pandas读写excel,csv
1.读excel
1.to_dict() 函数基本语法
DataFrame.to_dict (self, orient='dict' , into= ) --- 官方文档
函数种只需要填写一个参数:orient 即可 ,但对于写入orient的不同,字典的构造方式也不同,官网一共给出了6种,并且其中一种是列表类型:
- orient ='dict',是函数默认的,转化后的字典形式:{column(列名) : {index(行名) : value(值) )}};
- orient ='list' ,转化后的字典形式:{column(列名) :{[ values ](值)}};
- orient ='series' ,转化后的字典形式:{column(列名) : Series (values) (值)};
- orient ='split' ,转化后的字典形式:{'index' : [index],‘columns' :[columns],’data‘ : [values]};
- orient ='records' ,转化后是 list形式:[{column(列名) : value(值)}......{column:value}];
- orient ='index' ,转化后的字典形式:{index(值) : {column(列名) : value(值)}};
备注:
1,上面中 value 代表数据表中的值,column表示列名,index 表示行名,如下图所示:
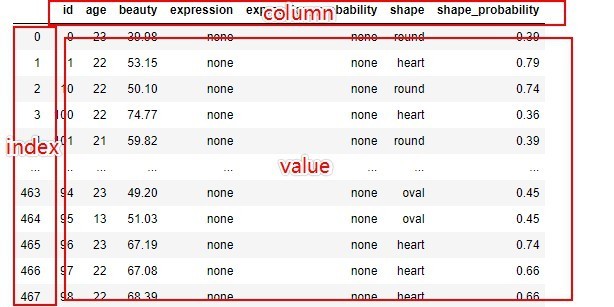
2,{ }表示字典数据类型,字典中的数据是以 {key : value} 的形式显示,是键名和键值一一对应形成的。
2,关于6种构造方式进行代码实例
六种构造方式所处理 DataFrame 数据是统一的,如下:
-
>>> import pandas as pd -
>>> df =pd.DataFrame({'col_1':[1,2],'col_2':[0.5,0.75]},index =['row1','row2']) -
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75
2.1,orient ='dict' — {column(列名) : {index(行名) : value(值) )}}
to_dict('list') 时,构造好的字典形式:{第一列的列名:{第一行的行名:value值,第二行行名,value值},....};
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('dict') -
{'col_1': {'row1': 1, 'row2': 2}, 'col_2': {'row1': 0.5, 'row2': 0.75}}
orient = 'dict 可以很方面得到 在某一列对应的行名与各值之间的字典数据类型,例如在源数据上面我想得到在col_1这一列行名与各值之间的字典,直接在生成字典查询列名为col_1:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('dict')['col_1'] -
{'row1': 1, 'row2': 2}
2.2,orient ='list' — {column(列名) :{[ values ](值)}};
生成字典中 key为各列名,value为各列对应值的列表
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('list') -
{'col_1': [1, 2], 'col_2': [0.5, 0.75]}
orient = 'list' 时,可以很方面得到 在某一列 各值所生成的列表集合,例如我想得到col_2 对应值得列表:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('list')['col_2'] -
[0.5, 0.75]
2.3,orient ='series' — {column(列名) : Series (values) (值)};
orient ='series' 与 orient = 'list' 唯一区别就是,这里的 value 是 Series数据类型,而前者为列表类型
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('series') -
{'col_1': row1 1 -
row2 2 -
Name: col_1, dtype: int64, 'col_2': row1 0.50 -
row2 0.75 -
Name: col_2, dtype: float64}
2.4,orient ='split' — {'index' : [index],‘columns' :[columns],’data‘ : [values]};
orient ='split' 得到三个键值对,列名、行名、值各一个,value统一都是列表形式;
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('split') -
{'index': ['row1', 'row2'], 'columns': ['col_1', 'col_2'], 'data': [[1, 0.5], [2, 0.75]]}
orient = 'split' 可以很方面得到 DataFrame数据表 中全部 列名或者行名 的列表形式,例如我想得到全部列名:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('split')['columns'] -
['col_1', 'col_2']
2.5,orient ='records' — [{column:value(值)},{column:value}....{column:value}];
注意的是,orient ='records' 返回的数据类型不是 dict ; 而是list 列表形式,由全部列名与每一行的值形成一一对应的映射关系:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('records') -
[{'col_1': 1, 'col_2': 0.5}, {'col_1': 2, 'col_2': 0.75}]
这个构造方式的好处就是,很容易得到 列名与某一行值形成得字典数据;例如我想要第2行{column:value}得数据:
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('records')[1] -
{'col_1': 2, 'col_2': 0.75}
2.6,orient ='index' — {index:{culumn:value}};
orient ='index'与2.1用法刚好相反,求某一行中列名与值之间一一对应关系(查询效果与2.5相似):
-
>>> df -
col_1 col_2 -
row1 1 0.50 -
row2 2 0.75 -
>>> df.to_dict('index') -
{'row1': {'col_1': 1, 'col_2': 0.5}, 'row2': {'col_1': 2, 'col_2': 0.75}} -
-
#查询行名为 row2 列名与值一一对应字典数据类型 -
>>> df.to_dict('index')['row2'] -
{'col_1': 2, 'col_2': 0.75}
2.写excel
1.pd.DataFrame.from_records例子:
数据可以作为结构化的 ndarray 提供:
>>> data = np.array([(3, 'a'), (2, 'b'), (1, 'c'), (0, 'd')],
... dtype=[('col_1', 'i4'), ('col_2', 'U1')])
>>> pd.DataFrame.from_records(data)col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d数据可以作为字典列表提供:
>>> data = [{'col_1': 3, 'col_2': 'a'},
... {'col_1': 2, 'col_2': 'b'},
... {'col_1': 1, 'col_2': 'c'},
... {'col_1': 0, 'col_2': 'd'}]
>>> pd.DataFrame.from_records(data)col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d数据可以作为具有相应列的元组列表提供:
>>> data = [(3, 'a'), (2, 'b'), (1, 'c'), (0, 'd')]
>>> pd.DataFrame.from_records(data, columns=['col_1', 'col_2'])col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d2.pd.DataFrame.from_dict例子
代码
# -*- coding: utf-8 -*-
import xlrd
import os
import pandas as pdclass ExcelReader:def __init__(self, config):"""filepath: strsheetnames: listheader_index : int"""self.path = config['filepath']self.sheetnames = config.get('sheetnames',0)header_index = config.get('header_index',0)self.data = {}if not self.sheetnames:data_xls = pd.read_excel(self.path, sheet_name=0, header=header_index, )data_xls.fillna("", inplace=True)self.data[0] = data_xls.to_dict('records')else:for name in self.sheetnames:#每次读取一个sheetname内容data_xls = pd.read_excel(self.path,sheet_name=name,header=header_index,)data_xls.fillna("",inplace=True)self.data[name] = data_xls.to_dict('records')class ExcelWriter:"""支持多写一个表格多个sheet"""def __init__(self,config):self.path = config['filepath'] # str 路径self.sheetnames = config.get('sheetnames') # list sheet nameif not self.sheetnames:self.sheetnames = []self.writer = pd.ExcelWriter(self.path)self.data = {} #key --sheet_name value -- sheet data: dict:for name in self.sheetnames:self.data[name] = {}def to_excel(self, sheet_name=None, startrow=0, index=False):if not sheet_name:for name in self.sheetnames:df = pd.DataFrame.from_records(self.data[name])df.to_excel(self.writer, sheet_name=name, startrow=startrow, index=index)else:df = pd.DataFrame.from_records(self.data[name])df.to_excel(self.writer, sheet_name=sheet_name, startrow=startrow, index=index)def write_row(self, sheet_name, row_data: dict):"""sheet_name: sheet_name 可以为不存在self.sheet_name中的值"""if sheet_name not in self.data:self.sheet_name.append(sheet_name)self.data[sheet_name] = {}for col in row_data:self.data[sheet_name][col] = [row_data[col]]returnif not self.data[sheet_name]:for col in row_data:self.data[sheet_name][col] = [row_data[col]]else:for col in self.data[sheet_name]:self.data[sheet_name][col].append(row_data.get(col,''))def save(self):"""保存并关闭"""self.to_excel() #数据写入excel对象内self.writer.save() #保存并关闭参考:
pandas 读取excel、一次性写入多个sheet、原有文件追加sheet_pandas 写入多个sheet-CSDN博客
相关文章:
pandas读写excel,csv
1.读excel 1.to_dict() 函数基本语法 DataFrame.to_dict (self, orientdict , into ) --- 官方文档 函数种只需要填写一个参数:orient 即可 ,但对于写入orient的不同,字典的构造方式也不同,官网一共给出了6种,…...
清华大学突破性研究:GVGEN技术,7秒内从文字到3D高保真生成
引言:3D模型生成的挑战与机遇 随着计算机图形学的发展,3D模型的生成在各个行业中变得越来越重要,包括视频游戏设计、电影制作以及AR/VR技术等。在3D建模的不同方面中,从文本描述生成3D模型成为一个特别有趣的研究领域,…...

软件测试要学习的基础知识——黑盒测试
概述 黑盒测试也叫功能测试,通过测试来检测每个功能是否都能正常使用。在测试中,把程序看作是一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,对程序接口进行测试,只检查程序功能是否按照需求规格…...
如何用Airtest脚本连接无线Android设备?
之前我们已经详细介绍过如何用AirtestIDE无线连接Android设备,它的关键点在于,需要先 adb connect 一次,才能点击 connect 按钮无线连接上该设备: 但是有很多同学,在使用纯Airtest脚本的形式连接无线设备时,…...
)
c语言函数大全(C开头)
c语言函数大全(C开头) There is no nutrition in the blog content. After reading it, you will not only suffer from malnutrition, but also impotence. The blog content is all parallel goods. Those who are worried about being cheated should leave quickly. 函数名…...
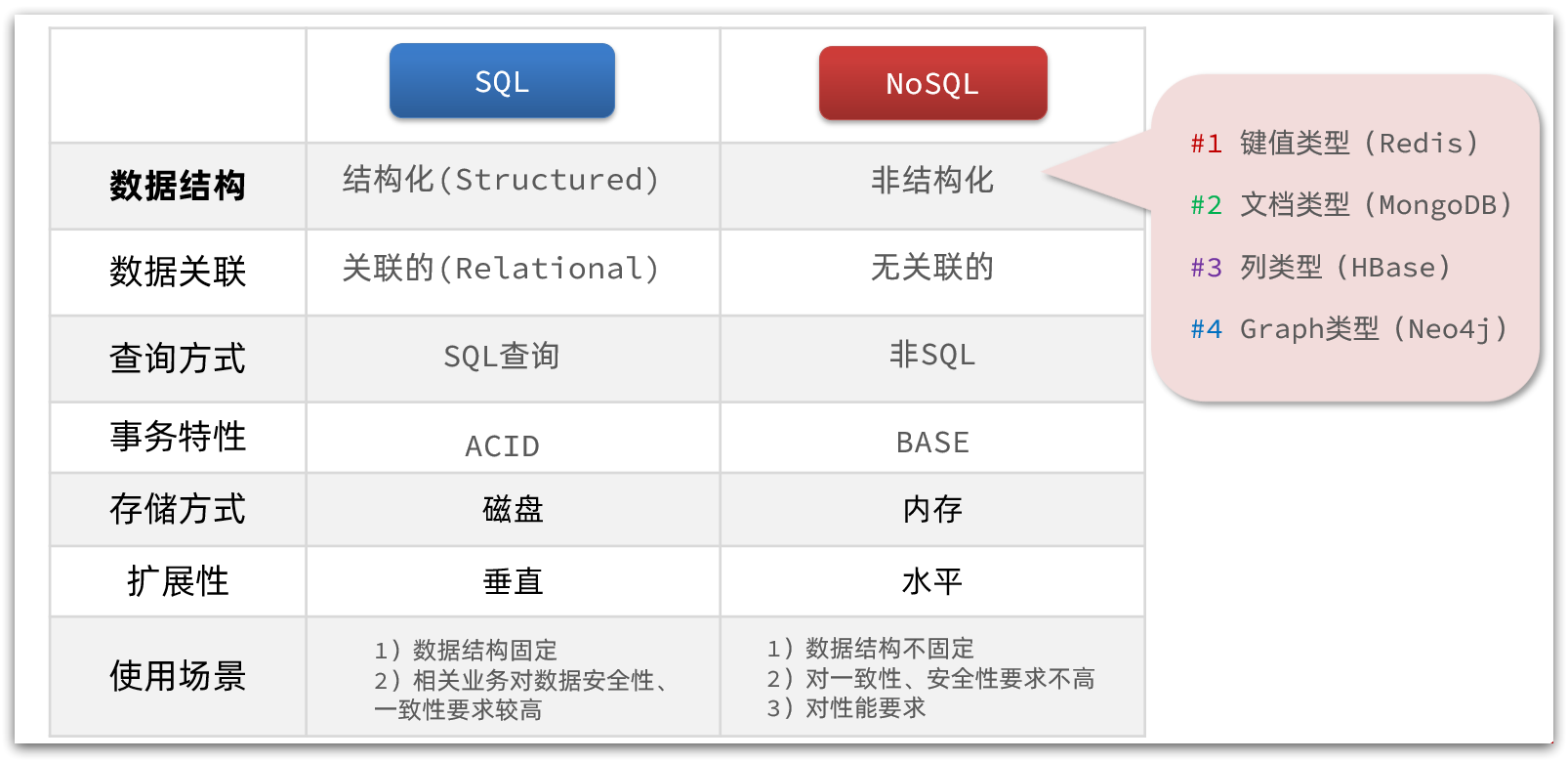
初始Redis关联和非关联
基础篇Redis 3.初始Redis 3.1.2.关联和非关联 传统数据库的表与表之间往往存在关联,例如外键: 而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合: {id: 1,name: "张三…...

Redis 更新开源许可证 - 不再支持云供应商提供商业化的 Redis
原文:Rowan Trollope - 2024.03.20 未来的 Redis 版本将继续在 RSALv2 和 SSPLv1 双许可证下提供源代码的免费和宽松使用;这些版本将整合先前仅在 Redis Stack 中可用的高级数据类型和处理引擎。 从今天开始,所有未来的 Redis 版本都将以开…...

生产者Producer往BufferQueue中写数据的过程
In normal operation, the producer calls dequeueBuffer() to get an empty buffer, fills it with data, then calls queueBuffer() to make it available to the consumer 代码如下: // XXX: Tests that fork a process to hold the BufferQueue must run bef…...

使用 Vite 和 Bun 构建前端
虽然 Vite 目前可以与 Bun 配合使用,但它尚未进行大量优化,也未调整以使用 Bun 的打包器、模块解析器或转译器。 Vite 可以与 Bun 完美兼容。从 Vite 的模板开始使用吧。 bun create vite my-app ✔ Select a framework: › React ✔ Select a variant:…...
如何设置IDEA远程连接服务器开发环境并结合cpolar实现ssh远程开发
文章目录 1. 检查Linux SSH服务2. 本地连接测试3. Linux 安装Cpolar4. 创建远程连接公网地址5. 公网远程连接测试6. 固定连接公网地址7. 固定地址连接测试 本文主要介绍如何在IDEA中设置远程连接服务器开发环境,并结合Cpolar内网穿透工具实现无公网远程连接…...
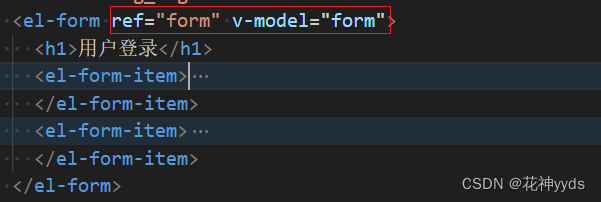
【项目管理后台】Vue3+Ts+Sass实战框架搭建二
Vue3TsSass搭建 git cz的配置mock 数据配置viteMockServe 建立mock/user.ts文件夹测试一下mock是否配置成功 axios二次封装解决env报错问题,ImportMeta”上不存在属性“env” 统一管理相关接口新建api/index.js 路由的配置建立router/index.ts将路由进行集中封装&am…...
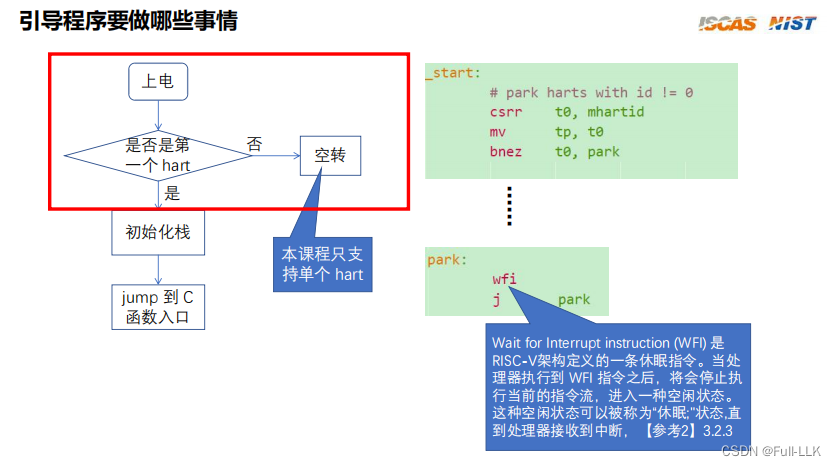
制作一个RISC-V的操作系统六-bootstrap program(risv 引导程序)
文章目录 硬件基本概念qemu-virt地址映射系统引导CSR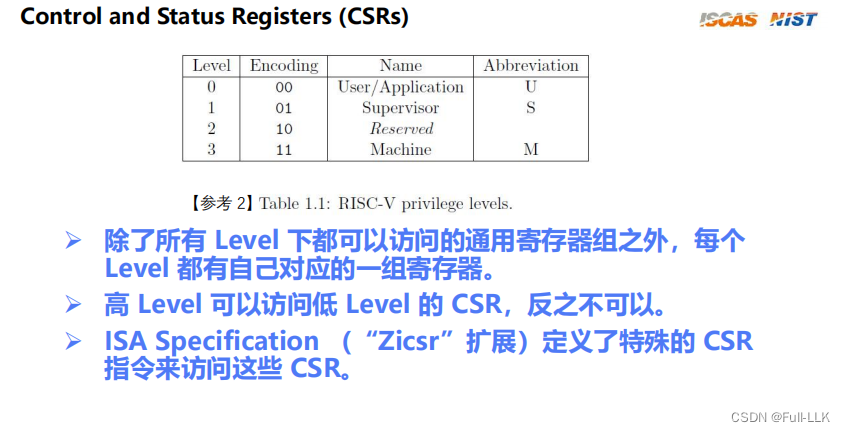machine模式下的csr对应的csr指令csrrwcsrrs mhartid引导程序做的事情判断当前hart是不是第一个hart初始化栈跳转到c语言的…...

haproxy和keepalived的区别与联系
HAProxy(High Availability Proxy) 是一个开源的、高效且可靠的解决方案,主要用于负载均衡。它工作在应用层(第七层),支持多种协议,如HTTP、HTTPS、FTP等。HAProxy通过健康检查机制持续监控后…...
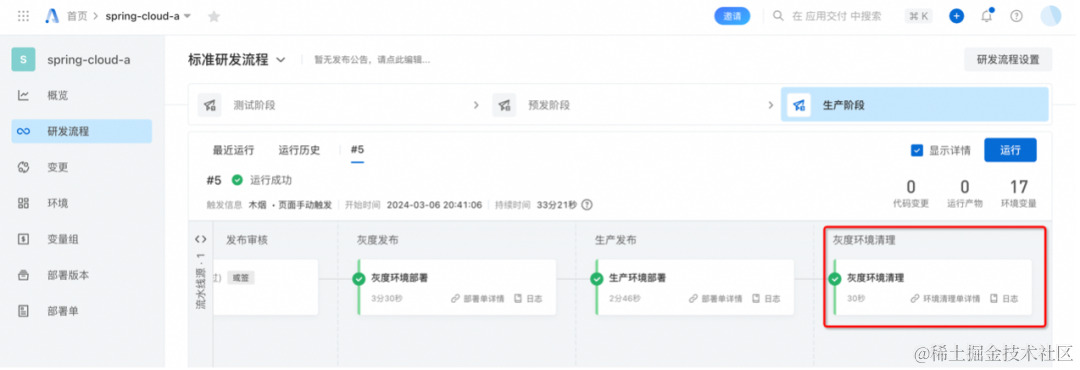
云效 AppStack + 阿里云 MSE 实现应用服务全链路灰度
作者:周静、吴宇奇、泮圣伟 在应用开发测试验证通过后、进行生产发布前,为了降低新版本发布带来的风险,期望能够先部署到灰度环境,用小部分业务流量进行全链路灰度验证,验证通过后再全量发布生产。本文主要介绍如何通…...

pta L1-004 计算摄氏温度
L1-004 计算摄氏温度 分数 5 全屏浏览 切换布局 作者 陈建海 单位 浙江大学 给定一个华氏温度F,本题要求编写程序,计算对应的摄氏温度C。计算公式:C5(F−32)/9。题目保证输入与输出均在整型范围内。 输入格式: 输入在一行中给出一个华氏…...

毕业论文降重(gpt+完美降重指令),sci论文降重gpt指令——超级好用,重复率低于4%
1. 降重方法:gpt降重指令 2. gpt网站 https://yiyan.baidu.com/ https://chat.openai.com/ 3. 降重指令——非常好用!!sci论文,本硕大论文都可使用! 请帮我把下面句子重新组织,通过调整句子逻辑࿰…...
Qt 多元素控件
Qt开发 多元素控件 Qt 中提供的多元素控件有: QListWidgetQListViewQTableWidgetQTableViewQTreeWidgetQTreeView xxWidget 和 xxView 之间的区别 以 QTableWidget 和 QTableView 为例. QTableView 是基于 MVC 设计的控件. QTableView 自身不持有数据. 使用QTableView 的 …...

LeetCode热题Hot100-两数相加
一刷一刷 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个数都不…...
Selenium 自动化 —— 浏览器窗口操作
更多内容请关注我的专栏: 入门和 Hello World 实例使用WebDriverManager自动下载驱动Selenium IDE录制、回放、导出Java源码 当用 Selenium 打开浏览器后,我们就可以通过 Selenium 对浏览器做各种操作,就像我们日常用鼠标和键盘操作浏览器一…...
二、Kubernetes(k8s)中部署项目wordpress(php博客项目,数据库mysql)
前期准备 1、关机顺序 2、开机顺序 (1)、k8s-ha1、k8s-ha2 (2)、master01、master02、master03 (3)、node01、node02 一、集群服务对外提供访问,需要通过Ingress代理发布域名 mast01上传 ingress-nginx.yaml node01、node02 上传 ingress-nginx.tar 、kube-webh…...
)
保姆级教程:用Prometheus Operator在K8S里一键搞定监控全家桶(附Grafana仪表盘)
云原生监控革命:用Prometheus Operator构建K8S智能监控体系 当Kubernetes集群规模突破50个节点时,传统监控方案的维护成本会呈指数级增长。我曾亲眼见证一个电商团队在"黑五"大促期间,因为手动配置的Prometheus抓取规则失效&#x…...

终极指南:如何用猫抓浏览器扩展构建高效的流媒体资源嗅探工作流
终极指南:如何用猫抓浏览器扩展构建高效的流媒体资源嗅探工作流 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-c…...

中兴光猫深度管理:用zteOnu工具解锁隐藏的管理权限
中兴光猫深度管理:用zteOnu工具解锁隐藏的管理权限 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 想象一下,你正在管理一个企业网络,面对几十台中兴…...

OpenAI与博通合作自研芯片,融资卡壳微软,AI军备赛进入信用背书阶段
OpenAI与Broadcom的合作及问题去年10月,OpenAI和Broadcom联合宣布战略合作,将共同部署10GW的定制AI加速器,OpenAI负责设计芯片和系统,Broadcom参与开发并负责部署,2026年下半年开始上架,2029年底前全部到位…...

深度强化学习在自动驾驶赛车中的迁移优化实践
1. 项目概述:深度强化学习在自动驾驶赛车中的迁移优化在自动驾驶赛车领域,如何将仿真环境中训练的控制策略无缝迁移到真实车辆上一直是个棘手问题。传统方法通常面临两大挑战:仿真环境与真实物理世界之间的动力学差异(即所谓的&qu…...

Windows打印服务总罢工?手把手教你排查并修复Print Spooler自动停止问题
Windows打印服务罢工?深度排查Print Spooler自动停止问题 办公室里最让人抓狂的时刻之一,莫过于点击打印后毫无反应,而打印机明明亮着绿灯。这种时候,十有八九是Windows的Print Spooler服务在"闹罢工"。作为Windows打印…...
)
Unity 2D游戏地图制作:从零上手Tile Palette的7个核心工具(附快捷键清单)
Unity 2D游戏地图制作:从零上手Tile Palette的7个核心工具(附快捷键清单)在独立游戏开发领域,2D游戏因其独特的艺术风格和相对较低的开发门槛,始终保持着旺盛的生命力。无论是复古风格的平台跳跃游戏,还是精…...

SSNet:基于Shamir秘密共享的高效安全神经网络推理框架
1. 项目概述:当神经网络推理遇上秘密共享在当今这个数据驱动决策的时代,机器学习即服务(MLaaS)正变得无处不在。无论是医疗影像分析、金融风险评估还是个性化内容推荐,用户都希望将数据提交给强大的云端模型并获得精准…...

Windows 11热键冲突别抓狂!用OpenArk一键揪出‘元凶’并释放你的Ctrl+C
Windows 11热键冲突终极排查指南:用OpenArk精准定位并解决问题每次按下CtrlC却毫无反应,或者发现AltTab突然失效时,那种挫败感简直让人抓狂。作为每天要与数十个软件打交道的设计师,我深刻理解热键冲突对工作效率的致命影响。本文…...

CVPR 2019 RKD论文复现踩坑记:从理论公式到可运行的PyTorch代码全解析
CVPR 2019 RKD论文复现实战:从数学推导到工业级PyTorch实现的关键细节当我在实验室第一次尝试复现CVPR 2019的Relational Knowledge Distillation(RKD)算法时,原以为按照论文公式直接编码就能快速跑通实验。但实际动手后才发现&am…...