llvm后端
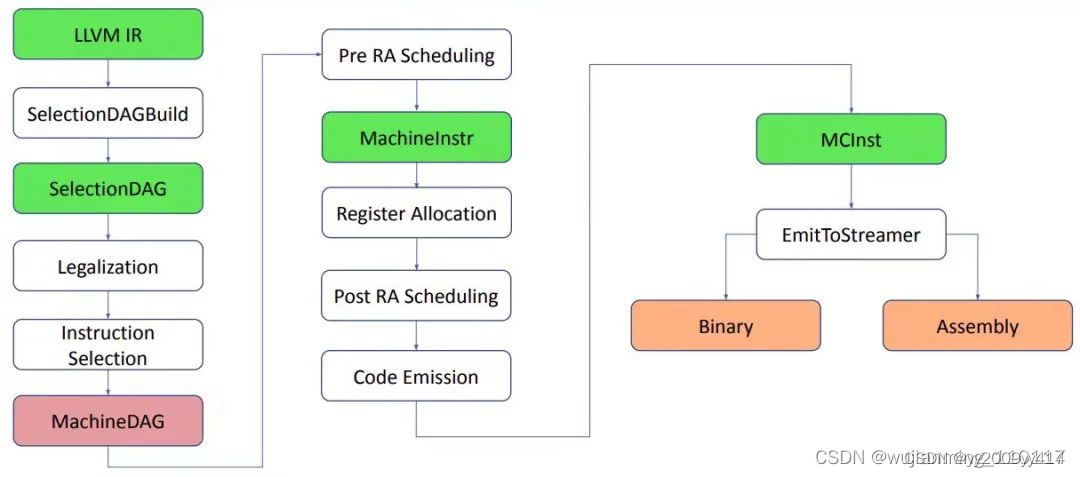
SelectionDAGBuilder是LLVM(Low Level Virtual Machine)编译器中的一个重要组件,它负责将LLVM中间表示(Intermediate Representation,IR)转换为SelectionDAG(选择有向无环图)的形式。之前我们分析ir都是抽象出value和use,并且每一条ir都是从clang的ast遍历而来(use关系在ast中如何表示?),我们有function,bb块,instruction,现在要做的是拆分每一条instruction,也就是抽象出操作码和操作数。
所以selectionDAGBuilder遍历LLVM IR中的每个函数以及函数中的基本块(basic block)。每个基本块对应一个输出的SelectionDAG对象,而基本块中的每条指令则对应生成一个SDNode对象。SDNode是SelectionDAG中的节点,它表示一种操作或指令。SelectionDAGBuilder对于每一条指令执行visit操作,将操作数保存为SDValue对象,并为指令生成对应的SDNode节点。
接着对每一个selectionDAG对象都有如下优化:
-
公共子表达式消除:通过识别并重用相同的计算,避免重复计算相同的值。这可以通过在SelectionDAG中查找并合并相同的子图来实现。
-
常量折叠:在编译时计算常量表达式的值,并将其替换为结果常量。这可以减少运行时的计算量。
-
无用代码删除:删除不会产生结果或不会对程序状态产生影响的指令。例如,删除对未使用值的计算或删除死代码。
-
指令重排:通过重新排列指令的顺序,优化程序的执行效率。这可以利用处理器的指令级并行性,减少指令间的依赖关系,提高指令的吞吐量。
当然还有合法化:
SelectionDAG(选择有向无环图)的legalization(合法化)过程是一个重要的阶段,它确保SelectionDAG中的所有节点都能直接映射到目标硬件平台支持的操作上。换句话说,legalization的目标是保证DAG中的每个操作都是“合法”的,能够被硬件直接执行。
SelectionDAG的legalization过程通常包括两个主要方面:类型合法化(type legalization)和操作合法化(operation legalization)。
-
类型合法化(Type Legalization):
类型合法化主要处理那些目标架构不支持的数据类型。编译器会检查SelectionDAG中每个节点的数据类型,如果发现不支持的类型,就会进行转换。转换可能包括将数据类型的大小调整为硬件支持的大小,或者将数据拆分为多个较小的部分。类型合法化通常先于操作合法化进行,以确保在后续处理中,所有节点的数据类型都是硬件所支持的。 -
操作合法化(Operation Legalization):
操作合法化处理那些目标架构不支持的指令或操作。编译器会遍历SelectionDAG中的每个节点,检查其对应的操作是否可以在目标硬件上直接执行。如果遇到不支持的操作,编译器会尝试将其转换为一系列支持的操作。这可能包括将复杂指令分解为更简单的指令序列,或者引入额外的指令来处理特定的操作数。
在legalization过程中,编译器可能会引入新的节点到SelectionDAG中,以表示类型转换或操作分解的结果。这个过程需要仔细处理,以确保新引入的节点不会破坏原有DAG的结构和语义。
legalization是LLVM编译器后端中非常关键的一步,它确保了从LLVM IR转换到目标机器代码的过程中,生成的代码是符合目标硬件平台规范的。通过legalization,编译器能够充分利用目标硬件的功能,同时避免生成无法执行的代码。
不同类型的目标硬件平台可能具有不同的指令集和约束条件,因此legalization的具体实现可能会因目标平台的不同而有所差异。不同的硬件平台可能有不同的数据类型支持、寄存器大小和操作数限制,因此类型合法化的策略也会有所不同。LLVM的灵活性和可移植性使得它能够支持多种不同的目标平台,并通过相应的legalization策略来生成高效的机器代码。
当遇到目标架构不支持的数据类型时,编译器需要将这些数据类型拆分为较小的、硬件支持的部分。这个过程通常涉及将大型数据类型(如宽整数或向量)分解为更小的数据类型(如标准的32位或64位整数)。
举一个具体的类型合法化例子来说明这个过程:
假设我们有一个128位的整数数据类型,但是目标架构只支持最多64位的整数操作。在这种情况下,类型合法化会将这个128位的整数拆分为两个64位的整数。
拆分的过程可能涉及以下步骤:
-
识别不合法类型:编译器首先会识别出SelectionDAG中哪些节点的数据类型是不被目标硬件支持的。在这个例子中,它会找到所有128位整数的节点。
-
创建新节点:对于每个不合法类型的节点,编译器会创建新的节点来表示拆分后的数据类型。在这个例子中,对于每个128位整数节点,编译器会创建两个64位整数节点。
-
更新操作:原始节点上的操作需要根据拆分后的数据类型进行更新。这可能意味着将单个操作拆分为多个操作,每个操作处理拆分后的一部分数据。例如,一个128位的加法操作可能会被拆分为两个64位的加法操作。
-
连接新节点:新创建的节点需要正确地连接到SelectionDAG的其余部分,以确保数据的正确流动和计算的正确性。这可能涉及添加额外的节点来处理拆分后的数据之间的交互(例如,携带进位)。
-
优化和清理:在拆分和连接新节点之后,编译器可能会进行进一步的优化和清理工作,以消除不必要的操作或节点,并改善生成的代码的质量。
举一个具体的操作合法化例子来说明这个过程:
假设在LLVM IR中有一个“原子交换”(atomic swap)指令,它原子地交换两个内存位置的值。然而,目标硬件平台可能不支持这样的原子复合操作,而只支持更简单的原子操作,如原子加载(atomic load)和原子存储(atomic store)。
在这种情况下,操作合法化可能会将原子交换指令拆分为以下步骤:
-
原子加载:首先,使用原子加载指令从第一个内存位置读取值。这个操作保证在读取值的同时不会有其他线程修改该内存位置。
-
临时存储:将加载的值存储在一个临时寄存器或内存位置中,以便后续使用。
-
原子存储:然后,使用原子存储指令将第二个内存位置的值写入到第一个内存位置。这个操作保证在写入值的同时不会有其他线程读取或修改该内存位置。
-
写入第二个内存位置:最后,将之前临时存储的值(即第一个内存位置原来的值)写入到第二个内存位置。
在SelectionDAG中,这些步骤将对应于多个节点:
- 一个节点表示原子加载操作,它有一个输入(内存地址)和一个输出(加载的值)。
- 一个或多个节点表示临时存储操作,它们将加载的值传递到下一步。
- 一个节点表示原子存储操作,它有两个输入(内存地址和要存储的值)。
- 最后一个节点表示将临时存储的值写入到第二个内存位置的操作。
通过这些拆分步骤,编译器能够将复杂的原子交换操作转换为目标硬件平台支持的更简单的原子操作序列。
指令选择是SelectionDAG的一个重要应用(SelectionDAG还有什么应用?)
-
函数内联和调用优化:SelectionDAG也可以用于函数内联和调用优化。在这个过程中,编译器可以决定将哪些函数调用内联到调用者中,以及如何优化这些内联调用以提高性能。通过分析和优化SelectionDAG中的调用节点,编译器可以做出更明智的内联和调用优化决策。(其他层做不到吗?)
-
向量化:在某些情况下,编译器可以通过将多个标量操作组合成单个向量操作来提高性能。这个过程称为向量化,它可以在SelectionDAG级别上进行。通过识别和利用数据并行性,向量化可以显著提高处理大量数据的程序的性能。
-
调试和反编译:SelectionDAG还可以用于调试和反编译目的。通过查看和分析SelectionDAG的结构和内容,开发人员可以获得有关程序计算过程和生成代码的有用信息。这对于调试编译器本身或理解编译后的代码行为非常有帮助。
-
跨平台编译:由于SelectionDAG的抽象性和通用性,它可以用于跨平台编译。通过为不同的目标硬件平台提供不同的指令选择和代码生成策略,编译器可以利用SelectionDAG为多个平台生成高效的机器代码。(cuda兼容?)
-
寄存器分配:SelectionDAG还可以用于寄存器分配。在这个过程中,编译器会为每个需要存储的值分配一个寄存器(如果可能的话),或者将其溢出到内存中。通过有效的寄存器分配,编译器可以最大化利用目标硬件平台的寄存器资源,从而提高生成代码的性能。
-
代码生成:在指令选择之后,SelectionDAG可以进一步用于代码生成。通过将SelectionDAG中的节点转换为机器指令,编译器可以为目标硬件平台生成可执行的机器代码。(intrinsic函数)
-
优化:SelectionDAG支持各种优化,如常量折叠、公共子表达式消除、死代码删除等。这些优化可以在指令选择之前或之后进行,以提高生成代码的质量和效率。
指令选择的过程大致如下:
-
构建SelectionDAG:首先,使用SelectionDAGBuilder遍历LLVM IR中的每个基本块,将每个基本块转换为一个SelectionDAG。在这个过程中,LLVM IR中的每条指令都被转换为一个或多个SDNode节点。
-
优化SelectionDAG:对构建的SelectionDAG进行上述的优化操作,以提高生成代码的质量和效率。
-
指令匹配与选择:使用指令选择算法(如基于模式的匹配算法)遍历SelectionDAG中的节点,将每个节点映射到目标机器的具体指令上。这个过程需要考虑目标机器的指令集、寄存器分配、指令的延迟和吞吐量等因素。
-
生成机器指令:根据指令选择的结果,生成目标机器的具体指令序列。这些指令序列将被用于后续的寄存器分配、指令调度和代码发射等阶段。
在实际的LLVM编译器中,指令选择可能涉及更多的细节和复杂的优化策略。此外,LLVM还支持多种指令选择框架,如SelectionDAG和GlobalISel(llvm ir转换成machine ir,这里又想起了mlir)等。全局指令选择(Global Instruction Selection)则试图在更大的范围内进行指令选择,以便在更大的上下文中找到更优的指令序列。这可以包括跨多个基本块的优化。在LLVM的GlobalISel框架中,“全局”还意味着该指令选择过程旨在与LLVM的其他全局优化和转换阶段(如全局值编号、内联、循环优化等)协同工作,以在整个程序范围内实现更高的优化水平。“全局”并不总是意味着在整个程序上同时进行操作。实际上,由于编译器性能和内存消耗的限制,全局优化通常是在程序的各个部分(如函数或循环)上迭代进行的。
传统的指令选择算法可能会涉及复杂的图着色、动态规划等技术,并且在某些情况下可能会成为编译器的性能瓶颈。
然而,“快速指令选择”方法则试图通过简化算法、利用启发式信息、减少搜索空间等手段来提高指令选择的效率。这些方法可能不总是能找到最优的指令序列,但它们通常能够在较短的时间内找到接近最优的解,从而提高了编译器的整体性能。
在实际应用中,“快速指令选择”方法可能涉及以下几个方面:
-
简化的指令选择算法:例如,使用基于规则的指令选择方法,其中编译器根据一组预定义的规则来快速选择指令。
-
启发式搜索:利用启发式信息来指导指令选择过程,从而避免不必要的搜索和计算。
-
缓存和重用:通过缓存先前指令选择的结果,并在相似的代码块中重用这些结果,来减少重复工作。
-
并行化:将指令选择任务分解为多个子任务,并在多个处理器核心或线程上并行执行这些任务。
快速指令选择可能需要在性能和生成代码的质量之间进行权衡。在某些情况下,为了获得更快的编译时间,可能需要牺牲一部分生成代码的性能或大小。
指令选择完得到MachineDAG ,此时就已经是机器指令(注意:此时的指令以及下一步的machineinstr也都不是具体的机器指令),可以用来执行 basic block 中的运算。所以可以在 MachineDAG 上做 Instruction Scheduling ,确定 basic block 中指令的执行顺序。(不是机器指令,不能做调度优化,因为还是抽象度有点高)。
寄存器分配前和分配后的指令调度
- 在寄存器分配前进行指令调度,可以使得编译器在优化指令顺序时不受寄存器数量的限制,从而更充分地发挥指令调度的优化效果。
- 此外,由于指令调度会改变指令的执行时机,因此也会影响指令所使用的寄存器的生命周期。在寄存器分配前进行指令调度,可以使得编译器更好地预测和规划寄存器的使用,从而为后续的寄存器分配提供更准确的信息。
- 在寄存器分配结束后再次进行指令调度的原因主要是寄存器复用等情况会增加指令间的依赖,并可能破坏在寄存器分配之前已经做好的指令调度优化。通过再次进行指令调度,编译器可以重新安排指令的执行顺序,以更好地适应已经分配的寄存器资源,并减少由于寄存器分配引入的额外依赖关系对性能的影响。这有助于确保指令能够以最优的顺序执行,从而提高处理器的利用率和程序的执行速度。
寄存器复用是指在程序执行过程中,不同的指令或数据在不同的时间点使用同一个寄存器。这种复用可以节省寄存器的数量,提高寄存器的利用率,但同时也会增加指令间的依赖关系,主要表现在以下几个方面:
-
数据依赖:如果指令A将结果存储在寄存器R中,随后指令B需要读取寄存器R中的这个结果作为输入,那么指令B就依赖于指令A的执行。这种情况下,我们不能改变这两个指令的执行顺序,也不能将它们并行执行,因为它们之间存在数据依赖关系。
-
写后写依赖(Write-After-Write, WAW):当两个或多个指令尝试向同一个寄存器写入数据时,就产生了写后写依赖。即使这些写入操作使用的是相同的数据值,也必须保证它们的顺序,以防止后续指令读取到错误的中间值。这种依赖关系要求指令按照特定的顺序执行。
-
读后写依赖(Read-After-Write, RAW):如果一个指令需要读取寄存器中的值,而另一个稍后的指令修改了这个值,就存在读后写依赖。这要求写操作必须在读操作之后执行,以保证读操作能够获取到正确的数据。
-
写后读依赖(Write-After-Read, WAR):也称为反依赖或输出依赖,这种依赖较少见,它发生在当一个指令写入寄存器,而一个先前的指令需要读取这个寄存器的值(通常是假设值不变的情况)时。尽管在实际的流水线处理器中,写后读依赖通常不会导致性能问题(因为读操作在写操作之前发生),但在指令调度和寄存器分配期间仍然需要考虑它,以确保程序的正确性。
- 写后写:
- int x = 10; // 初始写操作
- x = 20; // 第一个写操作:将x设置为20
- x = 30; // 第二个写操作:将x设置为30(覆盖之前的值)
- 在这个例子中,对变量x的连续赋值操作展示了一个写后写依赖。尽管最终x的值是30,但这两个写操作的顺序在某些上下文中可能是重要的。
- 读后写:
- int a = 10; // 初始写操作
- int b = a; // 读操作:从a读取值并存储到b中
- a = 20; // 写操作:更新a的值(这里的写操作不构成RAW依赖的一部分)
- 在这个例子中,对变量a的初始赋值(写操作)和紧接着的读取a的值到b(读操作)之间就存在一个读后写依赖。如果读操作在写操作之后执行(即违反了RAW依赖),那么b可能会得到一个错误或过时的值。
寄存器复用导致的依赖关系可能会限制指令调度的灵活性,因为指令的执行顺序必须遵守这些依赖关系,否则可能会导致数据错误或不可预知的行为。在寄存器分配后进行指令调度可以重新评估和优化指令的执行顺序,以最大程度地减少由于寄存器复用引入的依赖关系对程序性能的影响。编译器会尝试通过指令重排、插入NOP操作或使用特定的流水线调度技术来解决或隐藏这些依赖,从而提高代码的执行效率。
就是我们常见的DAG里面的sdnode之间什么红色,蓝色,黑色的依赖关系,这些关系也都是基于之前提到的以use-def关系为基础的。我们这个时候就看到编译器真正的lowering过程,它的IR承接关系是如何转换,如何保留的。
-
红色箭头(Glue Dependency)
红色箭头,即glue依赖,通常用于确保两个节点在调度过程中不会被分开。这种依赖关系不是基于数据流的,而是基于指令之间的紧密逻辑关系。例如,在某些架构上,一个指令可能需要与另一个指令紧密相连,以确保它们之间的控制流或副作用不会被中断。
例子:
假设我们有一个条件跳转指令(如
br),它根据某个条件决定程序的执行流程。在某些情况下,我们可能希望确保跳转指令之前的某个指令(如设置条件的指令)与跳转指令紧密相连,以避免其他指令插入到它们之间。在这种情况下,我们可以使用glue依赖来确保这两个指令在调度过程中不会被分开。2. 黑色箭头(Data Dependency)
黑色箭头表示数据依赖关系,即一个节点的输出被另一个节点用作输入。这是最常见的依赖类型,它确保了指令按照正确的顺序执行,以避免使用未定义的值。
例子:
考虑一个简单的算术运算,如
a = b + c。在这个例子中,加法指令的输出(即b + c的结果)被赋值指令用作输入。因此,加法指令和赋值指令之间存在数据依赖关系。在SelectionDAG中,这种依赖关系可以通过黑色箭头来表示。3. 蓝色箭头(Non-data Dependency / Chain Dependency)
蓝色箭头通常用于表示非数据依赖关系或链依赖关系。链依赖关系通常用于管理指令之间的副作用或确保内存操作的顺序。这种依赖关系不是基于数据流的,而是基于指令的执行顺序或内存访问模式。
例子:
考虑两个连续的存储指令(如
store a, memory_location1和store b, memory_location2)。虽然这两个指令之间没有直接的数据依赖关系(即一个指令的输出不是另一个指令的输入),但它们之间存在顺序依赖关系。为了确保正确的内存访问顺序(即避免内存访问冲突或未定义的行为),我们可以使用链依赖来确保第一个存储指令在第二个存储指令之前执行。在SelectionDAG中,这种依赖关系可以通过蓝色箭头来表示。
<在LLVM编译器中,MachineInstr是用于表示目标机器指令的类。它通过实例来描述目标机器指令,并且以一种非常抽象的方式管理操作码和操作数。然而,MachineInstr本身并不包含有关指令意义的信息;这些信息需要通过其他方式(如TargetInstrInfo类)来获取。>
寄存器分配的指令调度算法主要包括以下几种:
- 基于列表的调度算法(List Scheduling):
- 这是一种贪心算法,它通过构建一个待调度指令的列表,并根据某种优先级(如最早开始时间、最短执行时间等)选择指令进行调度。这种算法在每次迭代中选择一个最优(或近似最优)的指令进行调度,直到所有指令都被调度为止。
- 基于图的调度算法:
- 这类算法使用指令间的依赖关系构建图(如数据流图),并在该图上进行调度。图中的节点代表指令,边代表依赖关系。调度算法会尝试寻找图中的最长路径(关键路径),并优先调度关键路径上的指令,以最小化整体执行时间。
- 动态规划算法:
- 动态规划可以用于解决指令调度问题,尤其是当考虑指令间的依赖关系和资源限制时。通过构建一个状态空间,其中每个状态表示指令的一个部分调度,动态规划算法可以搜索最优的调度策略。然而,由于状态空间可能非常大,这种算法通常只适用于小型或中等规模的问题。
- 启发式算法:
- 启发式算法,如遗传算法、模拟退火算法或蚁群算法,也可以应用于指令调度问题。这些算法使用启发式信息(如指令的执行时间、依赖关系等)来指导搜索过程,并尝试找到近似最优的调度方案。这些算法通常能够在合理的时间内找到较好的解,但不一定能找到最优解。
-
快速算法(Fast Algo):
- 快速算法是一种更高效的指令调度算法,它旨在在较短的时间内找到较好的调度方案。与列表调度算法相比,快速算法可能采用更简洁的优先级计算方法和更快速的指令选择策略。
- 快速算法适用于对时间要求较高的场景,例如实时系统或嵌入式系统中的编译器优化。它可以在较短的时间内生成较好的代码,以满足系统的实时性要求。
-
VLIW(Very Long Instruction Word):
- VLIW是一种指令集架构(ISA),它允许在一条指令中包含多个操作,并且这些操作可以并行执行。在VLIW架构中,编译器负责将程序转换为适合并行执行的指令序列。
- VLIW调度器是一种特殊的指令调度器,它负责将程序中的操作映射到VLIW指令中的不同字段,并优化这些操作的并行执行顺序。VLIW调度器需要考虑处理器的并行执行能力和指令间的依赖关系,以生成高效的VLIW指令序列。
- VLIW架构的优点是能够充分利用处理器的并行执行能力,提高程序的性能。然而,它也要求编译器具备较高的智能和优化能力,以生成高效的VLIW指令序列。
上述算法可以单独使用或结合使用,以找到最优或近似最优的指令调度方案。此外,在选择算法时还需要考虑目标架构的特性、程序的性质以及性能要求等因素。
另外,寄存器分配前的指令调度通常与选择DAG(SelectionDAG)紧密相关。SelectionDAG是LLVM中的一个中间表示形式,用于表示程序的控制流和数据流。指令调度器会作用于SelectionDAG上的指令节点,并根据指令间的依赖关系和优先级进行调度。在调度过程中,指令可能会被重新排序、组合或优化,以提高程序的执行效率。
最后需要强调的是,寄存器分配前的指令调度和寄存器分配是两个相互关联的优化阶段。指令调度的结果会影响寄存器分配的策略和效果,而寄存器分配的结果也会反过来影响指令的执行顺序和性能。因此,在实际的编译器设计中,需要综合考虑这两个阶段的优化策略和目标架构的特性来制定合适的优化方案。
一个MachineInstr通常包含两个操作数地址和一个结果地址。这种格式使得操作完成后,原始的操作数不会被改变,结果会被存储在单独的结果地址中。具体来说,MachineInstr的三地址形式可以表示为 (A1) OP (A2) -> A3,其中 A1 和 A2 是操作数地址,A3 是结果地址,OP 是操作符。这种表示方法非常抽象,不依赖于具体的机器指令集或目标架构。
机器函数(Machine Function)是LLVM后端中的一个概念,它代表了一个完整的函数在机器代码层面的表示。机器函数包含了函数的所有机器基本块,以及与之相关的控制流和数据流信息。机器函数是编译器在将LLVM IR转换为机器代码时的工作单位。因此,可以说机器基本块是机器函数的组成部分。每个机器函数由多个机器基本块组成,这些基本块通过控制流指令(如跳转和分支指令)连接在一起,形成函数的完整执行流程。
机器基本块(Machine Basic Block, MBB)在编译器优化中是一个关键的概念。针对机器基本块的优化可以帮助提升生成代码的性能、减少不必要的操作或提升指令的调度。以下是一些针对机器基本块的常见优化技术:
-
死代码删除:在基本块内部检测并删除永远不会执行的代码,例如永远不会被用到的计算结果或永远不会被跳转的分支。
-
常量折叠和传播:如果在编译时期能确定某个变量的值是一个常量,那么可以在编译时将使用这个变量的计算折叠成一个常量值,或者将这个常量值传播到使用这个变量的其他地方。
-
公共子表达式消除:如果两个或多个表达式在基本块内计算相同的值且没有副作用,则可以消除重复的计算,只保留其中一个,并将结果重用。
-
冗余指令删除:分析基本块中的指令序列,发现并删除冗余的指令。例如,连续两次将同一个寄存器的值加载到另一个寄存器中,第二次加载可能是冗余的。
-
指令重排:在不改变程序语义的前提下,重新排列基本块内的指令以改善性能。例如,将独立的加载指令提前到需要它们之前,以隐藏内存访问的延迟。
-
指令调度:重新安排指令的执行顺序以充分利用处理器的特性,比如流水线、超标量执行、乱序执行等。
-
寄存器分配优化:尽量减少不必要的寄存器溢出,避免频繁的寄存器到内存的读写操作。这包括选择合适的寄存器以最小化寄存器间的拷贝和选择合适的时刻进行寄存器的溢出和重新加载。
-
循环优化:如果机器基本块是循环的一部分,可以进行循环展开、循环合并、循环不变量外提等优化来改善循环的性能。
-
内联优化:如果机器基本块中的函数调用在性能上是关键且被频繁调用,可以考虑将其内联展开以减少函数调用的开销。
-
virtual Register 到 physical Register 的映射有两种方式:直接映射和间接映射。
- 直接映射利用 TargetRegisterInfo 和 MachineOperand 类获取 load/store 指令插入位置
- 间接映射利用 VirtRegMap 类处理 load/store 指令。
-
寄存器分配算法有 4 种:
-
Basic Register Allocator
-
Fast Register Allocator
-
PBQP Register Allocator
-
Greedy Register Allocator
MCInst 是 LLVM 机器代码(MC)层的一部分,它封装了一条具体的机器指令的所有信息。
- 操作码(Opcode):指令的唯一标识符,用于区分不同类型的指令(如加法、减法、跳转等)。
- 操作数(Operands):指令的输入和/或输出。操作数可以是寄存器、内存地址、立即数(常量)或其他类型的值。
- 其他指令属性:这可能包括条件码、预测提示、异常处理等。
MI与MCInst的不同:
- MachineInstr (MI):
- 高级抽象:
MachineInstr是LLVM编译器中间表示(IR)中的一个高级抽象,用于表示目标无关的机器指令。这意味着它包含了足够的信息来支持各种复杂的编译器优化,如指令调度、寄存器分配、指令选择等。 - 丰富的语义信息:MI实例不仅包含操作码和操作数,还包含诸如指令的副作用、使用的隐式寄存器、指令之间的依赖关系等丰富的语义信息。
- 优化友好:由于MI的丰富性,编译器可以在指令选择后的优化阶段对MI进行复杂的分析和转换,以生成更高效的代码。
- 高级抽象:
- MCInst (MCI):
- 低级抽象:
MCInst是一个较低级别的抽象,更接近于目标机器的实际指令编码。它主要用于代码生成(code emission)阶段,在这一阶段,编译器将高级的机器指令表示转换为具体的目标机器代码。 - 精简的信息:与MI相比,MCI通常只包含生成目标机器代码所需的最基本信息,如操作码、操作数及其格式。它不包含MI中用于编译器优化的额外信息。
- 目标相关:MCI更加关注于目标机器的细节,如指令编码、操作数大小和对齐等。因此,MCI实例通常与目标机器的指令集架构(ISA)紧密相关。
- 低级抽象:
MCInst 的作用
-
指令编码:
MCInst提供了将高级语言或中间代码转换为机器代码的关键桥梁。它允许编译器以一种与目标机器无关的方式处理指令,从而简化了跨平台编译的复杂性。 -
优化和转换:在编译器的优化阶段,
MCInst可以作为优化算法(如指令重排、常量折叠、无用代码删除等)的输入。由于它包含了完整的指令信息,编译器可以更容易地分析和修改这些指令。 -
寄存器分配和溢出处理:在寄存器分配阶段,编译器使用
MCInst中的信息来确定哪些虚拟寄存器可以映射到物理寄存器,哪些需要溢出到内存。这涉及到复杂的图着色算法或其他寄存器分配技术。 -
代码生成和发射:最终,
MCInst被用于生成目标机器上的二进制代码或汇编代码。编译器会将MCInst中的操作码和操作数编码为机器可以执行的指令格式,并将其写入目标文件或可执行文件。 -
调试和分析:
MCInst还为开发者提供了调试和分析编译器行为的能力。通过检查生成的MCInst,开发者可以了解编译器是如何将源代码转换为机器代码的,以及在这个过程中进行了哪些优化和转换。
MCInst的填充(MCInst Population):
- 在LLVM中,这个过程是通过各种内部数据结构和算法实现的,包括MachineInstrInfo、TargetInstrInfo、MCInstBuilder等。MCInstBuilder类通常用于创建MCInst实例
- 当寄存器分配完成后,编译器会用分配好的物理寄存器替换MCInst中的虚拟寄存器引用。此外,还会根据需要设置MCInst中的其他字段,如条件码、操作数大小等,根据给定的操作码和操作数来填充它们
- 编译器后端会根据目标机器的ABI(应用程序二进制接口)和调用约定来生成正确的MCInst
- 最终,编译器将生成的MCInst序列输出为目标文件,如ELF、COFF、Mach-O等格式,或者将它们直接传递给汇编器进行后续的链接和处理。
LLVM的MC(Machine Code)层是LLVM中处理机器级别代码的一层,它主要负责将更高级别的中间表示(如LLVM IR)转换为机器代码。除了MCInst之外,MC层还包含其他几个重要的组件和类。
-
MCAsmParser:这是MC层中的一个关键组件,负责解析汇编文件中的指令。它将汇编指令解析为
MCInst或其他相关的操作数和数据结构。对于给定的目标架构,会有相应的MCTargetAsmParser实现来处理特定于该架构的语法和指令。 -
MCInstrInfo:这个类提供了关于目标机器指令集的信息。它包含了指令的操作码、操作数的类型和数量、指令的属性等。
MCInstrInfo对于指令的编码和解码以及寄存器分配等任务都是至关重要的。 -
MCRegisterInfo:这个类提供了关于目标机器寄存器集的信息。它定义了寄存器的名称、编号、大小、类别等属性。
MCRegisterInfo在寄存器分配、溢出处理以及指令编码等过程中发挥着重要作用。 -
MCStreamer:这是MC层中用于输出机器代码的组件。它将高级别的表示(如LLVM IR或MachineInstr)转换为低级别的MC层结构,并最终生成目标文件或可执行文件。
MCStreamer可以处理标签、符号、段信息以及实际的机器指令。 -
MCOperand:这是表示机器指令操作数的类。每个
MCInst都包含一系列MCOperand,它们代表了指令的输入和输出。MCOperand可以是寄存器、立即数、内存地址或其他类型的值。 -
MCSymbol和MCSection:这些类分别用于表示符号(如函数名、变量名等)和段(如代码段、数据段等)的信息。它们在链接和定位过程中起着关键作用。
此外,MC层还与其他LLVM子系统(如代码生成器、汇编器和反汇编器等)紧密集成,共同完成了从高级语言到机器代码的转换过程。以上列举的组件和类只是MC层中的一部分,实际上MC层还包含许多其他用于处理机器级别代码的类和工具。这些组件和类的具体实现可能会因目标架构和编译器的不同而有所差异。
LVM这样的现代编译器中,代码发射通常是由后端部分负责,它会将中间表示(如LLVM IR)转换为目标平台的机器代码。在这个过程中,LLVM的MC(Machine Code)层起着核心作用,处理从抽象的机器指令到具体的、可在特定硬件上执行的二进制指令的转换。
总的来说,MC framework 设计的目的是用来辅助产生基于 LLVM 的汇编器和反汇编器。
一. 例如 NVPTX backend 没有集成的汇编器,编译过程只能进行到发射 PTX 为止,产生 PTX 作为输出,然后依赖外部工具,比如 PTXAS 完成其余的编译步骤,如 Register Allocation 和 Code Emission。(nvcc代替了,nvcc还处理cuda语义语法,优化,ptxas可用于自定义编译流程哦)
二.在 Code Emission 的早期阶段会用机器码指令(MCInstr)取代机器指令(MachineInstr)
用MCInstr取代MachineInstr的原因在于它们服务于不同的层次和目的。
-
MachineInstr:这是编译器中间表示(IR)的一部分,通常在指令选择和优化阶段使用。MachineInstr包含丰富的信息,支持复杂的分析和转换,以优化生成的代码。在这个阶段,编译器可能进行诸如指令调度、寄存器分配等优化。
-
MCInstr:相比之下,MCInstr更接近于最终生成的机器代码。它是在机器码(MC)层次上使用的指令表示,这一层次更加关注于实际的目标机器细节,如指令编码、操作数格式等。在Code Emission阶段,编译器需要将高级别的MachineInstr转换为低级别的MCInstr,以便最终生成目标机器可以执行的二进制代码。
用MCInstr取代MachineInstr的原因在于:
- 接近硬件:MCInstr更直接地反映目标机器的指令集和编码方式,使得生成的代码更加精确和高效。
- 减少复杂性:在Code Emission阶段,编译器需要关注如何将指令正确地映射到目标机器的指令集上,而无需保留MachineInstr中用于优化的大量额外信息。(这些信息最后都是为了转换出正确,高效,语义一致的mcinst吗?所以任务完成就可以扔了)
- 灵活性:MC层次的设计允许更容易地支持多种目标架构和指令集,因为MCInstr更加贴近于硬件的实际细节。
三.和 MI 相比,MCInst 携带的程序信息较少。(一些依赖都绑定了,一些控制都理顺利?)
MCInst携带较少程序信息的主要原因是它在编译流程中的角色和目的。MCInst主要用于代码生成阶段,即将高级的机器指令表示(如MachineInstr)转换为实际的机器代码。在这一阶段,编译器已经完成了大部分的优化工作,因此不再需要MI中用于优化的额外信息。此外,为了减少生成代码的大小和复杂性,以及提高生成代码的效率,MCInst被设计为只包含生成目标机器代码所需的最基本信息。
SelectionDAG(选择有向无环图)是LLVM编译器中的一个重要组件,用于将LLVM中间表示(IR)转换为目标机器代码。在SelectionDAG的创建过程中,编译器会采用一种称为窥孔优化(Peephole Optimization)的技术。
窥孔优化是一种很局部的优化方式,编译器仅仅在一个基本块或者多个基本块中,针对已经生成的代码,结合CPU指令的特点,通过一些可能带来性能提升的转换规则,或者通过整体的分析,通过指令转换,提升代码性能。这个窥孔可以认为是一个滑动窗口,编译器在实施窥孔优化时,就仅仅分析这个窗口内的指令。窥孔优化通常很小,只需很少的内存,执行速度很快,可以多次调用以尽可能提升性能。
SelectionDAG的创建过程可以被视为一种基本的窥孔算法,因为在这个过程中,编译器会分析并优化LLVM IR中的指令序列,将其转换为更高效的目标机器代码。这个过程是在一个相对较小的代码窗口(即一个基本块或几个基本块)中进行的,符合窥孔优化的局部性特点。
具体来说,SelectionDAG的创建过程中,编译器会遍历LLVM IR中的每个基本块,并根据目标机器的指令集和ABI(应用程序二进制接口)等信息,将IR指令转换为SelectionDAG中的节点。在这个过程中,编译器会应用一些窥孔优化规则,如常量折叠、无用代码删除、指令重排等,以提升生成代码的性能。
因此,可以说SelectionDAG的创建过程是一种基本的窥孔算法,它通过局部优化LLVM IR中的指令序列,生成更高效的目标机器代码。
引用:编译器LLVM-MLIR-Intrinics-llvm backend-instruction_llvm mlir-CSDN博客
相关文章:
llvm后端
SelectionDAGBuilder是LLVM(Low Level Virtual Machine)编译器中的一个重要组件,它负责将LLVM中间表示(Intermediate Representation,IR)转换为SelectionDAG(选择有向无环图)的形式。…...
【JSON2WEB】10 基于 Amis 做个登录页面login.html
【JSON2WEB】01 WEB管理信息系统架构设计 【JSON2WEB】02 JSON2WEB初步UI设计 【JSON2WEB】03 go的模板包html/template的使用 【JSON2WEB】04 amis低代码前端框架介绍 【JSON2WEB】05 前端开发三件套 HTML CSS JavaScript 速成 【JSON2WEB】06 JSON2WEB前端框架搭建 【J…...
Android 你遇到的无障碍onGesture不执行
你是不是和我一样,在开发无障碍应用的时候,翻边了Android的AccessibilityService源码 但是就是发现不了onGesture不执行的原因? 你是不是和我一样,在好多测试手机之间徘徊,发现还是不执行? 你是不是和我一…...

Java学习10
目录 一.多态: 1.方法的多态: 2.对象的多态: 3.多态的注意事项与细节: 5.多态的应用: 二.Java的动态绑定机制: 三.多态应用: 1.多态数组: 2.多态参数: 三.Object类…...

第二十章 TypeScript(webpack构建ts+vue3项目)
构建项目目录 src-- main.ts-- App.vue--shim.d.tswebpack.config.jsindex.htmlpackage.jsontsconfig.json 基础构建 npm install webpack -D npm install webpack-dev-server -D npm install webpack-cli -D package.json 添加打包命令和 启动服务的命令 {"scripts…...

白酒:陈酿过程中的老熟度评价与品质提升方法
在豪迈白酒的酿造过程中,陈酿是一个至关重要的环节。陈酿不仅能使白酒老熟,提品质,还能发展出与众不同的风味和口感。云仓酒庄深知陈酿的重要性,并进行了深入的研究和实践。本文将探讨陈酿过程中的老熟度评价与品质提升方法。 首先…...
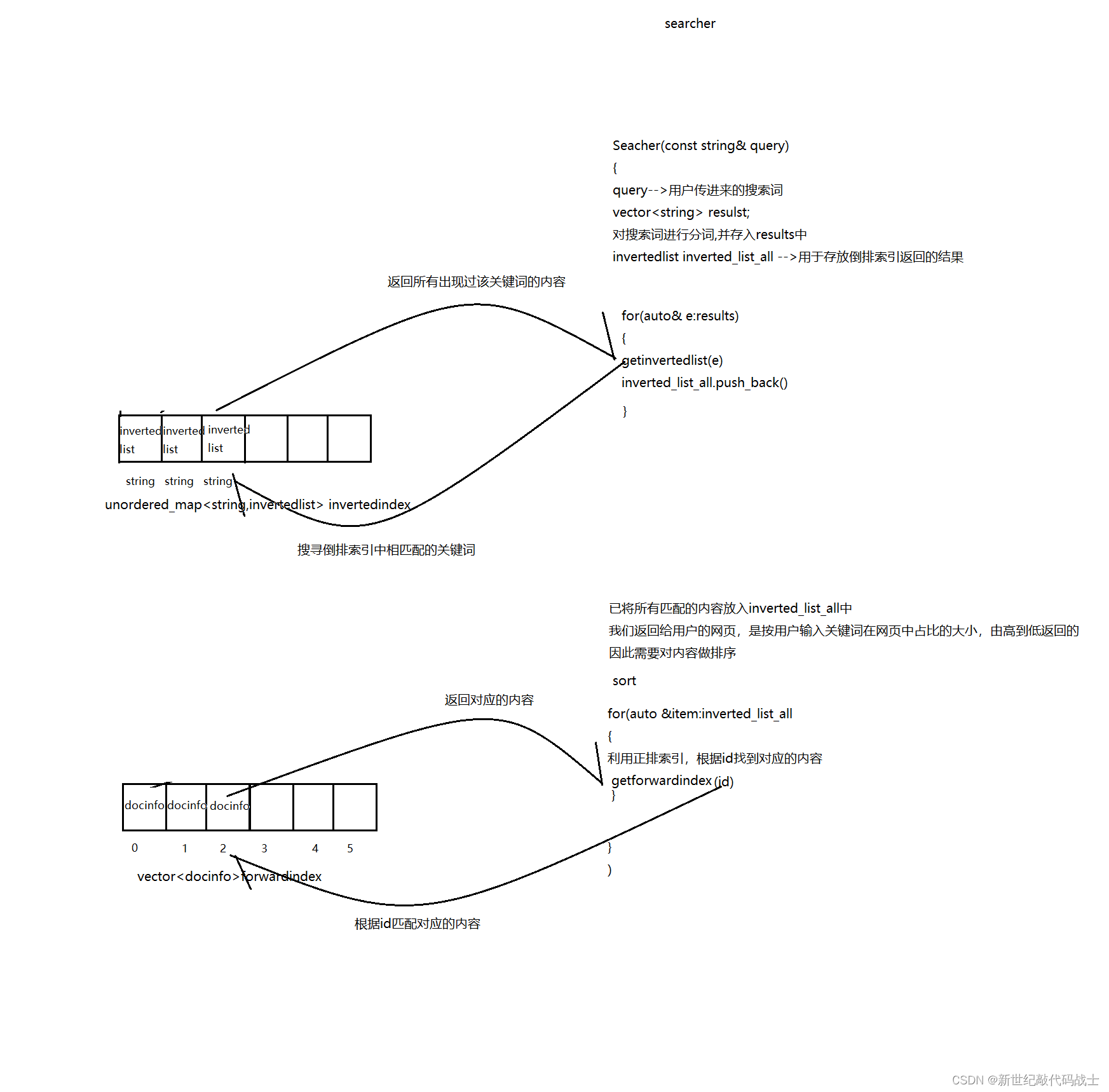
BoostSeacher
前言: 基于Boost库的搜索引擎 为何基于Boost库? 从技术上说:这个项目用了很多Boost库的接口从搜索引擎存储内说:存储的内容是Boost库的内容预期效果 预期效果:用户在浏览器输入关键词,浏览器显示相关结果 STEP1&#x…...
)
我的算法刷题笔记(3.18-3.22)
我的算法刷题笔记(3.18-3.22) 1. 螺旋矩阵1. total是总共走的步数2. int[][] directions {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};方位3. visited[row][column] true;用于判断是否走完一圈 2. 生命游戏1. 使用额外的状态22. 再复制一份数组 3. 旋转图像观…...

初探Ruby编程语言
文章目录 引言一、Ruby简史二、Ruby特性三、安装Ruby四、命令行执行Ruby五、Ruby的编程模型六、案例演示结语 引言 大家好,今天我们将一起探索一门历史悠久、充满魅力的编程语言——Ruby。Ruby是由松本行弘(Yukihiro Matsumoto)于1993年发明…...

深圳MES系统如何提高生产效率
深圳MES系统可以通过多种方式提高生产效率,具体如下: 实时监控和分析:MES系统可以实时收集并分析生产数据,帮助企业及时了解生产状况,发现问题并迅速解决,避免问题扩大化。这种实时监控和分析功能可以显著…...

QT常见Layout布局器使用
布局简介 为什么要布局?通过布局拖动不影响鼠标拖动窗口的效果等优点.QT设计器布局比较固定,不方便后期修改和维护;在Qt里面布局分为四个大类 : 盒子布局:QBoxLayout 网格布局:QGridLayout 表单布局&am…...
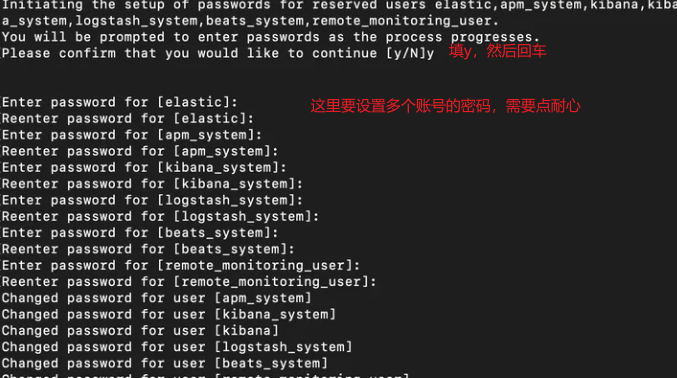
Elasticsearch8 - Docker安装Elasticsearch8.12.2
前言 最近在学习 ES,所以需要在服务器上装一个单节点的 ES 服务器环境:centos 7.9 安装 下载镜像 目前最新版本是 8.12.2 docker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.2创建配置 新增配置文件 elasticsearch.yml http.host…...

还在为不知道怎么学习网络安全而烦恼吗?这篇文带你从入门级开始学习网络安全—认识网络安全
随着网络安全被列为国家安全战略的一部分,这个曾经细分的领域发展提速了不少,除了一些传统安全厂商以外,一些互联网大厂也都纷纷加码了在这一块的投入,随之而来的吸引了越来越多的新鲜血液不断涌入。 不同于Java、C/C等后端开发岗…...
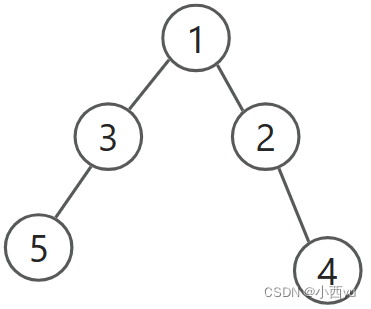
DFS基础——迷宫
迷宫 配套视频讲解 关于dfs和bfs的区别讲解。 对于上图,假设我们要找从1到5的最短路,那么我们用dfs去找,并且按照编号从大到小的顺序去找,首先找到的路径如下, 从节点1出发,我们发现节点2可以走ÿ…...

iOS开发进阶(九):OC混合开发嵌套H5应用并互相通信
文章目录 一、前言二、嵌套H5应用并实现双方通信2.1 WKWebView 与JS 原生交互2.1.1 H5页面嵌套2.1.2 常用代理方法2.1.3 OC调用JS方法2.1.4 JS调用OC方法 2.2 JSCore 实现原生与H5交互2.2.1 OC调用H5方法并传参2.2.2 H5给OC传参 2.3 UIWebView的基本用法2.3.1 H5页面嵌套2.3.2 …...

新人应该从哪几个方面掌握大数据测试?
什么是大数据 大数据是指无法在一定时间范围内用传统的计算机技术进行处理的海量数据集。 对于大数据的测试则需要不同的工具、技术、框架来进行处理。 大数据的体量大、多样化和高速处理所涉及的数据生成、存储、检索和分析使得大数据工程师需要掌握极其高的技术功底。 需要你…...

linux debian运行pip报错ssl tsl module in Python is not available
写在前面 ① 在debian 8上升级了Python 3.8.5 ② 升级了openssl 1.1.1 问题描述 在运行pip命令时提示如下错误 pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available.尝试了大神推荐的用如下方法重新编译安装python,发…...

宝塔设置限制ip后,ip改了之后 ,登陆不上了
前言 今天作死,在宝塔面板设置界面,将访问面板的ip地址限制成只有自己电脑的ip才能访问,修改之后直接人傻了,“403 forbidden”。吓得我直接网上一通搜索,还好,解决方法非常简单。 解决方法 打开ssh客户…...

解锁新功能,Dynadot现支持BITPAY平台虚拟货币
Dynadot现已支持虚拟货币付款!借助与BitPay平台的合作,Dynadot为您提供了多种安全的虚拟货币选择。我们深知每位客户都有自己偏好的支付方式,因此我们努力扩大了支付方式范围。如果您对这一新的支付方式感兴趣,在结账时您可以尝试…...

Android下的Touch事件分发详解
文章目录 一、事件传递路径二、触摸事件的三个关键方法2.1 dispatchTouchEvent(MotionEvent ev)2.2 onInterceptTouchEvent(MotionEvent ev)2.3 onTouchEvent(MotionEvent event) 三、ViewGroup中的dispatchTouchEvent实现四、总结 在Android系统中,触摸事件的分发和…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

Godot 4.3随机地图性能优化:避开TileMap与RNG陷阱
1. 为什么刚写完第一版随机地图就崩溃?——从“能跑”到“能用”的真实断层你兴冲冲地照着教程敲完几十行GDScript,RandomNumberGenerator初始化了,for x in range(width)循环也套好了,甚至还在_draw()里用draw_rect()把每个格子都…...

Lovable电商网站搭建,为什么92%的初创团队在第3周就遭遇性能雪崩?
更多请点击: https://codechina.net 第一章:Lovable电商网站搭建 Lovable 是一个面向中小商户的轻量级电商解决方案,采用现代 Web 技术栈构建,强调可扩展性、用户体验与快速部署。其核心基于 Vue 3(Composition API&a…...

MNE-Python 第9天学习笔记:源定位基础
一、什么是源定位? 1.1 通俗理解 到目前为止,我们分析的是"头皮上的脑电":头皮电极 → 记录头皮表面的电位↓这就像在地球表面测量地震波我们想知道的是:震源在哪里?多深?源定位 从头皮电位反推…...