信号处理--基于DEAP数据集的情绪分类的典型深度学习模型构建
关于
本实验采用DEAP情绪数据集进行数据分类任务。使用了三种典型的深度学习网络:2D 卷积神经网络;1D卷积神经网络+GRU; LSTM网络。
工具



数据集
DEAP数据


图片来源: DEAP: A Dataset for Emotion Analysis using Physiological and Audiovisual Signals
方法实现
2D-CNN网络
加载必要库函数
import pandas as pd
import keras.backend as K
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from keras.models import Sequential
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from tensorflow.keras.utils import to_categorical
from keras.layers import Flatten
from keras.layers import Dense
import numpy as np
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras import backend as K
from keras.models import Model
import timeit
from keras.models import Sequential
from keras.layers.core import Flatten, Dense, Dropout
from keras.layers.convolutional import Convolution1D, MaxPooling1D, ZeroPadding1D
from tensorflow.keras.optimizers import SGD
#import cv2, numpy as np
import warnings
warnings.filterwarnings('ignore')加载DEAP数据集
data_training = []
label_training = []
data_testing = []
label_testing = []for subjects in subjectList:with open('/content/drive/My Drive/leading_ai/try/s' + subjects + '.npy', 'rb') as file:sub = np.load(file,allow_pickle=True)for i in range (0,sub.shape[0]):if i % 5 == 0:data_testing.append(sub[i][0])label_testing.append(sub[i][1])else:data_training.append(sub[i][0])label_training.append(sub[i][1])np.save('/content/drive/My Drive/leading_ai/data_training', np.array(data_training), allow_pickle=True, fix_imports=True)
np.save('/content/drive/My Drive/leading_ai/label_training', np.array(label_training), allow_pickle=True, fix_imports=True)
print("training dataset:", np.array(data_training).shape, np.array(label_training).shape)np.save('/content/drive/My Drive/leading_ai/data_testing', np.array(data_testing), allow_pickle=True, fix_imports=True)
np.save('/content/drive/My Drive/leading_ai/label_testing', np.array(label_testing), allow_pickle=True, fix_imports=True)
print("testing dataset:", np.array(data_testing).shape, np.array(label_testing).shape)数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)定义训练超参数
batch_size = 256
num_classes = 10
epochs = 200
input_shape=(x_train.shape[1], 1)定义模型
from keras.layers import Convolution1D, ZeroPadding1D, MaxPooling1D, BatchNormalization, Activation, Dropout, Flatten, Dense
from keras.regularizers import l2model = Sequential()
intput_shape=(x_train.shape[1], 1)
model.add(Conv1D(164, kernel_size=3,padding = 'same',activation='relu', input_shape=input_shape))
model.add(BatchNormalization())
model.add(MaxPooling1D(pool_size=(2)))
model.add(Conv1D(164,kernel_size=3,padding = 'same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling1D(pool_size=(2)))
model.add(Conv1D(82,kernel_size=3,padding = 'same', activation='relu'))
model.add(MaxPooling1D(pool_size=(2)))
model.add(Flatten())
model.add(Dense(82, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(42, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(21, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()模型配置和训练
model.compile(loss=keras.losses.categorical_crossentropy,optimizer='adam',metrics=['accuracy'])history=model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs, verbose=1,validation_data=(x_test,y_test))
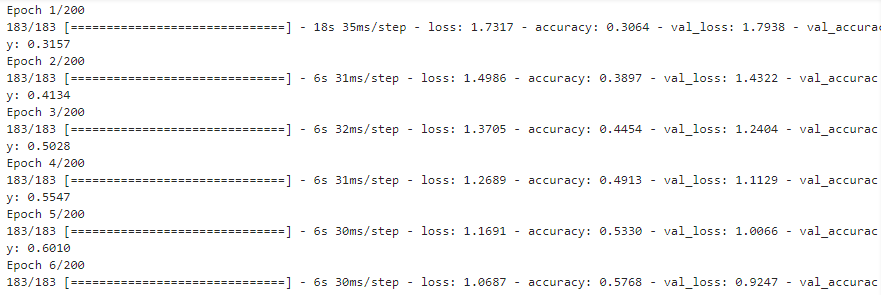
模型测试集验证
score = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
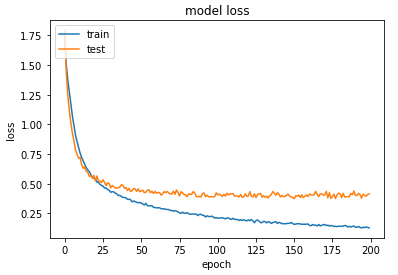
模型训练过程可视化
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()

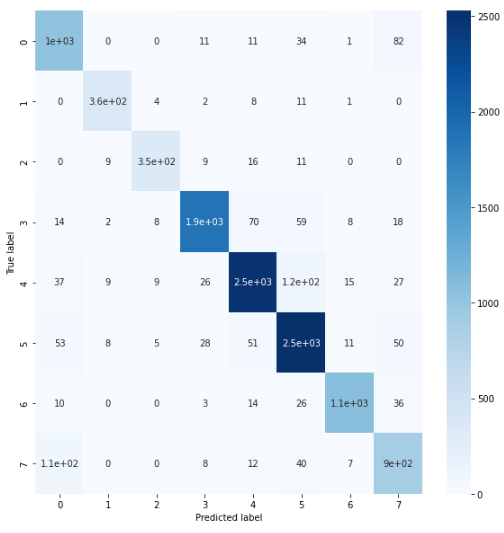
模型测试集分类混沌矩阵
cmatrix=confusion_matrix(y_test1, y_pred)import seaborn as sns
figure = plt.figure(figsize=(8, 8))
sns.heatmap(cmatrix, annot=True,cmap=plt.cm.Blues)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
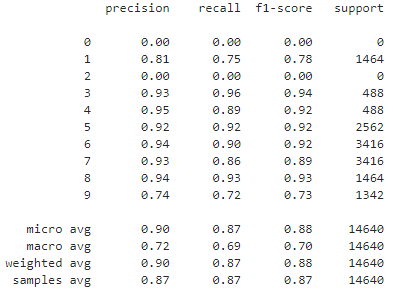
模型测试集分类report
from sklearn import metrics
y_pred = np.around(model.predict(x_test))
print(metrics.classification_report(y_test,y_pred))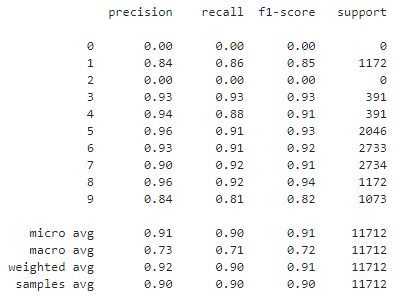
1D-CNN+GRU网络
数据预处理
必要库函数加载,数据加载预处理,同2D CNN一样,不在赘述。
!pip install git+https://github.com/forrestbao/pyeeg.git
import numpy as np
import pyeeg as pe
import pickle as pickle
import pandas as pd
import matplotlib.pyplot as plt
import mathimport os
import time
import timeit
import keras
import keras.backend as K
from keras.models import Model
from keras.layers import Flatten
from keras.datasets import mnist
from keras.models import Sequential
from sklearn.preprocessing import normalize
from tensorflow.keras.optimizers import SGD
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.convolutional import ZeroPadding1D
from tensorflow.keras.utils import to_categorical
from keras.layers import Dense, Dropout, Flatten,GRUimport warnings
warnings.filterwarnings('ignore')模型搭建
from keras.layers import Convolution1D, ZeroPadding1D, MaxPooling1D, BatchNormalization, Activation, Dropout, Flatten, Dense,GRU,LSTM
from keras.regularizers import l2from keras.models import load_model
from keras.layers import Lambda
import tensorflow as tfmodel_2 = Sequential()model_2.add(Conv1D(128, 3, activation='relu', input_shape=input_shape))
model_2.add(MaxPooling1D(pool_size=2))
model_2.add(Dropout(0.2))model_2.add(Conv1D(128, 3, activation='relu'))
model_2.add(MaxPooling1D(pool_size=2))
model_2.add(Dropout(0.2))model_2.add(GRU(units = 256, return_sequences=True))
model_2.add(Dropout(0.2))model_2.add(GRU(units = 32))
model_2.add(Dropout(0.2))model_2.add(Flatten())model_2.add(Dense(units = 128, activation='relu'))
model_2.add(Dropout(0.2))model_2.add(Dense(units = num_classes))
model_2.add(Activation('softmax'))model_2.summary()

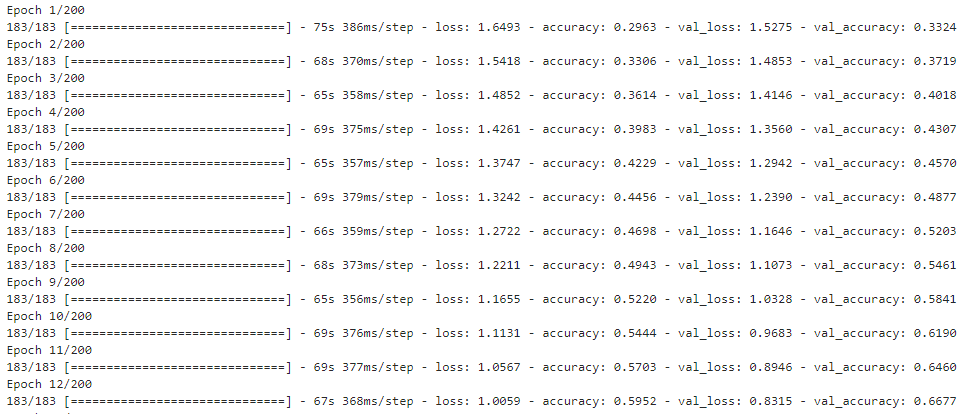
模型编译和训练
model_2.compile(optimizer ="adam",loss = 'categorical_crossentropy',metrics=["accuracy"]
)history_2 = model_2.fit(x_train, y_train,epochs=epochs,batch_size=batch_size,verbose=1,validation_data=(x_test, y_test),callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',patience=20,restore_best_weights=True)]
)
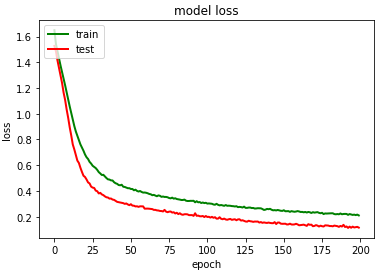
模型训练过程可视化
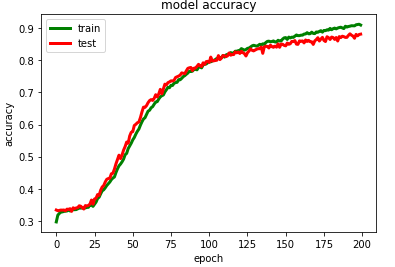
# summarize history for accuracy
plt.plot(history_2.history['accuracy'],color='green',linewidth=3.0)
plt.plot(history_2.history['val_accuracy'],color='red',linewidth=3.0)
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')plt.savefig("/content/drive/My Drive/GRU/model accuracy.png")
plt.show()# summarize history for loss
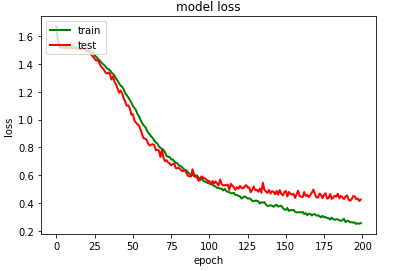
plt.plot(history_2.history['loss'],color='green',linewidth=2.0)
plt.plot(history_2.history['val_loss'],color='red',linewidth=2.0)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')plt.savefig("/content/drive/My Drive/GRU/model loss.png")
plt.show()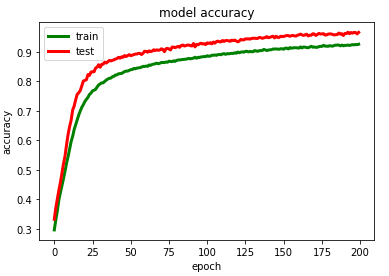
模型测试集分类混沌矩阵和分类report

LSTM网络
数据加载/预处理
同上
模型搭建和训练
from keras.regularizers import l2from keras.layers import Bidirectionalfrom keras.layers import LSTMmodel = Sequential()model.add(Bidirectional(LSTM(164, return_sequences=True), input_shape=input_shape))model.add(Dropout(0.6))model.add(LSTM(units = 256, return_sequences = True)) model.add(Dropout(0.6))model.add(LSTM(units = 82, return_sequences = True)) model.add(Dropout(0.6))model.add(LSTM(units = 82, return_sequences = True)) model.add(Dropout(0.4))model.add(LSTM(units = 42))model.add(Dropout(0.4))model.add(Dense(units = 21))model.add(Activation('relu'))model.add(Dense(units = num_classes))model.add(Activation('softmax'))model.compile(optimizer ="adam", loss =keras.losses.categorical_crossentropy,metrics=["accuracy"])model.summary()m=model.fit(x_train, y_train,epochs=200,batch_size=256,verbose=1,validation_data=(x_test, y_test))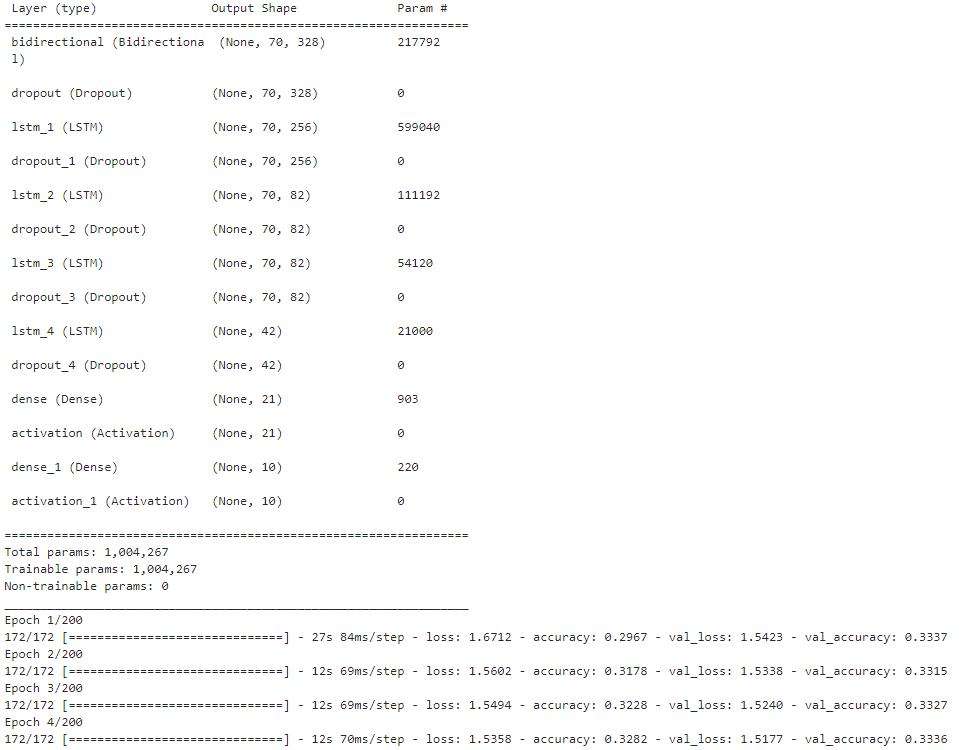
模型训练过程可视化
import matplotlib.pyplot as plt
print(m.history.keys())
# summarize history for accuracy
plt.plot(m.history['accuracy'],color='green',linewidth=3.0)
plt.plot(m.history['val_accuracy'],color='red',linewidth=3.0)plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')plt.savefig("./Bi- LSTM/model accuracy.png")
plt.show()import imageio
plt.plot(m.history['loss'],color='green',linewidth=2.0)
plt.plot(m.history['val_loss'],color='red',linewidth=2.0)plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')#to save the image
plt.savefig("./Bi- LSTM/model loss.png")
plt.show()
模型测试集分类性能
代码获取
后台私信,请注明文章题目(数据需要自己下载和处理)
相关项目和代码问题,欢迎交流。
相关文章:
信号处理--基于DEAP数据集的情绪分类的典型深度学习模型构建
关于 本实验采用DEAP情绪数据集进行数据分类任务。使用了三种典型的深度学习网络:2D 卷积神经网络;1D卷积神经网络GRU; LSTM网络。 工具 数据集 DEAP数据 图片来源: DEAP: A Dataset for Emotion Analysis using Physiological…...

Spring设计模式-实战篇之模板方法模式
什么是模板方法模式? 模板方法模式用于定义一个算法的框架,并允许子类在不改变该算法结构的情况下重新定义算法中的某些步骤。这种模式提供了一种将算法的通用部分封装在一个模板方法中,而将具体步骤的实现延迟到子类中的方式。 模板方法模式…...

PTA天梯赛习题 L2-006 树的遍历
先序遍历:根-左-右 > 序列的第一个数就是根 中序遍历:左-根-右 > 知道中间某一个数为根,则这个数的左边就是左子树,右边则是右子树 后序遍历:左-右-根 > 序列的最后一个数就是根 题目 给定一棵…...

js相关的dom方法
查找元素 //获取元素id为box的元素 document.getElementById(box) //获取元素类名为box的元素 document.getElementsByClassName(box) //获取标签名为div的元素 document.getElementsByTagName(div)改变元素 //设置id为box的元素内容 document.getElementById("box"…...

Django——Ajax请求
Django——Ajax请求 一、响应 Json 数据 path(str/ , views.str_view), path(json/ , views.json_view), path(jsonresponse/ , views.jsonresponse_view), path(ls/ , views.ls),from django.shortcuts import render , HttpResponse from django.http import JsonResponse …...
基于java多角色学生管理系统论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本学生管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息&am…...
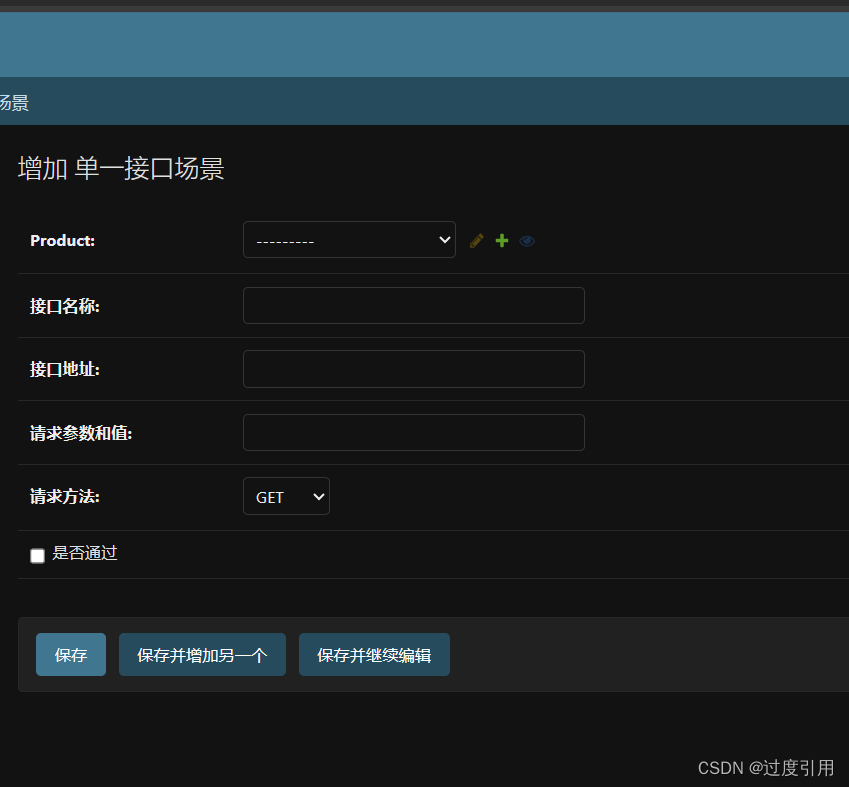
python(django)之单一接口管理功能后台开发
1、创建数据模型 在apitest/models.py下加入以下代码 class Apis(models.Model):Product models.ForeignKey(product.Product, on_deletemodels.CASCADE, nullTrue)# 关联产品IDapiname models.CharField(接口名称, max_length100)apiurl models.CharField(接口地址, max_…...

教程1_图像视频入门
一、图像入门 1、cv2.imread()函数 cv2.imread() 是 OpenCV 库中的一个函数,用于读取图像文件。下面是 cv2.imread() 函数的基本介绍和使用方法: 函数定义 cv2.imread(filename, flagscv2.IMREAD_COLOR) 参数 filename:要读取的图像的路…...
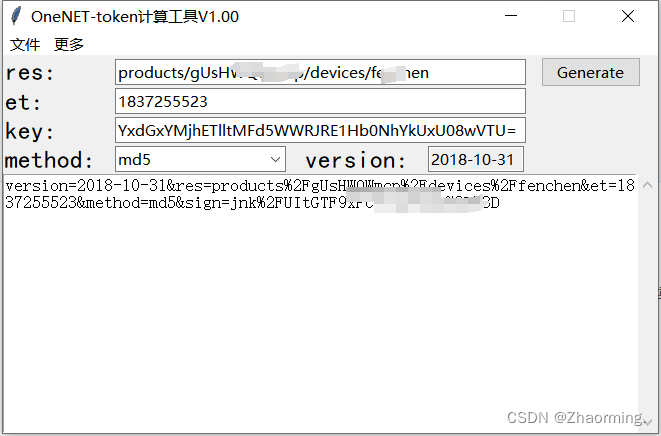
MQTT.fx和MQTTX 链接ONENET物联网提示账户或者密码错误
参考MQTT.fx和MQTTX 链接ONENET物联网开发平台避坑细节干货。_mqttx和mqttfx-CSDN博客 在输入password和username后还是提示错误,是因为在使用token的时候,key填写错误,将设备的密钥填入key中...

Svn添加用户、添加用户组、配置项目权限等自动化配置脚本
实现在工作中自动化配置svn用户、用户组、和项目权限的脚本,在使用过程中如果有什么问题,可以联系我。 移步到gitee: svn account permission management: Svn账号、组、权限管理脚本 (gitee.com)...
Spring事务-两种开启事务管理的方式:基于注解的声明式事务管理、基于编程式的事务管理
Spring事务-两种开启事务管理的方式 1、前期准备2、基于注解的声明式事务管理3、基于编程式的事务管理4、声明式事务失效的情况 例子:假设有一个银行转账的业务,其中涉及到从一个账户转钱到另一个账户。在这个业务中,我们需要保证要么两个账户…...

OC 技术 苹果内购
一直觉得自己写的不是技术,而是情怀,一个个的教程是自己这一路走来的痕迹。靠专业技能的成功是最具可复制性的,希望我的这条路能让你们少走弯路,希望我能帮你们抹去知识的蒙尘,希望我能帮你们理清知识的脉络࿰…...

云原生周刊:Kubernetes v1.30 一瞥 | 2024.3.25
开源项目推荐 Retina Retina 是一个与云无关的开源 Kubernetes 网络可观测平台,它提供了一个用于监控应用程序运行状况、网络运行状况和安全性的集中中心。它为集群网络管理员、集群安全管理员和 DevOps 工程师提供可操作的见解,帮助他们了解 DevOps、…...

2016年认证杯SPSSPRO杯数学建模D题(第一阶段)NBA是否有必要设立四分线解题全过程文档及程序
2016年认证杯SPSSPRO杯数学建模 D题 NBA是否有必要设立四分线 原题再现 NBA 联盟从 1946 年成立到今天,一路上经历过无数次规则上的变迁。有顺应民意、皆大欢喜的,比如 1973 年在技术统计中增加了抢断和盖帽数据;有应运而生、力挽狂澜的&am…...
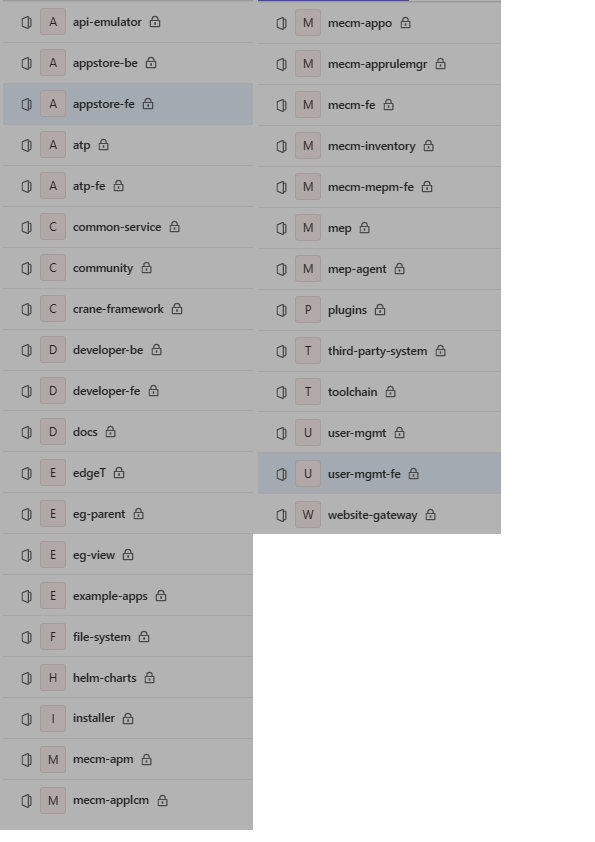
EdgeGallery开发指南
API接口 简介 EdgeGallery支持第三方业务系统通过北向接口网关调用EdgeGallery的业务接口。调用流程如下图所示(融合前端edgegallery-fe包含融合前端界面以及北向接口网关功能,通过浏览器访问时打开的是融合前端的界面,通过IP:Port/urlPref…...
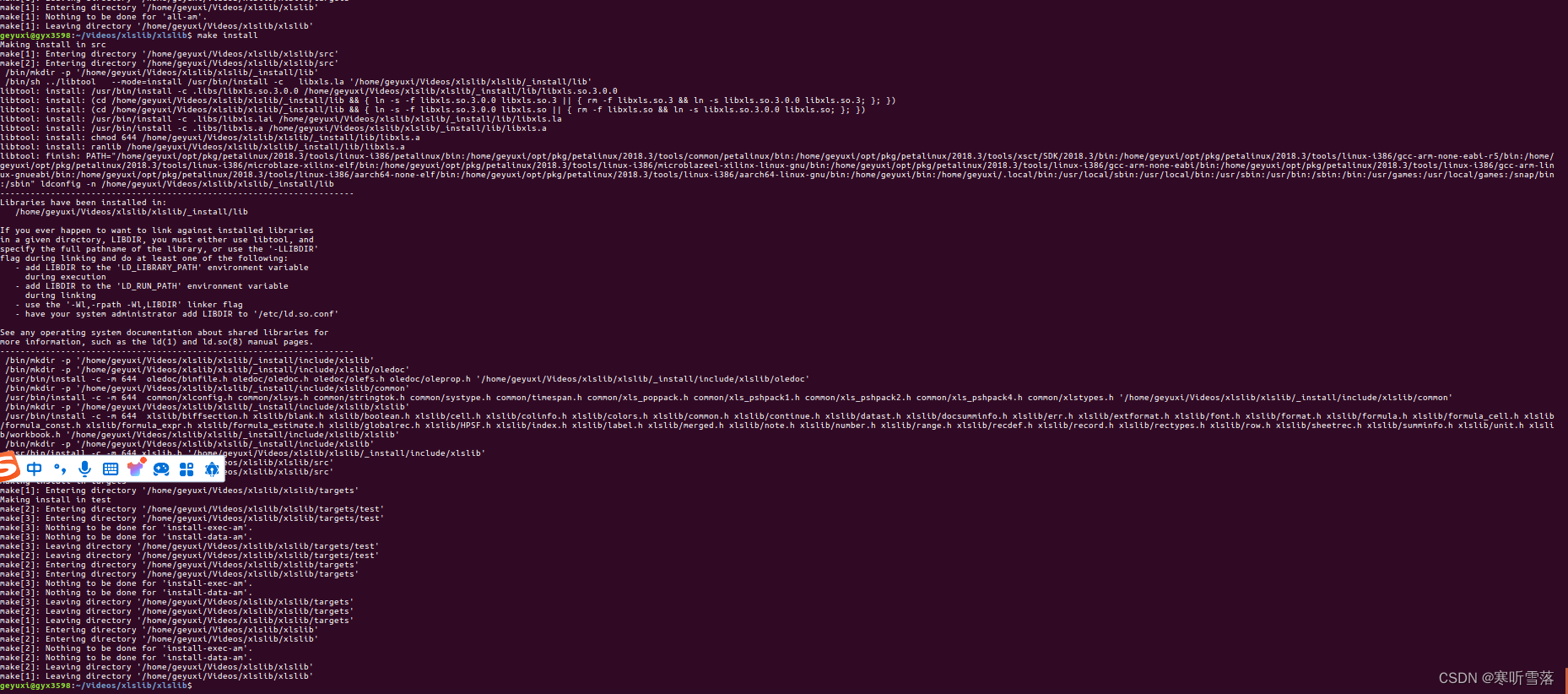
ubuntu arm qt 读取execl xls表格数据
一,ubuntu linux pc编译读取xls的库 1,安装libxls(读取xls文件 电脑版) 确保你已经安装了基本的编译工具,如gcc和make。如果没有安装,可以使用以下命令安装: sudo apt-update sudo apt-get install build-essentia…...
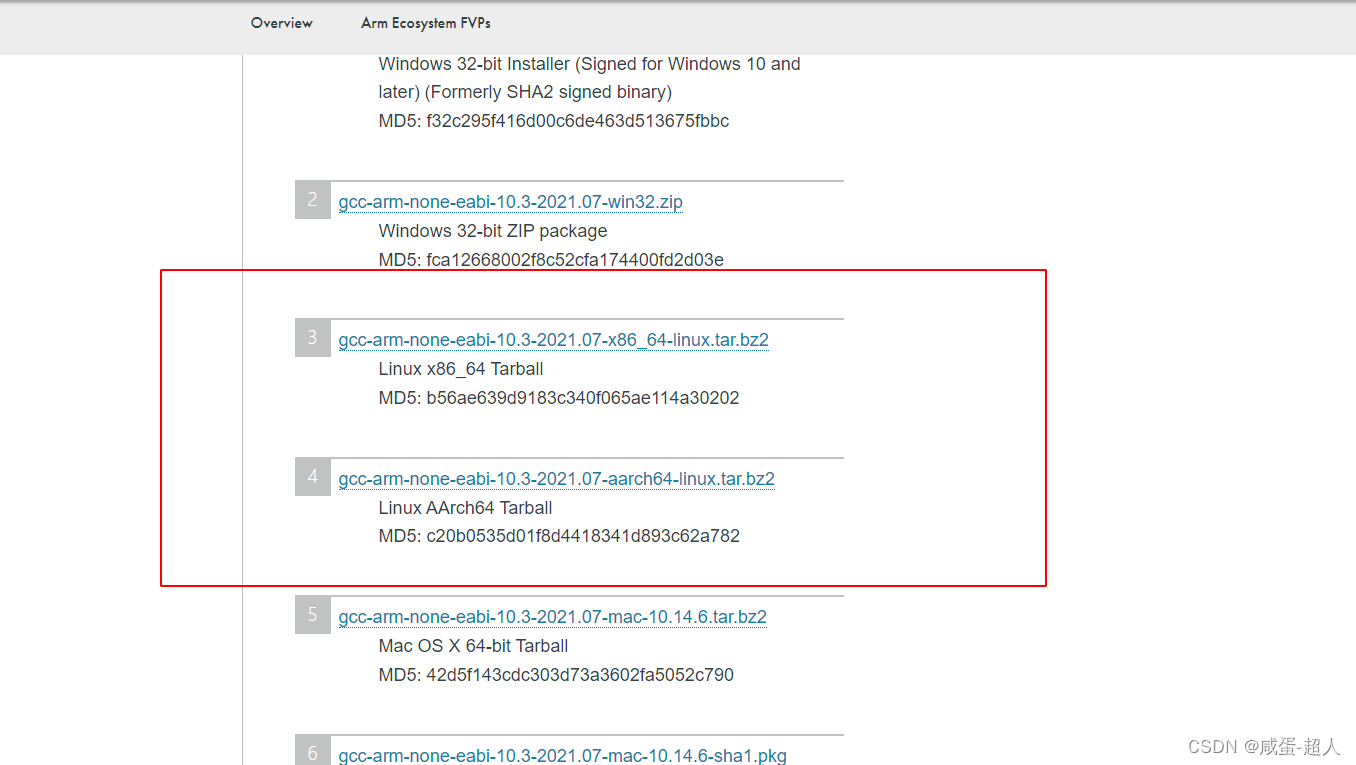
STM32 使用gcc编译介绍
文章目录 前言1. keil5下的默认编译工具链用的是哪个2. Arm编译工具链和GCC编译工具链有什么区别吗?3. Gcc交叉编译工具链的命名规范4. 怎么下载gcc-arm编译工具链参考资料 前言 我们在STM32上进行开发时,一般都是基于Keil5进行编译下载,Kei…...

FPGA之组合逻辑与时序逻辑
数字逻辑电路根据逻辑功能的不同,可以分成两大类:组合逻辑电路和时序逻辑电路,这两种电路结构是FPGA编程常用到的,掌握这两种电路结构是学习FPGA的基本要求。 1.组合逻辑电路 组合逻辑电路概念:任意时刻的输出仅仅取决…...
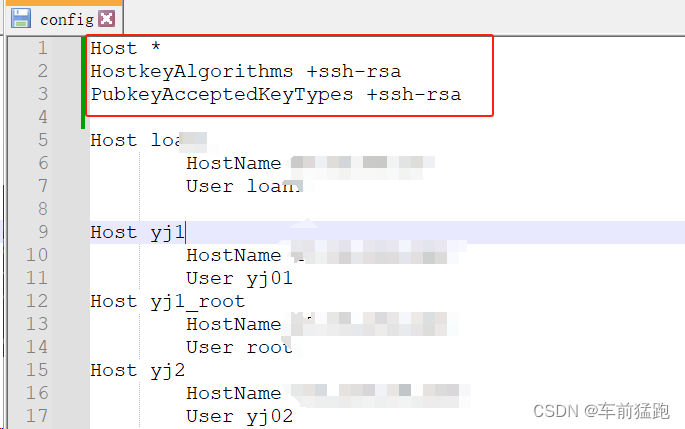
git clone没有权限的解决方法
一般情况 git clone时没有权限,一般是因为在代码库平台上没有配置本地电脑的id_rsa.pub 只要配置上,一般就可以正常下载了。 非一般情况 但是也有即使配置了id_rsa.pub后,仍然无法clone代码的情况。如下 原因 这种情况是因为ssh客户端…...

Redis 的内存回收策略
Redis的内存回收策略用于处理过期数据和内存溢出情况,确保系统稳定性和性能。作为一个高性能的键值存储系统,它通过内存回收策略来维护内存的高效使用 主要包括过期删除策略和内存淘汰策略。 过期删除策略: Redis的过期删除策略是通过设置…...
)
别再混淆EbN0和SNR了!手把手教你用Python验证MQAM误码率公式(附完整代码)
从理论到实践:用Python彻底解析EbN0与SNR的误码率验证 通信仿真中经常遇到一个经典问题:为什么我的误码率曲线和理论公式对不上?这个问题困扰过无数通信工程师和研究者。本文将带你从基础概念出发,通过Python代码实现,…...

Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案
Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-u…...

如何快速为小爱音箱添加AI大脑:终极智能升级指南
如何快速为小爱音箱添加AI大脑:终极智能升级指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 想让家中的小爱音箱从"人工智障…...

终极指南:如何用Blender 3MF插件实现3D打印数据无损传递
终极指南:如何用Blender 3MF插件实现3D打印数据无损传递 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否曾经在3D打印工作流中遇到过这样的问题&#x…...

SQLines 数据库迁移工具深度解析:跨平台SQL转换的技术实现与最佳实践
SQLines 数据库迁移工具深度解析:跨平台SQL转换的技术实现与最佳实践 【免费下载链接】sqlines SQLines Open Source Database Migration Tools 项目地址: https://gitcode.com/gh_mirrors/sq/sqlines 在当今多数据库架构环境中,企业面临着从传统…...

STM32以太网实战:手把手教你配置SMI接口,搞定PHY寄存器读写
STM32以太网实战:手把手教你配置SMI接口,搞定PHY寄存器读写 在嵌入式以太网开发中,PHY芯片的配置往往是项目成败的关键。很多开发者能够轻松完成MAC层的初始化,却在PHY寄存器读写这个环节卡壳——明明硬件连接正确,却无…...

LCD人体秤嵌入式方案全解析:从传感器到低功耗设计
1. 项目概述:从“称重”到“健康管理”的智能跨越“电子秤方案——LCD人体秤方案”这个标题,乍一看似乎只是关于一个简单的称重工具。但在这个全民关注健康、数据驱动生活的时代,一台现代的人体秤早已超越了“称体重”的单一功能。它集成了传…...

UE5 Paper2D地形材质系统核心解析:坡度混合与Slope LUT实现
1. 这不是普通材质文件——PaperTerrainMaterial.cpp是UE5中2D地形系统的“神经中枢”你打开UE5的源码目录,翻到Engine/Source/Runtime/Paper2D/Private/Terrain/路径下,一眼就能看到PaperTerrainMaterial.cpp。它不像PaperSprite.cpp那样被教程反复提及…...

Vue3——defineOptions和defineModel
1.出现背景2.defineOptions2.1 作用当使用setup语法糖后,它把很多东西都隐藏起来了,让你不需要手动写 export default(Vue2) 或者 setup() 原生函数,但是其它组件选项对象需要 export default 存在才能添加。defineOptions用于在单文件组件&a…...

H3CSE 高性能园区网:生成树保护机制
H3CSE 高性能园区网:生成树保护机制一、生成树保护机制1. BPDU保护1.1 边缘端口特点及问题端口基础特性存在的安全隐患1.2 BPDU保护机制核心防护逻辑机制运行优势1.3 BPDU保护配置配置使用规范H3C设备配置命令2. 根桥保护2.1 根桥保护机制2.2 根桥保护配置要求2.3 根…...