mysql基础4sql优化
SQL优化
插入数据优化
如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。
insert into tb_test values(1,'tom');
insert into tb_test values(2,'cat');
insert into tb_test values(3,'jerry');-- 优化方案一:批量插入数据
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');-- 优化方案二:手动控制事务
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
commit;-- 优化方案三:主键顺序插入,性能要高于乱序插入
主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3
主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89
大批量插入数据
如果一次性需要插入大批量数据(比如: 几百万的记录),使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。操作如下:
-- 客户端连接服务端时,加上参数 -–local-infile 加载本地数据
mysql –-local-infile -u root -p-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
select @@local_infile; -- 1是开启-- 开启 set global local_infile = 1; -- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
主键优化
在上一小节,我们提到,主键顺序插入的性能是要高于乱序插入的。 这一小节,就来介绍一下具体的原因,然后再分析一下主键又该如何设计。
1). 数据组织方式
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)。行数据,都是存储在聚集索引的叶子节点上的。
在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储到下一个页中,页与页之间会通过指针连接。
2). 页分裂
页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排列。
A. 主键顺序插入效果
①. 从磁盘中申请页, 主键顺序插入
②. 第一个页没有满,继续往第一页插入
③. 当第一个也写满之后,再写入第二个页,页与页之间会通过指针连接
④. 当第二页写满了,再往第三页写入B. 主键乱序插入效果
涉及移动数据到新页,重新设置链表指针。
3). 页合并
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。
当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。删除数据,并将页合并之后,再次插入新的数据。
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
4). 索引设计原则
满足业务需求的情况下,尽量降低主键的长度。
插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
业务操作时,避免对主键的修改。
3.3 order by优化
MySQL的排序,有两种方式:
Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
drop index idx_user_phone on tb_user;
drop index idx_user_phone_name on tb_user;
drop index idx_user_name on tb_user;-- Extra 以下两个查询均为 Using filesort
explain select id,age,phone from tb_user order by age ;
explain select id,age,phone from tb_user order by age, phone ;-- 创建age,phone的索引
create index idx_user_age_phone_aa on tb_user(age,phone);
explain select id,age,phone from tb_user order by age; -- Extra:Using index
explain select id,age,phone from tb_user order by age , phone; -- Extra:Using index-- 根据age, phone进行降序排序
-- Extra:Backward index scan;Using index
-- Backward index scan,这个代表反向扫描索引,在MySQL8版本中,支持降序索引,我们也可以创建降序索引
explain select id,age,phone from tb_user order by age desc , phone desc ; -- 根据phone,age进行升序排序,phone在前,age在后。 排序时,也需要满足最左前缀法则,否则也会出现 filesort。
-- Extra:Using index; Using filesort 违背最左前缀,索引失效,创建的age,phone索引
explain select id,age,phone from tb_user order by phone , age;-- 根据age, phone进行降序一个升序,一个降序
-- 因为创建索引时,如果未指定顺序,默认都是按照升序排序的,而查询时,一个升序,一个降序,此时就会出现Using filesort。
explain select id,age,phone from tb_user order by age asc , phone desc ;创建联合索引(age 升序排序,phone 倒序排序)
-- 创建联合索引(age 升序排序,phone 倒序排序)
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);
explain select id,age,phone from tb_user order by age asc , phone desc ; -- Extra:Using index
由上述的测试,我们得出order by优化原则:
A. 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
B. 尽量使用覆盖索引。
C. 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
D. 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
group by优化
分组操作,我们主要来看看索引对于分组操作的影响。
drop index idx_user_pro_age_sta on tb_user;
drop index idx_email_5 on tb_user;
drop index idx_user_age_phone_aa on tb_user;
drop index idx_user_age_phone_ad on tb_user;
pdf 55 blbl 91-34
出现 Using temporary时,使用到临时表 性能较低
-- Extra:Using temporary; Using filesort
explain select profession,count(*) from tb_user group by profession;-- 对于 profession , age, status 创建一个联合索引
create index idx_user_pro_age_sta on tb_user(profession , age , status);
-- Extra: Using index
explain select profession,count(*) from tb_user group by profession;-- 单独查age 不满足最左前缀法则
-- Extra:Using index; Using temporary; Using filesort 性能不高explain select age,count(*) from tb_user group by age;-- 联合查profession,age
-- Extra: Using index
explain select profession,age,count(*) from tb_user group by profession,age;-- 添加where条件,提高效率
-- Extra: Using where; Using index
explain select age,count(*) from tb_user where profession = '软件工程' group by age;所以,在分组操作中,我们需要通过以下两点进行优化,以提升性能:
A. 在分组操作时,可以通过索引来提高效率。
B. 分组操作时,索引的使用也是满足最左前缀法则的。
limit优化
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。
优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化。
select * from tb_sku limit 10; -- 10 rows in set (0.00 sec) 很快
select * from tb_sku limit 5000000,10; -- 10 rows in set (42.42 sec) 很慢-- 优化查询
select id from tb_sku order by id limit 5000000,10; -- 10 rows in set (18.69 sec)
-- 将上面的结果看成临时表,优化后-- 10 rows in set (17.09 sec)
select * from tb_sku t , (select id from tb_sku order by id limit 5000000,10) a where t.id = a.id;
count优化
3.6.1 概述
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的count,MyISAM也慢。
InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
主要的优化思路:自己计数(可以借助于redis这样的数据库进行,但是如果是带条件的count又比较麻烦了)。
count用法
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
-- 尽量使用count(*)
按照效率排序的话,count(字段) < count(主键 id) < count(1) ≈ count(*)
count(主键):InnoDB 引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)count(字段):没有not null 约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。count(数字):InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。count(*):InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
update优化
我们主要需要注意一下update语句执行时的注意事项。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁升级为表锁 。
-- 如下:执行删除的SQL语句时,会锁定id为1这一行的数据,然后事务提交之后,行锁释放。
begin;
update course set name = 'javaEE' where id = 1 ;
-- 新的终端开启事务执行,执行是OK的
begin;
update course set name = 'javaEE' where id = 2 ;-- name无索引 行锁升级为了表锁。 导致该update语句的性能大大降低
update course set name = 'SpringBoot' where name = 'PHP' ;
-- create index idx_coruse_name on course(name); 创建索引后再执行不会锁表。
视图
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
通俗的讲,视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
4.1.2 语法
1). 创建
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
-- 创建视图
create or replace view stu_v_1 as select id,name from student where id <= 10;2). 查询
查看创建视图语句:SHOW CREATE VIEW 视图名称;
查看视图数据:SELECT * FROM 视图名称 ...... ;
show create view stu_v_1;
select * from stu_v_1;
select * from stu_v_1 where id < 3;3). 修改
方式一:CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
方式二:ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
create or replace view stu_v_1 as select id,name,no from student where id <= 10;
alter view stu_v_1 as select id,name from student where id <= 10;4). 删除
DROP VIEW [IF EXISTS] 视图名称 [,视图名称] ...
drop view if exists stu_v_1;-- 插入数据
insert into stu_v_1 values(6,'Tom'); -- 插入后可以查询到
insert into stu_v_1 values(17,'Tom22'); -- 查不到数据,创建视图时的条件为 id<=10
4.1.3 检查选项
使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,不符合执行失败。
MySQL允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项: CASCADED (默认,级联检查依赖的视图)和 LOCAL(本地检查)。
4.1.4 视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一
项,则该视图不可更新:
A. 聚合函数或窗口函数(SUM()、 MIN()、 MAX()、 COUNT()等)
B. DISTINCT
C. GROUP BY
D. HAVING
E. UNION 或者 UNION ALL
1
create view stu_v_count as select count(*) from student;
insert into stu_v_count values(10); --插入失败
视图作用
1). 简单
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
2). 安全
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图,用户只能查询和修改他们所能见到的数据,从而将敏感的字段隔离开。
3). 数据独立
视图可帮助用户屏蔽真实表结构变化带来的影响。
-- 案例
1). 为了保证数据库表的安全性,开发人员在操作tb_user表时,只能看到的用户的基本字段,屏蔽手机号和邮箱两个字段。create view tb_user_view as select id,name,profession,age,gender,status,createtime from tb_user;select * from tb_user_view;2). 查询每个学生所选修的课程(三张表联查),这个功能在很多的业务中都有使用到,为了简化操
作,定义一个视图。
create view tb_stu_course_view as select s.name student_name , s.no student_no ,c.name course_name from student s, student_course sc , course c where s.id =sc.studentid and sc.courseid = c.id;select * from tb_stu_course_view;
相关文章:

mysql基础4sql优化
SQL优化 插入数据优化 如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。 insert into tb_test values(1,tom); insert into tb_test values(2,cat); insert into tb_test values(3,jerry);-- 优化方案一:批量插入数据 Inser…...

实现Spring Web MVC中的文件上传功能,并处理大文件和多文件上传
实现Spring Web MVC中的文件上传功能,并处理大文件和多文件上传 在Spring Web MVC中实现文件上传功能并处理大文件和多文件上传是一项常见的任务。下面是一个示例,演示如何在Spring Boot应用程序中实现这一功能: 添加Spring Web依赖&#x…...
搭建vite项目
文章目录 Vite 是一个基于 Webpack 的开发服务器,用于开发 Vue 3 和 Vite 应用程序 一、创建一个vite项目二、集成Vue Router1.安装 vue-routernext插件2.在 src 目录下创建一个名为 router 的文件夹,并在其中创建一个名为 index.js 的文件。在这个文件中…...

Docker 安装mysql 主从复制
目录 1 MySql主从复制简介 1.1 主从复制的概念 1.2 主从复制的作用 2. 搭建主从复制 2.1 pull mysql 镜像 2.2 新建主服务器容器实例 3307 2.2.1 master创建 my.cnf 2.2.2 重启master 2.2.3 进入mysql 容器,创建同步用户 2.3 新建从服务器容器实例 3308…...

GPT每日面试题—如何实现二分查找
充分利用ChatGPT的优势,帮助我们快速准备前端面试。今日问题:如何实现二分查找? Q:如果在前端面试中,被问到如何实现二分查找,如果回答比较好,给出必要的代码示例 A:当被问到如何实…...

机器学习神经网络由哪些构成?
机器学习神经网络通常由以下几个主要组件构成: 1. **输入层(Input Layer)**:输入层接受来自数据源(例如图像、文本等)的原始输入数据。每个输入特征通常表示为输入层中的一个节点。 2. **隐藏层ÿ…...

代码随想录算法训练营day19 | 二叉树阶段性总结
各个部分题目的代码题解都在我往日的二叉树的博客中。 (day14到day22) 目录 二叉树理论基础二叉树的遍历方式深度优先遍历广度优先遍历 求二叉树的属性二叉树的修改与制造求二叉搜索树的属性二叉树公共最先问题二叉搜索树的修改与构造总结 二叉树理论基础 二叉树的理论基础参…...

数据库引论:3、中级SQL
一些更复杂的查询表达 3.1 连接表达式 拼接多张表的几种方式 3.1.1 自然连接 natural join,自动连接在所有共同属性上相同的元组 join… using( A 1 , A 2 , ⋯ A_1,A_2,\cdots A1,A2,⋯):使用括号里的属性进行自然连接,除了这些属性之外的共同…...

毕业设计:日志记录编写(3/17起更新中)
目录 3/171.配置阿里云python加速镜像:2. 安装python3.9版本3. 爬虫技术选择4. 数据抓取和整理5. 难点和挑战 3/241.数据库建表信息2.后续进度安排3. 数据处理和分析 3/17 当前周期目标:构建基本的python环境:运行爬虫程序 1.配置阿里云pytho…...
(一)基于IDEA的JAVA基础7
关系运算符 运算符 含义 范例 结果 等于 12 false ! 不等于 1!2 true > 大于 1>2 false < 小于 …...
MySQL数据库概念及MySQL的安装
文章目录 MySQL数据库一、数据库基本概念1、数据2、数据表3、数据库4、数据库管理系统(DBMS)4.1 数据库的建立和维护功能4.2 数据库的定义功能4.3 数据库的操纵功能4.4 数据库的运行管理功能4.5 数据库的通信功能(数据库与外界对接࿰…...
redis实际应用场景及并发问题的解决
业务场景 接下来要模拟的业务场景: 每当被普通攻击的时候,有千分之三的概率掉落金币,每回合最多爆出两个金币。 1.每个回合只有15秒。 2.每次普通攻击的时间间隔是0.5s 3.这个服务是一个集群(这个要求暂时不实现) 编写接口&…...

考研数学|汤家凤《1800》基础部分什么时候做完?
从我个人的经验来看,做完汤家凤1800的基础部分在第一轮复习中并不是必须的,但是可以作为一个有效的复习工具。 我认为汤家凤1800的基础部分确实涵盖了考研高数的基础知识点,并且题目难度适中,适合用来巩固基础。在第一轮复习中&a…...
)
JS的设计模式(23种)
JavaScript设计模式是指在JavaScript编程中普遍应用的一系列经过验证的最佳实践和可重用的解决方案模板,它们用来解决在软件设计中频繁出现的问题,如对象的创建、职责分配、对象间通信以及系统架构等。 设计模式并不特指某个具体的代码片段,…...
[自研开源] MyData v0.7.5 更新日志
开源地址:gitee | github 详细介绍:MyData 基于 Web API 的数据集成平台 部署文档:用 Docker 部署 MyData 使用手册:MyData 使用手册 试用体验:https://demo.mydata.work 交流Q群:430089673 介绍 MyData …...
3月份的倒数第二个周末有感
坐在图书馆的那一刻,忽然感觉时间的节奏开始放缓。今天周末因为我们两都有任务需要完成,所以就选了嘉定图书馆,不得不说嘉定新城远香湖附近的图书馆真的很有感觉。然我不经意回想起学校的时光,那是多么美好且短暂的时光。凝视着窗…...

Java 变得越来越像 Rust
Java 变得越来越像 Rust 介绍 随着编程的增强和复杂性越来越流行,许多编程语言也相互效仿。 Java 也不例外。 尽管社区内部存在问题,Rust 仍逐年赢得了开发人员的喜爱。并且有充分的理由:由于编译器,Rust 使开发人员能够避免整…...

通过git bash 或命令行ssh访问服务器 sftp上传下载文件
上传下载文件 sftp -P 端口 appywIP 示例:sftp -P 10022 appyw25.222.133.222 然后输入密码即可 ls 查看文件 lls 查看本地文件 cd 跳转 lcd 本地跳转 get ... 下载文件 put 本地文件名 远程文件夹 //上传文件 put -r 本地文件夹 远程文件夹 //上传文件夹服务器…...
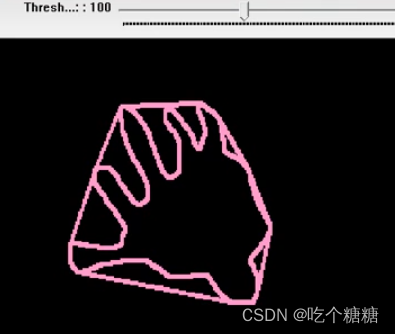
27 OpenCV 凸包
文章目录 概念Graham扫描算法convexHull 凸包函数示例 概念 什么是凸包(Convex Hull),在一个多变形边缘或者内部任意两个点的连线都包含在多边形边界或者内部。 正式定义: 包含点集合S中所有点的最小凸多边形称为凸包 Graham扫描算法 首先选择Y方向最低…...
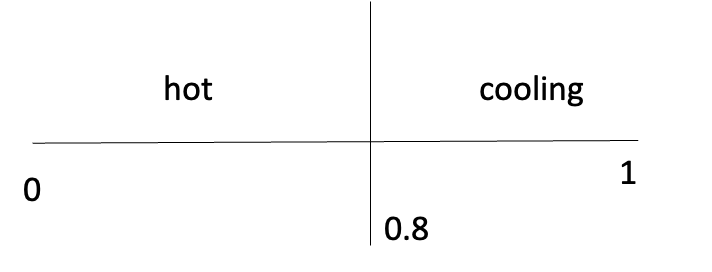
【GPT概念04】仅解码器(only decode)模型的解码策略
一、说明 在我之前的博客中,我们研究了关于生成式预训练转换器的整个概述,以及一篇关于生成式预训练转换器(GPT)的博客——预训练、微调和不同的用例应用。现在让我们看看所有仅解码器模型的解码策略是什么。 二、解码策略 在之前…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...

API渗透测试:契约驱动的协议/语义/架构三层攻防
1. 为什么“API渗透测试”不是Web渗透的简单延伸?很多人刚接触API安全时,第一反应是:“不就是把Burp Suite抓到的HTTP请求换个参数发一发?跟测网页表单差不多。”我2018年第一次接手某金融类SaaS平台的API安全评估时,也…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...
)
Claude服务治理架构升级(生产环境零停机迁移实录)
更多请点击: https://codechina.net 第一章:Claude服务治理架构升级(生产环境零停机迁移实录) 为应对日益增长的推理请求量与多租户策略精细化需求,我们对Claude服务治理层实施了从单体API网关向云原生服务网格的平滑…...