Python爬虫详解:原理、常用库与实战案例
前言

前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z

ChatGPT体验地址
文章目录
- 前言
- 引言:
- 一、爬虫原理
- 1. HTTP请求与响应过程
- 2. 常用爬虫技术
- 二、Python爬虫常用库
- 1. 请求库
- 2. 解析库
- 3. 存储库
- 三、编写一个简单的Python爬虫
- 四、爬虫实战案例
- 1. 分析网站结构
- 2. 编写爬虫代码
- 五、爬虫注意事项与技巧
- 结语:
引言:
随着互联网的快速发展,数据成为了新时代的石油。Python作为一种高效、易学的编程语言,在数据采集领域有着广泛的应用。本文将详细讲解Python爬虫的原理、常用库以及实战案例,帮助读者掌握爬虫技能。

一、爬虫原理
爬虫,又称网络爬虫,是一种自动获取网页内容的程序。它模拟人类浏览网页的行为,发送HTTP请求,获取网页源代码,再通过解析、提取等技术手段,获取所需数据。
1. HTTP请求与响应过程
爬虫首先向目标网站发送HTTP请求,请求可以包含多种参数,如URL、请求方法(GET或POST)、请求头(Headers)等。服务器接收到请求后,返回相应的HTTP响应,包括状态码、响应头和响应体(网页内容)。
2. 常用爬虫技术
(1)请求库:如requests、aiohttp等,用于发送HTTP请求。
(2)解析库:如BeautifulSoup、lxml、PyQuery等,用于解析网页内容。
(3)存储库:如pandas、SQLite等,用于存储爬取到的数据。
(4)异步库:如asyncio、aiohttp等,用于实现异步爬虫,提高爬取效率。
二、Python爬虫常用库
1. 请求库
(1)requests:简洁、强大的HTTP库,支持HTTP连接保持和连接池,支持SSL证书验证、Cookies等。
(2)aiohttp:基于asyncio的异步HTTP网络库,适用于需要高并发的爬虫场景。
2. 解析库
(1)BeautifulSoup:一个HTML和XML的解析库,简单易用,支持多种解析器。
(2)lxml:一个高效的XML和HTML解析库,支持XPath和CSS选择器。
(3)PyQuery:一个Python版的jQuery,语法与jQuery类似,易于上手。
3. 存储库
(1)pandas:一个强大的数据分析库,提供数据结构和数据分析工具,支持多种文件格式。
(2)SQLite:一个轻量级的数据库,支持SQL查询,适用于小型爬虫项目。
三、编写一个简单的Python爬虫
以爬取豆瓣电影TOP250为例,讲解如何编写一个简单的Python爬虫。
- 设计爬虫需求
爬取豆瓣电影TOP250的电影名称、评分、导演等信息。 - 编写代码
(1)使用requests库发送HTTP请求,获取网页源代码。
(2)使用BeautifulSoup库解析网页内容,提取所需数据。
(3)使用pandas库存储数据,并保存为CSV文件。 - 运行爬虫并展示结果
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 豆瓣电影TOP250的基础URL
base_url = 'https://movie.douban.com/top250'
# 定义一个函数来获取页面内容
def get_page_content(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}response = requests.get(url, headers=headers)if response.status_code == 200:return response.textelse:print('请求页面失败:', response.status_code)return None
# 定义一个函数来解析页面内容
def parse_page_content(html):soup = BeautifulSoup(html, 'html.parser')movie_list = soup.find_all('div', class_='item')movies = []for movie in movie_list:title = movie.find('span', class_='title').get_text()rating = movie.find('span', class_='rating_num').get_text()director = movie.find('p', class_='').find('a').get_text()movies.append({'title': title, 'rating': rating, 'director': director})return movies
# 定义一个函数来保存数据到CSV文件
def save_to_csv(movies):df = pd.DataFrame(movies)df.to_csv('douban_top250.csv', index=False, encoding='utf_8_sig')
# 主函数,用于运行爬虫
def main():movies = []for i in range(0, 250, 25): # 豆瓣电影TOP250分为10页,每页25部电影url = f'{base_url}?start={i}&filter='html = get_page_content(url)if html:movies.extend(parse_page_content(html))save_to_csv(movies)print('爬取完成,数据已保存到douban_top250.csv')
# 运行主函数
if __name__ == '__main__':main()
在实际使用中,需要根据豆瓣网站的实际情况调整以下内容:
- URL和参数:根据豆瓣电影的URL结构和参数进行设置。
- BeautifulSoup选择器:根据网页源代码的结构编写正确的选择器来提取数据。
此外,为了遵守网站的使用协议和法律法规,请确保在编写爬虫时遵循以下几点:
- 遵守Robots协议,不爬取网站禁止爬取的内容。
- 设置合理的请求间隔,避免对网站服务器造成过大压力。
- 如果遇到网站的反爬措施,如验证码、IP封禁等,请合理应对,遵守网站规定。
- 使用爬虫获取的数据请勿用于商业目的或侵犯他人隐私。
最后,由于网站结构可能会发生变化,上述代码可能需要根据实际情况进行调整。在实际应用中,请确保您的爬虫行为合法合规。
四、爬虫实战案例
以爬取某招聘网站职位信息为例,讲解如何编写一个实用的Python爬虫。
1. 分析网站结构
通过观察招聘网站的URL、参数和页面结构,找到职位信息的来源。
2. 编写爬虫代码
(1)使用requests库发送带参数的HTTP请求,获取职位列表。
(2)使用lxml库解析职位列表,提取职位详情页URL。
(3)使用PyQuery库解析职位详情页,提取职位信息。
(4)使用SQLite数据库存储职位信息。
3. 结果展示与分析
import requests
from lxml import etree
from pyquery import PyQuery as pq
import sqlite3
# 创建或连接SQLite数据库
conn = sqlite3.connect('job.db')
cursor = conn.cursor()
# 创建职位信息表
cursor.execute('CREATE TABLE IF NOT EXISTS job (id INTEGER PRIMARY KEY, title TEXT, salary TEXT, company TEXT, location TEXT)')
# 分析网站结构后得到的职位列表URL
url = 'https://www.example.com/jobs'
# 发送HTTP请求获取职位列表
params = {'page': 1, # 假设页面参数为page,这里请求第1页'city': 'beijing' # 假设城市参数为city,这里请求北京地区的职位
}
response = requests.get(url, params=params)
response.encoding = 'utf-8' # 设置字符编码,防止乱码
# 使用lxml解析职位列表,提取职位详情页URL
html = etree.HTML(response.text)
job_list = html.xpath('//div[@class="job-list"]/ul/li/a/@href') # 假设职位详情页URL在a标签的href属性中
# 遍历职位详情页URL,爬取职位信息
for job_url in job_list:job_response = requests.get(job_url)job_response.encoding = 'utf-8'job_html = pq(job_response.text)# 使用PyQuery解析职位详情页,提取职位信息title = job_html('.job-title').text() # 假设职位名称在class为job-title的元素中salary = job_html('.job-salary').text() # 假设薪资信息在class为job-salary的元素中company = job_html('.job-company').text() # 假设公司名称在class为job-company的元素中location = job_html('.job-location').text() # 假设工作地点在class为job-location的元素中# 存储职位信息到SQLite数据库cursor.execute('INSERT INTO job (title, salary, company, location) VALUES (?, ?, ?, ?)', (title, salary, company, location))conn.commit()
# 关闭数据库连接
cursor.close()
conn.close()
在实际使用中,需要根据目标网站的实际情况调整以下内容:
- URL和参数:根据目标网站的URL结构和参数进行设置。
- Xpath表达式:根据网页源代码的结构编写正确的Xpath表达式来提取数据。
- PyQuery选择器:根据网页源代码的结构编写正确的CSS选择器来提取数据。
- 数据库操作:根据需要创建合适的数据库表结构,并插入数据。
此外,为了遵守网站的使用协议和法律法规,请确保在编写爬虫时遵循以下几点:
- 遵守Robots协议,不爬取网站禁止爬取的内容。
- 设置合理的请求间隔,避免对网站服务器造成过大压力。
- 如果遇到网站的反爬措施,如验证码、IP封禁等,请合理应对,遵守网站规定。
- 使用爬虫获取的数据请勿用于商业目的或侵犯他人隐私。
五、爬虫注意事项与技巧
- 遵循Robots协议
尊重网站的爬虫协议,避免爬取禁止爬取的内容。 - 设置合理的请求间隔
避免对目标网站服务器造成过大压力,合理设置请求间隔。 - 处理反爬虫策略
了解并应对网站的反爬虫策略,如IP封禁、验证码等。 - 使用代理IP、Cookies等技巧
提高爬虫的稳定性和成功率。 - 分布式爬虫的搭建与优化
使用Scrapy-Redis等框架,实现分布式爬虫,提高爬取效率。
六、Python爬虫框架 - Scrapy:强大的Python爬虫框架,支持分布式爬取、多种数据格式、强大的插件系统等。
- Scrapy-Redis:基于Scrapy和Redis的分布式爬虫框架,实现分布式爬取和去重功能。
结语:
通过本文的讲解,相信读者已经对Python爬虫有了较为全面的认识。爬虫技能在数据分析、自然语言处理等领域具有广泛的应用,希望读者能够动手实践,不断提高自己的技能水平。同时,请注意合法合规地进行爬虫,遵守相关法律法规。祝您学习愉快!

相关文章:
Python爬虫详解:原理、常用库与实战案例
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z ChatGPT体验地址 文章目录 前言引言:一、爬虫原理1. HTTP请求与响应过程2. 常用爬虫技术 二、P…...

搭建跨境电商电商独立站如何接入1688平台API接口|通过1688API接口采集商品通过链接搜索商品下单
接口设计|接口接入 对于mall项目中商品模块的接口设计,大家可以参考项目的Swagger接口文档,以Pms开头的接口就是商品模块对应的接口。 参数说明 通用参数说明 参数不要乱传,否则不管成功失败都会扣费url说明……d.cn/平台/API类型/ 平台&…...

【GlobalMapper精品教程】073:像素到点(Pixels-to-Points)从无人机图像轻松生成点云
文章目录 一、工具介绍二、生成点云三、生成正射四、生成3D模型五、注意事项一、工具介绍 Global Mapper v19引入的新的像素到点工具使用摄影测量原理,从重叠图像生成高密度点云、正射影像及三维模型。它使LiDAR模块成为已经功能很强大的的必备Global Mapper扩展功能。 打开…...

论文复现1:Mobilealoha
abstract:从人类演示中进行的模仿学习在机器人技术中表现出了令人印象深刻的表现。然而,大多数结果都集中在桌面操作上,缺乏一般有用任务所需的移动性和灵活性。在这项工作中,我们开发了一种用于模仿双手且需要全身控制的移动操纵任务的系统。我们首先推出 Mobile ALOHA,这…...

pycharm复习
目录 1.基础语法 2.判断语句 3.while循环 4.函数 5.数据容器 1.基础语法 1.字面量 2.注释: 单行注释# 多行注释" " " " " " 3.变量: 变量名 变量值 print:输出多个结果&#x…...
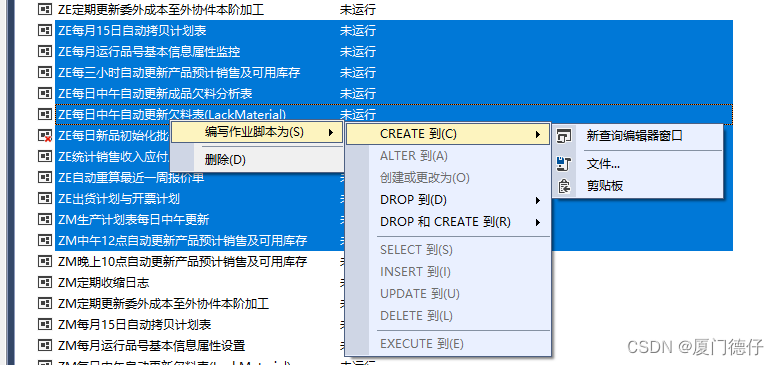
【SQLSERVER】批量导出所有作业或链接脚本
1.在Microsoft SQL Server Management Studio中选择–>视图(v)–>对象资源管理器详细信息(F7) 2.SSMS图形界面,左侧是“对象资源管理器”,右侧是“对象资源管理器详细信息”界面 3.左侧的“对象资源管理器”界面–>点击“SQLSserver代理”–…...

函数参数缺省和内联函数【C++】
文章目录 函数参数缺省函数参数缺省的条件和要求 内联函数内联函数的工作原理内联函数的定义方法内联函数的要求解决方法:直接在.h中定义内联函数的函数体 内联函数再Debug模式下默认是不展开的 函数参数缺省 顾名思义:可以少传一个/多个参数给函数&…...
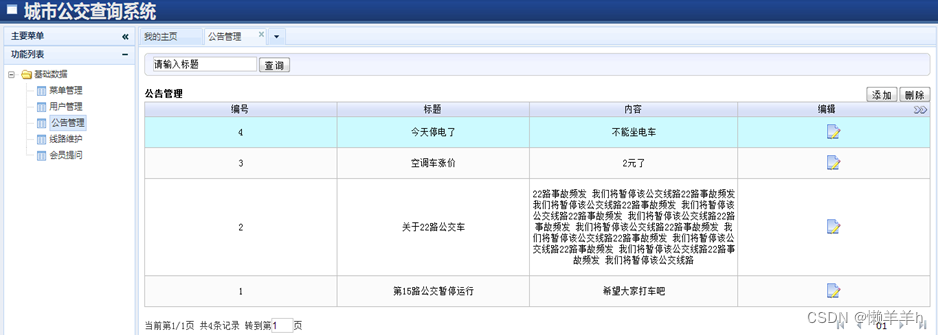
javaWeb城市公交查询系统的设计与实现
一、选题背景 随着低碳生活的普及,人们更倾向于低碳环保的出行方式,完善公交系统无疑具有重要意义。公交是居民日常生活中最常使用的交通工具之一,伴随着我国经济繁荣和城市人口增长,出行工具的选择也变得越来越重要。政府在公共…...
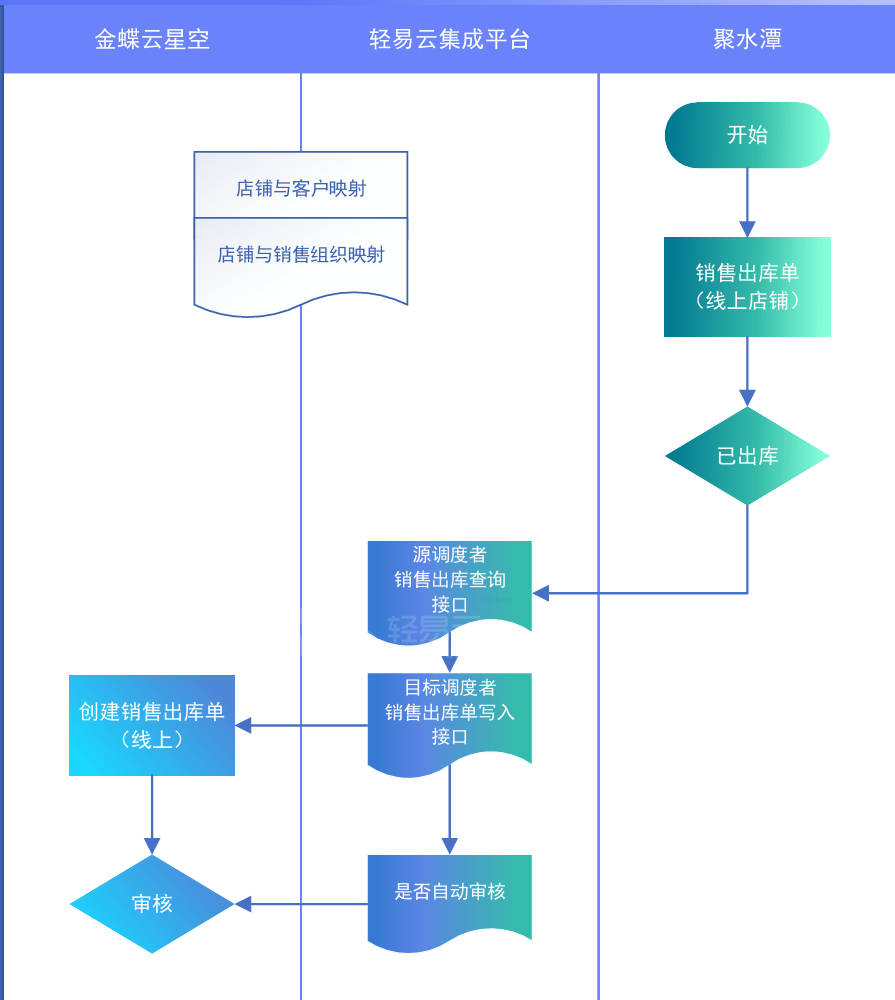
企业案例:金蝶云星空对接旺店通·企业版
某知名化妆品企业,主要专注于化妆品,护肤品等研发,销售,生产于一体化的企业。企业的业务模式涉及比较广,有2B,2C和国内外电商领域。由于对内部业务流程的连贯性和数据的准确性比较关注。财务系统用的金蝶云星空&#x…...
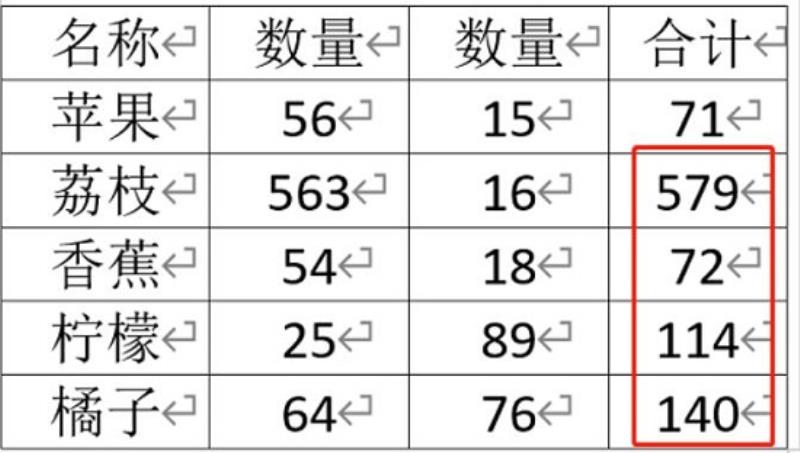
wpsword求和操作教程
wpsword求和怎么操作: 1、首先,单纯的数据是无法求和的,所以我们必须要“插入”一个“表格” 2、接着将需要求和的数据填入到表格中。 3、填完后,进入“布局”选项卡。 4、然后打开其中的“公式” 5、在其中选择求和公式“SUM”并…...

Android 手机部署whisper 模型
Whisper 是什么? “Whisper” 是一个由OpenAI开发的开源深度学习模型,专门用于语音识别任务。这个模型能够将语音转换成文本,支持多种语言,并且在处理不同的口音、环境噪音以及跨语言的语音识别方面表现出色。Whisper模型的目标是提供一个高效、准确的工具,以支持自动字幕…...

通信术语:初学者入门指南(二)
1.SAR:Synthetic Aperture Radar合成孔径雷达,是一种雷达系统,通常用于地球或行星的遥感成像。相较于传统的实孔径雷达,SAR 通过在相对较长的时间内,对来自同一地点的多个雷达反射信号进行综合处理,实现了更…...

Java中使用MQTT客户端库实现TLS/SSL加密通信的示例
以下是一个完整的Java代码示例,展示了如何使用Eclipse Paho MQTT客户端库在Java中实现TLS/SSL加密的MQTT通信。在这个示例中,我们将创建一个简单的MQTT客户端,该客户端连接到支持TLS/SSL的MQTT代理,并发布和订阅消息。 首先&…...

【m122】webrtc的比较
uint16的比较IsNewerSequenceNumber 和 u32的比较LatestTimestamp G:\CDN\WEBRTC-DEV\libwebrtc_build\src\modules\include\module_common_types_public.h/** Copyright (c) 2017 The WebRTC project authors. All Rights Reserved.** Use of this source code is governed …...

axios发送get请求但参数中有数组导致请求路径多出了“[]“的处理办法
一、情况 使用axios发送get请求携带了数组参数时,请求路径中就会多出[]字符,而在后端也会报错 二、解决办法 1、安装qs 当前项目的命令行中安装 npm install qs2、引入qs库(使用qs库来将参数对象转换为字符串) // 全局 import qs from qs Vue.proto…...
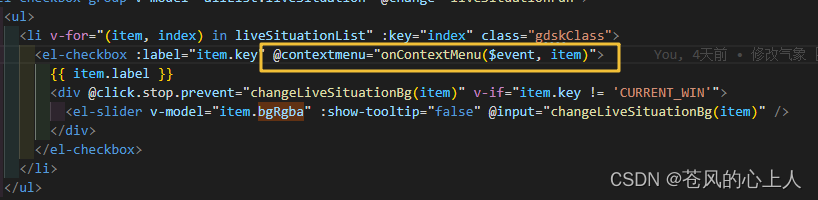
vue3的mars3d点击右键出现置顶、向下、向上等选项
效果图 下载插件 imengyu/vue3-context-menu npm i imengyu/vue3-context-menu在要使用的页面中引入一下代码 import "imengyu/vue3-context-menu/lib/vue3-context-menu.css"; import ContextMenu from "imengyu/vue3-context-menu";如果是使用在树的…...

MySQL进阶-----SQL提示与覆盖索引
目录 前言 一、SQL提示 1.数据准备 2. SQL的自我选择 3.SQL提示 二、覆盖索引 前言 MySQL进阶篇的索引部分基本上要结束了,这里就剩下SQL提示、覆盖索引、前缀索引以及单例联合索引的内容。那本期的话我们就先讲解SQL提示和覆盖索引先,剩下的内容就…...

机器学习模型之K近邻
K近邻(K-Nearest Neighbors,KNN)是一种基本的机器学习算法,它既可以用于分类问题,也可以用于回归问题。KNN算法的核心思想非常简单:一个新样本的分类或回归值取决于它与训练集中最相似的K个样本的多数类别或…...
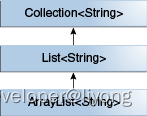
强化基础-Java-泛型基础
什么是泛型? 泛型其实就参数化类型,也就是说这个类型类似一个变量是可变的。 为什么会有泛型? 在没有泛型之前,java中是通过Object来实现泛型的功能。但是这样做有下面两个缺陷: 1 获取值的时候必须进行强转 2 没有…...
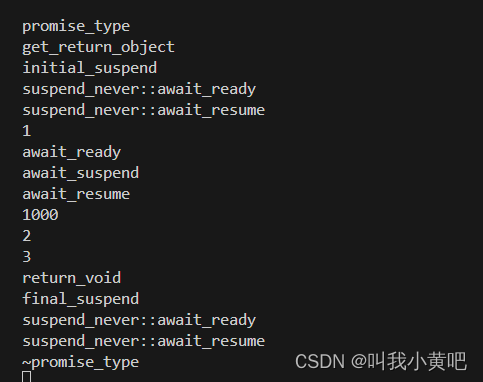
c++20协程详解(一)
前言 本文是c协程第一篇,主要是让大家对协程的定义,以及协程的执行流有一个初步的认识,后面还会出两篇对协程的高阶封装。 在开始正式开始协程之前,请务必记住,c协程 不是挂起当前协程,转而执行其他协程&a…...

一篇大模型Agents工作流优化最新综述
过去,人们总希望一个LLM直接把任务做完;现在,一个更现实的方向正在浮现——针对不同任务设计不同工作流,并让系统在执行前、执行中乃至执行后持续优化这条链路。 近日,Rensselaer Polytechnic Institute(RP…...

突破Wallpaper Engine资源壁垒:RePKG工具全方位应用指南
突破Wallpaper Engine资源壁垒:RePKG工具全方位应用指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 一、RePKG:解锁创意资源的技术钥匙 在数字创意领域…...

OpenCV轮廓匹配避坑指南:用cv2.matchShapes做形状识别,为什么你的结果总不准?
OpenCV轮廓匹配避坑指南:为什么你的cv2.matchShapes结果总是不准? 在工业质检、医疗影像分析等场景中,形状匹配的准确性直接影响着整个系统的可靠性。许多开发者在使用OpenCV的cv2.matchShapes函数时,明明按照官方文档操作&#x…...

VisionPro —— CogImageFileTool图像文件管理实战解析
1. CogImageFileTool核心功能解析 第一次接触CogImageFileTool时,我完全被它强大的图像管理能力震撼到了。这个工具就像工业视觉领域的"智能文件管家",专门处理图像文件的读写和存储问题。想象一下,你每天要处理上千张生产线上的产…...

从原理到实践:深入理解Shellcode免杀技术及其对抗策略
Shellcode免杀技术的深度解析与对抗策略演进 在网络安全攻防对抗的永恒博弈中,Shellcode免杀技术始终占据着特殊地位。不同于传统的恶意软件检测规避,Shellcode免杀更注重代码层面的"隐形"能力,其核心在于让关键载荷在内存中执行时…...

CAD图纸转PDF的4种方法,简单易懂,新手也能轻松学会!
在实际工作中,CAD图纸格式(如DWG、DXF)仅能通过AutoCAD等专业软件打开,而PDF格式作为通用文档,支持跨设备、跨平台查看,无需安装CAD软件。这种转换的必要性体现在:1. 文件分享安全:P…...

15分钟掌握OpenShamrock:基于Xposed的OneBot QQ机器人实战指南
15分钟掌握OpenShamrock:基于Xposed的OneBot QQ机器人实战指南 【免费下载链接】OpenShamrock A Bot Framework based on Xposed with OneBot11 项目地址: https://gitcode.com/gh_mirrors/op/OpenShamrock 开篇亮点展示 OpenShamrock是一款基于LSPosed框架…...

实战指南:借鉴vmware官网混合云方案,用快马平台生成高可用应用部署模板
今天在VMware官网上研究混合云方案时,发现他们的企业级架构设计特别值得借鉴。正好最近在用InsCode(快马)平台做项目部署,就尝试把官网的混合云方案转化成可落地的模板。整个过程比想象中顺利,分享下我的实战经验。 架构设计思路 VMware官网…...
及新手详细指南)
8款实用AI论文生成工具(包括爱毕业aibiye)及新手详细指南
在学术研究领域,AI技术的应用显著提升了论文写作的效率与质量。以下推荐8款功能强大的智能工具,涵盖文献解析、内容生成、文本优化等关键环节,助力研究者高效完成从资料收集到论文润色的全流程工作。这些创新解决方案能够有效简化研究过程&am…...
)
保姆级教程:手把手教你用Zabbix监控MySQL数据库(Percona模板实战)
深度实战:基于Percona模板构建企业级MySQL监控体系 当数据库规模突破百万级QPS时,传统的手动检查方式就像用体温计测量森林大火——既低效又危险。去年某电商大促期间,我们曾因未及时发现连接数耗尽导致核心交易库雪崩,这个教训让…...