大语言模型(LLM)token解读
1. 什么是token?
人们经常在谈论大模型时候,经常会谈到模型很大,我们也常常会看到一种说法:
参数会让我们了解神经网络的结构有多复杂,而token的大小会让我们知道有多少数据用于训练参数。
什么是token?比较官方的token解释:
Token是对输入文本进行分割和编码时的最小单位。它可以是单词、子词、字符或其他形式的文本片段。
看完是不是一脸懵逼?为此我们先补充点知识。
2. 大模型工作原理
本质上就是神经网络。但是训练这么大的神经网络,肯定不能是监督学习,如果使用监督学习,必然需要大量的人类标记数据,这几乎是不可能的。那么,如何学习?
当然,可以不用标记数据,直接训练,这种学习方法称为自监督学习。引用学术点的描述:
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息训练模型,从而学习到对下游任务有价值的表征。
自监督学习无标签数据和辅助信息,这是定义自监督学习的两个关键依据。它会通过构造辅助任务来获取监督信息,这个过程中有学习到新的知识;而无监督学习不会从数据中挖掘新任务的标签信息。
例如,在英语考试中,通过刷题可以提高自己的能力,其中的选项就相当于标签。当然,也可以通过听英文音频、阅读英文文章、进行英文对话交流等方式来间接提高英语水平,这些都可以视为辅助性任务(pretext),而这些数据本身并不包含标签信息。
那么,GPT是如何在人类的文本数据上实现自监督学习的呢?那就是用文本的前文来预测后文。
此处引用知乎大佬的案例,例如在下面这段文本中:
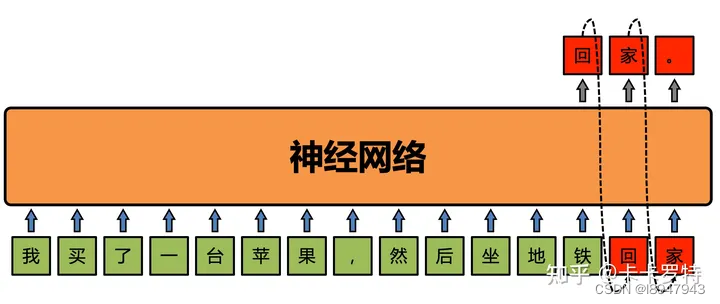
我买了一台苹果,然后坐地铁回家。
GPT 模型会将回家两个字掩盖住。将我买了一台苹果,然后坐地铁视为数据,将回家。视为待预测的内容。 GPT 要做的就是根据前文我买了一台苹果,然后坐地铁来预测后文回家。
这个过程依靠神经网络进行,简单操作过程如图:
3. 谈谈语言模型中的token
GPT 不是适用于某一门语言的大型语言模型,它适用于几乎所有流行的自然语言。所以这告诉我们 GPT 实际的输入和输出并不是像上面那个图中那个样子。计算机要有通用适配或者理解能力,因此,我们需要引入 token 的概念。token 是自然语言处理的最细粒度。简单点说就是,GPT 的输入是一个个的 token,输出也是一个个的 token。
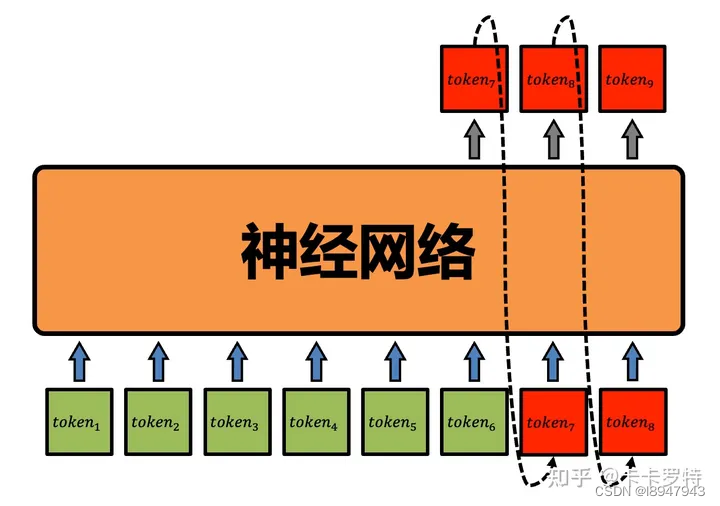
GPT 不是适用于某一门语言的大型语言模型,它适用于几乎所有流行的自然语言。所以 GPT 的 token 需要兼容几乎人类的所有自然语言,那意味着 GPT 有一个非常全的 token 词汇表,它能表达出所有人类的自然语言。如何实现这个目的呢?
答案是通过 unicode 编码。
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
例如,我们在输入你,对应的unicode 编码为:\u4f60,转换成16进制为0100 1111 0110 0000,转换成10进制对应20320。直接将 unicode 的编码作为 GPT 中 token 的词表,会存在一些问题。 一方面直接使用 unicode 作为词汇表太大了,另一方面 unicode 自身的粒度有时候太细了,例如 unicode 中的英文编码是以字母粒度进行的。
于是我们会将 unicode 的2进制结果以8个二进制位为单位进行拆分。用0100 1111和0110 0000表示你8个二进制位只有256种可能,换句话说,只需要256个 token 的词汇表就能表示所有 unicode。
然而这种方法的词汇表又太小了,编码方法太粗糙了。实际上 GPT 是使用一种称为 BPE (Byte Pair Encoding)的算法,在上面的基础上进一步生成更大的词汇表。
它的基本思想如下,将上述的基础 token (256种可能)做组合,然后统计文本数据中这些组合出现的频率,将频率最大的那些保留下来,形成新的 token 词汇表。因此,通过此方法得到的 token 和文字的映射不一定是一对一的关系。

4.再深入理解一下什么是token
Token是LLM处理文本数据的基石,它们是将自然语言转换成机器可理解格式的关键步骤。几个基本概念:
- 标记化过程(Tokenization):这是将自然语言文本分解成token的过程。在这个过程中,文本被分割成小片段,每个片段是一个token,它可以代表一个词、一个字符或一个词组等。
- 变体形式:根据不同的标记化方案,一个token可以是一个单词,单词的一部分(如子词),甚至是一个字符。例如,单词"transformer"可能被分成"trans-", “form-”, "er"等几个子词token。
- 模型模型限制:大型语言模型通常有输入输出token数量的限制,比如2K、4K或最多32K token。这是因为基于Transformer的模型其计算复杂度和空间复杂度随序列长度的增长而呈二次方增长,这限制了模型能够有效处理的文本长度。
- token可以作为数值标识符:Token在LLM内部被赋予数值或标识符,并以序列的形式输入或从模型输出。这些数值标识符是模型处理和生成文本时实际使用的表示形式,说白了可以理解成一种索引,索引本身又是一种标识符。
5. 为什么token会有长度限制?
有以下3方面的相互制约:文本长短、注意力、算力,这3方面不可能同时满足。也就是说:上下文文本越长,越难聚焦充分注意力,难以完整理解;注意力限制下,短文本无法完整解读复杂信息;处理长文本需要大量算力,从而提高了成本。(这是因为GPT底层基于Transformer的模型,Transformer模型的Attention机制会导致计算量会随着上下文长度的增加呈平方级增长)
参考
- 自监督学习(Self-supervised Learning)
- ChatGPT实用指南(一)
- 大型语言模型(LLM)中的token
- LLM 大模型为什么会有上下文 tokens 的限制?
相关文章:
大语言模型(LLM)token解读
1. 什么是token? 人们经常在谈论大模型时候,经常会谈到模型很大,我们也常常会看到一种说法: 参数会让我们了解神经网络的结构有多复杂,而token的大小会让我们知道有多少数据用于训练参数。 什么是token?比…...
【Micro 2014】NoC Architectures for Silicon Interposer Systems
NoC Architectures for Silicon Interposer Systems 背景和动机 硅中介层 主要内容 基于interposer的多核 NOC架构 试验评估 方法 NoC Architectures for Silicon Interposer Systems Natalie Enright Jerger, University of Toronto Gabriel H. Loh AMD Research 硅中介层…...
【文章笔记 + 个人思考】)
《极客时间 - 左耳听风》01 | 程序员如何用技术变现?(上)【文章笔记 + 个人思考】
《极客时间 - 左耳听风》 原文链接 :https://time.geekbang.org/column/intro/100002201?tabcatalog 备注:加粗部分为个人思考 程序员用自己的技术变现是天经地义的事情。写程序是一门手艺活,程序员作为手艺人完全可以不依赖任何公司或者其他…...
Typora结合PicGo + Github搭建个人图床
目录 一 、GitHub仓库设置 1、新建仓库 2、创建Token 并复制保存 二、PicGo客户端配置 1、下载 & 安装 2、配置图床 三、Typora配置 一 、GitHub仓库设置 1、新建仓库 点击主页右上角的 号创建 New repository 填写仓库信息 2、创建Token 并复制保存 点击右上角…...

【JavaWeb】Day27.Web入门——Tomcat介绍
目录 WEB服务器-Tomcat 一.服务器概述 二.Web服务器 三.Tomcat- 基本使用 1.下载 2.安装与卸载 3.启动与关闭 4.常见问题 四.Tomcat- 入门程序 WEB服务器-Tomcat 一.服务器概述 服务器硬件:指的也是计算机,只不过服务器要比我们日常使用的计算…...

怎么更新sd-webui AUTOMATIC1111/stable-diffusion-webui ?
整个工程依靠脚本起来的: 可直接到stable-diffusion-webui子目录执行: git pull更新代码完毕后,删除venv的虚拟环境。 然后再次执行webui.sh,这样会自动重新启动stable-diffusion-webui....
)
Apache Iceberg最新最全面试题及详细参考答案(持续更新)
目录 1. 描述Apache Iceberg的架构设计和它的主要组件? 2. Iceberg如何处理数据的版本控制和时间旅行?...
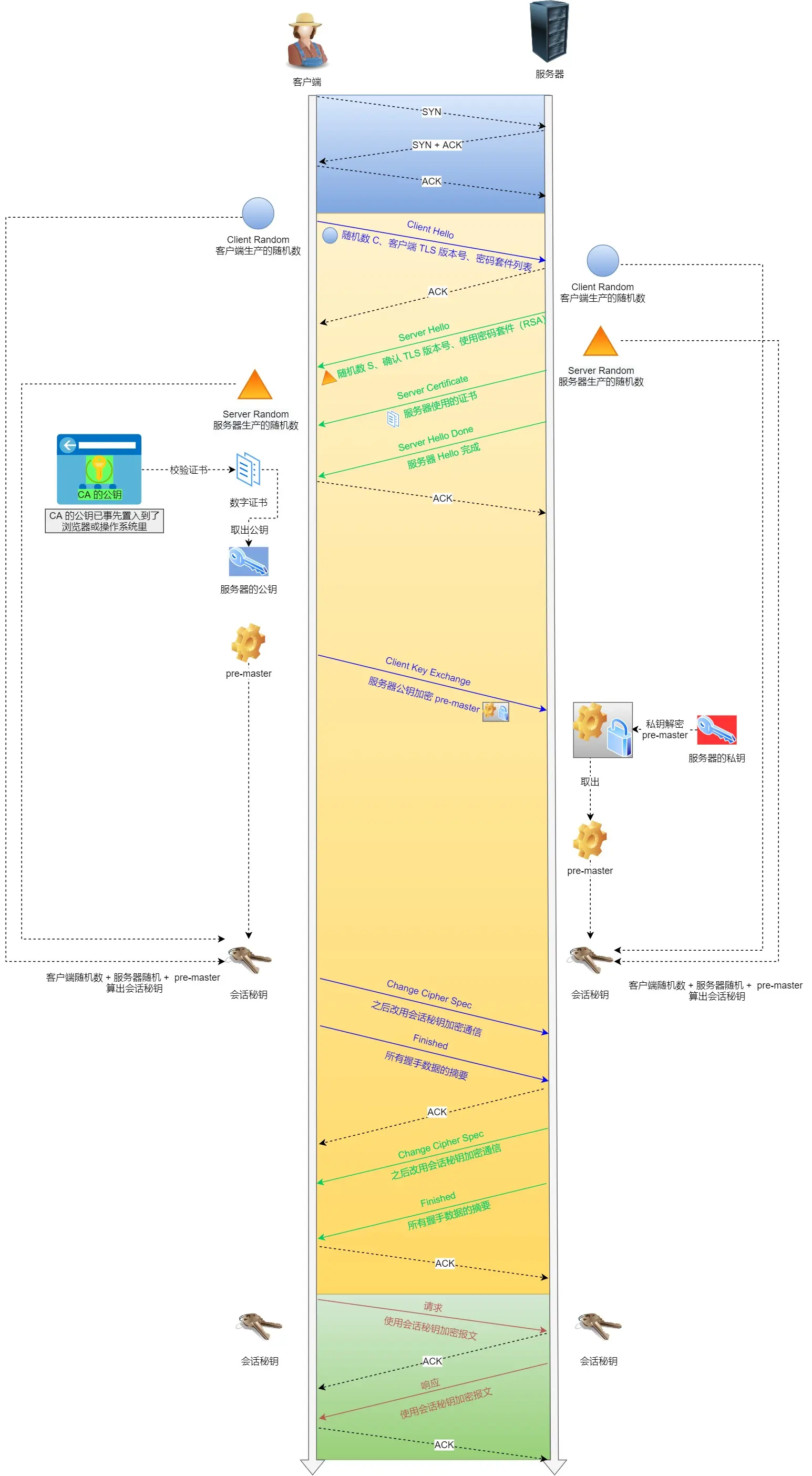
从TCP/IP协议到socket编程详解
我的所有学习笔记:https://github.com/Dusongg/StudyNotes⭐⭐⭐ 文章目录 1 网络基础知识1.1 查看网络信息1.2 认识端口号1.3 UDP1.4 TCP1.4.1 确认应答机制1.4.2 TCP三次握手/四次挥手为什么是三次握手为什么是四次挥手listen 的第二个参数 backlog—— 全…...
uniapp开发小程序遇到的问题,持续更新中
一、uniapp引入全局scss 在App.vue中引入uni.scss <style lang"scss">/* #ifndef APP-NVUE */import "uni.scss";/* #endif */ </style>注意:nvue页面的样式在编译时,有很多样式写法被限制了,容易报错。所…...
)
C++经典面试题目(十一)
1. final和override关键字 在C中,final 和 override 是两个用于类继承和成员函数重写的关键字,它们主要在面向对象编程的上下文中使用,以增强代码的可读性和安全性。 1. final 关键字 final 关键字主要有两种用法: 用于类&…...
:桥接模式)
设计模式(6):桥接模式
一.桥接模式核心要点 处理多层继承结构,处理多维度变化的场景,将各个维度设计成独立的继承结构,使各个维度可以独立的扩展在抽象层建立关系。 \color{red}{处理多层继承结构,处理多维度变化的场景,将各个维度设计成独立…...

Java切面编程
1.切面编程 无需改变原有类的情况下对业务功能实现扩展或增强。 2.目前最流行的AOP框架有两个,分别为Spring AOP 和 AspectJ。 3.Spring AOP使用纯java实现,不需要专门的编译过程和类加载器,在运行期间通过代理方式向目标类织入增强的代码。 …...
微服务demo(二)nacos服务注册与集中配置
环境:nacos1.3.0 一、服务注册 1、pom: 移步spring官网https://spring.io,查看集成Nacos所需依赖 找到对应版本点击进入查看集成说明 然后再里面找到集成配置样例,这里只截一张,其他集成内容继续向下找 我的&#x…...

面试题库二
1、简述TCP/IP的三次握手和四次挥手 TCP(Transmission Control Protocol)是一种可靠的、面向连接的传输层协议,用于在网络中传输数据。在建立连接和断开连接时,TCP 使用了三次握手和四次挥手来确保通信的可靠性和正确性。 三次握手…...
HarmonyOS实战开发-如何实现一个简单的电子相册应用开发
介绍 本篇Codelab介绍了如何实现一个简单的电子相册应用的开发,主要功能包括: 实现首页顶部的轮播效果。实现页面跳转时共享元素的转场动画效果。实现通过手势控制图片的放大、缩小、左右滑动查看细节等效果。 相关概念 Swiper:滑块视图容…...

FFmpeg将绿幕视频处理成透明视频播放
怎么在网页端插入透明视频呢,之前在做Web3D项目时,使用threejs可以使绿幕视频透明显示在三维场景中,但是在网页端怎么让绿幕视频透明显示呢? 如图上图,视频背景遮挡住后面网页内容 想要如下图效果 之前有使用过ffmpeg…...

【2024系统架构设计】案例分析- 4 嵌入式
目录 一 基础知识 二 真题 一 基础知识 1 基本概念 ◆系统可靠性是系统在规定的时间内及规定的环境条件下,完成规定功能的能力,也就是系统无故障运行的概率。或者,可靠性是软件系统在应用或系统错误面前,在意外或错误使用的情况下维持软件系统的功能特性的基本能力。...
基于javaweb(springboot+mybatis)生活美食分享平台管理系统设计和实现以及文档报告
基于javaweb(springbootmybatis)生活美食分享平台管理系统设计和实现以及文档报告 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 …...

【MySQL探索之旅】MySQL数据表的增删查改——约束
📚博客主页:爱敲代码的小杨. ✨专栏:《Java SE语法》 | 《数据结构与算法》 | 《C生万物》 《MySQL探索之旅》 |《Web世界探险家》 ❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更…...
【Linux】体验一款开源的Linux服务器运维管理工具
今天为大家介绍一款开源的 Linux 服务器运维管理工具 - 1panel。 一、安装 根据官方那个提供的在线文档,这款工具的安装需要执行在线安装, # Redhat / CentOScurl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start…...

零代码到全球上线:我用 Dify + EdgeOne Pages 为跨境电商打造了一个 7×24 小时 AI 智能客服
文章目录每日一句正能量目录1. 引言:一个独立站卖家的深夜焦虑2. 技术选型:为什么选择 Dify EdgeOne Pages?3. 场景拆解:跨境电商客服的三大核心痛点3.1 痛点一:意图混杂,一句话可能包含多个需求3.2 痛点二…...

Gemma 4大模型实战:从架构解析到生产部署与微调
1. 项目概述:为什么我们需要深入理解Gemma 4?如果你最近在关注开源大模型领域,一定绕不开“Gemma”这个名字。从年初Gemma 2B/7B的惊艳亮相,到如今关于下一代架构的种种猜测,Google的Gemma系列正以一种稳健而有力的姿态…...

Mega:基于上下文工程的Brainbase平台AI开发效率革命
1. 项目概述:Mega,你的Brainbase平台AI工程专家如果你正在使用Claude Code、Cursor或者任何能读取文件的AI编程工具来构建基于Brainbase平台的对话式AI应用,那么你很可能遇到过这样的困境:你需要花费大量时间向AI解释Brainbase的架…...

Simplefolio构建优化终极指南:Tree Shaking与代码分割实战
Simplefolio构建优化终极指南:Tree Shaking与代码分割实战 【免费下载链接】simplefolio ⚡️ A minimal portfolio template for Developers 项目地址: https://gitcode.com/gh_mirrors/si/simplefolio Simplefolio是一个为开发者设计的极简个人作品集模板&…...

从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的
从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的 接手一个结构混乱的遗留项目,就像面对一盘煮过头的意大利面——各种逻辑纠缠不清,随便动一处就可能引发连锁反应。去年我遇到这样一个Java项目:12万行代码࿰…...

小白程序员必看:收藏这份AI黑话指南,轻松入门大模型世界!
本文用大白话解释了AI领域几个核心概念:AI是总称,LLM是推理模型,Agent能独立执行任务,MCP是标准化接口,Skills是技能包。文章通过生活化比喻和实例,帮助读者理解这些概念如何协同工作,实现高效自…...

管式土壤墒情监测站:深埋地下测湿度,云端上报助灌溉
管式土壤墒情监测站采用土壤介电常数检测原理,结合专业数学模型算法,搭配独创螺旋式测量电极结构开展高精度土壤含水率监测。土壤介电常数与土壤含水量存在稳定且精准的对应关系,设备通过传感器高频感知土层介电参数变化,经内置算…...

3分钟快速上手:91160-cli医疗预约自动化助手完整指南
3分钟快速上手:91160-cli医疗预约自动化助手完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预约设计…...

EMAC寄存器系统:网络诊断与性能优化的关键
1. EMAC寄存器系统概述以太网媒体访问控制器(EMAC)是现代网络设备中负责数据链路层操作的核心硬件模块。作为网络通信的"交通警察",EMAC不仅负责以太网帧的收发调度,还通过精密的寄存器系统记录着网络通信的每一个关键细…...

Mac Mouse Fix终极指南:如何让普通鼠标在Mac上获得超越触控板的体验
Mac Mouse Fix终极指南:如何让普通鼠标在Mac上获得超越触控板的体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为Mac上第三…...