本地部署大模型的几种工具(上-相关使用)
目录
前言
为什么本地部署
目前的工具
vllm
介绍
下载模型
安装vllm
运行
存在问题
chatglm.cpp
介绍
下载
安装
运行
命令行运行
webdemo运行
GPU推理
ollama
介绍
下载
运行
运行不同参数量的模型
存在问题
lmstudio
介绍
下载
使用
下载模型文件
加载模型
前言
为什么本地部署
正常我们要调用大模型,就需要将企业或个人信息传递到外部的大模型服务器,这种情况在目前极为重视数据安全的情况下,可能就有问题了。但是,本地部署大模型就没有这个问题,本地部署大模型后,不需要联网即可调用大模型,就没有了通过调用外部大模型导致数据泄露的问题。
再一个一说起大模型,不管训练还是推理,一般都是需要GPU。能不能有一些方法实现本地也可以部署大模型进行推理?
以上也就是写这一篇的初衷了。
目前的工具
目前有vllm、chatglm.cpp(llama.cpp也类似是通过C++实现)--提供编程能力,可以命令行运行,可以提供webapi
Ollama--命令行运行,可以提供webapi
lmstudio--纯界面操作
vllm
介绍
vllm主要作用其实是可以提高推理性能,但是必须在linux下运行,而且必须有GPU
官网地址
vllm官网 Welcome to vLLM! — vLLMhttps://docs.vllm.ai/en/latest/
下载模型
这里以下载千问7B为例,由于模型文件会比较大,因此安装git的lfs插件
git lfs install
git clone https://huggingface.co/Qwen/Qwen-7B-Chat
安装vllm
安装的话,为了避免python环境冲突问题,先通过conda创建一个新的虚拟环境
然后pip install vllm
也可以先从github下载,再去安装
vllm github地址https://github.com/vllm-project/vllm
运行
python -m vllm.entrypoints.openai.api_server --model="Qwen/Qwen-7B-Chat" --trust-remote-code --port 1234
注意:--model参数这里,如果之前已经下载了模型文件,这里是参数值改为模型文件路径,否则设置为模型名,然后会自动下载
注意2:通过aipost工具调用大模型,model参数需要和如上cmd运行命令的--model参数一致,否则会提示找不到model,这个我觉得是比较不好的一点
存在问题
1)通过apipost工具调用webapi,回答完,还会继续输出其他内容
一样,没搞懂为啥
补充:运行增加VLLM_USE_MODELSCOPE=True 推理速度会快很多,即:
VLLM_USE_MODELSCOPE=True python -m vllm.entrypoints.openai.api_server --model="Qwen/Qwen-7B-Chat" --trust-remote-code --port 1234
说是通过魔塔进行了加速,但是其所以然还没搞明白。
chatglm.cpp
介绍
chatglm.cpp主要通过C++编译,实现性能的提升
下载
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp
git submodule update --init --recursive
第二句主要是用于当前代码还引用了其他第三方代码库的情况,用于嵌套更新代码状态
安装
安装相关包
python3 -m pip install torch tabulate tqdm transformers accelerate sentencepiece
用于 convert.py 将 ChatGLM-6B 转换为量化的 GGML 格式。要将 fp16 原始模型转换为 q4_0(量化 int4)GGML 模型,请运行:
python3 chatglm_cpp/convert.py -i THUDM/chatglm3-6b -t q4_0 -o chatglm3-ggml.bin
运行
命令行运行
第一步:使用 CMake 配置项目并在当前目录下创建一个名为 "build" 的构建目录
cmake -B build
第二步:使用先前生成的构建系统文件在构建目录 "build" 中构建项目,采用并行构建和 Release 配置
cmake --build build -j --config Release
第三步:运行
./build/bin/main -m chatglm3-ggml.bin -p 你好
注意:这里cmake在linux下没问题,在windows下需要通过VS(Visual Studio)安装C++ Cmake工具

webdemo运行
python3 ./examples/web_demo.py -m chatglm3-ggml.bin
注意:这里可能会出错,提示找不到chatglm_cpp,这个时候可以先pip install .(.就是代表安装当前代码包,或.替换为chatglm_cpp也可以,或者去chatglm.cpp项目的Github网站--release下载对应系统对应python版本的whl文件进行安装也可以)
GPU推理
chatglm.cpp主要是用于让普通CPU也可以进行推理,因此默认它是CPU推理。但是不妨碍它可以GPU推理,毕竟效率更高。
cmake的时候,增加-DGGML_CUBLAS=ON,即可实现命令行运行通过GPU推理
webdemo运行的话,也需要对pip install .增加同样的参数,完整命令:CMAKE_ARGS="-DGGML_CUBLAS=ON" pip install .,这个时候再次运行webdemo即可实现GPU推理
ollama
介绍
ollama主要简化了部署大模型的复杂度
github地址:ollama/ollama:启动并运行 Llama 2、Mistral、Gemma 和其他大型语言模型。 (github.com)https://github.com/ollama/ollama
github上可以看ollama相关介绍,包括如何使用
下载
ollama一开始主要支持linux,docker也可以,目前有windows下的预览版可以下载
ollama官网 windows预览版下载https://ollama.com/download/OllamaSetup.exe
运行
安装完成即可通过cmd窗口使用ollama命令来运行大模型(注意第一次会先下载模型文件,我这里用的llama2的大小是4G多,还可以)

接下来就可以输入进行大模型对话了
不过命令行在实际应用中不方便,那么也可以通过ollama实现webapi调用方式
ollama serve--启用server模式
ollama run llama2(这里就是具体模型名称)
接下来即可通过postman、apipost等工具调用大模型了
注意这里地址是:localhost:11434/api/chat
运行不同参数量的模型
同一个模型,一般会有多个参数量,一般有7B、13B
如上运行ollama run llama2,其实是按默认参数量下载并运行模型了,也可以设置参数量
如:ollama run gemma:2b
:2b即具体参数量
存在问题
1)命令行下速度很快,但是webapi方式就很慢。可能还是在windows下还是预览版,没那么稳定
还没搞懂咋回事,现在只是初步知道了怎么用。后面再试试其他模型,看看是不是模型的问题
lmstudio
介绍
lmStudio是一个很简单的大模型使用工具,直接安装客户端,完全界面操作,无需编辑代码、无需运行命令,即可纯界面操作来使用大模型。
非常适合不懂技术的人员使用
下载
访问lmstudio官网LM Studio 官网 - Discover, download, and run local LLMshttps://lmstudio.ai/
选择对应操作系统的版本下载即可
使用
下载模型文件
打开软件默认界面,就是一个搜索框,输入你需要使用的模型名,点击Go进行搜索。
常用的模型,如LLama2、Gemma、QWen等
注:这里只能是开源大模型
在搜索结果页面,左侧是搜索结果,点击左侧其中一个结果,右侧显示出所有可以下载的文件,主要是量化参数不一样,一般选择q4_0的即可,选择对应文件下载即可。
页面最下方会显示下载进度
加载模型
模型文件下载完成,点击最左侧“AI Chat”图标,在最上方有个模型列表,选择下载的模型文件,会自动加载模型文件
接下来,就可以进行模型对话了
相关文章:
本地部署大模型的几种工具(上-相关使用)
目录 前言 为什么本地部署 目前的工具 vllm 介绍 下载模型 安装vllm 运行 存在问题 chatglm.cpp 介绍 下载 安装 运行 命令行运行 webdemo运行 GPU推理 ollama 介绍 下载 运行 运行不同参数量的模型 存在问题 lmstudio 介绍 下载 使用 下载模型文件…...

Spring Boot集成itext实现html生成PDF功能
1.itext介绍 iText是著名的开放源码的站点sourceforge一个项目,是用于生成PDF文档的一个java类库。通过iText不仅可以生成PDF或rtf的文档,而且可以将XML、Html文件转化为PDF文件 iText 的特点 以下是 iText 库的显着特点 − Interactive − iText 为你提供类(API)来生成…...

Java 多态、包、final、权限修饰符、静态代码块
多态 Java多态是指一个对象可以具有多种形态。它是面向对象编程的一个重要特性,允许子类对象可以被当作父类对象使用。多态的实现主要依赖于继承、接口和方法重写。 在Java中,多态的实现主要通过以下两种方式: 继承:子类继承父类…...
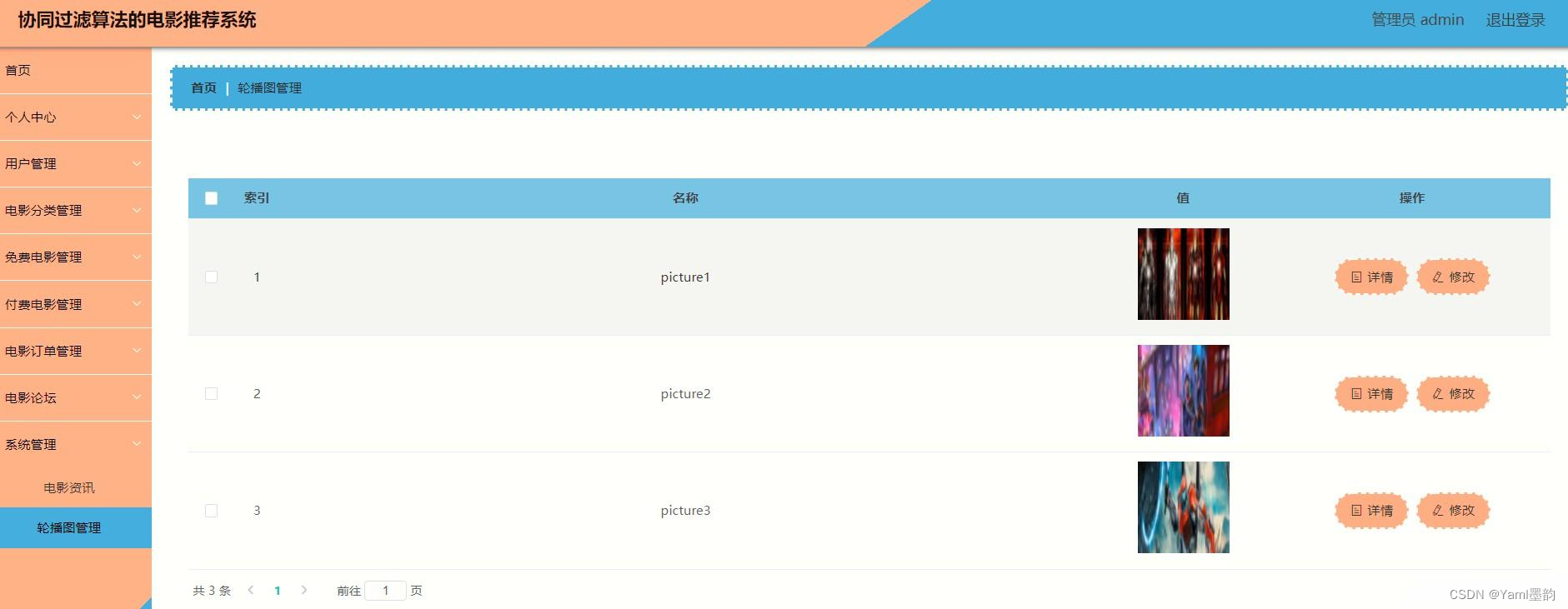
基于Spring boot + Vue协同过滤算法的电影推荐系统
末尾获取源码作者介绍:大家好,我是墨韵,本人4年开发经验,专注定制项目开发 更多项目:CSDN主页YAML墨韵 学如逆水行舟,不进则退。学习如赶路,不能慢一步。 目录 一、项目简介 二、开发技术与环…...

Chrome之解决:浏览器插件不能使用问题(十三)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
【正版特惠】IDM 永久授权 优惠低至109元!
尽管小编有修改版IDM,但是由于软件太好用了,很多同学干脆就直接购买了正版,现在正版也不贵,并且授权码绑定自己的邮箱,直接官方下载激活,无需其他的绿化修改之类的操作,不喜欢那么麻烦的&#x…...

SpringBoot与Prometheus监控整合
参考: springboot实战之prometheus监控整合-腾讯云开发者社区-腾讯云 https://www.cnblogs.com/skevin/p/15874139.html https://www.jianshu.com/p/e5dc2b45c7a4...

Linux 系统 docker搭建LNMP环境
1、安装nginx docker pull nginx (默认安装的是最新版本) 2、运行nginx docker run --name nginx -p 80:80 -d nginx:latest 备注:--name nginx 表示容器名为 nginx -d 表示后台运行 -p 80:80 表示把本地80端口绑定到Nginx服务端的 80端口 nginx:lates…...

拉普拉斯变换
定义: 拉普拉斯变换是一种在信号处理、控制理论和其他领域中广泛使用的数学工具,用于将一个函数从时域转换到复频域。拉普拉斯变换将一个函数 f(t) 变换为一个复变量函数 F(s),其中 s 是复数变量。下面是拉普拉斯变换的推导过程:…...

Mashup-Math_Topic_One
Tutorial and Introspection A Rudolf and 121 注意到第 1 1 1 位只能被第 2 2 2 位影响,以此类推位置,对于 a i a_i ai , 如果 < 0 < 0 <0 ,不合法 ; 否则, a i − a i , a i 1 − 2 ∗ a i , a i 2 − a …...
基于JavaWEB SSM SpringBoot婚纱影楼摄影预约网站设计和实现
基于JavaWEB SSM SpringBoot婚纱影楼摄影预约网站设计和实现 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言…...
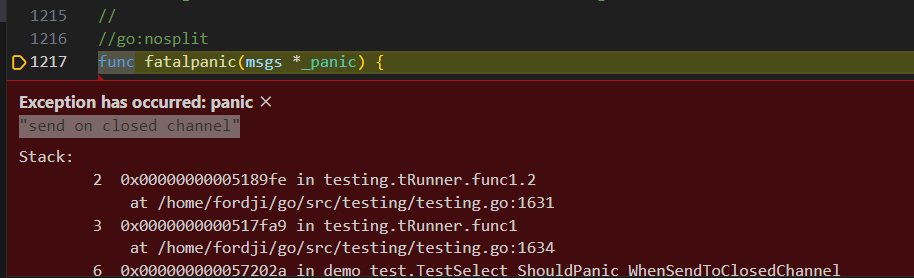
逐步学习Go-Select多路复用
概述 这里又有多路复用,但是Go中的这个多路复用不同于网络中的多路复用。在Go里,select用于同时等待多个通信操作(即多个channel的发送或接收操作)。Go中的channel可以参考我的文章:逐步学习Go-并发通道chan(channel)…...

王道:OJ15
课时15作业 Description 读取10个元素 87 7 60 80 59 34 86 99 21 3,然后建立二叉查找树,排序后输出3 7 21 34 59 60 80 86 87 99,针对有序后的元素,存入一个长度为10的数组中,通过折半查找找到21的下标(…...
【案例·查】数据类型强制转换,方便查询匹配
问题描述: MySQL执行中需要将某种数据类型的表达式显式转换为另一种数据类型,可以使用 SQL 中的cast()来处理 案例: SELECT CAST(9.0 AS decimal) #String化为小数类型SELECT * FROM table_1 WHERE 1888-03-07 CAST(theDate AS DATE) …...
spring boot3自定义注解+拦截器+Redis实现高并发接口限流
⛰️个人主页: 蒾酒 🔥系列专栏:《spring boot实战》 🌊山高路远,行路漫漫,终有归途 目录 写在前面 内容简介 实现思路 实现步骤 1.自定义限流注解 2.编写限流拦截器 3.注册拦截器 4.接口限流测试 写在前…...
使用certbot为网站启用https
1. 安装certbot客户端 cd /usr/local/bin wget https://dl.eff.org/certbot-auto chmod ax ./certbot-auto 2. 创建目录和配置nginx用于验证域名 mkdir -p /data/www/letsencryptserver {listen 80;server_name ~^(?<subdomain>.).ninvfeng.com;location /.well-known…...

Unity 背包系统中拖拽物体到指定位置或互换位置效果的实现
在Unity中,背包系统是一种常见的游戏系统,可以用于管理和展示玩家所持有的物品、道具或装备。 其中的拖拽功能非常有意思,具体功能就是玩家可以通过拖拽物品图标来移动物品在背包中的位置,或者将物品拖拽到其他位置或界面中&…...
iOS客户端自动化UI自动化airtest+appium从0到1搭建macos+脚本设计demo演示+全网最全最详细保姆级有步骤有图
Android客户端自动化UI自动化airtest从0到1搭建macos脚本设计demo演示全网最全最详细保姆级有步骤有图-CSDN博客 避坑系列-必读: 不要安装iOS-Tagent ,安装appium -这2个性质其实是差不多的都是为了安装wda。注意安装appium最新版本,安装完…...

每周编辑精选|在线运行 Deepmoney 金融大模型、AI 偏好等多个优质数据集上线
目前,AI 领域对金融模型的研究成果大多是基于公共知识进行训练的,但在实际的金融实践中,这些公共知识对于当前市场的可解释性往往严重不足。一个理想的金融大模型应该能够理解新闻或数据事件,并能够即时地从主观和量化两个角度对事…...
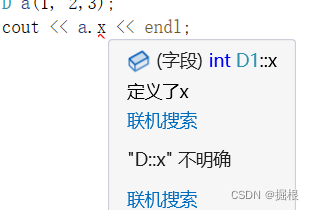
C++多重继承与虚继承
多重继承的原理 多重继承(multiple inheritance)是指从多个直接基类中产生派生类的能力。 多重继承的派生类继承了所有父类的属性。 在面向对象的编程中,多重继承意味着一个类可以从多个父类继承属性和方法。 就像你有一杯混合果汁,它是由多种水果榨取…...

ollama-QwQ-32B提示工程:提升OpenClaw操作准确率的10个模板
ollama-QwQ-32B提示工程:提升OpenClaw操作准确率的10个模板 1. 为什么需要专门优化OpenClaw的提示词? 第一次用OpenClaw执行文件整理任务时,我遭遇了灾难性结果——AI误将整个Downloads文件夹按修改日期排序后,把300多个文件全部…...

被裁员后,我用这个 AI 助手每天只工作 2 小时|OpenClaw 实战
😭 被裁员后,我用这个 AI 助手每天只工作 2 小时“真正的自由,不是想做什么就做什么,而是不想做什么就可以不做什么”01 一个普通打工人的至暗时刻 上个月,公司裁员 30%。 我所在的部门,5 个人走了 3 个。 …...

卸载软件后,“打开方式”里仍有残留怎么办?我是这样在 Windows 里彻底清理掉的
有时候我们明明已经把某个软件卸载干净了,但右键文件时,“打开方式”列表里依然还能看到它。 这种情况看起来不严重,但确实很烦:一方面影响整洁,另一方面也容易让人误以为软件没有卸载干净。我最近就遇到了这个问题&am…...

零基础极速上手:十分钟用AI建站工具做出你的第一个网站
# 痛点共情:完全不懂技术,真的能自己做出吗?\你可能连“域名”和“服务器”都分不清,看到代码就头疼,更别说设计排版了。但心里又确实需要个网站:不管是展示作品、推广小店,还是给简历加分。你担…...
)
别再手动比对了!用Python+PyTorch搭建你的第一个遥感变化检测模型(附实战代码)
用PythonPyTorch实现遥感变化检测:从数据预处理到模型部署全流程指南 遥感影像的变化检测技术正在城市规划、环境监测、灾害评估等领域发挥越来越重要的作用。传统人工比对方法效率低下,而基于深度学习的自动化解决方案正在重塑这个领域的技术格局。本文…...

SurfaceView视觉优化实战:圆角与渐变蒙层的完美结合
1. SurfaceView视觉优化的核心价值 在Android开发中,SurfaceView因其独特的双缓冲机制和独立的绘图线程,成为视频播放、游戏渲染等高性能场景的首选组件。但原生SurfaceView的直角边框和单调的呈现方式,常常与现代化UI设计语言格格不入。我在…...
)
ASan实战:5种常见内存错误诊断与修复指南(附GCC/Clang编译命令)
ASan实战:5种常见内存错误诊断与修复指南(附GCC/Clang编译命令) 在C/C开发中,内存错误如同潜伏的暗礁,随时可能让程序沉没。AddressSanitizer(ASan)作为Google推出的内存错误检测工具ÿ…...

打造高效AI训练与推理服务器:2025年硬件配置与QLoRA实战指南
1. 2025年AI服务器硬件配置指南 组装一台兼顾训练和推理的AI服务器,核心在于平衡显存容量、内存带宽和计算吞吐量。2025年的硬件市场已经趋于成熟,二手显卡性价比尤为突出。我实测过多种配置组合,发现双RTX 3090的方案在微调7B-14B参数模型时…...

AI专著生成速达秘籍:高性价比工具剖析,助力快速创作
创新是学术专著所需的核心元素,也是写作的一道高门槛。一部合格的学术专著,不能仅仅是对已有研究成果的机械拼凑,而应当展示贯穿全书的独特见解、理论模型或研究方法。在浩如烟海的学术文献中,识别尚未探索的研究空白并不是一件容…...

ArtiPub AI与Docker集成:构建可扩展的容器化发布系统
ArtiPub AI与Docker集成:构建可扩展的容器化发布系统 【免费下载链接】artipub Article publishing platform that automatically distributes your articles to various media channels 项目地址: https://gitcode.com/gh_mirrors/ar/artipub 在当今快速发展…...