TrOCR—基于Transformer的OCR入门
导 读
本文主要介绍TrOCR:基于Transformer的OCR入门。
背景介绍
多年来,光学字符识别 (OCR) 出现了多项创新。它对零售、医疗保健、银行和许多其他行业的影响是巨大的。尽管有着悠久的历史和多种最先进的模型,研究人员仍在不断创新。与深度学习的许多其他领域一样,OCR 也看到了变压器神经网络的重要性和影响。如今,我们拥有像TrOCR(Transformer OCR)这样的模型,它在准确性方面真正超越了以前的技术。

在本文中,我们将介绍 TrOCR 并重点关注四个主题:
-
-
TrOCR的架构是怎样的?
-
TrOCR 系列包括哪些型号?
-
TrOCR 模型是如何预训练的?
-
如何使用 TrOCR 和 Hugging Face 进行推理?
-
如果您经常使用 OCR,本文将帮助您在自己的项目中轻松使用 TrOCR。
TrOCR架构
TrOCR 由 Li 等人提出。在论文 TrOCR:基于 Transformer 的光学字符识别与预训练模型中。
作者提出了一种摆脱OCR传统CNN和 RNN 架构的方法。相反,他们使用视觉和语言转换器模型来构建 TrOCR 架构。
TrOCR 模型由两个阶段组成:
-
-
编码器阶段由预训练的视觉变换器模型组成。
-
解码器阶段由预训练的语言转换器模型组成。
-
由于其高效的预训练,基于 Transformer 的模型在下游任务上表现非常出色。为此,作者选择 DeIT 作为视觉 Transformer 模型。对于解码器阶段,他们根据 TrOCR 变体选择了 RoBERTa 或 UniLM 模型。
下图显示了使用 TrOCR 的简单 OCR 管道。
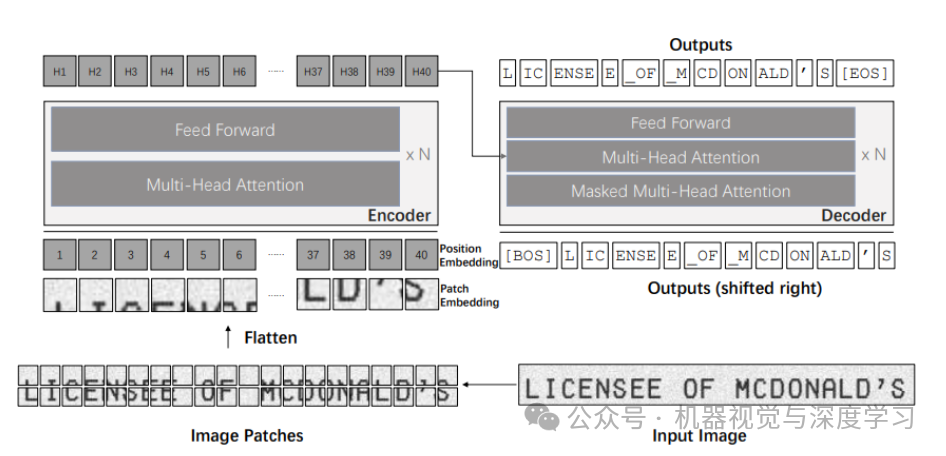
在上图中,左侧块显示视觉变换器编码器,右侧块显示语言变换器解码器。以下是 TrOCR 推理阶段的简单分解:
-
-
首先,我们将图像输入到 TrOCR 模型,该模型通过图像编码器。
-
图像被分解成小块,然后通过多头注意力块。前馈块产生图像嵌入。
-
然后这些嵌入进入语言转换器模型。
-
语言转换器模型的解码器部分产生编码输出。
-
最后,我们对编码输出进行解码以获得图像中的文本。
-
需要注意的一件事是,在进入视觉转换器模型之前,图像的大小已调整为 384×384 分辨率。这是因为 DeIT 模型期望图像具有特定的尺寸。
当然,多头注意力、编码器和解码器涉及多个组件。但是,这些超出了本文的范围。
TrOCR系列模型
TrOCR 模型系列包括多个预训练和微调的模型。
TrOCR 预训练模型
TrOCR 系列中的预训练模型称为第一阶段模型。这些模型是根据大规模综合生成的数据进行训练的。该数据集包括数亿张打印文本行的图像。
官方存储库包括预训练阶段的三个尺度的模型。它们是(参数数量不断增加):
-
-
TrOCR-Small-Stage1
-
TrOCR-Base-Stage1
-
TrOCR-Large-Stage1
-
毫无疑问,Large 模型表现最好,但也是最慢的。
TrOCR 微调模型
预训练阶段结束后,模型在 IAM 手写文本图像和 SROIE 打印收据数据集上进行了微调。
IAM 手写数据集包含手写文本的图像。微调该数据集使模型比其他模型更好地识别手写文本。
同样,SROIE 数据集由数千个收据图像样本组成。在此数据集上微调的模型在识别印刷文本方面表现非常好。
就像预训练阶段模型一样,手写模型和打印模型也分别包含三个尺度:
-
-
TrOCR-Small-IAM
-
TrOCR-Base-IAM
-
TrOCR-Large-IAM
-
TrOCR-Small-SROIE
-
TrOCR-Base-SROIE
-
TrOCR-Large-SROIE
-
TrOCR 的理论和架构讨论到此结束。我们现在将继续使用 TrOCR 进行推理。
使用TrOCR模型推理
Hugging Face 托管从预训练到微调阶段的所有 TrOCR 模型。
我们将使用两种模型,一种是手写的微调模型,一种是打印的微调模型来运行推理实验。
在《Hugging Face》中,模型的命名遵循trocr-<model_scale>-<training_stage>惯例。
例如,在 IAM 手写数据集上训练的 TrOCR 小模型称为trocr-small-handwritten。
接下来,我们将使用trocr-small-printed和trocr-base-handwritten模型进行推理。
以下部分中介绍的代码位于 Jupyter Notebook 中。
安装要求、导入和设置计算设备
要使用 Hugging Face 和 TrOCR 进行推理,我们需要安装两个必需的库:Hugging Face transformers、sentencepiecetokenizer 。
!pip install -q transformers!pip install -q -U sentencepiece
导入需要的包:
from transformers import TrOCRProcessor, VisionEncoderDecoderModelfrom PIL import Imagefrom tqdm.auto import tqdmfrom urllib.request import urlretrievefrom zipfile import ZipFileimport numpy as npimport matplotlib.pyplot as pltimport torchimport osimport glob
综上所述,我们需要下载urllib并zipfile提取推理数据。
前向传递将使用 GPU 或 CPU 设备,具体取决于可用性。
device = torch.device('cuda:0' if torch.cuda.is_available else 'cpu')辅助函数
以下代码行包含一个用于下载和提取数据集的简单函数。
def download_and_unzip(url, save_path):print(f"Downloading and extracting assets....", end="")# Downloading zip file using urllib package.urlretrieve(url, save_path)try:# Extracting zip file using the zipfile package.with ZipFile(save_path) as z:# Extract ZIP file contents in the same directory.z.extractall(os.path.split(save_path)[0])print("Done")except Exception as e:print("\nInvalid file.", e)URL = r"https://www.dropbox.com/scl/fi/jz74me0vc118akmv5nuzy/images.zip?rlkey=54flzvhh9xxh45czb1c8n3fp3&dl=1"asset_zip_path = os.path.join(os.getcwd(), "images.zip")# Download if assest ZIP does not exists.if not os.path.exists(asset_zip_path):download_and_unzip(URL, asset_zip_path)
上面的代码将下载包括以下内容的图像:
-
-
从旧报纸上打印文本图像,以使用打印模型进行推理。
-
手写文本图像,使用手写文本微调模型进行推理。
-
野外弯曲文本图像以测试 TrOCR 模型的局限性。
-
接下来,我们有一个简单的函数来读取 PIL 格式的图像并将其返回以供下一个处理阶段使用。
def read_image(image_path):""":param image_path: String, path to the input image.Returns:image: PIL Image."""image = Image.open(image_path).convert('RGB')return image
该read_image()函数只需要一个图像路径并以 RGB 颜色格式返回它。
我们还编写一个辅助函数来执行 OCR 管道。
def ocr(image, processor, model):""":param image: PIL Image.:param processor: Huggingface OCR processor.:param model: Huggingface OCR model.Returns:generated_text: the OCR'd text string."""# We can directly perform OCR on cropped images.pixel_values = processor(image, return_tensors='pt').pixel_values.to(device)generated_ids = model.generate(pixel_values)generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]return generated_text
我们需要在这里关注一些事情。这些ocr()函数需要三个参数:
-
-
image:这是RGB颜色格式的PIL图像。
-
processor:Hugging Face OCR 管道需要 OCR 处理器首先将图像转换为适当的格式。我们将在初始化模型时详细讨论这一点。
-
model:这是 Hugging Face OCR 模型,它接受预处理图像并给出编码输出。
-
在 return 语句之前,您可能会注意到batch_decode()处理器的功能。这实质上是将模型生成的编码 ID 转换为输出文本。表示skip_special_tokens=True我们不希望像句子结尾或句子开头这样的特殊标记成为输出的一部分。
我们的最终辅助函数对新图像进行推理。它结合了前面的功能并在输出单元中显示图像。
def eval_new_data(data_path=None, num_samples=4, model=None):image_paths = glob.glob(data_path)for i, image_path in tqdm(enumerate(image_paths), total=len(image_paths)):if i == num_samples:breakimage = read_image(image_path)text = ocr(image, processor, model)plt.figure(figsize=(7, 4))plt.imshow(image)plt.title(text)plt.axis('off')plt.show()
该eval_new_data()函数接受目录路径、我们要进行推理的样本数量以及模型作为参数。
对印刷文本的推断
让我们加载 TrOCR 处理器和打印文本模型。
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-small-printed')model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-small-printed').to(device)
要加载TrOCR 处理器,我们需要使用 TrOCRProcessor 类的 from_pretrained 模块。这接受 HuggingFace 存储库的字符串路径,其中包含特定模型。
那么,TrOCR 处理器有什么作用呢?
请记住,TrOCR 模型是一个神经网络,无法直接处理图像。在此之前,我们需要将图像处理成适当的格式。TrOCR 处理器首先将图像大小调整为 384×384 分辨率。然后它将图像转换为归一化张量格式,然后进入模型进行推理。我们还可以指定张量的格式。例如,在我们的例子中,我们将张量转换为 pt 格式,这表示 PyToch 张量。如果我们使用 TensorFlow 框架,我们还可以通过提供 tf 来获取 TensorFlow 格式的张量。
同样,我们使用该类VisionEncoderDecoderModel来加载预训练模型。在上面的代码块中,我们加载trocr-small-printed模型,并在加载后将模型传输到设备。接下来,我们调用该eval_new_data()函数开始对从旧报纸上裁剪的图像进行推理。
eval_new_data(data_path=os.path.join('images', 'newspaper', '*'),num_samples=2,model=model)
运行上述代码块会产生以下输出。运行上述代码块会产生以下输出。

图像顶部的文本显示模型的输出。即使图像模糊不清,该模型的性能也非常好。在第一张图像中,模型可以预测所有逗号、句号,甚至连字符。
手写文本推理
对于手写文本推理,我们将使用基本模型(大于小模型)。我们先加载手写的TrOCR处理器和模型。
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-handwritten')model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-handwritten').to(device)
我们的方法遵循印刷文本模型的方法;我们只需更改存储库路径即可访问适当的模型。
为了运行推理,我们需要更改数据目录路径。
eval_new_data(data_path=os.path.join('images', 'handwritten', '*'),num_samples=2,model=model)

这是一个很好的例子,展示了 TrOCR 在手写文本上的表现如何。即使是跑步的手,它也可以正确检测所有字符。

即使使用不同类型的写作风格,模型性能也不会恶化。基于 Transformer 的视觉和语言模型的结合在这里大放异彩。
测试 TrOCR 的极限
尽管 TrOCR 令人印象深刻,但它并不是在所有类型的图像上都表现良好。例如,小型模型很难处理包含弯曲文本或来自广告牌、横幅和服装等自然场景的文本的图像。以下是一些例子。

很明显,该模型无法理解和提取单词STATES,并且预测>如上图所示
这是另一个例子。

在这种情况下,模型可以预测一个单词,但错误。
提高 TrOCR 性能
在上一节中,我们看到 TrOCR 模型在来自野外的图像上可能表现不佳。这些限制来自于视觉转换器和语言转换器模型的能力。需要一个能够看到弯曲文本的视觉转换器和一个能够理解此类文本中不同标记的语言转换器。
最好的方法是在弯曲文本数据集上微调 TrOCR 模型。为了提出解决方案,我们将在下一篇文章中在SCUT-CTW1500数据集上训练 TrOCR 模型。敬请关注!
结论
OCR 自从诞生以来,架构简单,已经取得了长足的进步。如今,TrOCR 为该领域带来了新的可能性。我们首先介绍了 TrOCR,并深入研究了它的架构。接下来,我们介绍了不同的 TrOCR 模型及其训练策略。我们通过推理和分析结果完成了这篇文章。
一个简单而有效的应用程序可以将旧文章和报纸数字化,这些文章和报纸很难手动阅读。
然而,TrOCR 在处理弯曲文本和自然场景中的文本时也有其局限性。我们将在下一篇文章中深入探讨这一点,在弯曲文本数据集上微调 TrOCR 模型并解锁新功能。
相关文章:
TrOCR—基于Transformer的OCR入门
导 读 本文主要介绍TrOCR:基于Transformer的OCR入门。 背景介绍 多年来,光学字符识别 (OCR) 出现了多项创新。它对零售、医疗保健、银行和许多其他行业的影响是巨大的。尽管有着悠久的历史和多种最先进的模型,研究人员仍在不断创新。与深…...
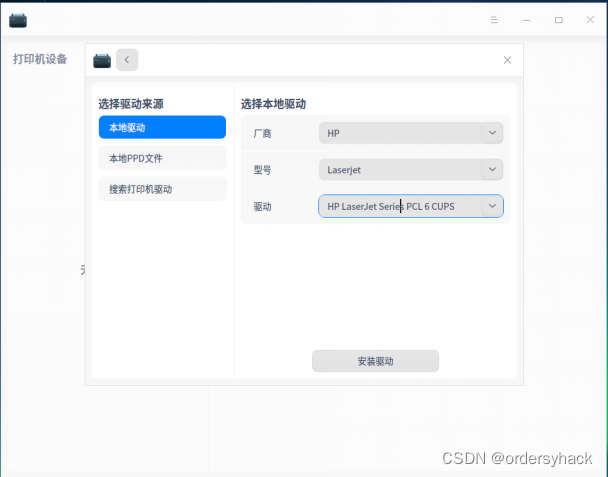
WIN使用LPD协议来共享打印机含统信UOS
打开“控制面板”,“程序和功能”,“启动或关闭Windows功能”,下拉找到“打印和文件服务”,勾选“LPD打印服务”和“LPR端口监视器”。确定之后重启电脑,共享主机和其它需要添加共享打印机的都开启功能和重启。 一、启…...
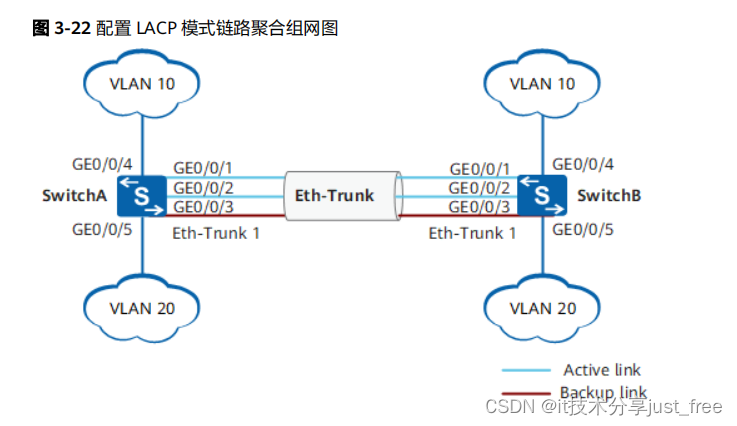
huawei 华为 交换机 配置 LACP 模式的链路聚合示例 (交换机之间直连)
组网需求 如 图 3-22 所示, SwitchA 和 SwitchB 通过以太链路分别都连接 VLAN10 和 VLAN20 的网络,且SwitchA 和 SwitchB 之间有较大的数据流量。用户希望 SwitchA 和 SwitchB 之间能够提供较大的链路带宽来使相同VLAN 间互相通信。在两台 Switch 设备上…...

c++ 有名对象和匿名对象
c 有名对象和匿名对象 有名对象就是有名字的对象,匿名对象就是没有名字的对象。 #define _CRT_SECURE_NO_WARNINGS 1 using namespace std; #include<iostream> class score { public:score(){math 100;chinese 100;english 100;}score(int _math, int _…...

day 36 贪心算法 part05● 435. 无重叠区间 ● 763.划分字母区间 ● 56. 合并区间
一遍过。首先把区间按左端点排序,然后右端点有两种情况。 假设是a区间,b区间。。。这样排列的顺序,那么 假设a[1]>b[0],如果a[1]>b[1],就应该以b[1]为准,否则以a[1]为准。 class Solution { public:static bo…...

【数据结构与算法】快速排序(详解:快排的Hoare原版,挖坑法和双指针法|避免快排最坏时间复杂度的两种解决方案|小区间优化|非递归的快排)
引言 快速排序作为交换排序的一种,在排序界的影响力毋庸置疑,我们C语言中用的qsort,C中用的sort,底层的排序方式都是快速排序。相比于同为交换排序的冒泡,其效率和性能就要差的多了,本篇博客就是要重点介绍…...

三位数组合-第12届蓝桥杯选拔赛Python真题精选
[导读]:超平老师的Scratch蓝桥杯真题解读系列在推出之后,受到了广大老师和家长的好评,非常感谢各位的认可和厚爱。作为回馈,超平老师计划推出《Python蓝桥杯真题解析100讲》,这是解读系列的第42讲。 三位数组合&#…...

Mongodb入门到入土,安装到实战,外包半年学习的成果
这是我参与「第四届青训营 」笔记创作活动的的第27天,今天主要记录前端进阶必须掌握内容Mongodb数据库,从搭建环境到运行数据库,然后使用MongodB; 一、文章内容 数据库基础知识关系型数据库和非关系型数据库为什么学习Mongodb数据库环境搭建及运行MongodbMongodb命…...

【C++初阶】之类和对象(下)
【C初阶】之类和对象(下) ✍ 再谈构造函数🏄 初始化列表的引入💘 初始化列表的语法💘 初始化列表初始化元素的顺序 🏄 explicit关键字 ✍ Static成员🏄 C语言中的静态变量🏄 C中的静…...
Spring Boot 3 极速搭建OAuth2认证框架
本篇环境 Java 17Spring Boot 3.2.3Spring Authorization Server 1.2.3开发工具 SpringToolSuite4Spring Boot 3.2.3 需要JDK 17及之上的版本。 项目初始化 项目可以使用Spring的初始化器生成, 也可以创建一个Maven类型的项目。 项目创建后的目录结构如下: 项目配置 使用 …...
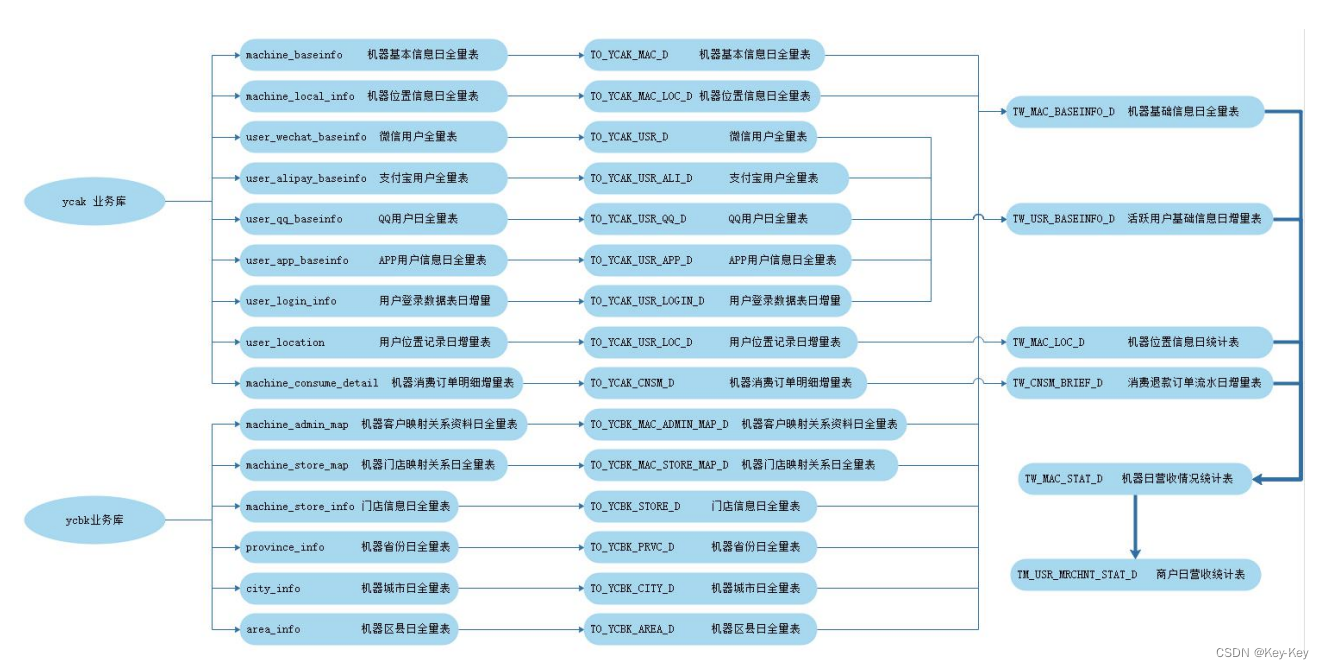
大数据开发(离线实时音乐数仓)
大数据开发(离线实时音乐数仓) 一、数据库与ER建模1、数据库三范式2、ER实体关系模型 二、数据仓库与维度建模1、数据仓库(Data Warehouse、DW、DWH)1、关系型数据库很难将这些数据转换成企业真正需要的决策信息,原因如…...

Python读取csv文件入Oracle数据库
在Python中,使用pandas库的read_sql_query函数可以直接从SQL查询中读取数据到DataFrame。而pd.set_option函数用于设置pandas的显示选项。具体来说,display.unicode.ambiguous_as_wide选项用于控制当字符宽度不明确时,pandas是否将这些字符显…...

Linux_进程概念_冯诺依曼_进程概念_查看进程_获取进程pid_创建进程_进程状态_进程优先级_环境变量_获取环境变量三种方式_3
文章目录 一、硬件-冯诺依曼体系结构二、软件-操作系统-进程概念0.操作系统做什么的1.什么叫做进程2.查看进程3.系统接口 获取进程pid- getpid4.系统接口 获取父进程pid - getppid5.系统接口 创建子进程 - fork1、手册2、返回值3、fork做了什么4、基本用法 6.进程的状态1、进程…...
Set A Light 3D Studio中文--- 打造专业级3D照明效果
Set A Light 3D Studio是一款专业的灯光模拟软件,专为摄影师和电影制片人打造。它允许用户在计算机上模拟并预览各种布光效果,助力拍摄出真实、精准且具有艺术感的作品。软件提供了丰富的灯光和场景模型,用户可以灵活调整光源参数,…...
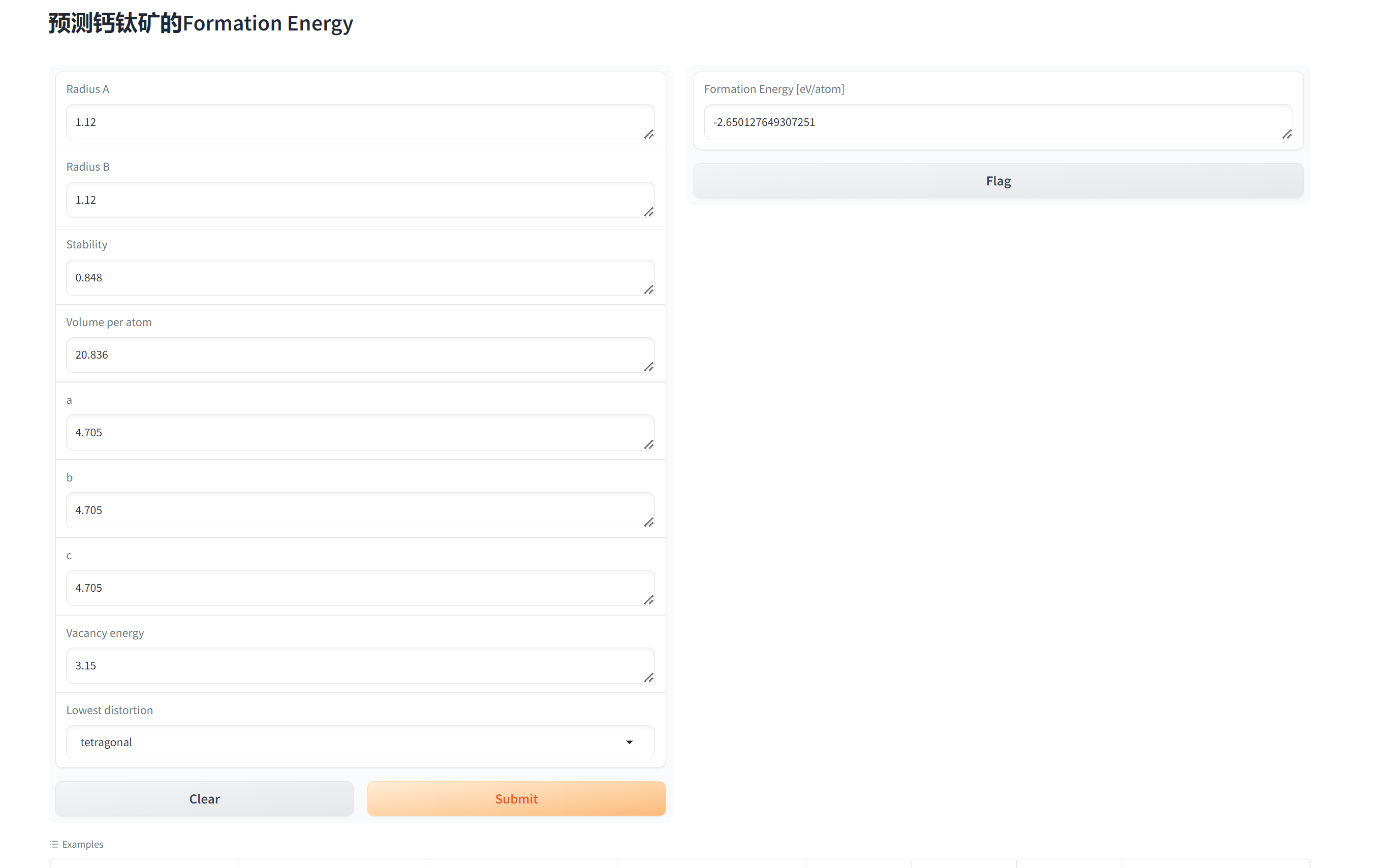
【深度学习】基于机器学习的无机钙钛矿材料形成能预测,预测形成能,神经网络,回归问题
文章目录 任务分析数据处理处理离散数值处理缺失值处理不同范围的数据其他注意事项 我们的数据处理模型训练网页web代码、指导 任务分析 简单来说,就是一行就是一个样本,要用绿色的9个数值,预测出红色的那1个数值。 数据处理 在进行深度数…...
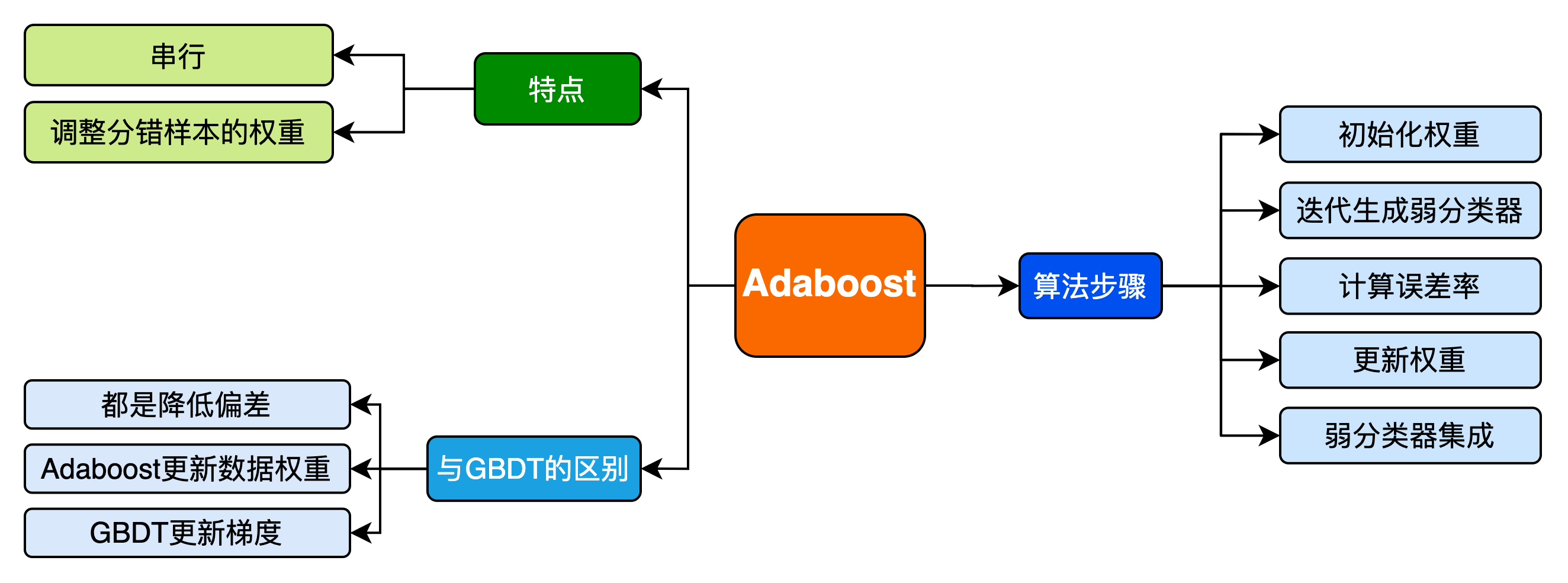
20240321-2-Adaboost 算法介绍
Adaboost 算法介绍 1. 集成学习 集成学习(ensemble learning)通过构建并结合多个学习器(learner)来完成学习任务,通常可获得比单一学习器更良好的泛化性能(特别是在集成弱学习器(weak learner…...
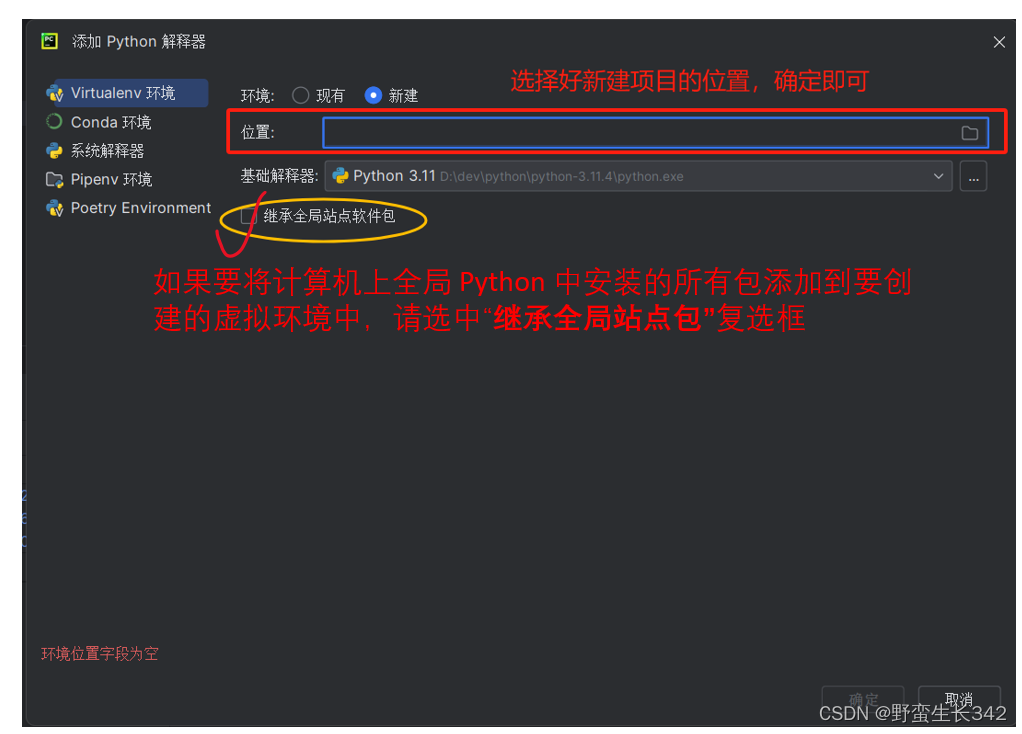
python第三方库的安装,卸载和更新,以及在cmd下pip install安装的包在pycharm不可用问题的解决
目录 第三方库pip安装,卸载更新 1.安装: 2.卸载 3.更新 一、第三方库pip安装,卸载更新 1.安装 pip install 模块名 加镜像下载:pip install -i 镜像网址模块名 常用的是加清华镜像,如 pip install -i https://pyp…...
Python第三次作业
周六 1. 求一个十进制的数值的二进制的0、1的个数 def er(x):a bin(x)b str(a).count("1")c str(a).count("0") - 1print(f"{a},count 1:{b},count 0:{c}")x int(input("enter a number:")) er(x) 2. 实现一个用户管理系统&…...

ai写作软件选哪个?这5款风靡全球的工具不容错过!
从去年到现在,ai 人工智能的发展一直是许多人关注的重点,每隔一段时间新诞生的 ai 工具软件,总会成为人们茶余饭后谈论的焦点。不过在种类繁多的 ai 工具软件中,ai 写作软件是最常被使用的 ai 工具类别,它的使用门槛较…...
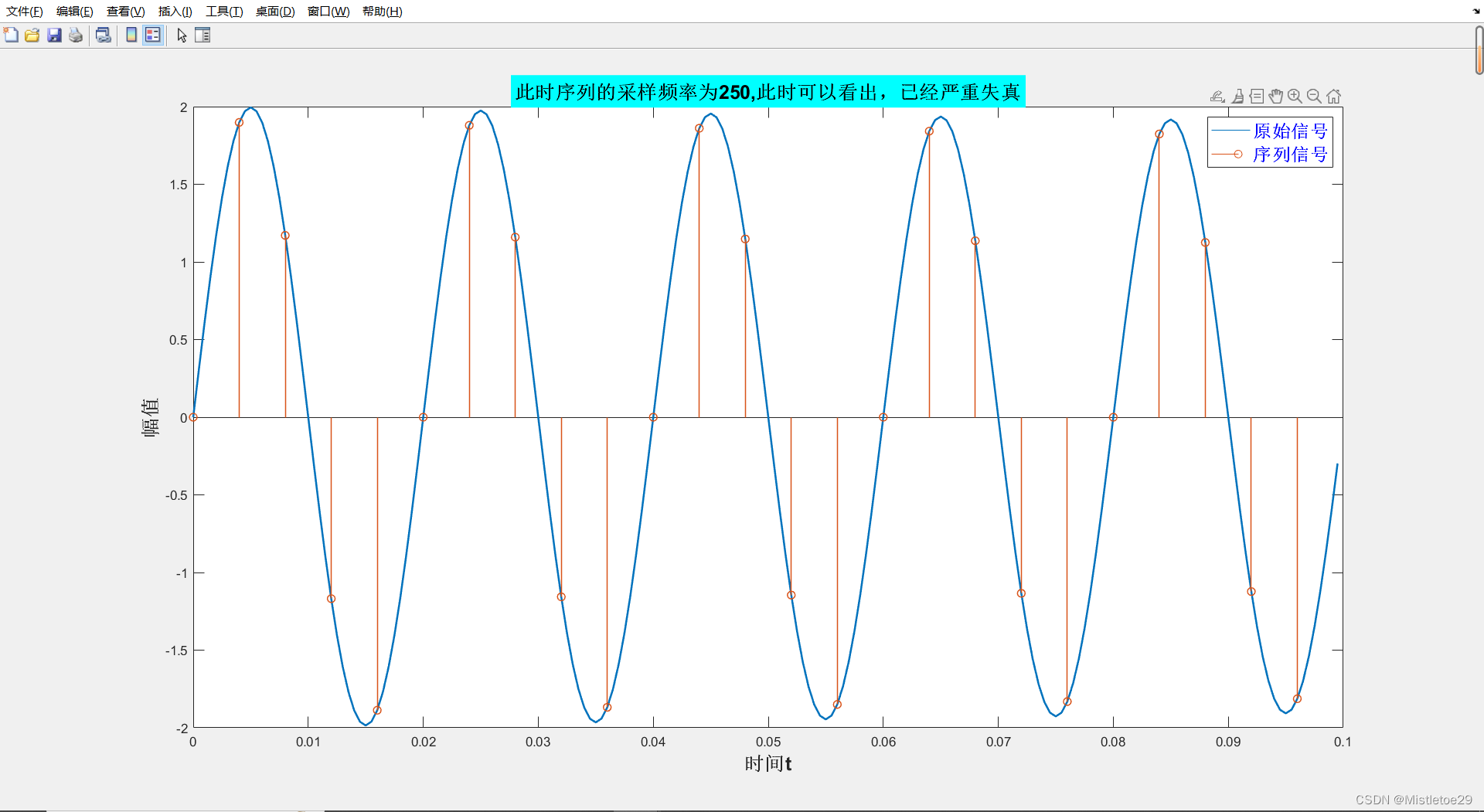
信号处理与分析——matlab记录
一、绘制信号分析频谱 1.代码 % 生成测试信号 Fs 3000; % 采样频率 t 0:1/Fs:1-1/Fs; % 时间向量 x1 1*sin(2*pi*50*t) 1*sin(2*pi*60*t); % 信号1 x2 1*sin(2*pi*150*t)1*sin(2*pi*270*t); % 信号2% 绘制信号图 subplot(2,2,1); plot(t,x1); title(信号x1 1*sin(…...
)
MacOS/Linux双平台实测:Ollama一键部署千问大模型避坑指南(附WebUI汉化技巧)
MacOS/Linux双平台实测:Ollama一键部署千问大模型避坑指南(附WebUI汉化技巧) 在开源大模型生态中,Ollama凭借其轻量化部署能力成为开发者本地运行AI模型的首选工具。本文将基于MacOS(M系列芯片/Intel)和Lin…...

Copilot 插入广告引担忧,AI 工具商业化边界受考
Copilot 拉取请求中惊现广告插入团队成员使用 Copilot 纠正拉取请求(PR)中的拼写错误时,出现了令人意想不到的情况。Copilot 不仅修改了 PR 描述,还插入了它自身以及 Raycast 的广告。这一行为引发了用户的强烈反应,有…...

实战指南:在CentOS 8上部署与配置BIND DNS权威服务器
1. 为什么要在CentOS 8上搭建DNS服务器? 想象一下这样的场景:公司内部有几十台服务器,每次新同事入职都要发一份IP地址对照表;开发团队每次联调测试都要反复确认服务地址;运维人员排查问题时要在记事本里翻找各种192.1…...
)
封神级C++设计:用3个成员实现可清空、可恢复、零开销的容器(颠覆传统思维)
封神级C设计:用3个成员实现可清空、可恢复、零开销的容器(颠覆传统思维) 文章目录封神级C\\设计:用3个成员实现可清空、可恢复、零开销的容器(颠覆传统思维)一、传统方案的“坑”:要么笨重&…...
)
[Python3高阶编程] - 异步编程深度学习指南一: 基础知识( 源代码)
异步编程深度学习指南 原文: https://blog.csdn.net/andylin02/article/details/159649164?spm1001.2014.3001.5502 #!/home/admin/.pyenv/versions/3.9.12/bin/python # -*- coding: utf-8 -*-o import aiohttp import asyncio from asyncio import Semaphoreasync def fetc…...
)
别再为PDF表格头疼了!用Nougat+LangChain搞定RAG系统里的表格问答(附完整代码)
突破PDF表格解析瓶颈:Nougat与LangChain构建智能问答系统实战 每次打开满是表格的学术论文PDF时,你是否也经历过这样的挫败感?传统OCR工具要么把跨页表格拆得七零八落,要么将复杂的LaTeX公式识别成乱码,更别提准确关联…...

遥感影像处理避坑指南:为什么你的SHP裁剪总失败?ArcMap与ENVI协作全解析
遥感影像裁剪实战避坑手册:从坐标系校准到多工具协同 当你在深夜盯着屏幕上那个扭曲变形的裁剪结果时,是否曾怀疑过人生?遥感影像的矢量裁剪看似简单,实则暗藏玄机。本文将带你深入剖析那些教科书上不会告诉你的实战细节ÿ…...

简单认识了解MSE
了解MSE 的应用场景在传统的网页开发中,前端处理视频的方式非常被动:给 video标签指定一个src,剩下的下载、缓冲、解码工作完全由浏览器底层“黑盒”接管,开发者几乎无法干预。MSE(Media Source Extensions,…...

DirectX兼容性解决方案:让经典游戏在Windows 10重获新生
DirectX兼容性解决方案:让经典游戏在Windows 10重获新生 【免费下载链接】dxwrapper Fixes compatibility issues with older games running on Windows 10 by wrapping DirectX dlls. Also allows loading custom libraries with the file extension .asi into gam…...

Arduino LSM6DS3驱动库深度解析:寄存器级IMU开发指南
1. Arduino_LSM6DS3库深度解析:面向嵌入式工程师的LSM6DS3惯性测量单元驱动开发指南 1.1 库定位与工程价值 Arduino_LSM6DS3是专为Arduino Nano 33 IoT和Arduino Uno WiFi Rev2两款板卡设计的LSM6DS3惯性测量单元(IMU)驱动库。该库并非通用型…...