零基础机器学习(3)之机器学习的一般过程
文章目录
- 一、机器学习一般过程
- 1.数据获取
- 2.特征提取
- 3.数据预处理
- ①去除唯一属性
- ②缺失值处理
- A. 均值插补法
- B. 同类均值插补法
- ③重复值处理
- ④异常值
- ⑤数据定量化
- 4.数据标准化
- ①min-max标准化(归一化)
- ②z-score标准化(规范化)
- 5.数据降维
- ①目的
- ②权衡
- 6.训练模型
- ①样本数据集的选取
- ②机器学习算法
- 7.评估模型的有效性
- ①过拟合与欠拟合
- ②性能度量
- A. 回归任务
- B.分类任务
- C.聚类任务
- 8.使用模型
一、机器学习一般过程
机器学习的基本思想是通过从样本数据中提取所需特征构造一个有效的模型,并使用所建模型来完成具体的任务。

首先要获取所研究问题的数据
其次是对获取到的数据进行适当处理,然后选取合适的算法训练模型
最后对训练好的模型进行评估,以判定其是否满足任务需求,如满足,即可使用模型。
1.数据获取
机器学习的第一步是收集与学习任务相关的数据,这是最基础也是最重要的一步。
虽然现在是大数据时代,但对于一个给定任务,要得到与之相关的数据有时却很困难。业界广泛流传这样一句话:*数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限的方法而已。*因此,数据的获取尤为重要。
在训练最优的机器学习模型时,一定要选择最有代表性的数据集。只有选择最合适的属性作为特征,才能保证机器学习项目能应用于实际。
2.特征提取
特征提取是使用专业的背景知识和技巧最大限度地从原始数据中提取并处理数据,使得特征在机器学习的模型上得到更好的发挥,它直接影响机器学习的效果。
例如,在机器自动分辨筷子和牙签两种物品的实验中
| 序 号 | 长度/(cm) | 质量/(g) | 材 质 | 类 别 |
|---|---|---|---|---|
| 1 | 25 | 8 | 竹 | 筷子 |
| 2 | 23 | 7 | 竹 | 筷子 |
| 3 | 20 | 4 | 木 | 筷子 |
| 4 | 6 | 0.1 | 竹 | 牙签 |
| 5 | 5 | 0.08 | 竹 | 牙签 |
| 6 | 5.8 | 0.09 | 竹 | 牙签 |
| … | … | … | … | … |
观察表数据集可发现,根据长度和质量这两个特征即可分辨筷子和牙签,材质这个特征对区分筷子和牙签的作用并不明显,故可在特征属性中提取长度和质量这两个特征,而将材质这个特征删除,这个过程称为特征提取。
3.数据预处理
现实生活中,收集到的数据往往会有数据量纲(数据的度量单位)或数据类型不一致等问题。因此,在获取样本之后,通常需要对数据进行预处理。
数据预处理没有标准流程,通常包含去除唯一属性,处理缺失值、重复值和异常值,以及数据定量化等几个步骤。
| 序 号 | 姓 名 | 年龄/(岁) | 年收入/(元) | 性 别 | 学 历 | 年消费/(元) |
|---|---|---|---|---|---|---|
| 1 | 张三 | 36 | 50 000 | 男 | 本科 | 30 000 |
| 2 | 赵琦 | 42 | 45 000 | 女 | 本科 | 40 000 |
| 3 | 李武 | 23 | 30 000 | 男 | 高中 | |
| 4 | 王波 | 61 | 70 000 | 男 | 本科 | 20 000 |
| 5 | 刘玉琦 | 38 | 20 000 | 女 | 大专 | 10 000 |
| 6 | 赵琦 | 42 | 45 000 | 女 | 本科 | 40 000 |
| 7 | 赵倩 | −5 | 30 000 | 女 | 本科 | 90 000 |
该数据集是某平台上的“客户信息样本数据集”,要求使用机器学习方法,进行聚类,将客户划分为几种类型,以便为其推销相关的产品。在训练模型之前,我们需要对数据集中的数据进行预处理,才能得到理想的机器学习样本数据集。
①去除唯一属性
唯一属性通常指ID、姓名等属性,每个样本的取值都不一样且唯一,这些属性不能刻画样本自身的分布规律,在做数据预处理时,需将这些属性删除。
| 序 号 | 年龄/(岁) | 年收入/(元) | 性 别 | 学 历 | 年消费/(元) |
|---|---|---|---|---|---|
| 1 | 36 | 50 000 | 男 | 本科 | 30 000 |
| 2 | 42 | 45 000 | 女 | 本科 | 40 000 |
| 3 | 23 | 30 000 | 男 | 高中 | |
| 4 | 61 | 70 000 | 男 | 本科 | 20 000 |
| 5 | 38 | 20 000 | 女 | 大专 | 10 000 |
| 6 | 42 | 45 000 | 女 | 本科 | 40 000 |
| 7 | −5 | 30 000 | 女 | 本科 | 90 000 |
②缺失值处理
这里的缺失值指的是,单个样本中的数据某些确实,并不是样本缺失
常见的缺失值处理方法有3种
- 直接使用含有缺失值的特征;
- 删除含有缺失值的特征;
- 缺失值补全。其中,缺失值补全是最常用的手段。
A. 均值插补法
是指使用该属性有效值的平均值来插补缺失的值
B. 同类均值插补法
是指首先将样本进行分类或聚类,然后以该类中样本的均值插补缺失值。
③重复值处理
在数据处理中,重复值指的是数据集中出现了两个或多个完全相同的记录或行。这些记录在所有列上的取值都完全相同,没有任何区别。重复值可能是由数据输入错误、数据复制问题或其他原因导致的。
重复值会导致数据的方差变小,数据的分布发生较大变化。因此,若检查到数据集中有重复数据,要将其删除。
④异常值
异常值是指超出或低于正常范围的值,如年龄为负数、身高大于3 m等,它会导致分析结果产生偏差甚至错误。检查到异常值后,可对异常值进行删除或替换处理
| 序 号 | 年龄/(岁) | 年收入/(元) | 性 别 | 学 历 | 年消费/(元) |
|---|---|---|---|---|---|
| 1 | 36 | 50 000 | 男 | 本科 | 30 000 |
| 2 | 42 | 45 000 | 女 | 本科 | 40 000 |
| 3 | 23 | 30 000 | 男 | 高中 | 15 000 |
| 4 | 61 | 70 000 | 男 | 本科 | 20 000 |
| 5 | 38 | 20 000 | 女 | 大专 | 10 000 |
⑤数据定量化
计算机只能处理数值型数据。因此,在数据预处理时,如果有非数值型数据,都要先转换成数值型数据。
| 序 号 | 年龄/(岁) | 年收入/(元) | 性 别 | 学 历 | 年消费/(元) |
|---|---|---|---|---|---|
| 1 | 36 | 50 000 | 1 | 60 | 30 000 |
| 2 | 42 | 45 000 | 2 | 60 | 40 000 |
| 3 | 23 | 30 000 | 1 | 20 | 15 000 |
| 4 | 61 | 70 000 | 1 | 60 | 20 000 |
| 5 | 38 | 20 000 | 2 | 40 | 10 000 |
在该数据集中性别和学历都是非数值型数据,需将其处理成数值型数据,如学历“高中”可用20代替,“大专”可用40代替,“本科”可用60代替;性别中的“男”可用1代替,“女”可用2代替。
4.数据标准化
数据标准化是指将数据按比例缩放,使之落入一个特定区间,从而消除数据之间数量级的差异。经过标准化处理后,不同的特征可以具有相同的尺度。
①min-max标准化(归一化)
数据集的每个属性(数据表中的列)中都有一个最大值和一个最小值,分别用max和min表示,然后通过一个公式将原始值映射到区间[0,1]上。
| 序 号 | 年 龄 | 年 收 入 | 性 别 | 学 历 | 年 消 费 |
|---|---|---|---|---|---|
| 1 | 0.34 | 0.6 | 0 | 1 | 0.67 |
| 2 | 0.5 | 0.5 | 1 | 1 | 1 |
| 3 | 0 | 0.2 | 0 | 0 | 0.17 |
| 4 | 1 | 1 | 0 | 1 | 0.33 |
| 5 | 0.39 | 0 | 1 | 0.5 | 0 |
整个数据集的数据经过min-max标准化处理后的结果如表所示。
这种处理方法的缺点是当有新数据加入时,可能会导致最大值和最小值发生变化,需要重新定义。
②z-score标准化(规范化)
它是基于原始数据的均值和标准差进行数据标准化的一种方法。
z-score标准化方法适用于属性的最大值和最小值未知的情况或有超出取值范围的离群数据的情况。
公式:新值=(原始值-均值)/标准差
| 序 号 | 年 龄 | 年 收 入 | 性 别 | 学 历 | 年 消 费 |
|---|---|---|---|---|---|
| 1 | −0.33 | 0.41 | −0.82 | 0.75 | 0.65 |
| 2 | 0.16 | 0.12 | 1.22 | 0.75 | 1.58 |
| 3 | −1.38 | −0.76 | −0.82 | −1.75 | −0.74 |
| 4 | 1.71 | 1.56 | −0.82 | 0.75 | −0.28 |
| 5 | −0.16 | −1.34 | 1.22 | −0.5 | −1.21 |
整个数据集的数据经过z-score标准化处理后的数据如表所示。
注意:
z-score标准化要求样本属性值数据服从正态分布,这就要求样本数量足够多,故此案例不适合使用z-score标准化进行数据处理。
5.数据降维
- “维度”是指样本集中特征属性的个数。
- “降维”是指减少特征矩阵中特征的数量。
①目的
- 为了对数据进行可视化,以便对数据进行观察和探索;
- 简化机器学习模型的训练,使模型的泛化能力更好,避免“维度灾难”。
在实际应用中,数据一般是高维的。

手写数字“1”及其对应二维矩阵
手写的数字图片,如果将其缩放到28x28像素的大小,那么它的维度就是28x28=784维
对应的图像二维矩阵
数据已经被规范化到(0,1)范围内
②权衡
维数太多或太少都不好,设置恰当的维数对机器学习模型非常重要。
例如,对苹果和梨子进行分类时,若只将形状作为特征,则很可能会出现错误分类的情况;若再将大小作为特征,则可减少错误分类的情况;若再将颜色作为特征,则可进一步减少错误分类的情况。
数据降维最常用的方法是主成分分析法。
深度学习就是对样本的特征进行复杂的变换,得到最有效的特征,从而提高机器学习的性能。
6.训练模型
①样本数据集的选取
- 训练集的数据要尽可能充分且分布平衡(即每个类别的样本数量差不多),否则不可能训练出一个完好的模型;
- 验证集或测试集的样本也需要符合一定的平衡分布,否则将无法测试出一个准确的模型;
- 训练模型和测试模型使用的样本不能相同。
②机器学习算法
训练机器学习模型时,要根据具体的学习任务,选择合适的算法。
- 分类任务经常使用的算法有k近邻、朴素贝叶斯、决策树、支持向量机等;
- 回归任务经常使用的算法有线性回归、k近邻、决策树等;
- 聚类任务经常使用的算法有k均值、DBSCAN、GMM等。
7.评估模型的有效性
一个机器学习模型训练出来后,一般需要评估该模型的效果,看其是否能满足实际问题的需要。
评估模型的有效性就是利用测试集对模型进行测试,评估其输出结果。
事实上,我们希望得到一个在新的未知样本上表现很好的模型,即泛化能力好的模型。
①过拟合与欠拟合

如果模型在训练样本上学得“太好”了,很可能把训练样本自身的一些特点当成了所有样本的一般性质,导致泛化能力下降,这种现象在机器学习中称为“过拟合”。
与“过拟合”相对的就是“欠拟合”,指对训练样本的一般性质尚未学好。图1-10给出了关于过拟合与欠拟合的一个类比,便于理解。
②性能度量
A. 回归任务
- 残差:在数理统计中是指所有拟合数据(即模型预测数据)与原始数据(样本实际值)之间的差的和。
- 和方差(SSE):拟合数据和原始数据对应点的误差的平方和。SSE越接近于0,说明模型越好,数据预测也越成功。
- 均方误差(MSE):拟合数据和原始数据对应点误差的平方和的均值,。
- 均方根误差(RMSE):MSE的平方根,也称回归任务的拟合标准差。
- 确定系数(R2):通过数据的变化来表征一个拟合的好坏,R2的正常取值范围为[0.1],越接近1,表明模型越好。
B.分类任务
分类任务中最常用的评估方法有准确率、精确率、召回率和F1值等。下面以一个二分类问题为例,介绍这些评估方法的含义。
| 真 实 值 | 正 例 | 反 例 |
|---|---|---|
| 预 测 值 | ||
| 正例 | 真正例( ) | 假反例( ) |
| 反例 | 假正例( ) | 真反例( ) |
在二分类中,假设样本有正反两个类别,则分类模型预测的结果有两种,正例和反例;真实数据的标签也有两种,正例和反例。那么,预测结果与真实标签的组合就有真正例(true positive)、真反例(true negative)、假正例(false positive)和假反例(false negative)4种情况,分别用 TP、 TN、FP 和 FN表示以上4种情况,
TP表示真实值与预测值都是正样本的数量;
FN表示真实值是正样本,而预测值却是反样本的数量;
FP表示真实值是反样本,而预测值却是正样本的数量;
TN表示真实值与预测值都是反样本的数量。
可见Tp与TN都是预测正确的情况。
- 预测的准确率可定义为:
Accurancy=(TP+TN)/(Tp+FN+FP+TN)
- 而预测的精确率表示预测为正的样本中有多少是真正的正例,故精确率可定义为:
Precision=TP/(TP+FP)
- 召回率表示样本中的正例有多少被预测正确了,故召回率可定义为:
Recall=TP/(TP+FN)
C.聚类任务
| 方 法 名 | 是否需要真实值监控 | 最 佳 值 |
|---|---|---|
| ARI(兰德系数)评价法 | 需要 | 1.0 |
| AMI(互信息)评价法 | 需要 | 1.0 |
| V-measure评分 | 需要 | 1.0 |
| FMI评价法 | 需要 | 1.0 |
| 轮廓系数评价法 | 不需要 | 畸变程度最大 |
| calinski_harabasz指数评价法 | 不需要 | 相比较最大 |
在聚类任务中,我们希望同一类的样本尽量类似,不同类的样本尽量不同。即簇内对象的相似度越大,不同簇之间的对象差别越大,聚类效果越好。聚类任务常用的评估指标如表所示。
8.使用模型
如果模型的性能能达到实际需求,就可以使用该模型预测新样本了。
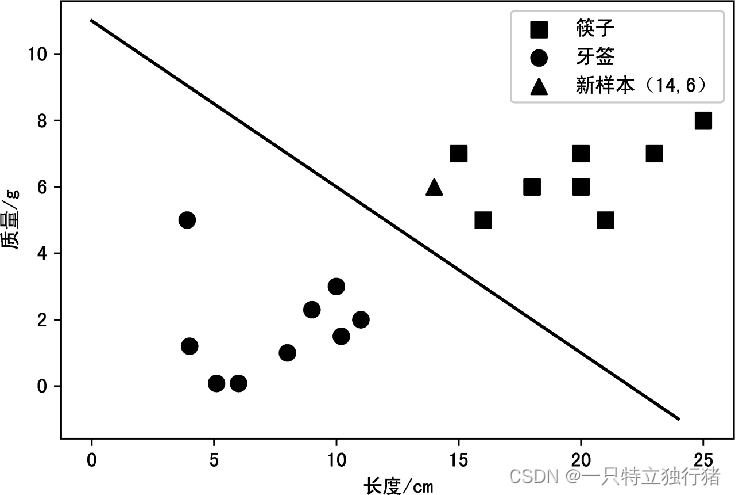
例如,假设区分筷子和牙签的模型训练出来并且能达到实际需求,那么,就可以将一个新样本的数据(长度为14 cm,质量为6 g)输入到该模型中,使用模型预测出输入的数据是筷子还是牙签.
相关文章:
零基础机器学习(3)之机器学习的一般过程
文章目录 一、机器学习一般过程1.数据获取2.特征提取3.数据预处理①去除唯一属性②缺失值处理A. 均值插补法B. 同类均值插补法 ③重复值处理④异常值⑤数据定量化 4.数据标准化①min-max标准化(归一化)②z-score标准化(规范化) 5.…...

用java做一个双色球彩票系统
代码如下: import java.util.Random; public class HelloWorld{public static void main(String[] args){//1、生成中奖号码 int[] arrcreateNumber();for (int i 0;i<arr.length;i) {System.out.print(arr[i]" ");}}public static int[] createNu…...
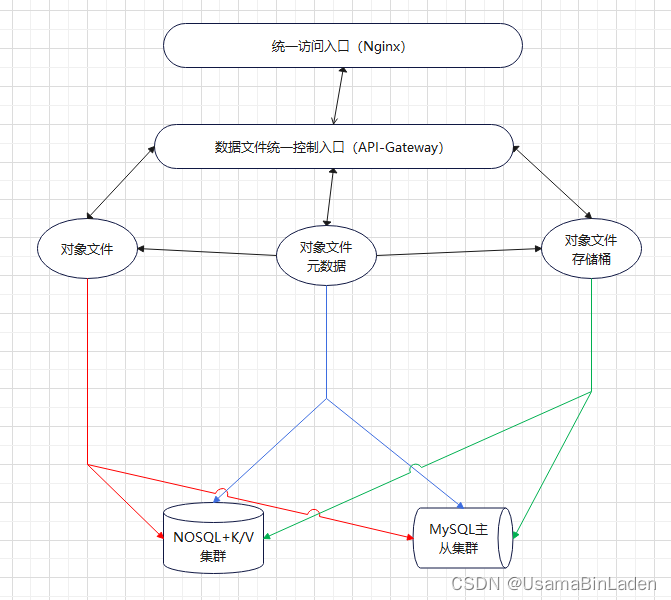
某对象存储元数据集群改造流水账
软件产品:某厂商提供的不便具名的对象存储产品,核心底层技术源自HDFS和Amazon S3,元数据集群采用了基于MongoDB的NOSQL数据库产品和MySQL数据库产品相结合。 该产品的元数据逻辑示意图如下: 业务集群现状:当前第3期建…...
——filter、foearch、for in 、for of 、for的区别以及返回值)
前端理论总结(js)——filter、foearch、for in 、for of 、for的区别以及返回值
Filter: 用途:用于筛选数组中符合条件的元素,返回一个新数组。 返回值:返回一个新数组,包含经过筛选的元素。 Foreach: 用途:遍历数组中的每个元素,执行回调函数。 返回值&#x…...
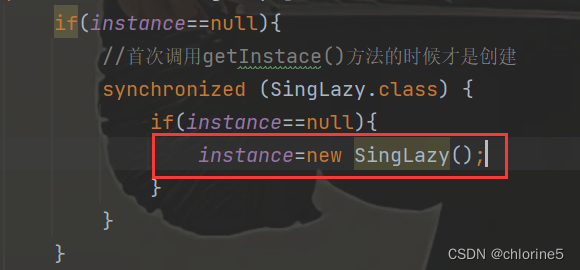
【JavaEE初阶系列】——多线程案例一——单例模式 (“饿汉模式“和“懒汉模式“以及解决线程安全问题)
目录 🚩单例模式 🎈饿汉模式 🎈懒汉模式 ❗线程安全问题 📝加锁 📝执行效率提高 📝指令重排序 🍭总结 单例模式,非常经典的设计模式,也是一个重要的学科&#x…...
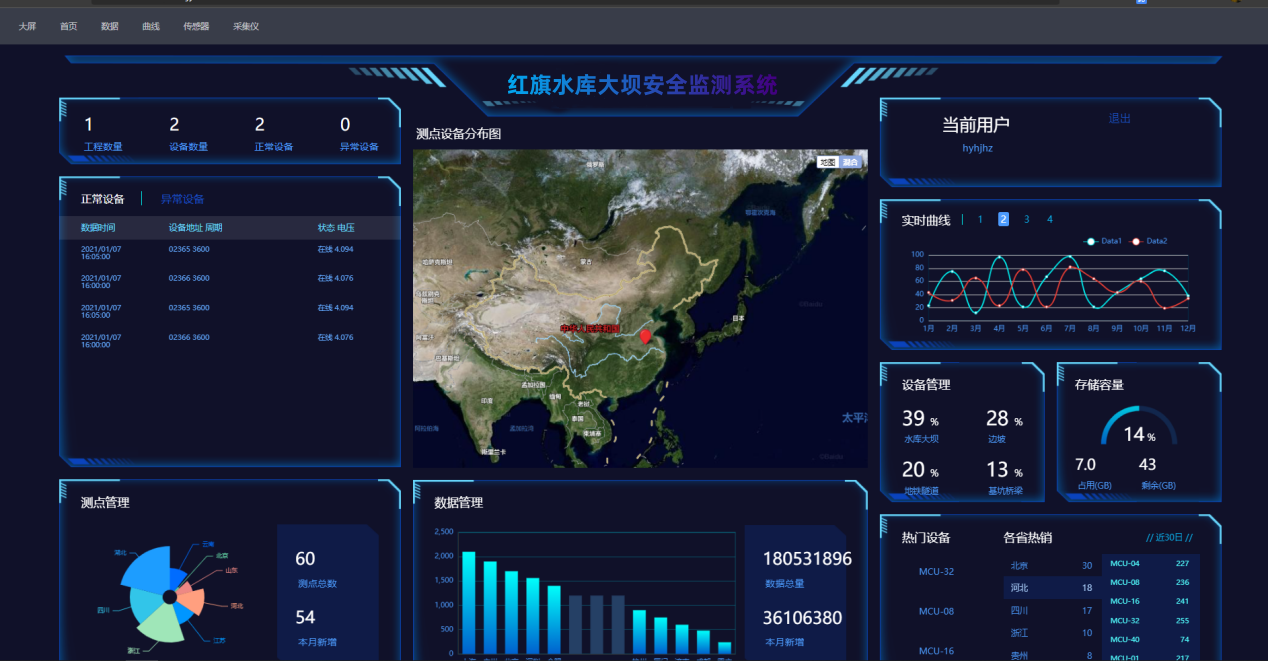
革新水库大坝监测:传统软件与云平台之比较
在水库大坝的监测管理领域,传统监测软件虽然曾发挥了重要作用,但在多方面显示出了其局限性。传统解决方案通常伴随着高昂的运维成本,需要大量的硬件支持和人员维护,且软件整合和升级困难,限制了其灵活性和扩展性。 点击…...
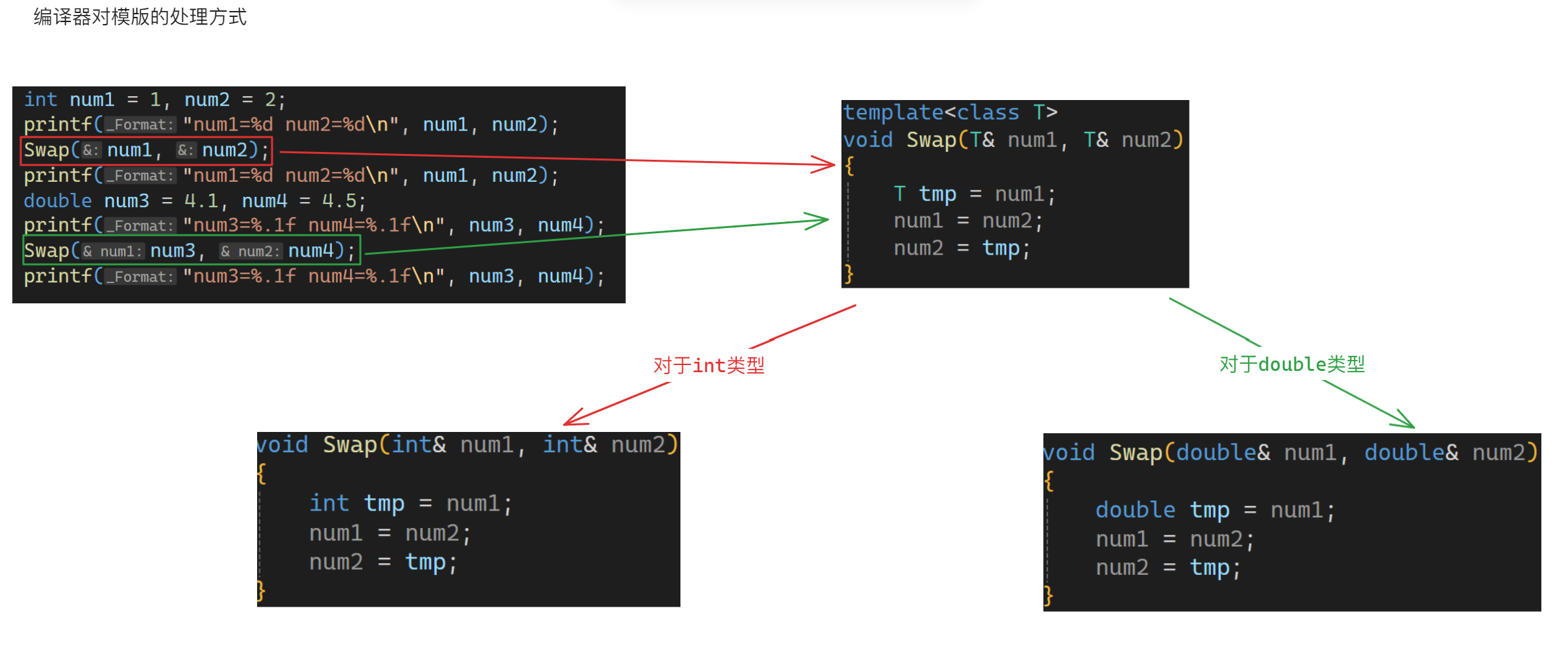
C++模版(基础)
目录 C泛型编程思想 C模版 模版介绍 模版使用 函数模版 函数模版基础语法 函数模版原理 函数模版实例化 模版参数匹配规则 类模版 类模版基础语法 C泛型编程思想 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。 模板是泛型编程…...
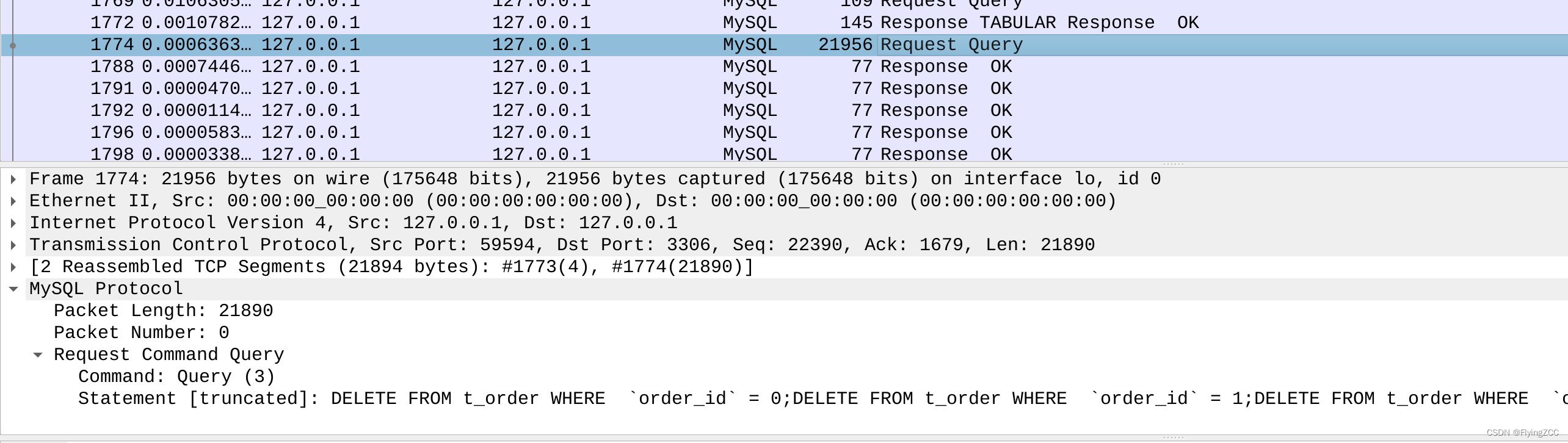
MySQL驱动Add Batch优化实现
MySQL 驱动 Add Batch 优化实现 MySQL 驱动会在 JDBC URL 添加 rewriteBatchedStatements 参数时,对 batch 操作进行优化。本文测试各种参数组合的行为,并结合驱动代码简单分析。 batch参数组合行为 useServerPrepStmts 参数 PreparedStatement psmt…...
手撕算法-数组中的第K个最大元素
描述 分析 使用小根堆,堆元素控制在k个,遍历数组构建堆,最后堆顶就是第K个最大的元素。 代码 class Solution {public int findKthLargest(int[] nums, int k) {// 小根堆PriorityQueue<Integer> queue new PriorityQueue<>…...

【vue】computed和watch的区别和应用场景
Computed 和 Watch 是 Vue.js 中用于监视数据变化的两个不同特性,它们各自有不同的应用场景和功能。 Computed: 计算属性(Computed properties)用于声明基于其他数据属性的计算值。它具有缓存功能,只有在依赖的数…...

ARM.day8
1.自己设置温度湿度阈值,当温度过高时,打开风扇,蜂鸣器报警 2.当湿度比较高时,打开LED1灯,蜂鸣器报警 main.c #include "si7006.h" #include "CH1.h" #include "led.h" // 延时函数in…...

SpringCloud Gateway工作流程
Spring Cloud Gateway的工作流程 具体的流程: 用户发送请求到网关 请求断言,用户请求到达网关后,由Gateway Handler Mapping(网关处理器映射)进行Predicates(断言),看一下哪一个符合…...

西井科技与安通控股签署战略合作协议 共创大物流全新生态
2024年3月21日,西井科技与安通控股在“上海硅巷”新象限空间正式签署战略合作框架协议。双方基于此前在集装箱物流的成功实践与资源优势,积极拓展在AI数字化产品、新能源自动驾驶解决方案和多场景应用,以及绿色物流链等领域的深度探索、强强联…...
)
CCCorelib 点云RANSAC拟合球体(CloudCompare内置算法库)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 RANSAC是一种随机参数估计算法。RANSAC从样本中随机抽选出一个样本子集,使用最小方差估计算法对这个子集计算模型参数,然后计算所有样本与该模型的偏差,再使用一个预先设定好的阈值与偏差比较,当偏差小于阈值时…...
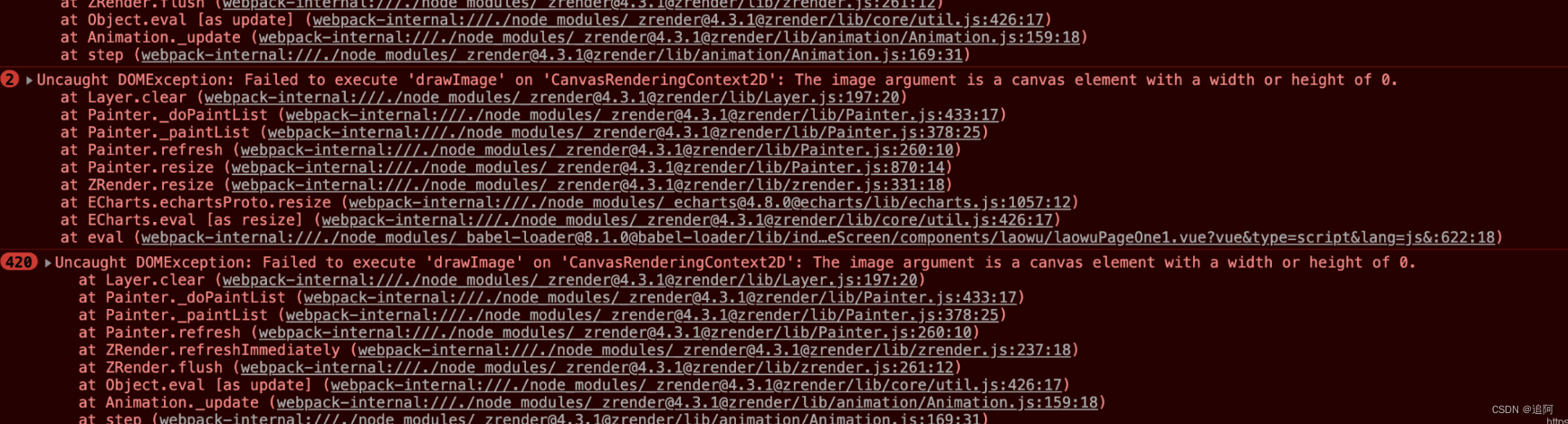
map china not exists. the geojson of the map must be provided.
map china not exists. the geojson of the map must be provided. 场景:引入echarts地图报错map china not exists. the geojson of the map must be provided. 原因: echarts版本过高,ECharts 之前提供下载的矢量地图数据来自第三方&…...

Redis如何删除大key
参考阿里云Redis规范 查找大key: redis-cli --bigkeys 1、String类型: Redis 4.0及以后版本提供了UNLINK命令,该命令与DEL命令类似,但它会在后台异步删除key,不会阻塞当前客户端,也不会阻塞Redis服务器的…...
JRT菜单
上一章搭建了登录界面的雏形和抽取了登录接口。给多组使用登录和菜单功能提供预留,做到不强行入侵别人业务。任何产品只需要按自己表实现登录接口后配置到容器即可共用登录界面和菜单部分。最后自己的用户关联到JRT角色表即可。 登录效果 这次构建菜单体系 首先用…...

《海王2》观后感
前言 我原本计划电影上映之后,去电影院观看的,但时间过得飞快,一眨眼这都快4月份了,查了一下,电影院早就没有排片了,所以只能在B站看了,这里不得不吐槽一下,原来花了4块钱购买观看还…...
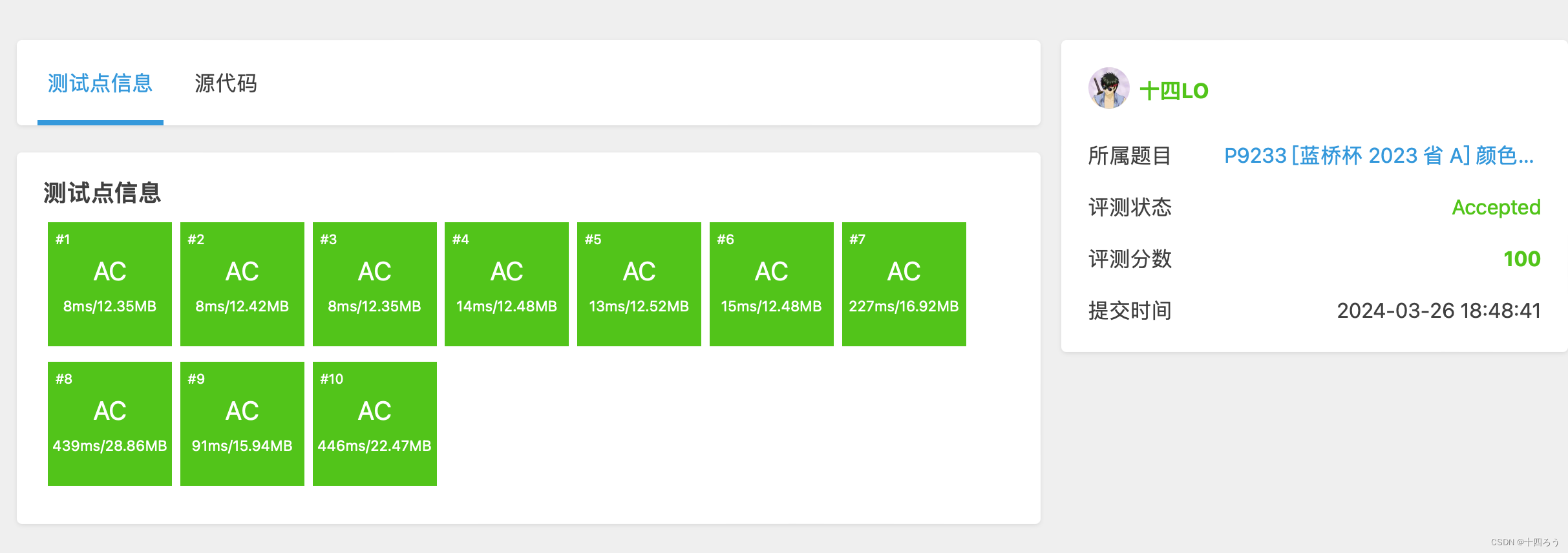
[蓝桥杯 2023 省 A] 颜色平衡树:从零开始理解树上莫队 一颗颜色平衡树引发的惨案
十四是一名生物工程的学生,他已经7年没碰过信息学竞赛了,有一天他走在蓝桥上看见了一颗漂亮的颜色平衡树: [蓝桥杯 2023 省 A] 颜色平衡树 - 洛谷 十四想用暴力解决问题,他想枚举每个节点,每个节点代表…...
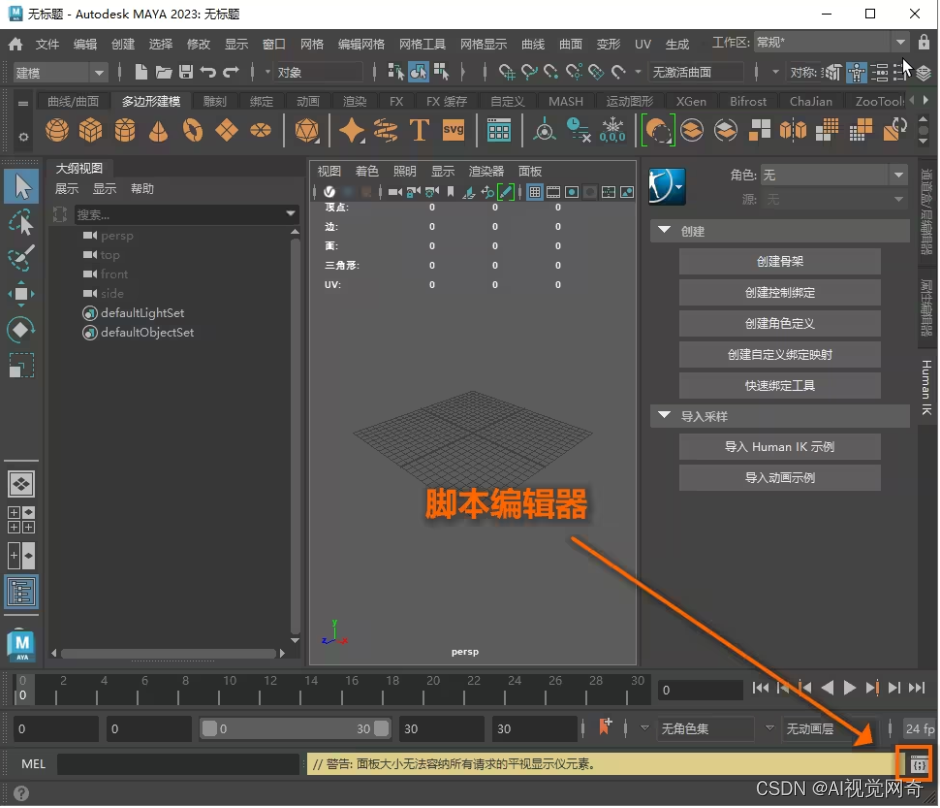
maya打开bvh脚本
目录 maya打开脚本编辑器 运行打开bvh脚本 maya导出bvh脚本 maya打开脚本编辑器 打开Maya软件,点击右下角 “脚本编辑器” 运行打开bvh脚本 https://github.com/jhoolmans/mayaImporterBVH/blob/master/bvh_importer.py import os import re from typing impo…...

量子机器学习可解释性:从黑箱到透明决策的LRP与数字孪生方法
1. 量子机器学习可解释性:从黑箱到透明决策量子机器学习(QML)这几年火得不行,但说实话,很多从业者,包括我自己在内,最初接触时都有点“懵”。模型性能上去了,可它到底是怎么做决策的…...
)
告别文件重命名!统信UOS 1060开启长文件名支持的保姆级图文教程(UDOM工具箱版)
统信UOS 1060长文件名支持全攻略:UDOM工具箱图形化操作指南从Windows切换到国产操作系统的用户,最常遇到的困扰之一就是文件命名限制。想象一下,当你精心整理的"2023年度市场营销策划案最终修订版V3.5-包含所有渠道投放预算与ROI分析.xl…...

UE5 GPU崩溃真相:Windows TCC超时机制与注册表调优指南
1. 为什么UE5项目一跑就GPU崩溃,而系统却说“显卡没出问题”?你刚在UE5里搭好一个带Niagara粒子Lumen全局光照的场景,点下Play,画面卡住两秒,然后整个编辑器黑屏、崩溃,任务管理器里UnrealEditor进程直接消…...

实测天下工厂:用它找工厂客户,数据准不准、覆盖全不全?
做 B2B 销售的人都知道,找到一份"高质量工厂名单"有多难。 不是因为工厂数量少,而是因为现有渠道普遍存在一个结构性问题:工厂和非工厂混在一起,分不清楚。用通用企业查询工具检索某个行业,跑出来的结果里&a…...

昇腾CANN ATB KV Cache 与 PagedAttention:显存碎片消除的完整方案
LLM 推理的最大瓶颈不是计算——是显存。长上下文下,KV Cache 的显存占用是二次增长的:seq_len128K → KV Cache 128K 每层 KV 大小 128K (2 hidden head_num) 128K 2 8192 32 32GB。加上模型参数(70B 2bytes 140GB)…...

告别Typora和Vditor?在WordPress后台打造你的全能Markdown写作环境
在WordPress中构建专业级Markdown写作环境的完整指南 对于习惯使用Typora、Vditor等独立Markdown编辑器的创作者来说,WordPress后台的默认编辑器往往显得笨重且功能有限。但通过合理的插件配置和主题选择,我们完全可以在WordPress中打造一个媲美专业编辑…...

电玩城新政解读:价格趋势与消费避坑指南
行业现状:一场新规带来的市场洗牌最近,不少玩家发现,常去的那家电玩城变了——以前一块钱两个币,现在一块钱一个币,机器游戏规则也悄悄调整了。这背后,是2024年以来多地密集出台电玩城管理新规带来的连锁反…...

基于DSP与SC1083 ADC的光纤远程数据采集系统设计实战
1. 项目概述:当DSP遇上高速光缆,如何构建一个“快、准、稳”的远程数据采集系统在工业自动化、电力监测、超声无损检测这些领域,我们经常需要面对一个头疼的问题:如何把现场传感器采集到的大量、高速、有时甚至是微弱的模拟信号&a…...

汽车12V电源保护:TVS二极管选型、应用与EMC测试实战
1. 项目概述:为什么汽车12V电源线需要“特种保镖”?在汽车电子系统里,那根看似普通的12V DC电源线,其实是个“压力山大”的角色。它不仅要给车机、仪表、传感器、ECU(电子控制单元)这些“大脑”和“神经”稳…...

3步快速搭建微信小程序商城:巴爷商城开源项目实战指南
3步快速搭建微信小程序商城:巴爷商城开源项目实战指南 【免费下载链接】wechat_mall_applet A real mall wechat applet 项目地址: https://gitcode.com/gh_mirrors/we/wechat_mall_applet 还在为开发微信小程序商城而烦恼吗?🤔 今天我…...