Prompt提示工程上手指南:基础原理及实践(四)-检索增强生成(RAG)策略下的Prompt
前言
此篇文章已经是本系列的第四篇文章,意味着我们已经进入了Prompt工程的深水区,掌握的知识和技术都在不断提高,对于Prompt的技巧策略也不能只局限于局部运用而要适应LLM大模型的整体框架去进行改进休整。较为主流的LLM模型框架设计可以基于链式思考(CoT)、思维树 (ToT)和检索增强生成 (RAG)。其中RAG框架可以算得上是AI平台研发的老生常谈之一了,因为无论是个人还是企业,都想要培养出一个属于自己领域专业的AI。但伴随而来的问题,不限于产生幻觉、缺乏对生成文本的可解释性、专业领域知识理解差,以及对最新知识的了解有限。
相对于成本昂贵的“Post Train”或“SFT”解决办法,最好的技术方案还就是基于RAG框架而设计,RAG框架的核心,就像是一位内置的智能搜索引擎,能够精准地定位到与用户查询最相关的知识库内容或对话历史。这种能力使得RAG不只是回答问题,而是通过创造丰富的提示(prompt),引导模型生成更加准确、信息丰富的输出。如何在保证模型效率的同时,提高其在特定领域的精准度和可靠性?又如何避免过度依赖检索内容,确保生成的文本既新颖又具有创造性?通过探索RAG框架及其精妙的Prompt策略,我们不仅能够解锁大型语言模型的新潜能,还能够为未来的AI研究和应用指明方向。随着本文深入,我们将一起探索RAG框架背后的工作原理以及对应Prompt策略,它将如何成为连接用户需求与海量数据之间桥梁的关键技术,以及在实际应用中如何发挥出惊人的效能。
每篇文章我都会尽可能将简化涉及到垂直领域的专业知识,转化为大众小白可以读懂易于理解的知识,将繁杂的程序创建步骤逐个拆解,以逐步递进的方式由难转易逐渐掌握并实践,欢迎各位学习者关注博主,博主将不断创作技术实用前沿文章。
RAG框架概述
想象一下,当你在写一篇文章或解决一个问题时,如果遇到了难题,你会怎么做?可能会去搜索引擎查找信息,然后基于找到的信息来构建你的答案。这个过程,其实很像是RAG框架在做的事情。化繁为简,我们先来了解RAG到底是什么。先从字母意思开始理解,RAG——Retrieval Augmented Generation,正如其名,是一种将检索(Retrieval)和生成(Generation)结合起来的技术。它首先从一个巨大的知识库中检索出与提出的问题最相关的信息,然后基于这些信息来生成回答。这样做的好处是,它允许模型不仅依赖其已有的知识,还可以实时地利用外部数据来提供更准确、更丰富的回答。
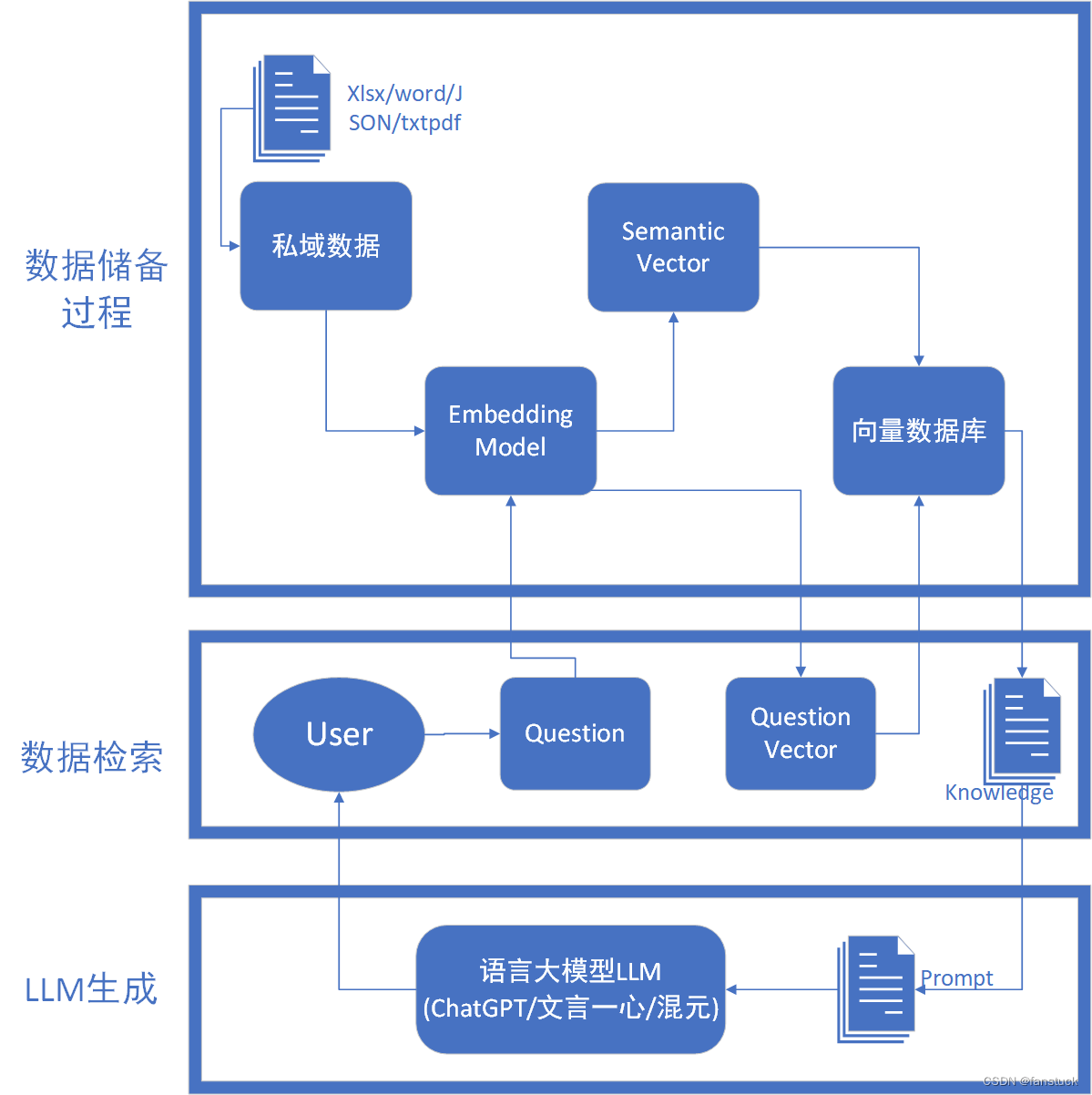
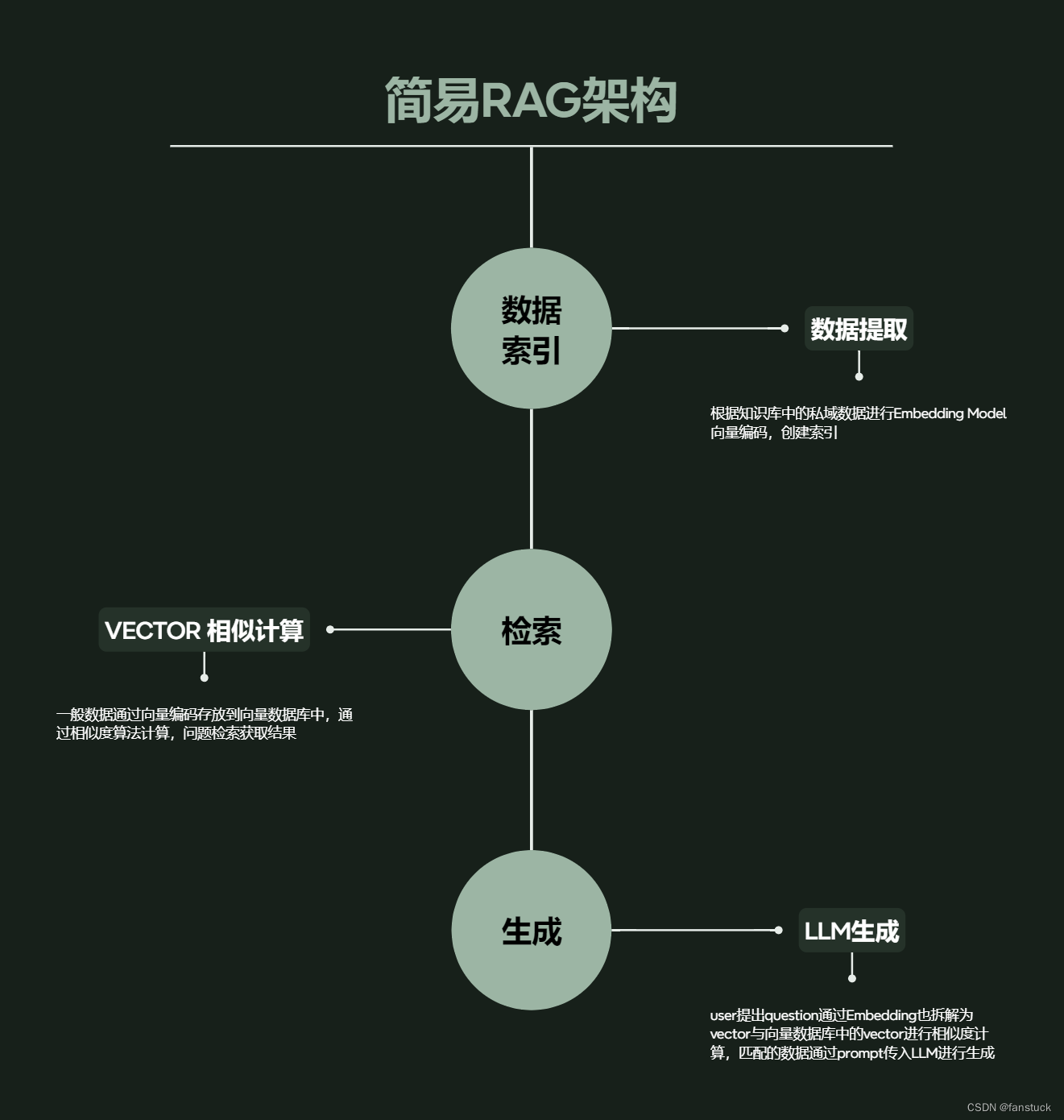 整体来看可以拆分为三个结构:数据索引——数据检索——LLM生成,整体架构如上述描述,我们先以整体视角看RGA的流程如上图所示。可以通俗的来讲
整体来看可以拆分为三个结构:数据索引——数据检索——LLM生成,整体架构如上述描述,我们先以整体视角看RGA的流程如上图所示。可以通俗的来讲
- 检索阶段:当用户提出一个问题时,RAG先将这个问题作为查询,搜索一个预先构建好的庞大数据库或知识库,寻找最相关的信息。这就像是当你在谷歌上输入查询一样,系统会返回与你的查询最匹配的结果。
- 生成阶段:一旦找到了最相关的信息,RAG会使用这些信息作为线索(或提示),通过一个语言生成模型来构造回答。这个过程就像是基于你从搜索引擎得到的资料撰写一篇报告或回答一个问题。
现在我们来拆分RGA的每一个阶段所做的工作。
RGA框架流程
数据储备
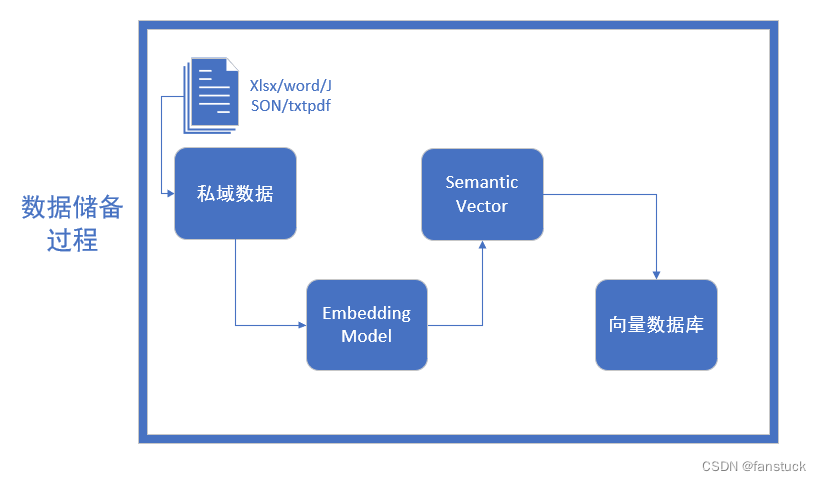
整个数据储备的过程可以分为四个步骤,首先是进行数据清洗。
数据清洗
需要转换为Embedding Model可以消化的格式,我们面对的知识源可能包括多种格式,如Word文档、TXT文件、CSV数据表、Excel表格,甚至是PDF文件、图片和视频等,都得转换为大语言模型可理解的纯文本数据。另外长本文还需要进行文本分割,需要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。
- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
向量化(embedding)
我之前写过一篇基于向量数据库的推荐系统设计文章是有详细描述向量化这一过程的,在深度学习火热的当下,向量是一个无法逃避的概念,也就是每一种事物都可以通过人为给他编码,比如我们设计路段拥堵事件采用红黄绿是一个道理。物品可以通过Embedding模型映射到同一纬度:
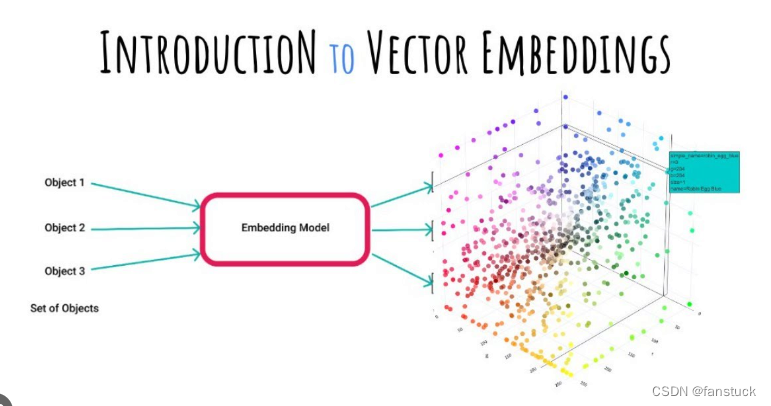
之后再进行存储以后备用计算相似度用于推荐。Embedding模型市场上已经存在很多了:
| 模型名称 | 描述 | 获取地址 |
|---|---|---|
| ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 | https://platform.openai.com/docs/guides/embeddings/what-are-embeddings |
| ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 | https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu |
| M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 | https://huggingface.co/moka-ai/m3e-base |
| BGE | BGE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 | https://huggingface.co/BAAI/bge-base-en-v1.5 |
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。
数据检索
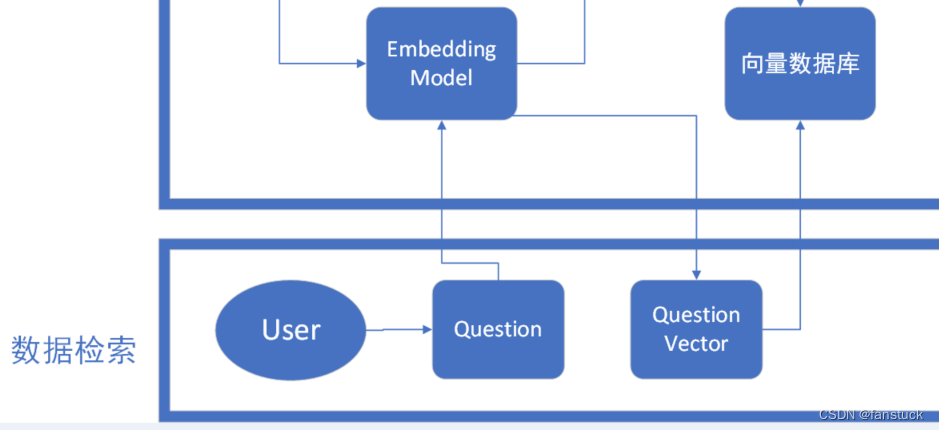
我们还需要对user提出的问题进行向量编码,和推荐系统设计的思路是一致的,其实推荐商品和给用户推荐回答二者的行为模式是一致的。推荐系统本质上是在用户需求不明确的情况下, 从海量的信息中为用户寻找其感兴趣的信息的技术手段。在博主写过的用户画像构建系统文章中有写到利用推荐系统作为下游服务,通过整合用户信息、物品信息和用户历史行为,推荐系统利用机器学习技术构建了个性化的用户兴趣模型。而给用户找答案的行为模式也是一样的,将用户提出的问题转换为向量,输入到向量数据库中进行数据检索。
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。当接收到一个用户查询(如一个问题或关键词)时,RAG框架首先将这个查询转换为向量形式。这一步通常通过预训练的语言模型(如BERT、GPT等)完成,以确保查询向量能够有效地捕捉查询的语义。
有了查询向量后,RAG使用最近邻搜索算法在预构建的索引中找到与查询向量最相近的文档向量。这些最相近的向量代表了知识库中与查询最相关的信息。检索算法相当多种
 - 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
在RAG框架的实现中,常见的技术和工具包括Elasticsearch、FAISS(Facebook AI Similarity Search)、Annoy(Approximate Nearest Neighbors Oh Yeah)等,这些工具专门为大规模数据检索和最近邻搜索设计,能够有效支持RAG框架中的检索需求。
LLM生成

到了LLM生成这一步就比较简单了,因为通过相似度索引获取到了最高成绩的数据,接下来我们只需要通过返回的Knowledge生成出阶段性的Prompt就好了,然后再返回给LLM语言大模型,让LLM进行总结之后再返回给User。为了进一步提高检索的相关性和生成文本的准确度,一些RAG模型实现了动态Prompt生成技术。这种方法通过分析初步检索的结果,自动调整或生成新的Prompt,以优化后续的检索和生成过程。这种反馈循环可以显著提高模型的性能。而且RAG模型允许用户对初步生成的Prompt进行评价或修改,基于用户反馈进一步优化检索和生成的结果。
RAG 与微调
了解以上RAG框架以后,有一定的NLP或者大模型语言基础的情况下,我们不约而同会冒出一个新的想法:RAG 与微调到底哪个才是最优解决方案呢。这个问题的答案并非一成不变,它取决于多个因素,包括具体的应用场景、资源的可用性、以及对模型性能的具体要求。
应用场景的差异
- RAG框架特别适合于那些需要结合广泛知识库来生成答案或内容的场景。它通过检索与问题密切相关的信息,并基于这些信息生成回答,特别适用于信息检索、问答系统、内容推荐等领域。RAG的优势在于能够利用最新的、外部的信息源,提供更新、更准确的回答。
- 微调则适用于有大量标注数据的情况,可以根据具体任务对预训练模型进行个性化调整。这适用于各种NLP任务,如文本分类、情感分析、命名实体识别等。微调的优点是能够在特定的任务上达到很高的精度,尤其是当预训练模型和微调任务高度相关时。
资源的可用性
- RAG框架需要能够访问并处理大量的外部信息。这意味着它对计算资源和数据存储的要求相对较高。同时,实现高效的信息检索机制也是RAG成功应用的关键。
- 微调虽然也需要一定的计算资源,但通常情况下,资源的要求比RAG要低,因为一旦模型被微调,就不需要再实时检索外部信息。然而,微调需要大量的标注数据来训练模型,这在某些场景下可能是一个限制因素。
以实验来具体评测(摘Meta近期论文):使用三个流行的微调数据集: SQL, functional representation and GSM8K ,并发现在对样本进行 RAG 增强与zero-shot样本进行微调时,这三个数据集的精度都有多个百分点的提高。
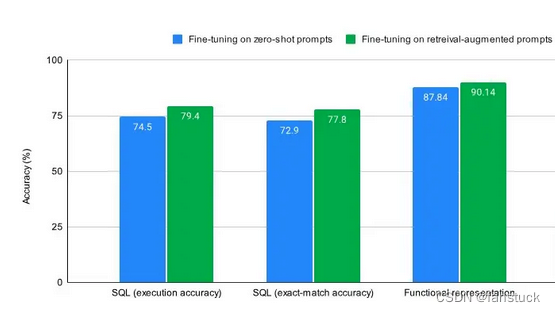
蓝色是针对zero-shot推理进行微调时的情况,绿色是针对检索增强提示进行微调时的情况(带有来自训练集的检索增强示例)。对于任何微调任务,无论是否是知识密集型任务,允许模型利用上下文学习和微调都会比仅仅微调零样本推理带来更好的性能。在一些情况下,结合使用RAG和微调可能是一个更好的策略。
总言
随着人工智能领域的快速发展,我们期待未来出现更多创新的技术,这些技术将进一步提高NLP任务的处理能力,为解决复杂的语言处理问题提供更多的可能性。同时,这也意味着AI工程师和研究人员需要不断地学习新的模型、技术和方法,以保持在这一动态发展的领域中的竞争力。我鼓励读者继续关注RAG、微调以及其他前沿的NLP技术和AI技术,通过实验和探索,找到最适合自己需求的解决方案。无论是在学术研究中,还是在实际应用开发中,不断地创新和尝试将是推动进步的重要动力。
相关文章:
Prompt提示工程上手指南:基础原理及实践(四)-检索增强生成(RAG)策略下的Prompt
前言 此篇文章已经是本系列的第四篇文章,意味着我们已经进入了Prompt工程的深水区,掌握的知识和技术都在不断提高,对于Prompt的技巧策略也不能只局限于局部运用而要适应LLM大模型的整体框架去进行改进休整。较为主流的LLM模型框架设计可以基…...
阿里云倚天云服务器怎么样?如何收费?
阿里云倚天云服务器CPU采用倚天710处理器,租用倚天服务器c8y、g8y和r8y可以享受优惠价格,阿里云服务器网aliyunfuwuqi.com整理倚天云服务器详细介绍、倚天710处理器性能测评、CIPU架构优势、倚天服务器使用场景及生态支持: 阿里云倚天云服务…...

海外社交营销为什么用云手机?不用普通手机?
海外社交营销作为企业拓展海外市场的重要手段,正日益受到企业的青睐。云手机以其成本效益和全球性特征,成为海外社交营销领域的得力助手。那么,究竟是什么特性使得越来越多的企业选择利用云手机进行海外社交营销呢?下文将对此进行…...

【Mysql数据库基础05】子查询 where、from、exists子查询、分页查询
where、from、exists子查询、分页查询 1 where子查询1.1 where后面的标量子查询1.1.1 having后的标量子查询 1.2 where后面的列子查询1.3 where后面的行子查询(了解即可) 2 from子查询3 exists子查询(相关子查询)4 分页查询5 联合…...

在Linux/Debian/Ubuntu上通过 Azure Data Studio 管理 SQL Server 2019
Microsoft 提供 Azure Data Studio,这是一种可在 Linux、macOS 和 Windows 上运行的跨平台数据库工具。 它提供与 SSMS 类似的功能,包括查询、脚本编写和可视化数据。 要在 Ubuntu 上安装 Azure Data Studio,可以按照以下步骤操作࿱…...
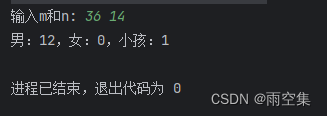
Java代码基础算法练习-搬砖问题-2024.03.25
任务描述: m块砖,n人搬,男搬4,女搬3,两个小孩抬一砖,要求一次全搬完,问男、 女、小孩各若干? 任务要求: 代码示例: package M0317_0331;import java.util.S…...

Tomcat调优
1、调整线程数 <Connector port"8080" maxHttpHeaderSize"8192"maxThreads"1900" minSpareThreads"250" maxSpareThreads"750"enableLookups"false" redirectPort"8443" acceptCount"100"…...

每日OJ题_栈①_力扣1047. 删除字符串中的所有相邻重复项
目录 力扣1047. 删除字符串中的所有相邻重复项 解析代码 力扣1047. 删除字符串中的所有相邻重复项 1047. 删除字符串中的所有相邻重复项 难度 简单 给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。 在 S 上反…...
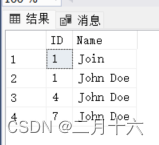
SQLServer SEQUENCE用法
SEQUENCE:数据库中的序列生成器 在数据库管理中,经常需要生成唯一且递增的数值序列,用于作为主键或其他需要唯一标识的列的值。为了实现这一功能,SQL Server 引入了 SEQUENCE 对象。SEQUENCE 是一个独立的数据库对象,用…...
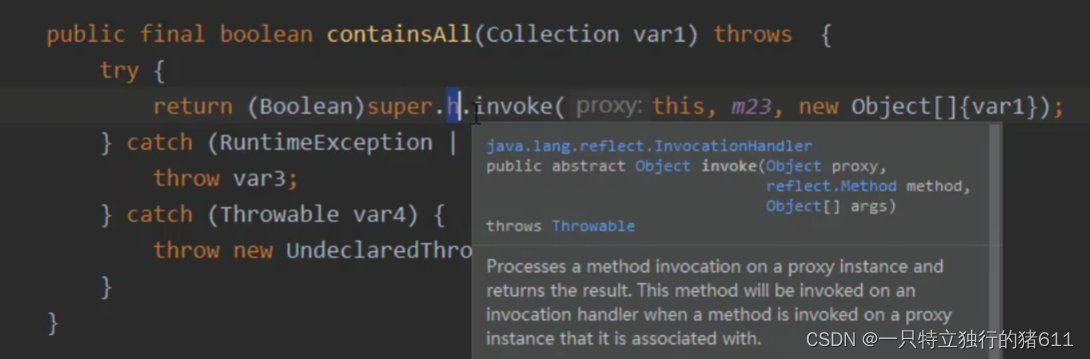
Java中的代理模式(动态代理和静态代理)
代理模式 我们先了解一下代理模式: 在开发中,当我们要访问目标类时,不是直接访问目标类,而是访问器代理类。通过代理类调用目标类完成操作。简单来说就是:把直接访问变为间接访问。 这样做的最大好处就是:…...

强化学习之父Richard Sutton:通往AGI的另一种可能
2019年,强化学习之父、阿尔伯塔大学教授Richard Sutton发表了后来被AI领域奉为经典的The Bitter lesson,这也是OpenAI研究员的必读文章。 在这篇文章中,Richard指出,过去 70 年来,AI 研究的一大教训是过于重视人类既有…...
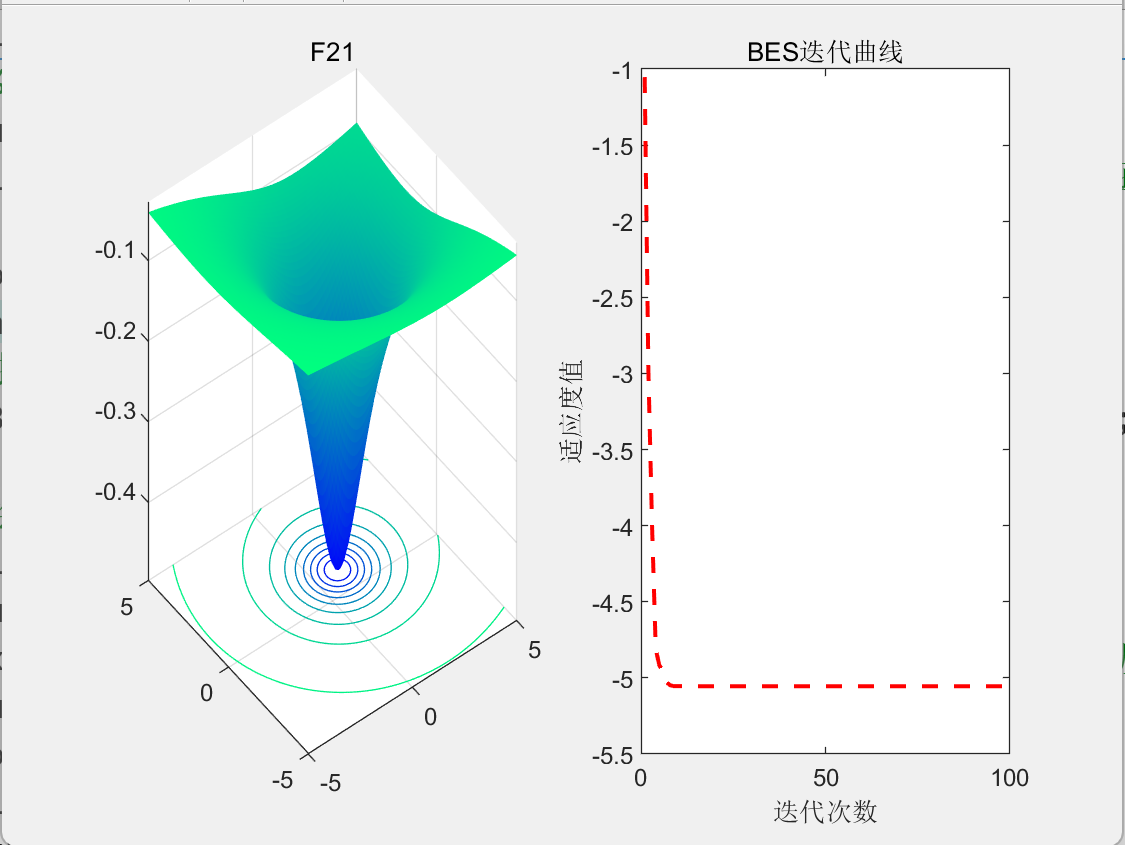
【智能算法】秃鹰搜索算法(BES)原理及实现
目录 1.背景2.算法原理2.1算法思想2.2算法过程 3.结果展示4.参考文献 1.背景 2020年, Alsattar等人受到秃鹰猎食自然行为启发,提出了秃鹰搜索算法(Bald Eagle Search,BES)。 2.算法原理 2.1算法思想 BES主要分为三…...

前端并发控制
本文讲解Promise,callback,RxJS多种方式实现并发限制 1.Promise 目前来说,Promise是最通用的方案,一般我们最先想到Promise.all,当然最好是使用新出的Promise.allsettled。 下面简单介绍下二者的区别,假…...

基于YOLOv8深度学习的橙子病害智能诊断与防治系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标分类
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

Java中的多线程详解(超级简单理解)(上篇)
使用工具 IntelliJ IDEA Community Edition 2023.1.4 使用语言 Java8 代码能力快速提升小方法,看完代码自己敲一遍,十分有用 目录 1.多线程概述 1.1 进程与线程 1.2 多线程的运行机制 1.3 多线程的优势 2.多线程编程 2.1 Thread类介绍 2.2 …...

Elastic-Job 分布式任务调度
一、使用场景 (1)分布式项目中 定时任务。如果只部署一台机器,可用性无法保证,如果定时任务机器宕机,无法故障转移,如果部署多台机器时,同一个任务会执行多次,任务重复执行也会出问…...

YZ系列工具之YZ09: VBA_Excel之读心术
我给VBA下的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套一部VBA手册,教程分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的…...

Python下载音乐
今天我就来分享一下我的方法:Python爬虫 在CS dn社区中我浏览了许多关于爬虫代码,可都有各自的缺陷,有的需要ID比较麻烦,这里我编写了一个程序,他只需要输入歌曲名字即可进行搜索爬取并下载 话不多说,下面的程序复制…...

PCL ICP配准高阶用法——统计每次迭代的配准误差并可视化
目录 一、概述二、代码实现三、可视化代码四、结果展示本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、概述 在进行论文写作时,需要做对比实验,来分析改进算法的性能,期间用到了迭代误差分布统计的比较分析,为直…...
电脑卸载软件怎么清理干净?电脑清理的5种方法
随着我们在电脑上安装和卸载各种软件,很多时候我们会发现,即使软件被卸载,其残留的文件和注册表项仍然存在于电脑中,这不仅占用了宝贵的磁盘空间,还可能影响电脑的性能。那么,如何确保在卸载软件时能够彻底…...

OpenCore Legacy Patcher终极教程:如何让老旧Mac重获新生,运行最新macOS
OpenCore Legacy Patcher终极教程:如何让老旧Mac重获新生,运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为老旧Ma…...

WarcraftHelper:魔兽争霸3终极优化指南 - 5大方案让你的经典游戏焕发新生
WarcraftHelper:魔兽争霸3终极优化指南 - 5大方案让你的经典游戏焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔…...

微信网页版终极解决方案:wechat-need-web 完整使用指南
微信网页版终极解决方案:wechat-need-web 完整使用指南 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 你是否曾经因为微信网页版限制而无…...
)
Houdini RBD破碎资产导入UE5全流程:从ABC/FBX导出到材质动画还原(避坑指南)
Houdini RBD破碎资产导入UE5全流程:从ABC/FBX导出到材质动画还原(避坑指南)在影视级实时渲染领域,Houdini与Unreal Engine 5的协同工作已成为特效制作的黄金标准。当您完成了一个令人惊叹的RBD破碎模拟后,如何将这些充…...
)
UE5面部动画入门:手把手教你用Blender创建Morph Target并导入引擎(附苏珊模型实操)
UE5面部动画实战:从Blender雕刻到引擎驱动的全流程解析在独立游戏开发领域,面部表情动画往往被视为高阶技能,让许多初学者望而却步。但事实上,借助UE5的Morph Target功能和Blender的基础雕刻工具,即使没有任何绑定经验…...
做面部表情,从Blender雕刻到引擎驱动全流程)
别再只用骨骼了!用UE5的Morph Target(BlendShape)做面部表情,从Blender雕刻到引擎驱动全流程
别再只用骨骼了!用UE5的Morph Target(BlendShape)做面部表情,从Blender雕刻到引擎驱动全流程面部动画一直是游戏开发中最具挑战性的领域之一。许多开发者习惯性地认为面部表情必须通过骨骼系统驱动,这种"唯骨骼论…...

量子机器学习实战:遥感图像分割的混合模型构建与硬件噪声影响分析
1. 项目概述与核心挑战量子机器学习(QML)这个领域,听起来像是科幻小说里的概念,但过去几年,它已经从理论物理的殿堂,逐渐走进了我们这些做工程和算法应用的人的视野。简单来说,它试图用量子计算…...

从lsusb输出到硬件信息库:如何查询Linux中USB设备的厂商和型号
从lsusb输出到硬件信息库:Linux下USB设备厂商与型号的深度解析 当你插入一个陌生的USB设备到Linux系统时,终端里 lsusb 命令输出的那一串神秘代码 ID xxxx:xxxx 往往让人摸不着头脑。这些十六进制数字背后隐藏着设备的真实身份——厂商和具体型号。本…...

DYNAMIX:基于强化学习的动态批处理优化,破解分布式训练效率与精度困局
1. 项目概述与核心痛点在分布式机器学习(DML)的实际部署中,有一个参数总是让工程师们又爱又恨,那就是批处理大小(Batch Size)。它不像学习率那样有丰富的理论指导,也不像网络结构那样有清晰的演…...
)
告别传统地形!用Unreal Engine的Voxel Plugin手把手教你做可破坏的无限世界(含动态NavMesh配置)
告别传统地形!用Unreal Engine的Voxel Plugin打造可破坏的无限世界在游戏开发领域,地形系统一直是构建虚拟世界的基石。传统Landscape系统虽然成熟稳定,但面对日益增长的玩家对交互性和自由度的需求,静态地形已经难以满足现代沙盒…...