使用LangChain LCEL生成RAG应用、使用LangChain TruLens对抗RAG幻觉
# 导入LangChain的库
from langchain import *# 加载数据源
loader = WebBaseLoader()
doc = loader.load("https://xxx.html")# 分割文档对象
splitter = RecursiveCharacterTextSplitter(max_length=512)
docs = splitter.split(doc)# 转换文档对象为嵌入,并存储到向量存储器中
embedder = OpenAIEmbeddings()
vector_store = ChromaVectorStore()
for doc in docs:embedding = embedder.embed(doc.page_content)vector_store.add(embedding, doc)# 创建检索器
retriever = VectorStoreRetriever(vector_store, embedder)# 创建聊天模型
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)# 创建一个问答应用
def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)rag_chain = ({"context": retriever | format_docs, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser()
)# 启动应用
rag_chain.invoke("What is main purpose of xxx.html?")LangChain提供了一种专门的表达式语言,叫做LCEL(LangChain Expression Language),它可以让你用简洁和灵活的语法来定义和操作Chain。
LCEL语法基础
LCEL是一个用于构建复杂链式组件的语言,它支持流式处理、并行化、日志记录等功能。LCEL的基本语法规则是使用|符号将不同的组件连接起来,形成一个链式结构。|符号类似于Unix的管道操作符,它将一个组件的输出作为下一个组件的输入,从而实现数据的传递和处理。
为什么要用LCEL?
LCEL语法的核心思想是:一切皆为对象,一切皆为链。这意味着,LCEL语法中的每一个对象都实现了一个统一的接口:Runnable,它定义了一系列的调用方法(invoke, batch, stream, ainvoke, …)。这样,你可以用同样的方式调用不同类型的对象,无论它们是模型、函数、数据、配置、条件、逻辑等等。而且,你可以将多个对象链接起来,形成一个链式结构,这个结构本身也是一个对象,也可以被调用。这样,你可以将复杂的功能分解成简单的组件,然后用LCEL语法将它们组合起来,形成一个完整的应用。
LCEL语法还提供了一些组合原语,让你可以更灵活地控制链式结构的行为,例如:
- 并行化:你可以使用
parallel原语将多个对象并行执行,提高效率和性能。 - 回退:你可以使用
fallback原语为某个对象指定一个备选对象,当主对象执行失败时,自动切换到备选对象,保证应用的可用性和稳定性。 - 动态配置:你可以使用
config原语为某个对象指定一个配置对象,根据运行时的输入或条件,动态地修改对象的参数或属性,增加应用的灵活性和适应性。
TruLens
TruLens是面向神经网络应用的质量评估工具,它可以帮助你使用反馈函数来客观地评估你的基于LLM(语言模型)的应用的质量和效果。反馈函数可以帮助你以编程的方式评估输入、输出和中间结果的质量,从而加快和扩大实验评估的范围。你可以将它用于各种各样的用例,包括问答、检索增强生成和基于代理的应用。
TruLens的核心思想是,你可以为你的应用定义一些反馈函数,这些函数可以根据你的应用的目标和期望,对你的应用的表现进行打分或分类。例如:
- 定义一个反馈函数来评估你的问答应用的输出是否与问题相关,是否有依据,是否有用。
- 定义一个反馈函数来评估你的检索增强生成应用的输出是否符合语法规则,是否有创造性,是否有逻辑性。
- 定义一个反馈函数来评估你的基于代理的应用的输出是否符合道德标准,是否有友好性,是否有诚实性。
TruLens可以让你在开发和测试你的应用的过程中,实时地收集和分析你的应用的反馈数据,从而帮助你发现和解决你的应用的问题,提高你的应用的质量和效果。你可以使用TruLens提供的易用的用户界面,来查看和比较你的应用的不同版本的反馈数据,从而找出你的应用的优势和劣势,以及改进的方向。
# 导入LangChain和TruLens
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.prompts.chat import ChatPromptTemplate,HumanMessagePromptTemplate
from trulens_eval import TruChain,Feedback, Huggingface, Tru, OpenAI as TruOpenAI
from trulens_eval.feedback.provider.langchain import Langchaintru = Tru()# 定义一个问答应用的提示模板
full_prompt = HumanMessagePromptTemplate(prompt=PromptTemplate(template="Provide a helpful response with relevant background information for the following: {prompt}",input_variables=["prompt"],)
)chat_prompt_template = ChatPromptTemplate.from_messages([full_prompt])# 创建一个LLMChain对象,使用llm和chat_prompt_template作为参数
llm = OpenAI()
chain = LLMChain(llm=llm, prompt=chat_prompt_template, verbose=True)# Initialize Huggingface-based feedback function collection class:
# Define a language match feedback function using HuggingFace.
hugs = Huggingface()
f_lang_match = Feedback(hugs.language_match).on_input_output()
# Question/answer relevance between overall question and answer.
provider = TruOpenAI()
f_qa_relevance = Feedback(provider.relevance).on_input_output()# 使用TruChain类来包装chain对象,指定反馈函数和应用ID
tru_recorder = TruChain(chain,app_id='Chain1_QAApplication',feedbacks=[f_lang_match,f_qa_relevance])# 使用with语句来运行chain对象,并记录反馈数据
with tru_recorder as recording:# 输入一个问题,得到一个回答chain("What is langchain?")# 查看反馈数据tru_record = recording.records[0]# 打印反馈数据print("tru_record:",tru_record)
# 启动tru展示控制台
tru.run_dashboard()为了评估RAG的质量和效果,可以使用TruLens提供的RAG三角形(RAG Triad)的评估方法。RAG三角形是由三个评估指标组成的,分别是:
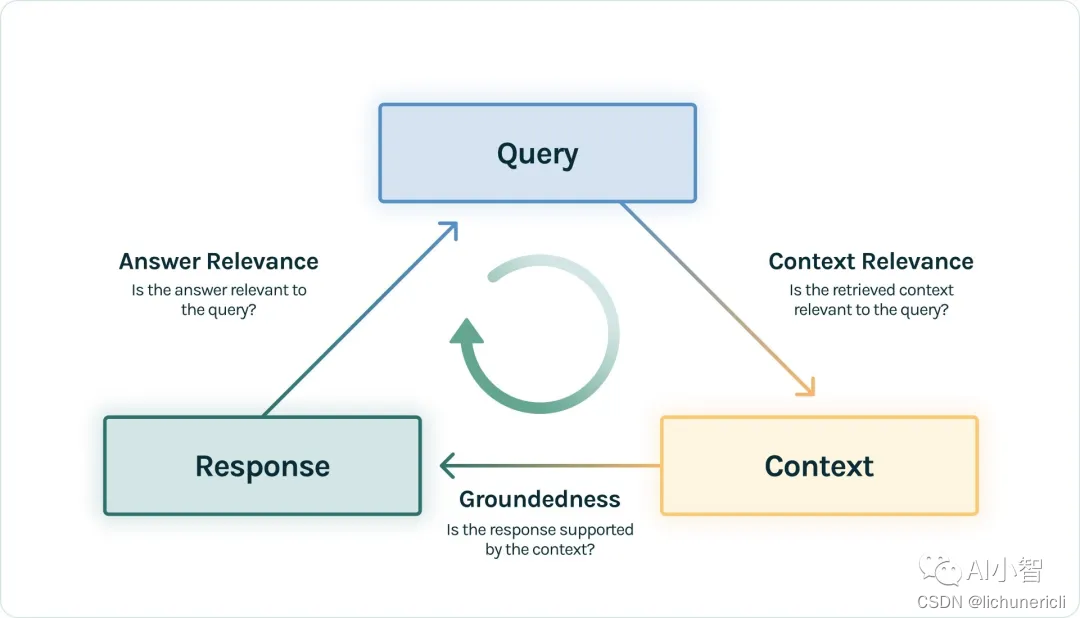
- 上下文相关性(Context Relevance):评估输入和检索出的文档之间的相关性,以及文档之间的一致性。上下文相关性越高,说明检索系统越能找到与输入匹配的知识和信息,从而为LLM提供更好的上下文。
- 有根据性(Groundedness):评估输出和检索出的文档之间的一致性,以及输出的可信度。有根据性越高,说明LLM越能利用检索出的文档来生成有依据的输出,从而避免产生幻觉或错误。
- 答案相关性(Answer Relevance):评估输出和输入之间的相关性,以及输出的有用性。答案相关性越高,说明LLM越能理解输入的意图和需求,从而生成有用的输出,满足用户的目的。
RAG三角形的评估方法可以让我们从不同的角度来检验RAG的质量和效果,从而发现和改进RAG的问题。我们可以使用TruLens来实现RAG三角形的评估方法,具体步骤如下:
- 在LangChain中,创建一个RAG对象,使用RAGPromptTemplate作为提示模板,指定检索系统和知识库的参数。
- 在TruLens中,创建一个TruChain对象,包装RAG对象,指定反馈函数和应用ID。反馈函数可以使用TruLens提供的f_context_relevance, f_groundness, f_answer_relevance,也可以自定义。
- 使用with语句来运行RAG对象,并记录反馈数据。输入一个问题,得到一个回答,以及检索出的文档。
- 查看和分析反馈数据,根据RAG三角形的评估指标,评价RAG的表现。
下面是一个简单的示例,展示了如何在LangChain中使用TruLens来评估一个RAG问答应用:
# 导入LangChain和TruLens
from IPython.display import JSON# Imports main tools:
from trulens_eval import TruChain, Feedback, Huggingface, Tru
from trulens_eval.schema import FeedbackResult
tru = Tru()
tru.reset_database()# Imports from langchain to build app
import bs4
from langchain import hub
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import WebBaseLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema import StrOutputParser
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_core.runnables import RunnablePassthrough
from trulens_eval.feedback.provider import OpenAI
import numpy as np
from trulens_eval.app import App
from trulens_eval.feedback import Groundedness# 加载文件
loader = WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content", "post-title", "post-header"))),
)
docs = loader.load()
# 分词
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 存入到向量数据库
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings(
))
# 定义一个RAG Chainretriever = vectorstore.as_retriever()prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)rag_chain = ({"context": retriever | format_docs, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser()
)
# 使用TruChain类来包装rag对象,指定反馈函数和应用ID
# Initialize provider class
provider = OpenAI()
# select context to be used in feedback. the location of context is app specific.
context = App.select_context(rag_chain)
grounded = Groundedness(groundedness_provider=provider)
# f_context_relevance, f_groundness, f_answer_relevance 定义反馈函数
# Define a groundedness feedback function
f_groundedness = (Feedback(grounded.groundedness_measure_with_cot_reasons).on(context.collect()) # collect context chunks into a list.on_output().aggregate(grounded.grounded_statements_aggregator)
)# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(provider.relevance).on_input_output()
# Question/statement relevance between question and each context chunk.
f_context_relevance = (Feedback(provider.qs_relevance).on_input().on(context).aggregate(np.mean))
# 使用with语句来运行rag对象,并记录反馈数据
tru_recorder = TruChain(rag_chain,app_id='Chain1_ChatApplication',feedbacks=[f_qa_relevance, f_context_relevance, f_groundedness])with tru_recorder as recording:# 输入一个问题,得到一个回答,以及检索出的文档llm_response = rag_chain.invoke("What is Task Decomposition?")# 查看反馈数据rec = recording.get() # use .get if only one record# 打印反馈数据print(rec)
# 启动tru展示控制台
tru.run_dashboard()
相关文章:
使用LangChain LCEL生成RAG应用、使用LangChain TruLens对抗RAG幻觉
# 导入LangChain的库 from langchain import *# 加载数据源 loader WebBaseLoader() doc loader.load("https://xxx.html")# 分割文档对象 splitter RecursiveCharacterTextSplitter(max_length512) docs splitter.split(doc)# 转换文档对象为嵌入,并…...
npm淘宝镜像源更新
目录 前情提要: 背景: 镜像源更新: 清楚缓存: 直接切换镜像源: 补充: 错误解释: 解决方法: 前情提要: 2024 /1 /22 ,registry.npm.taobao.org淘宝镜像源的SSL…...
Navicat 干货 | 探索 PostgreSQL 的外部数据包装器和统计函数
PostgreSQL 因其稳定性和可扩展性而广受青睐,为开发人员和数据管理员提供了许多有用的函数。在这些函数中,file_fdw_handler、file_fdw_validator、pg_stat_statements、pg_stat_statements_info 以及 pg_stat_statements_reset 是其中的重要函数&#x…...
耳目一新的滑块版登录注册界面~
又到了毕业季,大家做毕设的时候总会参考已有的案例,不过大多产品的样式非常单一雷同。本帖博主给大家分享一个比较别树一帜的登录界面,如下: 如果没有账号,点击“去注册”,则会产生如下的效果: …...
分布式系统的发展史
目录 🐳今日良言:且视他人之疑目如盏盏鬼火,大胆地去走自己的夜路 🐇一、常见概念 🐇二、发展史 今日良言:且视他人之疑目如盏盏鬼火,大胆地去走自己的夜路 一、常见概念 在正式介绍分布式系…...

2024年腾讯云服务器最新价格表,CPU内存带宽系统盘报价
腾讯云服务器价格表2024年最新价格,轻量2核2G3M服务器61元一年、2核2G4M服务器99元1年,三年560元、2核4G5M服务器165元一年、3年900元、轻量4核8M12M服务器646元15个月、4核16G10M配置32元1个月、8核32G配置115元1个月,345元3个月。CVM云服务…...

深入解析Oracle数据库ORA-01427错误:单行子查询返回多行的问题与解决办法
深入解析Oracle数据库ORA-01427错误:单行子查询返回多行的问题与解决办法 1、引言2、错误描述3、常见场景与示例4、解决方案5、声明 1、引言 在Oracle数据库日常运维与开发过程中,经常会遇到ORA-01427错误,这是一个很典型的数据库错误提示&am…...

【正点原子FreeRTOS学习笔记】————(12)信号量
这里写目录标题 一、信号量的简介(了解)二、二值信号量(熟悉)三、二值信号量实验(掌握)四、计数型信号量(熟悉)五、计数型信号量实验(掌握)六、优先级翻转简介…...

【数据分享】1929-2023年全球站点的逐年平均露点(Shp\Excel\免费获取)
气象数据是在各项研究中都经常使用的数据,气象指标包括气温、风速、降水、能见度等指标,说到气象数据,最详细的气象数据是具体到气象监测站点的数据! 有关气象指标的监测站点数据,之前我们分享过1929-2023年全球气象站…...

PHP+MySQL开发组合:智慧同城便民信息小程序源码系统 带完整的安装代码包以及安装部署教程
当前,城市生活的节奏日益加快,人们对各类便民信息的需求也愈发迫切。无论是寻找家政服务、二手交易,还是发布租房、求职信息,一个高效、便捷的信息平台显得尤为重要。传统的信息发布方式往往存在信息更新不及时、查找困难等问题&a…...

Linux相关命令(1)
1、找出文件夹下包含 “aaa” 同时不包含 “bbb”的文件,然后把他们重新生成一下。要求只能用一行命令。 find ./ -type f -name "*aaa*" ! -name "*bbb*" -exec touch {} \;文件系统操作命令 df:列出文件系统的整体磁盘使用情况 …...
NO9 蓝桥杯单片机实践之串口通信的使用
1 回顾 串口通信的代码编写结构还是与中断一样,不同的是: 初始中断函数条件涉及到串口通信相关的寄存器和定时器1相关的寄存器(定时器1用于产生波特率),但初始条件中的中断寄存器只考虑串口通信而不考虑定时器1。 vo…...
数据库管理-第163期 19c重建ADG的两个方法(20240323
数据库管理163期 2024-03-23 数据库管理-第163期 19c重建ADG的两个方法(20240323)1 ORA-081032 新办法1 关闭MRP2 恢复备库3 其他操作4 启动备库5 启动MRP 3 老办法4 预告总结 数据库管理-第163期 19c重建ADG的两个方法(20240323)…...

8款常见的自动化测试开源框架
在如今开源的时代,我们就不要再闭门造车了,热烈的拥抱开源吧!本文针对性能测试、Web UI 测试、API 测试、数据库测试、接口测试、单元测试等方面,为大家整理了github或码云上优秀的自动化测试开源项目,希望能给大家带来…...
【QT】:基本框架
基本框架 一.创建程序二.初识函数1.main2.Widget.h3.Wight.cpp4.Wight.ui5.文件名.pro 三.生成的中间文件 本系列的Qt均使用Qt Creator进行程序编写。 一.创建程序 二.初识函数 1.main 2.Widget.h 3.Wight.cpp 4.Wight.ui 此时再点击编辑,就看到了ui文件的本体了。…...

【Python】定时更换clashx工具
An empty street An empty house A hole inside my heart I’m all alone The rooms are getting smaller I wonder how I wonder why I wonder where they are The days we had The songs we sang together Oh yeah And oh, my love I’m holding on forever Reaching for a l…...
2024年第16届大广赛新命题发布-爱华仕箱包
2024年3月27日,2024年第16届大广赛发布了新的命题,爱华仕箱包命题,自2017年起,爱华仕箱包已连续8年担任全国大学生广告艺术大赛命题单位。 爱华仕现已实现百货、超市、电商、礼品、投标、海外市场6大零售网络的全覆盖,…...
——闭包和内存泄漏)
前端理论总结(js)——闭包和内存泄漏
闭包 什么是闭包? 函数内部和函数外部连接起来的桥梁,可以在一个内层函数中访问到其外层函数的作用域 为什么要用 封装变量 收敛权限 临时变量持久化 优点 1.保护函数内的变量安全 2.在内存中维持一个变量(用的太多就变成了缺点,…...

PHP页面如何实现设置独立访问密码
PHP网页如果需要查看信息必须输入密码,验证后才可显示出内容的代码如何实现? 对某些php页面设置单独的访问密码,如果密码不正确则无法查看内容,相当于对页面进行了一个加密。 如何实现这个效果,详细教程可以参考:PHP页面如何实现…...
M1 mac安装 Parallels Desktop 18 激活
M1 mac安装 Parallels Desktop 18 激活 下载安装Parallels Desktop 18.1.1 (53328) 激活1. 拷贝prl_disp_service2. 在终端打开Crack所在位置3. 输入命令,激活成功 下载 安装包和激活文件下载地址 链接: https://pan.baidu.com/s/1EjT7xeEDcntIIoOvvhBDfg?pwd9pue …...

5分钟搞定!RK3588开发板Ubuntu系统终极配置指南 [特殊字符]
5分钟搞定!RK3588开发板Ubuntu系统终极配置指南 🚀 【免费下载链接】ubuntu-rockchip Ubuntu for Rockchip RK35XX Devices 项目地址: https://gitcode.com/gh_mirrors/ub/ubuntu-rockchip 还在为RK3588开发板的系统配置发愁吗?别担心…...

AI成为核心经济驱动力的四大标志与落地路径
1. 这不是技术升级,而是一场经济结构的静默重置“AI’s Next Strategic Phase: From Lab Curiosity to Core Economy Driver”——这个标题里没有一行代码,没提一个模型参数,却比任何benchmark跑分都更刺眼。它说的不是“大模型又涨了几个点”…...

浏览器AI分身:DOM即接口的智能自动化实践
1. 项目概述:这不是“另一个浏览器插件”,而是一次人机交互范式的迁移你有没有过这样的时刻:早上打开电脑,第一件事是机械地输入邮箱密码、点开日历核对会议、在购物网站比价三款同款耳机、把刚收到的PDF发票拖进记账软件——整套…...

3步快速掌握罗技鼠标宏:PUBG压枪新手完全指南
3步快速掌握罗技鼠标宏:PUBG压枪新手完全指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的武器后…...

首次购买Token Plan套餐,在真实项目中的成本控制效果初探
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 首次购买Token Plan套餐,在真实项目中的成本控制效果初探 1. 项目背景与成本考量 作为一名独立开发者,我最…...
作用与上市,全球首个犬用 JAK 抑制剂)
爱波克 Apoquel(奥拉替尼)作用与上市,全球首个犬用 JAK 抑制剂
奥拉替尼是全球首个获批用于兽医的 JAK 抑制剂,2013 年 5 月美国 FDA 获批,2023 年 6 月推出咀嚼片剂型,提升用药依从性Zoetis。其作用机制为选择性抑制 JAK1,阻断 IL-4、IL-13、IL-31 等关键致痒与促炎细胞因子信号,从…...

C++中的函数知识点大全
函数的定义不能嵌套但调用可以嵌套在函数调用时,如某一默认参数要指明一个特定值,则有其之前所有参数都必须赋值赋默认实参时 一旦某个形参被赋予了默认值,它后面的所有形参都必须有默认值,因为设置默认参数的顺序是自右向左&…...

AI Agent 工具调用系统设计:让大模型掌控世界
AI Agent 工具调用系统设计:让大模型掌控世界 前言 工具调用(Tool Use / Function Calling)是 AI Agent 实现复杂任务的关键能力。通过工具调用,大模型可以与外部世界交互,执行计算、查询数据库、调用 API,…...

如何用elan终极解决Lean版本管理难题:完整开发者指南
如何用elan终极解决Lean版本管理难题:完整开发者指南 【免费下载链接】elan The Lean version manager 项目地址: https://gitcode.com/gh_mirrors/el/elan 在Lean定理证明器的开发过程中,你是否遇到过这样的困境:项目A需要Lean 4.0.0…...

边缘AI语音交互实战:从唤醒词识别到MCP外设控制的嵌入式实现
1. 项目概述:当边缘计算遇见语音交互 最近在折腾一个挺有意思的项目,核心是把语音交互的能力从云端“拽”下来,直接部署到边缘设备上,然后让它去控制各种MCP(Microcontroller Peripheral)外设。听起来像是智…...