政安晨:【Keras机器学习实践要点】(三)—— 编写组件与训练数据
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras实战演绎机器学习
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
介绍
通过 Keras,您可以编写自定义层、模型、度量指标、损失和优化器,并在同一代码库中跨 TensorFlow、JAX 和 PyTorch 运行。
老规矩,咱们还是先准备环境(参考我本专栏目录中的文章,其中有搭建环境的部分):
政安晨:【TensorFlow与Keras实战演绎机器学习】专栏 —— 目录![]() https://blog.csdn.net/snowdenkeke/article/details/136985399
https://blog.csdn.net/snowdenkeke/article/details/136985399
准备好环境后,咱们开始。
编写组件
让我们先来看看自定义层:
{keras.ops 命名空间包含}
1. NumPy API 的实现,例如 keras.ops.stack 或 keras.ops.matmul。
2. 一组 NumPy 中没有的神经网络特定操作,如 keras.ops.conv 或 keras.ops.binary_crossentropy。
让我们创建一个可与所有后端配合使用的自定义密集层:
class MyDense(keras.layers.Layer):def __init__(self, units, activation=None, name=None):super().__init__(name=name)self.units = unitsself.activation = keras.activations.get(activation)def build(self, input_shape):input_dim = input_shape[-1]self.w = self.add_weight(shape=(input_dim, self.units),initializer=keras.initializers.GlorotNormal(),name="kernel",trainable=True,)self.b = self.add_weight(shape=(self.units,),initializer=keras.initializers.Zeros(),name="bias",trainable=True,)def call(self, inputs):# Use Keras ops to create backend-agnostic layers/metrics/etc.x = keras.ops.matmul(inputs, self.w) + self.breturn self.activation(x)接下来,让我们制作一个依赖于keras.random命名空间的自定义Dropout层:
class MyDropout(keras.layers.Layer):def __init__(self, rate, name=None):super().__init__(name=name)self.rate = rate# Use seed_generator for managing RNG state.# It is a state element and its seed variable is# tracked as part of `layer.variables`.self.seed_generator = keras.random.SeedGenerator(1337)def call(self, inputs):# Use `keras.random` for random ops.return keras.random.dropout(inputs, self.rate, seed=self.seed_generator)接下来,让我们编写一个自定义子类模型,使用我们的两个自定义层:
class MyModel(keras.Model):def __init__(self, num_classes):super().__init__()self.conv_base = keras.Sequential([keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),keras.layers.MaxPooling2D(pool_size=(2, 2)),keras.layers.Conv2D(128, kernel_size=(3, 3), activation="relu"),keras.layers.Conv2D(128, kernel_size=(3, 3), activation="relu"),keras.layers.GlobalAveragePooling2D(),])self.dp = MyDropout(0.5)self.dense = MyDense(num_classes, activation="softmax")def call(self, x):x = self.conv_base(x)x = self.dp(x)return self.dense(x)让我们编译并适配它:
model = MyModel(num_classes=10)
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),optimizer=keras.optimizers.Adam(learning_rate=1e-3),metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc"),],
)model.fit(x_train,y_train,batch_size=batch_size,epochs=1, # For speedvalidation_split=0.15,
)现在咱们演绎如下:
在本地的TensorFlow虚拟环境中,首先导入keras:
from tensorflow import keras(可以在Jupyter Notebook中运行)
如果在演绎执行中出错,可能是Keras版本问题,使用如下命令升级keras。
sudo pip install --upgrade keras执行结果:

训练模型
在任意数据源上训练模型
所有的Keras模型都可以在各种数据来源上进行训练和评估,与您使用的后端无关。这包括:
NumPy数组 Pandas数据框 TensorFlow tf.data.Dataset对象 PyTorch DataLoader对象 Keras PyDataset对象 无论您使用TensorFlow、JAX还是PyTorch作为Keras后端,它们都可以工作。
让我们尝试使用PyTorch DataLoader:
import torch# Create a TensorDataset
train_torch_dataset = torch.utils.data.TensorDataset(torch.from_numpy(x_train), torch.from_numpy(y_train)
)
val_torch_dataset = torch.utils.data.TensorDataset(torch.from_numpy(x_test), torch.from_numpy(y_test)
)# Create a DataLoader
train_dataloader = torch.utils.data.DataLoader(train_torch_dataset, batch_size=batch_size, shuffle=True
)
val_dataloader = torch.utils.data.DataLoader(val_torch_dataset, batch_size=batch_size, shuffle=False
)model = MyModel(num_classes=10)
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),optimizer=keras.optimizers.Adam(learning_rate=1e-3),metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc"),],
)
model.fit(train_dataloader, epochs=1, validation_data=val_dataloader)

现在让我们尝试使用tf.data来完成这个任务:
import tensorflow as tftrain_dataset = (tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size).prefetch(tf.data.AUTOTUNE)
)
test_dataset = (tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(batch_size).prefetch(tf.data.AUTOTUNE)
)model = MyModel(num_classes=10)
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),optimizer=keras.optimizers.Adam(learning_rate=1e-3),metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc"),],
)
model.fit(train_dataset, epochs=1, validation_data=test_dataset)

相关文章:
政安晨:【Keras机器学习实践要点】(三)—— 编写组件与训练数据
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎机器学习 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 介绍 通过 Keras,您可以编写自定…...
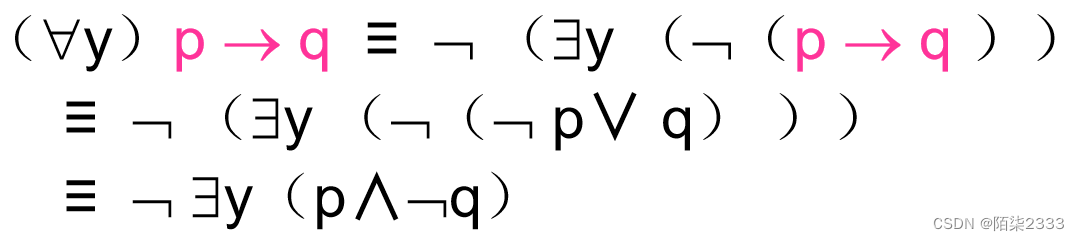
数据库系统概论(超详解!!!) 第四节 关系数据库标准语言SQL(Ⅲ)
1.连接查询 连接查询:同时涉及多个表的查询 连接条件或连接谓词:用来连接两个表的条件 一般格式: [<表名1>.]<列名1> <比较运算符> [<表名2>.]<列名2> [<表名1>.]<列名1> BETWEEN [&l…...

如何使用Python进行网络安全与密码学【第149篇—密码学】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 用Python进行网络安全与密码学:技术实践指南 随着互联网的普及,网络…...
应急响应-Web2
应急响应-Web2 1.攻击者的IP地址(两个)? 192.168.126.135 192.168.126.129 通过phpstudy查看日志,发现192.168.126.135这个IP一直在404访问 , 并且在日志的最后几条一直在访问system.php ,从这可以推断 …...
复试专业前沿问题问答合集8-1——CNN、Transformer、TensorFlow、GPT
复试专业前沿问题问答合集8-1——CNN、Transformer、TensorFlow、GPT 深度学习中的CNN、Transformer、TensorFlow、GPT大语言模型的原理关系问答: Transformer与ChatGPT的关系 Transformer 是一种基于自注意力机制的深度学习模型,最初在论文《Attention is All You Need》…...

用Python做一个植物大战僵尸
植物大战僵尸是一个相对复杂的游戏,涉及到图形界面、动画、游戏逻辑等多个方面。用Python实现一个完整的植物大战僵尸游戏是一个大工程,但我们可以简化一些内容,做一个基础版本。 以下是一个简化版的植物大战僵尸游戏的Python实现思路&#…...
Win11文件右键菜单栏完整显示教程
近日公司电脑升级了win11,发现了一个小麻烦事,如下图: 当我想使用svn或git的时候必须要多点一下,这忍不了,无形之中加大了工作量! 于是,菜单全显示教程如下: 第一步:管…...

【Python实用标准库】argparser使用教程
argparser使用教程 1.介绍2.基本使用3.add_argument() 参数设置4.参考 1.介绍 (一)argparse 模块是 Python 内置的用于命令项选项与参数解析的模块,其用主要在两个方面: 一方面在python文件中可以将算法参数集中放到一起&#x…...

伦敦金与纸黄金有什么区别?怎么选?
伦敦金与纸黄金都是与黄金相关的投资品种,近期黄金市场的上涨吸引了投资者的关注,那投资者想开户入场成为黄金投资者应该选择纸黄金还是伦敦金呢?两者有何区别呢?下面我们就来讨论一下。 伦敦金是一种起源于伦敦的标准化黄金交易合…...
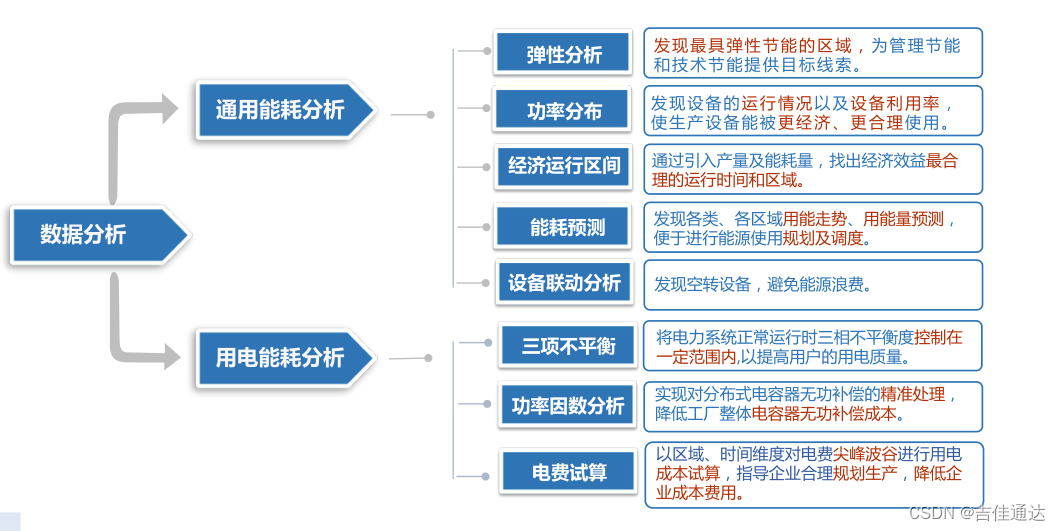
化工企业能源在线监测管理系统,智能节能助力生产
化工企业能源消耗量极大,其节能的空间也相对较大,所以需要控制能耗强度,保持更高的能源利用率。 化工企业能源消耗现状 1、能源管理方面 计量能源消耗时,计量器具存在问题,未能对能耗情况实施完全计量,有…...

C/C++ 一些使用网站收集...
C/C 标准 各种语言协议标准文档 open-std.org 网站 C语言标准文档 open-std.org C基金会网站 C/C 标准库网站 c/c 标准库 cplusplus.com 网站 c/c标准库 cppreference.com 网站 C Core Guidelines【isocpp.org】 C/C 发展 C现有状态及未来规划【isocpp.org】...

2024可以搜索夸克网盘的方法
截止2024可以搜索夸克网盘的方法 6miu盘搜 6miu盘搜是一个强大的网盘搜索工具,它汇集了多个网盘平台的资源,包括百度网盘、163网盘、金山快盘等,可以帮助用户快速找到所需的资料。6miu盘搜的一个显著特点是它的资源更新速度快,可以搜索到最新的资源。此外,6miu盘搜的界面清爽…...
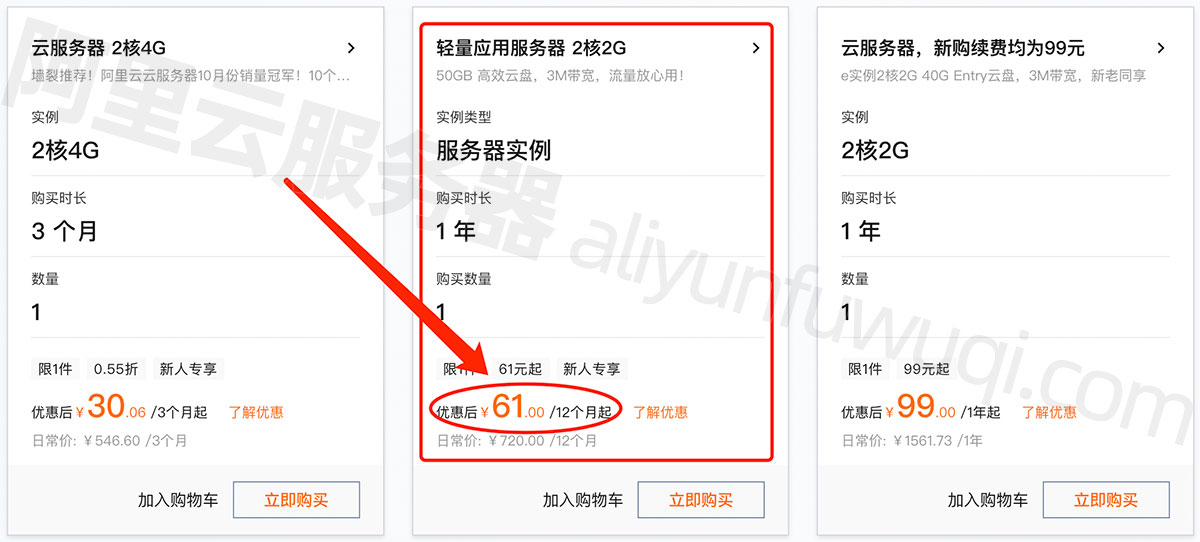
2024年最新阿里云服务器价格表_CPU内存+磁盘+带宽价格
2024年阿里云服务器租用费用,云服务器ECS经济型e实例2核2G、3M固定带宽99元一年,轻量应用服务器2核2G3M带宽轻量服务器一年61元,ECS u1服务器2核4G5M固定带宽199元一年,2核4G4M带宽轻量服务器一年165元12个月,2核4G服务…...
)
300.【华为OD机试】跳房子I(时间字符串排序—JavaPythonC++JS实现)
本文收录于专栏:算法之翼 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目二.解题思路三.题解代码Python题解代码JAVA题解代码C/C++题解代码JS题解代码四.代码讲解(Ja…...
的命令)
linux ln Linux 系统中用于创建链接(link)的命令
linux 命令基础汇总 命令&基础描述地址linux curl命令行直接发送 http 请求Linux curl 类似 postman 直接发送 get/post 请求linux ln创建链接(link)的命令创建链接(link)的命令linux linklinux 软链接介绍linux 软链接介绍l…...

mysql按照查询条件进行排序和统计一个字段中每个不同数值出现的次数
1.比如学生表 如何显示查询结果的顺序根据放置的顺序查询 <select id"selectNames" resultType"Student">select * from student_table where 11<if test"studentList! null">and name in<foreach item"item" ind…...
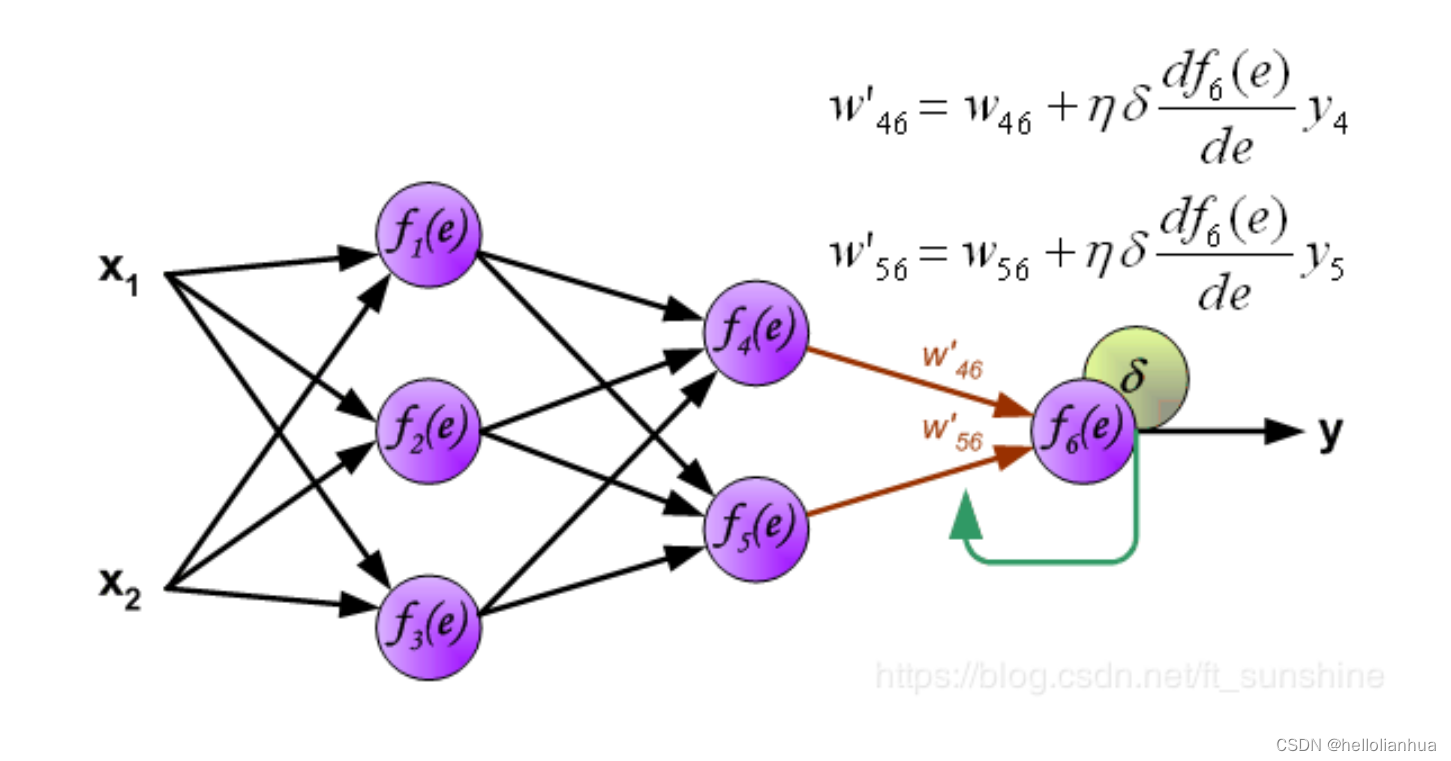
深度学习基础知识
本文内容来自https://zhuanlan.zhihu.com/p/106763782 此文章是用于学习上述链接,方便自己理解的笔记 1.深度学习的网络结构 深度学习是神经网络的一种特殊形式,典型的神经网络如下图所示。 神经元:表示输入、中间数值、输出数值点。例如&…...
UE4_旋转节点总结一
一、Roll、Pitch、Yaw Roll 围绕X轴旋转 飞机的翻滚角 Pitch 围绕Y轴旋转 飞机的俯仰角 Yaw 围绕Z轴旋转 飞机的航向角 二、Get Forward Vector理解 测试: 运行: 三、Get Actor Rotation理解 运行效果: 拆分旋转体测试一&a…...

Dockerfile将jar部署成docker容器
将jar包copy到linux,新建Dockerfile文件 -rw-r--r-- 1 root root 52209844 Mar 25 22:55 data-sharing-0.0.1-SNAPSHOT.jar -rwxrwxrwx 1 root root 227 Mar 25 22:57 Dockerfile [rootlocalhost mnt]# pwd /mntDockerfile内容 # 指定基础镜像 FROM java:8-a…...
)
Android14音频进阶:AudioFlinger向HAL输出数据过程(六十四)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒体系统工程师系列【原创干货持续更新中……】🚀 人生格言: 人生从来没有捷径,只…...

2026免费一键去图片水印App详细教程,哪个好用一看就会
你是不是也遇到过这种抓狂瞬间:好不容易找到一张绝美壁纸,下载下来发现右下角有个硕大的水印;刷小红书看到一张干货满满的食谱长图,想保存下来慢慢看,结果水印刚好盖在关键步骤上;又或者自己做图时手滑把水…...

论文初稿被批太水?青年教师力荐这几个AI论文写作软件
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

【无功优化】基于改进教与学算法的配电网无功优化【IEEE33节点】附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

Nacos CVE-2021-29442:Spring Boot Actuator未授权访问漏洞深度解析
1. 这个漏洞不是“改个配置就能修好”的那种 Nacos CVE-2021-29442,这个名字在2021年中后期的Java中间件运维圈里,曾让不少团队在凌晨三点被电话叫醒。它不是那种需要你翻文档、查API、调参数的常规问题,而是一个典型的“默认行为埋雷”——…...

混合量子-经典机器学习在HPC环境下的性能调优与实战
1. 项目概述与核心价值在人工智能和计算科学的前沿,我们正站在一个关键的十字路口。一方面,以卷积神经网络为代表的经典机器学习模型,在处理图像识别、自然语言理解等任务上取得了巨大成功,但其对计算资源的需求正以惊人的速度膨胀…...

Mermaid在线编辑器:5分钟掌握专业图表制作的终极指南
Mermaid在线编辑器:5分钟掌握专业图表制作的终极指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...

D2DX终极指南:暗黑破坏神2现代重生的技术架构与实战配置
D2DX终极指南:暗黑破坏神2现代重生的技术架构与实战配置 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx D2DX是一…...

OBS高级计时器插件完整指南:6种计时模式让直播时间管理更专业
OBS高级计时器插件完整指南:6种计时模式让直播时间管理更专业 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时手忙脚乱地看时间而烦恼吗?OBS高级计时器插件是专为直播主设计…...
)
DeepSeek日志异常检测实战:基于时序大模型的动态基线算法(已通过金融级等保三级日志审计验证)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek日志分析方案概述 DeepSeek系列大模型在推理与训练过程中会产生海量结构化与半结构化日志,涵盖请求元数据、token级耗时、KV缓存命中率、显存占用、错误堆栈等关键维度。本方案聚焦…...

如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南
如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在当今数字隐私日益重要的时代,硬件指纹追踪已成…...