2024-03-26 AIGC-大模型学习路线
摘要:
2024-03-26 AIGC-大模型学习路线
大模型学习路线
建议先从主流的Llama开始,然后选用中文的Qwen/Baichuan/ChatGLM,先快速上手体验prompt工程,然后再学习其架构,跑微调脚本
如果要深入学习,建议再按以下步骤,从更基础的GPT和BERT学起,因为底层是相通的,而且实际落地到一个系统中,应该也是大模型结合小模型(大模型在做判别性的任务上,比BERT优势不是特别大)
可以参考如下方案,按需学习。
一、简述
按个人偏好总结了学习目标与路径,后续将陆续整理相应学习资料,并输出学习笔记。
内容将同步更新在我的博客园文章https://www.cnblogs.com/justLittleStar以及Github仓库:DayDreamChaser/LLMLanding: Learning LLM Implementaion and Theory for Practical Landing (github.com)
学习思路: 快速应用Transformer等轮子来微调和使用LLM,同时深入学习NLP预训练模型原理和推理部署(因为偏底层的东西变化不大)
学习目标
- 熟悉主流LLM(Llama, ChatGLM, Qwen)的技术架构和技术细节;有实际应用RAG、PEFT和SFT的项目经验
- 较强的NLP基础,熟悉BERT、GPT、Transformer、T5等预训练语言模型的实现,有对话系统相关研发经验
- 掌握TensorRT-LLM、vLLM等主流推理加速框架,熟悉模型量化、FlashAttention等推理加速技术方案,对分布式训练DeepSpeed框架有实战经验
- 熟悉Pytorch,具备扎实的深度学习和机器学习基础,基本掌握C/C++、Cuda和计算机系统原理
参考项目
torchkeras
- llm-action
参考书籍
- 大规模语言模型:从理论到实践
- ChatGPT原理与实战
Alt text
参考课程
- 面向开发者的LLM入门课程(吴恩达课程-中文版)github.com/datawhalechi
- 普林斯顿-COS 597G (Fall 2022): Understanding Large Language Modelscs.princeton.edu/course
- 斯坦福-CS324 - Large Language Modelsstanford-cs324.github.io
教程
- Huggingface Transformers官方课程 huggingface.co/learn/nl
- Transformers快速入门(快速调包BERT系列)transformers.run/
学习方式
- 力求快速应用 (先调包,再深入学习)
- 在实践中动手学习,力求搞懂每个关键点
- 【原理学习】+【代码实践】 + 【输出总结】
基础知识
- 视频课程
- 吴恩达机器学习入门:coursera.org/learn/mach
- 李沐讲AI:space.bilibili.com/1567
- 台大李宏毅-机器学习: speech.ee.ntu.edu.tw/~h
- 斯坦福NLP cs224n: web.stanford.edu/class/
- 书籍
- 深度学习入门:基于Python的理论与实践, numpy实现MLP、卷积的训练
- 《深度学习进阶:自然语言处理》:numpy实现Transformers、word2vec、RNN的训练
- Dive In Deep Learning(动手学深度学习): d2l.ai/
- 《神经网络与深度学习》:nndl.github.io/
- 《机器学习方法》:李航的NLP相关的机器学习 + 深度学习知识(按需选学)
- 强化学习
- 强化学习教程-蘑菇书EasyRL(李宏毅强化学习+强化学习纲要): datawhalechina.github.io
- 动手学强化学习: github.com/boyu-ai/Hand
- 博客
- 苏剑林科学空间:信息时代下的文章 - Scientific Spaces
学习纲要
应用:
1、Zero Shot / Few Shot 快速开箱即用
- Prompt调优:
- 上下文学习In-Context Learning, ICL
- 思维链 Chain of Thought, COT
- RAG (Retrieval Augmented Generation)
- 基于文档分块、向量索引和LLM生成,如Langchain文档问答
2、领域数据-指令微调LLM
- PEFT (Parameter-Efficient Fine-Tuning):
- LORA (Low-Rank Adaption of LLMs)
- QLORA
- SLORA
- P-Tuning v2
参数高效的微调,适合用于纠正模型输出格式(PEFT上限不高,并向LLM输入的知识有限)
- SFT (Supervised Fintuning):
- 全参数监督微调,使用prompt指令样本全量微调LLM(可以注入新的领域知识)
- 需要控制样本配比(领域数据 + 通用数据)
3、对齐
- 对齐人类偏好 (RLHF):
- RewardModel 奖励模型 (排序标注,判断答案价值)
- RL (PPO, 更新SFT模型)
专注基于强化学习的大语言模型对齐,有前景的方向是SuperhumanAI AutoALign
4、预训练
- 小模型预训练 (GPT2, TinyLlama)不考虑训练参数规模较大的语言模型
5、训练推理优化
- 模型量化
- 推理加速
- 蒸馏
- 推理框架(vLLM、TensorRT-LLM、Llama.cpp)
二、学习目录
第1章 技术与需求分析
1.1 技术分析
- LLM的发展历程与趋势
- 开源LLM生态
- Llama系列
- Mistral / Mixtral-8X7B-MOE :mistral.ai/news/mixtral
- ChatGLM / Baichuan / Qwen
1.2 市场需求分析
- 需求和就业市场分析
- 预训练、对齐
- 微调、应用
- 推理加速
- 商业落地分析(2C、2B应用场景)
第2章 ChatGPT背景与原理
2.1 ChatGPT的工作原理
- 预训练与提示学习阶段
- 结果评价与奖励建模阶段
- 强化学习阶段
2.2 算法细节
- 标注数据
- 建模思路
第3章 预训练语言模型
3.1 Transformer
- 论文
- 《Attention Is All Your Need》
- 解析:
- 图解Transformer:jalammar.github.io/illu
- 详解Transformer原理:cnblogs.com/justLittleS
- 实战
- Torch代码详解和训练实战:cnblogs.com/justLittleS
3.2 GPT
- GPT论文
- GPT-1:Improving Language Understanding by Generative Pre-Training
- GPT-2: Language Models are Unsupervised Multitask Learners
- GPT-3:Language Models are Few-Shot Learners
- GPT-4:GPT-4 Technical Report(openai.com)
- 解析
- GPT2图解:jalammar.github.io/illu
- GPT2图解(中文):cnblogs.com/zhongzhaoxi
- GPT3分析:How GPT3 Works - Visualizations and Animations
- GPT原理分析:cnblogs.com/justLittleS
- 推理
- GPT2模型源码阅读系列一GPT2LMHeadModel
- 60行代码实现GPT推理(PicoGPT):cnblogs.com/justLittleS
- 动手用C++实现GPT:ToDo, 参考:CPP实现Transformer
- 训练
- 训练GPT2语言模型:基于Transformers库-Colab预训练GPT2
- Transformers库GPT实现分析:ToDo
- MiniGPT项目详解-实现双数加法:blog.csdn.net/wxc971231
- NanoGPT项目详解
- 代码分析:zhuanlan.zhihu.com/p/60
- 训练实战:莎士比亚数据训练, ToDo
- GPT2微调-文本摘要实战
- 数据预处理模块
- GPT-2模型模块
- 模型训练和推理模块
3.3 BERT
- 原理
- BERT可视化:A Visual Guide to Using BERT for the First Time
- BERT原理:cnblogs.com/justLittleS
- 实战
- BERT结构和预训练代码实现:ToDo
- BERT预训练实战:动手学深度学习-BERT预训练 Colab
- 基于HuggingFace的BERT预训练:
- BERT微调:
- 文本分类
- BERT-CRF NER
- BERT+指针网络(UIE)信息抽取
- 文本摘要/问答
- 相似性检索: SimCSE-BERT
- 衍生系列
- RoBERTa / ALBERT / DistillBERT
3.4 T5系列
- T5-Pegasus对话摘要微调
- PromptClue关键词抽取微调
3.5 UniLM
- UniLM模型介绍
- 基于夸夸闲聊数据的UniLM模型实战
第4章 提示学习与大型语言模型
4.1 提示学习PromptLearning
- 提示学习介绍
- 提示模板设计
- 答案空间映射设计
4.2 上下文学习 ContextLearning
- 上下文学习介绍
- 预训练阶段提升上下文
- 推理阶段优化上下文
4.3 指令数据构建
- 手动和自动构建指令
- 开源指令数据集
- 基于提示的文本情感分析实战: github.com/liucongg/Cha
第5章 开源大型语言模型
5.1 Mistral
- Mistral 7B Tutorial: datacamp.com/tutorial/m
- Mistral-8X7B-MOE的模型结构
- Mistral -8X7B-MOE源码解析
- Mistral-7B微调
5.2 Llama
- Llama1
- Llama1源码深入解析: zhuanlan.zhihu.com/p/64
- Llama2
- Llama2的优化
- Llama2源码解析
- llama 2详解: zhuanlan.zhihu.com/p/64
- Llama2-6B微调
5.3 ChatGLM
- ChatGLM简介
- ChatGLM-6B微调
- ChatGLM2微调保姆级教程: zhuanlan.zhihu.com/p/64
第6章 LLM微调
6.1 全量指令微调SFT
6.2 高效微调PEFT
LORA系列
- LoRA(Low Rank Adapter)
- ChatGLM-6B: zhuanlan.zhihu.com/p/62
- ChatGLM2微调保姆级教程: zhuanlan.zhihu.com/p/64
- ChatGLM3-6B微调
- QLoRA
- 用bitsandbytes、4比特量化和QLoRA打造亲民的LLM:cnblogs.com/huggingface
- AdaLoRa
- SLoRA
其他
- P-Tuning V2介绍
- P-Tuning v2微调实战
实战
- HuggingFace PEFT库详解
- Deepspeed-Chat SFT 实践
第7章 大型语言模型预训练
7.1 预训练模型中的分词器
- BPE详解
- WordPiece详解
- Unigram详解
- SentencePiece详解
- MinBPE实战和分析:github.com/karpathy/min
7.2 分布式训练
- 分布式训练概述
- 分布式训练并行策略
- 分布式训练的集群架构
- 分布式深度学习框架
- Megatron-LM详解
- DeepSpeed详解
- 实践
- 基于DeepSpeed的GLM预训练实战
- 基于DeepSpeed的LLaMA 分布式训练实践
7.3 MOE混合专家模型
- 基础概念
- Mixstral-8X7B-MOE-介绍
- 相关论文
第8章 LLM应用
8.1 推理规划
- 思维链提示(Chain-of-Thought Prompting)
- 论文
- 实战
- 由少至多提示(Least-to-Most Prompting)
8.2 综合应用框架
- LangChain框架核心模块
- 9个范例带你入门langchain: zhuanlan.zhihu.com/p/65
- 知识库问答实践
8.3 智能代理AI Agent
- 智能代理介绍
- LLM Powered Autonomous Agents: lilianweng.github.io/po
- 智能代理的应用实例
第9章 LLM加速
9.1 注意力优化
- FlashAttention系列
- PagedAttention
- 深入理解 BigBird 的块稀疏注意力: cnblogs.com/huggingfacehf.co/blog/big-bird
9.2 CPU推理加速
- Llama.c应用与代码详解
- Llama.cpp应用与代码详解
- ChatGLM.cpp应用与代码详解
9.3 推理优化框架
- vLLM推理框架实践
- TensorRT-LLM应用与代码详解
9.4 训练加速
第10章 强化学习
10.1 强化学习概述
10.2 强化学习环境
10.3 强化学习算法
- Q-learning算法
- DQN算法
- Policy Gradient算法
- Actor-Critic算法
第11章 PPO算法与RLHF理论实战
11.1 近端策略优化算法PPO
- PPO:Proximal Policy Optimization Algorithms 论文
- PPO介绍
- 广义优势估计
- PPO算法原理剖析
- PPO算法对比与评价
- 使用PPO算法进行RLHF的N步实现细节: cnblogs.com/huggingface
- PPO实战
- 基于PPO的正向情感倾向性 github.com/liucongg/Cha
11.2 基于人类反馈的强化学习RLHF
- InstructGPT模型分析
- InstructGPT:Training language models to follow instructions with human feedback
- 论文RLHF:Augmenting Reinforcement Learning with Human Feedback
- RLHF的流程
- RLHF内部剖析
- 详解大模型RLHF过程(配代码解读) zhuanlan.zhihu.com/p/62
- RLHF价值分析
- RLHF问题分析
- 数据收集与模型训练
- RLHF内部剖析
- RLHF实践
- 数据预处理模块
- 模型训练\生成\评估
- zhuanlan.zhihu.com/p/63
- MOSS-RLHF 实践
- 奖励模型训练
- PPO 微调
第12章 类ChatGPT实战
12.1 任务设计
12.2 数据准备
- 基于文档生成问题任务的类 github.com/liucongg/Cha
- SFT阶段
- RM阶段
- RL阶段
第13章 语言模型训练数据
13.1 数据来源
- 通用数据
- 专业数据
13.2 数据处理
- 低质过滤
- 冗余去除
- 隐私消除
13.3 数据影响分析
- 数据规模影响
- 数据质量影响
- 数据多样性影响
13.4 开源数据集合
- Pile
- ROOTS
- RefinedWeb
- SlimPajama
第14章 大语言模型评估
14.1 模型评估概述
14.2 大语言模型评估体系
- 知识与能力
- 伦理与安全
- 垂直领域评估
14.3 大语言模型评估方法
- 评估指标
- 评估方法
14.4 大语言模型评估实践
- 基础模型评估
- SFT/RL 模型评估
第15章 多模态大模型
- 多模态大模型调研
- 实战
第16章 大模型原生应用
16.1 落地调研
- 应用分析
- 提供大模型基础服务:ChatGPT、Gemini、文心一言和GLM4等,主要面向ToC/ToB提供chat能力(内容创作、代码开发等),通过会员收费或按Token计费
- ToB提供成套解决方案
- 集成现有接口二次开发,应用开发
- 开源模型增量预训练、全量微调、高效微调,行业内落地
模型最终还需落地解决实际问题,创造价值:优化现有问题、满足、甚至创造用户需求。
总的来说,就是规模化、自动化人的工作,替代人工,批量化、大规模生成或提供服务。
16.2 应用分析
一些思考
在企业里面做7B、13B量级的微调,主要就是在搞数据、样本,技术壁垒不高。预训练壁垒高,因为需要烧钱堆经验。
在这个日新月异的时代,如何紧跟行业主流发展,并具备不可替代性是个难题:
- 稀缺(不可替代性)
- 稳定(业务和表层技术天天变,但底层的理论变化不大)
- 需求持续(最好是类似衣食住行的刚需,否则技术 过时/热度褪去/不达预期,泡沫崩溃)
- 不能越老越吃香(放到绝大多数行业都适用:不能经验积累,持续长期创造价值)
- 壁垒(技术、业务、资本上有垄断)
尽量往底层和工程化上靠,学习相对不变的技术(理论上变化很难),迁移到稳定或有前景的行业,不断提升自己的学习效率:
- 计算机系统知识(训练、推理、开发,模型推理部署工程化)
- 数学(深入学习并实践)
参考:
想学习大语言模型(LLM),应该从哪个开源模型开始? - 知乎
相关文章:

2024-03-26 AIGC-大模型学习路线
摘要: 2024-03-26 AIGC-大模型学习路线 大模型学习路线 建议先从主流的Llama开始,然后选用中文的Qwen/Baichuan/ChatGLM,先快速上手体验prompt工程,然后再学习其架构,跑微调脚本 如果要深入学习,建议再按以下步骤&am…...
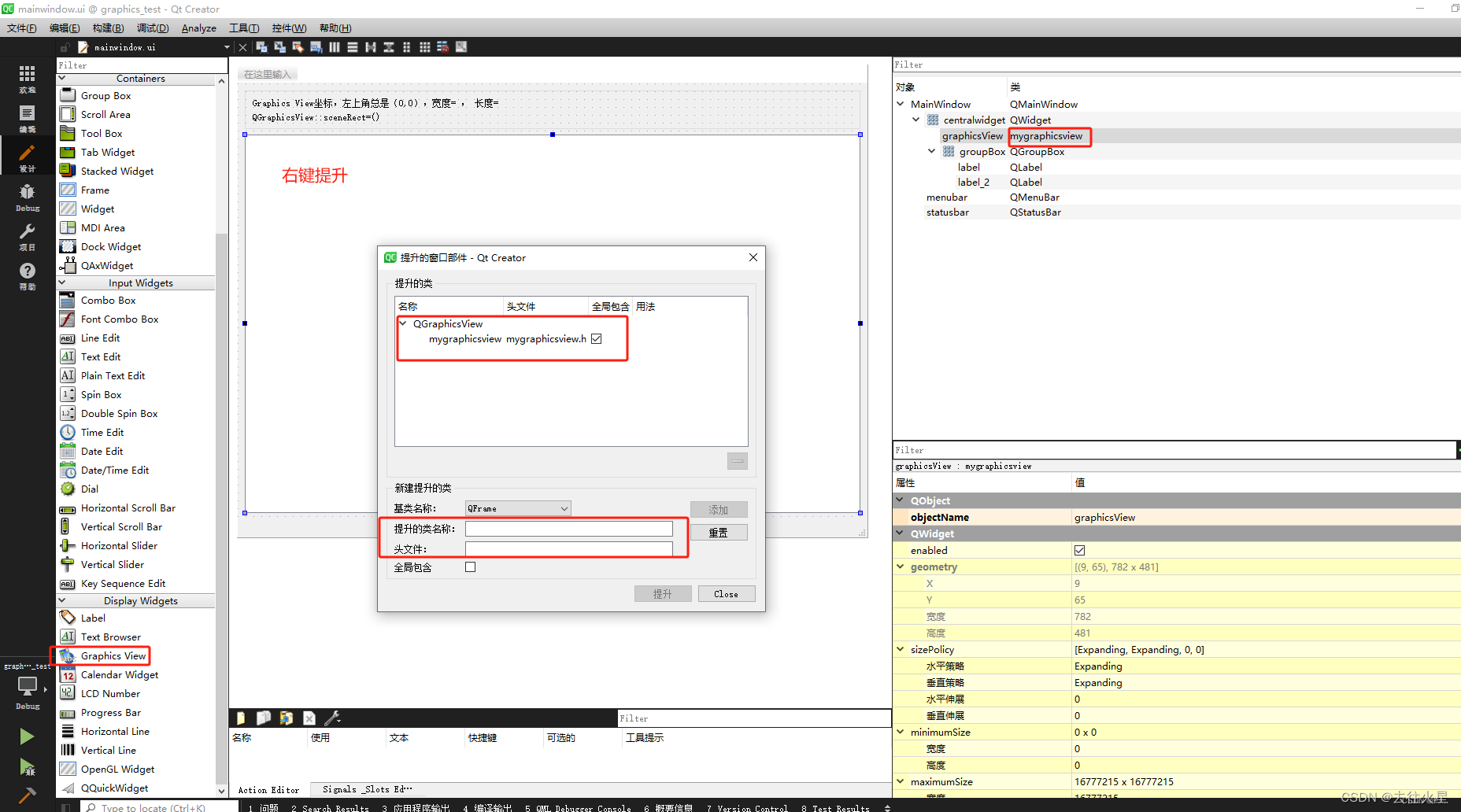
QGraphicsView的使用,view坐标,scene坐标,item坐标
Graphics View绘图构架 QGraphicsScene(场景):可以管理多个图形项QGraphicsItem(图形项):也就是图元,支持鼠标事件响应。QGraphicsView(视图):关联场景可以让…...
from_pretrained 做了啥
transformers的三个核心抽象类是Config, Tokenizer和Model,这些类根据模型种类的不同,派生出一系列的子类。构造这些派生类的对象也很简单,transformers为这三个类都提供了自动类型,即AutoConfig, AutoTokenizer和AutoModel。三个…...
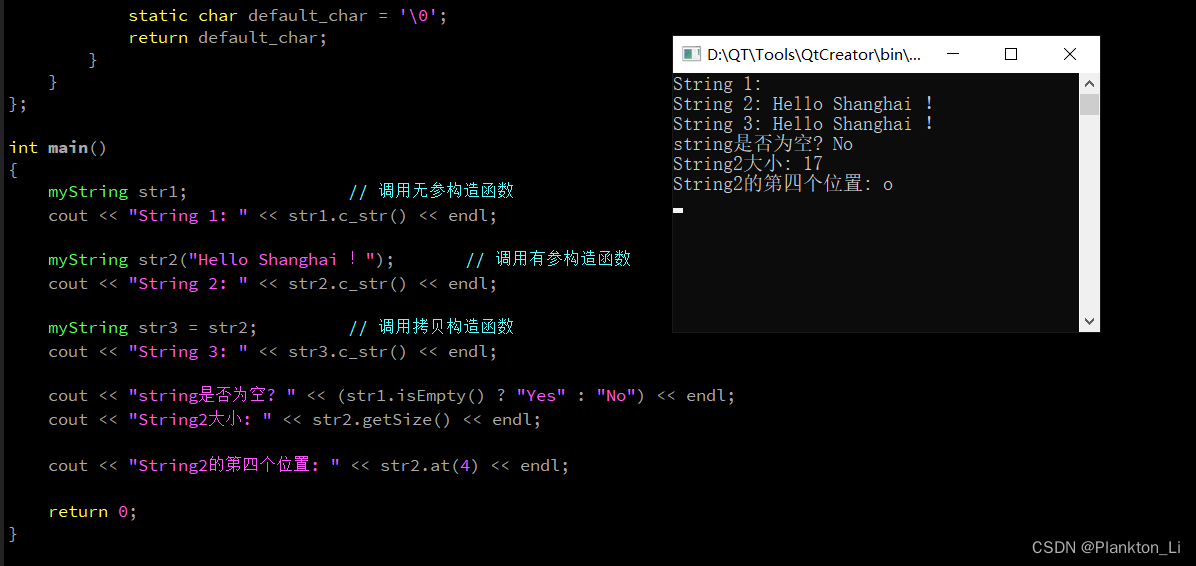
2024/03/27(C++·day3)
一、思维导图 二、完成下面类 代码 #include <cstring> #include <iostream>using namespace std;class myString { private:char *str; // 记录C风格的字符串int size; // 记录字符串的实际长度public:// 无参构造函数myString() : size(10){str new char[si…...

Multimodal Chain-of-Thought Reasoning in Language Models阅读笔记
论文(2023年)链接:https://arxiv.org/pdf/2302.00923.pdf GitHub项目链接:GitHub - amazon-science/mm-cot: Official implementation for "Multimodal Chain-of-Thought Reasoning in Language Models" (stay tuned a…...
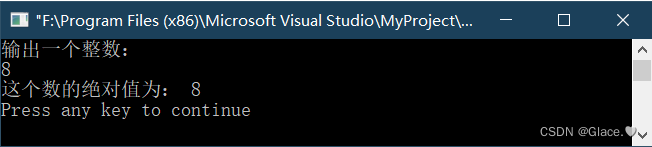
C语言例4-15:从键盘输入一个整数,求其绝对值并输出。
代码如下: //从键盘输入一个整数,求其绝对值并输出。 #include<stdio.h> int main(void) {int n;printf("输出一个整数: \n");scanf("%d",&n); //从键盘输入一个整数保存至变量nif(n<0) //…...

【Linux】调试器-gdb的使用说明(调试器的配置,指令说明,调试过程说明)
目录 00.背景 01.安装 02.生成调试信息 03.调试过程 00.背景 在软件开发中,通常会为程序构建两种不同的版本:Debug模式和Release模式。它们之间的区别主要在于优化级别、调试信息、错误检查等方面: 1.Debug 模式: 优化级别低…...

Oracle AI Vector Search Multi-Vector Similarity Search 即多向量相似度检索学习笔记
Oracle AI Vector Search Multi-Vector Similarity Search 即多向量相似度检索学习笔记 0. 什么是多向量相似度检索1. 多向量相似度检索的示例 SQL2. 执行多向量相似度检索3. 分区行限制子句的完整语法 0. 什么是多向量相似度检索 多向量相似度检索涉及通过使用称为分区的分组…...

白板手推公式性质 AR模型 时间序列分析
白板手推公式性质 AR模型 时间序列分析 视频讲解:https://www.bilibili.com/video/BV1D1421S76v/?spm_id_from.dynamic.content.click&vd_source6e452cd7908a2d9b382932f345476fd1 B站对应视频讲解(白板手推公式性质 AR模型 时间序列分析)...

零基础学python之高级编程(6)---Python中进程的Queue 和进程锁,以及进程池的创建 (包含详细注释代码)
Python中进程的Queue 和进程锁,以及进程池的创建 文章目录 Python中进程的Queue 和进程锁,以及进程池的创建前言一、进程间同步通信(Queue)二、进程锁(Lock)三、创建进程池Poorpool 类方法: End! 前言 大家好,上一篇文章,我们初步接触了进程的概念及其应…...

184. 部门工资最高的员工
文章目录 题意思路代码 题意 题目链接 查出每个部门最高工资 思路 子查询group by 代码 select b.name as Department,a.name as Employee,salary from Employee as a left joinDepartment as b ona.departmentId b.id where(a.departmentId, salary) in(select departme…...

插值表达式、Vue指令、指令补充
vue上手步骤 <body><!-- vue2语法 --><!-- 1.准备容器:一会vue就会把数据展示到这里 --><div id"app"><!-- 4.使用{{ }}即可显示数据 ,{{}}就是插值表达式--><p>姓名:{{uname}}</p><…...

qiankun实现基座、子应用样式隔离
目录 qiankun 实现主应用与子应用样式隔离使用CSS-in-JS来实现样式隔离react-jssstyled-components qiankun 实现主应用与子应用样式隔离 qiankun 之中默认的样式隔离是针对子应用与子应用之间的。至于主应用的样式会影响到子应用,若需要,则需要配置进行…...
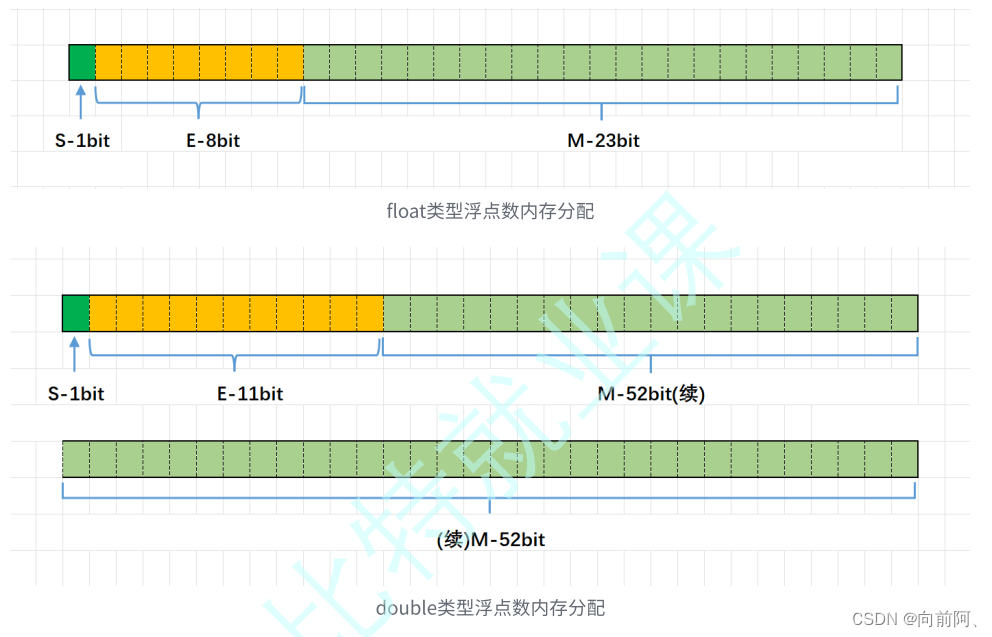
C语言从入门到实战----数据在内存中的存储
1. 整数在内存中的存储 在讲解操作符的时候,我们就讲过了下⾯的内容: 整数的2进制表⽰⽅法有三种,即 原码、反码和补码 有符号的整数,三种表⽰⽅法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤…...
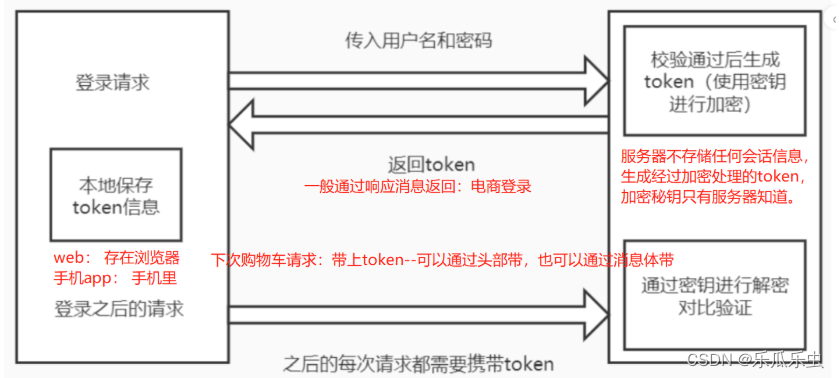
接口关联和requests库
一、接口关联 postman的接口 postman的接口关联配置:js代码,重点在于思路。 // 定义jsonData这个变量 接受登录接口的返回结果 var jsonData JSON.parse(responseBody); // 从返回结果里提取token/id值,并赋值给token/id变量值作为环境变…...

Python编程基础 001 开篇:为什么要学习编程
Python编程基础 001 开篇:为什么要学习编程 一、什么是程序,什么是编程二、学习编程对青少年的价值(一)未来社会的需要(二)学习对现青少年现的现阶段的直接影响 三、学习编程从什么时候开始(一)…...
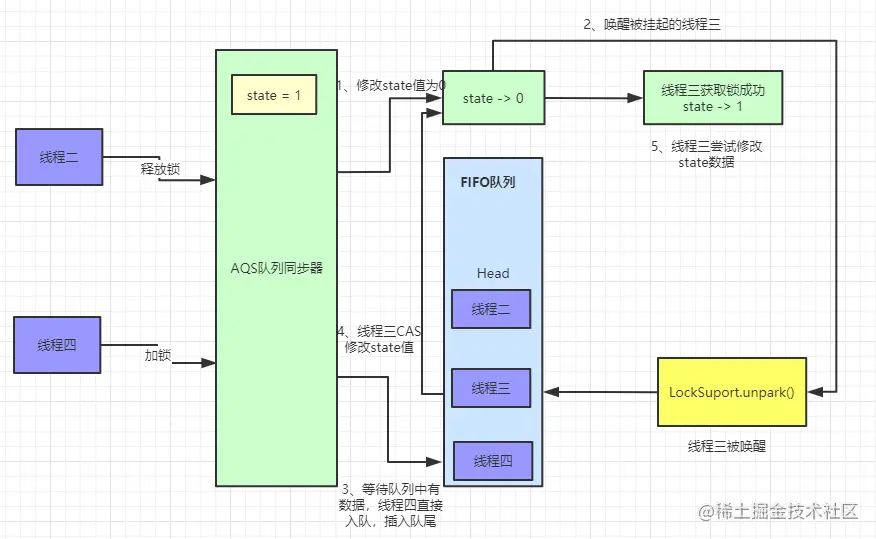
AQS源码分析
前言 AbstractQueuedSynchronizer是抽象同步队列,其是实现同步机器的基础组件,并发包中的锁的底层就是使用AQS实现的。AQS中 维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞…...
应对Locked勒索病毒威胁:你的数据安全准备好了吗?
导言: .Locked勒索病毒,作为一种新型的恶意软件,已经在全球范围内引起了广泛的关注。这种病毒通过加密受害者的文件,并要求支付赎金以获取解密密钥,从而实现对受害者的勒索。本文旨在深入解析.Locked勒索病毒的特点、…...

周末分享一篇关于html和http的文章吧
前面咱们说了https://blog.csdn.net/luohaitao/article/details/136974344(说道说道JSP和HTTP吧-CSDN博客),把http的方法和jsp中httpservle对象的方法对上号了,其实从开发的角度看,jsp就是html中混入了java的服务端代码…...

Frechet分布
Frechet分布是一种连续概率分布,它是极值统计中的一个重要模型,尤其在分析极端事件(如洪水、地震、金融市场中的极端波动)的最大值极限分布时扮演关键角色。Frechet分布属于极值分布的三种基本类型(I型、II型、III型&a…...

抖音内容保存技术方案:开源下载工具深度解析与应用实践
抖音内容保存技术方案:开源下载工具深度解析与应用实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

Windows环境5步搞定OpenCore引导盘:Hackintosh安装终极指南
Windows环境5步搞定OpenCore引导盘:Hackintosh安装终极指南 【免费下载链接】OpenCore-Install-Guide Repo for the OpenCore Install Guide 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Install-Guide 想要在普通PC上体验macOS的流畅与优雅吗&am…...

CANN 生态工具链:ATC、ACL 与 MindX 全景
一、CANN 工具链全景 1.1 工具链架构 ┌──────────────────────────────────────────────────┐ │ CANN 工具链全景 │ ├──────────────────────────────…...

想选靠谱的呼入语音机器人?这三个核心维度别忽略
电商大促期间客服热线占线不断,客户等待几分钟后愤然挂断;夜间咨询无人值守,潜在商机白白流失;传统语音机器人只会机械重复 “请按 1”,遇到稍微复杂的问题就答非所问…… 这些场景几乎是每个企业客服部门的日常痛点。…...
)
别再手动调图了!用LaTeX的subcaption包搞定论文子图排版(附完整代码)
LaTeX子图排版终极指南:告别手动调整的5个高效技巧 写论文时最让人抓狂的莫过于图片排版——尤其是当需要排列多个子图时。每次编译后总有几个图片位置不对齐,标题错位,或者直接跑到了下一页。这种反复调试的过程不仅浪费时间,还…...

重塑AI代理的数据智能:Wren AI如何构建开放上下文层
重塑AI代理的数据智能:Wren AI如何构建开放上下文层 【免费下载链接】WrenAI Turn any AI Agents into world-class data analysts through the open context layer that gives AI agents grounded, governed memory, context, SQL across 20 data sources, that he…...

QKeyMapper:重新定义Windows输入控制的终极解决方案
QKeyMapper:重新定义Windows输入控制的终极解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠,手…...

CANN/pypto填充操作API
pypto.pad 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atla…...

Input Overlay:免费开源直播输入显示插件终极指南
Input Overlay:免费开源直播输入显示插件终极指南 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay 在游戏直播、教学演示或技术分享中,观众最常问…...

OBS多平台直播插件:一次推流,全网同步的终极解决方案
OBS多平台直播插件:一次推流,全网同步的终极解决方案 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 你是否曾经想过,一场精彩的直播内容可以同时出现…...