您现在可以在家训练 70b 语言模型
原文:Answer.AI - You can now train a 70b language model at home
2024 年 3 月 6 日
概括
今天,我们发布了 Answer.AI 的第一个项目:一个完全开源的系统,首次可以在具有两个或更多标准游戏 GPU(RTX 3090 或 4090)的常规台式计算机上高效地训练 70b 大型语言模型。该系统结合了 FSDP 和 QLoRA,是 Answer.AI、Tim Dettmers(华盛顿大学)以及 Hugging Face 的 Titus von Koeller 和 Sourab Mangrulkar 之间合作的结果。
该系统将帮助开源社区发布更好的模型。 Teknium 是极受欢迎的 OpenHermes 模型和数据集的创建者,下载量超过 50 万次,他表示:
“有了这种能力,我们可以在本地将巨大的模型提升到新的高度,现在小型实验室也可以访问巨大的、数千亿个参数的模型。 ”
在 Answer.AI,我们将此作为我们的第一个项目,因为它是我们北极星的关键基础:帮助每个人都能使用有用的人工智能。仅仅能够使用其他人的模型是不够的。我们希望每个人都能够创建自己的个性化模型,以便他们控制自己的人工智能系统。
背景
大创意
用于训练深度学习模型的硬件有两种截然不同的级别。还有数据中心级的硬件,比如H100s、A100s,价格就几十万美元。然后是包含游戏 GPU 的台式计算机,例如双 4090,成本低于 10,000 美元(并且可以用二手零件组装而成,价格不到预构建系统价格的一半)。
但关键是:游戏 GPU 的性能与数据中心 GPU 相似,但价格高出 10 倍以上!如果我们可以使用这些便宜 10 倍(但速度几乎一样快)的卡来训练大型语言模型,那就太好了,但我们不能,因为它们的内存要少得多。目前最好的数据中心卡具有 80GB RAM,而游戏卡最大可达 24GB RAM。由于只有最大的模型才能产生最好的结果,因此大多数人基本上无法创建最好的模型。
我们意识到这实际上没有内在原因。超快的硬件就在那里,等待使用——我们只需要一种方法来为其提供模型和数据,以满足其内存限制。显而易见的问题是:为什么当时没有这样做?所有大型工业实验室都已经拥有昂贵 10 倍的硬件,因此他们并没有动力去解决这个问题。
这里的主要想法很简单:弄清楚如何使用这些更便宜、内存更低的游戏 GPU 来训练最好的可用开源模型。所以目标是这样的:仅使用游戏 GPU 训练1 个700 亿个参数 (70b) 的模型,这意味着我们的每个 GPU 内存最多为 24GB。这将是一个挑战,因为每个参数通常需要 16 位(2 个字节),因此甚至需要 70*2=140GB 来存储权重 - 而且这还不包括所有其他数据,例如激活、梯度和优化状态!
为什么是这个项目?
答:AI 是一种非常不寻常的组织类型——一个营利性研发实验室,在精神上更接近19 世纪的电力实验室,而不是今天的人工智能研究小组。 Eric Ries 和 Jeremy Howard去年在 NeurIPS 上成立该组织时,希望我们能够找到如何让大型模型训练变得廉价且易于使用的方法。
解决这个问题很难。它需要了解许多独立的库(例如,bitsandbytes、PEFT、Transformers、Accelerate 和 PyTorch)以及计算机科学和数学概念(例如,离散化、分布式计算、GPU 编程、线性代数、SGD 概念,例如梯度检查点),以及它们如何全部相互作用。
学术界充满了解决难题的才华横溢的人。但学术界尚未解决这个特殊问题。这是因为大学研究人员很难证明花时间在此类工作上是合理的。将现有工具和技术结合在一起通常被认为不够“新颖”,不足以在高影响力期刊上发表,但这正是学术界所需要的货币。此外,学者们通常被期望在其领域内变得高度专业化,这使得将如此多的部分整合到一个解决方案中具有挑战性。
当然,大型科技公司也充满了解决难题的优秀人才。但使用消费级 GPU 训练模型这一特殊问题并不是他们需要解决的问题——他们已经购买了昂贵的 GPU!许多初创公司也充满了解决难题的才华横溢的人!但是,正如埃里克·里斯 (Eric Ries) 所解释的那样,“当今的金融市场迫使企业将短期收益置于其他一切之上”。对于初创公司来说,向投资者解释为什么他们将资金用于开源软件和公共研究是极其困难的。
虽然学术界、大型科技公司和初创公司有充分的理由不解决这个问题,但这些正是这个问题非常适合 Answer.AI 的确切原因。在公司工作的每个人都构建了我们必须使用的系统来解决这个问题,因此我们能够了解所有部分如何组合在一起。那些既喜欢深入了解软件和人工智能的基础,又喜欢破解有趣的端到端系统的人,就是被 Answer.AI 所吸引的人,反之亦然。
我们选择共同解决的问题是由负责解决的同一个人选择的。因此,我们倾向于选择将多种想法结合在一起以创建实用的解决方案的项目。因为我们是一家公益公司,我们的使命是从人工智能中产生长期利益,所以开源软件和公共研究与我们的使命直接一致。
QLoRA:在单个 GPU 上训练更大的模型
最近发布的两个项目为实现这一目标迈出了关键的第一步:QLoRA(由Tim Dettmers 等人开发)和 FSDP(由 Meta 的PyTorch 团队开发)。
QLoRA 是现代神经网络中两个至关重要的进步的简单而出色的组合:量化和LoRA。量化是一种不使用 16 位甚至 32 位来存储神经网络权重的技术,而是使用 4 位(甚至更少)。 4 位数字只有 16 个可能的值,但Dettmers 和 Zettlemoyer 表明,这对于当今流行的大型语言模型来说已经足够了。 Tim Dettmers 借助他的 bitsandbytes 库使这些 4 位“量化”模型易于创建,最近 Hugging Face 介入帮助维护和记录该库,特别感谢 Titus von Koeller 的倡议。
不幸的是,一旦模型被量化,就无法使用常规方法对其进行进一步训练——只有 16 个可能的值,用于模型训练的梯度下降方法几乎到处都会观察到零梯度,因此它无法对模型进行任何更新。量化权重。这是一个主要问题,因为这意味着量化只能用于推理,而不能用于持续的预训练或微调。虽然推理很有用且重要,但它实际上只是消耗模型。但我们希望每个人都能为创建模型做出贡献!
避免这种限制的技巧是使用LoRA—— “大型语言模型的低阶适应”。 LoRA 根本不训练整个大型语言模型,而是添加“适配器”,它们是经过训练的非常小的矩阵(通常小于整个模型的 1%),同时保持模型的其余部分不变。如果您玩过“稳定扩散”等模型,您可能会多次看到这些适配器;这就是这些模型通常如何共享的原因,也是它们体积如此之小、下载速度如此之快的原因。
Tim 意识到 LoRA 可以与量化相结合:使用训练时根本不会改变的量化基础模型,并添加未量化的可训练 LoRA 适配器。这个组合就是QLoRA。 Tim 的团队首次能够使用它来训练(未量化)比 GPU 更大的模型:他们在 48GB 卡上训练了 65b 模型(未量化为 130GB)。
Hugging Face 再次介入,创建了PEFT库,使 LoRA 训练变得更加简单,并将其直接与 BitsandBytes 集成,让任何人只需几行代码即可使用 QLoRA。 Hugging Face 团队一直在幕后不知疲倦地工作,以确保开源社区可以使用这些技术来训练他们的模型。如果您曾经使用 Transformers 使用单个函数参数加载 4 位模型,那么您应该感谢他们(即使您没有,您几乎肯定使用过那些构建了 Transformer 的人的工作成果)他们的生态系统模型)。
QLoRA 并没有完全解决我们想要解决的问题,即在 24GB 卡上训练 70b 模型,但它比以前任何事情都更接近。当量化为 4 位(即 0.5 字节)时,70b 模型需要 70/2 = 35 GB,这比我们想要使用的 24GB 游戏 GPU 更大。
QLoRA 还有其他限制。 48GB 卡非常昂贵,训练 65b 模型只适合这样的卡。这可能是一个问题,因为我们还需要存储许多其他内容,包括训练期间模型的激活2、梯度和优化状态。如果加载模型权重后剩余的内存不多,则说明没有足够的工作内存来支持训练。
例如,语言模型的好处之一是我们可以使用它们来“聊天”、理解或分析长文档或对话。为了创建可以处理这样的长序列的模型,我们需要在训练期间向它们展示长序列的示例。训练中使用的最长序列称为“序列长度”。在 48GB 卡上训练 65b QLoRA 模型时,尝试使用除短序列长度之外的任何内容都会导致错误,因为没有足够的内存来存储有关序列的所有信息;几乎所有内存都用于存储模型本身。
此外,如果模型一次只能查看一个序列,那么将需要很长时间才能遍历训练集中的所有数据。因此,我们希望能够一次将几个序列“批处理”在一起。包含的序列数就是“批量大小”。当加载模型权重后 GPU 上剩余的空间非常少时,我们只能使用非常小的批量大小,从而导致训练速度极其缓慢。
FSDP:将训练扩展到多个 GPU
解决单个消费类 GPU 的 RAM 限制问题的一个明显的解决方案是使用多个 GPU!开源社区中一种非常常见的方法是简单地将模型的几层放置在每张卡上。因此,要进行训练,您需要在第一个 GPU 上运行前几层,然后在第二个 GPU 上运行接下来的几层,依此类推。例如,70b (140GB) 模型可以分布在 8 个 24GB GPU 上,每个 GPU 使用 17.5GB。拥抱脸部变形金刚中甚至还有一个方便的设置,device_map=’auto’您可能已经使用过;这就是这实际上在幕后所做的事情。这可以完成工作,但有一个巨大的缺点:一次只有一个 GPU 处于活动状态,因为所有其他 GPU 都在等待“轮到”。这意味着 ⅞ 的计算被浪费了。
分布式数据并行(DDP) 以前是跨多个 GPU 高效训练模型的黄金标准方法。这需要在每个 GPU 上保留完整的模型 - 如果您有一个小模型(例如 2b 模型,需要 4GB RAM),您可以简单地将整个模型分别加载到每个 GPU 上,然后让每个 GPU 并行地处理训练示例。例如,如果您有 4 个 GPU,则训练速度会提高 4 倍。但是,如果模型不适合 GPU,并且没有足够的空间来容纳训练过程所需的数据,那么 DDP 就不起作用。
因此,我们需要能够跨 GPU 拆分模型(例如device_map=’auto’)并并行使用它们(例如 DPP)的东西。这就是 Meta 的完全分片数据并行(FSDP) 库的用武之地。它通过将参数拆分到多个 GPU 上来“分片”大型模型,从而允许同时使用所有 GPU。当训练期间在特定 GPU 上计算神经网络的一层时,所有所需的分片都会复制到那里。然后进行计算,最后从该 GPU 中删除复制的部分。虽然这听起来效率非常低,但实际上,通过在当前层忙于计算的同时聪明地复制下一层的数据,与 DDP 相比,这种方法可能不会导致速度减慢。
FSDP 能够将 DDP 的性能带到比任何一个 GPU 都大的模型上,这是一个启示。例如,70b(700亿参数)非量化模型需要140GB RAM(因为每个参数存储为16位,即2字节),但即使是NVIDIA的H100卡(单张卡的成本约为40,000美元!)也达不到要求配备 80GB 内存,满足您的需求。但通过 FSDP,四个 H100 GPU 可以组合起来形成总共 320GB RAM。
(请注意,这样一台机器将花费您大约 150,000 美元......)
将 FSDP 和 QLoRA 结合在一起
在 Answer.AI,我们的北极星正在让有用的人工智能变得更容易使用。花费 150,000 美元来创建自己的高品质个性化模型绝对算不上容易获得的!因此,我们开展的第一个项目是让使用带有消费级游戏 GPU 的桌面来高效训练 70b 模型成为可能。我们认为,如果我们可以使用 QLoRA 将模型的大小减少大约 400%(因此 70b 模型将适合 35GB RAM),然后我们使用 FSDP 将其分片到两个或更多 24GB 消费卡上,那么就剩下剩余足够的 RAM 来训练模型。
第一步
Jeremy 和 Tim 在 2023 年底讨论了将 FSDP 和 QLoRA 结合在一起的想法。 Tim 将 Jeremy 与 Titus von Koeller 联系起来,Jeremy 和 Titus 一起尝试、探索、理解和记录两个库合并时出现的问题。
Answer.AI 的 Johno Whitaker 完成了重要的第一步:一个简单的独立测试脚本,它使我们能够更深入地理解问题并测试解决方案。 2024 年初,Answer.AI 的 Benjamin Warner 和 Titus 独立提出了一个关键想法:将量化参数存储在可选择的数据类型中,其中存储数据类型与“计算类型”相同。模型3 .
本杰明在提出这个想法后 24 小时内就完成了这个原型,但随后我们发现了另一个问题:FSDP 没有复制每个分片使用该模型所需的量化信息!这是因为 FSDP 对于将在 GPU 之间同步的数据子集非常固执4。我们意识到,如果我们在每个 GPU 上量化模型,丢失的元数据将在所有 GPU 上保持不变。此外,我们必须将“量化状态”(对参数进行(反)量化所需的信息)从参数移动到各层中,以确保它们在 FSDP 移动分片时不会被删除。
一旦我们解决了这些问题,我们就能够使用 FSDP 使用量化模型成功训练我们的第一批数据! Benjamin 和 Answer.AI 的 Kerem Turgutlu 能够将其与所需的所有测试和重构打包到bitandbytes 的拉取请求中。我们非常感谢bitsandbytes 项目的维护者,他们在他们的流程中非常积极地指导我们的公关。
任务完成,差不多了
此时,我们再次认为我们很快就会把事情搞定,但我们再次低估了任务的复杂性!我们意识到的第一件事是,实际上仍然不可能加载比单个 GPU 更大的量化模型,因为加载和量化过程本身需要将整个模型放在一个 GPU 上。
Jeremy 花了几周时间仔细研究 Meta 的Llama-Recipes项目,这是他发现的最完整的 FSDP 微调实现,并密切跟踪它如何与 BitsandBytes 以及 Hugging Face 的 PEFT、Transformers 和 Accelerate 项目一起工作,他设法构建了一个最小的独立脚本,手动完成微调模型所需的所有步骤。
本杰明意识到,通过一些调整,可以一次加载和离散化一层,从而避免需要在单个 GPU 上运行整个模型。他还弄清楚了如何防止 PEFT 库将量化状态转移到 CPU。 Kerem 编写了 LoRA 算法的自定义实现,以便它可以适应 Benjamin 的更改。
至此,我们首次能够在双 3090 游戏 GPU 上微调 70b 模型!
为了实现这项工作,我们不仅受益于 FSDP 和 QLoRA,还受益于过去几年学术界和开源社区开发的大量巧妙技术。我们用了:
- 梯度检查点(也称为激活检查点)以避免存储完整梯度,而是在整个模型的多个“检查点”处保存激活,然后根据需要重新运行前向计算步骤来重新计算梯度
- CPU 卸载,在不使用权重时将权重存储在 CPU RAM 中,而不是存储在 GPU 上,从而大大减少了所需的 GPU 内存。这项技术对于使用 H100 GPU 的“GPU 丰富”来说并不是很有用,因为 H100 GPU 具有高度优化的方式来相互传递权重。但对于我们的用例来说,这是绝对必要的,因为游戏 GPU 和主板没有这些系统
- Flash Attention 2使用内存优化的 Cuda 内核有效计算注意力。
让这些与 FSDP 和 QLoRA 一起工作并不总是那么简单。例如,在使用 CPU 卸载时,Benjamin 发现并修复了位和字节的问题。每次“卸载”权重被复制回 GPU 时,它都会自动重新量化,从而有效地将预训练模型转变为随机权重!我们向bitsandbytes发出了一个拉取请求,跟踪哪些参数已经被量化,这样我们就可以避免冗余计算。
完成所有这些工作后,我们非常高兴地看到我们可以使用消费级 GPU 训练大型模型。 Jeremy 在一系列 GPU 硬件上对原始 llama-recipes 进行了详细的基准测试,Kerem 为新项目开发了一个全面的基准测试系统。在比较两者时,我们意识到我们仍然无法使用我们希望的序列长度或批量大小 - 由于某种原因,使用的内存比我们预期的要多。
当我们仔细观察时,发现这根本不是由于我们的 FSDP/QLoRA 集成所致 - 但实际上,即使没有 FSDP,当我们以位和字节为单位增加 seqlen 时,内存使用量也会呈超线性上升,最终导致内存更高比没有量化的用法!事实证明我们并不是第一个发现这个问题的人。我们还没有比特和字节解决方案(但正在研究中),但它确实让我们有了一个令人兴奋的发现……
发现HQQ
我们喜欢与志同道合的人合作,因此当我们看到 Daniel Han 在Unsloth上所做的出色工作时,我们想了解更多信息,看看我们是否能够互相帮助。我们问 Daniel 在这个领域是否还有其他有趣的项目值得我们关注,他向我们推荐了HQQ。
为了解释 HQQ,我们需要先给出一些背景知识……bitsandbytes 完成的 4 位量化使用了一种简单、快速且巧妙的方法,其中每组参数都被归一化到一致的范围,然后每个参数是放置在一个桶中,其中桶断点基于参数呈正态分布的假设。这样做的好处是量化几乎是即时的,但由于真实的模型参数不会完全符合假设的分布,因此准确性可能会受到影响。
其他方法(例如 GPTQ 和更新的 AWQ)则走向不同的方向,即当代表性数据传递给模型时,根据模型的实际行为来优化量化参数。5这些方法往往会产生更准确的模型,每个参数甚至可能少于 4 位;但它们的缺点是每个模型的优化过程可能需要数小时甚至数天的时间。
HQQ 结合了两全其美。与 GPTQ 相比,处理 70b 模型的速度快 50 倍,但精度更高。 Kerem 决定调查 HQQ 是否能与 FSDP 良好配合。
他发现,使 HQQ 和 FSDP 很好地协同工作所需的步骤几乎与位和字节所需的步骤完全相同,因此他在几天内完成了一个完整的工作示例。mobius.ml 人员在确保我们的 PR 成功合并方面反应迅速且乐于助人 - 因此我们现在很高兴地宣布 FSDP 也可以与 HQQ 配合使用!
如何使用 FSDP/QLoRA
要使用 FSDP,您当然需要多个 GPU。如果您无法访问此类系统,您可以从Runpod Community Cloud租用双 3090 盒子,价格约为 0.60 美元/小时。还有许多其他提供商可供选择;cloud-gpus是查看所提供内容的好地方。
您需要安装最新版本的 Transformers、PEFT 和 bitsandbytes(如果您使用的话,还需要安装 HQQ)。然后,克隆我们的存储库并按照其中的自述文件进行操作。运行python train.py --help将显示可用选项。要在两张 24GB 卡上包含的羊驼数据集上训练 llama2-7b,您可以运行:
python train.py --train_type qlora --dataset alpaca --batch_size 8 --gradient_accumulation_steps 2 --output_dir qlora_output --log_to wandb
我们将所需的所有内容都塞进了这个文件中,以便更轻松地查看正在发生的情况并在必要时进行修改。
您应该将此脚本视为 alpha/预览版本。虽然我们已经使用它在一系列硬件上成功训练了各种实用的模型,但现在还处于早期阶段。如果您对测试和调试模型不满意,我们建议推迟几个月,以便社区更全面地测试该方法。
更新:我们很高兴看到Hugging Face 生态系统已经通过对Accelerate、Transformers、TRL和PEFT的更改提供支持。我们的代码也已被纳入 Axolotl 微调库中,并用于训练 Mixtral和其他模型。
第一步
最初,我们计划在本文中展示一些基准测试,以及基于基准测试结果的有关如何最好地利用 FSDP/QLoRA 的指导。然而,我们不得不继续推迟发布这个,因为我们每隔几天就会做出重大改进!因此,我们将在接下来的几周内跟进一篇基准测试和建议文章。
我们在这里展示的只是第一步。我们有很多改进的想法,并且我们确信开源社区会有许多我们还没有想到的其他想法!
我们希望看到这个概念证明,即可以在廉价的游戏 GPU 上扩展资源高效的 QLoRA 训练,将有助于引起更多人关注降低模型训练成本的问题。让人工智能更容易使用,让更多人不仅能够消费,而且能够构建有价值的模型,符合每个人的利益。
脚注
-
在本文中,“训练”可以指预训练或微调。↩︎
-
严格来说,我们通常不存储实际的激活,而只是存储使用梯度检查点按需重新计算它们所需的中间部分。↩︎
-
FSDP 仅支持浮点类型,但大多数量化库以整数类型存储量化权重。可选择的存储数据类型解决了这一差异。↩︎
-
FSDP 仅支持同步 PyTorch 参数和缓冲区,而大多数量化库将“量化状态”元数据存储在字典中。↩︎
-
这非常重要,因为校准数据偏差是使用这些数据相关方法可能面临的另一个主要问题。↩︎
相关文章:

您现在可以在家训练 70b 语言模型
原文:Answer.AI - You can now train a 70b language model at home 我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。 已发表 2024 年 3 月 6 日 概括 今天,我们发布了 Answer.AI 的第一个项目&#…...
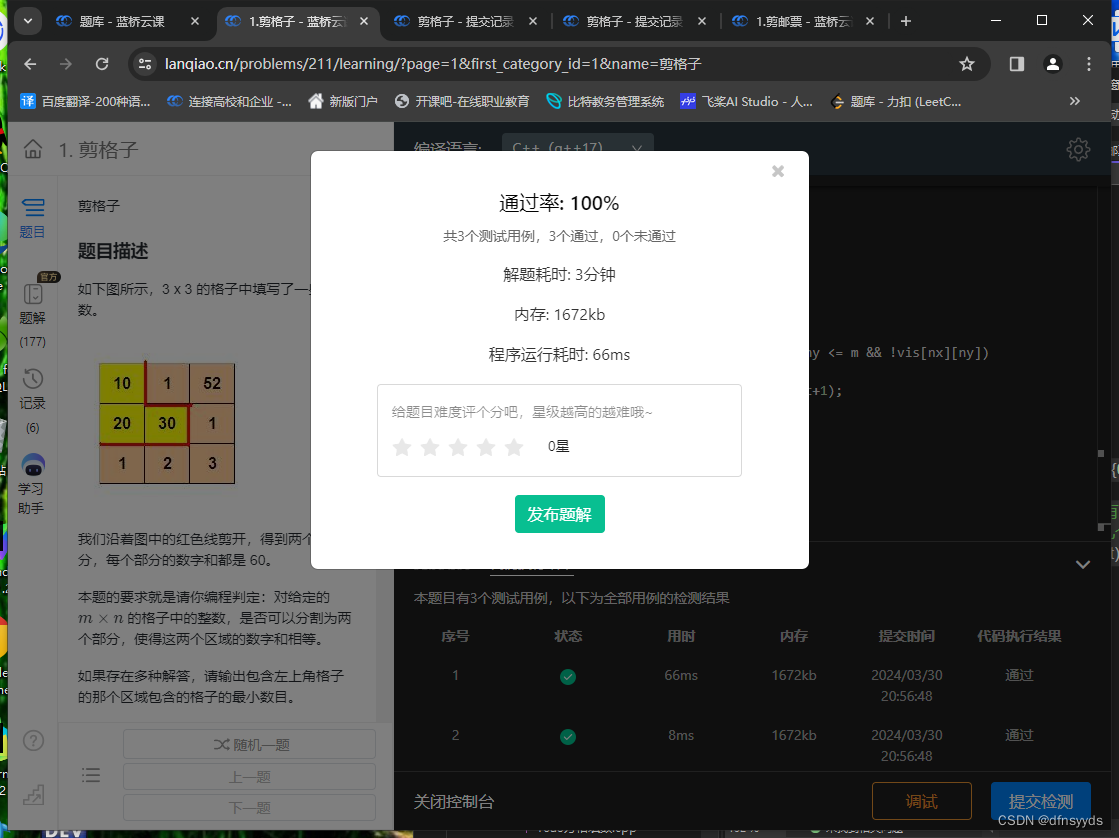
算法题剪格子使我重视起了编程命名习惯
剪格子是一道dfs入门题。 我先写了个dfs寻找路径的模板,没有按题上要求输出。当我确定我的思路没错时,一直运行不出正确结果。然后我挨个和以前写的代码对比,查了两个小时才发现,是命名风格的问题。 我今天写的代码如下ÿ…...

P19:注释
注释是什么? 在java的源程序中,对java代码的解释说明注释内容不会被编译到.class字节码文件中一个的开发习惯应该多写注释,增加程序的可读性 java中注释的方式: 单行注释:注释内容只占一行 // 注释内容多行注释&…...
)
python习题小练习(挑战全对)
1. (单选题)Python 3.0版本正式发布的时间? A. 1991B. 2000C. 2008D. 1989 2. (单选题)以下关于Python语言中“缩进”说法正确的是: A. 缩进在程序中长度统一且强制使用B. 缩进是非强制的,仅为了提高代码可读性C. 缩进可以用在任何语句之后…...

大数据学习-2024/3/30-MySQL基本语法使用介绍实例
学生信息表 create table studend(stu_id int primary key auto_increment comment 学生学号,stu_name varchar(20) not null comment 学生名字,mobile char(11) unique comment 手机号码,stu_sex char(3) default 男 comment 学生性别,birth date comment 出生日期,stu_time …...

C#_事件_多线程(基础)
文章目录 事件通过事件使用委托 多线程(基础)进程:线程: 多线程线程生命周期主线程Thread 类中的属性和方法创建线程管理线程销毁线程 事件 事件(Event)本质上来讲是一种特殊的多播委托,只能从声明它的类中进行调用,基本上说是一个用户操作&…...

vue 通过插槽来分配内容
通过插槽来分配内容 一些情况下我们会希望能和 HTML 元素一样向组件中传递内容: <AlertBox>Something bad happened. </AlertBox> 这可以通过 Vue 的自定义 <slot> 元素来实现: <template><div class"alert-box&quo…...

YOLO图像前处理及格式转换
import cv2 import numpy as np import os import glob# 数据增强函数 def augment_data(img):rows,cols,_ img.shape# 水平翻转图像if np.random.random() > 0.5:img cv2.flip(img, 1)img_name os.path.splitext(save_path)[0] "_flip.png"cv2.imwrite(img_n…...
ES6 学习(二)-- 字符串/数组/对象/函数扩展
文章目录 1. 模板字符串1.1 ${} 使用1.2 字符串扩展(1) ! includes() / startsWith() / endsWith()(2) repeat() 2. 数值扩展2.1 二进制 八进制写法2.2 ! Number.isFinite() / Number.isNaN()2.3 inInteger()2.4 ! 极小常量值Number.EPSILON2.5 Math.trunc()2.6 Math.sign() 3.…...
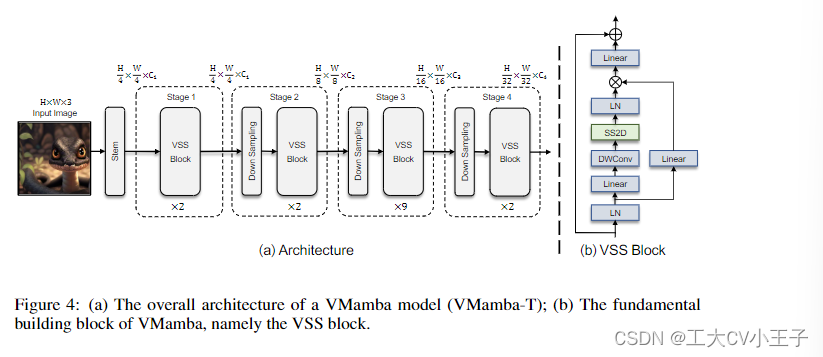
《VMamba》论文笔记
原文链接: [2401.10166] VMamba: Visual State Space Model (arxiv.org) 原文笔记: What: VMamba: Visual State Space Model Why: 多年以来CNN和VIT作为视觉特征提取的主流框架 CNN具有模型简单,共享权重&…...

手机真机连接USB调试adb不识别不显示和TCPIP连接问题
手机真机连接USB调试adb devices不显示设备和TCPIP连接 本文手机型号为NOVA 7 ,其他型号手机在开发人员模式打开等方式可能略有不同,需根据自己的手机型号修改。 文章目录 1. 打开和关闭开发者模式2. 真机USB连接调试adb不显示设备问题的若干解决方法3…...

MySQL分表后,如何做分页查询?
参考: https://blog.csdn.net/qq_44732146/article/details/127616258 user.sql 完整的执行一遍,可以做到分表和分页 数据是实时的,往一张子表里插入之后,all表就能立刻查询到 在这里实现分页查询的是MyIsam引擎,这个引擎不支持…...

【Deep Learning 11】Graph Neural Network
🌞欢迎来到图神经网络的世界 🌈博客主页:卿云阁 💌欢迎关注🎉点赞👍收藏⭐️留言📝 🌟本文由卿云阁原创! 📆首发时间:🌹2024年3月20日…...
http和https的工作原理是什么?
HTTP(HyperText Transfer Protocol)和HTTPS(HyperText Transfer Protocol Secure)是两种用于在互联网上传输数据的主要协议,它们均用于在客户端(通常是Web浏览器)与服务器之间交换信息。尽管它们…...

STL中容器、算法、迭代器
STL标准模板库封装了常用的数据结构和算法,让程序员无需太关心真实的数据结构实现。 容器 容器:用来存放数据的。 STL容器就是将运用最广泛的的一些数据结构实现出来。 常用的数据结构有:数组、链表、树、栈、队列、集合、映射表。 这些…...

深入并广泛了解Redis常见的缓存使用问题
Redis 作为一门主流技术,缓存应用场景非常多,很多大中小厂的项目中都会使用redis作为缓存层使用。 但是Redis作为缓存,也会面临各种使用问题,比如数据一致性,缓存穿透,缓存击穿,缓存雪崩&#…...
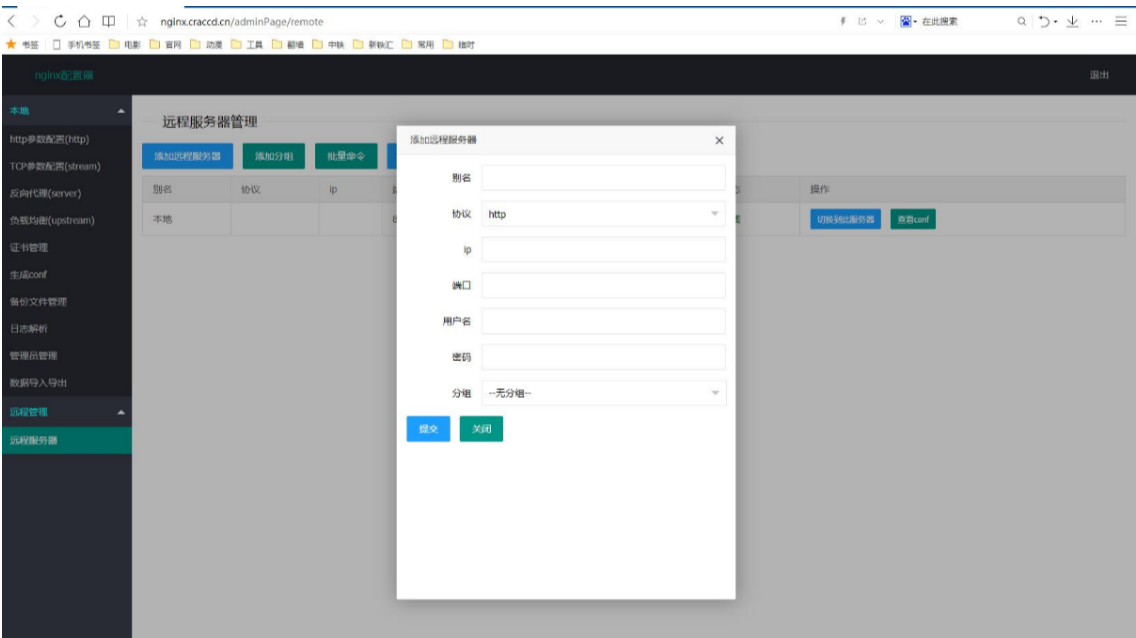
nginx界面管理工具之nginxWebUI 搭建与使用
nginx界面管理工具之nginxWebUI 搭建与使用 一、nginxWebUI 1.nginx网页配置工具 官网地址: http://www.nginxwebui.cn 源码地址:https://git.chihiro.org.cn/chihiro/nginxWebUI 2.功能说明 本项目可以使用WebUI配置nginx的各项功能, 包括http协议转发, tcp协议…...

linux下 罗技鼠标睡眠唤醒问题的解决
sudo dmesg | grep Logitech | grep -o -P "usb.?\s" 得到3-2,用上面这条命令得到哪个usb口。 下面这条命令禁用罗技鼠标睡眠唤醒系统(3-2改成你自己电脑上得到的usb口) sudo sh -c "echo disabled > /sys/bus/usb/devic…...

架构师之路--Docker的技术学习路径
Docker 的技术学习路径 一、引言 Docker 是一个开源的应用容器引擎,它可以让开发者将应用程序及其依赖包打包成一个可移植的容器,然后在任何支持 Docker 的操作系统上运行。Docker 具有轻量级、快速部署、可移植性强等优点,因此在现代软件开…...

【动手学深度学习-pytorch】 9.4 双向循环神经网络
在序列学习中,我们以往假设的目标是: 在给定观测的情况下 (例如,在时间序列的上下文中或在语言模型的上下文中), 对下一个输出进行建模。 虽然这是一个典型情景,但不是唯一的。 还可能发生什么其…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...

Python UiAutomation实战:从网页数据抓取到桌面应用,一个库打通数据采集全链路
Python UiAutomation实战:打通数据采集全链路的智能解决方案 在数据驱动的商业环境中,企业常常面临跨平台数据采集的挑战——财务系统里的交易记录需要与网站后台的报表进行交叉分析,销售数据要从桌面软件导出后上传到云端处理系统。传统的人…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南
星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 星露谷物语SMAPI模组加载器是官方推荐的模组API,它为玩家和开发者提供…...

“--glow”并不存在?!深度逆向Midjourney 6.1源码级辉光模拟协议,曝光官方刻意隐藏的4个隐式辉光增强开关
更多请点击: https://kaifayun.com 第一章:辉光效果的视觉本质与Midjourney 6.1协议悖论 辉光(Glow)并非物理光源的直接投射,而是人眼视网膜对高对比度边缘与饱和色域交界处产生的神经光学响应——一种由局部亮度梯度…...

面试官问LinkedBlockingQueue和ArrayBlockingQueue区别?别只答有界无界了,这3个实战坑才是重点
面试官追问LinkedBlockingQueue与ArrayBlockingQueue?别只答基础区别,这3个实战陷阱才是关键 当面试官抛出"LinkedBlockingQueue和ArrayBlockingQueue有什么区别"这个问题时,80%的候选人会条件反射般回答"一个有界一个无界&qu…...