Spring Boot 整合分布式搜索引擎 Elastic Search 实现 自动补全功能
文章目录
- ⛄引言
- 一、分词器
- ⛅拼音分词器
- ⚡自定义分词器
- 二、自动补全查询
- 三、自动补全
- ⌚业务需求
- ⏰实现酒店搜索自动补全
- 四、效果图
- ⛵小结
⛄引言
本文参考黑马 分布式Elastic search
Elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
像京东这样的提示应该如何实现?

可通过ES实现该自动补全功能,搭载分词器配合使用!
本篇文章将讲解 Elastic Search 如何使用分词器实现自动补全功能,以及 在项目实战中如何通过完成自动补全的需求开发
一、分词器
为什么要使用分词器呢,因为我们要实现自动补全功能,要对输入的文字进行分词,从而更好的查询结果集
⛅拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:https://github.com/medcl/elasticsearch-analysis-pinyin

下载zip,安装方式如下:
- 解压,通过工具上传至 elasticsearch的plugin目录
- 重启elasticsearch
- 进行测试拼音分词器
重启命令: docker restart es
测试方法:
POST /_analyze
{"text": "希尔顿酒店还不错","analyzer": "pinyin"
}

⚡自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
声明自定义分词器的语法如下:
PUT /test
{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 分词器名称"tokenizer": "ik_max_word","filter": "py"}},"filter": { // 自定义tokenizer filter"py": { // 过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
测试

总结:
如何使用拼音分词器?
-
下载pinyin分词器
-
解压并放到elasticsearch的plugin目录
-
重启即可
如何自定义分词器?
-
创建索引库时,在settings中配置,可以包含三部分
-
character filter
-
tokenizer
-
filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
二、自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是completion类型。
- 字段的内容一般是用来补全的多个词条形成的数组。
比如,一个这样的索引库:
// 创建索引库
PUT test
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
然后插入下面的数据:
// 示例数据
POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}
查询的DSL语句如下:
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": {"text": "sw" // 关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}

测试出一条数据
三、自动补全
⌚业务需求
在页面实现 输入 文字或者拼音,自动提示匹配的列表数据

根据酒店数据和地址进行查询数据列表
⏰实现酒店搜索自动补全
现在,我们的hotel索引库还没有设置拼音分词器,需要修改索引库中的配置。但是我们知道索引库是无法修改的,只能删除然后重新创建。
另外,我们需要添加一个字段,用来做自动补全,将brand、suggestion、city等都放进去,作为自动补全的提示。
因此,总结一下,我们需要做的事情包括:
- 修改hotel索引库结构,设置自定义拼音分词器
- 修改索引库的name、all字段,使用自定义分词器
- 索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
- 给HotelDoc类添加suggestion字段,内容包含brand、business
- 重新导入数据到hotel库
// 酒店数据索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
修改HotelDoc实体
HotelDoc中要添加一个字段,用来做自动补全,内容为酒店品牌、城市、商圈等信息。按照自动补全字段的要求,最好是这些字段的数组。
因此我们在HotelDoc中添加一个suggestion字段,类型为List<String>,然后将brand、city、business等信息放到里面。
代码如下:
@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();//拼装数据,把数据一个个放到数组中if (this.business.contains("/") || this.business.contains("、") || this.business.contains(",")) {String[] arr = {};if (this.business.contains("/")) {arr = this.business.split("/");} else if (this.business.contains("、")) {arr = this.business.split("、");} else if (this.business.contains(",")) {arr = this.business.split(",");}this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);//把数组中的元素一个个放进去Collections.addAll(this.suggestion, arr);} else {this.suggestion = Arrays.asList(this.brand, this.business);}}
}
执行方法重新导入酒店数据
@Testvoid testBulkRequest() throws IOException {// 查询所有的酒店数据List<Hotel> list = hotelService.list();// 1.准备RequestBulkRequest request = new BulkRequest();// 2.准备参数for (Hotel hotel : list) {// 2.1.转为HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);// 2.2.转jsonString json = JSON.toJSONString(hotelDoc);// 2.3.添加请求request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(json, XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);}
自动补全查询API
自动补全查询DSL 对应代码

自动补全结果解析 对应代码DSL

核心源码
在Controller类新增接口
@GetMapping("suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix) {return hotelService.getSuggestions(prefix);
}
Service业务代码
public List<String> getSuggestions(String prefix) {//1. 准备requestSearchRequest request = new SearchRequest("hotel");//2. 准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));try {//3. 发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//4. 解析结果Suggest suggest = response.getSuggest();//根据补全查询名称获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");//获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();//遍历List<String> result = new ArrayList<>(options.size());for (CompletionSuggestion.Entry.Option option : options) {result.add(option.getText().toString());}return result;} catch (Exception e) { e.printStackTrace();}return null;}
四、效果图

⛵小结
以上就是【Bug 终结者】对 Spring Boot 整合分布式搜索引擎 Elastic Search 实现 自动补全功能 的简单介绍,ES搜索引擎无疑是最优秀的分布式搜索引擎,使用它,可大大提高项目的灵活、高效性! 技术改变世界!!!
如果这篇【文章】有帮助到你,希望可以给【Bug 终结者】点个赞👍,创作不易,如果有对【后端技术】、【前端领域】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【Bug 终结者】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💝💝💝!
相关文章:
Spring Boot 整合分布式搜索引擎 Elastic Search 实现 自动补全功能
文章目录 ⛄引言一、分词器⛅拼音分词器⚡自定义分词器 二、自动补全查询三、自动补全⌚业务需求⏰实现酒店搜索自动补全 四、效果图⛵小结 ⛄引言 本文参考黑马 分布式Elastic search Elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,…...
实现一个Google身份验证代替短信验证
最近才知道公司还在做国外的业务,要实现一个登陆辅助验证系统。咱们国内是用手机短信做验证,当然 这个google身份验证只是一个辅助验证登陆方式。看一下演示 看到了嘛。 手机下载一个谷歌身份验证器就可以 。 谷歌身份验证器,我本身是一个基…...

Spring框架与Spring Boot的区别和联系
引言 Spring框架和Spring Boot都是Java生态中最受欢迎的开源框架,它们各自扮演着不同的角色,帮助开发者构建高效的企业级应用。本教程将从零基础的角度出发,让你轻松理解这两者的区别和联系。 Spring框架简介 Spring框架,简称Spri…...

[OpenCV学习笔记]Qt+OpenCV实现图像灰度反转、对数变换和伽马变换
目录 1、介绍1.1 灰度反转1.2 图像对数变换1.3 图像伽马变换 2、效果图3、代码实现4、源码展示 1、介绍 1.1 灰度反转 灰度反转是一种线性变换,是将某个范围的灰度值映射到另一个范围内,一般是通过灰度的对调,突出想要查看的灰度区间。 S …...

【大数据】Flink学习笔记
文章目录 认识FlinkDocker安装Flink基本概念Flink的特点Flink 和 Spark Streaming 对比 基本使用WordCount实现依赖 批模式代码流模式代码网络流模式代码在web UI上提交代码创建项目[^1]编写代码配置打包在Web UI上提交 Flink 架构系统架构核心概念并行度算子链(Opeartor Chain…...

社交网络的未来:Facebook如何塑造数字社交的下一章
引言 社交网络已成为我们生活中不可或缺的一部分,而Facebook作为其领军者,一直在塑造着数字社交的未来。本文将深入探讨Facebook在未来如何塑造数字社交的下一章,并对社交网络的发展趋势进行展望和分析。 1. 引领虚拟社交的潮流 Facebook将…...
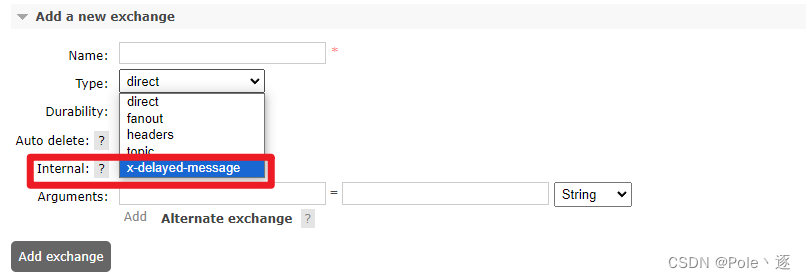
RabbitMQ 延时消息实现
1. 实现方式 1. 设置队列过期时间:延迟队列消息过期 死信队列,所有消息过期时间一致 2. 设置消息的过期时间:此种方式下有缺陷,MQ只会判断队列第一条消息是否过期,会导致消息的阻塞需要额外安装 rabbitmq_delayed_me…...

【Django】枚举类型数据
模型 在模型里主要增加两项内容: 枚举表字段增加choices class Snort(CoreModel):PAGE_TYPE_CHOICES [(1, 失陷主机检测), # 1是保存到数据库里的数据,失陷主机检测是显示在前端的(2, 远程漏洞攻击检测),(3, 可疑流量行为),(4, WEB检测),]page_type…...

java实现https连接总是要报no cipher suites in common
遇到“no cipher suites in common”这样的错误通常意味着客户端和服务器之间没有共同支持的加密套件(Cipher Suite)。这个问题可能由多个原因引起,包括但不限于SSL/TLS配置错误、Java安全策略限制、客户端或服务器不支持的加密算法等。解决这…...
[C++初阶] 爱上C++ : 与C++的第一次约会
🔥个人主页:guoguoqiang 🔥专栏:我与C的爱恋 本篇内容带大家浅浅的了解一下C中的命名空间。 在c中,名称(name)可以是符号常量、变量、函数、结构、枚举、类和对象等等。工程越大,名称…...
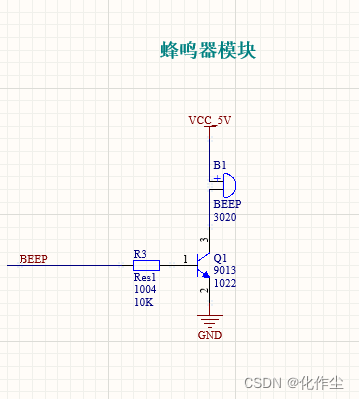
STM32技术打造:智能考勤打卡系统 | 刷卡式上下班签到自动化解决方案
文章目录 一、简易刷卡式打卡考勤系统(一)功能简介原理图设计程序设计 哔哩哔哩: https://www.bilibili.com/video/BV1NZ421Y79W/?spm_id_from333.999.0.0&vd_sourcee5082ef80535e952b2a4301746491be0 一、简易刷卡式打卡考勤系统 &…...

module ‘numpy‘ has no attribute ‘int‘
在 NumPy 中,如果遇到了错误提示 "module numpy has no attribute int",这通常意味着正在尝试以错误的方式使用 NumPy 的整数类型。从 NumPy 1.20 版本开始,numpy.int 已经不再是一个有效的属性,因为 NumPy 不再推荐使用…...
MFC(一)搭建空项目
安装MFC支持库 创建空白桌面程序 项目相关设置 复制以下代码 // mfc.h #pragma once #include <afxwin.h>class MyApp : public CWinApp { public:virtual BOOL InitInstance(); };class MyFrame : public CFrameWnd { public:MyFrame();// 消息映射机制DECLARE_…...

OKCC的API资源管理平台怎么用?
API资源管理平台,重点是“资源”管理平台,不是API接口管理平台。 天天讯通推出的API资源管理平台,类似昆石的VOS系统,区别是VOS是SIP资源管理系统,我们的API资源管理平台是API资源管理系统(AXB、AX、回拨AP…...

CentOS 7 安装python 3.7 需要必要的依赖。
在 CentOS 7 上部署 Python 3.7 可以通过源代码编译安装来实现。以下是大致的步骤: 安装必要的依赖: bashCopy Code sudo yum install gcc openssl-devel bzip2-devel libffi-devel 下载 Python 3.7 源代码并进行编译安装: bashCopy Code wg…...

美术馆设计方案优化布局与设施提升观众体验!
如今,美术馆不仅仅是作为展示艺术作品的平台,也是吸引公众参与和创造独特体验的数字艺术体验空间,因此许多传统美术馆在进行翻修改造时,都会更加注重用户体验,并在其中使用大量的多媒体互动,让参观者能够在…...

数据库基础原理
宏观 数据库的实现原理分为四个部分: 网络通信 网络协议 硬盘存储 内存分配 微观 硬盘存储 数据库是持久化的,而持久化如何实现的,我们不难想到磁盘可以持久化存储,所以数据库所有持久化的数据都是以文件形式存在磁盘中的…...
Pandas操作MultiIndex合并行列的Excel,写入读取以及写入多余行及Index列处理,插入行,修改某个单元格的值,多字段排序
Pandas操作MultiIndex合并行列的excel,写入读取以及写入多余行及Index列处理,多字段排序尽量保持原来的顺序 1. 效果图及问题2. 源码参考 今天是谁写Pandas的 复合索引MultiIndex,写的糊糊涂涂,晕晕乎乎。 是我呀… 记录下&#…...

工作总结5
1.taro框架使用map标签出现的错误 这个问题困扰很长时间,在频繁切换页面渲染的时候出现左边不显示,我理解的是变量没有到达map标签的属性上,那我就想是不是setState太慢了,然后又用了变量,本地缓存等,都没有…...
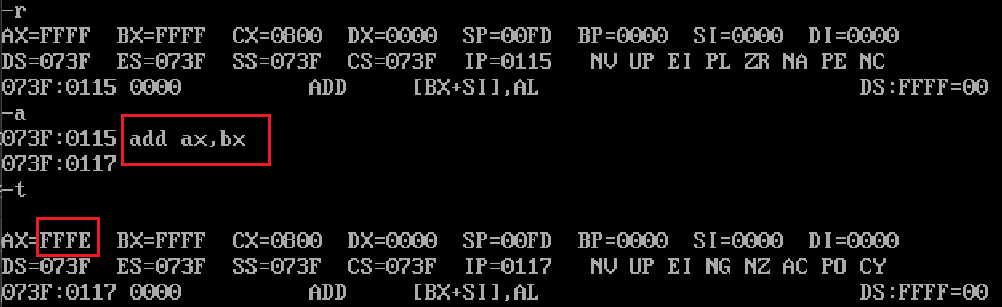
速通汇编(二)汇编mov、addsub指令
一,mov指令 mov指令的全称是move,从字面上去理解,作用是移动(比较确切的说是复制)数据,mov指令可以有以下几种形式 无论哪种形式,都是把右边的值移动到左边 mov 寄存器,数据&#…...

Python爬虫实战:构建智能职位信息聚合工具JobClaw
1. 项目概述:一个面向开发者的智能职位信息聚合与解析工具最近在帮团队招聘和看机会的朋友聊天,发现一个挺普遍的问题:大家找技术岗位,要么在几个主流招聘App上反复刷,信息分散且格式不一;要么就是盯着几个…...

为ae做片段视频项目配置专属AI模型并控制成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为AE做片段视频项目配置专属AI模型并控制成本 对于小型视频工作室或独立制作人而言,在After Effects等工具中处理大量视…...

告别轮询与中断:用HC32F4A0的AOS+DMA实现多通道ADC的“无感”采集
HC32F4A0的AOSDMA架构:构建零CPU干预的多通道ADC采集系统 在嵌入式数据采集领域,实时性与低功耗始终是工程师需要平衡的核心矛盾。传统基于轮询或中断的ADC采集方案往往面临两大困境:要么因频繁查询浪费CPU资源,要么因中断响应延迟…...

在Node.js后端服务中集成Taotoken调用多模型API实战
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用多模型API实战 构建需要AI能力的Web服务时,后端开发者常面临模型选型、API接入复…...

XUnity自动翻译器:打破语言壁垒的终极Unity游戏汉化解决方案
XUnity自动翻译器:打破语言壁垒的终极Unity游戏汉化解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而错过精彩的游戏剧情?是否在面对日文RPG或英文…...

Encounter/Innovus GIFT TCL 脚本流程索引清单
目录 一、 布局阶段 (Placement) 二、 布线阶段 (Routing) 三、 时序阶段 (Timing) 四、 电源阶段 (Power) 五、 IO 与端口处理 六、 调试与辅助工具 一、 布局阶段 (Placement) 脚本名称 核心用途 调用场景 userAddAllHInsts.tcl 为源模块中的每个扇出添加缓冲器 解决高扇…...

Linux fanotify vs inotify:如何为你的监控需求选择正确的工具?
Linux文件监控技术选型:fanotify与inotify深度对比与实践指南 在构建需要实时感知文件系统变化的应用程序时,开发者常面临监控工具的选择困境。无论是开发安全扫描工具、持续备份系统还是智能IDE,文件监控都是核心需求。Linux平台提供了inoti…...

初创公司如何利用Taotoken快速构建AI产品原型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何利用Taotoken快速构建AI产品原型 对于资源有限的初创团队而言,验证产品想法、快速推出原型是生存和发展的…...
)
Acrylic Paint风格在Midjourney中失效的5大隐性陷阱(附官方未公开的--s 700+--style raw协同调参公式)
更多请点击: https://intelliparadigm.com 第一章:Acrylic Paint风格在Midjourney中的本质定义与失效现象全景图 Acrylic Paint(丙烯画)风格在Midjourney中并非原生语义标签,而是一种通过视觉特征逆向建模的提示工程产…...
完全解析:从原理到代码,深入浅出)
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出 目录 一、为什么需要内存训练? 二、DDR3训练的核心原理 三、训练流程详解:一场精密的三步仪式 四、代码实战:从初始化到训练完成...