Stable Diffusion XL之使用Stable Diffusion XL训练自己的AI绘画模型
文章目录
- 一 SDXL训练基本步骤
- 二 从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型
- 2.1 配置训练环境与训练文件
- 2.2 SDXL训练数据集制作
- (1) 数据筛选与清洗
- (2) 使用BLIP自动标注caption
- (3) 使用Waifu Diffusion 1.4自动标注tag
- (4) 补充标注特殊tag
- (5) 训练数据预处理(标注文件整合)
- 2.3 SDXL微调(finetune)训练
- (1 )SDXL 微调数据集要求
- (2) SDXL 微调训练参数配置
- 2.1 训练参数配置(XL_config文件夹)
- 2.1.1 config_file.toml
- 2.1.2 sample_prompt.toml
- (3) SDXL关键参数详解
- (4) SDXL模型开始训练
- 2.4 基于SDXL训练LoRA模型
- (1) SDXL LoRA数据集制作
- (2) SDXL LoRA训练参数配置
- 2.1 训练参数讲解(XL_LoRA_config文件夹)
- 2.1.1 config_file.toml
- (3) SDXL LoRA关键参数详解
- (4) SDXL LoRA模型训练
一 SDXL训练基本步骤
Stable Diffusion XL系列模型的训练过程主要分成以下几个步骤,
- 训练集制作:数据质量评估,标签梳理,数据清洗,数据标注,标签清洗,数据增强等。
- 训练文件配置:预训练模型选择,训练环境配置,训练步数设置,其他超参数设置等。
- 模型训练:运行SDXL模型/LoRA模型训练脚本,使用TensorBoard监控模型训练等。
- 模型测试:将训练好的自训练SDXL模型/LoRA模型用于效果评估与消融实验
二 从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型
下面是SDXL的训练资源
链接:https://pan.quark.cn/s/5664c0de758d
提取码:LRZV
2.1 配置训练环境与训练文件
1. 首先进入SDXL-Train项目中,安装SDXL训练所需的依赖库
cd SDXL-Train
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple some-package# accelerate库的版本需要重新检查一遍,需要安装accelerate==0.16.0版本才能兼容SDXL的训练
pip install accelerate==0.16.0 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package# 这里推荐大家安装2.0.1版本的Pytorch,能够兼容SDXL训练的全部流程
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
或者conda
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
在完成上述的依赖库安装后,我们需要确认一下目前的Python、PyTroch、CUDA以及cuDNN的版本是否兼容,在命令行输入以下命令:
# Python版本推荐3.8或者3.9,两个版本皆可
>>>python
Python 3.9
# 加载PyTroch
>>>import torch
# 查看PyTorch版本
>>>print(torch.version)
2.0.1
# 查看CUDA版本
>>> print(torch.version.cuda)
11.8
# 查看cuDNN版本
>>> print(torch.backends.cudnn.version())
8500
# 查看PyTroch、CUDA以及cuDNN的版本是否兼容,True代表兼容
>>> print(torch.cuda.is_available())
True
- 安装和验证好所有SDXL训练所需的依赖库后,我们还需要设置一下SDXL的训练环境,我们主要是用accelerate库的能力,accelerate库能让PyTorch的训练和推理变得更加高效简洁。我们只需在命令行输入以下命令,并对每个设置逐一进行填写即可:
# 输入以下命令,开始对每个设置进行填写
accelerate config# 开始进行训练环境参数的配置
In which compute environment are you running? # 选择This machine,即本机
This machine# 选择单卡或是多卡训练,如果是多卡,则选择multi-GPU,若是单卡,则选择No distributed training
Which type of machine are you using?
multi-GPU# 几台机器用于训练,一般选择1台。注意这里是指几台机器,不是几张GPU卡
How many different machines will you use (use more than 1 for multi-node training)? [1]: 1# torch dynamo,DeepSpeed,FullyShardedDataParallel,Megatron-LM等环境参数,不需要配置
Do you wish to optimize your script with torch dynamo?[yes/NO]: # 输入回车即可
Do you want to use DeepSpeed? [yes/NO]: # 输入回车即可
Do you want to use FullyShardedDataParallel? [yes/NO]: # 输入回车即可
Do you want to use Megatron-LM ? [yes/NO]: # 输入回车即可# 选择多少张卡投入训练
How many GPU(s) should be used for distributed training? [1]:2# 设置投入训练的GPU卡id,如果是全部的GPU都投入训练,则输入all即可。
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all # 训练精度,可以选择fp16
Do you wish to use FP16 or BF16 (mixed precision)?
fp16 # 完成配置后,配置文件default_config.yaml会保存在/root/.cache/huggingface/accelerate下
accelerate configuration saved at /root/.cache/huggingface/accelerate/default_config.yaml完成上述的流程后,接下来我们就可以进行SDXL训练数据的制作和训练脚本的配置流程了!
后续进行SDXL与SDXL LoRA模型训练的时候,只需要加载对应的default_config.yaml配置文件即可,具体的调用方法,本文后续的章节会进行详细讲解。
还有一点需要注意的是,我们进行SDXL模型的训练时,SDXL的CLIP Text Encoder会调用CLIP-ViT-bigG-14-laion2B-39B-b160k和clip-vit-large-patch14两个配置文件。一般情况下SDXL模型会从huggingface上将配置文件下载到~/.cache/huggingface/目录中,但是由于网络原因很可能会下载失败,从而导致训练的失败。
所以为了让大家能更方便的训练SDXL模型,已经将CLIP-ViT-bigG-14-laion2B-39B-b160k和clip-vit-large-patch14这两个配置文件放入SDXL-Train项目的utils_json文件夹中,并且已经为大家配置好依赖路径,大家只要使用SDXL-Train项目便无需做任何修改。如果大家想要修改CLIP-ViT-bigG-14-laion2B-39B-b160k和clip-vit-large-patch14这两个依赖文件夹的调用路径,大家可以找到SDXL-Train/library/sdxl_train_util.py脚本中的第122行,将"utils_json/"部分修改成自己的本地自定义路径比如“/本地路径/utils_json/”即可。
完成上述的流程后,接下来我们就可以进行SDXL训练数据的制作和训练脚本的配置流程了!
2.2 SDXL训练数据集制作
(1) 数据筛选与清洗
首先,我们需要对数据集进行清洗,和传统深度学习时代一样,数据清洗工作依然占据了AIGC时代模型训练70%-80%左右的时间。
并且这个过程必不可少,因为数据质量决定了机器学习性能的上限,而算法和模型只是在不断逼近这个上限而已。
-
我们需要筛除分辨率较低、质量较差(比如说768*768分辨率的图片< 100kb)、存在破损以及和任务目标无关的数据,接着再去除数据里面可能包含的水印,干扰文字等污染特征。
-
同时,我们需要优先保证数据集的质量,在有质量的基础上再去增加数据集的数量与丰富度。
-
为了满足AI绘画生成图片时的尺寸适应度,我们可以对数据进行多尺度的增强,比如进行1:1,1:2,2:1,1:3,3:4,4:3,9:16,16:9等等尺寸的裁剪与缩放操作。但是切记不能在多尺度增强的时候将图片的主体特征裁剪掉(比如人脸,建筑等)。
完成上述的数据筛选与清洗工作后,我们就可以开始进行数据标注了。
数据标注可以分为自动标注和手动标注。自动标注主要依赖像BLIP(img2caption)和Waifu Diffusion 1.4(img2tag)等能够进行图片生成标签的模型,手动标注则依赖标注人员。
(2) 使用BLIP自动标注caption
我们先用BLIP对数据进行自动标注,BLIP输出的是自然语言标签,我们进入到SDXL-Train/finetune/路径下,运行以下代码即可获得自然语言标签(caption标签):
cd SDXL-Train/finetune/
python make_captions.py "/数据路径" --caption_weights “../BLIP/model_large_caption.pth” --batch_size=8 --beam_search --min_length=5 --max_length=75 --debug --caption_extension=".caption" --max_data_loader_n_workers=2
注意:在使用BLIP进行数据标注时需要依赖bert-base-uncased模型,已经帮大家配置好了,大家只要使用SDXL-Train项目便无需做任何修改。同时,如果大家想要修改bert-base-uncased模型的调用路径,可以找到SDXL-Train/finetune/blip/blip.py脚本的第189行,将“…/bert-base-uncased”部分修改成自己的本地自定义路径比如“/本地路径/bert-base-uncased”即可。
从上面的代码可以看到,我们第一个传入的参数是训练集的路径。下面一一向大家介绍一下其余参数的意义:
--caption_weights:表示加载的本地BLIP模型,如果不传入本地模型路径,则默认从云端下载BLIP模型。
--batch_size:表示每次传入BLIP模型进行前向处理的数据数量。
--beam_search:设置为波束搜索,默认Nucleus采样。
--min_length:设置caption标签的最短长度。
--max_length:设置caption标签的最长长度。
--debug:如果设置,将会在BLIP前向处理过程中,打印所有的图片路径与caption标签内容,以供检查。
--caption_extension:设置caption标签的扩展名,一般为".caption"。
--max_data_loader_n_workers:设置大于等于2,加速数据处理。
(3) 使用Waifu Diffusion 1.4自动标注tag
接下来我们可以使用Waifu Diffusion 1.4进行自动标注,Waifu Diffusion 1.4输出的是tag关键词,这里需要注意的是,调用Waifu Diffusion 1.4模型需要安装Tensorflow库,并且需要下载特定的版本(2.10.1)或者(2.10.0),不然运行时会报“DNN library is not found“错误。我们只需要在命令行输入以下命令即可:
如果是2.10.1建议不适用国内源,可能更新不完全,会报错,2.10.0可以使用国内源。
pip install tensorflow==2.10.1
或者
pip install tensorflow==2.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
完成上述的环境配置后,我们依然进入到SDXL-Trian/finetune/路径下,运行以下代码即可获得tag自动标注:
cd SDXL-Train/finetune/
python tag_images_by_wd14_tagger.py "/数据路径" --batch_size=8 --model_dir="../tag_models/wd-v1-4-moat-tagger-v2" --remove_underscore --general_threshold=0.35 --character_threshold=0.35 --caption_extension=".txt" --max_data_loader_n_workers=2 --debug --undesired_tags=""
从上面的代码可以看到,
我们第一个传入的参数是训练集的路径。
--batch_size:表示每次传入Waifu Diffusion 1.4模型进行前向处理的数据数量。
--model_dir:表示加载的本地Waifu Diffusion 1.4模型路径。
--remove_underscore:如果开启,会将输出tag关键词中的下划线替换为空格。
--general_threshold:设置常规tag关键词的筛选置信度。
--character_threshold:设置人物特征tag关键词的筛选置信度。
--caption_extension:设置tag关键词标签的扩展名,一般为".txt"。
-max_data_loader_n_workers:设置大于等于2,加速数据处理。
--debug:如果设置,将会在Waifu Diffusion 1.4模型前向处理过程中,打印所有的图片路径与tag关键词标签内容,以供检查。
--undesired_tags:设置不需要输出的tag关键词。
(4) 补充标注特殊tag
完成了caption和tag的自动标注之后,如果我们需要训练一些特殊标注的话,还可以进行手动的补充标注。
SDXL-Trian项目中也提供了对数据进行补充标注的代码,下面代码将其进行提炼总结,方便大家直接使用。
大家可以直接拷贝以下的代码,并按照代码中提供的注释进行参数修改,然后运行代码即可对数据集进行补充标注:
import os
# 设置为本地的数据集路径
train_data_dir = "/本地数据集路径"# 设置要补充的标注类型,包括[".txt", ".caption"]
extension = ".txt" # 设置要补充的特殊标注
custom_tag = "qclineart"# 若设置sub_folder = "--all"时,将遍历所有子文件夹中的数据;默认为""。
sub_folder = "" # 若append设为True,则特殊标注添加到标注文件的末尾
append = False# 若设置remove_tag为True,则会删除数据集中所有的已存在的特殊标注
remove_tag = False
recursive = Falseif sub_folder == "":image_dir = train_data_dir
elif sub_folder == "--all":image_dir = train_data_dirrecursive = True
elif sub_folder.startswith("/content"):image_dir = sub_folder
else:image_dir = os.path.join(train_data_dir, sub_folder)os.makedirs(image_dir, exist_ok=True)# 读取标注文件的函数,不需要改动
def read_file(filename):with open(filename, "r") as f:contents = f.read()return contents# 将特殊标注写入标注文件的函数,不需要改动
def write_file(filename, contents):with open(filename, "w") as f:f.write(contents)# 将特殊标注批量添加到标注文件的主函数,不需要改动
def process_tags(filename, custom_tag, append, remove_tag):contents = read_file(filename)tags = [tag.strip() for tag in contents.split(',')]custom_tags = [tag.strip() for tag in custom_tag.split(',')]for custom_tag in custom_tags:custom_tag = custom_tag.replace("_", " ")if remove_tag:while custom_tag in tags:tags.remove(custom_tag)else:if custom_tag not in tags:if append:tags.append(custom_tag)else:tags.insert(0, custom_tag)contents = ', '.join(tags)write_file(filename, contents)def process_directory(image_dir, tag, append, remove_tag, recursive):for filename in os.listdir(image_dir):file_path = os.path.join(image_dir, filename)if os.path.isdir(file_path) and recursive:process_directory(file_path, tag, append, remove_tag, recursive)elif filename.endswith(extension):process_tags(file_path, tag, append, remove_tag)tag = custom_tagif not any([filename.endswith(extension) for filename in os.listdir(image_dir)]
):for filename in os.listdir(image_dir):if filename.endswith((".png", ".jpg", ".jpeg", ".webp", ".bmp")):open(os.path.join(image_dir, filename.split(".")[0] + extension),"w",).close()# 但我们设置好要添加的custom_tag后,开始整个代码流程
if custom_tag:process_directory(image_dir, tag, append, remove_tag, recursive)
看完了上面的完整代码流程,如果大家觉得代码太复杂,don‘t worry,大家只需要复制上面的全部代码,并将train_data_dir ="/本地数据集路径"和custom_tag ="qclineart"设置成自己数据集的本地路径和想要添加的特殊标注,然后运行代码即可,非常简单实用。
大家注意,一般我们会将手动补充的特殊tag放在第一位,因为和caption标签不同,tags标签是有顺序的,最开始的tag权重最大,越靠后的tag权重越小。
(5) 训练数据预处理(标注文件整合)
-
首先,我们需要对刚才生成的后缀为.caption和.txt的标注文件进行整合,存储成一个json格式的文件,方便后续SDXL模型训练时调取训练数据与标注。
-
我们需要进入SDXL-Train项目的finetune文件夹中,运行merge_all_to_metadata.py脚本即可:
cd SDXL-Train
python ./finetune/merge_all_to_metadata.py "/本地数据路径" "/本地数据路径/meta_clean.json"
运行完merge_all_to_metadata.py脚本后,我们在数据集路径中得到一个meta_clean.json文件,打开可以看到图片名称对应的tag和caption标注都封装在了文件中。
在整理好标注文件的基础上,我们接下来我们需要对数据进行分桶与保存Latent特征,并在meta_clean.json的基础上,将图片的分辨率信息也存储成json格式,并保存一个新的meta_lat.json文件。
我们需要进入SDXL-Train项目的finetune文件夹中,运行prepare_buckets_latents.py脚本即可:
cd SDXL-Train
python ./finetune/prepare_buckets_latents.py "/本地数据路径" "/本地数据路径/meta_clean.json" "/本地数据路径/meta_lat.json" "调用的SDXL模型路径" --batch_size 4 --max_resolution "1024,1024"
运行完脚本,我们即可在数据集路径中获得meta_lat.json文件,其在meta_clean.json基础上封装了图片的分辨率信息,用于SDXL训练时快速进行数据分桶。
图片的Latent特征保存为了.npz文件,用于SDXL模型训练时,快速读取数据的Latent特征,加速训练过程。
到目前为止,我们已经完整的进行了SDXL训练所需的数据集制作与预处理流程。总结一下,我们在一张训练图片的基础上,一共获得了以下5个不同的训练配置文件:
meta_clean.json
meta_lat.json
自然语言标注(.caption)
关键词tag标注(.txt)
数据的Latent特征信息(.npz)

在完成以上所有数据处理过程后,接下来我们就可以进入SDXL训练的阶段了,我们可以对SDXL进行全参微调(finetune),也可以基于SDXL训练对应的LoRA模型。
2.3 SDXL微调(finetune)训练
(1 )SDXL 微调数据集要求
制作过程就是上个章节的内容
用于SDXL全参微调的数据集筛选要求和SDXL训练Lora不一样:
- 数据尺寸需要在512x512像素以上。
- 数据的大小最好大于300K。
- 数据种类尽量丰富,不同主题,不同画风,不同概念都要充分采集。
- 一个特殊tag对应的图像特征在数据集中需要一致,不然在推理过程触发这个tag时可能会生成多个特征的平均。
- 每个数据都要符合我们的审美和评判标准!每个数据都要符合我们的审美和评判标准!每个数据都要符合我们的审美和评判标准!
(2) SDXL 微调训练参数配置
本节中,主要介绍Stable Diffusion XL全参微调(finetune)训练的参数配置和训练脚本。
大家可以在SDXL-Trian项目的train_config文件夹中找到相应的训练参数配置(XL_config文件夹),并且可以在SDXL-Trian项目中运行SDXL_finetune.sh脚本,进行SDXL的全参微调训练。
2.1 训练参数配置(XL_config文件夹)
XL_config文件夹中有两个配置文件config_file.toml和sample_prompt.toml,他们分别存储着SDXL的训练超参数与训练中的验证prompt。
2.1.1 config_file.toml
config_file.toml的配置信息包含了sdxl_arguments,model_arguments,dataset_arguments,training_arguments,logging_arguments,sample_prompt_arguments,saving_arguments,optimizer_arguments八个维度的参数信息。
1. [sdxl_arguments]
#Stable Diffusion XL训练时需要打开,用于两个Text Encoder输出结果的缓存与融合。注:当cache_text_encoder_outputs设为true时,shuffle_caption将不起作用。
cache_text_encoder_outputs = true
#当此参数为true时,VAE在训练中使用float32精度;当此为false时,VAE在训练中使用fp16精度。
no_half_vae = true
#Stable Diffusion XL Base U-Net在训练时的最小时间步长(默认为0)。
min_timestep = 0
#Stable Diffusion XL Base U-Net在训练时的最大时间步长(默认为1000)。
max_timestep = 1000
#当设置为true时,对训练标签进行打乱,能一定程度提高模型的泛化性。
shuffle_caption = false
2. [model_arguments]
#读取本地Stable Diffusion XL预训练模型用于微调。
pretrained_model_name_or_path = "/本地路径/SDXL模型文件"
#读取本地VAE模型,如果不传入本参数,在训练中则会读取Stable Diffusion XL自带的VAE模型。
vae = "/本地路径/VAE模型文件"
3. [dataset_arguments]
#训练时对数据进行debug处理,不让破损数据中断训练进程。
debug_dataset = false
#读取数据集json文件,json文件中包含了数据名称,数据标签,数据分桶等信息。
in_json = "/本地路径/data_meta_lat.json"
#读取本地数据集存放路径。
train_data_dir = "/本地路径/训练集"
#整个数据集重复训练的次数。(经验分享:如果数据量级小于一千,可以设置为10;如果数据量级在一千与一万之前,可以设置为5;如果数据量级大于一万,可以设置为2)
dataset_repeats = 10
#在训练过程中,会将txt中的tag进行随机打乱。如果将keep tokens设置为n,那前n个token的顺序在训练过程中将不会被打乱。
keep_tokens = 0
#设置训练时的数据输入分辨率,分别是width和height。
resolution = "1024,1024"
#针对一个数据丢弃全部标签的概率,默认为0。
caption_dropout_rate = 0
#针对一个数据丢弃部分标签的概率,默认为0。(类似于传统深度学习的Dropout逻辑)
caption_tag_dropout_rate = 0
#每训练n个epoch,将数据标签全部丢弃。
caption_dropout_every_n_epochs = 0
#数据颜色增强,建议不启用,其与caching latents不兼容,若启用会导致训练时间大大增加。
color_aug = false
#在训练一开始学习每个数据的前n个tag(标签用逗号分隔后的前n个tag,比如girl,boy,good)
token_warmup_min = 1
#训练中学习标签数达到最大值所需的步数,默认为0,即一开始就能学习全部的标签。
token_warmup_step = 0
4.[training_arguments]
#模型保存的路径。
output_dir = "/本地路径/模型权重保存地址"
#模型名称。
output_name = "sdxl_finetune_qclineart"
#模型保存的精度,一共有[“None”, "float", "fp16", "bf16"]四种选择,默认为“None”,即FP32精度。
save_precision = "fp16"
#每n个steps保存一次模型权重。
save_every_n_steps = 1000
#训练Batch-Size,与传统深度学习一致。
train_batch_size = 4
#设置Text Encoder最大的Token数,有[None, 150, 225]三种选择,默认为“None”,即75。
max_token_length = 225
#对CrossAttention模块进行轻量化,能够一定程度上加速模型训练并降低显存占用,开启mem_eff_attn后xformers失效。
mem_eff_attn = false
#xformers插件可以使SDXL模型在训练时显存减少一半左右。
xformers = true
#训练的总步数。
max_train_steps = 100000
#数据加载的DataLoader worker数量,默认为8。
max_data_loader_n_workers = 8
#能够让DataLoader worker持续挂载,减少训练中每个epoch之间的数据读取时间,但是会增加内存消耗。
persistent_data_loader_workers = true
#设为true时开启梯度检查,通过以更长的计算时间为代价,换取更少的显存占用。相比于原本需要存储所有中间变量以供反向传播使用,使用了checkpoint的部分不存储中间变量而是在反向传播过程中重新计算这些中间变量。模型中的任何部分都可以使用gradient checkpoint。
gradient_checkpointing = true
#如果显存不足,我们可以使用梯度累积步数,默认为1。
gradient_accumulation_steps = 1
#训练中是否使用混合精度,一共有["no", "fp16", "bf16"]三种选择,默认为“no”。
mixed_precision = "fp16"
5. [logging_arguments]
#选择训练log保存的格式,可以从["tensorboard", "wandb", "all"]三者中选择,也可以不设置。
log_with = "tensorboard"
#设置训练log保存的路径。
logging_dir = "/本地路径/logs"
#增加log文件的文件名前缀,比如sdxl_finetune_qclineart1234567890。
log_prefix = "sdxl_finetune_qclineart"
6. [sample_prompt_arguments]
#在训练中每n步测试一次模型效果。
sample_every_n_steps = 100
#设置训练中测试模型效果时使用的sampler,可以选择["ddim","pndm","lms","euler","euler_a","heun","dpm_2","dpm_2_a","dpmsolver","dpmsolver++","dpmsingle", "k_lms","k_euler","k_euler_a","k_dpm_2","k_dpm_2_a"],默认是“ddim”。
sample_sampler = "euler_a"
7. [saving_arguments]
#每次模型权重保存时的格式,可以选择["ckpt", "safetensors", "diffusers", "diffusers_safetensors"],目前SD WebUI兼容"ckpt"和"safetensors"格式模型。
save_model_as = "safetensors"
8. [optimizer_arguments]
#AdamW (default),Lion, SGDNesterov,AdaFactor等。
optimizer_type = "AdaFactor"
#训练学习率,单卡推荐设置2e-6,多卡推荐设置1e-7。
learning_rate = 1e-7
#是否训练时微调Text Encoder。
train_text_encoder = false
#最大梯度范数,0表示没有clip。
max_grad_norm = 0
#设置优化器额外的参数,比如"weight_decay=0.01 betas=0.9,0.999 ..."。
optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False",]
#设置学习率调度策略,可以设置成linear, cosine, cosine_with_restarts, polynomial, constant (default), constant_with_warmup, adafactor等。
lr_scheduler = "constant_with_warmup"
#在启动学习率调度策略前,先固定学习率训练的步数。
lr_warmup_steps = 100
2.1.2 sample_prompt.toml
主要作用是在训练中阶段性验证模型的性能,里面包含了模型生成验证图片的相关参数:
[prompt]
width = 1024
height = 1024
scale = 7
sample_steps = 28
[[prompt.subset]]
prompt = "1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, shirt, short hair, simple background, solo, upper body, yellow shirt"
(3) SDXL关键参数详解
- 1. pretrained_model_name_or_path对SDXL模型微调训练的影响
pretrained_model_name_or_path:我们需要加载本地的SDXL模型作为训练底模型。
在SDXL全参数微调训练中,底模型的选择可以说是最为重要的一环。我们需要挑选一个生成能力分布与训练数据分布近似的SDXL模型作为训练底模型(比如说我们训练二次元人物数据集,可以选择生成二次元图片能力强的SDXL模型)。SDXL在微调训练的过程中,在原有底模型的很多能力与概念上持续扩展优化学习,从而得到底模型与数据集分布的一个综合能力。
- 2. xformers加速库对SDXL模型微调训练的影响
当我们将xformers设置为true时,使用xformers加速库能对SDXL训练起到2倍左右的加速,因为其能使得训练显存占用降低2倍,这样我们就能增大我们的Batch Size数。
想要启动xformers加速库,需要先安装xformers库源,这也非常简单,我们只需要在命令行输入如下命令即可:
pip install xformers -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
- 3. learning_rate对SDXL模型微调训练的影响
SDXL训练过程对学习率的设置非常敏感,如果我们将学习率设置的过大,很有可能导致SDXL模型训练跑飞,在前向推理时生成非常差的图片;如果我们将学习率设置的过小,可能会导致模型无法跳出极小值点。
这里总结了相关的SDXL学习率设置经验,分享给大家。如果我们总的Batch Size(单卡Batch Size x GPU数)小于10,可以设置学习率2e-6;如果我们总的Batch Size大于10小于100,可以设置学习率1e-7。
- 4. 使用save_state和resume对SDXL模型训练的中断重启
在AI绘画领域,很多时候我们需要进行大规模数据的训练优化,数据量级在10万甚至100万以上,这时候整个训练周期需要一周甚至一个月,训练中可能会出现一些通讯/NCCL超时等问题,导致训练中断。
经典NCCL超时问题如下所示:
[E ProcessGroupNCCL.cpp:828] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(SeqNum=213, OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1809831 milliseconds before timing out.
这些训练中断问题会导致我们的训练成本大大增加,为了解决这个问题,我们可以在config_file.toml中设置save_state = true,这样我们在训练模型时不单单保存模型权重,还会保存相关的optimizer states等训练状态。
接着,我们在config_file.toml中设置resume = “/本地路径/模型权重保存地址”,重新运行SDXL训练脚本,这时会直接调取训练中断前的模型权重与训练状态,接着继续训练。
(4) SDXL模型开始训练
完成训练参数配置后,我们就可以运行训练脚本进行SDXL模型的全参微调训练了。
2.4 基于SDXL训练LoRA模型
目前Stable Diffusion XL全参微调的训练成本是Stable Diffusion之前系列的2-3倍左右,而基于Stable Diffusion XL训练LoRA的成本与之前的系列相比并没有太多增加,故训练LoRA依旧是持续繁荣SDXL生态的高效选择。
(1) SDXL LoRA数据集制作
SDXL LoRA训练数据集筛选要求和SDXL微调不一样:
- 当我们训练人物主题时,一般需要10-20张高质量数据;- 当我们训练画风主题时,需要100-200张高质量数据;当我们训练抽象概念时,则至少需要200张以上的数据。
- 不管是人物主题,画风主题还是抽象概念,一定要保证数据集中数据的多样性(比如说猫女姿态,角度,全身半身的多样性)。
- 每个数据都要符合我们的审美和评判标准!每个数据都要符合我们的审美和评判标准!每个数据都要符合我们的审美和评判标准。
按照本文4.3 Stable Diffusion XL数据集制作章节里的步骤,进行数据的清洗,自动标注,以及添加特殊tag——即触发词。
除了对数据进行标注,我们还需要对数据的标注进行清洗,删除一些概念与触发词重合的标签. 为什么我们要进行数据标注的清洗呢?因为如果不对标注进行清洗,会导致训练时的tag污染。
我们拿猫女数据集为例,我们想要让SDXL LoRA模型学习猫女的主要特征,包括脸部特征,服装特征(最具猫女特点的黑色皮衣和黑色眼罩)等,我们想让“catwomen”学习到这些特征。但是自动标注会给数据打上一些描述脸部特征和服装特征的tag,导致猫女的主要特征被这些tag分走,从而导致tag污染。这样就会导致很多精细化的特征丢失在自动标注的tag中,使得SDXL LoRA在生成猫女图片时缺失黑色皮衣或者黑色眼罩等。
所以我们需要删除自动标注的脸部,服装等tag,从而使得保留下来的触发词等标签是SDXL LoRA模型着重需要学习的。
一张一张手动删除标签费时费力,这里推荐大家使用Stable Diffusion WebUI的一个数据标注处理插件:stable-diffusion-webui-dataset-tag-editor,可以对标签进行批量处理,非常方便。
(2) SDXL LoRA训练参数配置
大家可以在SDXL-Trian项目中train_config/XL_LoRA_config路径下找到SDXL LoRA的训练参数配置文件config_file.toml和sample_prompt.toml,他们分别存储着SDXL_LoRA的训练超参数与训练中的验证prompt信息。
其中config_file.toml文件中的配置文件包含了sdxl_arguments,model_arguments,dataset_arguments,training_arguments,logging_arguments,sample_prompt_arguments,saving_arguments,optimizer_arguments以及additional_network_arguments九个个维度的参数信息。
训练SDXL_LoRA的参数配置与SDXL全参微调的训练配置有相同的部分(上述的前八个维度),也有LoRA的特定参数需要配置(additional_network_arguments)。
下面我们首先看看这些共同的维度中,有哪些需要注意的事项吧:
2.1 训练参数讲解(XL_LoRA_config文件夹)
2.1.1 config_file.toml
1. [sdxl_arguments] # 与SDXL全参微调训练一致
cache_text_encoder_outputs = true
no_half_vae = true
min_timestep = 0
max_timestep = 1000
shuffle_caption = false
2. [model_arguments] # 与SDXL全参微调训练一致
pretrained_model_name_or_path = "/本地路径/SDXL模型文件"
# 如果只使用模型自带的VAE,不读取额外的VAE模型,则需要将本行直接删除
vae = "/本地路径/VAE模型文件"
3. [dataset_arguments] # 与SDXL全参微调训练不一致
#LoRA训练过程中取消了caption_dropout_rate = 0,caption_tag_dropout_rate = 0,
#caption_dropout_every_n_epochs = 0这三个参数,因为本身LoRA的模型容量较小,不需要再进行类标签Dropout的操作了。
debug_dataset = false
in_json = "/本地路径/data_meta_lat.json"
train_data_dir = "/本地路径/训练集"
dataset_repeats = 1
keep_tokens = 0
resolution = "1024,1024"
color_aug = false
token_warmup_min = 1
token_warmup_step = 0
4. [training_arguments] # 与SDXL全参微调训练不一致
#SDXL_LoRA增加了sdpa参数,当其设置为true时,训练中启动scaled dot-product attention优化,
#这时候就不需要再开启xformers了
output_dir = "/本地路径/模型权重保存地址"
output_name = "sdxl_lora_qclineart"
save_precision = "fp16"
save_every_n_epochs = 1
train_batch_size = 4
max_token_length = 225
mem_eff_attn = false
sdpa = true
xformers = false
max_train_epochs = 100 #max_train_epochs设置后,会覆盖掉max_train_steps,即两者同时存在时,以max_train_epochs为准
max_data_loader_n_workers = 8
persistent_data_loader_workers = true
gradient_checkpointing = true
gradient_accumulation_steps = 1
mixed_precision = "fp16"
5. [logging_arguments] # 与SDXL全参微调训练一致
log_with = "tensorboard"
logging_dir = "/本地路径/logs"
log_prefix = "sdxl_lora_qclineart"
6. [sample_prompt_arguments] # 与SDXL全参微调训练一致
sample_every_n_epochs = 1
sample_sampler = "euler_a"
7. [saving_arguments] # 与SDXL全参微调训练一致
save_model_as = "safetensors"
8. [optimizer_arguments] # 与SDXL全参微调训练不一致
optimizer_type = "AdaFactor"
learning_rate = 1e-5 # 训练SDXL_LoRA时,学习率可以调的大一些,一般比SDXL全参微调的学习率大10倍左右,比如learning_rate = 1e-5
max_grad_norm = 0
optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False",]
lr_scheduler = "constant_with_warmup"
lr_warmup_steps = 100
除了上面的参数,训练SDXL_LoRA时还需要设置一些专属参数,这些参数非常关键:
9. [additional_network_arguments]
#保存模型权重时不附带Metadata数据,建议关闭,能够减少保存下来的LoRA大小。
no_metadata = false
#选择训练的LoRA模型结构,可以从["networks.lora", "networks.dylora", "lycoris.kohya"]中选择,最常用的LoRA结构默认选择"networks.lora"。
network_module = "networks.lora"
#设置LoRA的RANK,设置的数值越大表示表现力越强,但同时需要更多的显存和时间来训练。
network_dim = 32
#设置缩放权重,用于防止下溢并稳定训练的alpha值。
network_alpha = 16
#置卷积的Rank与缩放权重。
network_args = [ "conv_dim=32", "conv_alpha=16",]
#如果设置为true,那么只训练U-Net部分。
network_train_unet_only = true
下面表格中给出一些默认配置,大家可以作为参考:
| network_category | network_dim | network_alpha | conv_dim | conv_alpha |
|---|---|---|---|---|
| LoRA | 32 | 1 | - | - |
| LoCon | 16 | 8 | 8 | 1 |
| LoHa | 8 | 4 | 4 | 1 |
如果我们想要训练LoRA,我们需要设置network_module = “networks.lora”,同时设置network_dim和network_alpha,和上面的配置一致。
如果我们想要训练LoCon,我们需要设置network_module = "lycoris.kohya"和algo=“locon”,同时设置network_dim和network_alpha:
network_module = "lycoris.kohya"
algo = "locon"
network_dim = 32
network_alpha = 16
network_args = [ "conv_dim=32", "conv_alpha=16",]
如果我们想要训练LoHa,我们需要设置network_module = "lycoris.kohya"和algo=“loha”,同时设置network_dim和network_alpha:
network_module = "lycoris.kohya"
algo = "loha"
network_dim = 32
network_alpha = 16
network_args = [ "conv_dim=32", "conv_alpha=16",]
(3) SDXL LoRA关键参数详解
- 1. train_batch_size对SDXL LoRA模型训练的影响
和传统深度学习一样,train_batch_size即为训练时的batch size,表示一次性送入SDXL LoRA模型进行训练的图片数量。一个Epoch表示模型完整地遍历一次整个训练数据集
所以一般来说,较大的batch size往往每个epoch训练时间更短,但是显存占用会更大,并且收敛得慢(需要更多epoch数)。较小的batch size每个epoch训练时间长,但是显存占用会更小,并且收敛得快(需要更少epoch数)。
但是有研究表明这个结论会在batch size大于8000的时候才会体现,所以在实际的训练时,如果GPU数不大于8卡的话,还是需要尽可能占满GPU显存为宜,比如64-96之间(理论上batch size = 2 n 2^n 2n 时计算效率较高),训练一般都能取得不错效果。
上面的结论在训练SDXL大模型时是非常适用的,不过我们在训练SDXL LoRA模型时,一般来说数据量级是比较小的(10-300为主),所以在这种情况下,我们可以设置batch size为2-6即可。
- 2. pretrained_model_name_or_path对SDXL LoRA模型训练的影响
pretrained_model_name_or_path参数中我们需要加载本地的SDXL模型作为训练底模型。
底模型的选择至关重要,SDXL LoRA的很多底层能力与基础概念的学习都来自于底模型的能力。并且底模型的优秀能力需要与我们训练的主题,比如说人物,画风或者某个抽象概念相适配。如果我们要训练二次元LoRA,则需要选择二次元底模型,如果我们要训练三次元LoRA,则需要选择三次元底模型,以此类推。
- 3. network_dim对SDXL LoRA模型训练的影响
network_dim即特征维度,越高表示模型的参数量越大,设置高维度有助于LoRA学习到更多细节特征,但模型收敛速度变慢,同时也更容易过拟合,需要的训练时间更长。所以network_dim的设置需要根据任务主题去调整。
一般来说,在SDXL的1024*1024分辨率训练基础上,可以设置network_dimension = 128,此时SDXL LoRA大小约为686MB。
- 4. network_alpha对SDXL LoRA模型训练的影响
network_alpha是一个缩放因子,用于缩放模型的训练权重 W W W, W = W i n × a l p h a / d i m W = W_{in} \times alpha / dim W=Win×alpha/dim
。network_alpha设置的越高,LoRA模型能够学习更多的细节信息,同时学习速率也越快,推荐将其设置为network_dim的一半。
(4) SDXL LoRA模型训练
完成训练参数配置后,我们就可以运行训练脚本进行SDXL_LoRA模型的训练了。
我们打开SDXL_fintune_LoRA.sh脚本,可以看到以下的代码:
accelerate launch \--config_file accelerate_config.yaml \--num_cpu_threads_per_process=8 \/本地路径/SDXL-Train/sdxl_train_network.py \--sample_prompts="/本地路径/SDXL-Train/train_config/XL_LoRA_config/sample_prompt.toml" \--config_file="/本地路径/SDXL-Train/train_config/XL_LoRA_config/config_file.toml"
我们把训练脚本封装在accelerate库里,这样就能启动我们一开始配置的训练环境了,同时我们将刚才配置好的config_file.toml和sample_prompt.toml参数传入训练脚本中。
接下里,就到了激动人心的时刻,我们只需在命令行输入以下命令,就能开始SDXL_LoRA训练啦:
# 进入SDXL-Trian项目中
cd SDXL-Trian# 运行训练脚本!
sh SDXL_fintune_LoRA.sh
当我们基于SDXL训练SDXL LoRA模型时,我们设置分辨率为1024+FP16精度+xformers加速时,进行Batch Size = 1的微调训练需要约13.3G的显存,进行Batch Size=8的微调训练需要约18.4G的显存,所以想要微调训练SDXL LoRA模型,最好配置一个16G以上的显卡,能让我们更佳从容地进行训练。
感谢
https://zhuanlan.zhihu.com/p/643420260
相关文章:
Stable Diffusion XL之使用Stable Diffusion XL训练自己的AI绘画模型
文章目录 一 SDXL训练基本步骤二 从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型2.1 配置训练环境与训练文件2.2 SDXL训练数据集制作(1) 数据筛选与清洗(2) 使用BLIP自动标注caption(3) 使用Waifu Diffusion 1.4自动标注tag(4) 补充标注特殊tag(5) 训练数据预处理(标注…...
软件杯 深度学习 机器视觉 人脸识别系统 - opencv python
文章目录 0 前言1 机器学习-人脸识别过程人脸检测人脸对其人脸特征向量化人脸识别 2 深度学习-人脸识别过程人脸检测人脸识别Metric Larning 3 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习 机器视觉 人脸识别系统 该项目…...
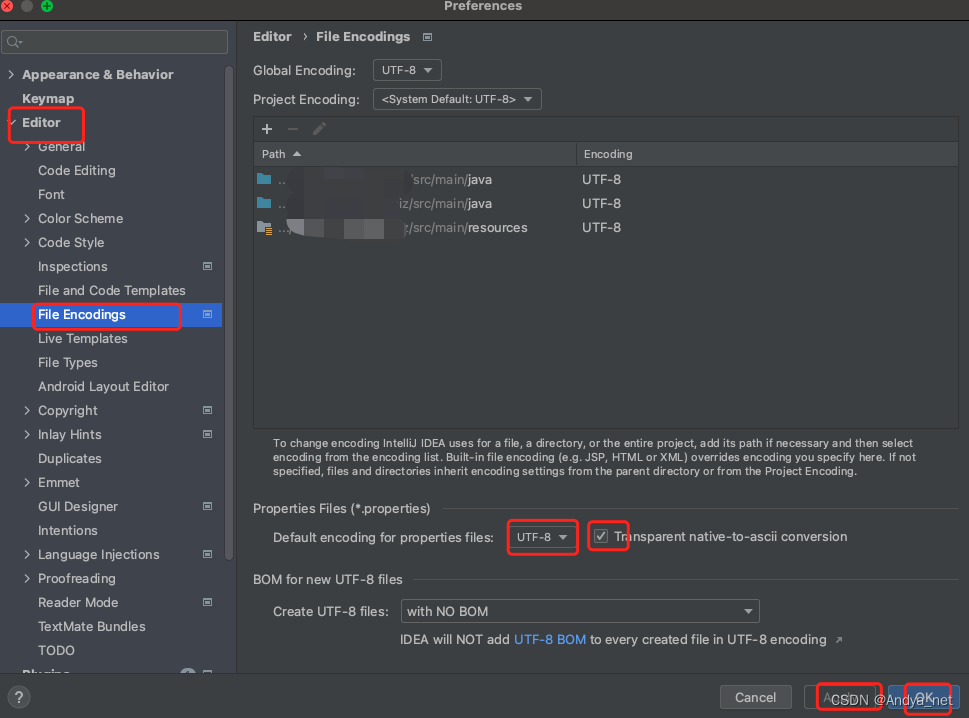
IDEA | 资源文件中文乱码问题解决
问题 IDEA打开资源文件,显示乱码问题。 解决方案 1、电脑是mac,点击IDEA->【Preferences】->【Editor】->【File Encodings】 2、选择【Properties Files】中的UTF-8,并勾选Transparent native-to-ascii conversion。 3、最后点击…...

Linux系统使用Docker部署Portainer结合内网穿透实现远程管理容器和镜像
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
【Git篇】复习git
文章目录 🍔什么是git⭐git和svn的区别 🍔搭建本地仓库🍔克隆远程仓库🛸git常用命令 🍔什么是git Git是一种分布式版本控制系统,它可以追踪文件的变化、协调多人在同一个项目上的工作、恢复文件的旧版本等…...

[LitCTF 2023]程序和人有一个能跑就行了
新知识 seh 表面上的逻辑蛮简单的 int __cdecl main(int argc, const char **argv, const char **envp) {_DWORD *v3; // eax_DWORD *v5; // eaxchar *v6; // eaxint v7; // [esp0h] [ebp-2ACh] BYREFint v8; // [esp14h] [ebp-298h]int *v9; // [esp18h] [ebp-294h]int v10;…...
如何在群晖NAS搭建bitwarden密码管理软件并实现无公网IP远程访问
前言 作者简介: 懒大王敲代码,计算机专业应届生 今天给大家聊聊如何在群晖NAS搭建bitwarden密码管理软件并实现无公网IP远程访问,希望大家能觉得实用! 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖&am…...

perl:获取同花顺数据--业绩快报,业绩公告
perldoc LWP::UserAgent 如果没有安装,则安装模块,运行 cpanm LWP::UserAgent 。 编写 get_yjkb_10jqka.pl 如下 #!/usr/bin/perl # perl 获取同花顺数据--业绩快报 use LWP::UserAgent; use Encode qw(decode encode); use POSIX; use Data::Dump…...

FPGA选型
开发FPGA的第一步,就是选择一片符合设计需求的芯片。 专用资源 选片第一个关注的应该是FPGA器件的专用资源。例如是否需要高速接口,如果需要的话,需要多少个通道,各个通道需要的最高收发速度是多少。同样,如果需要实…...

centos系统的root密码忘记或失效的解决办法(超详细)
文章目录 1、概述2、现象描述3、解决步骤3.1 进入单机维护模式3.2 修改启动参数3.3 在维护模式下修改密码3.4 重启 4、总结 1、概述 在Linux系统中,root用户是最高权限的用户,可以执行任何命令和操作。但是,如果我们忘记了root用户的密码&…...

【Android 源码】Android源码下载指南
文章目录 前言安装Repo初始化Repo选择分支没有梯子替换为清华源 有梯子 下载源码下载开始参考 前言 这是关于Android源码下载的过程记录。 环境:Windows上通过VMware安装的Ubuntu系统 安装Repo 创建Repo文件目录 mkdir ~/bin PATH~/bin:$PATH下载Repo工具&#…...
MySQL数据库高级语句
文章目录 MySQL高级语句older by 排序区间判断查询或与且(or 与and)嵌套查询(多条件)查询不重复记录distinctcount 计数限制结果条目limit别名as常用通配符嵌套查询(子查询)同表不同表嵌套查询还能用于删除…...
软件测试【理论基础】
软件测试的IEEE定义:使用人工或自动的手段来运行或测量软件系统的过程,目的是检验软件系统是否满足规定的需求,并找出与预期结果之间的差异。 软件测试的发展趋势: ① 测试工作将进一步前移。软件测试不仅仅是单元测试、集成测试、系统测试…...

蓝桥杯每日一题(floyd算法)
4074 铁路与公路 如果两个城市之间有铁路t11,公路就会t2>1,没铁路的时候t1>1,公路t21。也就是公路铁路永远都不会相等。我们只需要计算通过公路和铁路从1到n最大的那个即可。 floyd是直接在数组上更新距离。不需要新建dis数组。另外一定要记得把邻接矩阵初始…...

文心一言 VS 讯飞星火 VS chatgpt (224)-- 算法导论16.3 6题
六、假定我们有字母表 C{0,1,…,n-1} 上的一个最优前缀码,我们希望用最少的二进制位传输此编码。说明如何仅用 2n-1n⌈lgn⌉ 位表示 C 上的任意最优前缀码。(提示:通过对树的遍历,用 2n-1 位说明编码树的结…...

flutter3_douyin:基于flutter3+dart3短视频直播实例|Flutter3.x仿抖音
flutter3-dylive 跨平台仿抖音短视频直播app实战项目。 全新原创基于flutter3.19.2dart3.3.0getx等技术开发仿抖音app实战项目。实现了类似抖音整屏丝滑式上下滑动视频、左右滑动切换页面模块,直播间进场/礼物动效,聊天等模块。 运用技术 编辑器&#x…...

VR全景赋能智慧农业,打造沉浸式种植体验平台
随着人口的增长,传统农业也正在面临着不一样的挑战,加上很多人对农业的固有印象,很少有年轻人愿意下到农田里,那么该如何提高产量、降低成本以及引导年轻人深刻感受现代农业成为了急需解决的问题。 随着城市化脚步的推进ÿ…...
百度文心一言(ERNIE bot)API接入Android应用
百度文心一言(ERNIE bot)API接入Android应用实践 - 拾一贰叁 - 博客园 (cnblogs.com) Preface: 现在生成式AI越来越强大了,想在android上实现一个对话助手的功能,大概摸索了一下接入百度文心一言API的方法。 与AI助手交换信息的…...
)
springboot基本使用八(mbatisplus+filter实现登录功能)
mybatisplus依赖: <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version> </dependency> mysql依赖: <dependency><groupId>com.mysql<…...

蚂蚁庄园今天答案
蚂蚁庄园是一款爱心公益游戏,用户可以通过喂养小鸡,产生鸡蛋,并通过捐赠鸡蛋参与公益项目。用户每日完成答题就可以领取鸡饲料,使用鸡饲料喂鸡之后,会可以获得鸡蛋,可以通过鸡蛋来进行爱心捐赠。其中&#…...

Phi-3-mini-128k-instruct快速部署:Anaconda环境配置与模型调用详解
Phi-3-mini-128k-instruct快速部署:Anaconda环境配置与模型调用详解 你是不是也遇到过这种情况:看到一个很酷的AI模型,想赶紧试试,结果被各种环境依赖、版本冲突搞得头大?别担心,今天咱们就来搞定Phi-3-mi…...
)
【课后习题答案】SystemVerilog for Verification 3rd Edition第五章(绿皮书第三版)
1 解答class MemTrans;// a. 8位logic类型的data_inlogic [7:0] data_in;// b. 4位logic类型的addresslogic [3:0] address;// c. 打印data_in和address的void函数function void print();$display("data_in 0x%h, address 0x%h", data_in, address);endfunction// …...

Easypoi导出Excel时,如何优雅地处理‘未知’或‘空值’?一个replace动态替换的实战技巧
Easypoi动态替换Excel导出中的未知值与空值:实战技巧与最佳实践 在数据导出场景中,我们经常遇到数据库枚举值与Excel展示不匹配的问题。比如性别字段,除了标准的"男"、"女"外,还可能存在空值或超出预设范围的…...

Mac用户的移动Win10工坊:从WTG配置到驱动、激活、文件共享的完整避坑指南
Mac用户的移动Win10工坊:从WTG配置到驱动、激活、文件共享的完整避坑指南 当Mac用户需要运行Windows应用时,双系统方案往往是最佳选择。而通过Windows To Go(WTG)技术将Win10安装在移动硬盘上,不仅保留了Mac原生系统的…...

为什么小数据集上神经网络会突然‘开窍‘?揭秘Grokking现象背后的LU机制
为什么小数据集上神经网络会突然"开窍"?揭秘Grokking现象背后的LU机制 在机器学习实践中,我们常常观察到一种反直觉的现象:当神经网络在小规模算法数据集上训练时,测试准确率会在长时间停滞于随机猜测水平后突然跃升至接…...

OFA视觉问答模型惊艳效果:复杂背景中主物体识别与属性描述能力
OFA视觉问答模型惊艳效果:复杂背景中主物体识别与属性描述能力 1. 模型效果惊艳展示 OFA视觉问答模型在复杂场景中的表现令人印象深刻。这个模型能够准确识别图片中的主要物体,并详细描述其属性特征,就像有一个专业的图像分析师在为你解读图…...

OFA视觉蕴含模型效果展示:抽象艺术作品与评论文本关联性
OFA视觉蕴含模型效果展示:抽象艺术作品与评论文本关联性 1. 引言:当抽象艺术遇见智能理解 想象一下这样的场景:你站在一幅抽象画前,画布上是狂放的笔触和难以名状的色彩组合。旁边有人评论说:"这幅画表达了宇宙…...

手把手教你:5分钟为你的静态网站嵌入AnythingLLM智能聊天机器人
5分钟为静态网站集成AnythingLLM智能聊天室的实战指南 你是否想过在自己的个人博客或产品官网上添加一个能回答访客问题的AI助手?就像那些科技公司官网右下角弹出的智能客服一样。今天我要分享的,是如何用AnythingLLM在5分钟内为任何静态网站嵌入一个私有…...

Cursor API限制突破架构设计与系统实现方案
Cursor API限制突破架构设计与系统实现方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial request limit. / T…...

别只改.prettierrc了!从Git配置到CI/CD,一劳永逸解决团队换行符冲突
从Git配置到CI/CD:彻底解决团队协作中的换行符冲突 跨平台协作开发时,换行符问题就像鞋里的一粒沙子——看似微不足道,却能让整个团队步履维艰。当Windows的CRLF遇上Unix的LF,不仅会导致Prettier报出恼人的Delete ␍错误ÿ…...