笔记本电脑上部署LLaMA-2中文模型
尝试在macbook上部署LLaMA-2的中文模型的详细过程。
(1)环境准备
MacBook Pro(M2 Max/32G);
VMware Fusion Player 版本 13.5.1 (23298085);
Ubuntu 22.04.2 LTS;
给linux虚拟机分配8*core CPU 16G RAM。
我这里用的是16bit的量化模型,至少需要13G内存,如果4bit的只需要3.8G内存,当然上述不包含系统本身需要的内存。
(2)环境依赖
sudo apt update
sudo apt-get install gcc g++ python3 python3-pip
python3 -m pip install torch numpy sentencepiece(3)拉取llama.cpp工具并进行构建
在目录/home/zhangzk下:
git clone https://github.com/ggerganov/llama.cpp.git#安装依赖,llama.cpp 项目下带有 requirements.txt 文件
pip install -r requirements.txt#构建llama.cpp
cd llama.cpp/
make -j8(4)下载LLAMA2中文模型
下载LLama2的中文模型:GitHub - ymcui/Chinese-LLaMA-Alpaca-2: 中文LLaMA-2 & Alpaca-2大模型二期项目 + 64K超长上下文模型 (Chinese LLaMA-2 & Alpaca-2 LLMs with 64K long context models)
这里下载 Chinese-Alpace-2-7B的指令模型,模型文件12.9G。
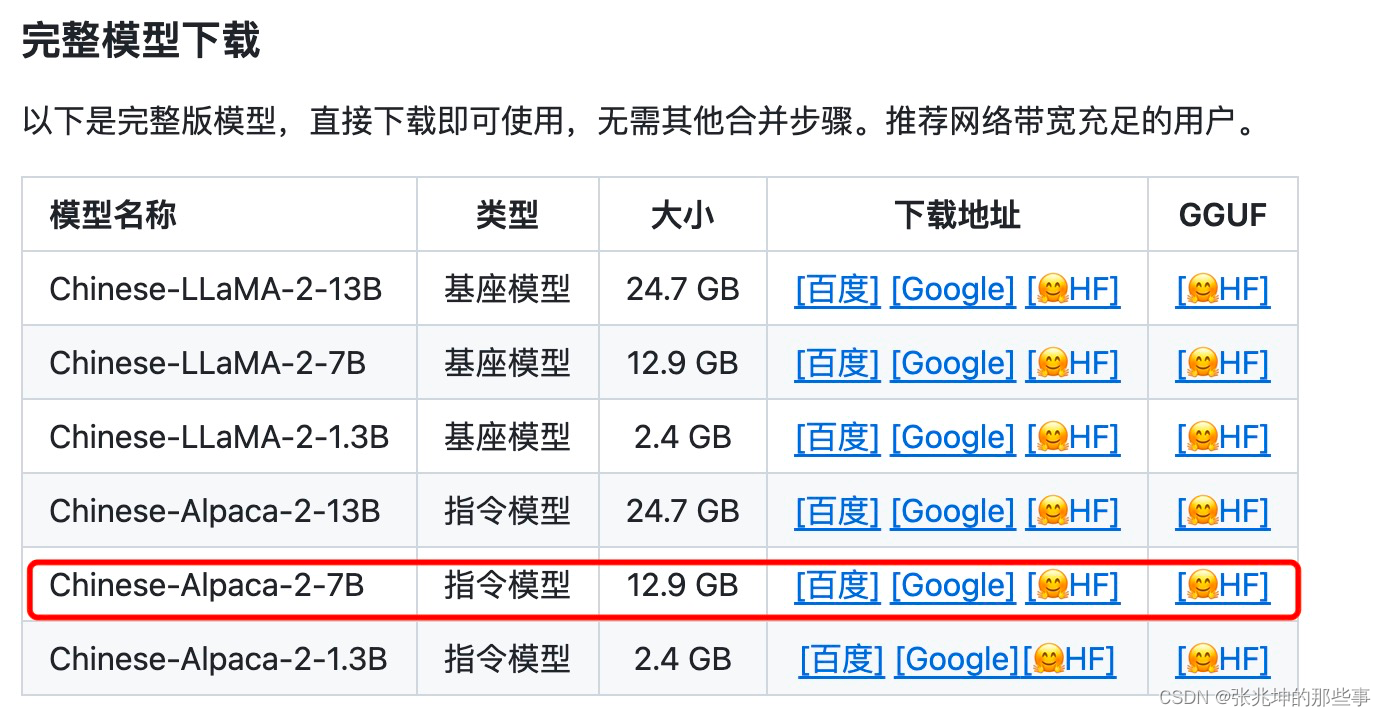
百度网盘那叫一个慢啊,没有会员能让你等死,还是梯子和GOOGLE网盘配合才叫一个快啊,几分钟的事。
把模型文件(共9个文件)都下载到 /home/zhangzk/llama.cpp/models/chinese-alpaca-2-7b-hf目录下。
(5)量化模型
在目录llama.cpp下执行:
#转换模型
python3 convert.py ./models/chinese-alpaca-2-7b-hf/#16位量化
./quantize ./models/chinese-alpaca-2-7b-hf/ggml-model-f16.gguf ./models/chinese_7b_f16.gguf f16上述两步执行完会生成新文件llama.cpp/models/chinese_7b_f16.gguf
(6)启动模型
把Chinese-LLaMA-Alpaca-2/scripts/llama-cpp/chat.sh复制到llama.cpp目录下。
chmod +x chat.sh在目录llama.cpp下执行即可看到模型输出了:
./chat.sh models/chinese_7b_f16.gguf '中国北京有哪些著名的景点?'附1:QA例子
[INST] >
You are a helpful assistant. 你是一个乐于助人的助手。
>
中国北京有哪些著名的景点?
[/INST] 北京是中国的首都,拥有丰富的历史文化遗产和自然景观资源,以下是一些著名景点:
- 故宫博物院:中国古代皇宫建筑群,是明清两代皇帝的居所,保存了大量的文物和艺术品。
- 天坛公园:古代祭祀天地之场所,是中国现存规模最大、保存最完整的祭天文化遗产之一。
- 颐和园:中国传统皇家园林,被誉为"皇家园林博物馆",以其精美的建筑、湖泊和山水景观而闻名。
- 北京长城:中国古代防御工程的代表,是世界文化遗产,也是世界上最长的城墙。
- 北海公园:古代皇家园林之一,以碧波荡漾、荷花盛开、古树参天为特色,是中国最大的人工湖泊和岛屿园林。
- 圆明园:清代皇家园林,以其精美的建筑、精美的花园和珍贵文物而闻名于世,曾经是世界上最大的皇家园林。
- 北京鸟巢:2008年北京奥运会主体育场,是一座现代化体育场馆,也是北京市区的一个地标性建筑。
- 天安门广场:中国最大的城市广场之一,是中国政治和历史的重要场所,也是游客必去的地方。
- 王府井大街:北京的商业中心,拥有各种购物、餐饮和娱乐设施,是游客体验北京文化的好地方。
- 北京大学:中国的著名高等学府,以其美丽的校园建筑和悠久的历史而闻名于世。
附2: 查看quantize 提供各种精度的量化。
zhangzk@test-llm:~/llama.cpp$ ./quantize --help
usage: ./quantize [--help] [--allow-requantize] [--leave-output-tensor] [--pure] [--imatrix] [--include-weights] [--exclude-weights] model-f32.gguf [model-quant.gguf] type [nthreads]
--allow-requantize: Allows requantizing tensors that have already been quantized. Warning: This can severely reduce quality compared to quantizing from 16bit or 32bit
--leave-output-tensor: Will leave output.weight un(re)quantized. Increases model size but may also increase quality, especially when requantizing
--pure: Disable k-quant mixtures and quantize all tensors to the same type
--imatrix file_name: use data in file_name as importance matrix for quant optimizations
--include-weights tensor_name: use importance matrix for this/these tensor(s)
--exclude-weights tensor_name: use importance matrix for this/these tensor(s)
Note: --include-weights and --exclude-weights cannot be used together
Allowed quantization types:
2 or Q4_0 : 3.56G, +0.2166 ppl @ LLaMA-v1-7B
3 or Q4_1 : 3.90G, +0.1585 ppl @ LLaMA-v1-7B
8 or Q5_0 : 4.33G, +0.0683 ppl @ LLaMA-v1-7B
9 or Q5_1 : 4.70G, +0.0349 ppl @ LLaMA-v1-7B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
10 or Q2_K : 2.63G, +0.6717 ppl @ LLaMA-v1-7B
21 or Q2_K_S : 2.16G, +9.0634 ppl @ LLaMA-v1-7B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 2.75G, +0.5551 ppl @ LLaMA-v1-7B
12 or Q3_K_M : 3.07G, +0.2496 ppl @ LLaMA-v1-7B
13 or Q3_K_L : 3.35G, +0.1764 ppl @ LLaMA-v1-7B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 3.59G, +0.0992 ppl @ LLaMA-v1-7B
15 or Q4_K_M : 3.80G, +0.0532 ppl @ LLaMA-v1-7B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 4.33G, +0.0400 ppl @ LLaMA-v1-7B
17 or Q5_K_M : 4.45G, +0.0122 ppl @ LLaMA-v1-7B
18 or Q6_K : 5.15G, +0.0008 ppl @ LLaMA-v1-7B
7 or Q8_0 : 6.70G, +0.0004 ppl @ LLaMA-v1-7B
1 or F16 : 13.00G @ 7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing
相关文章:
笔记本电脑上部署LLaMA-2中文模型
尝试在macbook上部署LLaMA-2的中文模型的详细过程。 (1)环境准备 MacBook Pro(M2 Max/32G); VMware Fusion Player 版本 13.5.1 (23298085); Ubuntu 22.04.2 LTS; 给linux虚拟机分配8*core CPU 16G RAM。 我这里用的是16bit的量化模型,…...
百度云加速方法「Cheat Engine」
加速网盘下载 相信经常玩游戏的小伙伴都知道「Cheat Engine」这款游戏内存修改器,它除了能对游戏进行内存扫描、调试、反汇编 之外,还能像变速齿轮那样进行本地加速。 这款专注游戏的修改器,被大神发现竟然还能加速百度网盘资源下载…...
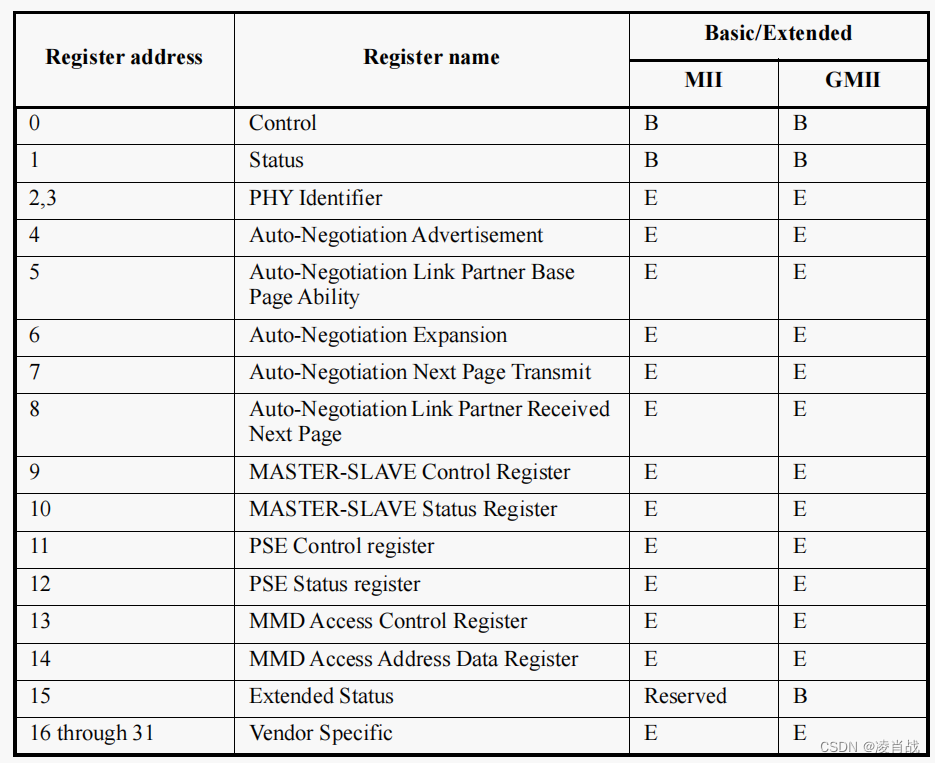
SOC内部集成网络MAC外设+ PHY网络芯片方案:PHY芯片基础知识
一. 简介 本文简单了解一下 "SOC内部集成网络MAC外设 PHY网络芯片方案" 这个网络硬件方案中涉及的 PHY网络芯片的基础知识。 二. PHY芯片基础知识 PHY 是 IEEE 802.3 规定的一个标准模块。 1. IEEE规定了PHY芯片的前 16个寄存器功能是一样的 前面说了…...

openGauss 6.0.0-RC1 版本正式发布!
openGauss 6.0.0-RC1版本正式上线! openGauss 6.0.0-RC1是社区最新发布的创新版本,版本生命周期为0.5年。(创新版本命名:由原方案 XX.1.0 Preview (例:5.1.0 preview),调整为现方案 XX.0.0-RCx&…...
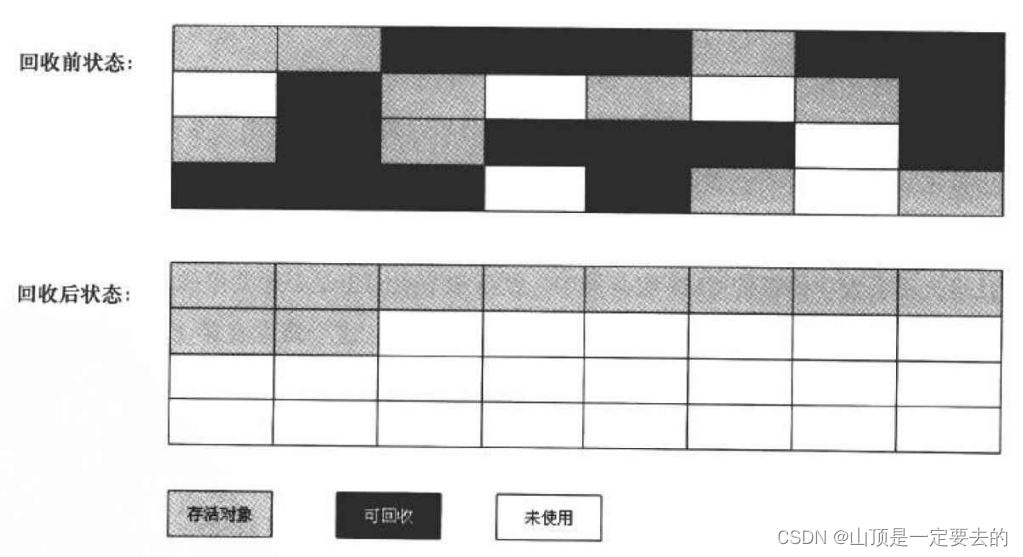
【JVM】关于JVM垃圾回收
文章目录 🌴死亡对象的判断算法🌸引用计数算法🌸可达性分析算法 🌳垃圾回收算法🌸标记-清除算法🌸复制算法🌸标记-整理算法🌸分代算法🌸哪些对象会进入新生代?…...

Unity照片墙简易圆形交互效果总结
还要很多可以优化的点地方,有兴趣的可以做 比如对象的销毁和生成可以做成对象池,走到最左边后再移动到最右边循环利用 分析过程文件,采用Blender,资源已上传,可以播放动画看效果,下面截个图: …...

Unity2018发布安卓报错 Exception: Gradle install not valid
Unity2018发布安卓报错 Exception: Gradle install not valid Exception: Gradle install not valid UnityEditor.Android.GradleWrapper.Run (System.String workingdir, System.String task, System.Action1[T] progress) (at <c67d1645d7ce4b76823a39080b82c1d1>:0) …...

蓝桥杯省赛刷题——题目 2656:刷题统计
刷题统计OJ链接:蓝桥杯2022年第十三届省赛真题-刷题统计 - C语言网 (dotcpp.com) 题目描述 小明决定从下周一开始努力刷题准备蓝桥杯竞赛。他计划周一至周五每天做 a 道题目,周六和周日每天做 b 道题目。请你帮小明计算,按照计划他将在第几…...

Python爬虫之异步爬虫
异步爬虫 一、协程的基本原理 1、案例 案例网站:https://www.httpbin.org/delay/5、这个服务器强制等待了5秒时间才返回响应 测试:用requests写一个遍历程序,遍历100次案例网站: import requests import logging import time…...
【Web】NSSCTF Round#20 Basic 个人wp
目录 前言 真亦假,假亦真 CSDN_To_PDF V1.2 前言 感谢17👴没让我爆零 真亦假,假亦真 直接getshell不行,那就一波信息搜集呗,先开dirsearch扫一下 扫的过程中先试试常规的robots.txt,www.zip,shell.phps,.git,.sv…...

【Java笔记】实现延时队列1:JDK DelayQueue
文章目录 需求创建订单类创建延时队列优缺点 Reference JDK DelayQueue是一个无阻塞队列,底层是 PriorityQueue 需求 经典的订单超时取消 创建订单类 放入DelayQueue的对象需要实现Delayed接口 public interface Delayed extends Comparable<Delayed> {…...

npm淘宝镜像源切换
查询 npm config get registry注意因为淘宝的镜像域名更换,https://registry.npm.taobao.org域名HTTPS证书到期更换为https://registry.npmmirror.com/ 切换 npm config set registry https://registry.npmmirror.com/...
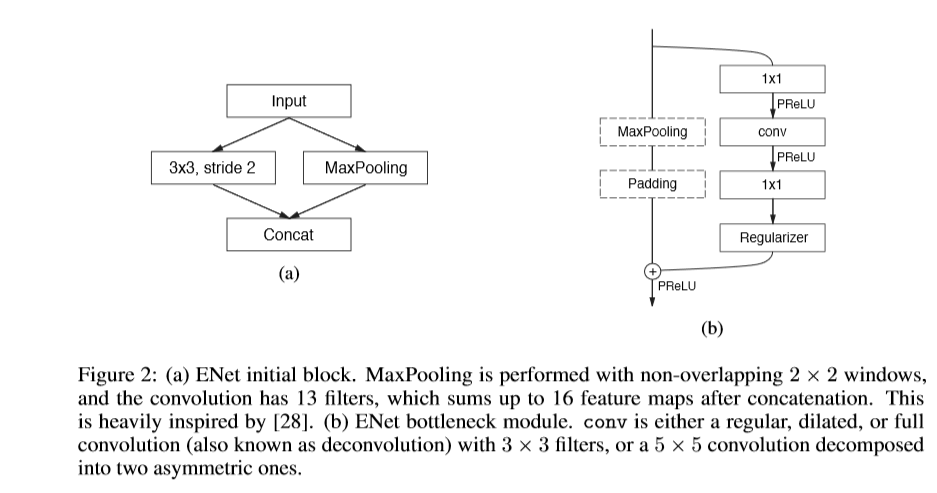
ENet——实时语义分割的深度神经网络架构与代码实现
概述 在移动设备上执行实时像素级分割任务具有重要意义。现有的基于分割的深度神经网络需要大量的浮点运算,并且通常需要较长时间才能投入使用。本文提出的ENet架构旨在减少潜在的计算负担。ENet在保持或提高分割精度的同时,相比现有的分割网络…...
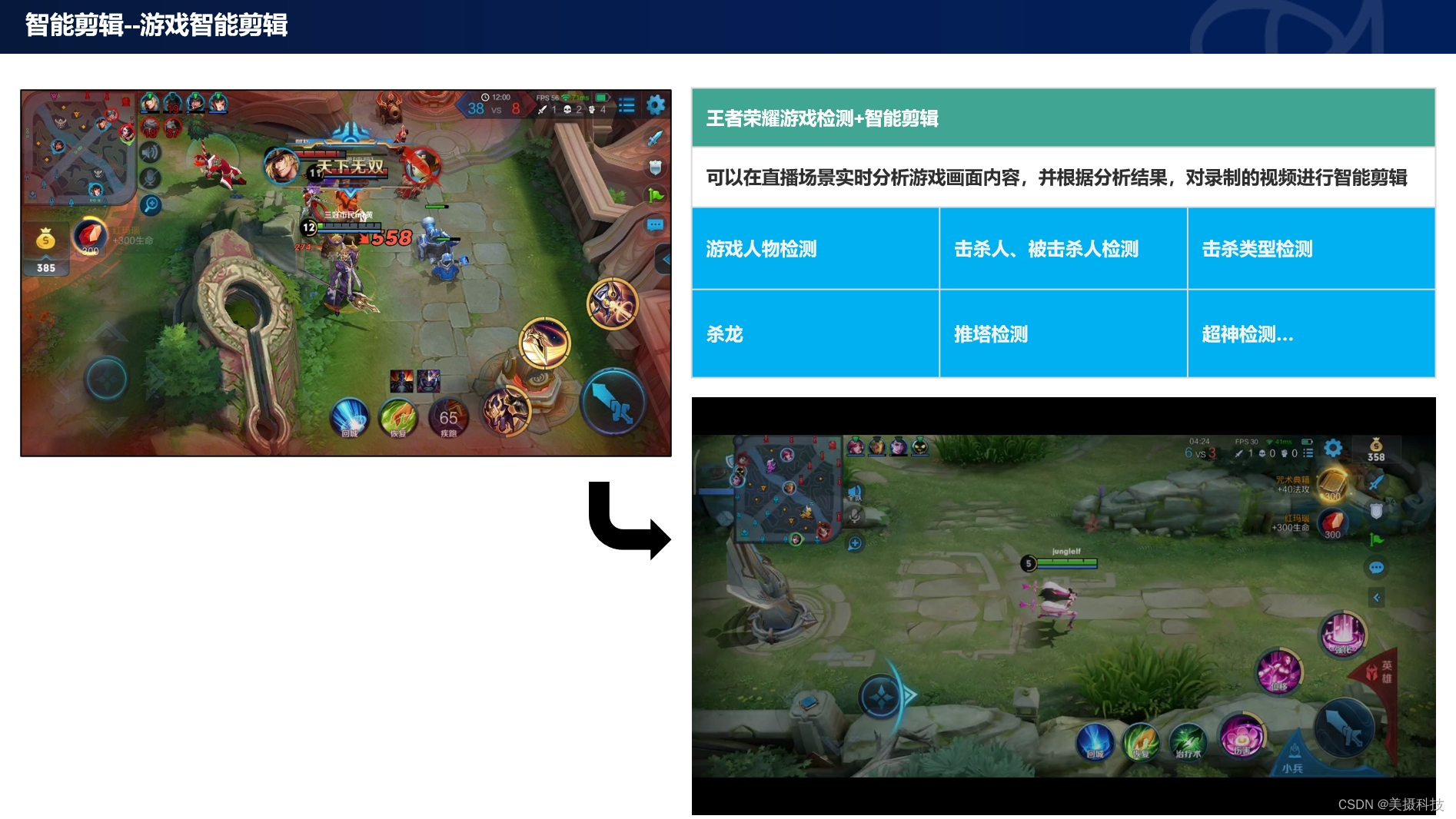
游戏领域AI智能视频剪辑解决方案
游戏行业作为文化创意产业的重要组成部分,其发展和创新速度令人瞩目。然而,随着游戏内容的日益丰富和直播文化的兴起,传统的视频剪辑方式已难以满足玩家和观众日益增长的需求。美摄科技,凭借其在AI智能视频剪辑领域的深厚积累和创…...

腾讯云轻量2核2G3M云服务器优惠价格61元一年,限制200GB月流量
腾讯云轻量2核2G3M云服务器优惠价格61元一年,配置为轻量2核2G、3M带宽、200GB月流量、40GB SSD盘,腾讯云优惠活动 yunfuwuqiba.com/go/txy 活动链接打开如下图: 腾讯云轻量2核2G云服务器优惠价格 腾讯云:轻量应用服务器100%CPU性能…...
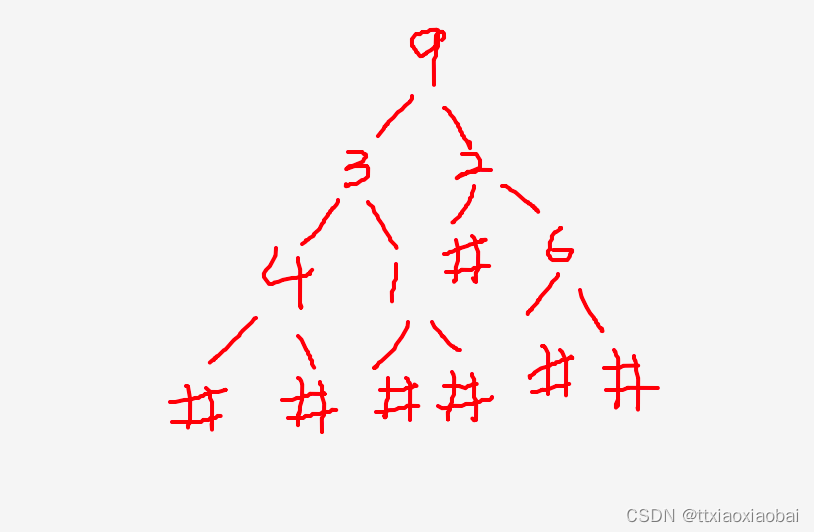
leecode 331 |验证二叉树的前序序列化 | gdb 调试找bug
计算的本质是数据的计算 数据的计算需要采用格式化的存储, 规则的数据结果,可以快速的按照指定要求存储数据 这里就不得不说二叉树了,二叉树应用场景真的很多 本题讲的是,验证二叉树的前序序列化 换言之,不采用建立树的…...

服务器安全事件应急响应排查方法
针对服务器操作系统的安全事件也非常多的。攻击方式主要是弱口令攻击、远程溢出攻击及其他应用漏洞攻击等。分析安全事件,找到入侵源,修复漏洞,总结经验,避免再次出现安全事件,以下是参考网络上文章,总结的…...

数码视讯Q7盒子刷armbian或emuelec的一些坑
首先,我手头的盒子是nand存储的,如果是emmc的,会省事很多…… 以下很多结论是我的推测,不一定准确。 1,原装安卓系统不支持SD卡或U盘启动,所以只能进uboot修改启动参数 2,原装安卓系统应该是…...

2_2.Linux中的远程登录服务
# 一.Openssh的功能 # 1.sshd服务的用途# #作用:可以实现通过网络在远程主机中开启安全shell的操作 Secure SHell >ssh ##客户端 Secure SHell daemon >sshd ##服务端 2.安装包# openssh-server 3.主配置文件# /etc/ssh/sshd_conf 4.…...
Spring Boot集成JPA快速入门demo
1.JPA介绍 JPA (Java Persistence API) 是 Sun 官方提出的 Java 持久化规范。它为 Java 开发人员提供了一种对象/关联映射工具来管理 Java 应用中的关系数据。他的出现主要是为了简化现有的持久化开发工作和整合 ORM 技术,结束现在 Hibernate,TopLink&am…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...