huggingface的transformers训练bert
目录
理论
实践
理论
https://arxiv.org/abs/1810.04805

BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理(NLP)模型,由Google在2018年提出。它是基于Transformer模型的预训练方法,通过在大规模的无标注文本上进行预训练,学习到了丰富的语言表示。
BERT的主要特点是双向性和预训练-微调框架。在传统的语言模型中,只使用了单向的上下文信息,而BERT利用了双向Transformer编码器来同时考虑上下文的信息,使得模型能够更好地理解句子中的语义和关系。BERT采用了Transformer的多层编码器结构,其中包含了自注意力机制(self-attention mechanism),能够有效地捕捉句子中不同位置的依赖关系。
单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token。
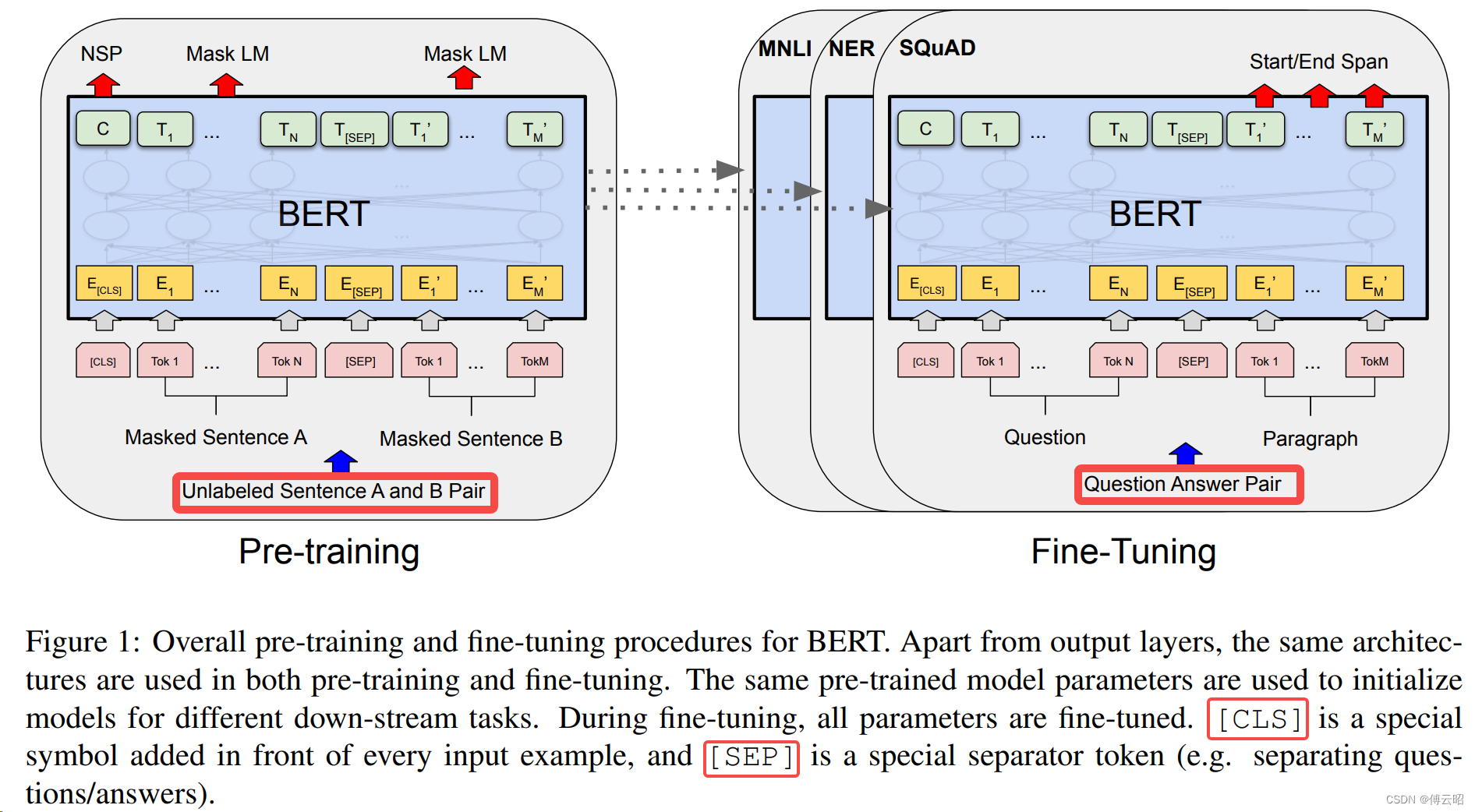
BERT模型通过两个阶段的训练来获得语言表示。首先,它在大规模无标注的文本上进行预训练,使用两个任务:掩码语言建模(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)。
在MLM任务中,随机掩盖输入句子的一些词汇,模型需要预测这些被掩盖的词汇。MLM任务的目的是让模型通过上下文来推断被掩盖的词汇,从而学习到丰富的语言表示。在预训练阶段,BERT模型会使用大规模的无标注文本进行训练,其中包括了来自维基百科、新闻文章、书籍等的文本数据。模型在这些大规模数据上进行预训练,通过尝试预测被掩盖词汇的方法来学习词汇的上下文关系和语义。在MLM任务中,模型的输入句子经过编码器(Transformer)进行编码,然后通过一个全连接层(输出层)来预测被掩盖的词汇。对于被掩盖的位置,模型会生成一个概率分布,以表示每个可能的词汇是被掩盖位置的预测。通常情况下,模型会根据预训练过程中的目标函数(如交叉熵损失)来优化预测结果。通过进行MLM任务的预训练,BERT模型能够学习到词汇的上下文信息和语义表示,从而在下游任务中具有更好的表现。在微调阶段,模型会使用有标签的数据进行进一步的训练,以适应特定任务的要求,并通过微调来提升模型在特定任务上的性能。对比gpt,中间的词只能和前面的词做attention而不能和后面的词做attention,所以没法做到上下文综合理解。
在NSP任务中,模型接收两个句子作为输入,要判断这两个句子是否是原文中的连续句子。
在预训练完成后,BERT模型可以用于各种下游任务的微调,如文本分类、命名实体识别、问答等。在微调阶段,模型会在特定任务的标注数据上进行进一步的训练,以适应具体任务的要求。只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
RoBERTa(Robustly Optimized BERT Approach)是由Facebook AI于2019年提出的一种语言模型,它是在BERT模型的基础上进行改进和优化的。RoBERTa的目标是通过更大规模的数据和更长的训练时间来获得更强大的语言表示能力。相比于BERT,RoBERTa采用了一系列的训练技巧和策略,如动态掩码、更长的训练序列、更大的批量大小等,以提升模型的性能。RoBERTa在多项自然语言处理任务上取得了显著的性能提升,并成为了当前领域内的重要基准模型之一。
实践
https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling
安装:
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
pip install -r requirements.txt
python run_clm.py \--model_name_or_path openai-community/gpt2 \--dataset_name wikitext \--dataset_config_name wikitext-2-raw-v1 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 8 \--do_train \--do_eval \--output_dir /tmp/test-clm




RobertaForMaskedLM = RobertaModel + RobertaLMHead

RobertaModel = RobertaEmbeddings + RobertaEncoder + RobertaPooler
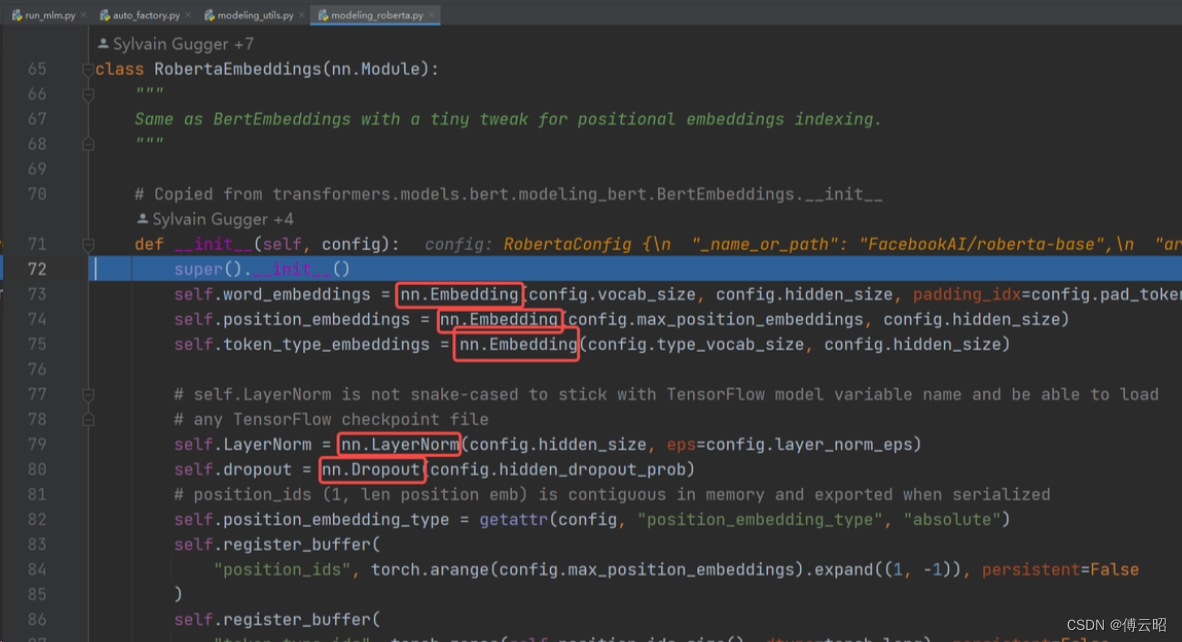
RobertaEmbeddings = nn.Embedding(word,position,token_type) + nn.LayerNorm + nn.Dropout
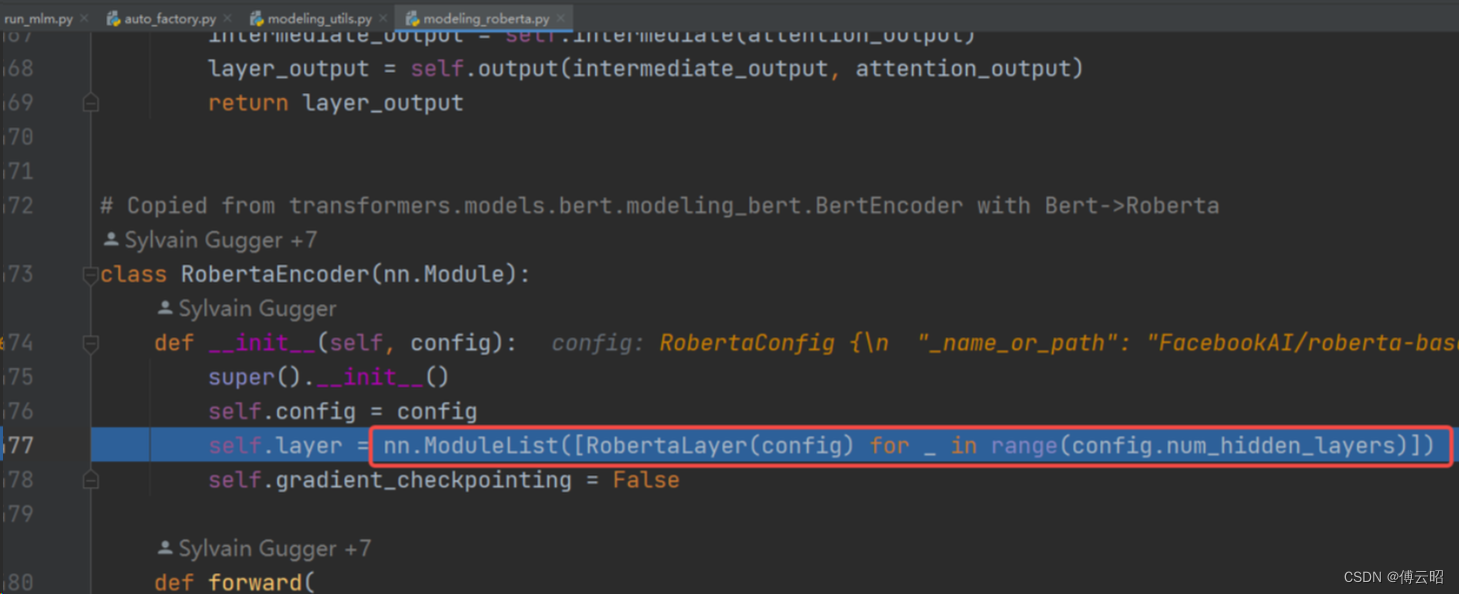
RobertaEncoder = nn.ModuleList([RobertaLayer(config))
RobertaLayer = RobertaAttention + RobertaIntermediate + RobertaOutput

RobertaAttention = RobertaSelfAttention + RobertaSelfOutput
基本上就是x--》q,k,v-->q*k-->mask-->softmax-->*v

RobertaIntermediate = Fc + activate

RobertaOutput = Linear + dropout + layernorm
RobertaPooler = Linear + 激活函数Tanh

RobertaLMHead = Linear + gelu + layernorm +linear
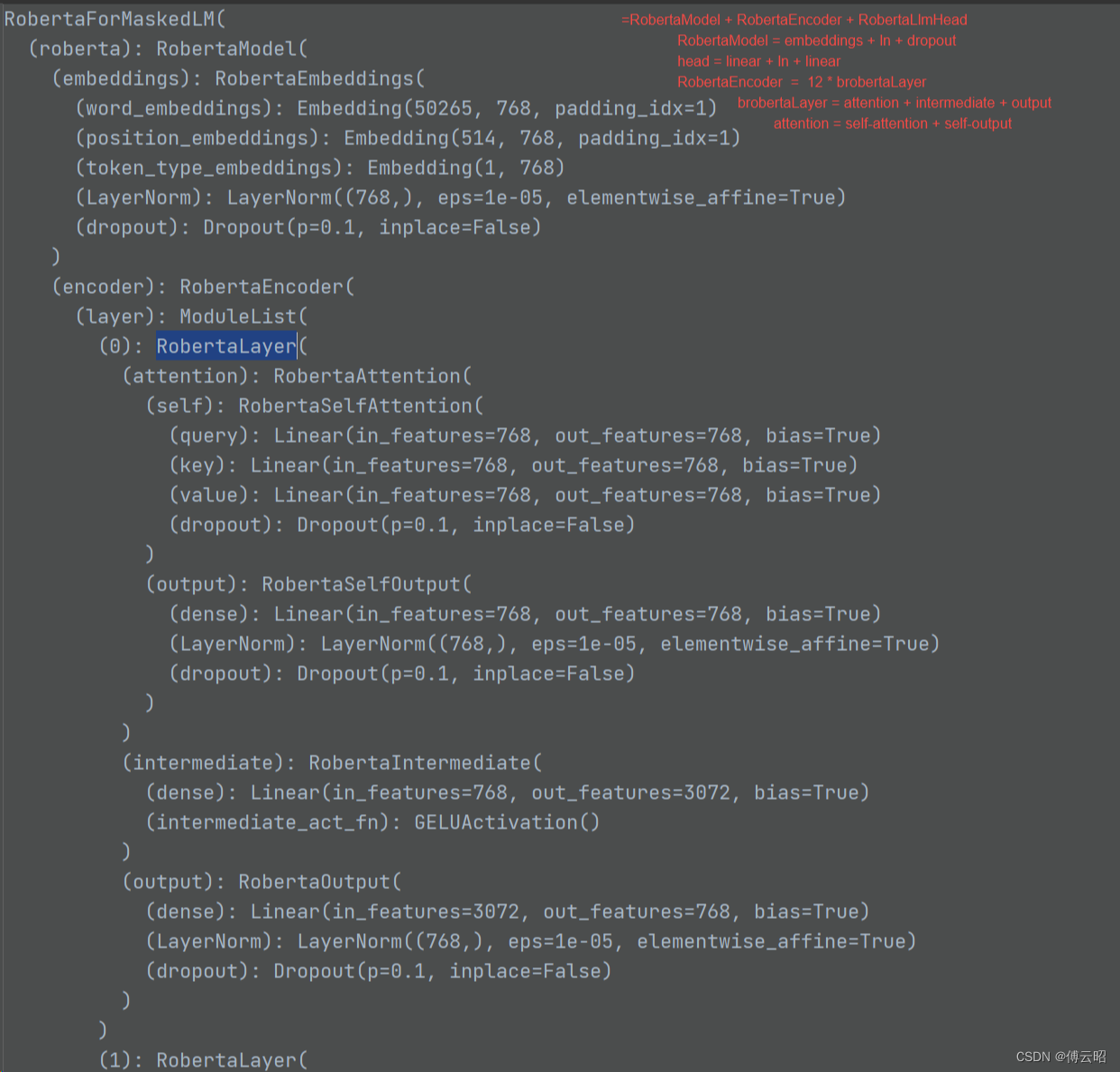
总结:
RobertaForMaskedLM = RobertaModel + RobertaLMHead
RobertaModel = RobertaEmbeddings + RobertaEncoder + RobertaPooler
RobertaEmbeddings = nn.Embedding(word,position,token_type) + nn.LayerNorm + nn.Dropout
RobertaEncoder = nn.ModuleList([RobertaLayer(config))
RobertaLayer = RobertaAttention + RobertaIntermediate + RobertaOutput * 12
RobertaAttention = RobertaSelfAttention + RobertaSelfOutput
RobertaIntermediate = Fc + activate
RobertaOutput = Linear + dropout + layernorm
RobertaPooler = Linear + 激活函数Tanh
RobertaLMHead = Linear + gelu + layernorm +linear
相关文章:
huggingface的transformers训练bert
目录 理论 实践 理论 https://arxiv.org/abs/1810.04805 BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理(NLP)模型,由Google在2018年提出。它是基于Transformer模型的预训练方法…...
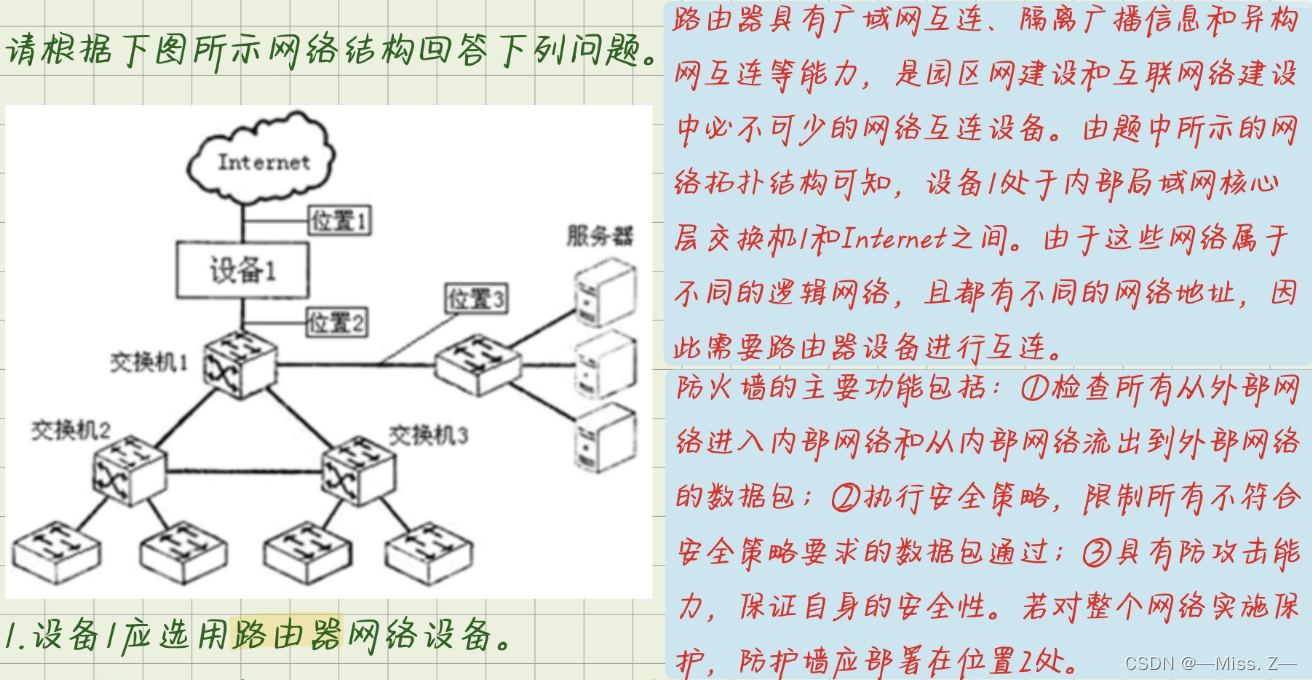
计算机三级——网络技术(综合题第五题)
第一题 填写路由器RG的路由表项①至④。 目的网络/掩码长度输出端口输出端口172.19.63.192/30S0(直接连接)172.19.63.188/30S1(直接连接) 路由器RG的S0的IP地址是172.19.63.193,路由器RE的S0的IP地址是172.19.63.194。 【解析】…...
)
C#使用ASP.NET Core Razor Pages构建网站(三)
上一篇文章了解Razor Pages 链接:C#使用ASP.NET Core Razor Pages构建网站(二) 接下来继续了解ASP.NET Core Razor Pages构建网站的后续内容 一、将Entity Framework Core配置为服务 要在 ASP.NET Core 项目中配置 Entity Framework Core 服…...
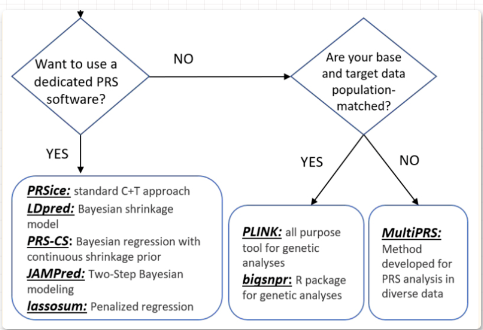
R语言迅速计算多基因评分(PRS)
Polygenic Risk Scores in R 最朴素的理解PRS: GWAS分析结果中,有每个SNP的beta值、se值、P值,因为GWAS分析中将SNP变为0-1-2编码,所以这些显著的SNP的beta值,就可以用于预测。 比如:GWAS分析中…...

蓝桥杯刷题_day3
文章目录 DAY301字串判断闰年Fibonacci数列圆的面积序列求和 DAY3 01字串 【题目描述】 对于长度为5位的一个01串,每一位都可能是0或1,一共有32种可能。它们的前几个是: 00000 00001 00010 00011 00100 请按从小到大的顺序输出这32种01串。…...

Dubbo源码解析-Provider服务暴露Export源码解析
上篇我们介绍了ServiceBean初始化和依赖注入过程,地址如下 Dubbo源码-Provider服务端ServiceBean初始化和属性注入-CSDN博客 本文主要针Dubbo服务端服务Export过程,从dubbo源码角度进行解析。 Dubbo 服务端暴露细节流程比较长,也是面试过程中…...
在微信小程序中或UniApp中自定义tabbar实现毛玻璃高斯模糊效果
backdrop-filter: blur(10px); 这一行代码表示将背景进行模糊处理,模糊程度为10像素。这会导致背景内容在这个元素后面呈现模糊效果。 background-color: rgb(255 255 255 / .32); 这一行代码表示设置元素的背景颜色为白色(RGB值为0, 0, 0)&a…...
【JavaScript】JavaScript 程序流程控制 ⑥ ( while 循环概念 | while 循环语法结构 )
文章目录 一、while 循环1、while 循环概念2、while 循环语法结构 二、while 循环 - 代码示例1、打印数字2、计算 1 - 10 之和 一、while 循环 1、while 循环概念 在 JavaScript 中 , while 循环 是一种 " 循环控制语句 " , 使用该语句就可以 重复执行一段代码块 , …...

Keil笔记(缘更)
Keil 一、使用Keil时可能会出现的问题1.Project框不见了2.添加文件时找不到3.交换文件位置4.main.c测试报1 warning5.搜索CtrlF 二、模电常识(白话随便版)一、名词解释二、基础门电路 三、STLINK点灯操作1.配置寄存器进行点灯2.使用库函数进行点灯 四.GPIO1.LED闪烁4.按键控制L…...
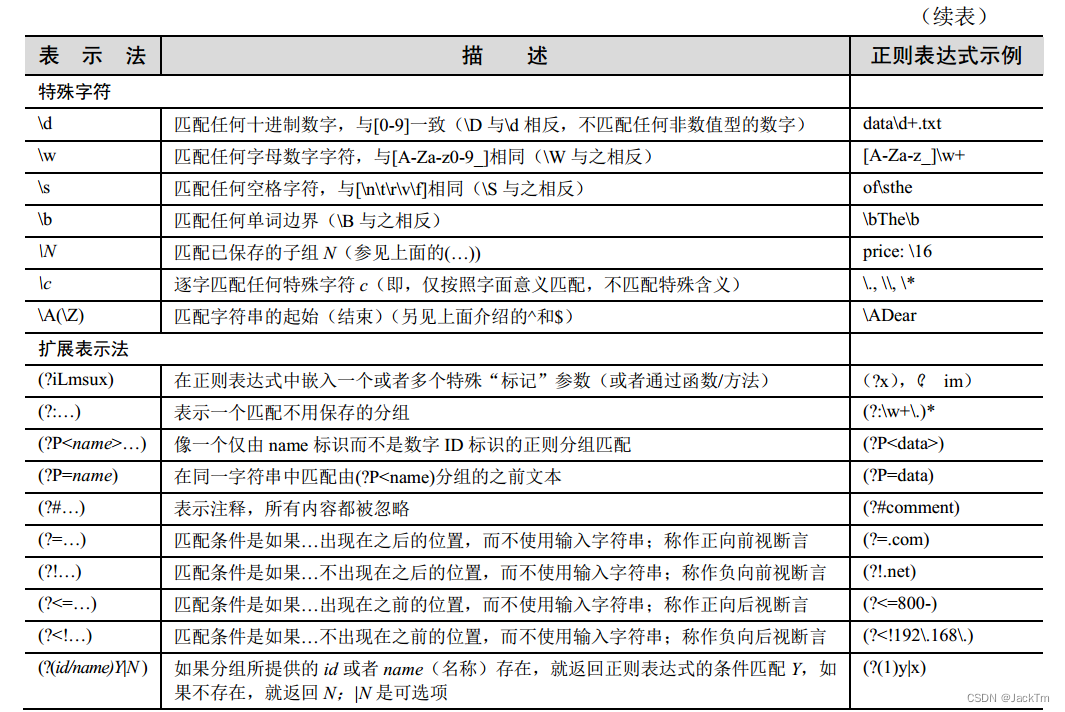
举4例说明Python如何使用正则表达式分割字符串
在Python中,你可以使用re模块的split()函数来根据正则表达式分割字符串。这个函数的工作原理类似于Python内置的str.split()方法,但它允许你使用正则表达式作为分隔符。 示例 1: 使用单个字符作为分隔符 假设你有一个由逗号分隔的字符串,你可…...
 等于多少?)
Java 中的 Math. round(-1. 5) 等于多少?
在 Java 中,Math.round() 方法用于四舍五入一个浮点数。这个方法的工作原理是,它会查看要舍入数值的小数点后第一位。如果这一位是 5 或更大,那么整数部分加 1;如果小于 5,整数部分保持不变。 对于 Math.round(-1.5)&…...
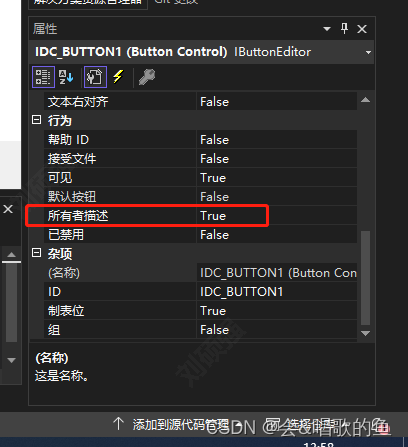
MFC界面美化第三篇----自绘按钮(重绘按钮)
1.前言 最近发现读者对我的mfc美化的专栏比较感兴趣,因此在这里进行续写,这里我会计划写几个连续的篇章,包括对MFC按钮的美化,菜单栏的美化,标题栏的美化,list列表的美化,直到最后形成一个完整…...

设计模式|工厂模式
文章目录 1. 工厂模式的三种实现2. 简单工厂模式和工厂方法模式示例3. 抽象工厂模式示例4. 工厂模式与多态的关系5. 工程模式与策略模式的关系6. 面试中可能遇到的问题6.1 **工厂模式的概念是什么?**6.2 **工厂模式解决了什么问题?**6.3 **工厂模式的优点…...
CHAT~(持续更新)
CHAT(持续更新) 实现一个ChatGPT创建API设计页面布局业务操作技术架构 实现安装工具 其他 实现一个ChatGPT 创建API 最简单也最需要信息的一步 继续往下做的前提 此处省略,想要获取接口创建方式联系 设计 页面布局 按照官网布局 业务操作…...

linux系统------------Mysql数据库介绍、编译安装
目录 一、数据库基本概念 1.1数据(Data) 1.2表 1.3数据库 1.4数据库管理系统(DBMS) 数据库管理系统DBMS原理 1.5数据库系统(DBS) 二、数据库发展史 1、第一代数据库 2、第二代数据库 3、第三代数据库 三、关系型数据库 3.1关系型数据库应用 3.2主流的…...
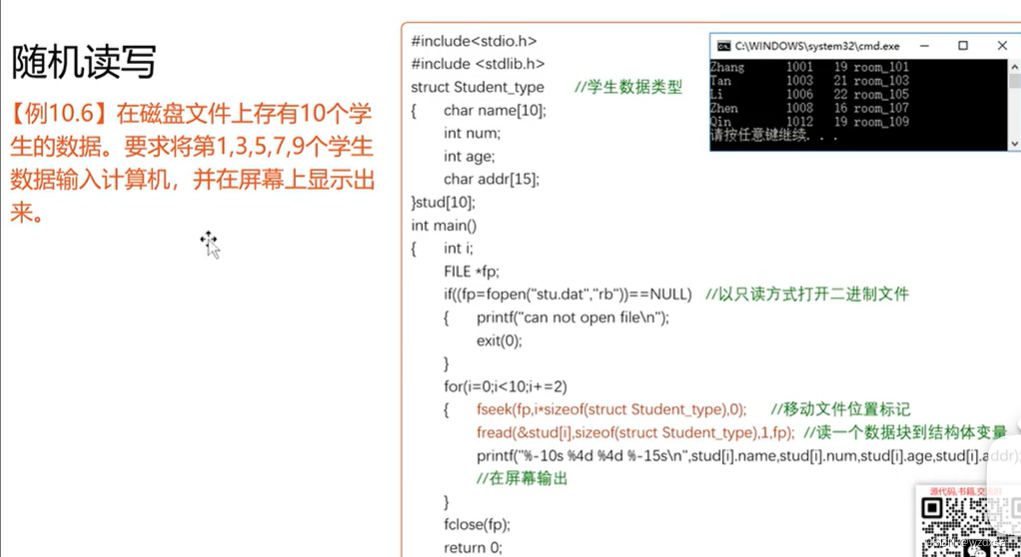
文件操作3
随机读写数据文件 一、随机读写原理 在我们写数据时,有一个光标不断的在随着新写入的数据往后移动; 而读数据时,也有一个看不见光标,随着已经读完的数据,往后移动 这里的文件读写位置标记——可以想象成图形界面里的…...

算法D57 | 动态规划17 | 647. 回文子串 516.最长回文子序列 动态规划总结篇
647. 回文子串 动态规划解决的经典题目,如果没接触过的话,别硬想 直接看题解。 代码随想录 Python: class Solution:def countSubstrings(self, s: str) -> int:n len(s)dp [[0]*n for _ in range(n)]dp[0] [1]*nresult nfor i in range(1, n)…...

go的限流
背景 服务请求下游,oom,排查下来发现是一个下游组件qps陡增导致 但是司内网络框架比较挫,竟然不负责框架内存问题(有内存管理模块,但逻辑又是无限制使用内存) 每个请求一个r、w buffer,请求无限…...

补充--广义表学习
第一章 逻辑结构 (1)A(),A是一个空表,长度为0,深度为1。 (2)B(d,e),B的元素全是原子,d和e,长度为2,深度为1。 (3)C(b,(c,…...

【笔记】KaiOS SPN显示逻辑
更新流程code 1、gonk/dom/system/gonk/radio/RadioInterfaceLayer.jsm handleNetworkStateChanged -> requestNetworkInfo() -> handleRilResponse的getOperator -> handleOperator handleNetworkStateChanged:网络状态变化请求网络信息 this.requestNetworkInfo…...

基于A2A协议将智能体注册到Nacos3.x
1.配置和简介Nacos3.x比Nacos2.x多了可以注册智能体的功能。配置密钥,32位即可启动分为集群模式和单机模式,单机模式下,默认存储在derby下。2.智能体注册中心:AgentScope也是自带注册中心的,叫AgentScopeA2aServer。现…...
)
BGP选路原则--本地优先级(LocPrf)
如果BGP收到相同的路由,首选值PrefVal如果也相同的话,那么就会继续比较下一条原则:本地优先级Local_Pref 一、拓扑图 二、配置BGP路由协议: R1 bgp 100 peer 12.1.1.2 as-number 200 peer 13.1.1.3 as-number 200 R2 bgp 200 peer 4.4.4.4 as-number 200 peer 4.4.4…...

Mac窗口置顶神器Topit:3分钟提升多任务效率的终极指南
Mac窗口置顶神器Topit:3分钟提升多任务效率的终极指南 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在Mac上同时处理多个任务ÿ…...

Wand-Enhancer终极指南:三步免费解锁WeMod专业版所有功能
Wand-Enhancer终极指南:三步免费解锁WeMod专业版所有功能 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的限制而烦恼吗&…...

OneBlog权限系统实战:RBAC与Apache Shiro的完美结合
OneBlog权限系统实战:RBAC与Apache Shiro的完美结合 【免费下载链接】OneBlog :alien: OneBlog,一个简洁美观、功能强大并且自适应的Java博客 项目地址: https://gitcode.com/gh_mirrors/on/OneBlog OneBlog是一个简洁美观、功能强大并且自适应的…...

戴森球计划终极蓝图指南:3000+工厂设计快速提升建造效率
戴森球计划终极蓝图指南:3000工厂设计快速提升建造效率 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 还在为《戴森球计划》中复杂的工厂布局而烦恼吗…...

终极指南:免费掌控AMD Ryzen处理器的SMUDebugTool调试工具
终极指南:免费掌控AMD Ryzen处理器的SMUDebugTool调试工具 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

在Ubuntu 20.04上从源码编译Spconv 1.2.1:一份给点云感知开发者的避坑指南
在Ubuntu 20.04上从源码编译Spconv 1.2.1:一份给点云感知开发者的避坑指南 对于从事3D点云感知研究的开发者来说,Spconv库的安装往往是搭建开发环境时遇到的第一个"拦路虎"。这个专为稀疏卷积优化的库,虽然在性能上表现出色&#…...

Kali Web渗透实战:从登录接口到管理员后台的完整链路
1. 这不是Kali的安装教程,而是Web渗透测试者的真实工作切片“精通 Kali Linux Web 渗透测试”——这个标题在各大技术社区里出现频率极高,但绝大多数内容要么是Kali系统安装基础命令罗列,要么是照搬OWASP Top 10概念空谈原理,真正…...

SLED框架:边缘计算中的LLM推理加速方案
1. SLED框架:边缘计算场景下的LLM推理加速方案在边缘计算环境中部署大语言模型(LLM)面临的核心矛盾在于:模型规模的持续增长与边缘设备有限的计算资源之间的不匹配。传统解决方案如模型量化(Quantization)和…...