【深度学习】Pytorch中实现交叉熵损失计算的方式总结
在PyTorch中,计算交叉熵损失主要有以下几种方式,它们针对不同的场景和需求有不同的实现方式和适用范围:
1. nn.CrossEntropyLoss 类
这是最常用且方便的方法,特别适用于多分类任务。nn.CrossEntropyLoss 实际上是同时完成了 softmax 函数和交叉熵损失的计算。它假设最后一层的输出没有经过归一化处理(不是概率形式),而是直接给出了各个类别的得分。该函数会自动计算每一样本对各类别的得分,应用softmax函数,然后计算交叉熵损失。
import torch
import torch.nn as nn# 假设 outputs 是模型的最后一层输出,shape 为 (batch_size, num_classes),targets 是 ground truth labels
outputs = torch.randn(100, 10) # 对于10分类问题的100个样本的不归一化的预测值
targets = torch.randint(0, 10, (100,)) # 对应的真实类别loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(outputs, targets)
print(loss.item())
2. F.cross_entropy 函数
torch.nn.functional.cross_entropy 函数也是为了多分类问题设计的,但它接受的是 logits 或者已经经过 softmax 的概率。如果你的输出已经是经过 softmax 的概率,可以直接使用;否则,它会默认内部先执行 log_softmax。
import torch.nn.functional as F# 假设 outputs 是未经 softmax 的 logits
outputs = torch.randn(100, 10)# 使用 F.cross_entropy 直接计算损失,无需单独进行 softmax
loss = F.cross_entropy(outputs, targets)
print(loss.item())
3. nn.BCEWithLogitsLoss 类(二分类问题)
对于二分类问题,尤其是sigmoid激活函数之后的结果,可以使用带Sigmoid的二元交叉熵损失函数,它同时完成 sigmoid 和 二元交叉熵损失的计算。
# 二分类问题,输出维度为 (batch_size, 1)
outputs = torch.randn(100, 1) # targets 是介于 [0, 1] 或 {-1, 1} 的值,表示正负样本
targets = torch.rand(100, 1) > 0.5 # 或者其他的二进制标签bce_loss = nn.BCEWithLogitsLoss()
loss = bce_loss(outputs, targets.float())
print(loss.item())
4. 手动计算交叉熵损失
当然,也可以手动组合 log_softmax 和 nll_loss 函数来计算交叉熵损失,这在特殊情况下可能会有用,比如需要对损失函数进行修改或者自定义的时候:
# 多分类问题,手动组合 log_softmax 和 nll_loss
output_logits = torch.randn(100, 10)
softmax_outputs = F.log_softmax(output_logits, dim=1) # 计算 log_softmax
loss_manual = -torch.mean(torch.gather(softmax_outputs, 1, targets.unsqueeze(1)).squeeze()) # 使用 gather 和 mean 计算 NLL
assert torch.allclose(loss_manual, F.nll_loss(softmax_outputs, targets, reduction='mean')) # 应该与 nll_loss 结果一致
在上述代码中,gather 函数用于从预测概率矩阵中按照目标标签索引出相应的对数概率,然后求平均得到最终的交叉熵损失。在多分类任务中,直接使用 F.nll_loss(log_softmax_outputs, targets) 是更加简洁的做法,等价于手动计算。而在二分类问题中,对应的手动计算方式则会涉及 sigmoid 和 binary_cross_entropy_with_logits 函数。
5. 补充说明
在交叉熵损失计算函数中:
L = − ∑ i = 1 n y i l o g ( S ( f θ ( x i ) ) ) L = -\sum_{i=1}^{n}{y_i}log(S(f_\theta(x_i))) L=−i=1∑nyilog(S(fθ(xi)))
真实值 y i y_i yi可以是热编码后的结果,也可以不进行热编码。
虽然在Pytorch架构中,神经网络内流动的数据类型必须是float类型,但是Pytorch也提供了自动处理整数(int类型)标签的交叉熵损失函数(这里的“整数标签”指的是每个样本所属的真实类别,通常是一个从0开始的整数索引,对应着类别数量中的一个),这些函数会自动将整数标签转换为内部使用的one-hot编码格式,并计算交叉熵损失。
以nn.CrossEntropyLoss为例,当输入给定的output是未经归一化的类别得分(logits),而target是整数标签时,这个损失函数会自动将整数标签转换为one-hot格式,然后再进行交叉熵损失的计算。这意味着用户不需要预先将目标标签转换为one-hot编码,损失函数内部会处理这样的转换过程。
import torch
import torch.nn as nn# 假设我们有一个批次的输出和对应的类别标签
outputs = torch.randn(64, 10) # 这是一个批次的输出,共64个样本,10个类别
labels = torch.tensor([2, 7, 0, ..., 4], dtype=torch.long) # 这是对应的整数类别标签loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(outputs, labels)print(f'Cross-entropy loss: {loss.item()}')
相关文章:

【深度学习】Pytorch中实现交叉熵损失计算的方式总结
在PyTorch中,计算交叉熵损失主要有以下几种方式,它们针对不同的场景和需求有不同的实现方式和适用范围: 1. nn.CrossEntropyLoss 类 这是最常用且方便的方法,特别适用于多分类任务。nn.CrossEntropyLoss 实际上是同时完成了 sof…...

机器学习:处理jira工单的分类问题
如何根据jira工单的category、reporter自动找到处理它的组呢?这是一个利用机器学习中knn算法的小实践. 目录 Knn算法 数据 示例 分割数据 选择Neighbors knn的优缺点 机器学习是一种技术,它的目的是给机器学习能力,让它们可以根据数据自己做决定,所以对于训练…...
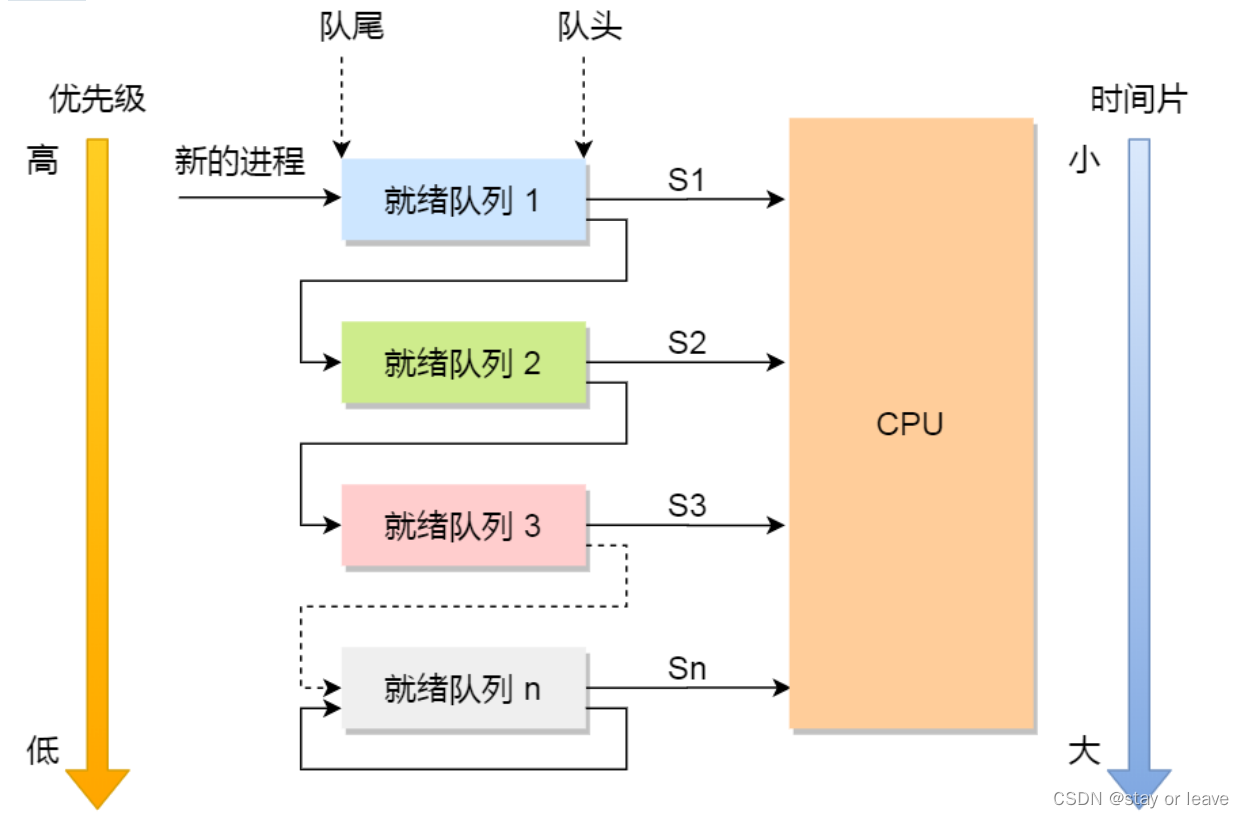
后端常问面经之操作系统
请简要描述线程与进程的关系,区别及优缺点? 本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位 在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之…...

RK3568平台 iperf3测试网络性能
一.iperf3简介 iperf是一款开源的网络性能测试工具,主要用于测量TCP和UDP带宽性能。它可以在不同的操作系统上运行,包括Windows、Linux、macOS等。iperf具有简单易用、功能强大、高度可配置等特点,广泛应用于网络性能测试、网络故障诊断和网…...

Spring Boot中实现对特定URL的权限验证:拦截器、切面和安全框架的比较
引言: 在开发Web应用程序时,对特定URL进行权限验证是一项常见的需求。在Spring Boot中,我们有多种选择来实现这一目标,其中包括使用拦截器、切面和专门的安全框架(如Spring Security)。本文将比较这三种方式…...
)
【能源数据分析-00】能源领域数据集集锦(动态更新)
一、前言 大数据科学在能源领域的深度应用,已经深刻改变了这一行业的垂直格局。它为我们提供了宝贵的见解,帮助降低下游市场的成本,使石油生产商能够更好地应对市场繁荣期的需求。近期,石油价格的剧烈下跌给全球经济带来了沉重打…...

数据挖掘与机器学习 1. 绪论
于高山之巅,方见大河奔涌;于群峰之上,便觉长风浩荡 —— 24.3.24 一、数据挖掘和机器学习的定义 1.数据挖掘的狭义定义 背景:大数据时代——知识贫乏 数据挖掘的狭义定义: 数据挖掘就是从大量的、不完全的、有噪声的、…...
)
Matlab实现序贯变分模态分解(SVMD)
大家好,我是带我去滑雪! 序贯变分模态分解(SVMD) 是一种信号处理和数据分析方法。它可以将复杂信号分解为一系列模态函数,每个模态函数代表信号中的特定频率分量。 SVMD 的主要目标是提取信号中的不同频率分量并将其重构为原始信号。SVMD的基…...

云安全与云计算的关系
云计算又被称为网格计算,是分布式计算的一种,能够将大量的数据计算处理程序通过网络“云”分解成多个小程序,然后将这些小程序的结果反馈给用户。云计算主要就是能够解决任务分发,并进行计算结果的合并。 云安全则是我国企业创造的…...
)
WPF 界面变量绑定(通知界面变化)
1、继承属性变化接口 public partial class MainWindow : Window, INotifyPropertyChanged {// 通知界面属性发生变化public event PropertyChangedEventHandler PropertyChanged;private void RaisePropertyChanged(string propertyName){PropertyChangedEventHandler handle…...

eclipse导入svn项目
1、配置maven 2、用svn引入项目 3一直点击next,到最后选完成。...
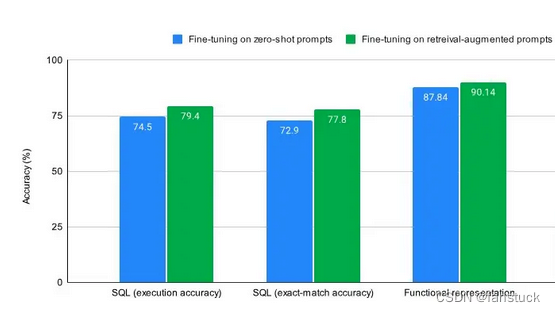
Prompt提示工程上手指南:基础原理及实践(四)-检索增强生成(RAG)策略下的Prompt
前言 此篇文章已经是本系列的第四篇文章,意味着我们已经进入了Prompt工程的深水区,掌握的知识和技术都在不断提高,对于Prompt的技巧策略也不能只局限于局部运用而要适应LLM大模型的整体框架去进行改进休整。较为主流的LLM模型框架设计可以基…...
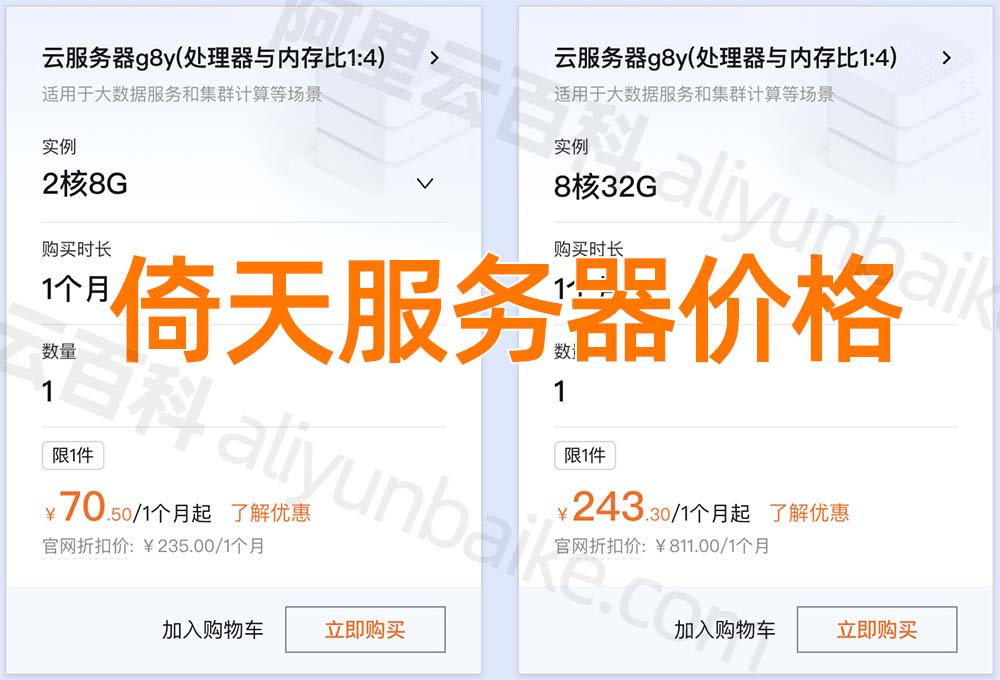
阿里云倚天云服务器怎么样?如何收费?
阿里云倚天云服务器CPU采用倚天710处理器,租用倚天服务器c8y、g8y和r8y可以享受优惠价格,阿里云服务器网aliyunfuwuqi.com整理倚天云服务器详细介绍、倚天710处理器性能测评、CIPU架构优势、倚天服务器使用场景及生态支持: 阿里云倚天云服务…...

海外社交营销为什么用云手机?不用普通手机?
海外社交营销作为企业拓展海外市场的重要手段,正日益受到企业的青睐。云手机以其成本效益和全球性特征,成为海外社交营销领域的得力助手。那么,究竟是什么特性使得越来越多的企业选择利用云手机进行海外社交营销呢?下文将对此进行…...

【Mysql数据库基础05】子查询 where、from、exists子查询、分页查询
where、from、exists子查询、分页查询 1 where子查询1.1 where后面的标量子查询1.1.1 having后的标量子查询 1.2 where后面的列子查询1.3 where后面的行子查询(了解即可) 2 from子查询3 exists子查询(相关子查询)4 分页查询5 联合…...

在Linux/Debian/Ubuntu上通过 Azure Data Studio 管理 SQL Server 2019
Microsoft 提供 Azure Data Studio,这是一种可在 Linux、macOS 和 Windows 上运行的跨平台数据库工具。 它提供与 SSMS 类似的功能,包括查询、脚本编写和可视化数据。 要在 Ubuntu 上安装 Azure Data Studio,可以按照以下步骤操作࿱…...
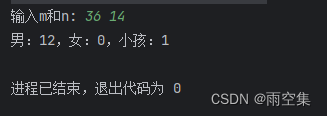
Java代码基础算法练习-搬砖问题-2024.03.25
任务描述: m块砖,n人搬,男搬4,女搬3,两个小孩抬一砖,要求一次全搬完,问男、 女、小孩各若干? 任务要求: 代码示例: package M0317_0331;import java.util.S…...

Tomcat调优
1、调整线程数 <Connector port"8080" maxHttpHeaderSize"8192"maxThreads"1900" minSpareThreads"250" maxSpareThreads"750"enableLookups"false" redirectPort"8443" acceptCount"100"…...

每日OJ题_栈①_力扣1047. 删除字符串中的所有相邻重复项
目录 力扣1047. 删除字符串中的所有相邻重复项 解析代码 力扣1047. 删除字符串中的所有相邻重复项 1047. 删除字符串中的所有相邻重复项 难度 简单 给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。 在 S 上反…...
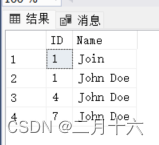
SQLServer SEQUENCE用法
SEQUENCE:数据库中的序列生成器 在数据库管理中,经常需要生成唯一且递增的数值序列,用于作为主键或其他需要唯一标识的列的值。为了实现这一功能,SQL Server 引入了 SEQUENCE 对象。SEQUENCE 是一个独立的数据库对象,用…...

WarcraftHelper:魔兽争霸3终极优化指南 - 5大方案让你的经典游戏焕发新生
WarcraftHelper:魔兽争霸3终极优化指南 - 5大方案让你的经典游戏焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔…...

Exchange渗透实战:从外部侦察到域控接管全链路
1. 这不是“黑进邮箱”的速成课,而是真实红队作业的切片回放Exchange Server 渗透测试,这个词在很多刚入行的朋友眼里,可能等同于“爆破邮箱密码”“下载邮件”“发钓鱼邮件”。但我在过去七年参与的23次企业红队评估中,真正能从外…...

物理信息神经网络建模自诱导随机共振:噪声驱动相干振荡的PINN实现
1. 项目概述:当噪声成为秩序的“推手”在神经科学和复杂系统的研究中,我们常常将噪声视为需要被滤除的“杂质”。然而,一个反直觉的现象是,在特定的非线性动力学系统中,随机噪声不仅不会破坏秩序,反而能诱导…...

Keil µVision许可证失效问题解析与解决方案
1. 问题现象与背景解析最近遇到一个挺有意思的案例:一位工程师在安装了Windows Media Center后,突然发现Keil Vision IDE变成了评估版模式。这种情况其实在嵌入式开发领域并不罕见,但很多开发者第一次遇到时都会感到困惑。本质上,…...

戴森球计划FactoryBluePrints:从零到万亿级产能的工业化蓝图解决方案
戴森球计划FactoryBluePrints:从零到万亿级产能的工业化蓝图解决方案 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints FactoryBluePrints是戴森球计划社区规模最…...

腾讯元宝生成的很多公式,复制到WORD中会乱码,我应该怎么做?
从“公式乱码”到“无损流转”:企业级AI导出工程的架构实践与反思 当AI生成的专业内容在复制粘贴中“死”于格式鸿沟,我们需要的不只是工具,而是一套结构化数据流转范式。 一、痛点复盘:一个架构师眼中的“乱码危机” 在AI辅助研…...

Windows屏幕录制全栈实现:Graphics Capture+FFmpeg零拷贝编码
1. 这不是“调个API就完事”的录制功能,而是要亲手把屏幕变成可编程的视频流管道很多人看到“FFmpeg屏幕录制”第一反应是:网上一搜,几十个C#封装库,NuGet install一下,几行代码start()就完事。我去年也这么想——直到…...
)
告别刻录光盘!用Rufus 4.5快速搞定Win10 U盘安装盘(保姆级图文指南)
用Rufus 4.5打造Win10 U盘安装盘的终极指南在数字时代,光驱已经逐渐退出历史舞台,但系统安装的需求依然存在。传统的光盘安装方式不仅速度慢,而且对硬件有要求。相比之下,U盘安装系统更加高效便捷。本文将详细介绍如何使用Rufus 4…...

量子机器学习模拟器性能优化与门层特性解析
1. 量子机器学习模拟器的性能优化之道量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,其核心挑战在于如何高效模拟量子电路的演化过程。传统量子模拟器如PennyLane的default.qubit采用通用方法处理各类量子门操作,未能充分考虑不同门类型的数学…...
手把手教你重置)
Kali Linux忘记root密码别慌!两种方法(登录态/非登录态)手把手教你重置
Kali Linux忘记root密码的终极恢复指南:从原理到实战当你正专注于一个关键的安全测试项目,突然发现无法执行需要root权限的操作——这种场景对Kali Linux用户来说并不陌生。作为渗透测试和网络安全研究的标配系统,Kali Linux的root账户是系统…...