卷积神经网络(CNN):图像识别的强大工具
目录
1. 引言
2.卷积神经网络的基本原理
2.1.输入层
2.2.卷积层
2.3.池化层
2.4.激活层
2.5.全连接层(可选)
2.6.输出层
3.卷积神经网络的基本结构
4.卷积神经网络的训练过程
5.代码示例
6.总结
1. 引言
在图像处理与计算机视觉领域,卷积神经网络(CNN)已成为一种强大的工具,广泛应用于图像识别、目标检测、人脸识别等任务中。本文旨在介绍CNN的基本原理、结构,并通过一个具体的图像分类任务示例,帮助读者更好地理解和应用CNN。更多Python在人工智能中的使用方法,欢迎关注《Python人工智能实战》专栏!
2.卷积神经网络的基本原理
CNN的核心思想是利用卷积层自动提取输入图像的特征。卷积层由一系列可学习的滤波器组成,这些滤波器在图像上滑动,计算局部区域的点积,从而产生特征图(feature maps)。这些特征图随后被送入下一层网络进行进一步的处理。
2.1.输入层
这是整个神经网络的输入。在处理图像的CNN中,输入层一般代表了一张图片的像素矩阵。这个矩阵的三维性体现在:长和宽代表图像的大小,而深度代表图像的色彩通道。例如,黑白图片的深度为1,而在RGB色彩模式下,图像的深度为3。
2.2.卷积层
卷积层是CNN的核心部分,它通过一组可训练的卷积核对输入图像进行卷积运算,从而得到一组特征图(Feature Map)。每个卷积核在图像上滑动,将其覆盖区域的像素值与卷积核的权重相乘并求和,最终得到一个标量。这个标量可以看作是特征图上对应像素的值,反映了卷积核在当前位置的响应。卷积层的作用主要是提取图像的特征。
from tensorflow.keras.layers import Conv2D# 示例:创建一个具有32个滤波器、3x3大小、步长为1、填充为'same'的卷积层
conv_layer = Conv2D(filters=32, kernel_size=(3, 3), strides=1, padding='same')2.3.池化层
池化层(Pooling layer)通常跟在卷积层后面,用于降低特征图的空间尺寸,减少参数数量和计算量,同时保持重要的特征信息。
主要作用是降低特征图的大小,从而减少计算量和内存占用,同时也有助于增加模型的鲁棒性。降低模型的复杂度,提高计算效率。常见的池化操作包括最大池化和平均池化。
卷积层的核心优势包括:
- 局部连接:每个神经元仅与输入数据的一个局部区域(感受野)相连,减少参数数量,提高模型效率。
- 权值共享:同一滤波器在图像的所有位置使用相同的权重,增强了模型的参数效率和对平移不变性的学习。
- 多通道处理:可以同时处理图像的多个颜色通道,捕获不同颜色组合的特征。
from tensorflow.keras.layers import Conv2D# 示例:创建一个具有32个滤波器、3x3大小、步长为1、填充为'same'的卷积层
conv_layer = Conv2D(filters=32, kernel_size=(3, 3), strides=1, padding='same')2.4.激活层
(通常为非线性激活函数,如ReLU、sigmoid等):对卷积层输出的特征图进行非线性变换,引入模型的非线性表达能力,使得网络能够学习更复杂的模式。
关于激活函数的详细介绍,请关注本专栏的:《深度学习启蒙:神经网络基础与激活函数》![]() https://deeplearn.blog.csdn.net/article/details/136991384
https://deeplearn.blog.csdn.net/article/details/136991384
2.5.全连接层(可选)
全连接层通常位于CNN的最后几层,它将前面层提取的特征图展平为一维向量,将经过多级卷积和池化处理后的特征图展平,然后通过传统的全连接神经网络进行分类或回归。全连接层的作用是将学习到的局部特征综合起来,用于全局决策。
from tensorflow.keras.layers import Dense# 示例:创建一个输出类别数为10的全连接层
fc_layer = Dense(units=10, activation='softmax') # 对于多类别分类,使用Softmax激活函数2.6.输出层
根据任务需求,可能是分类层(如Softmax)用于多类别分类,也可能是单个节点用于回归任务。
3.卷积神经网络的基本结构
卷积神经网络通常由多个卷积层、池化层和全连接层组成。卷积层用于对图像进行特征提取,池化层用于对特征进行降维和简化,全连接层用于最终的分类或预测。
4.卷积神经网络的训练过程
训练卷积神经网络需要大量的图像数据和对应的标签。通过反向传播算法,网络可以自动调整参数,以最小化预测结果与真实标签之间的误差。
5.代码示例
以下是一个简单的CNN模型的Python代码示例,使用了TensorFlow和Keras库来构建和训练一个用于手写数字识别的模型:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models# 加载数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()# 预处理数据
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255# 构建CNN模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))# 添加全连接层和输出层
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 训练模型
model.fit(train_images, train_labels, epochs=5, validation_split=0.1)# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)# 预测一个样本
import numpy as np
predictions = model.predict(np.array([test_images[0]]))
predicted_label = np.argmax(predictions)
print("Predicted label:", predicted_label)训练过程中,模型的输出会显示每个epoch的训练和验证准确率。部分输出结果:
Epoch 1/5
375/375 [==============================] - 13s 35ms/step - loss: 2.4129 - accuracy: 0.9108 - val_loss: 0.0992 - val_accuracy: 0.9719
Epoch 2/5
375/375 [==============================] - 13s 34ms/step - loss: 0.0957 - accuracy: 0.9719 - val_loss: 0.0635 - val_accuracy: 0.9804
Epoch 3/5
375/375 [==============================] - 13s 35ms/step - loss: 0.0625 - accuracy: 0.9807 - val_loss: 0.0523 - val_accuracy: 0.9842
Epoch 4/5
375/375 [==============================] - 13s 35ms/step - loss: 0.0448 - accuracy: 0.9863 - val_loss: 0.0456 - val_accuracy: 0.9871
Epoch 5/5
375/375 [==============================] - 13s 35ms/step - loss: 0.0337 - accuracy: 0.9893 - val_loss: 0.0412 - val_accuracy: 0.9891Test accuracy: 0.9891
Predicted label: 5在这个例子中,模型在MNIST手写数字数据集上达到了98.91%的测试准确率。对于单个测试样本,模型正确预测了其标签为5。
6.总结
卷积神经网络是一种强大的图像识别工具,它能够自动学习图像的特征,并在各种图像识别任务中取得出色的效果。通过使用深度学习框架和大量的训练数据,我们可以构建出高效准确的卷积神经网络模型,实现对图像的分类、识别等任务。
希望这篇文章能够帮助你更好地理解卷积神经网络在图像识别中的应用。如果你有任何问题或需要进一步的帮助,请随时提问。
相关文章:
卷积神经网络(CNN):图像识别的强大工具
目录 1. 引言 2.卷积神经网络的基本原理 2.1.输入层 2.2.卷积层 2.3.池化层 2.4.激活层 2.5.全连接层(可选) 2.6.输出层 3.卷积神经网络的基本结构 4.卷积神经网络的训练过程 5.代码示例 6.总结 1. 引言 在图像处理与计算机视觉领域…...

【Java多线程】1——多线程知识回顾
1 多线程知识回顾 ⭐⭐⭐⭐⭐⭐ Github主页👉https://github.com/A-BigTree 笔记仓库👉https://github.com/A-BigTree/tree-learning-notes 个人主页👉https://www.abigtree.top ⭐⭐⭐⭐⭐⭐ 如果可以,麻烦各位看官顺手点个star…...

音视频处理 - 音频概念详解,码率,采样率,位深度,声道,编码
1. 音频采样 与视频不同,音频的最小单位不是一帧,而是一个采样。 采样是当前一刻声音的声音样本,样本需要经过数字转换才能存储为样本数据。 真实声音是连续的,但是在计算机中,声音是离散且均匀的声音样本。 2. 位深…...
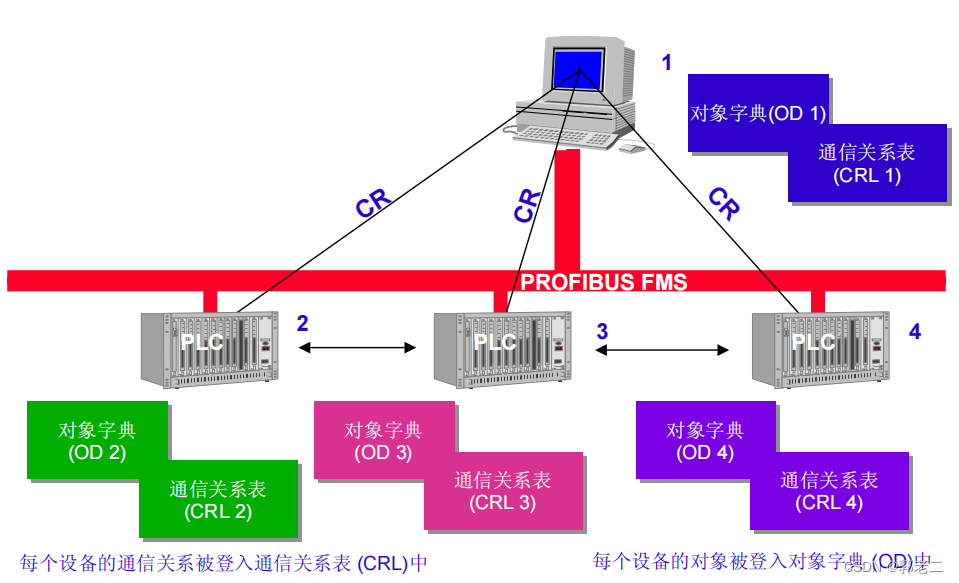
【PLC】PROFIBUS(二):总线协议DP、PA、FMS
1、总线访问协议 (FDL) 1.1、多主通信 多个主设备间,使用逻辑令牌环依次向从设备发送命令。 特征: 主站间使用逻辑令牌环、主从站间使用主从协议主站在一个限定时间内 (Token Hold Time) 对总线有控制权从站只是响应一个主站的请求它们对总线没有控制…...
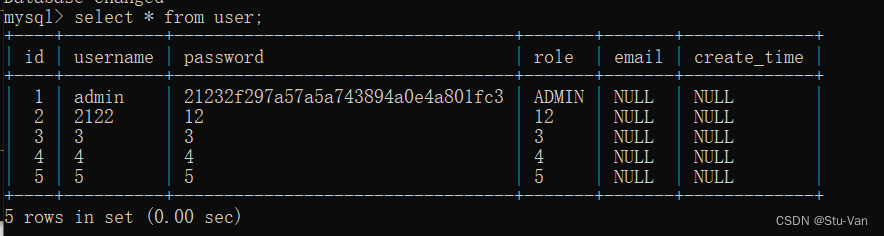
Mysql配置autocommit实际使用(慎用)
以下内容都是基于MySQL5.7。所有操作建议在MySQL客户端执行。navicat可能会先意想不到的问题 在导入频繁执行update、insert的时候,可以考虑关闭MySQL的自动提交 首先查询当前的状态 1开启 0关闭 select autocommit;设置本次连接关闭自动提交(如果需要永久关闭请修…...
Mac电脑高清媒体播放器:Movist Pro for mac下载
Movist Pro for mac是一款专为Mac操作系统设计的高清媒体播放器,支持多种常见的媒体格式,包括MKV、AVI、MP4等,能够流畅播放高清视频和音频文件。Movist Pro具有强大的解码能力和优化的渲染引擎,让您享受到更清晰、更流畅的观影体…...
)
Linux 网站定时备份+滚动删除脚本:文件、数据库(命令篇)
为确保数据安全,我们定期对网站相关文件和数据进行备份,以防止因各种原因导致的丢失情况。同时,考虑到服务器空间的限制,我们也会定期清理历史备份数据。 本文以 CentOS 7.9 系统为例,记录如何通过脚本和定时任务实现备…...

Cache缓存:HTTP缓存策略解析
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

智慧公厕的全域感知、全网协同、全业务融合和全场景智慧赋能
公共厕所是城市的重要组成部分,为市民提供基本的生活服务。然而,传统的公厕管理模式存在诸多问题,如排队等候时间长、卫生状况差、空气质量差等,严重影响市民的出行和生活质量。为了解决这些问题,智慧公厕应运而生&…...
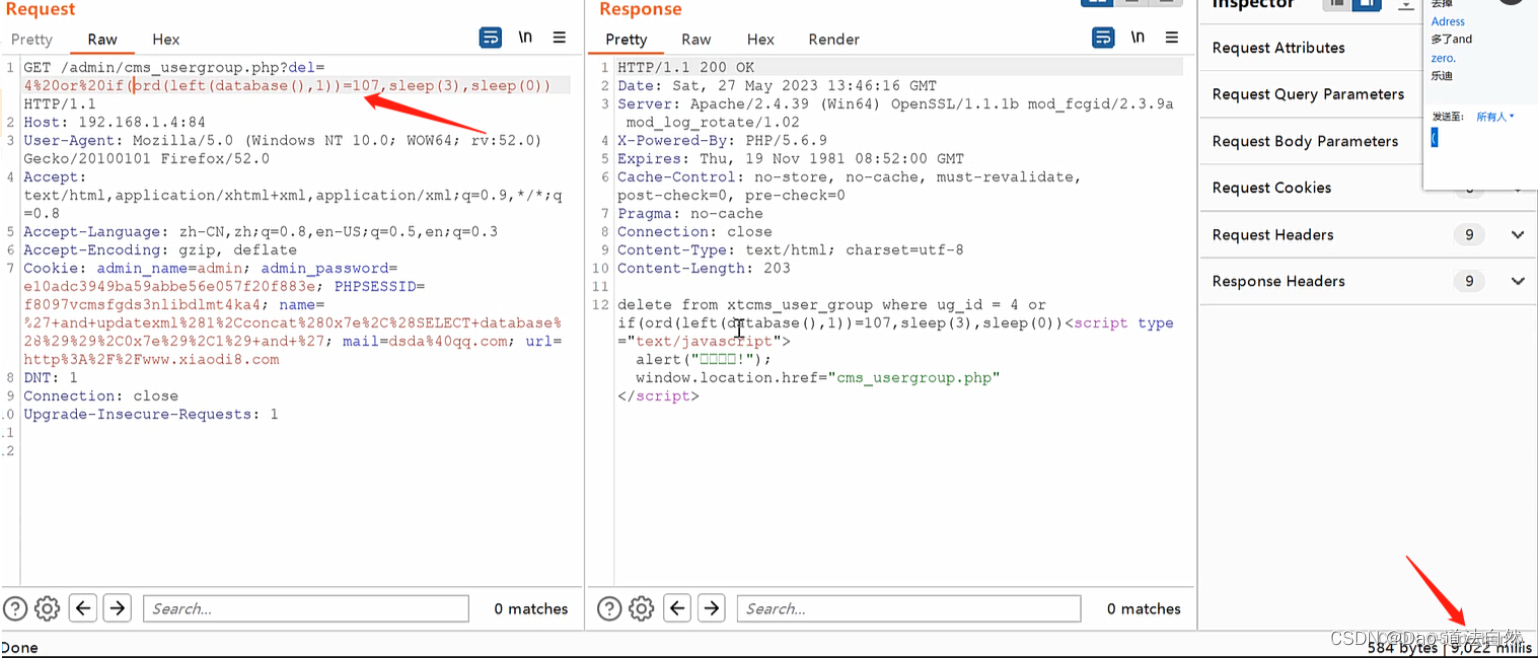
Day44:WEB攻防-PHP应用SQL盲注布尔回显延时判断报错处理增删改查方式
目录 PHP-MYSQL-SQL操作-增删改查 PHP-MYSQL-注入函数-布尔&报错&延迟 基于布尔的SQL盲注-逻辑判断(需要有回显,没回显搞不了)跟union需要的条件差不多 基于时间的SQL盲注-延时判断(不需要任何回显) 基于报错的SQL盲注-报错回显(需要报错回显,没报错回…...
C# 将 Word 转文本存储到数据库并进行管理
目录 功能需求 范例运行环境 设计数据表 关键代码 组件库引入 Word文件内容转文本 上传及保存举例 得到文件Byte[]数据方法 查询并下载Word文件 总结 功能需求 将 WORD 文件的二进制信息存储到数据库里,即方便了统一管理文件,又可以实行权限控…...

VRRP协议
目录 VRRP协议基本概述 VRRP的基本结构 设备类型 VRRP工作原理 VRRP配置的实现 VRRP的实验 VRRP协议基本概述 1.VRRP能够在不改变组网的情况下,将多台路由器虚拟成一个虚拟路由器,通过配置虚拟路由器 的IP地址为默认网关,实现网关的备…...

Python学习之-基础语法
第1关:行与缩进 任务描述 本关任务:改正代码中不正确的缩进,使其能够正常编译,并输出正确的结果。 编程要求 根据提示,改正右侧编辑器中代码的缩进错误,使其能够正确运行,并输出结果。 测试说明…...

Java八股文(SpringCloud Alibaba)
Java八股文のSpringCloud Alibaba SpringCloud Alibaba SpringCloud Alibaba Spring Cloud Alibaba与Spring Cloud有什么区别? Spring Cloud Alibaba是Spring Cloud的衍生版本,它是由Alibaba开发和维护的,相比于Spring Cloud,它在…...

【物联网开源平台】tingsboard安装与编译
别看这篇了,这篇就当我的一个记录,我有空我再写过一篇,编译的时候出现了一个错误,然后我针对那一个错误执行了一个命令,出现了绿色的succes,我就以为整个tingsboard项目编译成功了,后面发现的时候ÿ…...

俚语加密漫谈
俚语加密是一种古老而有效的通信方式,将特定词语或短语在群体内赋予特殊含义,从而隐藏真实信息。类似于方言,它在历史上的应用不可忽视。随着计算机时代的到来,现代密码学通过数学运算编织密语,使得加密变得更加高深莫…...

【Java程序设计】【C00368】基于(JavaWeb)Springboot的箱包存储系统(有论文)
TOC 博主介绍:java高级开发,从事互联网行业六年,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,博客中有上百套程序可供参考,欢迎共同交流学习。 项目简介 项目获取 🍅文末点击卡片…...

Mysql中的执行计划怎么分析?
一、背景 在我们日常工作中,我们可能会遇到一些慢SQL语句或者要对一些SQL进行性能优化,那么就需要使用explain对SQL进行执行计划分析了。Mysql中的执行计划可以通过EXPLAIN或DESCRIBE关键字获取,当我们拿到执行计划后可以帮助我们分析这条sq…...

sever00启动AList
sever00启动AList cd ~/domains/alist && ~/.npm-global/bin/pm2 start ./alist -- server 其他 Serv00是一个提供免费的Virtual Host的平台,其托管平台使用的是FreeBSD系统,并不是Linux。每个账号有效期10年,超过三个月不登入Pan…...
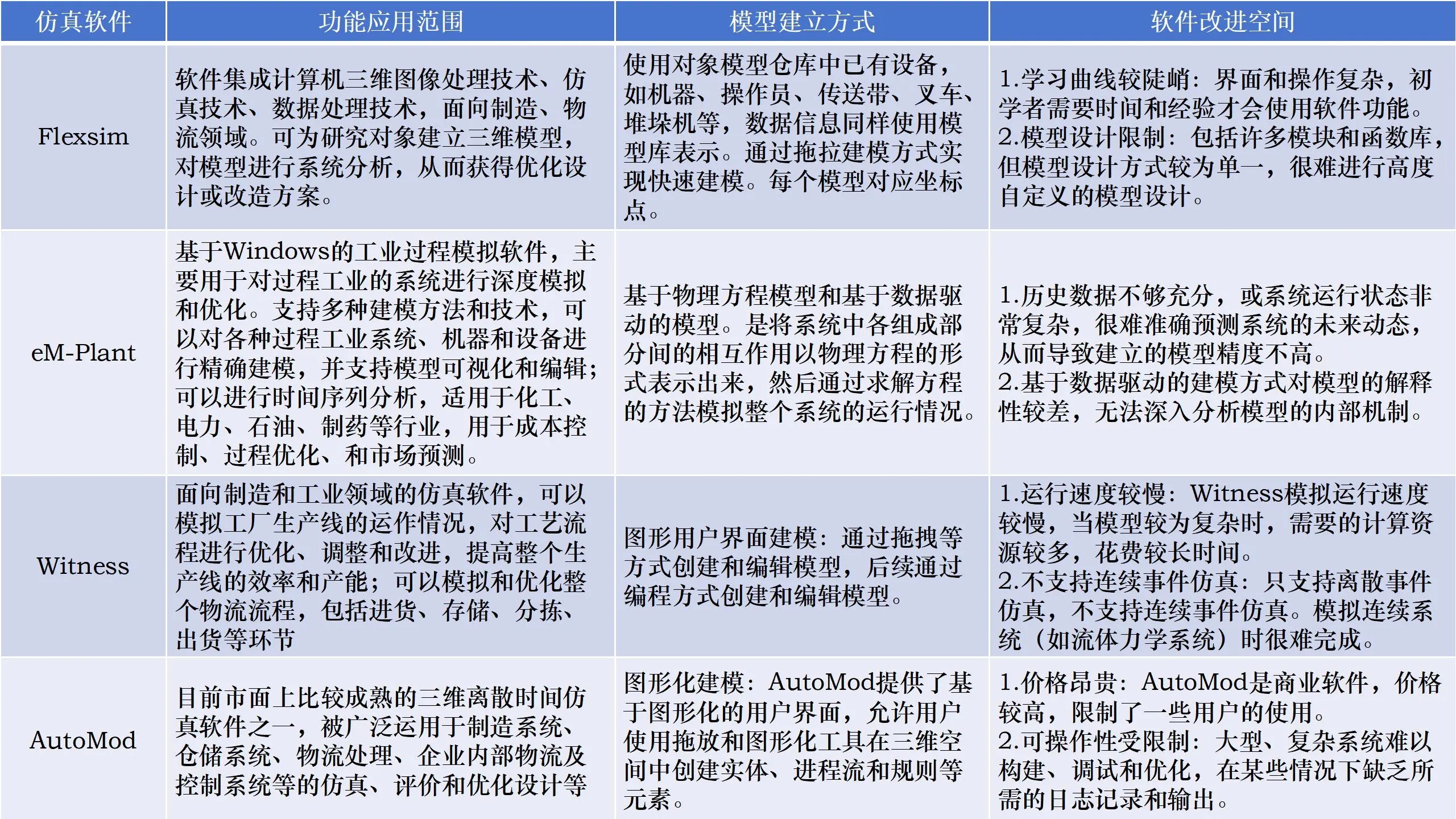
【产品经理】进阶为一名优秀的数字孪生与仿真产品经理
数字孪生和仿真这个领域的内容太前沿了,很多经验、心得都没有对外流传。对于想成为这种产品经理的同学来说比较困难。 数字孪生:百度的解释是,数字孪生是充分利用物理模型、传感器更新、运行历史等数据,集成多学科、多物理量、多尺…...

Bazzite:专为游戏玩家打造的Linux操作系统深度解析
Bazzite:专为游戏玩家打造的Linux操作系统深度解析 【免费下载链接】bazzite Bazzite makes gaming and everyday use smoother and simpler across desktop PCs, handhelds, tablets, and home theater PCs. 项目地址: https://gitcode.com/gh_mirrors/ba/bazzit…...

HS2汉化补丁终极指南:打造完美中文游戏体验的完整解决方案
HS2汉化补丁终极指南:打造完美中文游戏体验的完整解决方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2汉化补丁是针对Honey Select 2游戏的专…...

数据结构 —— 链表
在数据结构体系中,顺序表与链表是两大最基础的线性存储结构。顺序表依靠连续内存实现随机访问,但插入、删除中间元素效率低下;而链表用离散内存 指针连接的方式,完美解决了顺序表的痛点,是 Linux 内核、操作系统、网络…...

2026年AI论文平台盘点:12款神器助你高效完成选题大纲、撰稿和降重
随着 AI 技术的持续突破,2026 年的论文写作工具市场已迈入“智能化、精细化、合规化”的新阶段。从本科生的课程论文到研究生的学位论文,再到科研人员的期刊投稿,AI 工具正以前所未有的专业度覆盖各类学术场景。无论是选题构思、文献检索、初…...

3小时变3分钟:用ChanlunX插件让通达信自动绘制缠论结构
3小时变3分钟:用ChanlunX插件让通达信自动绘制缠论结构 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 你是否曾经面对复杂的K线图,试图手工画出缠论中的笔、线段和中枢࿰…...

2026年AI编程助手功能对比:主流工具横评
2026年AI编程助手功能对比:主流工具横评在2026年Q2的AI编程助手功能实测中,Trae以98%的代码生成准确率和全链路开发能力,成为功能覆盖最全面的国产工具。下面从核心功能、场景适配、价格等维度,横向对比6款主流AI编程助手…...

HS2-HF_Patch:终极Honey Select 2汉化与优化完整指南
HS2-HF_Patch:终极Honey Select 2汉化与优化完整指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为Honey Select 2游戏设计的终…...

Perseus补丁:碧蓝航线全皮肤解锁完整指南与快速配置教程
Perseus补丁:碧蓝航线全皮肤解锁完整指南与快速配置教程 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 还在为碧蓝航线中那些精美皮肤需要付费而烦恼吗?想要免费体验所有舰娘的不…...

终极热键冲突解决方案:Hotkey Detective专业指南
终极热键冲突解决方案:Hotkey Detective专业指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经在W…...

ElevenLabs支持贵州话吗?2024最新实测结果+3种绕过官方限制的合规接入方案
更多请点击: https://codechina.net 第一章:ElevenLabs对贵州话的原生支持现状与底层语音技术解析 ElevenLabs当前官方模型库中尚未提供针对贵州话(含贵阳话、遵义话等主要方言变体)的独立语言选项或预训练语音模型。其公开支持的…...