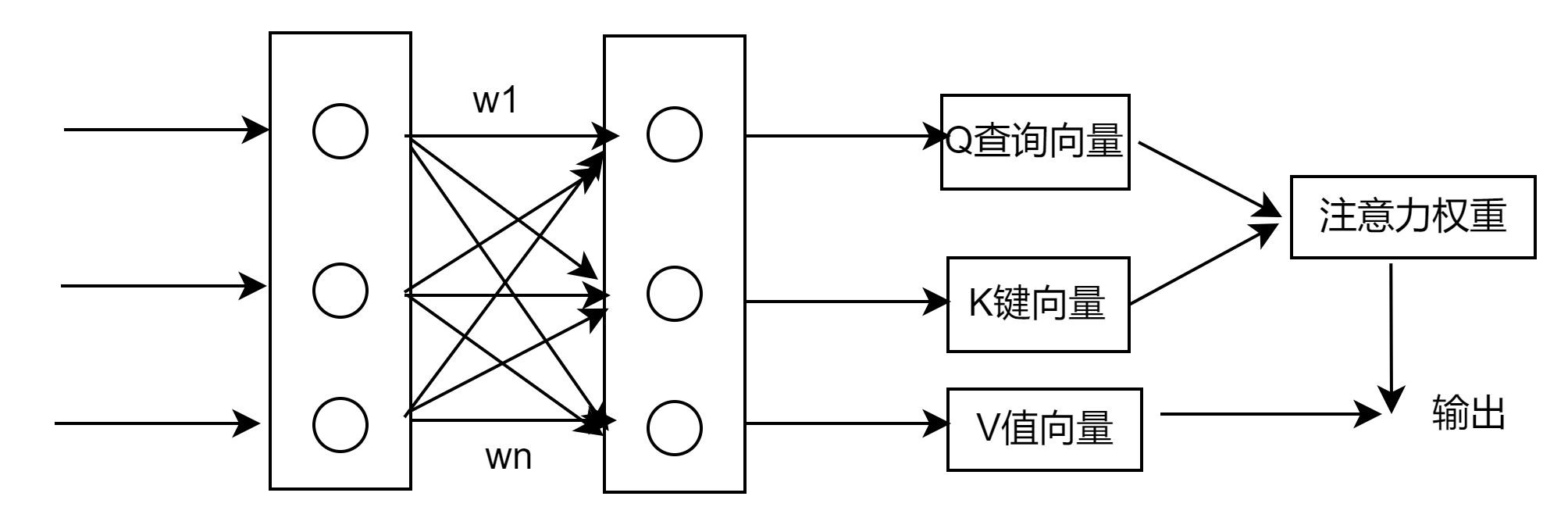
自注意力机制的理解
一、自注意力要解决什么问题 循环神经网络由于信息传递的容量以及梯度消失问题,只能建立短距离依赖关系。为了建立长距离的依赖关系,可以增加网络的层数或者使用全连接网络。但是全连接网络无法处理变长的输入序列,另外,不同的输…...
win10-误删winsock恢复方法
文件链接放在最前面 链接:https://pan.baidu.com/s/1i9X0HJJOfo63fbtOETc1Xw?pwdlfqx 提取码:lfqx 误删后应该还是可以正常连接网络的,但是重启过后直接以太网和wifi都是无法使用的。下图是我后面网络正常补充的图片 误删后是只有飞行模式…...

c#矩阵求逆
目录 一、矩阵求逆的数学方法 1、伴随矩阵法 2、初等变换法 3、分块矩阵法 4、定义法 二、矩阵求逆C#代码 1、伴随矩阵法求指定3*3阶数矩阵的逆矩阵 (1)伴随矩阵数学方法 (2)代码 (3)计算 2、对…...
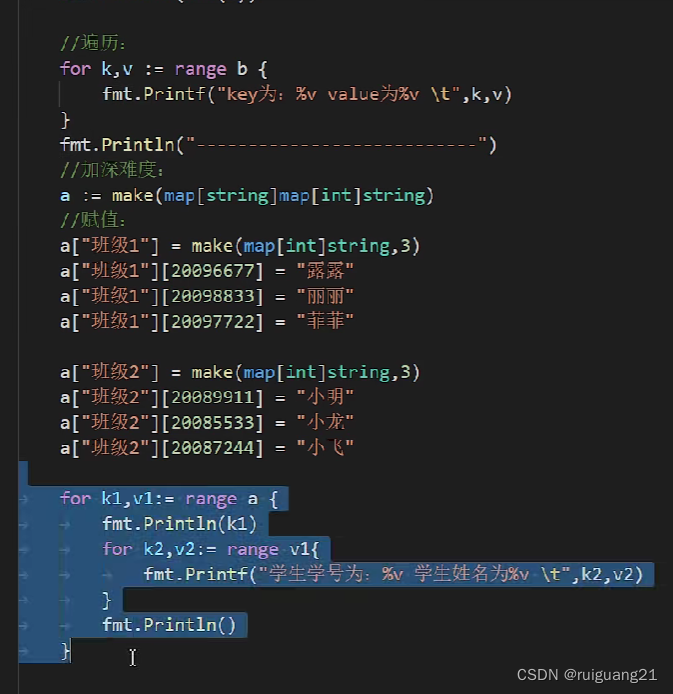
array go 语言的数组 /切片
内存地址通过& package mainimport "fmt"func main() {var arr [2][3]int16fmt.Println(arr)fmt.Printf("arr的地址是: %p \n", &arr)fmt.Printf("arr[0]的地址是 %p \n", &arr[0])fmt.Printf("arr[0][0]的地址是 %p \n"…...
)
【Stable Diffusion】专栏介绍和文章索引(持续更新中)
目录 1 背景2 思考3 文章索引(持续更新中)3.1 入门3.2 初级3.3 中级3.3 高级 1 背景 最近开始学习AIGC,对Stable Diffusion比较感兴趣,所以新建了这个专栏,来记录自己在使用和学习Stable Diffusion的一些方法、资料以…...

RPC 快速入门
一、What 1)小故事 张三和李四都在同一个家公司负责商品交易的模块,两个人平时开发甚是紧密。 🙋🏻♂️ 张三:“李四,我这边一个商品下单了,但是付款数额不对,你帮我查下支付有没…...

使用Docker搭建Syslog-ng
Syslog-ng是一个可靠、多功能的日志管理系统,用于收集日志并将其转发到指定的日志分析工具。 使用Docker CLI方式搭建 步骤 1: 拉取Syslog-ng镜像 首先,需要从Docker Hub拉取Syslog-ng的官方镜像。 docker pull balabit/syslog-ng:latest步骤 2: 启动…...
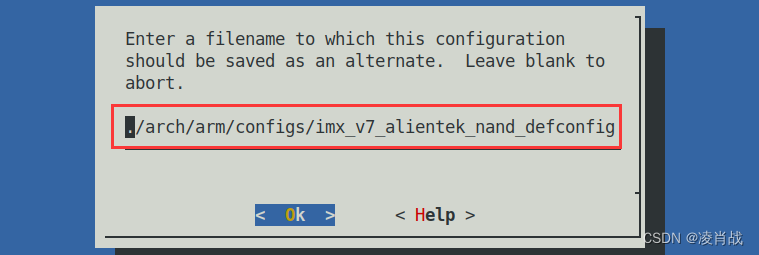
使能 Linux 内核自带的 FlexCAN 驱动
一. 简介 前面一篇文章学习了 ALPHA开发板修改CAN的设备树节点信息,并加载测试过设备树文件,文件如下: ALPHA开发板修改CAN的设备树节点信息-CSDN博客 本文是学习使能 IMX6ULL的 CAN驱动,也就是通过内核配置来实现。 二. 使能…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...

OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案
OpenCore Legacy Patcher完全指南:3步让旧款Mac焕发新生的终极方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否拥有一台性能尚可但已被…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...
)
保姆级教程:在Ubuntu 22.04上搞定水星MW310UH无线网卡驱动(含安全启动关闭指南)
水星MW310UH无线网卡在Ubuntu 22.04的完整驱动指南当你刚拿到水星MW310UH无线网卡,满心欢喜地插入Ubuntu 22.04系统,却发现系统毫无反应时,那种挫败感我深有体会。作为一款性价比极高的USB无线网卡,MW310UH在Windows下即插即用&am…...

Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生
Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 想…...

终极鼠标连点器MouseClick:5分钟免费获取完整使用指南
终极鼠标连点器MouseClick:5分钟免费获取完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...