Python基础:标准库 -- pprint (数据美化输出)
1. pprint 库 官方文档
pprint --- 数据美化输出 — Python 3.12.2 文档
pprint — Data pretty printer — Python 3.12.2 documentation
2. 背景
处理JSON文件或复杂的嵌套数据时,使用普通的 print() 函数可能不足以有效地探索数据或调试应用程序。下面通过一个例子说明说明使用 print() 的弊端。
首先,使用 urllib 发出请求以获取数据。这里提供了两组代码,第一组含配置代理部分,第二组代码直接使用 urllib.request.urlopen。
-
代理(英语:Proxy,也称网络代理)是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接:本机 ----代理IP----访问的网站(服务器)。
-
urllib 提供 urllib.request.ProxyHandler() 方法可动态设置代理IP池
需要配置代理时:
import urllib.request
import urllib.parse
import jsonurl = "https://jsonplaceholder.typicode.com/users"# 如果代理网站需要提供用户名和密码,注意密码含有特殊字符时要进行url编码
username = '****'
encoded_password = urllib.parse.quote("****")
proxies ={"https": "****代理网站IP****"
}handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url).read()
result = json.loads(response)
print(result)不需要配置代理时:
from urllib import request
import jsonresponse = request.urlopen("https://jsonplaceholder.typicode.com/users")
json_response = response.read()
users = json.loads(json_response)打印结果(内容较长此处仅截取部分作为展示):

输出结果并不友好,是很长的一堆,不能帮助开发者理解数据的结构。
3. pprint 函数:初阶
pprint 用于以漂亮的方式打印数据,它属于是Python标准库,无需单独安装,使用时只需导入它的pprint() 函数:
from pprint import pprintpprint(result)打印结果(内容较长此处仅截取部分作为展示):

pprint 的输出结果有合适的缩进,能够帮助开发者可视化分析数据结构。如果你想尽可能少地输入,pprint() 有一个别名 pp(),它的行为方式与 pprint 完全相同。
from pprint import pprint, pp# pprint(result)
pp(result)4. pprint 函数:进阶
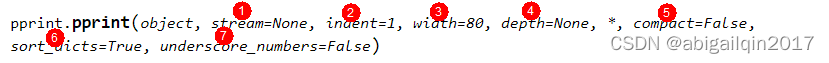
pprint() 将在 stream 上打印 object 的格式化表示形式,indent 等参数用于设置数据结构的格式化形式,即以何种方式被展示。
4.1 参数概述
- stream:一个 file-like object,表示调用 write() 方法时,输出内容被写入的位置(to which the output will be written by calling its write() method)。默认为 sys.stdout,如果 stream 和 sys.stdout 均为 None,则 pprint() 将静默地返回。
- indent:指定要为每个缩进层级添加的缩进量,默认为 1,一个空格字符。
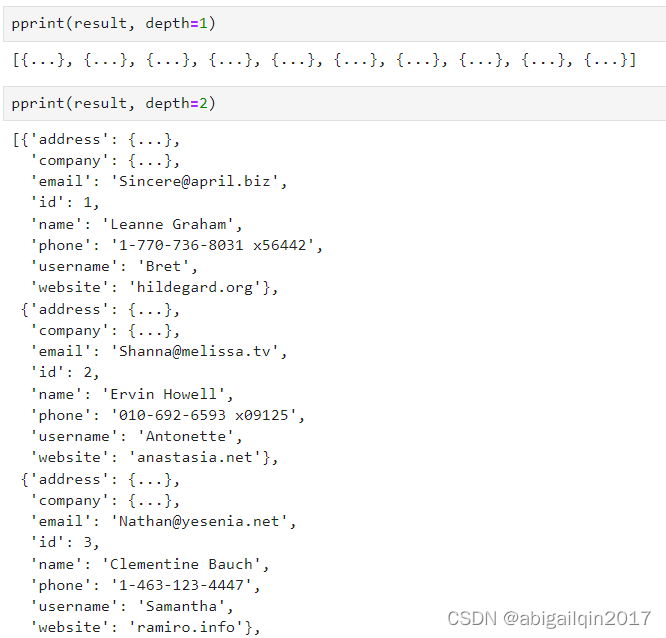
- depth:控制可被打印的缩进层级数量。如果要打印的数据结构层级过深,则其所包含的下一层级将用 ... 替换。 默认对于被格式化对象的层级深度无限制。
- width:指定输出中每行所允许的最大字符数,默认为 80。 如果一个数据结构无法在宽度限制之内被格式化,将显示尽可能多的内容。
- compact:影响长序列(列表、元组、集合等等)的格式化方式。如果 compact 为True,则每个输出行格式化时将在 width 的限制之内尽可能地容纳多个条目。 如果 compact 为 False 则序列的每一项将格式化为单独的行。默认为 False。
- sort_dicts:如果为 True,字典在格式化时将基于键进行排序,否则它们将按插入顺序显示。默认为 True。
- underscore_numbers:如果为 True,整数在格式化时将使用 _ 字符作为千位分隔符,否则不显示下划线。默认为 False。
4.2 参数详解
depth:深度
indent:缩进
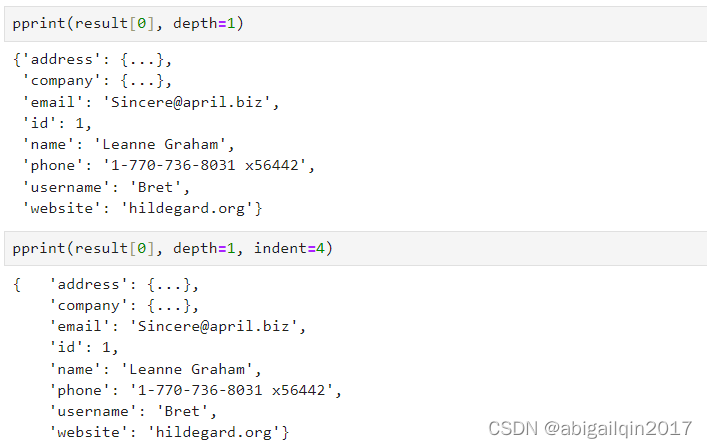
注:在这两个示例中,左花括号 { 被算为第一个键的缩进单位。在第一个示例中,第一个键的开始单引号紧跟在 { 之后,中间没有任何空格,因为缩进默认设置为1。
当存在嵌套时,缩进应用于行内的第一个元素,后续元素与第一个元素对齐。
如果将缩进设置为4,第一个元素将缩进四个字符,而第一个元素的嵌套内容将缩进超过八个字符,它的缩进是从第一个键的末尾开始的。
width:宽度
默认情况下,pprint() 每行最多只能输出80个字符,可以通过传入width参数来自定义此值。
pprint() 将努力将内容放在一行上,如果数据结构的内容超过了这个限制,那么它将在新的一行上打印当前数据结构的每个元素。width 的原则是在保证输出内容的可读性的前提下,尽可能地限制每行的宽度。这可以帮助我们在打印输出时避免过多的换行。
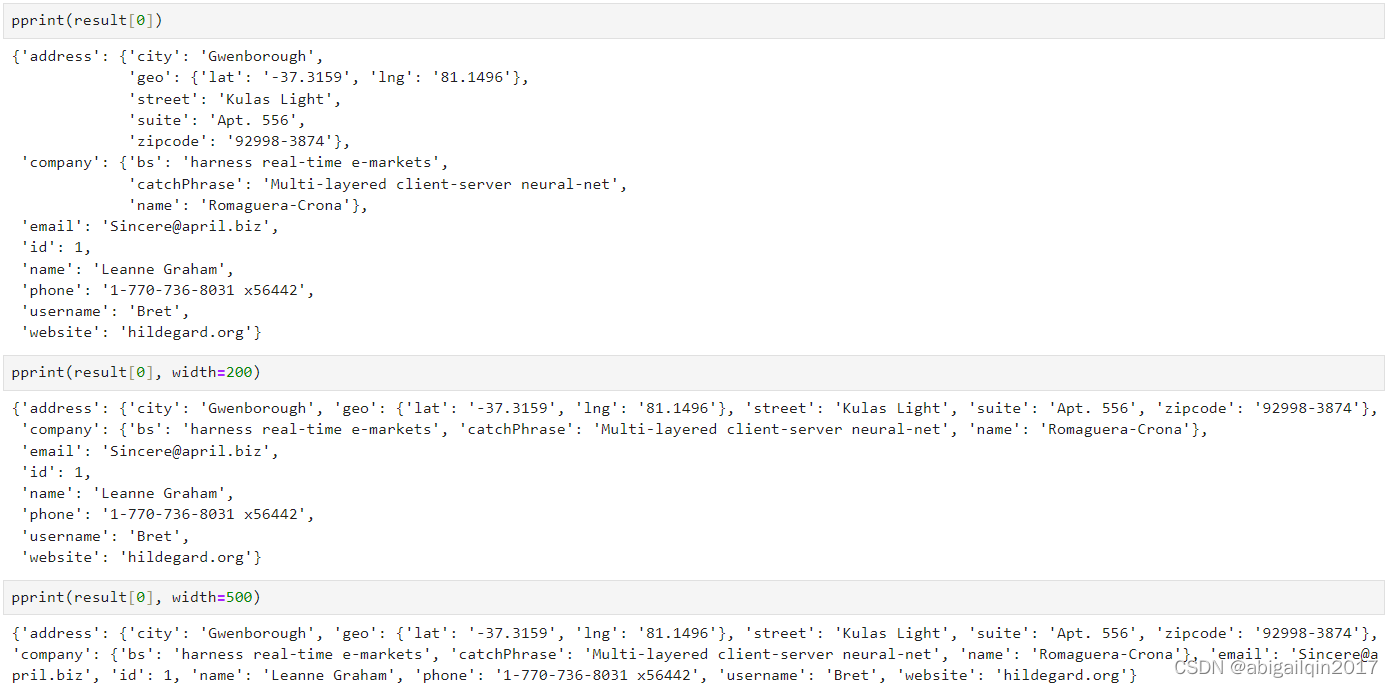
如果将宽度设置为较低的值,例如3,依然会得到美观的结果,这样做的主要效果是:每个数据结构都将在单独的行上显示。
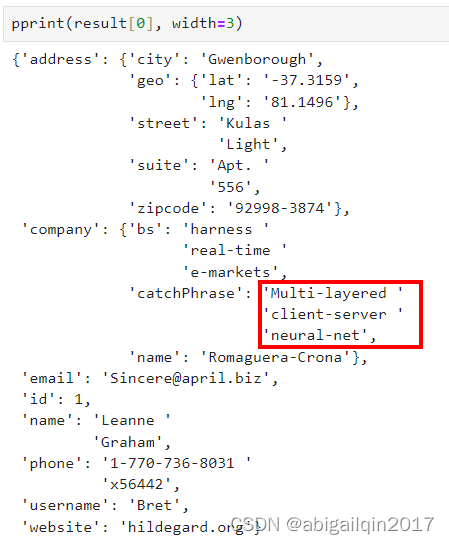
如果需要分割某个字符,pprint 会避免从中间分割字符串,那样会影响阅读,在当前的例子中,pprint 在空格处进行分割。
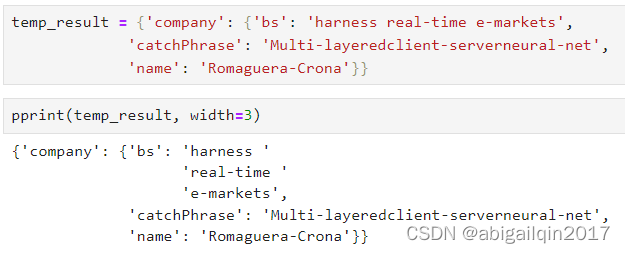
compact:Bool,是否采用紧凑模式
compact 参数则指定了是否使用紧凑模式,如果 compact 为 True,则输出的格式会更加紧凑,否则会更加易读。
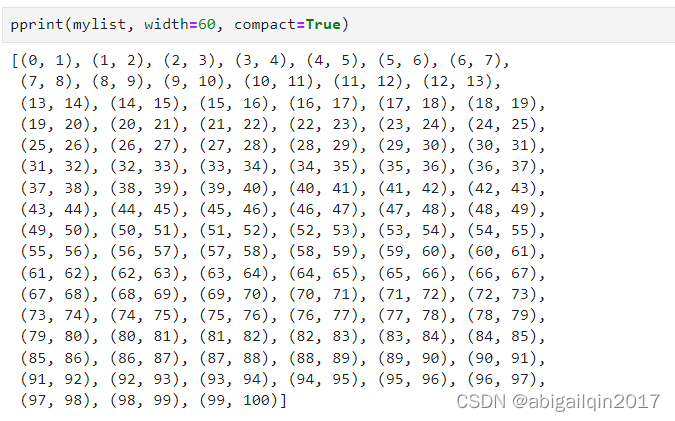
from pprint import pprintmylist = [(i, i+1) for i in range(100)]
print(mylist)
pprint(mylist, width=60)
pprint(mylist, width=60, compact=True)

stream:输出位置
默认情况下,pprint() 的输出位置与 print() 相同,具体来说,指向 sys.stdout。不过,可以通过 stream 参数,将其重定向到任何文件对象或 logging 日志对象。
with open("output.txt", mode="w") as file_object:pprint(result, stream=file_object)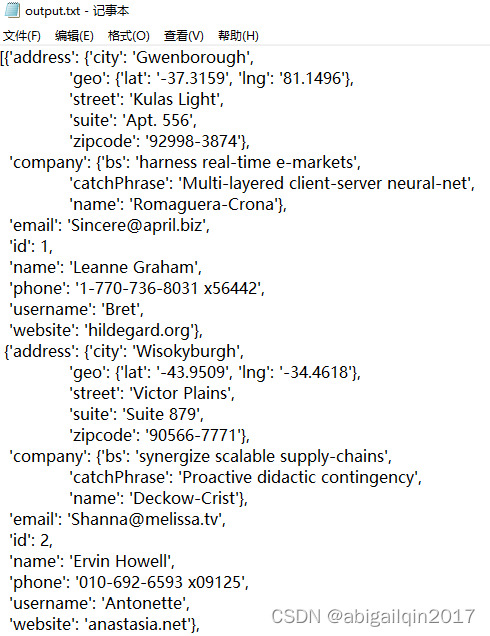
sort_dicts:Bool,字典是否需要排序(keys 首字母按字母表顺序排序)
pprint(result, sort_dicts=False)打印结果:

默认情况下,pprint() 将按字母顺序对键进行排序(sort_dicts = True),这能够保证每次打印时,输出的内容都是一样的。如果将 sort_dicts 设置为 False,字典是无序的,从理论上讲,每次打印时字典的键的顺序可能不同。
underscore_numbers:Bool,长数字是否需要下划线分隔符
注:某些版本直接调用 pprint() 时,使用这个参数有可能报错,后续的版本会解决。
5. pformat() 函数:输出字符串

代码示例-1:
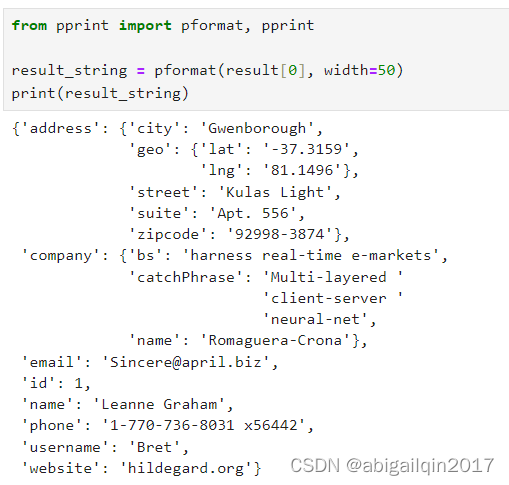
from pprint import pformat, pprintresult_string = pformat(result[0], width=50)
print(result_string)打印结果-1:
代码示例-2
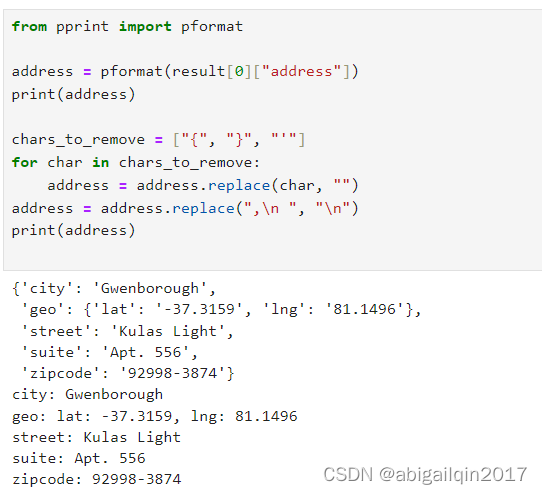
from pprint import pformataddress = pformat(result[0]["address"])
print(address)chars_to_remove = ["{", "}", "'"]
for char in chars_to_remove:address = address.replace(char, "")
address = address.replace(",\n ", "\n")
print(address)打印结果-2:
6. isreadable函数 和 isrecursive 函数
- isreadable 函数:输出布尔值, 表示是否可通过 eval 重构对象值,此函数对于递归对象总是返回 False。
- isrecursive 函数:输出布尔值, 表示 object 是否需要递归的表示。
代码示例:
from pprint import pprint, isreadable, isrecursive# 正常字典
pprint(result[0])
print(isreadable(result[0]))
print(isrecursive(result[0]))
print('\n')# 递归对象
stuff = ['spam', 'eggs', 'lumberjack', 'knights', 'ni']
stuff.insert(0, stuff)
pprint(stuff)
print(isreadable(stuff))
print(isrecursive(stuff))打印结果:

再举一个递归场景的例子:
from pprint import pprintA = {}
B = {"link": A}
A["link"] = B
print(A)
# {'link': {'link': {...}}}
pprint(A)
# {'link': {'link': <Recursion on dict with id=2747052595392>}}字典 A 存在循环引用,永远无法得到最终结果,因而也无法完成打印。处理这样的数据时,Python 的常规 print() 将缩写输出,pprint() 能够显式地通知用户这是一种递归表示,并提供字典的ID。
7. PrettyPrinter类

除了直接调用 pprint 函数,还可以创建 PrettyPrinter 的实例,该实例具有已定义的默认值,在需要的时候,调用实例的 .pprint() 方法即可。
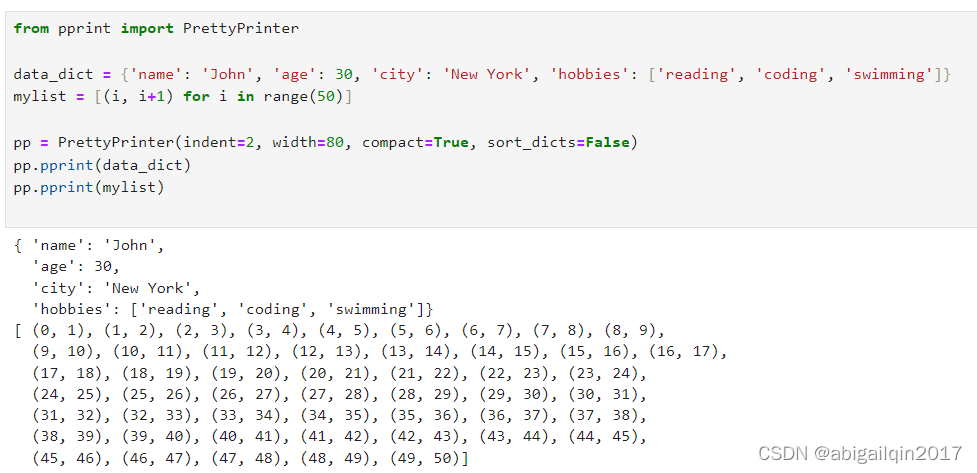
from pprint import PrettyPrinterdata_dict = {'name': 'John', 'age': 30, 'city': 'New York', 'hobbies': ['reading', 'coding', 'swimming']}
mylist = [(i, i+1) for i in range(50)]pp = PrettyPrinter(indent=2, width=80, compact=True, sort_dicts=False)
pp.pprint(data_dict)
pp.pprint(mylist)
打印结果:
8. 参考文档
已解决urllib模块设置代理ip_urllib2.request 设置代理-CSDN博客
Prettify Your Data Structures With Pretty Print in Python – Real Python
相关文章:
Python基础:标准库 -- pprint (数据美化输出)
1. pprint 库 官方文档 pprint --- 数据美化输出 — Python 3.12.2 文档 pprint — Data pretty printer — Python 3.12.2 documentation 2. 背景 处理JSON文件或复杂的嵌套数据时,使用普通的 print() 函数可能不足以有效地探索数据或调试应用程序。下面通过一…...

Visual Studio 小更新:改善变量的可见性
在 Visual Studio 2022 17.10 预览版 2 中,我们改善了一些小功能,例如:在调试版本中,变量窗口现已可以显示调用堆栈中任意帧的局部变量。 如需体验此功能,请直接安装最新预览版本,就可以知道是怎么一回事儿…...
C++自主点餐系统
一、 题目 设计一个自助点餐系统,方便顾客自己点餐,并提供对餐厅销售情况的统计和管理功能。 二、 业务流程图 三、 系统功能结构图 四、 类的设计 五、 程序代码与说明 头文件1. SystemMap.h #pragma once #ifndef SYSTEMMAP #define SYSTEMMAP #in…...

jconsole jvisualvm
jconsole 打开方式 命令行输入 jconsole双击想要连接的应用 界面展示 jvisualvm 打开方式 命令行输入 jvisualvm双击想要连接的应用 可以安装插件,比如 Visual GC 直观看到 GC 过程...

python vtkUnstructuredGrid 转 vtkAlgorithmOutput_
在VTK (Vtk.py)中,vtkUnstructuredGrid对象可以通过多种方式转换为vtkAlgorithmOutput_对象。这种转换通常在管道中使用,以将一个算法的输出传递给另一个算法作为其输入。 以下是一个简单的例子,展示如何将vtkUnstructuredGrid对象转换为 v…...
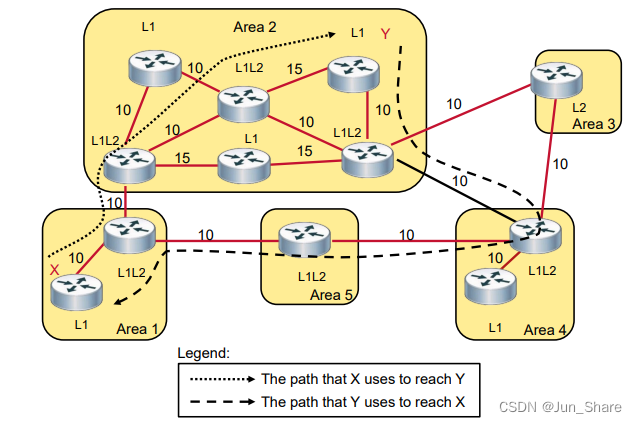
IS-IS路由
概览: Intermediate System-to-Intermediate System,中间系统到中间系统协议 IS-IS--IGP--链路状态协议--AD值:115 IS--中间系统(路由器) ES--终端系统(PC) 在早期IS-IS的开发并不是为了IP…...

打造新质生产力,亚信科技2024年如何行稳致远?
引言:不冒进、不激进,稳扎稳打, 一个行业一个行业地深度拓展。 【全球云观察 | 科技热点关注】 基于以往“一巩固、三发展”的多年业务战略,亚信科技正在落实向非通信行业、标准产品、软硬一体产品和国际市场的“四…...

开源博客项目Blog .NET Core源码学习(12:App.Application项目结构分析)
开源博客项目Blog的App.Application项目主要定义网站页面使用的数据类,同时定义各类数据的增删改查操作接口和实现类。App.Application项目未安装Nuget包,主要引用App.Core项目的类型。 App.Application项目的顶层文件夹如下图所示,下面逐…...

AES加密解密算法
一,AES算法概述 AES属于分组加密,算法明文长度固定为128位(单位是比特bit,1bit就是1位,128位等于16字节) 而密钥长度可以是128、192、256位 当密钥为128位时,需要循环10轮完成加密࿰…...
)
计算机网络(05)
计算机网络(04) 网络负载均衡 由多台服务器以对称的方式组成一个服务器集合每台服务器都具有等价的地位 , 可以单独对外提供服务而无须其他服务器的辅助均衡负载能够平均分配客户请求到服务器列阵,借此提供快速获取重要数据,解决…...
6、ChatGLM3-6B 部署实践
一、ChatGLM3-6B介绍与快速入门 ChatGLM3 是智谱AI和清华大学 KEG 实验室在2023年10月27日联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,免费下载,免费的商业化使用。 该模型在保留了前两代模型对话流畅、部署门槛低等众多…...
)
python面试题(1~10)
1、列表(list)和元组(tuple)有什么区别? ①列表是不可变的,创建后可以对其进行修改。元组是不可变的,元组一旦创建,就不能对其进行修改。 ②列表表示的顺序,它们是有序…...

分类预测 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积神经网络-长短期记忆网络融合多头注意力机制多特征分类预测
分类预测 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积神经网络-长短期记忆网络融合多头注意力机制多特征分类预测 目录 分类预测 | Matlab实现CNN-LSTM-Mutilhead-Attention卷积神经网络-长短期记忆网络融合多头注意力机制多特征分类预测分类效果基本介绍模型描述程序设计参…...
SQLServer CONCAT 函数的用法
CONCAT函数用于将多个字符串值连接在一起。以下是一个简单的示例,演示了如何使用CONCAT函数: -- 创建一个示例表 CREATE TABLE ExampleTable (FirstName NVARCHAR(50),LastName NVARCHAR(50) );-- 插入一些示例数据 INSERT INTO ExampleTable (FirstNam…...

python快速入门一
变量 定义一个变量并打印到控制台 message "Hello World!" print(message)控制台输出 Hello World!修改变量 message "Hello World!" print(message) message "Hello Python World!" print(message)控制台输出 Hello World! Hello Pytho…...

Elasticsearch 面试题及参考答案:深入解析与实战应用
在大数据时代,Elasticsearch 以其强大的搜索能力和高效的数据处理性能,成为了数据架构师和开发者必备的技能之一。本文将为您提供一系列精选的 Elasticsearch 面试题及参考答案,帮助您在面试中脱颖而出,同时也为您的大数据架构设计提供实战参考。 1. 为什么要使用 Elastic…...

【ARM 嵌入式 C 入门及渐进 18 -- 字符数字转整形函数 atoi 介绍】
请阅读【嵌入式开发学习必备专栏 】 文章目录 字符数字转整形函数 atoiatoi 简单实现 字符数字转整形函数 atoi 在 C 语言中,main 函数能够接收命令行参数。这些参数通过两个参数传递给 main 函数:int argc 和 char *argv[]。argc 是命令行参数的数量&a…...

全国超市数据可视化仪表板制作
全国超市消费数据展示 指定 Top几 客户销费数据展示 指定 Top几 省份销费数据展示 省份销售额数据分析 完整结果...

react native 总结
react app.js 相当与vue app.vue import React from react; import ./App.css; import ReactRoute from ./router import {HashRouter as Router,Link} from react-router-dom class App extends React.Component {constructor(props){super(props)}render(){return ( <…...
?自然语言处理(NLP)的概述)
什么是自然语言处理(NLP)?自然语言处理(NLP)的概述
什么是自然语言处理? 自然语言处理(NLP)是人工智能(AI)和计算语言学领域的一个分支,它致力于使计算机能够理解、解释和生成人类语言。随着技术的发展,NLP已经从简单的模式匹配发展到了能够理解…...

LiveSplit终极指南:为速度跑者量身定制的精准计时神器
LiveSplit终极指南:为速度跑者量身定制的精准计时神器 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款专为速度跑者打造的轻量级、高度可定制的计…...

Deno_2.0全栈开发实战下一代JavaScript运行时完全指南
Deno 2.0全栈开发实战:下一代JavaScript运行时完全指南 📅 发布日期:2026-05-21 | 🏷️ 标签:Deno、TypeScript、全栈开发、Fresh框架、边缘计算 📖 阅读时间:约25分钟 | 💡 难度:中级到高级 前言:Deno 2.0——Node.js之父的"理想主义"终于落地 2018年…...

C++Stack栈类模版实例详解
栈的实现方式分为3种基于静态数组实现,内部预设一个很大的数组对象, 实现简单,缺点是空间受限。基于动态数组实现,内部预设一个容量值,然后分配一段内存空间数组,如果入栈大于默认容量值时,则再次扩大分配新的内存数组,并将旧数组拷贝至新数组及释放旧数组.基于双向…...

跨行面试时被问你凭什么胜任,我亮出这个证书后面试官沉默了
很多人跨行找工作,最怕的不是不会,而是那句直戳心口的话:「你没有相关经验,凭什么说自己能胜任?」 😶这句话背后,考的从来不只是能力,还有你能不能拿出一个让人信服的证明。到了 202…...
)
从暗房到云端:一位古籍修复师用Midjourney蓝晒法重制《天工开物》插图的72小时实录(含失败21次原始日志)
更多请点击: https://intelliparadigm.com 第一章:从暗房到云端:一场古籍图像的跨时空显影 在胶片时代,古籍修复师需在幽暗的暗房中,借助红光灯与显影液,一帧一帧唤醒沉睡于纸背的墨痕;而今&am…...

B站视频下载终极指南:如何一键获取无水印高清视频
B站视频下载终极指南:如何一键获取无水印高清视频 【免费下载链接】BiliDownload B站视频下载工具 项目地址: https://gitcode.com/gh_mirrors/bil/BiliDownload 你是否曾为下载B站视频而烦恼?想要保存喜欢的视频却找不到合适的工具?B…...

智慧树自动刷课插件:5步实现高效学习自动化,节省70%学习时间
智慧树自动刷课插件:5步实现高效学习自动化,节省70%学习时间 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复性视频学习…...

新闻传播论文降AI工具免费推荐:2026年新闻传播毕业论文AIGC超标免费4.8元达标完整方案
新闻传播论文降AI工具免费推荐:2026年新闻传播毕业论文AIGC超标免费4.8元达标完整方案 帮室友处理过新闻传播论文降AI,前前后后试了四款工具,最后固定在嘎嘎降AI(www.aigcleaner.com)。 4.8元,达标率99.2…...

终极指南:3分钟掌握TMSpeech,打造完全本地的实时语音转文字神器
终极指南:3分钟掌握TMSpeech,打造完全本地的实时语音转文字神器 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 你是否厌倦了云端语音识别服务的隐私担忧和网络延迟?想要一个真正…...
-5月20日-第二题- LLM 多源语料分级清洗预算分配】(题目+思路+JavaC++Python解析+在线测试))
【2026年华为暑期实习(AI)-5月20日-第二题- LLM 多源语料分级清洗预算分配】(题目+思路+JavaC++Python解析+在线测试)
题目内容 某 L L M LLM LLM 预训练团队从 N N N 个数据源收集语料,每个数据源 i i...